927be39449c946d1768521e95b968d33.ppt
- Количество слайдов: 87



Word. Net for MT Christiane Fellbaum Dept. of Computer Science fellbaum@princeton. edu

The Challenge Globalization requires more texts and speech to be translated faster across more languages

The half-empty glass • Manual translation is difficult, expensive, time-consuming • Machine translation is of low quality, often unacceptable

The half-full glass • Human-aided machine translation can work for restricted domains (science, instruction manuals, etc. , but not literature or poetry) • Restricted domains use limited vocabulary (terminology) • Key words are less polysemous (often monosemous) • “Prefabricated” phrases (“let x be y”) don’t need to be translated anew each time
: lexical disambiguation")
Hardest part of translation(? ): lexical disambiguation

Focus on two challenges • identify the intended sense of a polysemous word in the source • find the context-appropriate word in the target language

A local resource: Word. Net

What is Word. Net? • A large lexical database, or “electronic dictionary, ” developed and maintained at Princeton http: //wordnet. princeton. edu • Includes most English nouns, verbs, adjectives, adverbs • Can be used by humans and machines • Princeton Word. Net is for English only, but it is linked to wordnets is many other languages

What’s special about Word. Net? • Traditional paper dictionaries are organized alphabetically: words that are found together (on the same page) are not related by meaning • Word. Net is organized by meaning: words in close proximity are semantically similar • Human users and computers can browse Word. Net and find words that are meaningfully related to their queries (somewhat like in a hyperdimensional thesaurus)

What’s special about Word. Net? Word. Net gives information about two fundamental, universal properties of human language: polysemy and synonymy Polysemy = one: many mapping of form and meaning Synonymy = one: many mapping of meaning and form

Polysemy One word form expresses multiple meanings {table, tabular_array} {table, piece_of_furniture} {table, mesa} {table, postpone} Note: the most frequent word forms are the most polysemous!

Synonymy One concept is expressed by several different word forms: {beat, hit, strike} {car, motorcar, automobile}
 means matching a word")
Polysemy and synonymy Understanding and generating language (as for translation) means matching a word form with the intended, contextappropriate meaning People (fluent speakers of a language) do this very efficiently
 synonymous, denotationally equivalent, words into unordered sets of")
Synonymy in Word. Net groups (roughly) synonymous, denotationally equivalent, words into unordered sets of synonyms (“synsets”) {hit, beat, strike} {big, large} {queue, line} By definition, each synset expresses a distinct meaning/concept Each word form-meaning pair is unique

Polysemy in Word. Net A word form that appears in n synsets is n-fold polysemous {table, tabular_array} {table, piece_of_furniture} {table, mesa} {table, postpone} table is fourfold polysemous/has four senses four distinct concepts are associated with the word form table

Some Word. Net stats Part of speech noun Word forms Synsets 117, 798 82, 115 verb 11, 529 13, 767 adjective 21, 479 18, 156 adverb 4, 481 3, 621 total 155, 287 117, 659

The “Net” part of Word. Net Synsets are interconnected Bi-directional arcs express semantic relations Result: large semantic network (graph)

Hypo-/hypernymy relates noun synsets Relates more/less general concepts Creates hierarchies, or “trees” {vehicle} / {car, automobile} {bicycle, bike} / {convertible} {SUV} {mountain bike} “A car is is a kind of vehicle” <=>“The class of vehicles includes cars, bikes” Hierarchies can have up to 16 levels

Hyponymy Transitivity: A car is a kind of vehicle An SUV is a kind of car => An SUV is a kind of vehicle
 {car, automobile} | {engine} / {spark plug} {cylinder} “An engine")
Meronymy/holonymy (part-whole relation) {car, automobile} | {engine} / {spark plug} {cylinder} “An engine has spark plugs” “Spark plus and cylinders are parts of an engine”

Meronymy/Holonymy Inheritance: A finger is part of a hand A hand is part of an arm An arm is part of a body =>a finger is part of a body
")
Structure of Word. Net (Nouns)

Word. Net Data Model Relations type-of part-of Concepts rec: 12345 1 - financial institute rec: 54321 2 - side of a river rec: 9876 - small string instrument rec: 65438 - musician playing violin rec: 42654 - musician rec: 35576 1 - string of instrument rec: 29551 2 - subatomic particle rec: 25876 - string instrument Vocabulary of a language bank 1 2 fiddle violin fiddler violist string
 1980")
A bit of history (or: Did we just make this stuff up? ) 1980 s Research in Artificial Intelligence (AI): How do humans store and access knowledge about concept? Knowledge about concepts is huge--must be stored in an efficient and economic fashion Hypothesis: concepts are interconnected via meaningful relations

A bit of history One hypothesis: Knowledge about concepts is computed “on the fly” via access to general concepts E. g. , we know that “canaries fly” because “birds fly” and “canaries are a kind of bird”
 | bird (has feathers,")
A bit of history animal (alive, breathes, moves. . ) | bird (has feathers, lays eggs, . . ) | canary (yellow, sings, …)

A bit of history Knowledge is stored at the highest possible node (animals move, birds fly, canaries sing) Collins & Quillian (1969) measured reaction times to statements involving knowledge distributed across different “levels”
 bird lays eggs faster than")
A bit of history People confirmed statements like (1) bird lays eggs faster than (2) canary lays eggs Hypothesis: (2) requires “look-up” at higher level, (1) doesn’t

A bit of history Collins’ & Quillian’s results are not compelling Reaction time to statements like “do canaries move? ” are influenced by prototypicality (robins are more typical birds than emus) word frequency (robin occurs more often than emu and people recognize frequent words faster), uneven semantic distance across levels But the idea inspired Word. Net (1986), which asked: Can most/all of the lexicon be represented as a semantic network? Or are there unconnectable words and concepts?

Adjective relations Strong association between members of antonymous adjective pairs: hot-cold, old-new, high-low, big-small, . . . Word. Net connects members of such pairs (“direct antonyms”) as well as similar but less salient adjectives ( e. g. , cool, lukewarm. . . )

Experimental Evidence Reaction time measurements for semantic judgments (it takes less time to confirm that hot and cold are opposites than that hot and chilly are) Weakened by: frequency, prototypicality effects

Relations among verbs Manner relation connects verbs like move-walk-run-jog communicate-talk-whisper Relations reflecting temporal or logical order: divorce-marry, snore-sleep, buy-pay Manner relation builds “trees”

WN as a lexical resource “Have concept, need words” --depart from synset, travel in Word. Net space “Have word, need concept” --query word form, find associated synsets

Is Word. Net a Thesaurus? • Yes: --it groups together meaningfully related words • No: --it labels the relations --the relations are limited --related words are linked to specific concepts (disambiguated); thesaurus is a “bag of words” --many words linked in Word. Net do not cooccur in the same thesaurus entry --Word. Net allows one to measure and quantify the semantic similarity or distance among words and concepts
 bicycle, bike, wheel,")
Web interface for WN search • Noun • キ S: (n) bicycle, bike, wheel, cycle (a wheeled vehicle that has two wheels and is moved by foot pedals) • o direct hyponym / full hyponym • キ S: (n) bicycle-built-for-two, tandem bicycle, tandem (a bicycle with two sets of pedals and two seats) • キ S: (n) mountain bike, all-terrain bike, off-roader (a bicycle with a sturdy frame and fat tires; originally designed for riding in mountainous country) キ S: (n) ordinary, ordinary bicycle (an early bicycle with a very large front wheel and small back wheel) キ S: (n) push-bike (a bicycle that must be pedaled) キ S: (n) safety bicycle, safety bike (bicycle that has two wheels of equal size; pedals are connected to the rear wheel by a multiplying gear) • • キ S: (n) velocipede (any of several early bicycles with pedals on the front wheel) • o part meronym • キ S: (n) bicycle seat, saddle (a seat for the rider of a bicycle) • • キ キ S: (n) bicycle wheel (the wheel of a bicycle) S: (n) chain (a series of (usually metal) rings or links fitted into one another to make a flexible ligament) • キ S: (n) coaster brake (a brake on a bicycle that engages with reverse pressure on the pedals S: (n) handlebar (the shaped bar used to steer a bicycle) • キ ) S: (n) kickstand (a swiveling metal rod attached to a bicycle or motorcycle or other two-wheeled vehicle; the rod lies horizontally when not in use but can be kicked into a vertical position as a support to hold the vehicle upright when it is not being ridden) Verb

Word. Net as a lexical resource • WN has been incorporated into many dictionaries • Google “define” usually brings up WN entry at the top of the list • User-created visual interfaces (e. g. , visualthesaurus. com)


Back to the problem • How does a computer find the right word associated with a given concept, or • the right concept associated with a given word? (This is is a crucial step in information retrieval, text mining, document sorting, machine translation. . . )

• Example: John needed cash so he walked over to the bank Which bank? Money institution? (building/institution? ) Sloping land by the water?
: bank (river")
Word Sense Discrimination Less difficult: homonymy (unrelated senses of a word form): bank (river bank/financial institution), bat (mammal/raquet), club (social organization/stick) Systems perform very well/near-perfect E. g. , can rely on “one sense per discourse” rule (Yarowsky) Very difficult: polysemy (related senses of a word form): bank (institution vs. building) Systems perform much worse Need local context
 • Statistical (corpus-based clustering")
Approaches to WSD • Knowledge-based (using resources like Word. Net) • Statistical (corpus-based clustering of senses; many use Word. Net in addition) • Supervised (train on manually disambiguated corpus) • Unsupervised (“discover” senses)
 a given")
Knowledge-Based Approaches Determine which sense in a lexical resource (like Word. Net) a given token (occurrence) of a word represents “Dumb” method: assume that the most frequently occurring sense of a polysemous word is the context-appropriate one Works amazingly well: 65 -70% correct for nouns Frequency is relative to a human-annotated “gold standard” corpus

Less “dumb” approaches
 •")
Basic Assumptions • Natural language context is coherent (*Colorless green ideas sleep furiously) • Words co-ocurring in context are semantically related to one another • Given word w 1 with sense 1, determine which sense 1, 2, 3, …of word w 2 is the context-appropriate one • WN allows one to determine and measure meaning similarity among co-occurring words
 of the target")
Word. Net-Based Method • Look for words in the vicinity (context) of the target word • Find that sense of the target word that is related to the context words in Word. Net (shared superordinate, parts, definition, etc. ) • Shortest path among candidate words often shows the intended sense Bank/money institution and cash are linked (share word in their definitions), so if cash and bank co-occur in a context, bank likely has the “financial institution” sense

Deriving meaning similarity metrics from WN’s structure Shortest path length is between concepts in noun hierarchies (Leacock&Chodorow) Problem: edges are not of equal length in natural language (i. e. , semantic distance is not uniform) possession | white elephant | Indian elephant

Corrections for differences in edge lengths • Scale by depth of hierarchies of the synsets whose similarity is measured (path from target to its root) • Density of sub-hierarchy: intuition that words in denser hierarchies (more sisters) are very closely related to one another • Types of link (IS-A, HAS-A, other): too many “changes of directions” reduce score
 Intuition: similarity of two concepts is the degree to which")
Information-based similarity measure (Resnik) Intuition: similarity of two concepts is the degree to which they share information in common Can be determined by the concepts’ relative position wrt the lowest common superordinate Define “class”: all concepts below the lowest common superordinate
 medium of exchange / money | cash")
Information-based similarity measure (Resnik) medium of exchange / money | cash | coin credit / | nickel dime credit card Classes: coin, medium of exchange
 Information content of a concept c: IC(c) = -logp(p(c)) p")
Information-based similarity measure (Resnik) Information content of a concept c: IC(c) = -logp(p(c)) p is p of encountering a token of concept c in a corpus Class notion entails that occurrence of a member of the class counts as occurrence of all class members Probability of a word is the sum of all counts of all class members divided by total number of words in the corpus p increases as you go up the hierarchy
 Similarity of a pair of concepts is determined by the")
Information-based similarity measure (Resnik) Similarity of a pair of concepts is determined by the least probable (most informative) class they belong to sim. R (c 1 c 2) = -logp(lso (c 1 c 2))

“Lesk” method overlap of words in definitions of synsets is a measure of similarity (Lesk: Why is a pine cone not like an ice cream cone? Because there’s no lexical overlap in their definitions!)
 properties of words in a corpus • Context-based")
Knowledge-Lean Approaches • Exploit distributional (contextual) properties of words in a corpus • Context-based clustering (with/without WN support) • Induce senses from clusters • Use WN similarity to evaluate clusters
 • For each token of a target")
Knowledge-Lean Approaches (Mc. Carthy et al. ) • For each token of a target word, find words that are distributionally similar (based on corpus analysis) • Nearest neighbors characterize the domain of the target • Use WN relations and WN gloss overlap to measure similarity between target and its neighbors • Sense of target that is most similar to words in the domain is predominant in that domain • Target word (token) is assigned that WN sense

Supervised systems • Perform better than unsupervised ones • WSD is a learning task • Train classifiers on data annotated by humans (“gold standard”) • Each sense-tagged occurrence of a particular word is a feature vector used in learning • Problem: hand-annotated data are sparse!

Supervised learning with sparse data • • Start with hand-annotated seed Determine contextual classifiers Augment contextual classifiers with WN similarity Reasoning: if baseball is a good discriminator for a sense of play, then football, hockey, etc. should also be a good discriminator for that sense of play • Use monosemous (single-sense) relatives only

Similarity measures Good reference: Ted Pedersen: : Word. Net. Similarity http: //wn-similarity. sourceforge. net
 can discriminate word senses within one")
Back to MT Now that we (think we) can discriminate word senses within one language, how do we find the corresponding senses in another language?
 for Translation Needed: Wordnet(s) in the target language(s)")
Word. Net(s) for Translation Needed: Wordnet(s) in the target language(s)

Crosslinguistic Word. Nets • Starting in late 1990 s, Word. Nets were built for languages other than English • Genetically and typologically unrelated languages: Turkish, Hindi, Chinese, Korean, Basque, Zulu, Arabic, … (currently >60) • Mapped to Princeton Word. Net www. globalwordnet. org • Great potential for crosslinguistic applications

Mapping words and synsets across multilingual Word. Nets • First set of foreign-language WNs (“Euro. Word. Net”) were built with reference to Princeton Word. Net • Princeton WN as the hub (“interlingual index”) • Each synset in each WN was linked to a “record” (PWN synset identifier) in the index • Crosslingual mapping of words and synsets proceeds via the index

Domains Road vehicle car 1 auto trein 4 train 2 German Words 2 ENGLISH Car … Train … Vehicle 3 auto tren veicolo Auto Zug voertuig 1 Transport. Device vehículo 1 Spanish Words Device Air Water 2 English Words 2 Fahrzeug 1 Object Transport 1 Inter-Lingual-Index auto treno 2 Italian Words dopravní prostředník auto 1 2 Czech Words vlak Dutch Words 1 liiklusvahend auto 3 véhicule voiture 1 train 2 French Words killavoor 2 Estonian Words
 Relations are represented")
EWN Interlingual Index is flat list of synsets (relations were removed) Relations are represented in each language-specific wordnet (incl. English WN, which “resurfaced” as one of the language-specific wordnets)

Mismatches in multilingual Word. Nets Concepts not lexicalized in English required new entries in the Interlingual Index (w/out English synset): --Arabic lexically distinguishes 12 kinds of cousin --Index may refer to “son of father’s brother”/”daughter of mother’s sister” etc. Automatic system will likely choose underspecified concept, “cousin. ” Human translator can decide to use “cousin” or a more specific paraphrase

Mismatches in multilingual Word. Nets Conversely, some lgs. lack equivalents of English words: --Dutch lacks a word for container but has kinds (hyponyms) of container (box, bag, bucket. . ) Respective hierarchies reflects this difference: Du. bag, box, . . kind of artifact Engl. bag, box, …kind of container, which is a kind of artifact Translator may specify the kind of container
 Dutch Wordnet voorwerp {object}")
English-Dutch snippet English Wordnet object artifact, artefact (a man-made object) Dutch Wordnet voorwerp {object} natural object artifact body lichaam {body} container box bag bak {box} tas {bag}

From Euro. Word. Net to Global Word. Net • Currently, wordnets exist for more than 60 languages, including: • Arabic, Bantu, Basque, Chinese, Bulgarian, Estonian, Hebrew, Icelandic, Japanese, Kannada, Korean, Latvian, Nepali, Persian, Romanian, Sanskrit, Tamil, Thai, Turkish, Zulu. . . • Many languages are genetically and typologically unrelated • http: //www. globalwordnet. org

• The more languages, the more mismatches • Not all languages have the same lexical categories (N, V, Adj)

Problems with ILI model requires lots of entries that are not represented in the ILI language (English) ILI is English-centric, may bias constructions of other wordnets (esp. those using the “translation” method)

Better model Replace ILI based on a natural language with a formal, language-independent ontology Concepts are represented by axioms in first order logic

Top level ontologies have been worked out by philosophers SUMO, Dolce, . . . strictly categorize and distinguish entities (objects, endurants), events (perdurants), properties
 • Suggested Upper Merged")
Ontology • Mapping of several competing ontologies to Word. Net(s) • Suggested Upper Merged Ontology (SUMO; Niles and Pease)
 1 K terms, 4 K")
SUMO • • • Upper-level, formal ontology (abstract concepts) 1 K terms, 4 K axioms MILO: (mid-level ontology): several K more terms SUMO+MILO: 20 K terms, 70 K axioms are written in SUO-KIF language (Knowledge Interchange Format) • All terms manually mapped to WN (and WNs in other languages)
 (before")
Axiom for “earlier” in SUMO (<=> (earlier ? INTERVAL 1 ? INTERVAL 2) (before (End. Fn ? INTERVAL 1) (Begin. Fn ? INTERVAL 2))) “An interval that precedes another; the ending of the first interval is before the beginning of the second interval” ? = variable Fn=function that takes a time interval and returns the time point at the end of the interval Ontology also has axioms for “before, ” etc.

“Clean” ontologies refer to essential properties distinguish among rigid and non-rigid entities allow reasoning, inferencing: if x is a y, and y is a z, then z is an x

An ontology differs from a wordnet Wordnets – represent how we use language e. g. , the word „cat“. Ontologies - represent what it is to be a cat. e. g. , meta-property „rigidity“

Rigidity „Cat“ is a rigid concept. „Pet“ is a non-rigid concept. A concept is rigid if it is essential to all of its instances. Permanence – Fluffy is always a cat, not always a pet. Necessity – Fluffy cannot stop being a cat. Fluffy can stop being a pet.

Reasoning with rigidity Fluffy was a cat. Fluffy was not a pet on Monday. Fluffy was a pet on Tuesday. #Fluffy was not a cat on Tuesday. Pet-hood is sensitive to time and circumstances Cat-hood is not Need to distinguish rigid and non-rigid in the ontology!
 Cat (Rigid) Pet (Non-Rigid) Fluffy (Instance)")
Making ontological distinctions Animal (Rigid) Cat (Rigid) Pet (Non-Rigid) Fluffy (Instance)

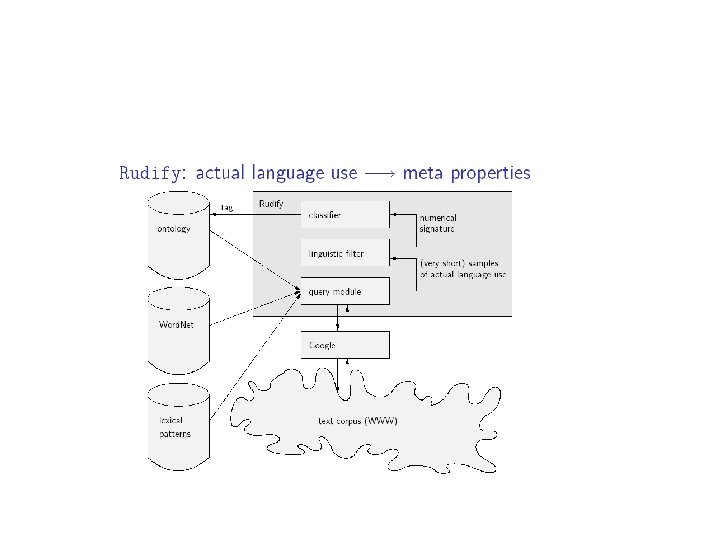
“Rudify” An ontology annotation tool currently being developed

“Rudify” Rudify learns to classify words collected from the web by means of lexical patterns Associate the words with the appropriate concept Distinguish rigid from non-rigid concepts
 (a")
Lexical patterns that distinguish rigid from non-rigid concepts X (would be | make) (a good | a bad) Y X is no longer a(n) Y vs. Xs (such as | like) Ys Xs and other Ys

Training Rudify 100 selected words/concepts contexts from Google 50 rigid, 50 non-rigid manually annotated as +/- rigid
")
Testing Rudify Two test suites: --297 Base Concepts (identified by the Spanish wordnet team) --287 terms referring to Regions and Species (common regions and species, Latin species)

How well does Rudify do? Rudify’s classification is compared with that of Onto. Clean Out of the 287 Regions and Species terms, Rudify misclassified only three, where rigid concepts were misclassified as nonrigid
 Misclassification due to lexical pattern: Wolf was classified as non-rigid “The")
Error Analysis (1) Misclassification due to lexical pattern: Wolf was classified as non-rigid “The dog is no longer a wolf but a separate species” (2) Misclassification due to polysemy/metaphor wildcat (animal, gun, mascot) Apollo (butterfly, god, space mission)
927be39449c946d1768521e95b968d33.ppt