b172c84b9586b21b517088b1c015e1eb.ppt
- Количество слайдов: 17



Web mining

Определение Web Mining — это использование методов интеллектуального анализа данных для автоматического обнаружения веб-документов и услуг, извлечения информации из вебресурсов и выявления общих закономерностей в Интернете
; описание посетителей,")
В бизнес-аналитике Web Mining решает следующие задачи: описание посетителей сайта (кластеризация, классификация); описание посетителей, которые совершают покупки в интернет-магазине (кластеризация, классификация); определение типичных сессий и навигационных путей пользователей сайта (поиск популярных наборов, ассоциативных правил); определение групп или сегментов посетителей (кластеризация); нахождение зависимостей при пользовании услугами сайта (поиск ассоциативных правил).
 — получение")
В Web Mining можно выделить следующие этапы: входной этап (англ. input stage) — получение «сырых» данных из источников (логи серверов, тексты электронных документов); этап предобработки (англ. preprocessing stage) — данные представляются в форме, необходимой для успешного построения той или иной модели; этап моделирования (англ. pattern discovery stage); этап анализа модели (англ. pattern analysis stage) — интерпретация полученных результатов.

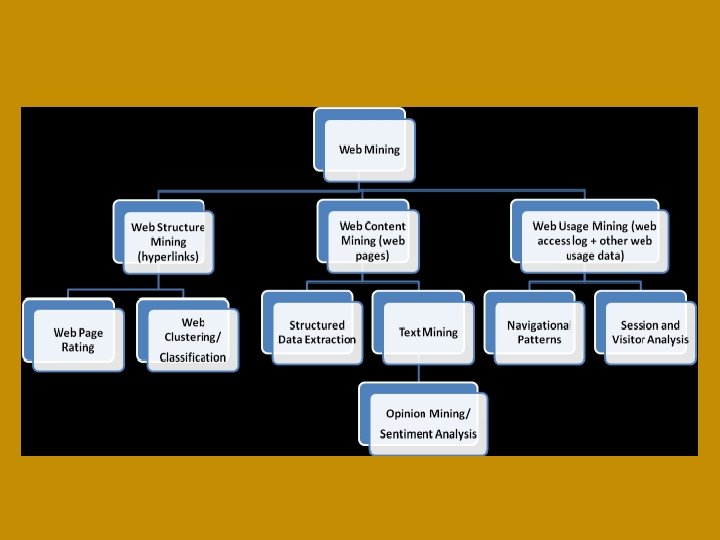
Общая взаимосвязь между категориями Web Mining и задачами интеллектуального анализа данных
 — процесс извлечения знаний из контента документов или их")
Web Content Mining (Извлечение вебконтента) — процесс извлечения знаний из контента документов или их описания, доступных в Интернете. Поиск знаний в сети Интернет является непростой и трудоемкой задачей. Именно это направление Web Mining решает её. Оно основано на сочетании возможностей информационного поиска, машинного обучения и интеллектуального анализа данных.
 — процесс обнаружения структурной информации в Интернете. Данное направление")
Web Structure Mining (Извлечение веб-структур) — процесс обнаружения структурной информации в Интернете. Данное направление рассматривает взаимосвязи между веб- страницами, основываясь на связях между ними. Построенные модели могут быть использованы для категоризации и поиска схожих веб-ресурсов, а также для распознавания авторских сайтов.
 — это автоматическое обнаружение шаблонов в маршруте передвижения")
Web Usage Mining (Анализ использования веб-ресурсов) — это автоматическое обнаружение шаблонов в маршруте передвижения пользователя и связанных с ним данными, собранными или приобретенными в результате взаимодействия с одним или несколькими веб -сайтами. Это направление основано на извлечении данных из логов веб-серверов. Целью анализа является выявление предпочтений посетителей при использовании тех или иных ресурсов сети Интернет.

Web Mining и информационный поиск Некоторые утверждают, что информационный поиск в Интернете — это частный случай Web Mining, другие ассоциируют Web Mining с интеллектуальным информационным поиском. На самом деле информационный поиск — это автоматический поиск всех необходимых документов, однако, в то же время не исключено получение некоторых нерелевантных документов. Основные задачи информационного поиска заключаются в поиске полезных документов, полнотекстовом индексировании, и в настоящее время исследования в области информационного поиска включают в себя моделирование, классификацию и категоризацию документов, пользовательских интерфейсов, визуализацию данных, фильтрацию, и т. д. Задача, которую, как считается, выполняет частный случай Web Mining — это классификация или категоризация веб-документов, которые могут быть использованы для индексации. В этой связи, Web Mining является частью процесса информационного поиска. Тем не менее, следует отметить, что не все задачи индексации используют методы интеллектуального анализа данных.

Web Mining и извлечение информации Целью информационного извлечения является превращение коллекции документов, обычно с помощью информационно-поисковых систем, в легко усвояемую и проанализированную информацию. Процесс извлечения информации направлен на вынимание релевантных фактов из документов, в то время как процесс информационного поиска направлен на селекцию релевантных документов. Первый заинтересован в структуре или представлении документа, то есть работает на уровне тонкой детализации, а второй рассматривает текст документа как коллекцию неупорядоченных слов. Тем не менее, различия между двумя процессами становятся несущественными, если цель информационного поиска — это извлечение информации. Благодаря динамике и разнообразию веб содержимого, создание ручного режима систем информационного извлечения не представляется возможным. В связи с этим, большинство систем по извлечению данных сосредотачивают внимание на конкретные веб-сайты. Другие используют обучающие машины или методы интеллектуального анализа данных и способны извлекать веб-документы в автоматическом или полуавтоматическом режиме. С этой точки зрения, Web Mining является частью процесса извлечения информации из Интернета.

Web Mining и машинное обучение Web Mining работает не по тому же принципу, что и применяющиеся в Интернете методы машинного обучения. Тем не менее, между двумя областями исследований существует тесная связь, и методы машинного обучения могут быть применены к процессам Web Mining. Например, недавние исследования показали, что применение методов машинного обучения может улучшить процесс классификации текстов, по сравнению с результатами работы традиционных методов информационного поиска.

Web Content Mining описывает автоматический поиск информационных ресурсов в Интернете и включает в себя добычу содержимого из вебданных. По сути, Web Content Mining является аналогом метода интеллектуального анализа данных для реляционных баз данных, так как существует возможность найти похожие типы знаний из неструктурированных данных, находящихся в веб-документах. Вебдокумент может содержать несколько типов данных, такие как текст, изображения, аудио, видео, метаданные и гиперссылки. Некоторые из них частично структурированные, такие как HTML-документы, некоторые более структурированные, такие как данные в таблицах или базах данных, но большинство информации хранится в неструктурированных текстовых данных. Существуют различные методы поиска информации в Интернете. Наиболее распространенным подходом является поиск на основе ключевых слов. Традиционные поисковые системы имеют сканеры для поиска и сбора полезной информации в Интернете, методы индексирования для хранения информации и обработки запросов, чтобы предложить пользователям более точную информацию. Web Content Mining выходит за рамки традиционной технологии IR (англ. Information Retrieval).

Web Structure Mining — это процесс выявления структурной информации в Интернете Web Structure Mining пытается обнаружить модель, лежащую в основе ссылочной структуры в Интернете. Модель основана на топологии гиперссылки с или без описания ссылки. Эта модель может быть использована для классификации Веб-страницы и полезна для получения информации, такие как сходство и отношения между вебсайтами. Ссылочная структура содержит важную информацию, и может помочь в фильтрации и ранжировании веб-страниц. В частности, ссылка со страницы А на страницу В может считаться рекомендацией страницы B автором А. Были предложены некоторые новые алгоритмы, использующие ссылочную структуру не только для поиска по ключевым словам, но и других задач, таких как автоматическое создание Yahoo-подобных иерархий или идентификаций сообществ в Интернете. Качественное выполнение этих алгоритмов, как правило, лучше, чем исполнение IR -алгоритмов, поскольку они используют больше информации, чем просто содержимое страниц.

Web Usage Mining — это процесс извлечения полезной информации из пользовательских журналов доступа, журналов прокси-сервера, браузерных журналов, пользовательских сессионных данных. Говоря простым языком, Web Usage Mining — это процесс выяснения того, что пользователи делают в Интернете. Анализируется следующая информация: какие страницы просматривал пользователь; какова последовательность просмотра страниц. Анализируется также, какие группы пользователей можно выделить среди общего их числа на основе истории просмотра Web-узла. Статистика фиксирует идентификационные данные веб-пользователей вместе с их поведением на сайте. В зависимости от вида использования данных, результатом работы Web Usage Mining будут являться: Данные веб-сервера; Данные серверных приложений; Данные прикладного уровня.

Плюсы Web Usage Mining имеет ряд преимуществ: Государственные учреждения используют эту технологию для классификации угроз и для борьбы с терроризмом. Эта технология позволила электронной торговле создать персонализированный маркетинг, который в конечном итоге привел к увеличению объемов торговли. Компании могут установить более тесные взаимоотношениями с клиентами, предоставляя им именно то, что им нужно. Компании могут лучше понять потребности клиента и быстрее реагировать на потребности клиентов. Компании могут найти, привлечь и удержать клиентов, сэкономить на себестоимости продукции за счет использования приобретенного понимания требований заказчика. Компании повышают рентабельность за счет целевого ценообразования на основе созданных профилей.

Минусы Web Usage Mining Самый критикуемый этический вопрос, связанный с Web Usage Mining, является вопрос о вторжении в частную жизнь. Защита считается нарушенной, когда полученная информация об отдельном пользователе используется или распространяется без их ведома и согласия. Полученные данные будут проанализированы и кластеризованы в форме профилей или будут анонимными до кластеризации без создания личных профилей. Таким образом, эти приложения деиндивидуализируют пользователя, судя о них только по их щелчками мыши. Другой важной проблемой является то, что компании по сбору данных могут их использовать для совершенно разных целей, что существенно нарушает интересы пользователей. Растущая тенденция использования персональных данных в качестве товара призывает владельцев веб-сайтов к торговле этими данными, расположенными на их сайтах. Некоторые алгоритмы интеллектуального анализа могут использовать спорные атрибуты, как пол, раса, религия или сексуальная ориентация. Эти методы могут быть против антидискриминационного законодательства.
b172c84b9586b21b517088b1c015e1eb.ppt