a0ef4fa6bb404eea6ac9de8f431ce1df.ppt
- Количество слайдов: 132



Web Caches 張燕光 資訊 程系 成功大學 ykchang@mail. ncku. edu. tw

Introduction • • HTTP What is a Web Cache? How Web Cache Works? Internet Cache Protocol (ICP) The Centralized Protocol The Distributed Protocol Conclusion Future Works

HTTP • Tim Berners-Lee invented • HTTP/1. 0, the most popular protocol on Internet • Request-Response Model • Request method, headers, and response status • HTTP/1. 1 – Cache Control

Request Origin Server directly HTTP Request Web Browser Web Server HTTP Request Web Browser

Definition • A web cache is a place where temporary copies of objects are kept. – Essentially, once the object pointed to by a URL has been cached, subsequent requests for the URL will result in the cached copy being returned, and little or no extra network traffic. • Ideas from: CPU cache, File system cache, An Internet component have been caching for a long time DNS(Domain Name System)

Web Caching Proxy • Cache data close to the clients • Proxy cache sits between origin web servers and clients • receive requests from clients – service the requests locally if valid copy of the requested objects exist in the cache – otherwise, get the requested objects for the clients and save a copy of the object locally

Adding a cache proxy HTTP Request Web Browser Web Server HTTP Request Web Browser Cache Server
![Web Caching: Advantages [I] • Reduce latency: – take less time to get an](https://present5.com/presentation/a0ef4fa6bb404eea6ac9de8f431ce1df/image-8.jpg "Web Caching: Advantages [I] • Reduce latency: – take less time to get an")
Web Caching: Advantages [I] • Reduce latency: – take less time to get an object from caching proxy than origin server (popular objects) – Because of traffic reduction, not cached pages can be retrieved relatively faster than no-cache environment, due to less network traffic and lesser server load • Reduce traffic, network congestion, or bandwidth consumption: the popular objects are only obtained from origin server once
![Web Caching: Advantages [II] • Reduce the load of remote web server: – by](https://present5.com/presentation/a0ef4fa6bb404eea6ac9de8f431ce1df/image-9.jpg "Web Caching: Advantages [II] • Reduce the load of remote web server: – by")
Web Caching: Advantages [II] • Reduce the load of remote web server: – by means of disseminating data among caches over the Internet • Robustness of web service: if remote web server is down (or network partitioning), cached copy can be used instead for most of static data
![Web Caching: Advantages [III] • A side effect: easy to get aggregate access pattern](https://present5.com/presentation/a0ef4fa6bb404eea6ac9de8f431ce1df/image-10.jpg "Web Caching: Advantages [III] • A side effect: easy to get aggregate access pattern")
Web Caching: Advantages [III] • A side effect: easy to get aggregate access pattern for analysis • the cache may be pre-loaded with the relevant URLs • Cache may be a control point for uses inside an institution with bandwidth management, QOS, access control, etc.
![Web Caching: Disadvantages [I] • a client might be looking at stale data due](https://present5.com/presentation/a0ef4fa6bb404eea6ac9de8f431ce1df/image-11.jpg "Web Caching: Disadvantages [I] • a client might be looking at stale data due")
Web Caching: Disadvantages [I] • a client might be looking at stale data due to the lack of proper proxy updating, • access latency may increase in the case of a cache miss due to extra proxy processing. – Hence, cache hit rate should be maximized and the cost of a cache miss should be minimized when designing a caching system. – Example • A single proxy is a single point of failure.
![Web Caching: Disadvantages [II] • A single proxy cache is always a bottleneck. –](https://present5.com/presentation/a0ef4fa6bb404eea6ac9de8f431ce1df/image-12.jpg "Web Caching: Disadvantages [II] • A single proxy cache is always a bottleneck. –")
Web Caching: Disadvantages [II] • A single proxy cache is always a bottleneck. – A limit has to be set for # of clients a proxy can serve. – An efficiency lower bound (i. e. the proxy system is ought to be at least as efficient as using direct contact with the remote servers) should also be enforced. – Which page to be removed from its cache? (cache placement and replacement) • Reducing hits on the original remote server might disappoint information providers, since they cannot maintain a true hits log of their pages. – Cache-busting technique (RFC 2227) – Hence, they might decide not to allow their documents to be cacheable. distributed among proxies? (control information distribution)
![Web Caching: Disadvantages [III] • Can confuse logging and access control, e. g. on](https://present5.com/presentation/a0ef4fa6bb404eea6ac9de8f431ce1df/image-13.jpg "Web Caching: Disadvantages [III] • Can confuse logging and access control, e. g. on")
Web Caching: Disadvantages [III] • Can confuse logging and access control, e. g. on subscription services. • Potential invasion of your privacy • another service you have to find the time to set up and maintain! • May have to justify cost of extra hardware. • require expertise you don't have - e. g. Unix or Windows NT/2000

Isolated Cache • Browser cache – only serves the users using the same computer on which the browser resides (Netscape, IE, Mosaic, …) – useful when the user clicks the ‘Back’ button • Proxy Cache (Caching proxy) – similar, but in a large scale • Web server-side cache • It may cause confusion if not aware of its existence (e. g. dynamic CGI, user updates on the server, etc. , reload may not work)

Where is Web Cache? • Main Memory Cache • Disk Cache • No CPU Cache (too small)

How Web Cache Works? • All caches have a set of rules: – How to determine if the copy in the cache is fresh or not (Expiration model in HTTP/1. 1) – How to check if the copy in the cache is consistent with the one in the origin server (validation model in HTTP 1. 1) – When to serve the requested object from the cache if the copy in the cache is fresh or even not fresh (Cache-Control in HTTP/1. 1) – When to save the objects in the cache (Cache. Control in HTTP/1. 1)
 • If object's headers tell cache not to")
How Web Cache Works? (cont. ) • If object's headers tell cache not to keep the object, it won't. Also, if no validator is present, most caches will mark the object as uncacheable. • If the object is authenticated or secure, it won't be cached. • If an object is stale, the origin server will be asked to validate the object, or tell the cache whether the copy that it has is still good.
 • A cached object is considered fresh (that")
How Web Cache Works? (cont. ) • A cached object is considered fresh (that is, able to be sent to a client without checking with the origin server): – If it has an expiry time or other age-controlling directive set, and is still within the fresh period. – If a browser cache has already seen the object, and has been set to check once a session. – If a proxy cache has seen the object recently, and it was modified relatively long ago. • Fresh documents are served directly from the cache, without checking with the origin server.
")
CHU proxy hit ratio Proxy. chu. edu. tw 70 60 Hit ratio 50 (%) 40 30 20 10 0 1 G 2 G 3 G 4 G 5 G Cache Size 6 G 7 G
 50 40 30 20")
DEC proxy hit ratio DEC 70 60 Hit ratio (%) 50 40 30 20 10 0 1 G 2 G 3 G 4 G 5 G Cache Size 6 G 7 G

Hit Ratio • • Cache hit ratio of backbone server > local Increase as the number of users Image > other type pages Small > large file

Increase Hit Ratio • Buy a larger disk • Internet accelerator (replaces browsers cache with its own larger one), plus it notifies you when the content has changed • Prefetching, DNS resolution caching, persistent connections, optimizations and advertisement blocking • Refresh, filtering (link)

Configuration • Netscape has its own disk based caching mechanism, but this does not seem to be suitable for sharing between multiple users. • Internet Explorer: There a variety of methods of configuring proxy mode, depending on the Operating System and Internet Explorer version you're running. – Some versions also support the Netscape proxy auto-configuration (PAC) format, which requires the browser to download a Java. Script program from a pre-configured URL.

Configure Proxy in Netscape
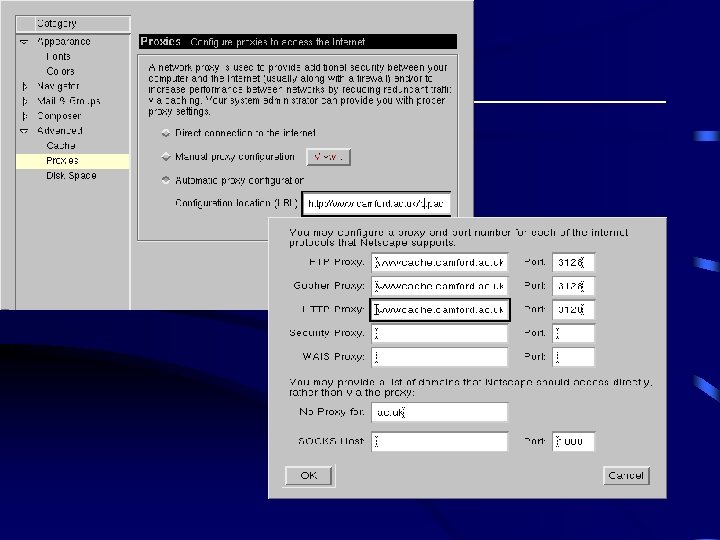

Netscape Configuration files • Windows: In the Proxy Information section of netscape. ini – (Note) you may find that you Wais_Proxy. Port=8001 have no netscape. ini in 32 -bit Ftp_Proxy. Port=3128 Gopher_Proxy. Port=3128 version, or just an empty file Http_Proxy. Port=3128 of this name. It looks as No_Proxy=ac. uk, org. uk Gopher_Proxy=wwwcache. camford. ac. uk though all of the Netscape FTP_Proxy=wwwcache. camford. ac. uk configuration info is being HTTP_Proxy=wwwcache. camford. ac. uk stored in the Registry, though Wais_Proxy=wwwcache. camford. ac. uk it's not clear exactly where.

Netscape Configuration files • Unix: In home directory as. netscape-preferences in version 1 and netscape/preferences in version 2 and above FTP_PROXY: wwwcache. camford. ac. uk: 3128 HTTP_PROXY: wwwcache. camford. ac. uk: 3128 GOPHER_PROXY: wwwcache. camford. ac. uk: 3128 WAIS_PROXY: wwwcache. camford. ac. uk: 8001 NO_PROXY: ac. uk, org. uk The variable PROXY_MODE is used to control whether proxying is enabled, and if so whether a static list of proxy servers is used, or a Java. Script program : - 0 - no proxying of requested URLs, 1 - manual proxy configuration, 2 - download proxy autoconfiguration Java. Script, e. g. PROXY_MODE: 2 PROXY_URL: http: //www. camford. ac. uk/p. pac Indicates that the proxy autoconfiguration script http: //www. camford. ac. uk/p. pac should be used.

Proxy Auto Configuration • One single institutional proxy is not enough – Single point of failure – Pages need different proxy to get faster responses – Make proxies transparent to users • proxy auto-configuration (PAC) is supported by Netscape and IE – Javascript code (a subset)
 { if (url. substring(0, 5)")
PAC example • function Find. Proxy. For. URL(url, host) { if (url. substring(0, 5) == "http: ") { return "PROXY x. xxx: p; DIRECT"; } else if (url. substring(0, 6) == "https: ") { return "PROXY y. yyy: q; DIRECT"; } else if (url. substring(0, 4) == "ftp: ") { return "PROXY z. zzz: r; DIRECT"; } else { return "DIRECT"; } } • A complete example: proxy. chu. edu. tw/proxy. pac

Example #1: • Use proxy for everything except local hosts • All hosts which aren't fully qualified, or the ones that are in local domain, will be connected to directly. Everything else will go through w 3 proxy: 8080. If the proxy goes down, connections become automatically direct. • function Find. Proxy. For. URL(url, host){ if (is. Plain. Host. Name(host) || dns. Domain. Is(host, ". netscape. com")) return "DIRECT"; else return "PROXY w 3 proxy. netscape. com: 8080; DIRECT"; } • Note: This is the simplest and most efficient autoconfig file for cases where there's only one proxy.

Example #2: • use the proxy for everything else except local hosts in the netscape. com domain, with the further exception that hosts www. netscape. com and merchant. netscape. com will go through the proxy • function Find. Proxy. For. URL(url, host) { if ((is. Plain. Host. Name(host) || dns. Domain. Is(host, ". netscape. com")) && !local. Host. Or. Domain. Is(host, "www. netscape. com") && !local. Host. Or. Doamin. Is(host, "merchant. netscape. com")) return "DIRECT"; else return "PROXY w 3 proxy. netscape. com: 8080; DIRECT"; }
 { if (is. Plain.")
Example #3: subnet-based • function Find. Proxy. For. URL(url, host) { if (is. Plain. Host. Name(host) || dns. Domain. Is(host, ". mydomain. com") || is. In. Net(host, "198. 95. 0. 0", "255. 0. 0")) return "DIRECT"; else return "PROXY proxy. mydomain. com: 8080"; }

Example #4: Load balancing/routing based on URL patterns • function Find. Proxy. For. URL(url, host) { if (is. Plain. Host. Name(host) ||dns. Domain. Is(host, ". mydomain. com")) return "DIRECT"; else if (sh. Exp. Match(host, "*. com")) return "PROXY proxy 1. mydomain. com: 8080; " + "PROXY proxy 4. mydomain. com: 8080"; else if (sh. Exp. Match(host, "*. edu")) return "PROXY proxy 2. mydomain. com: 8080; " + "PROXY proxy 4. mydomain. com: 8080"; else return "PROXY proxy 3. mydomain. com: 8080; " + "PROXY proxy 4. mydomain. com: 8080"; }

PAC for web server • httpd. conf in apache – Add. Type application/x-ns-proxy-autoconfig. pac

How to control cache? • HTML Meta Tags – In a document's <HEAD> section -- mark a document as uncacheable, or expire it at a certain time – Meta tags are easy to use, but aren't very effective – read by browser, not proxy – Meta tags resource
 • Many people believe that assigning")
Pragma HTTP Headers (and why they don't work) • Many people believe that assigning a Pragma: nocache HTTP header to an object will make it uncacheable. This is not necessarily true; • HTTP specification does not set any guidelines for Pragma response headers; instead, Pragma request headers (the headers that a browser sends to a server) are discussed. • Although a few caches may honor this header, the majority won't, and it won't have any effect. • Use the HTTP headers

Controlling Freshness with the Expires Header • We saw it in RFC 2616 – Compute freshness – expires: Fri, 30 Oct 1998 14: 19: 41 GMT
![Cache-Control Headers • max-age=[seconds] - specifies the maximum amount of time that an object](https://present5.com/presentation/a0ef4fa6bb404eea6ac9de8f431ce1df/image-38.jpg "Cache-Control Headers • max-age=[seconds] - specifies the maximum amount of time that an object")
Cache-Control Headers • max-age=[seconds] - specifies the maximum amount of time that an object will be considered fresh. Similar to Expires, this directive allows more flexibility. [seconds] is the number of seconds from the time of the request you wish the object to be fresh for. • s-maxage=[seconds] - similar to max-age, except that it only applies to proxy (shared) caches. • public - marks the response as cacheable, even if it would normally be uncacheable. For instance, if your pages are authenticated, the public directive makes them cacheable.
 to submit request")
Cache-Control Headers • no-cache - forces caches (both proxy and browser) to submit request to the origin server for validation before releasing a cached copy, every time. This is useful to assure that authentication is respected (in combination with public), or to maintain rigid object freshness, without sacrificing all of the benefits of caching. • must-revalidate - tells caches that they must obey any freshness information you give them about an object. The HTTP allows caches to take liberties with the freshness of objects; by specifying this header, you're telling cache that you want it to strictly follow your rules. • proxy-revalidate - similar to must-revalidate, except that it only applies to proxy caches.

Validators and Validation • • • Last-Modified-Time Etag If-modified-since If-matched, If-not-matched …

Tips: building a cache-aware Site • Refer to objects consistently - this is the golden rule of caching. If you serve the same content on different pages, to different users, or from different sites, it should use the same URL. This is the easiest and most effective way to make your site cache-friendly. For example, if you use /index. html in your HTML as a reference once, always use it that way. • Use a common library of images and other elements and refer back to them from different places. • Make caches store images and pages that don't change often by specifying a far-away Expires header. • Make caches recognize regularly updated pages by specifying an appropriate expiration time.
 changes,")
Tips: building a cache-aware Site • If a resource (especially a downloadable file) changes, change its name. That way, you can make it expire far • in the future, and still guarantee that the correct version is served; the page that links to it is the only one that will need a short expiry time. • Don't change files unnecessarily. If you do, everything will have a falsely young Last-Modified date. For instance, when updating your site, don't copy over the entire site; just move the files that you've changed. • Use cookies only where necessary - cookies are difficult to cache, and aren't needed in most situations. If you must use a cookie, limit its use to dynamic pages.

Tips: building a cache-aware Site • Minimize use of SSL - because encrypted pages are not stored by shared caches, use them only when you have to, and use images on SSL pages sparingly. • use the Cacheability Engine - it can help you apply many of the concepts in this tutorial. • Cacheability check

Writing Cache-Aware Scripts • By default, most scripts won't return a validator (e. g. , a Last-Modified or ETag HTTP header) or freshness information (Expires or Cache-Control). • While some scripts really are dynamic (meaning that they return a different response for every request), many (like search engines and databasedriven sites) can benefit from being cache-friendly

Writing Cache-Aware Scripts • Generally speaking, if a script produces output that is reproducable with the same request at a later time (whether it be minutes or days later), it should be cacheable. • If the content of the script changes only depending on what's in the URL, it is cacheble; • if the output depends on a cookie, authentication information or other external criteria, it probably isn't.
")
Writing Cache-Aware Scripts • The best way to make a script cache-friendly (perform better) is to dump its content to a plain file whenever it changes. Web server can treat it like any other Web page, generating and using validators, which makes your life easier. Remember to only write files that have changed, so Last-Modified times are preserved. • Another way to make a script cacheable in a limited fashion is to set an age-related header for as far in the future as practical. Although this can be done with Expires, it's probably easiest to do so with Cache. Control: max-age, which will make the request fresh for an amount of time after the request.

Writing Cache-Aware Scripts • If you can't do that, you'll need to make the script generate a validator, and then respond to If-Modified. Since and/or • If-None-Match requests. This can be done by parsing the HTTP headers, and then responding with 304 Not Modified when appropriate. Unfortunately, this is not a trival task. • Don't count on all requests from a user coming from the same host, because caches often work together. • Generate Content-Length response headers.

Writing Cache-Aware Scripts • If you have to use scripting, don't POST unless it's appropriate. The POST method is (practically) impossible to cache; if you send information in the path or query (via GET), caches can store that information for the future. POST, on the other hand, is good for sending large amount of information to the server (which is why it won't be cached; it's very unlikely that the same exact POST will be made twice). • Don't embed user-specific information in the URL unless the content generated is completely unique to that user.

Apache • run httpd –l: print a list of available modules mod_expires and mod_headers. • -enable-module=expires and -enablemodule=headers arguments to configure • mod_expires automatically calculates and inserts a Cache-Control: max-age header as appropriate.

Apache • . htaccess ### activate mod_expires Expires. Active On ### Expire. gif's 1 month from when they're accessed Expires. By. Type image/gif A 2592000 ### Expire everything else 1 day from when it's last modified ### (this uses the Alternative syntax) Expires. Default "modification plus 1 day" ### Apply a Cache-Control header to index. html <Files index. html> Header append Cache-Control "public, must-revalidate" </Files>
![Problems for Caching [I] • How are the cache proxies organized, hierarchically, distributed, or](https://present5.com/presentation/a0ef4fa6bb404eea6ac9de8f431ce1df/image-51.jpg "Problems for Caching [I] • How are the cache proxies organized, hierarchically, distributed, or")
Problems for Caching [I] • How are the cache proxies organized, hierarchically, distributed, or hybrid? (caching system architecture) • Where to place a cache proxy in order to achieve optimal performance? (placement) • What can be cached in the caching system, data, connection, or computation? (caching contents) • How do proxies cooperate with each other? (proxy cooperation)
![Problems for Caching [II] • What kind of data/information can be shared among cooperated](https://present5.com/presentation/a0ef4fa6bb404eea6ac9de8f431ce1df/image-52.jpg "Problems for Caching [II] • What kind of data/information can be shared among cooperated")
Problems for Caching [II] • What kind of data/information can be shared among cooperated proxies? (data sharing) • How does a proxy decide where to fetch a page requested by a client? (cache resolution & routing) • How does a proxy decide what and when to prefetch from Web server or other proxies to reduce access latency in the future? (prefetching)
![Problems for Caching [III] • How does a proxy manage which page to be](https://present5.com/presentation/a0ef4fa6bb404eea6ac9de8f431ce1df/image-53.jpg "Problems for Caching [III] • How does a proxy manage which page to be")
Problems for Caching [III] • How does a proxy manage which page to be stored in its cache and which page to be removed from its cache? (cache placement and replacement) • How does a proxy maintain data consistency? (cache coherency) • How is the control information (e. g. URL routing information) distributed among proxies? (control information distribution) • How to deal with data which is not cacheable? (dynamic data caching)
![Problems for Caching [IV] • How to reconstruct the requested pages? • How to](https://present5.com/presentation/a0ef4fa6bb404eea6ac9de8f431ce1df/image-54.jpg "Problems for Caching [IV] • How to reconstruct the requested pages? • How to")
Problems for Caching [IV] • How to reconstruct the requested pages? • How to cache a process (code for execution) instead of data? (concept of “Active”)

Properties of caching systems I • Fast access: – From users’ point of view, access latency is an important measurement of the quality of Web service. A desirable caching system should aim at reducing Web access latency. In particular, it should provide users a lower latency on average than those without employing a caching system. . • Transparency. – A Web caching system should be transparent for the user, the only results user should notice are faster response and higher availability.

Properties of caching systems II • Robustness. – From users’ prospect, robustness means availability - important measurement of quality of Web service. Users desire to have Web service available whenever they want. The robustness has three aspects. 1. It’s desirable that a few proxies crash wouldn’t tear the entire system down. The caching system should eliminate the single point failure as much as possible. 2. caching system should fall back gracefully to failures. 3. caching system would be design in such a way that it’s easy to recover from a failure.

Properties of caching systems III • Scalability. – We have seen an explosive growth in network size and density in last decades and is facing a more rapid increasing growth in near future. The key to success in such an environment is the scalability. – We would like a caching scheme to scale well along the increasing size and density of network. – This requires all protocols employed in the caching system to be as lightweight as possible.

Properties of caching systems IV • Efficiency. There are two aspects to efficiency. – First, how much overhead does the Web caching system impose on network? • We would like a caching system to impose a minimal additional burden on the network. This includes both control packets and extra data packets incurred by using a caching system. – Second, the caching system should not adopt any scheme which leads to under-utilization of critical resources in network.

Properties of caching systems V • Adaptivity. – It’s desirable to make the caching system adapt to the dynamic changing of the user demand the network environment. The adaptivity involves several aspects: cache management, cache routing, proxy placement, etc. This is essential to achieve optimal performance.

Properties of caching systems VI • Stability. – The schemes used in Web caching system shouldn’t introduce instabilities into the network. For example, naïve cache routing based on dynamic network information will result in oscillation. Such an oscillation is not desirable since the network is under-utilization and the variance of the access latency to a proxy or server would be very high.

Properties of caching systems VII • Load balancing. – It’s desirable that the caching scheme distributes the load evenly through the entire network. A single proxy/server shouldn’t be a bottleneck (or hot spot) and thereby degrades the performance of a portion of the network or even slow down the entire service system.

Properties of caching systems IIX • Ability to deal with heterogeneity. – As networks grow in scale and coverage, they span a range of hardware and software architectures. The Web caching schemes need adapt to a range of network architectures. • Simplicity. – Simplicity is always an asset. Simpler schemes are easier to implement and likely to be accepted as international standards. We would like an ideal Web caching mechanism to be simple to deploy.

Caching Architecture • Performance depends on the size of its client community: the bigger is the user community, the higher the hit rate on caches • Therefore, a caching architecture should provide the paradigm for caches to cooperate efficiently with each other • Hierarchical, Distributed, and Hybrid

Caching Architecture: Hierarchical • caches are placed at multiple levels of the network. • assume there are 4 levels of caches: bottom, institutional, regional, and national levels • first proposed in the Harvest project, other examples are SQUID, Adaptive Web caching, Access Driven cache,

Hierarchical Cache National Cache Origin Server Regional Cache Institutional Cache Clients

Hierarchical Cache • When a cache is not satisfied by a client cache, the request is redirected to the institutional cache. • If the object is not present at the institutional level, the request travels to the regional cache which in turn forwards unsatisfied requests to the national cache. • If the object is not in the national cache, the origin server is contacted directly. • When the object is found, either at a cache or origin server, it travels down hierarchy, leaving a copy at each of the intermediate caches.

Hierarchical Cache with queries Query siblings, parent, and also the origin server.

Hierarchical Cache with queries

Hierarchical Cache • Problems: – To set up the hierarchy, caches often need to be placed at key access points in the network, require significant coordination among participating cache servers. – Large disk space is needed in the higher level cache to obtain a reasonable hit rate. – Tariff based volume charging: not fair for upper level caches. – Differences in levels of Hierarchy. – Every hierarchy level may introduce additional delays. – High level caches may become bottlenecks and have long queuing delays. – Multiple copies of the same document are stored at different cache levels.

Caching Architecture: Distributed • There are only caches at the bottom level. • In order to decide from which institutional cache to retrieve a miss document, all institutional caches keep meta-data information about the content of every other institutional cache. • most of the traffic flows through low network levels, which are less congested and no additional disk space is required at intermediate network levels. • In addition, distributed caching allows better load sharing and are more fault tolerant.

Caching Architecture: Distributed • To make the distribution of the meta-data information more efficient and scalable, a hierarchical distribution mechanism can be employed. However, the hierarchy is only used to distribute directory information about the location of the documents, not actual document copies.

Caching Architecture: Distributed • a large-scale deployment of distributed caching may encounter several problems: – high connection times, – higher bandwidth usage, – Administrative issues, etc.
 of Squid – Malpani’s")
Caching Architecture: Distributed • Approaches – Internet Cache Protocol (ICP) of Squid – Malpani’s multicast approach similar to ICP (1995) – Cache Array Routing Protocol (CARP) – Distributed internet cache (by Povey) – Fully distributed internet cache (by Tewari) – CRISP – Cachemesh – Summary cache/Digest cache – Relais project

Cluster-based caching: multicast • Adaptive Web cache • Dynamic web cache • LSAM

Hybrid caching architecture • ICP is a typical example • Documents are fetched from a parent/neighbor cache that has the lowest RTT • Rabinovich et. al. limit the cooperation to avoid obtaining pages from distant or slower caches, instead from origin server

Caching Architecture Summary • Access latency – Isolated cache Tisolated = Ttcp 1 + Tlookup + [ Ttcp 2 ] – Cooperative cache Tco-op = Ttcp 1 + Tlookup + [Tremote-lookup + Ttcp 2 ] • Fixed home or not

Increase Hit Ratio • Cooperative caches: use a group of isolated caching proxies through cooperation – If a proxy cache can not find the requested object locally, it first tries to find if any cooperative cache has a copy of the requested object and get it from there, – otherwise, get the requested object from origin server

ICP & Squid • Squid is the most popular proxy cache • It is free and source code is publicly available • derived from Harvest Cache • single、non-blocking request

Squid • • • proxying and caching of HTTP; proxying for SSL; FTP, WAIS, Gopher cache hierarchies; transparent caching; HTTP server acceleration; ICP, HTCP, CARP, and Cache Digests; WCCP; extensive access controls; Delay pools (Bandwith management) SNMP; caching of DNS lookups. An article
 see")
Squid Enhanced Services • • statistics, . . . cache manager (/cgi-bin/cachemgr. cgi) see fwd. Start() and fwd. Dispatch() access. log

squid. conf • See “OPTIONS WHICH AFFECT THE NEIGHBOR SELECTION ALGORITHM” – TAG: cache_peer_domain – TAG: icp_query_timeout (msec) – TAG: hierarchy_stoplist – TAG: no_cache
")
squid. conf • See “OPTIONS WHICH AFFECT THE CACHE SIZE” – TAG: cache_mem (bytes) – TAG: cache_swap_low (percent, 0 -100) –…

ICP • ICP stands for Internet Cache Protocol • ICP is a lightweight protocol that provides a mechanism for a cache to determine which of its peers can best satisfy a given request. • ICP messages are transmitted via UDP consisting of a 20 -bytes header and a URL. • ICP multicasts a query to all other peers whenever a local cache miss occurs
 HTTP Request HTTP Response ICP Query ICP Hit or Miss Parent")
ICP (sibling hit) HTTP Request HTTP Response ICP Query ICP Hit or Miss Parent Sibling Master Proxy Web Server Sibling

Advantages of ICP • ICP replies indicate the current network conditions • SRC_RTT feature of ICP: ICMP-based measurement of the network RTT between the neighbor cache and the origin server

Disadvantages of ICP • The additional delay introduced by the ICP query and reply. – ICP round trip delay • 1 -3 milliseconds in LAN • 40 -200 milliseconds in WAN (National) • 200 - milliseconds in WAN (International) – Squid sets 2 seconds as the timeout for ICP messages
 – remote hit: the fastest")
Disadvantages of ICP • The additional delay (cont. ) – remote hit: the fastest response time from the peer caching the requested object – remote miss: the slowest response time from one of the peers • heavy traffic – # of ICP is proportional to n 2 * r, where n is the # of caches in the group and r is the request rate
 1000 500")
Round trip delay of the ICP 1500 1300 Round Trip Delay (msec) 1000 500 300 100 30 40 50 20 20 20 mi 6. chu mi 7. chu mi 8. chu cs 1. chu cs 2. chu 250 proxy. nsysu proxy. ncu Round trip delay of the ICP query/reply from a workstation to various Squid servers.
 • Solve the heavy traffic problem of ICP • allocate")
The Centralized protocol (CRISP) • Solve the heavy traffic problem of ICP • allocate a server as the index server recording a complete directory of cache contents of all the peers • Only one query message to the index server instead of multicasting to all the peers
 HTTP Request HTTP Response Index Request Index Response Local Server 1")
Centralize (index hit) HTTP Request HTTP Response Index Request Index Response Local Server 1 Index Server Master Proxy Web Server Local Server 2
 HTTP Request HTTP Response Index Request Index Response Index Update Local")
Centralize (index miss) HTTP Request HTTP Response Index Request Index Response Index Update Local Server 1 Index Server Master Proxy Web Server Local Server 2

The Distributed Protocol • Solve the additional delay problem of ICP • Every peer records a complete directory of cache contents of all the peers • Every time a peer getting a new object, it informs all the other peer about the new object
 HTTP Request Web Server HTTP Response Local Server 1 Master Proxy")
Distributed (remote hit) HTTP Request Web Server HTTP Response Local Server 1 Master Proxy Local Server 2
 HTTP Request Web Server HTTP Response Index Update Local Server 1 Master")
Distributed (miss) HTTP Request Web Server HTTP Response Index Update Local Server 1 Master Proxy Local Server 2

Comparisons • No cache sharing: isolated cache • simple cache sharing: ICP • Single-copy cache sharing: – CRISP – The Distributed Protocol

Structure of the cooperative caching server. L 0 Li L 1 Ci L 2 ws C 1 Index server ws C 2 ws Cn

Comparisons: • Duplication vs. no-duplication of data • Effective cache size: x = n C – C h (n-1) n servers, each has C • Hit ratio = h = f(x) byte cache, h=hit ratio 70 60 heff Hit ratio 50 (%) 40 f(x) 30 20 10 0 1 G 2 G 3 G 4 G 5 G 6 G 7 G Cache Size Proxy. chu. edu. tw

# of HTTP messages generated by a request. ICP, the centralized, and proposed protocol L 2 (I) local hit (II)remote hit (III) miss L 1 L 0 2 0 0 4 2 2
 local hit L 2")
# of ICP messages generated by a request. ICP (I) local hit L 2 L 1 0 0 (II) remote 2(n-1) hit (III) miss Centralized 2(n-1) proposed L 1 0 L 1 Li L 2 0 0 0 2 2 2 0 0 3 3 3 n-1
*n*r")
ICP: average # of HTTP messages • L 0: HL 0 = 2(1 -heff)*n*r • L 1: HL 1 = 4 heff (n-1)/n*r+2(1 -heff)r • L 2: HL 2 = HL 1 + 2 r ICP: average # of UDP messages • L 1/L 2: IL=4[(n-1/n) *heff*(n-1)+(1 -heff )*(n-1)]

CRISP: average # of HTTP messages • The same as ICP CRISP : average # of UDP messages • L 1/L 2: IL=2(n-1)/n *h*r+(1 -h)*3*r • Li: [(n-1)/n*2+(1 -h)*3]*n*r

DIST: average # of HTTP messages • The same as ICP DIST : average # of UDP messages • L 1/L 2: 2*(1 -h)*(n-1)*r

Comparisons • Average number of ICP messages • • h= n = 5 0. 5 0. 4 0. 3 n = 4 0. 5 0. 4 0. 3 • ICP(L 1/L 2) >14. 4 >14. 7 >15. 0 >10. 5 >10. 8 >11. 1 • Cent(L 1/L 2) • Cent(Li) 2. 3 2. 44 2. 58 2. 25 2. 4 11. 5 12. 2 12. 9 9 9. 6 2. 55 10. 2 • Proposed 4 4. 2 4. 8 5. 6 3 3. 6

Comparisons • Average number of HTTP messages • • • h L 0 L 1 L 2 n = 5 0. 5 0. 4 0. 3 7 n = 4 0. 5 0. 4 0. 3 5 6 4 4. 8 5. 6 2. 6 4. 6 2. 48 2. 36 2. 5 2. 4 4. 48 4. 36 4. 5 4. 4 2. 3 4. 3

Implementation • Modify squid 2. 0 • introduce a new type ICP message: I_Have

Conclusion of Proposed • Totally remove the additional delay for remote cache lookup • Suitable for a cooperative cache of less than 6 peers

Distributed Internet Cache Povey’ 97 Upper level servers only store the directory of documents cached in the leaf caches in its subtree

Distributed Internet Cache Povey’ 97

Distributed Internet Cache Povey’ 97

Summary Cache • Use k hash functions and m-bit vector to store the directory info instead of URLto-proxy-ID mapping (ID=1. . n proxy servers) – Each proxy needs (n -1) m-bit vectors – Suppose 1 G disk cache, each page ~ 32 K: • Total 32 K page entries in cache • 32 K*40 bytes (URL length ~ 40 bytes and ignoring ID storage) for each proxy’s direcotry • Total 1280 K*(n-1) bytes for each proxy to store the cache info of all other n-1 proxies – For SC: m/8 * (n-1) bytes

SC: Experiments • Wisconsin Proxy Benchmark 1. 0: – a collection of client processes that issue requests following patterns observed in real traces including request size distribution and temporal locality and a collection of server processes that delay the replies to emulatencies in the Internet

SC: Experiments • 10 Sun Sparc 10 Mbs Ethernet – 4 sparc: 4 proxy running Squid 75 MB cache – 4 sparc: 30 processes on each • processes issue requests with no thinking time in between and the requested document size follow the Pareto distribution with alpha=1. 1 and k=3. 0 – 2 sparc: act as servers each with 15 servers listing on different ports • two different cache hit ratios 25% and 40% • Using netstat we collect the number of UDP datagrams sent and received the TCP packets sent and received and the total number of IP packets handled by the Ethernet network interface

SC: Experiments
 = P 1 1")
SC: Bloom filter • • Bit vector V H 1(URL) = P 1 1 H 2(URL) = P 2 H 3(URL) = P 3 1 m bits H 4(URL) = P 4 1 … 1 Hk(URL) = Pk Hn () is a hash function, e. g. MD 5
, the probability that a")
SC: Bloom filter • After inserting n keys (nk bits), the probability that a particular bit is still 0 is (1 kn -1/m) • So, the probability of a false positive is kn k (1 -1/m) )

SC: Bloom filter • Update: – Update whole SC • Threshold: when the digests differ beyond a threshold, say, 5% or 10%, • Regular time intervals: every say 5 mins, – Piggybacking update notifications

SC: update delay impact

SC: Bloom filter • Deletion operation for local digest: – For each bit in the m-bit vector, use an l-bit counter to record the number of times that a particular bit is turned on by different URLs – l = 4 by experience – If deletion is not supported, cache summary must be rebuilt from scratch on a periodic basis to erase stale bits and prevent bit pollution

Cache Digest • Similar to summary cache

Beyond Hierarchy • Design principles – Minimize the number of hops to locate and access data • Separate data and metadata, hints, and cache-to-cache transfer – Do not slow down misses • Location-hints – Share data among many caches • Separate data paths and metadata paths, location-hints – Cache data close to clients • Push caching

Hierarchy Delay

Beyond Hierarchy Cache Miss Rates

Beyond Hierarchy

Beyond Hierarchy
")
CARP • implemented in Microsoft® Proxy Server 2. 0. (discontinued on March 31, 2001) • Philosophically, protocols like ICPv 2 are based on dynamic "pinging" of neighboring proxy to locate copies of cached objects. • an alternate approach is based on hash-based routing of URLs using known "request resolution path" through a network of proxies that is determined by the URL of the request. • An interesting side effect of this deterministic mechanism is that cache duplication is avoided. P. S. Microsoft Proxy was replaced by ISA Server includes a full-featured enterprise firewall and high-performance Web cache plus Proxy Server.
: URL_Hash += _rotl(URL_Hash, 19) +")
CARP • • • For (each char in URL): URL_Hash += _rotl(URL_Hash, 19) + char ; For (each char in Member. Proxy. Name): Member. Proxy_Hash += _rotl(Member. Proxy_Hash, 19) + char ; Becaues member names are often similar to each other, their hash values are further spread across hash space via the following additional operations: • Member. Proxy_Hash += Member. Proxy_Hash * 0 x 62531965 ; • Member. Proxy_Hash = _rotl (Member. Proxy_Hash, 21) ; .
 the URL hash by")
CARP • Hashes are combined by first exclusive oring (XOR) the URL hash by the machine name and then multiplying by a constant and performing a bitwise rotation. All final and intermediate values are 32 bit unsigned integers. • Combined_Hash = (URL_hash ^ Member. Proxy_Hash) ; • Combined_Hash += Combined_Hash * 0 x 62531965 ; • Combined_Hash = _rotl(Combined_Hash, 21) ;

Hyper Text Caching Protocol • HTCP similar to ICP, but contain full HTTP request headers

Web Cache Control Protocol • Cisco cache engine

Future works • Reduce the number of messages generated – piggy-back approach with HTTP message • Reduce the storage overhead for recording the cache contents of all the peers – bloom filter [Rousskov: digest cache] • T = Ticp + Tlookup + [Tremote + Ticp] – prefetch – redirection

Future works • Reduce wasteful caching overhead – predict what object will not be reused – not-cachable object does not go through proxy • Qo. S – IP basis – per-object basis

squid access log • http: //www. linofee. org/~jel/proxy/Squid/acc esslog. shtml
a0ef4fa6bb404eea6ac9de8f431ce1df.ppt