
Уральский государственный университет им. А. М. Горького математико-механический



















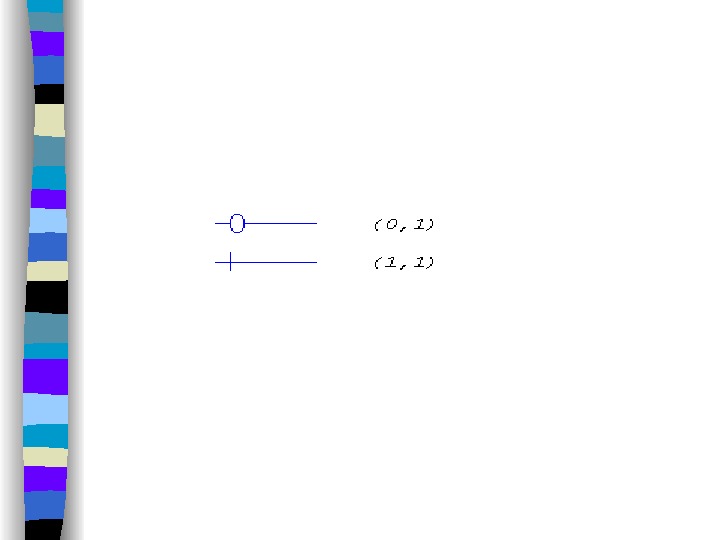


























































































































































































































































































































































































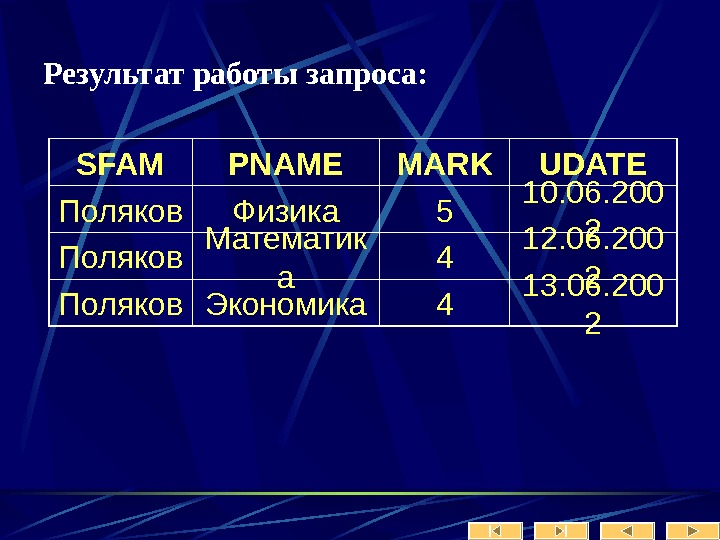
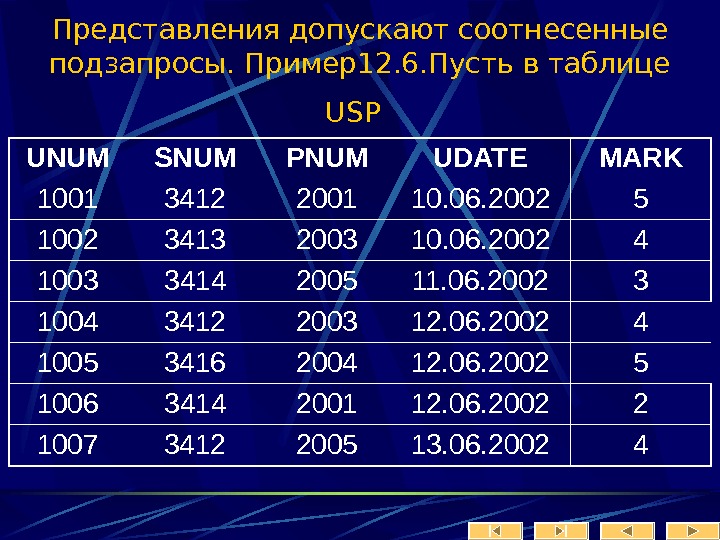




























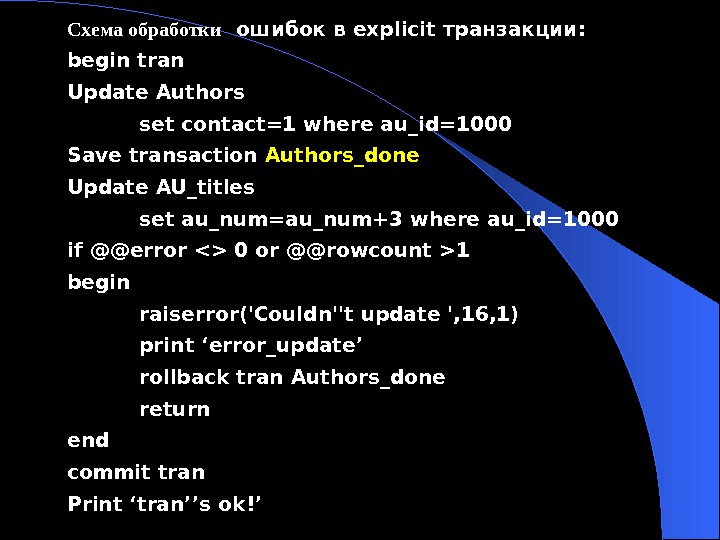



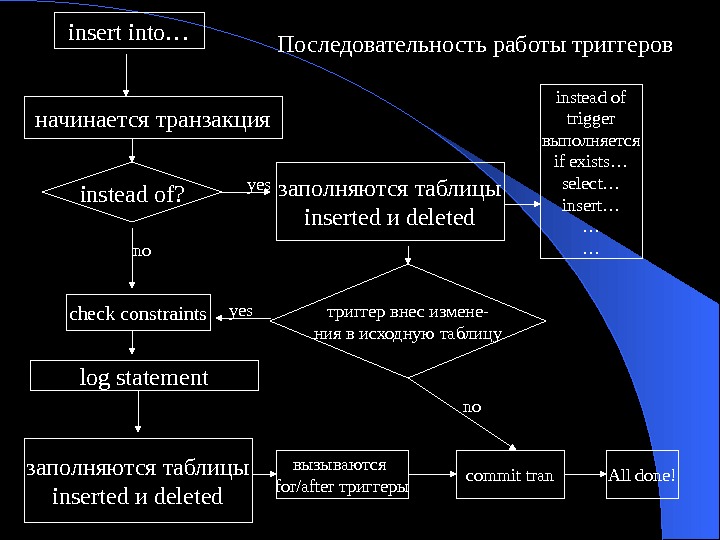



























































































































































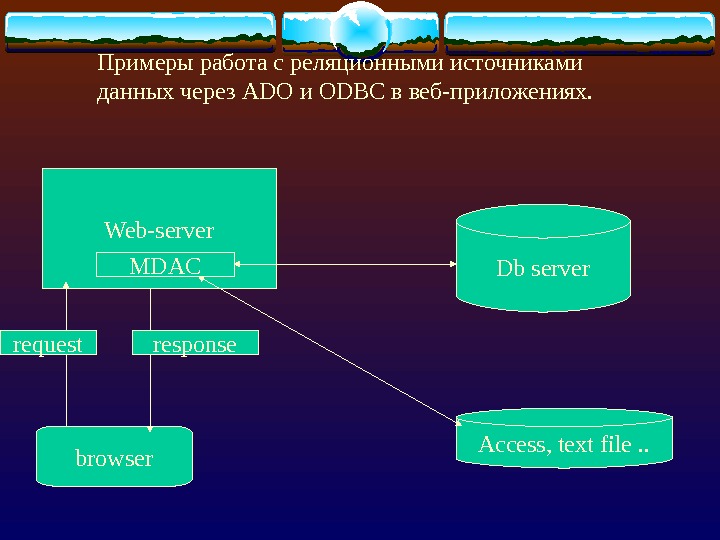
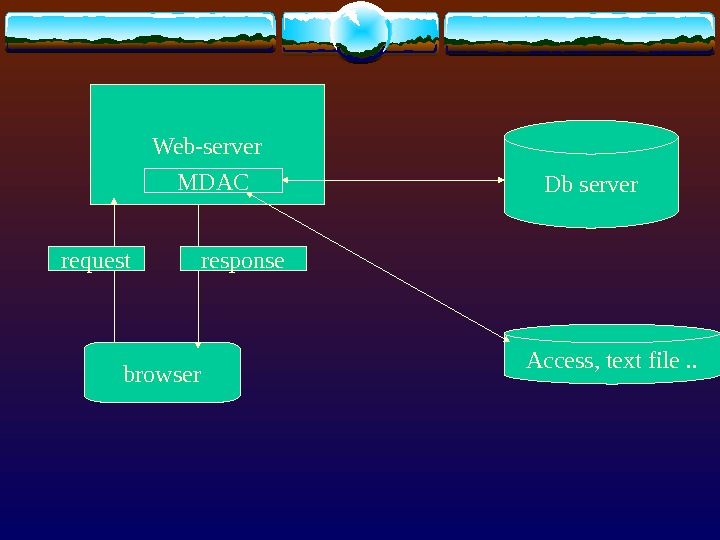






1325087_presentation.ppt
- Размер: 2.7 Mегабайта
- Количество слайдов: 671
Описание презентации Уральский государственный университет им. А. М. Горького математико-механический по слайдам
Уральский государственный университет им. А. М. Горького математико-механический факультет «Автоматизированные базы данных» лекции-презентации Стихиной Т. К. , к. ф. -м. н. , доцент кафедры информатики и процессов управления
Список литературы: 1. Гектор Гарсиа-Молина, Джеффри Д. Ульман, Дженнифер Уидом «Системы баз данных. Полный курс» . : Пер. с англ. -М. : Издательский дом «Вильямс» , 2003. 2. Советов Б. Я. , Цехановский В. В. , Чертовский В. Д. « Базы данных. Теория и практика » . Учебник для вузов. М. : Высшая школа. , 2005. 3. Диго С. М. , «Базы данных. Проектирование и использование» : Учебник. -М. : «Финансы и статистика» , 2005. 4. Дейт К. Дж. «Введение в системы баз данных» . -8 -е изд. : Пер. с англ. -СПб: Издательский дом «Вильямс» , 2006. 5. Хомоненко А. Д. Базы данных: Учебник для вузов, СПб. , Корона принт, 2006. 6. Астахова И. Ф. и др. « SQL в примерах и задачах» . 7. Электронный справочник « Books Online » СУБД Microsoft SQL Server.
Содержание курса: Лекция № 1 Банки, базы, структуры Лекция № 2 Модели БД Лекция № 3 Нормализация Лекция № 4 Целостность и реляционные операци и Лекция № 5 СУБД, исторические моменты и факт ы Лекция № 6 SQL(часть1) Лекция № 7 SQL(часть2) Лекция № 8 DDL
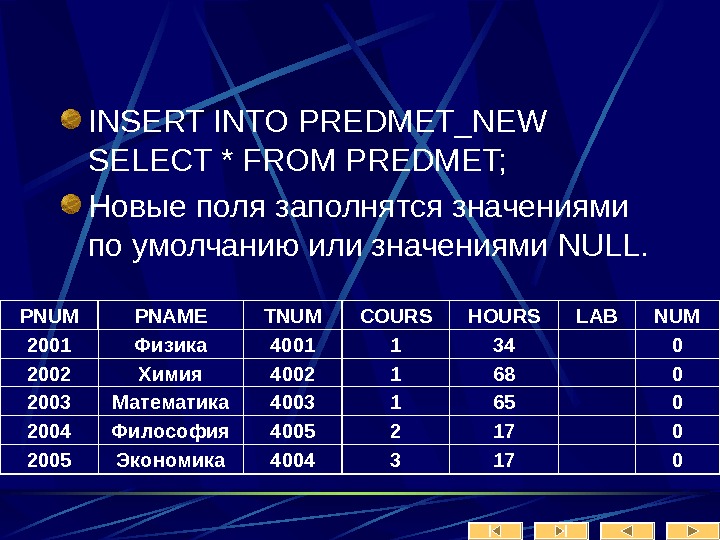
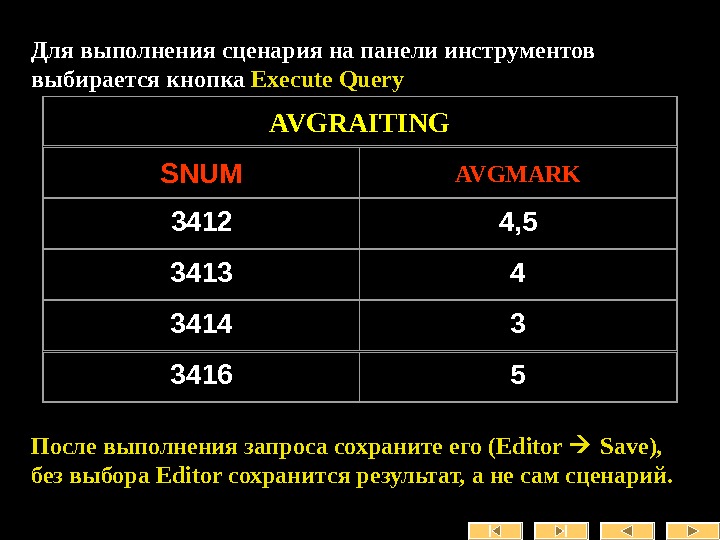
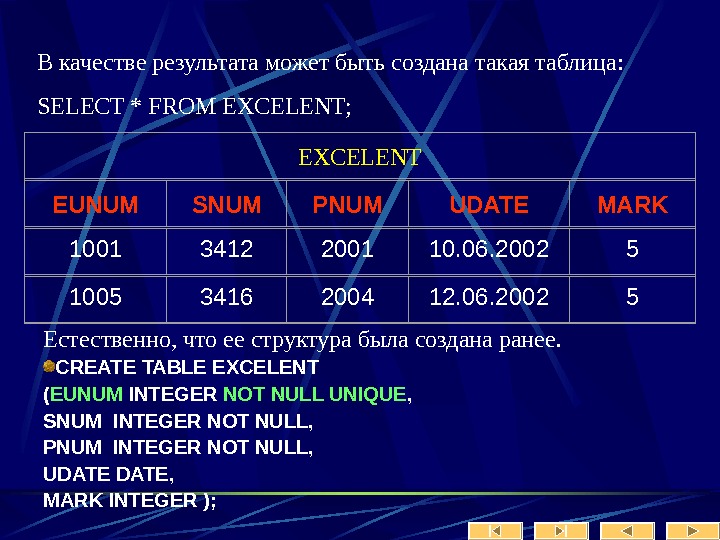
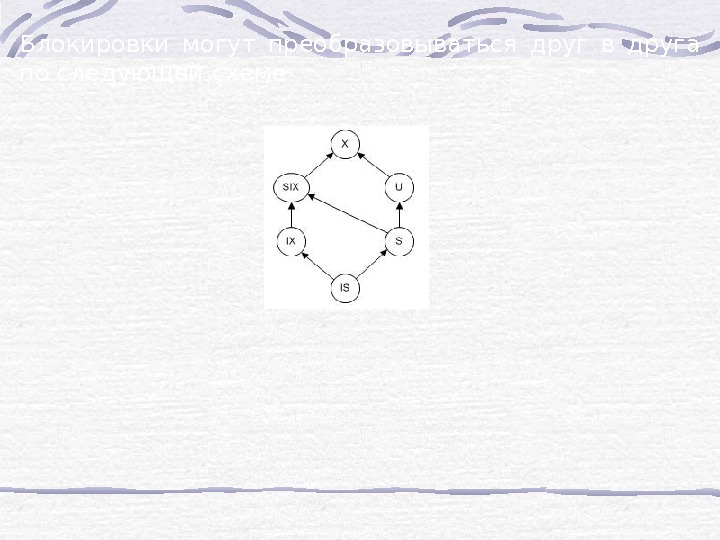
Содержание(продолжение): Лекция № 9 Использование сценариев Лекция № 10 DML особенности применения Лекция № 11 Views – Представления Лекция № 12 Транзакции, триггеры Лекция № 13 Параллельность и блокировки Лекция № 14 Репликации , дублирование, восстановление Лекция № 15 Поиск и индексация Лекция № 16 Механизмы доступа к данным. P. S. В презентациях использованы некоторые тексты скриптов Кобзева Е. С.
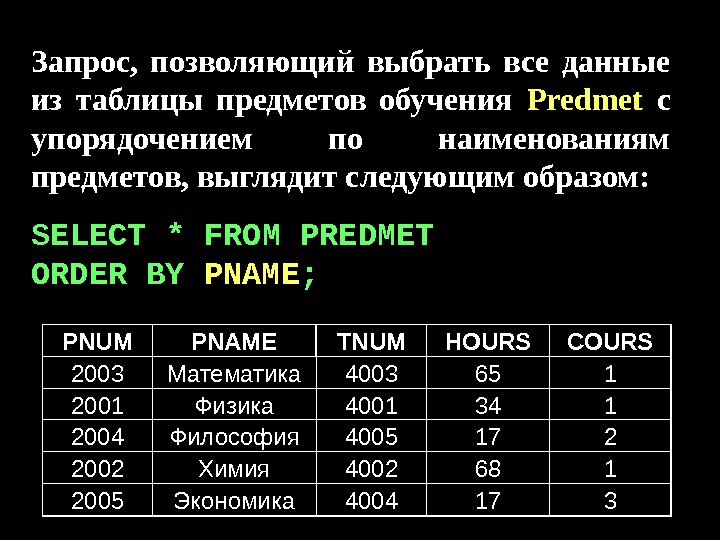
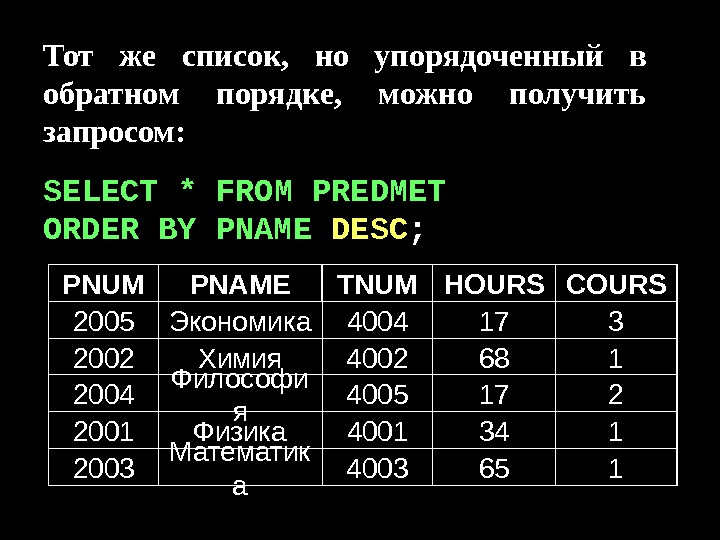
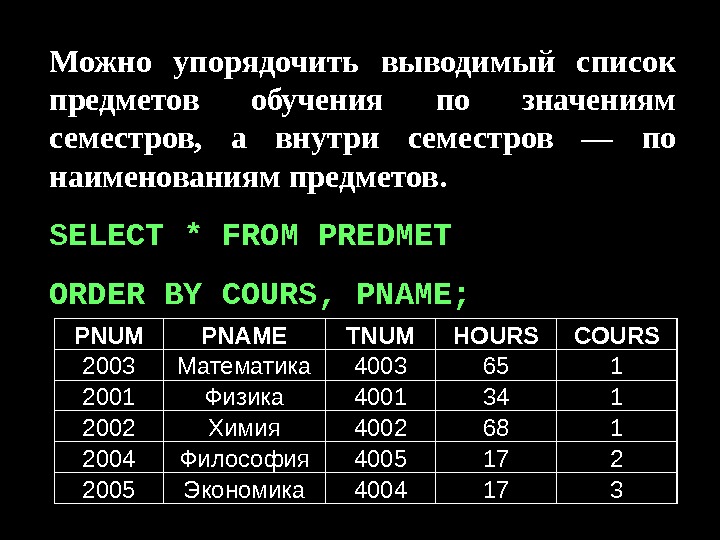
Data bank (банк данных)-совокупность данных(файлов данных, баз данных) об одной предметной области. Data base (база данных)-совокупность взаимосвязанных данных, используемых несколькими приложениями под управлением системы управления базой данных. База данных — динамически обновляем ая модел ь внешнего мира с использованием единого хранилища. Лекция № 1 Банки, базы, структуры Базы данных и системы управления.
Докомпьютерные базы данных: • библиотечные каталоги • реестры ценностей 1880 г. – перепись населения в США отняла 7 лет жизни у 1500 сотрудников. В конкурсе по оптимизации этой работы победил Герман Холерит, придумавший кодировать информацию в перфокартах.
Компьютеры были созданы для решения вычислительных задач, со временем они все чаще стали использоваться для построения систем обработки документов, а точнее, содержащейся в них информации. Система управления базой данных более широкое понятие, чем база данных. Основные черты СУБД ( DBMS ): • обеспечение постоянного хранения большого объема данных • предоставление программного интерфейса для доступа и манипуляции данными • управление транзакциями – обеспечение одновременной работы нескольких конкурирующих запросов
Первые коммерческие СУБД на базе ЭВМ возникли в 1960 х. Сферы применения: • системы бронирование билетов • банковские системы • корпоративные приложения (учет труда и заработной платы) Такие СУБД базировались на файловых системах и не могли обеспечить в частности контроль над транзакциями.
1970 г. Ted Codd “A relational model for large shared data banks” – работа сотрудника IBM Кодда, инициировавшая появление реляционных СУБД, – наиболее распространенных в настоящее время.
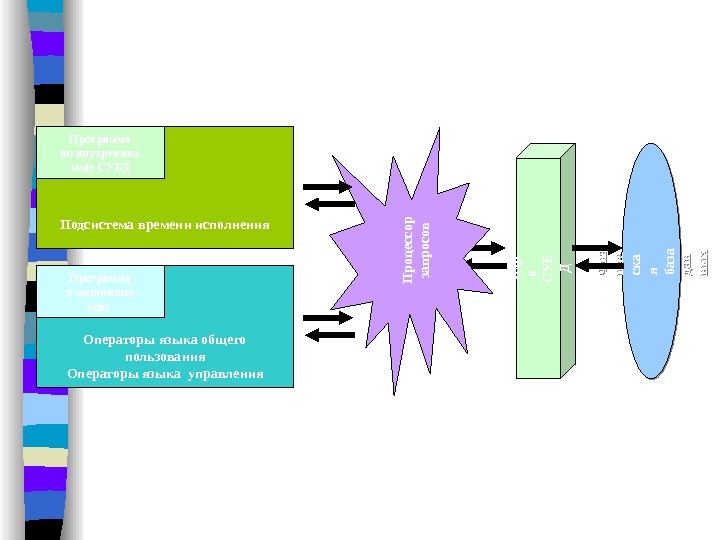
Обычно современная СУБД содержит следующие компоненты: • ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию • процессор языка базы данных , обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода • подсистему поддержки времени исполнения , которая интерпретирует программы м анипуляции данными, создающие пользовательский интерфейс с СУБД • а также , сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
Подсистема времени исполнения Программа во внутреннем коде СУБД Операторы языка общего пользования Операторы языка управления Программа в машинном коде П роцессор запросов Я др о СУ Б ДФ из иче ска я база дан ны х
Представление данных с помощью модели «сущность-связь». Прежде, чем приступать к созданию системы автоматизированной обработки информации, разработчик должен сформировать понятия о предметах, фактах и событиях, которыми будет оперировать данная система. Для того, чтобы привести эти понятия к той или иной модели данных, необходимо заменить их информационными представлениями. Одним из наиболее удобных инструментов унифицированного представления данных, независимого от реализующего программного обеспечения, является модель «сущность-связь» (entity — relationship model, ER — model).
Модель «сущность-связь» основывается на некой важной семантической информации о реальном мире и предназначена для логического представления данных. Она определяет значения данных в контексте их взаимосвязи с другими данными. Важным для нас является тот факт, что из модели «сущность-связь» могут быть порождены все существующие модели данных (иерархическая, сетевая, реляционная, объектная), поэтому она является наиболее общей. Модель «сущность-связь» была предложена в 1976 г. Питером Пин-Шэн Ченом Модель «сущность-связь» не определяет операций над данными и ограничивается описанием только их логической структуры.
Элементы модели Сущность (entity) — это объект, который может быть идентифицирован неким способом, отличающим его от других объектов. Примеры: конкретный человек, предприятие, событие и т. д. Набор сущностей (entity set) — множество сущностей одного типа (обладающих одинаковыми свойствами). Примеры: все люди, предприятия, праздники и т. д. Наборы сущностей не обязательно должны быть непересекающимися. Например, сущность, принадлежащая к набору МУЖЧИНЫ, также принадлежит набору ЛЮДИ. Сущность фактически представляет из себя множество атрибутов, которые описывают свойства всех членов данного набора сущностей.
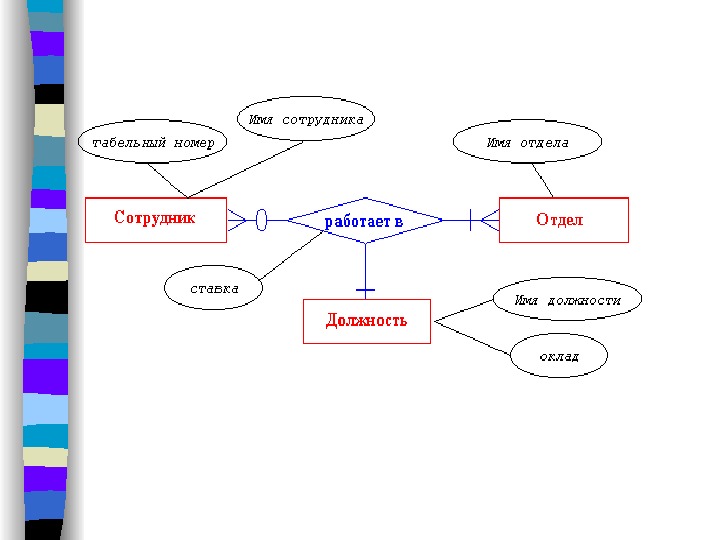
Пример: рассмотрим множество работников некого предприятия. Каждого из них можно описать с помощью характеристик табельный номер, имя, возраст. Поэтому, сущность СОТРУДНИК имеет атрибуты ТАБЕЛЬНЫЙ_НОМЕР, ИМЯ, ВОЗРАСТ. Используя нотацию языка Pascal этот факт можно представить как: type employee = record number : string[6]; name : string[50]; age : integer; end; В дальнейшем для определения сущности и ее атрибутов будем использовать обозначение вида СОТРУДНИК (ТАБЕЛЬНЫЙ_НОМЕР, ИМЯ, ВОЗРАСТ).
Множество значений (область определения) атрибута называется доменом. Например, для атрибута ВОЗРАСТ домен (назовем его ЧИСЛО_ЛЕТ) задается интервалом целых чисел больших нуля, поскольку людей с отрицательным возрастом не бывает. В статье П. Чена атрибут определяется как функция, отображающая набор сущностей в набор значений или в декартово произведение наборов значений. Так атрибут ВОЗРАСТ производит отображение в набор значений (домен) ЧИСЛО_ЛЕТ. Атрибут ИМЯ производит отображение в декартово произведение наборов значений ИМЯ, ФАМИЛИЯ и ОТЧЕСТВО.
Отсюда определяется ключ сущности — группа атрибутов, такая, что отображение набора сущностей в соответствующую группу наборов значений является взаимнооднозначным отображением. Другими словами: ключ сущности — это один или более атрибутов уникально определяющих данную сущность. К лючем сущности СОТРУДНИК является атрибут ТАБЕЛЬНЫЙ_НОМЕР (конечно, только в том случае, если все табельные номера на предприятии уникальны).
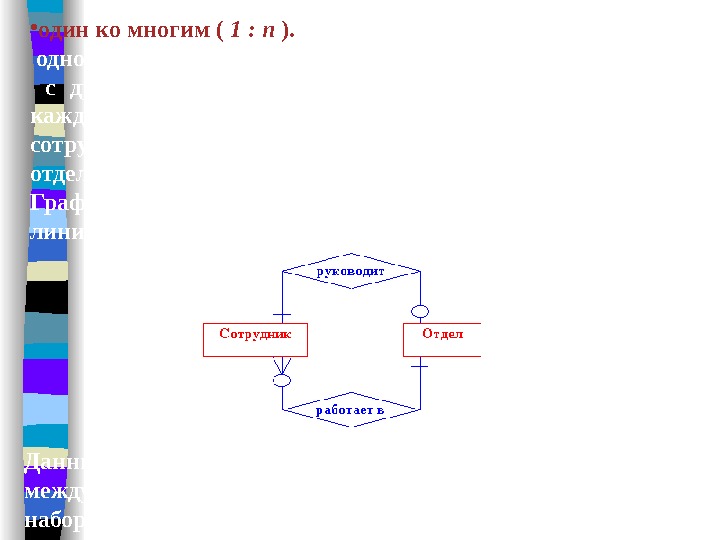
Связь (relationship) — это ассоциация, установленная между несколькими сущностями. Примеры: • поскольку каждый сотрудник работает в каком-либо отделе, между сущностями СОТРУДНИК и ОТДЕЛ существует связь «работает в» или ОТДЕЛ-РАБОТНИК; • так как один из работников отдела является его руководителем, то между сущностями СОТРУДНИК и ОТДЕЛ имеется связь «руководит» или ОТДЕЛ-РУКОВОДИТЕЛЬ; • могут существовать и связи между сущностями одного типа, например связь РОДИТЕЛЬ — ПОТОМОК между двумя сущностями ЧЕЛОВЕК;
Связь также может иметь атрибуты. Например, для связи ОТДЕЛ-РАБОТНИК можно задать атрибут СТАЖ_РАБОТЫ_В_ОТДЕЛЕ. Роль сущности в связи — функция, которую выполняет сущность в данной связи. Например, в связи РОДИТЕЛЬ-ПОТОМОК сущности ЧЕЛОВЕК могут иметь роли «родитель» и «потомок». Указание ролей в модели «сущность-связь» не является обязательным и служит для уточнения семантики связи.
Набор связей (relationship set) — это отношение между n (причем n не меньше 2) сущностями, каждая из которых относится к некоторому набору сущностей. Пример: сущности наборы сущностей —————- e 1 принадлежит E 1 e 2 принадлежит E 2 . . . en принадлежит En тогда [e 1, e 2, . . . , en] — набор связей R В случае n=2 , т. е. когда связь объединяет две сущности, она называется бинарной. n -арный набор связей ( n>2 ) всегда можно заменить множеством бинарных, однако первые лучше отображают семантику предметной области.
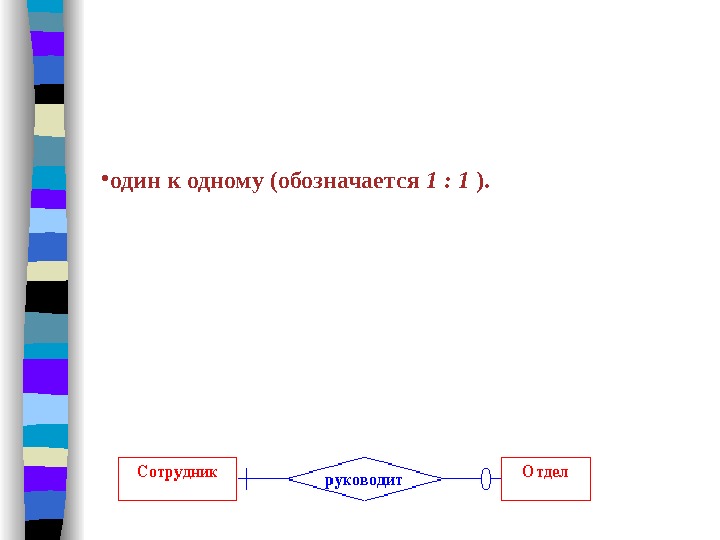
То число сущностей, которое может быть ассоциировано через набор связей с другой сущностью, называют степенью связи. Рассмотрение степеней особенно полезно для бинарных связей. Могут существовать следующие степени бинарных связей: • один к одному (обозначается 1 : 1 ). Это означает, что в такой связи сущности с одной ролью всегда соответствует не более одной сущности с другой ролью. В рассмотренном нами примере это связь «руководит», поскольку в каждом отделе может быть только один начальник, а сотрудник может руководить только в одном отделе. Данный факт представлен на следующем рисунке, где прямоугольники обозначают сущности, а ромб — связь. Так как степень связи для каждой сущности равна 1, то они соединяются одной линией.
• Другой важной характеристикой связи помимо ее степени является класс принадлежности входящих в нее сущностей или кардинальность связи. Так как в каждом отделе обязательно должен быть руководитель, то каждой сущности «ОТДЕЛ» непременно должна соответствовать сущность «СОТРУДНИК». Однако, не каждый сотрудник является руководителем отдела, следовательно в данной связи не каждая сущность «СОТРУДНИК» имеет ассоциированную с ней сущность «ОТДЕЛ». Таким образом, говорят, что сущность «СОТРУДНИК» имеет обязательный класс принадлежности (этот факт обозначается также указанием интервала числа возможных вхождений сущности в связь, в данном случае это 1, 1), а сущность «ОТДЕЛ» имеет необязательный класс принадлежности (0, 1).
Теперь данную связь мы можем описать как 0, 1: 1, 1. В дальнейшем кардинальность бинарных связей степени 1 будем обозначать следующим образом:
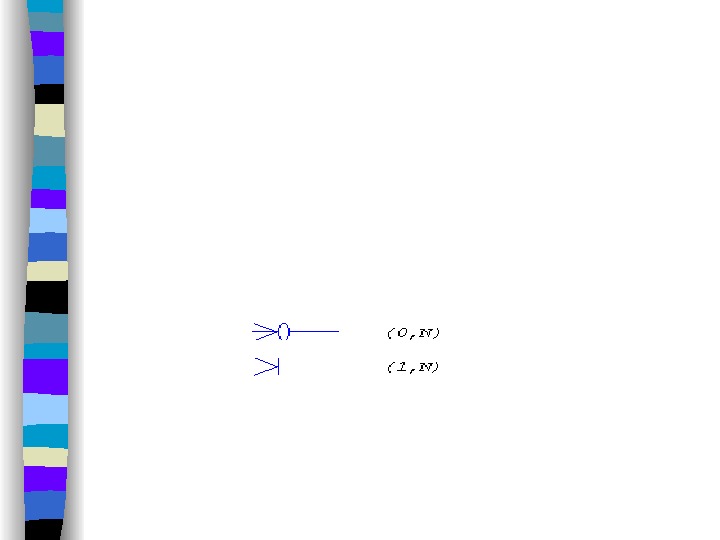
• один ко многим ( 1 : n ). В данном случае сущности с одной ролью может соответствовать любое число сущностей с другой ролью. Такова связь ОТДЕЛ-СОТРУДНИК. В каждом отделе может работать произвольное число сотрудников, но сотрудник может работать только в одном отделе. Графически степень связи n отображается «древообразной» линией, так это сделано на следующем рисунке. Данный рисунок дополнительно иллюстрирует тот факт, что между двумя сущностями может быть определено несколько наборов связей.
Здесь также необходимо учитывать класс принадлежности сущностей. Каждый сотрудник должен работать в каком-либо отделе, но не каждый отдел (например, вновь сформированный) должен включать хотя бы одного сотрудника. Поэтому сущность «ОТДЕЛ» имеет обязательный, а сущность «СОТРУДНИК» необязательный классы принадлежности. Кардинальность бинарных связей степени n будем обозначать так:
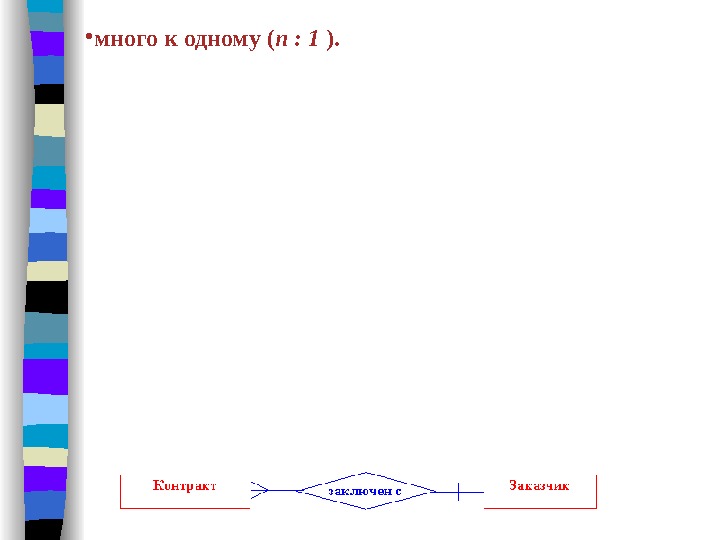
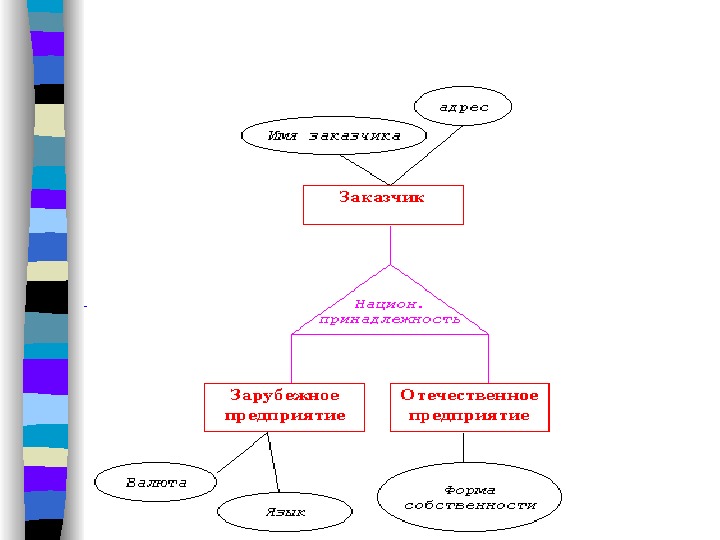
• много к одному ( n : 1 ). Эта связь аналогична отображению 1 : n. Предположим, что рассматриваемое нами предприятие строит свою деятельность на основании контрактов, заключаемых с заказчиками. Этот факт отображается в модели «сущность-связь» с помощью связи КОНТРАКТ-ЗАКАЗЧИК, объединяющей сущности КОНТРАКТ(НОМЕР, СРОК_ИСПОЛНЕНИЯ, СУММА) и ЗАКАЗЧИК(НАИМЕНОВАНИЕ, АДРЕС). Так как с одним заказчиком может быть заключено более одного контракта, то связь КОНТРАКТ-ЗАКАЗЧИК между этими сущностями будет иметь степень n : 1.
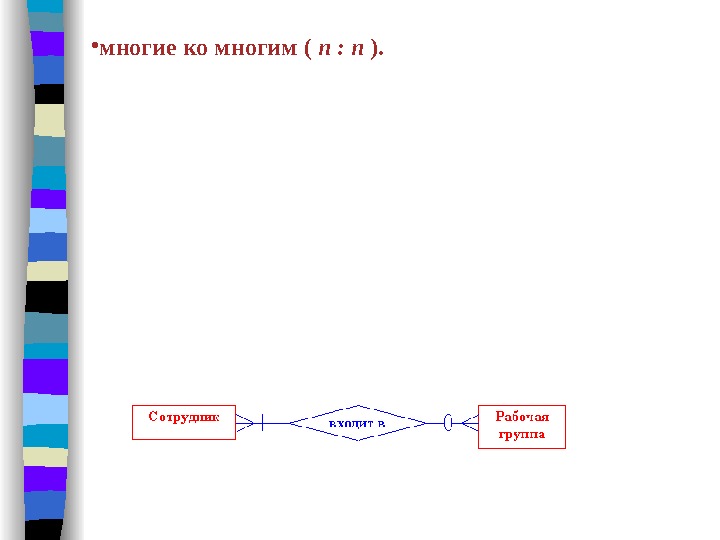
• многие ко многим ( n : n ). В этом случае каждая из ассоциированных сущностей может быть представлена любым количеством экземпляров. Пусть на рассматриваемом нами предприятии для выполнения каждого контракта создается рабочая группа, в которую входят сотрудники разных отделов. Поскольку каждый сотрудник может входить в несколько (в том числе и ни в одну) рабочих групп, а каждая группа должна включать не менее одного сотрудника, то связь между сущностями СОТРУДНИК и РАБОЧАЯ_ГРУППА имеет степень n : n.
Если существование сущности x зависит от существования сущности y , то x называется зависимой сущностью (иногда сущность x называют «слабой», а «сущность» y — сильной). В качестве примера рассмотрим связь между ранее описанными сущностями РАБОЧАЯ_ГРУППА и КОНТРАКТ. Рабочая группа создается только после того, как будет подписан контракт с заказчиком, и прекращает свое существование по выполнению контракта. Таким образом, сущность РАБОЧАЯ_ГРУППА является зависимой от сущности КОНТРАКТ. Зависимую сущность будем обозначать двойным прямоугольником, а ее связь с сильной сущностью линией со стрелкой:
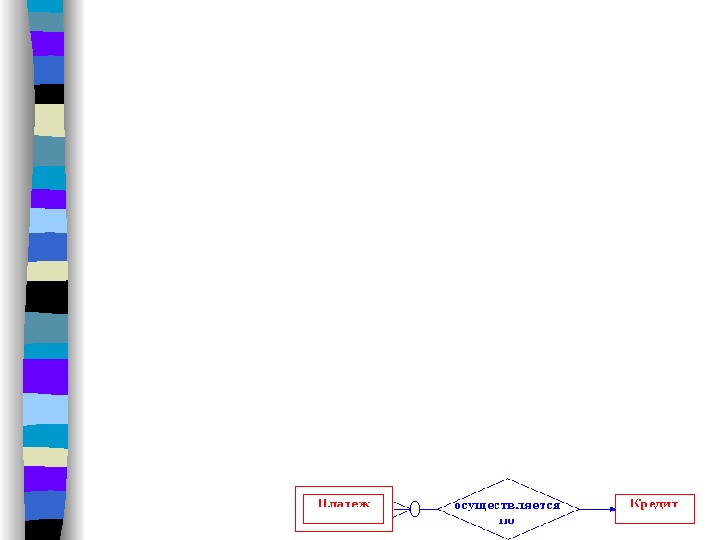
Заметим, что кардинальность связи для сильной сущности всегда будет (1, 1). Класс принадлежности и степень связи для зависимой сущности могут быть любыми. Предположим, например, что рассматриваемое нами предприятие пользуется несколькими банковскими кредитами, которые редставляются набором сущностей КРЕДИТ (НОМЕР_ДОГОВОРА, СУММА, СРОК_ПОГАШЕНИЯ, БАНК). По каждому кредиту должны осуществляться выплаты процентов и платежи в счет его погашения. Этот факт представляется набором сущностей ПЛАТЕЖ(ДАТА, СУММА) и набором связей «осуществляется по». В том случае, когда получение запланированного кредита отменяется, информация о нем должна быть удалена из базы даных. Соответственно, должны быть удалены и все сведения о плановых платежах по этому кредиту. Таким образом, сущность ПЛАТЕЖ зависит от сущности КРЕДИТ.
Диаграмма «сущность-связь». Очень важным свойством модели «сущность-связь» является то, что она может быть представлена в виде графической схемы. Это значительно облегчает анализ предметной области. Существует несколько вариантов обозначения элементов диаграммы «сущность-связь», каждый из которых имеет свои положительные черты.
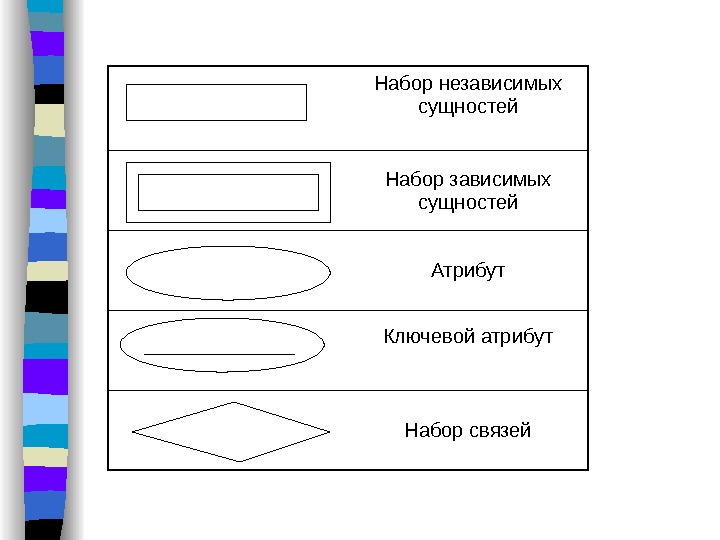
С писок используемых обозначений. Набор независимых сущностей Набор зависимых сущностей Атрибут Ключевой атрибут Набор связейимя сущности имя атрибута имя связи
Атрибуты с сущностями и сущности со связями соединяются прямыми линиями. При этом для указания кардинальностей связей используются обозначения, введенные в ыше.
В процессе построения диаграммы можно выделить несколько очевидных этапов: 1. Идентификация представляющих интерес сущностей и связей. 2. Идентификация семантической информации в наборах связей (например, является ли некоторый набор связей отображением 1: n ). 3. Определение кардинальностей связей. 4. Определение атрибутов и наборов их значений (доменов). 5. Организация данных в виде отношений «сущность-связь».
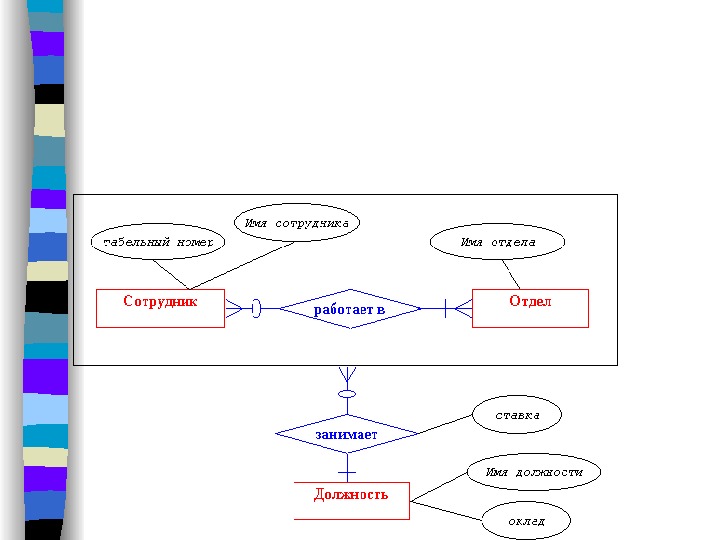
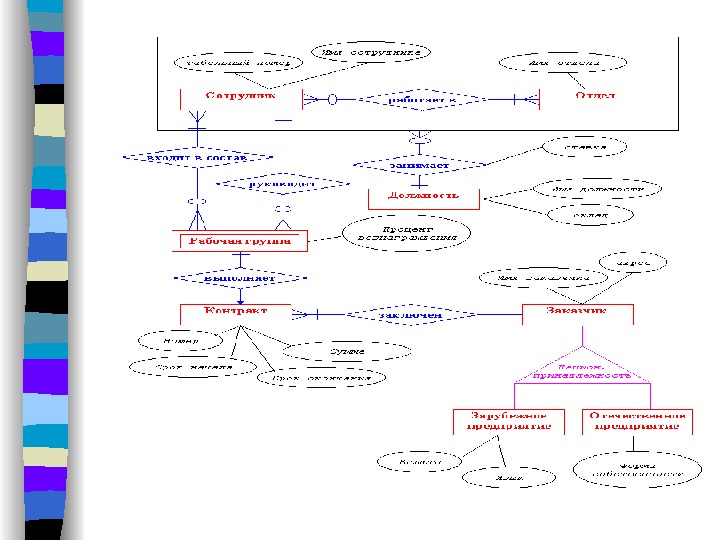
В качестве примера построим диаграмму, отображающую связь данных для подсистемы учета персонала предприятия. Тренарная связь
Как уже отмечалось выше, каждый n -арный набор связей можно заменить несколькими бинарными наборами. Сейчас как раз представляется удобный случай, чтобы оценить преимущества каждого из этих способов представления связей. Тренарная связь, показанная здесь, безусловно несет более полную информацию о предметной области. Действительно, она однозначно отображает тот факт, что оклад сотрудника зависит от его должности, отдела, где он работает, и ставки. Однако, в этом случае возникают некоторые проблемы с определением степени связи.
Хотя, как было сказано, каждый работник может занимать несколько должностей, а в штате каждого отдела существуют вакансии с различными должностями, тем не менее класс принадлежности сущности ДОЛЖНОСТЬ на приведенном рисунке установлен в (1, 1). Это объясняется тем, что ДОЛЖНОСТЬ ассоциируется фактически не с сущностями СОТРУДНИК и ОТДЕЛ, а со связью между ними. Обозначать этот факт предлагается так, как это показано на следующей диаграмме:
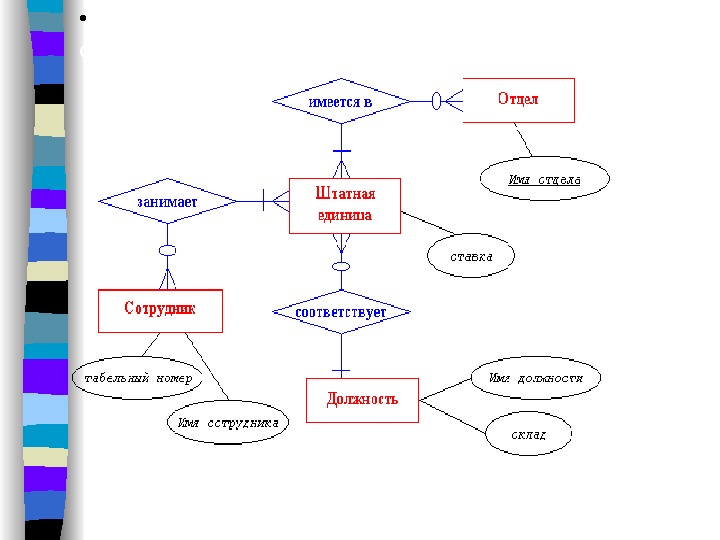
• Попытаемcя отобразить ассоциации сотрудников, отделов и должностей с помощью бинарных связей.
• В этом случае для адекватного описания семантики предметной области необходимо ввести еще одну сущность ШТАТНАЯ_ЕДИНИЦА, которая фактически заменяет собой связь РАБОТАЕТ_В в абстрактной сущности и поэтому имеет атрибут ставка.
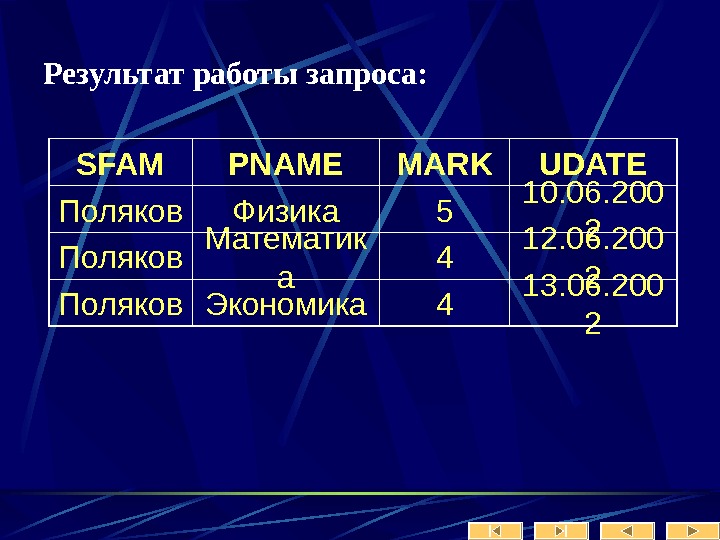
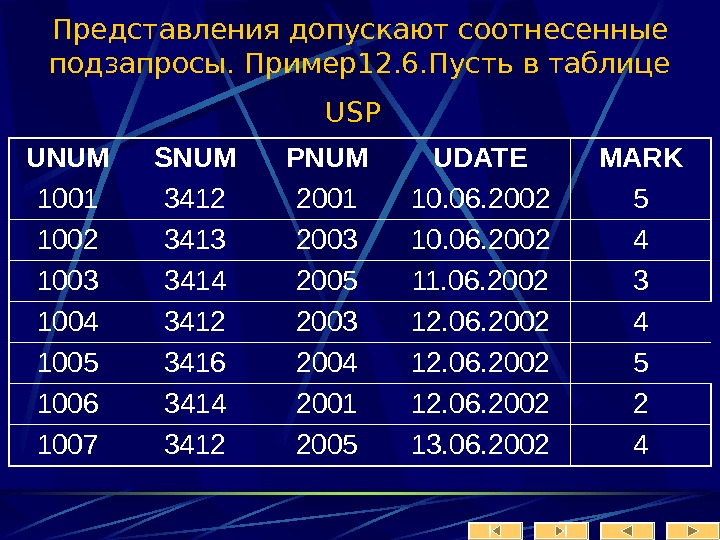
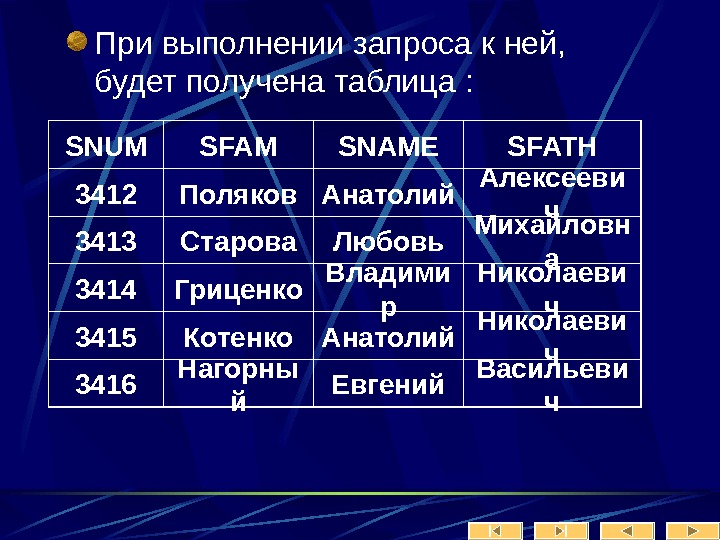
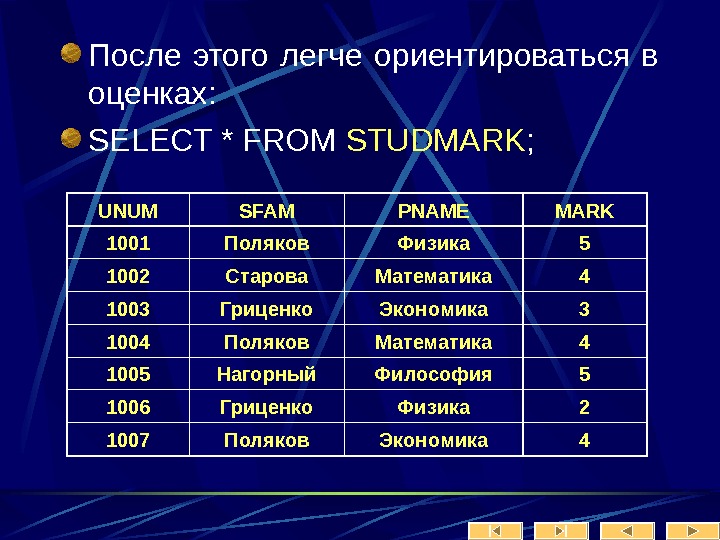
Рассмотрим теперь более внимательно информационный объект «заказчик».
Лекция № 2 Модели БД Иерархическая модель данных. Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных.
• Атрибут (элемент данных) — наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем. • Запись — именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи — конкретная запись с конкретным значением элементов • Групповое отношение — иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) — подчиненными. Иерархическая база данных может хранить только такие древовидные структуры.
Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой по иерархическому пути. При графическом изображении групповые отношения изображают дугами ориентированного графа, а типы записей — вершинами (диаграмма Бахмана).
Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись. При удалении родительской записи автоматически удаляются все подчиненные.
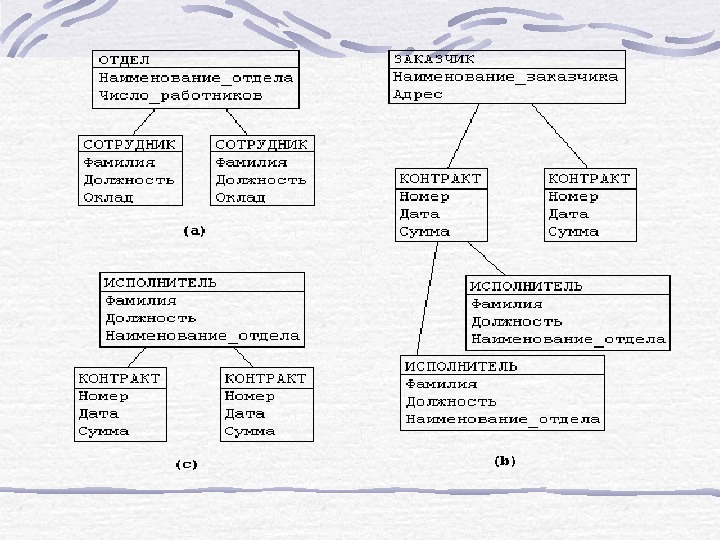
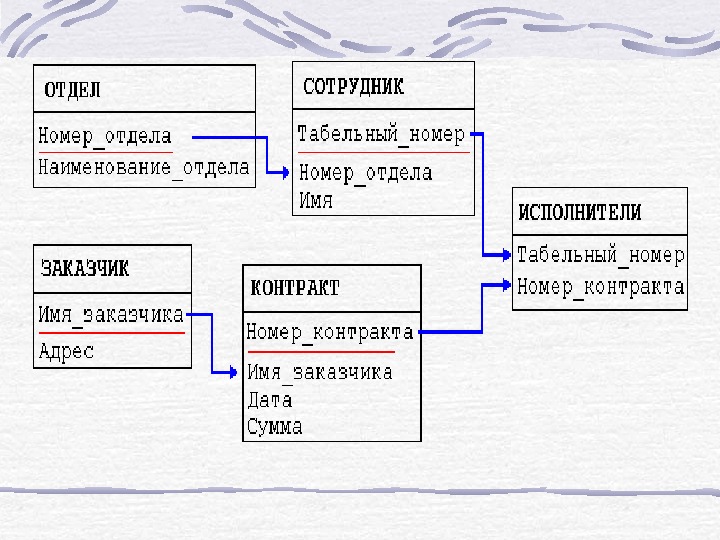
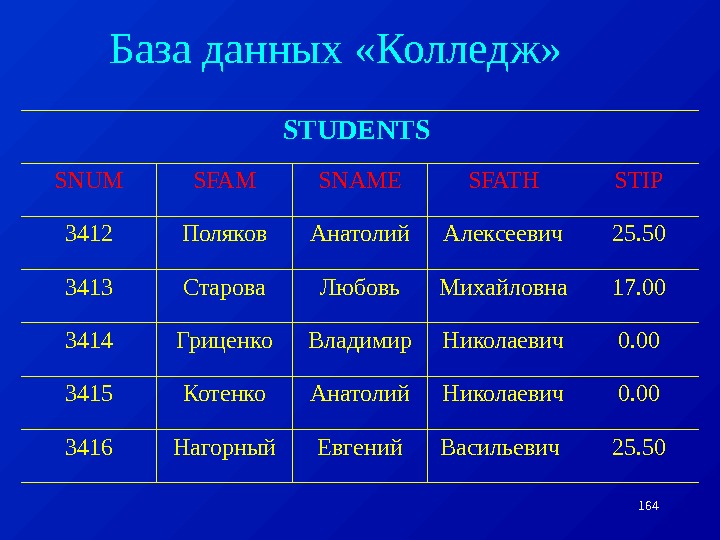
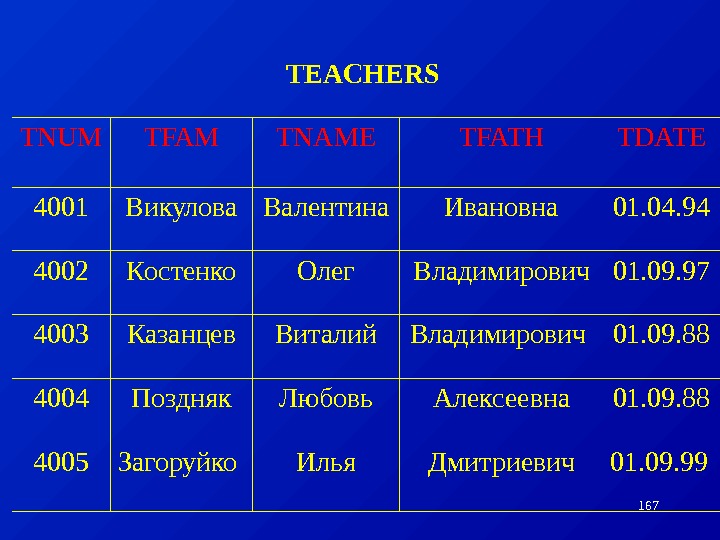
Пример: Рассмотрим следующую модель данных предприятия: предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе. Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры : заказчик — контракты с ним — сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК(НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА, СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА)
Из этого примера видны недостатки иерархических БД: • Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями. • Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1: N, то есть одной родительской записи может соответствовать любое число дочерних. Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т. е. возникает связь типа M: N). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ — дочерней (рис. (c)). Таким образом, мы опять вынуждены дублировать информацию.
Операции над данными, определенные в иерархической модели: • ДОБАВИТЬ в базу данных новую запись. Для корневой записи обязательно формирование значения ключа. • ИЗМЕНИТЬ значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям. • УДАЛИТЬ некоторую запись и все подчиненные ей записи. • ИЗВЛЕЧЬ: • извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей • извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева)
• В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 1 тысячи руб. ) Как видим, все операции изменения применяются только к одной «текущей» записи (которая предварительно извлечена из базы данных). Такой подход к манипулированию данных получил название «навигационного».
Ограничения целостности. Поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка). Как уже отмечалось, не обеспечивается автоматическое поддержание соответствия парных записей, входящих в разлные иерархии.
Сетевая модель данных На разработку этого стандарта большое влияние оказал американский ученый Ч. Бахман. Основные принципы сетевой модели данных были разработны в середине 60 -х годов, эталонный вариант сетевой модели данных описан в отчетах рабочей группы по языкам баз данных (COnference on DAta SYstem Languages) CODASYL (1971 г. ). Сетевая модель данных определяется в тех же терминах, что и иерархическая. Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между записью-владельцем и записью-членом также имеет вид 1: N.
Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно этой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа (т. е. , скажем, сотрудник из предыдущего примера, не может работать в двух отделах).
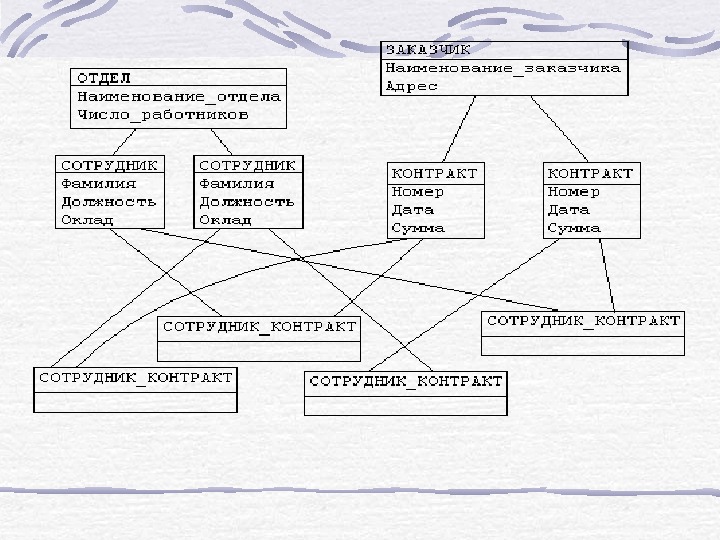
Иерархическая структура преобразовывается в сетевую следующим образом : • древья (a) и (b) заменяются одной сетевой структурой, в которой запись СОТРУДНИК входит в два групповых отношения; • для отображения типа M: N вводится запись СОТРУДНИК_КОНТРАКТ, которая не имеет полей и служит только для связи записей КОНТРАКТ и СОТРУДНИК, см. рис. (Отметим, что в этой записи может храниться и полезная информация, например, доля данного сотрудника в общем вознаграждении по данному контракту. )
Каждый экземпляр группового отношения характеризуется следующими признаками: • способ упорядочения подчиненных записей: • произвольный, • хронологический /очередь/, • обратный хронологический /стек/, • сортированный. • Если запись объявлена подчиненной в нескольких групповых отношениях, то в каждом из них может быть назначен свой способ упорядочивания.
• режим включения подчиненных записей: • автоматический — невозможно занести в БД запись без того, чтобы она была сразу же закреплена за неким владельцем; • ручной — позволяет запомнить в БД подчиненную запись и не включать ее немедленно в экземпляр группового отношения. Эта операция позже инициируется пользователем).
• режим исключения Принято выделять три класса членства подчиненных записей в групповых отношениях: 1. Фиксированное. Подчиненная запись жестко связана с записью владельцем и ее можно исключить из группового отношения только удалив. При удалении записи-владельца все подчиненные записи автоматически тоже удаляются. В рассмотренном выше примере фиксированное членство предполагает групповое отношение «ЗАКЛЮЧАЕТ» между записями «КОНТРАКТ» и «ЗАКАЗЧИК», поскольку контракт не может существовать без заказчика.
2. Обязательное. Допускается переключение подчиненной записи на другого владельца, но невозможно ее существование без владельца. Для удаления записи-владельца необходимо, чтобы она не имела подчиненных записей с обязательным членством. Таким отношением связаны записи «СОТРУДНИК» и «ОТДЕЛ». Если отдел расформировывается, все его сорудники должны быть либо переведены в другие отделы, либо уволены.
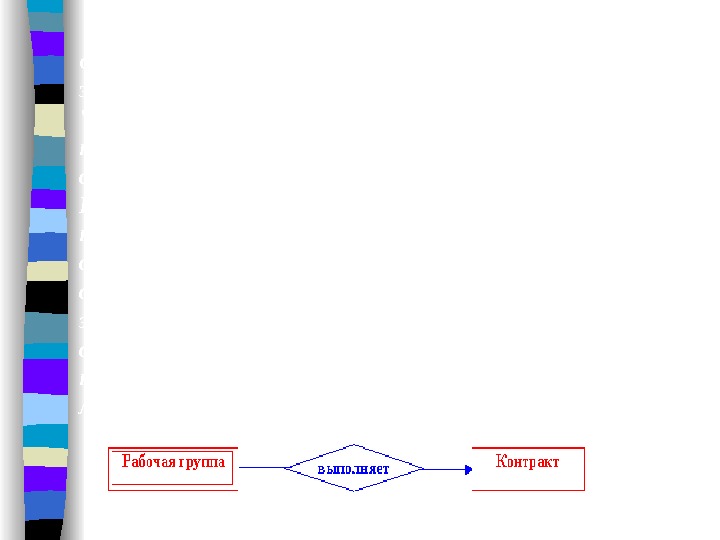
3. Необязательное. Можно исключить запись из группового отношения, но сохранить ее в базе данных не прикрепляя к другому владельцу. При удалении записи-владельца ее подчиненные записи — необязательные члены сохраняются в базе, не участвуя более в групповом отношении такого типа. Примером такого группового отношения может служить «ВЫПОЛНЯЕТ» между «СОТРУДНИКИ» и «КОНТРАКТ», поскольку в организации могут существовать работники, чья деятельность не связана с выполненинем каких-либо договорных обязательств перед заказчиками.
Операции над данными. • ДОБАВИТЬ — внести запись в БД и, в зависимости от режима включения, либо включить ее в групповое отношение, где она объявлена подчиненной, либо не включать ни в какое групповое отношение. • ВКЛЮЧИТЬ В ГРУППОВОЕ ОТНОШЕНИЕ — связать существующую подчиненную запись с записью-владельцем. • ПЕРЕКЛЮЧИТЬ — связать существующую подчиненную запись с другой записью-владельцем в том же групповом отношении. • ОБНОВИТЬ — изменить значение элементов предварительно извлеченной записи.
• ИЗВЛЕЧЬ — извлечь записи последовательно по значению ключа, а также используя групповые отношения — от владельца можно перейти к записям — членам, а от подчиненной записи к владельцу набора. • УДАЛИТЬ — убрать из БД запись. Если эта запись является владельцем группового отношения, то анализируется класс членства подчиненных записей. Обязательные члены должны быть предварительно исключены из группового отношения, фиксированные удалены вместе с владельцем, необязательные останутся в БД. • ИСКЛЮЧИТЬ ИЗ ГРУППОВОГО ОТНОШЕНИЯ — разорвать связь между записью-владельцем и записью-членом.
Ограничения целостности. Как и в иерархической модели, обеспечивается только поддержание целостности по ссылкам (владелец отношения — член отношения).
Реляционная модель данных Реляционная модель предложена сотрудником компании IBM Е. Ф. Коддом в 1970 г. В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД.
Структура данных. В реляционной модели достигается гораздо более высокий уровень абстракции данных, чем в иерархической или сетевой. В статье Е. Ф. Кодда утверждается, что » реляционная модель предоставляет средства описания данных на основе только их естественной структуры, т. е. без потребности введения какой-либо дополнительной структуры для целей машинного представления «. Другими словами, представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название «реляционная» происходит от английского relation — «отношение»).
Определения: • Декартово произведение: Для заданных конечных множеств D 1, D 2, . . , Dn (не обязательно различных) декартовым произведением D 1*D 2*. . *Dn называется множество произведений вида: d 1*d 2*. . *dn , где Пример: если даны два множества A (a 1, a 2, a 3) и B (b 1, b 2), их декартово произведение будет иметь вид С=A*B (a 1*b 1, a 2*b 1, a 3*b 1, a 1*b 2, a 2*b 2, a 3*b 2)
• Отношение: Отношением R , определенным на множествах D 1, D 2, . . , Dn называется подмножество декартова произведения D 1*D 2*. . *Dn. При этом: • множества D 1, D 2, . . , Dn называются доменами отношения • элементы декартова произведения D 1*D 2*. . *Dn называются кортежами • число n определяет степень отношения ( n=1 — унарное, n=2 — бинарное, . . . , n -арное) • количество кортежей называется мощностью отношения Пример: на множестве С из предыдущего примера могут быть определены отношения R 1 (a 1*b 1, a 3*b 2) или R 2 (a 1*b 1, a 2*b 1, a 1*b 2)
Отношения удобно представлять в виде таблиц. На рис унку ниже представлена таблица (отношение степени 5), содержащая некоторые сведения о работниках гипотетического предприятия. Строки таблицы соответствуют кортежам. Каждая строка фактически представляет собой описание одного объекта реального мира (в данном случае работника), характеристики которого содержатся в столбцах. Можно провести аналогию между элементами реляционной модели данных и элементами модели «сущность-связь». Реляционные отношения соответствуют наборам сущностей, а кортежи — сущностям. Поэтому, также как и в модели «сущность-связь» столбцы в таблице, представляющей реляционное отношение, называют атрибутами.
Каждый атрибут определен на домене, поэтому домен можно рассматривать как множество допустимых значений данного атрибута. Несколько атрибутов одного отношения и даже атрибуты разных отношений могут быть определены на одном и том же домене. В примере выше , атрибуты «Оклад» и «Премия» определены на домене «Деньги». Поэтому, понятие домена имеет семантическую нагрузку: данные можно считать сравнимыми только тогда, когда они относятся к одному домену. Таким образом, в рассматриваемом нами примере сравнение атрибутов «Табельный номер» и «Оклад» является семантически некорректным, хотя они и содержат данные одного типа.
Именнованное множество пар «имя атрибута — имя домена» называется схемой отношения. Мощность этого множества — называют степенью или «арностью» отношения. Набор именованных схем отношений представляет из себя схему базы данных. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). В нашем случае ключом является атрибут «Табельный номер», поскольку его значение уникально для каждого работника предприятия. Если кортежи идентифицируются только сцеплением значений нескольких атрибутов, то говорят, что отношение имеет составной ключ. Отношение может содержать несколько ключей. Всегда один из ключей объявляется первичным, его значения не могут обновляться. Все остальные ключи отношения называются возможными ключами.
В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. Рассмотренный в п редыдущем разделе пример базы данных , содержащей сведения о подразделениях предприятия и работающих в них сотрудниках, применительно к реляционной модели будет иметь вид:
Например, связь между отношениями ОТДЕЛ и СОТРУДНИК создается путем копирования первичного ключа «Номер_отдела» из первого отношения во второе. Таким образом: • для того, чтобы получить список работников данного подразделения, необходимо 1. из таблицы ОТДЕЛ установить значение атрибута «Номер_отдела» , соответствующее данному «Наименованию_отдела» 2. выбрать из таблицы СОТРУДНИК все записи, значение атрибута «Номер_отдела» которых равно полученному на предыдушем шаге.
• для того, чтобы узнать в каком отделе работает сотрудник, нужно выполнить обратную операцию: 1. определяем «Номер_отдела» из таблицы СОТРУДНИК 2. по полученному значению находим запись в таблице ОТДЕЛ. Атрибуты, представляющие собой копии ключей других отношений, называются внешними ключами.
Свойства отношений. 1. Отсутствие кортежей-дубликатов. Из этого свойства вытекает наличие у каждого кортежа первичного ключа. Для каждого отношения, по крайней мере, полный набор его атрибутов является первичным ключом. Однако, при определении первичного ключа должно соблюдаться требование «минимальности», т. е. в него не должны входить те атрибуты, которые можно отбросить без ущерба для основного свойства первичного ключа — однозначно определять кортеж. 2. Отсутствие упорядоченности кортежей. 3. Отсутствие упордоченности атрибутов. Для ссылки на значение атрибута всегда используется имя атрибута. 4. Атомарность значений атрибутов, т. е. среди значений домена не могут содержаться множества значений (отношения).
Лекция № 3 Нормализация Свойства отношений. 1. Отсутствие кортежей-дубликатов. Из этого свойства вытекает наличие у каждого кортежа первичного ключа. Для каждого отношения, по крайней мере, полный набор его атрибутов является первичным ключом. Однако, при определении первичного ключа должно соблюдаться требование «минимальности», т. е. в него не должны входить те атрибуты, которые можно отбросить без ущерба для основного свойства первичного ключа — однозначно определять кортеж. 2. Отсутствие упорядоченности кортежей. 3. Отсутствие упордоченности атрибутов. Для ссылки на значение атрибута всегда используется имя атрибута. 4. Атомарность значений атрибутов, т. е. среди значений домена не могут содержаться множества значений (отношения).
Функциональные зависимости Функциональной зависимостью ( FD ) на отношении R называется выражение вида: «Если 2 кортежа согласуются по атрибутам A 1, A 2, A 3, . . , An, то они также согласуются по атрибуту B » Формальная запись: A 1 A 2…An B. Говорят что « A 1, A 2, …, An функционально определяют B » A 1 A 2…An B 1 A 1 A 2…An B 2 … A 1 A 2…An Bn Краткая запись: A 1 A 2…An B 1 B 2. . Bn
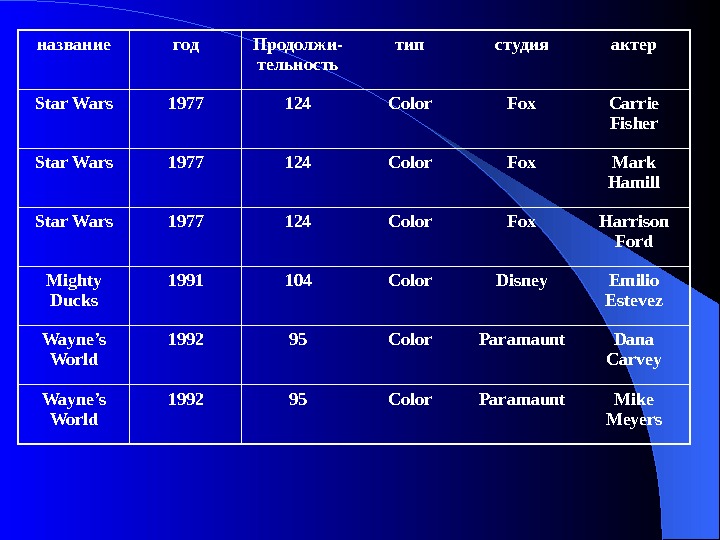
название год Продолжи- тельность тип студия актер Star Wars 1977 124 Color Fox Carrie Fisher Star Wars 1977 124 Color Fox Mark Hamill Star Wars 1977 124 Color Fox Harrison Ford Mighty Ducks 1991 104 Color Disney Emilio Estevez Wayne’s World 1992 95 Color Paramaunt Dana Carvey Wayne’s World 1992 95 Color Paramaunt Mike Meyers
Пример: Отношение Фильмы (название, год, продолжительность, тип, студия, актер) Можно выделить 3 функциональные зависимости: название год продложительность название год тип название год студия Краткая запись: название год продложительность тип студия название год актер – не
Множество атрибутов A={A 1, A 2, …, An} – ключ отношения R, если : 1. A функционально определяет все остальные атрибуты отношения 2. А – наименьшее по включению Ключ для приведенного примера: { название, год, актер } { название, год } не ключ, так как название год актер не FD Суперключ – множество атрибутов, содержащих ключ.
Функциональная зависимость A 1 A 2…An B 1 B 2. . Bm называется • тривиальной, если {B, 1 B 2, . . , Bm} – подмножество {A 1, A 2, …, An} • нетривиальной , если множества частично не пересекаются • полностью нетривиальной , если множества не пересекаются Тривиальные FD всегда выполнимы!
Пусть A={A 1, A 2, . . , An}- множество атрибутов и S – множество функциональных зависимостей. Замыканием A над функциональными зависимостями из S называется множество атрибутов B, такое, что всякое отношение, удовлетворяющее всем функциональным зависимостям из S, удовлетворяет также зависимости: A 1 A 2…An B То есть A 1 A 2…An B следует из S Обозначение: {A 1, A 2, . . , An} +
Алгоритм вычисления замыкания: 1. Пусть X – вычисляемое замыкание. X={A 1, A 2, . . , An} 2. Последовательно ищем функциональные зависимости B 1 B 2…Bm C в S такие, что: B 1, B 2…, Bm X, а С X. Добавляем C в X. 3. Повторяем шаг 2, пока возможно расширение X. Поскольку X только растет, и множество атрибутов конечно – процесс прекратится в некоторый момент. 4. Построенное множество X — {A 1, A 2, . . , An} +
Пример: Атрибуты : A, B, C, D, E, F FDs: AB C BC AD D E CF B Построим {A, B}+ 1. X={A, B} 2. X={A, B, C} 3. X={A, B, C, D} 4. X={A, B, C, D, E}
Обоснование алгоритма. Докажем что: 1. Алгоритм не рассматривает излишних зависимостей. То есть покажем, что если FD: A 1 A 2…An B помечена алгоритмом (B принадлежит замыканию ) , то A 1 A 2…An B справедлива в любом отношении, удовлетворяющем всем зависимостям из S 2. Алгоритм находит все зависимости, которые следуют из S, то есть если зависимость не найдена алгоритмом, то она не следует из S
1. По индукции по количеству повторения шага 2 алгоритма. Покажем, что каждое отношение, удовлетворяющее всем зависимостям из S , удовлетворяет также зависимости A 1 A 2… An D , где D – атрибут добавленный к замыканию на очередном шаге База: A 1 A 2…An D, где D находится среди Ai – тривиальная зависимость, удовлетворяется в любом отношении. Шаг: Пусть D был добавлен при использовании правила B 1 B 2… Bm D. По предположению индукции A 1 A 2…An Bi , для I=1. . m. Таким образом два любых кортежа R , согласующиеся по атрибутам A 1 , A 2 , … , An , согласуются также по B 1 , B 2… , Bm. Поскольку R удовлетворяет зависимости B 1 B 2…Bm D , то указанные кортежи согласуются по атрибуту D. Таким образом R удовлетворяет зависимости A 1 A 2…An
2. Пусть A 1 A 2…An B – функциональная зависимость, которая не следует из S согласно алгоритму. То есть B не принадлежит замыканию {A 1, A 2, . . , An} + над зависимостями из S. Покажем, что A 1 A 2…An B действительно не следует из S, то есть существует хотя бы одно отношение, удовлетворяющее всем зависимостям из S и не удовлетворяющее A 1 A 2…An B. Возьмем отношение I из 2 -х кортежей, которые согласуются по всем атрибутам из {A 1, A 2, . . , An} + и не согласуются по всем оставшимся атрибутам: {A 1, A 2, . . , An} + остальные атрибуты t: 1 1. . . 1 1 0 0 0 . . . 0 0 0 s: 1 1. . . 1 1 1 . . .
а)Покажем, что I удовлетворяет всем функциональным зависимостям из S. Предположим, что в S существует FD C 1 C 2…Ck D, которой не удовлетворяет I. Кортежи t и s, согласующиеся по атрибутам { C 1, C 2, …, Ck} должны не согласовываться по атрибуту D. По построению I такое возможно, если C 1, C 2, …, Ck принадлежат {A 1, A 2, . . , An} + и D находится среди оставшихся атрибутов. Но это означает, что замыкание вычислено неверно – поскольку D должен быть добавлен к {A 1, A 2, . . , An} + на шаге 2. Предположение неверно. b) Покажем, что I не удовлетворяет A 1 A 2…An B. t и s согласуются по всем атрибутам из замыкания, значит согласуются и по атрибутам A 1 , A 2 , … , An. B не принадлежит замыканию {A 1, A 2, . . , An} +. Следовательно I не удовлетворяет зависимости A 1 A 2…An B по определению замыкания
Транзитивность Если A 1 A 2…An B 1 B 2. . Bm и B 1 B 2. . Bm С 1 С 2. . С k , то A 1 A 2…An С 1 С 2. . С k. Доказательство: Построим замыкание {A 1, A 2, . . , An} + над двумя указанными функциональными зависимостями. С 1 , С 2 , . . , С k принадлежат замыканию по алгоритму построения. Значит A 1 A 2…An С 1 С 2. . С k по определению замыкания. Связь замыкания и ключей {A 1, A 2, . . , An} + — множество всех атрибутов тогда и только тогда, когда A 1, A 2, . . , An – суперключ отношения R.
Вернемся к примеру с фильмами и киностудиями. Создадим отношение Фильм. Студия , хранящее связь фильмов и киностудий, без информации об актерах. название год продолжи тельность тип студия адрес студии Star Wars 1977 124 Color Fox Hollywood Mighty Ducks 1991 104 Color Disney Buena Vista Wayne’s World 1992 95 Color Paramount Hollywood
Выделим две зависимости: название год студия адрес студии По правилу транзитивности имеем: название год адрес студии
Аномалии в схеме реляционной базы 1. Избыточность – информация без необходимости повторяется в нескольких кортежах 2. Update аномалия – необходимость обновлять информацию в нескольких кортежах 3. Delete аномалия – удаление части информации может привести к потере другой информации. Пример – удалим единственного актера из фильма Диснея и потеряем всю информацию о фильме. Для устранения аномалий используют декомпозицию отношений.
Декомпозиция отношения – разбиение атрибутов на подмножества, определяющие схему новых отношений и проецирование исходных кортежей в эти новые отношения. Пример: разобьем отношение Фильмы на два, для избавления от аномалий 1. Фильмы1 – в него входят все атрибуты кроме «актер» . Фильмы1(название, год, продолжительность, тип, студия) 2. Фильмы2(название, год, актер) название год продолжи тельность тип студия Star Wars 1977 124 Color Fox Mighty Ducks 1991 104 Color Disney Wayne’s World 1992 95 Color Paramount Фильмы
название год Актер Star Wars 1977 Carrie Fisher Star Wars 1977 Mark Hamill Star Wars 1977 Harrison Ford Mighty Ducks 1991 Emilio Estevez Wayne’s World 1992 Dana Carvey Wayne’s World 1992 Mike Meyers Фильмы
Цель декомпозиции – заменить отношение, на несколько отношений, не подверженных аномалиям. Существует формальное условие, при выполнении которого отношение не подвержено описанным аномалиям – нормальная форма Бойса-Кодда ( BCNF ) . Отношение R находится в BCNF тогда и только тогда, когда не существует нетривиальной FD A 1 A 2…An B 1 B 2. . Bm такой, что {A 1, A 2, …, An} не является суперключом. То есть левая часть всякой нетривиальной зависимости должна быть суперключом (должна содержать ключ).
Пример: Отношение Фильмы (название, год, продолжительность, тип, студия, актер) не находится в BCNF. Выше было показано, что ключ для приведенного примера: { название, год, актер } и имеет место зависимость: название год продолжительность тип студия – левая часть не суперключ. Отношение Фильмы1(название, год, продолжительность, тип, студия) находится в BCNF, поскольку имеется единственная зависимость: название год продолжительность тип студия и ее левая часть — суперключ
Стратегия декомпозиции отношения в BCNF: 1. Выбираем нетривиальную FD A 1 A 2…An B 1 B 2. . Bm на которой нарушается BCNF ({A 1, A 2, …, An} не суперключ ) 2. В первое отношение помещаем все атрибуты из левой и правой части FD 3. Во второе отношение помещаем все атрибуты из левой части и оставшиеся атрибуты не вошедшие в правую часть выбранной FD. Именно таким образом отношение фильмы было разбито на два, относительно зависимости, нарушающей BCNF исходного отношения: название год продолжительность тип студия В дальнейшем исходное отношение может быть восстановлено. Для этого достаточно «склеить» кортежи новых отношений по атрибутам из левой части функциональной зависимости, которая инициирует декомпозицию.
Возьмем рассмотренное выше отношение Фильм. Студия. Были выделены функциональные зависимости: название год студия адрес студии (по правилу транзитивности) название год адрес студии Кроме того очевидна зависимость: название год продолжительность тип Ключ: { название, год }. На зависимости: студия адрес студии BCNF нарушается. Произведем декомпозицию: Фильм. Студия 1(студия, адрес студии) Фильм. Студия 2(название, год, продолжительность, тип, студия)
Не всегда существует возможность провести декомпозицию в BCNF. Пример: отношение Билеты(название (фильма, кинотеатр, город). Предположим, что одинаковые фильмы не заказываются одновременно в 2 -х кинотеатрах одного города и существуют кинотеатры, показывающие несколько фильмов одновременно. Выделим следующие FD: кинотеатр город название город кинотеатр Ключи: { название, город } и { кинотеатр, название } – можно проверить, построив замыкание, оно будет содержать все атрибуты отношения, причем ни один из атрибутов в одиночестве ключом не является. FD кинотеатр город нарушает BCN
Попытаемся провести декомпозицию: { кинотеатр, город } { кинотеатр, название } FD название город кинотеатр перестанет выполнятся при склейке отношений. Например: кинотеатр | город колизей | екатеринбург салют | екатеринбург кинотеатр | название колизей | матрица салют | матрица Склеив получаем: кинотеатр | город | название колизей | екатеринбург | матрица салют | екатеринбург | матрица
Отношение находится в третьей нормальной форме , если для всякой функциональной зависимости либо левая часть является суперключом, либо все атрибуты правой части входят в ключ. Отношение билеты находится в 3 N
Отношение находится в первой нормальной форме, если все атрибуты атомарные. Отношение находится во второй нормальной форме, если оно находится в 1 NF и каждый не ключевой атрибут функционально зависит от ключа, но не зависит ни от какого собственного подмножества ключа. Отношение находится в третьей нормальной форме, если оно находится в 2 NF и каждый не ключевой атрибут не транзитивно зависит от первичного ключа. Отношение находится в BCNF , если оно находится в 3 NF и отсутствуют зависимости атрибутов первичного ключа от не ключевых атрибутов.
Лекция № 4 Целостность и реляционные операции Ограничения целостности Целостность данных — это механизм поддержания соответствия базы данных предметной области. В реляционной модели данных определены два базовых требования обеспечения целостности: • целостность ссылок • целостность сущностей.
Целостность сущностей. Объект реального мира представляется в реляционной базе данных как кортеж некоторого отношения. Требование целостности сущностей заключается в следующем: каждый кортеж любого отношения должен отличатся от любого другого кортежа этого отношения (т. е. любое отношение должно обладать первичным ключом).
Вполне очевидно, что если данное требование не соблюдается (т. е. кортежи в рамках одного отношения не уникальны), то в базе данных может хранится противоречивая информация об одном и том же объекте. Поддержание целостности сущностей обеспечивается средствами системы управления базой данных (СУБД). Это осуществляется с помощью двух ограничений: • при добавлении записей в таблицу проверяется уникальность их первичных ключей • не позволяется изменение значений атрибутов, входящих в первичный ключ.
Целостность ссылок Сложные объекты реального мира представляются в реляционной базе данных в виде кортежей нескольких нормализованных отношений, связанных между собой. При этом: 1. Связи между данными отношениями описываются в терминах функциональных зависимостей. 2. Для отражения функциональных зависимостей между кортежами разных отношений используется дублирование первичного ключа одного отношения (родительского) в другое (дочернее). Атрибуты, представляющие собой копии ключей родительских отношений, называются внешними ключами.
Требование целостности по ссылкам состоит в следующем: Д ля каждого значения внешнего ключа, появляющегося в дочернем отношении, в родительском отношении должен найтись кортеж с таким же значением первичного ключа.
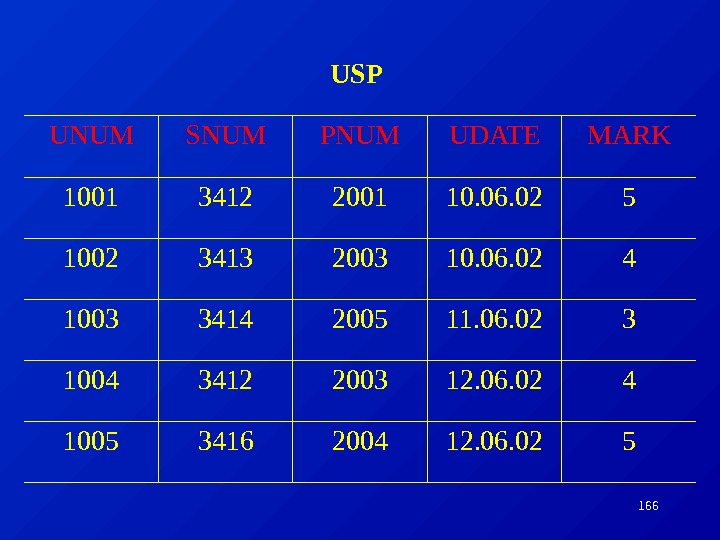
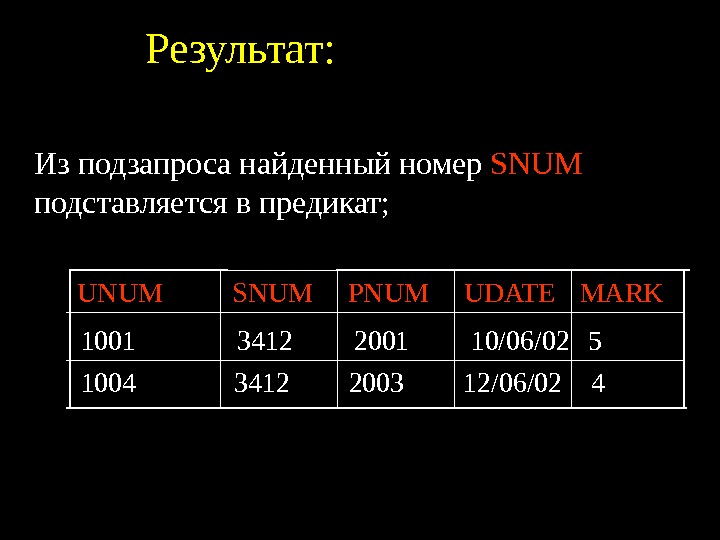
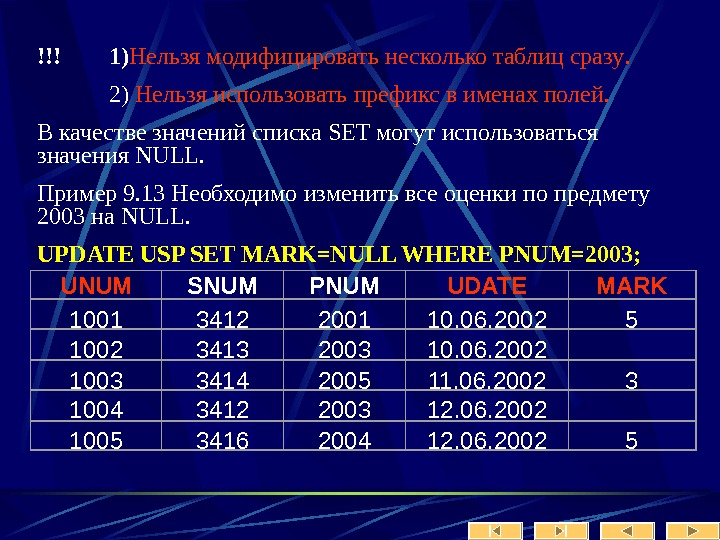
Пусть, например, даны отношения ОТДЕЛ ( N_ОТДЕЛА , ИМЯ_ОТДЕЛА) и СОТРУДНИК ( N_СОТРУДНИКА , N_ОТДЕЛА, ИМЯ_СОТРУДНИКА), в которых хранятся сведения о работниках предприятия и подразделениях, где они работают. Отношение ОТДЕЛ в данной паре является родительским, поэтому его первичный ключ «N_отдела» присутствует в дочернем отношении СОТРУДНИК. Требование целостности по ссылкам означает здесь, что в таблице СОТРУДНИК не может присутствовать кортеж со значением атрибута «N_отдела» , которое не встречается в таблице ОТДЕЛ. Если такое значение в отношении ОТДЕЛ отсутствует, значение внешнего ключа в отношении СОТРУДНИК считается неопределенным.
Как правило, поддержание целостности ссылок также возлагается на систему управления базой данных. Например, она может не позволить пользователю добавить запись, содержащую внешний ключ с несуществующим (неопределенным) значением. Ч асто вместо выражения «целостность по ссылкам» употребляют его синонимы «ссылочная целостность», «целостность связей» или «требование внешнего ключа».
Реляционное исчисление. В реляционной модели определяются два базовых механизма манипулирования данными: • основанная на теории множеств реляционная алгебра • основанное на математической логике реляционное исчисление.
Операции над данными (реляционная алгебра). Операции обработки кортежей. Эти операции связаны с изменением состава кортежей в каком-либо отношении. • ДОБАВИТЬ — необходимо задать имя отношения и ключ кортежа. • УДАЛИТЬ — необходимо указать имя отношения, а также идентифицировать кортеж или группу кортежей, подлежащих удалению. • ИЗМЕНИТЬ — выполняется для названного отношения и может корректировать как один, так и несколько кортежей.
На входе каждой такой операции используется одно или несколько отношений, результатом выполения операции всегда является новое отношение. В рассмотренных ниже примерах (которые заимствованы из книги Э. Озкарахан «Машины баз данных и управление базами данных» -М: «Мир», 1989) используются следующие отношения: P(D 1, D 2, D 3) Q(D 4, D 5) R(M, P, Q, T) S(A, B) 1 11 x 1 x 101 5 a 5 a 2 11 y x 2 y 105 3 a 10 b 3 11 z y 1 z 500 9 a 15 c 4 12 x w 50 1 b 2 d w 10 2 b 6 a w 300 4 b 1 b
В реляционной алгебре определены следующие операций обработки отношений: • ПРОЕКЦИЯ (ВЕРТИКАЛЬНОЕ ПОДМНОЖЕСТВО). Операция проекции представляет из себя выборку из каждого кортежа отношения значений атрибутов, входящих в список A, и удаление из полученного отношения повторяющихся строк.
• ВЫБОРКА (ОГРАНИЧЕНИЕ, ГОРИЗОНТАЛЬНОЕ ПОДМНОЖЕСТВО). На входе используется одно отношение, результат — новое отношение, построенное по той же схеме, содержащее подмножество кортежей исходного отношения, удовлетворяющих условию выборки.
• ОБЪЕДИНЕНИЕ. Отношения-операнды в этом случае должны быть определены по одной схеме. Результирующее отношение содержит все строки операндов за исключением повторяющихся.
• ПЕРЕСЕЧЕНИЕ. На входе операции два отношения, определенные по одной схеме. На выходе — отношение, содержащие кортежи, которые присутствуют в обоих исходных отношениях.
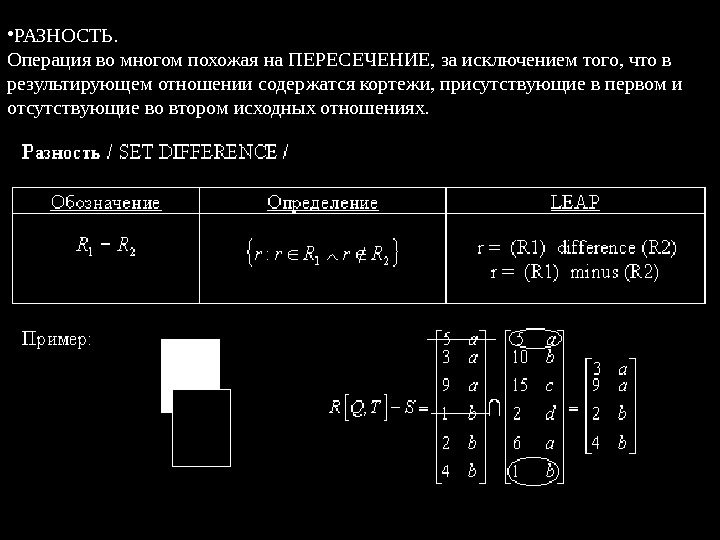
• РАЗНОСТЬ. Операция во многом похожая на ПЕРЕСЕЧЕНИЕ, за исключением того, что в результирующем отношении содержатся кортежи, присутствующие в первом и отсутствующие во втором исходных отношениях.
• ДЕКАРТОВО ПРОИЗВЕДЕНИЕ Входные отношения могут быть определены по разным схемам. Схема результирующего отношения включает все атрибуты исходных. Кроме того: • степень результирующего отношения равна сумме степеней исходных отношений • мощность результирующего отношения равна произведению мощностей исходных отношений.
• СОЕДИНЕНИЕ Данная операция имеет сходство с ДЕКАРТОВЫМ ПРОИЗВЕДЕНИЕМ. Однако, здесь добавлено условие, согласно которому вместо полного произведения всех строк в результирующее отношение включаются только строки, удовлетворяющие опредленному соотношению между атрибутами соединения (А 1 , A 2 ) соответствующих отношений.
Также как и выражения реляционной алгебры формулы реляционного исчисления определяются над отношениями реляционных баз данных, и результатом вычисления также является отношение. Эти механизмы манипулирования данными различаются уровнем процедурности: • запрос, представленный на языке релационной алгебры, может быть вычислен на основе вычисления элементарных алгебраичесских операций с учетом их старшинства и возможных скобок • формула реляционного исчисления только устанавливает условия, которым должны удовлетворять кортежи результирующего отношения. Поэтому языки реляционного исчисления являются более непроцедурными или декларативными.
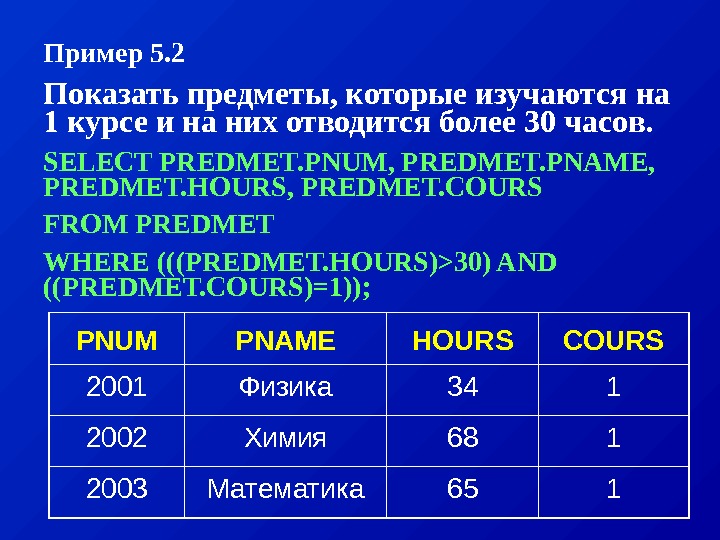
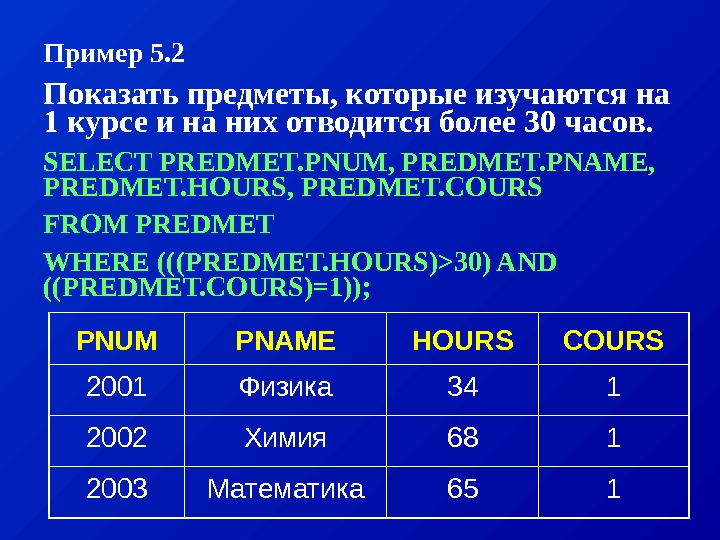
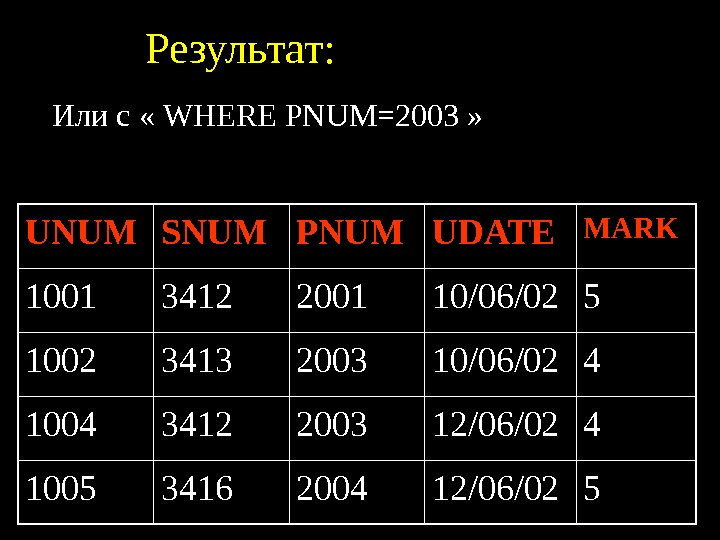
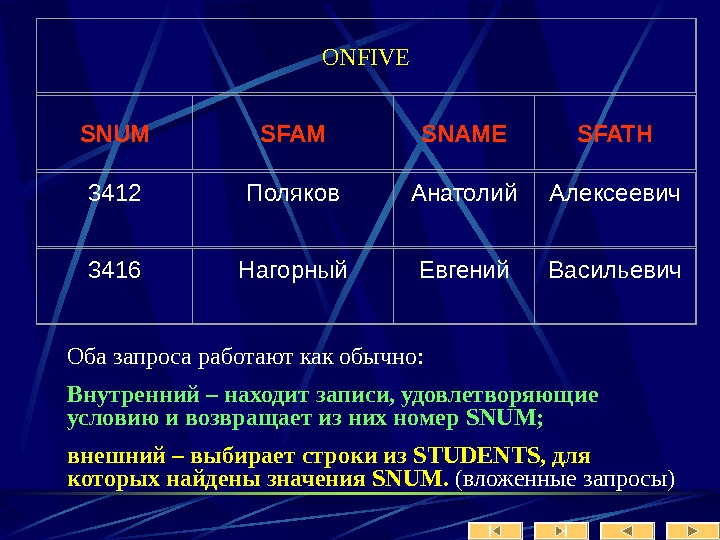
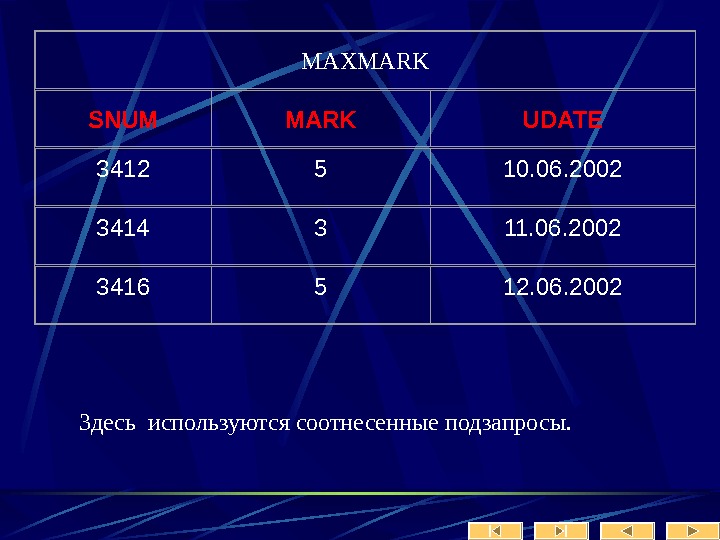
Пример: Пусть даны два отношения: СОТРУДНИКИ (СОТР_НОМЕР, СОТР_ИМЯ, СОТР_ЗАРПЛ, ОТД_НОМЕР) ОТДЕЛЫ(ОТД_НОМЕР, ОТД_КОЛ, ОТД_НАЧ) Мы хотим узнать имена и номера сотрудников, являющихся начальниками отделов с количеством работников более 10. Выполнение этого запроса средствами реляционной алгебры распадается на четко определенную последовательность шагов: (1). выполнить соединение отношений СОТРУДНИКИ и ОТДЕЛЫ по условию СОТР_НОМ = ОТДЕЛ_НАЧ. С 1 = СОТРУДНИКИ [СОТР_НОМ = ОТД_НАЧ] ОТДЕЛЫ
(2). из полученного отношения произвести выборку по условию ОТД_КОЛ > 10 С 2 = С 1 [ОТД_КОЛ > 10]. (3). спроецировать результаты предыдущей операции на атрибуты СОТР_ИМЯ, СОТР_НОМЕР С 3 = С 2 [СОТР_ИМЯ, СОТР_НОМЕР]
Заметим, что порядок выполнения шагов может повлиять на эффективность выполнения запроса. Так, время выполнения приведенного выше запроса можно сократить, если поменять местами этапы (1) и (2). В этом случае сначала из отношения СОТРУДНИКИ будет сделана выборка всех кортежей со значением атрибута ОТДЕЛ_КОЛ > 10, а затем выполнено соединение результирующего отношения с отношением ОТДЕЛЫ. Машинное время экономится за счет того, что в операции соединения участвуют меньшие отношения.
На языке реляционного исчисления данный запрос может быть записан как: Выдать СОТР_ИМЯ и СОТР_НОМ для СОТРУДНИКИ таких, что существует ОТДЕЛ с таким же, что и СОТР_НОМ значением ОТД_НАЧ и значением ОТД_КОЛ большим 50. Здесь мы указываем лишь характеристики результирующего отношения, но не говорим о способе его формирования. СУБД сама должна решить какие операции и в каком порядке надо выполнить над отношениями СОТРУДНИКИ и ОТДЕЛЫ. Задача оптимизации выполнения запроса в этом случае также ложится на СУБД.
Лекция № 5 СУБД, исторические моменты и факты • 1975 — основана компания Microsoft. • 1977 — основана компания Software Development Laboratories (ныне — Oracle Corporation). • 1978 — Software Development Laboratories переименована в Relational Software, Inc. • 1979 — выпущена первая официальная версия СУБД Oracle — V 2. • 1980 — выпущена версия Oracle 2 для операционной системы VAX/VMS.
• 1982 — выпущена версия Oracle 3, которая стала первой СУБД, поддерживающей обработку транзакций и способной выполняться на разных платформах, в том числе на мэйнфреймах и мини-ЭВМ. • 1983 — Relational Software, Inc. переименована в Oracle Corporation. • 1984 — выпущена и перенесена на несколько различных платформ версия Oracle 4. • 1986 — выпущена версия Oracle 5, поддерживающая возможности создания приложений в архитектуре «клиент-сервер» , распределенную обработку данных, кластеры VAX.
• 1987 — заключено соглашение между Microsoft и Sybase о лицензировании СУБД Sybase (Sybase Data. Server). Oracle становится крупнейшим в мире производителем СУБД. • 1988 — выпущена версия Oracle 6, а чуть позже объявлено, что Oracle 6. 2 будет поддерживать симметричные кластеры с применением Oracle Parallel Server. Oracle выпустила Unix Relational Financial Applications. В том же году Microsoft и Ashton-Tate анонсировали первую версию Microsoft SQL Server — реляционную СУБД для локальных вычислительных сетей. Новый продукт носил название Ashton-Tate/Microsoft SQL Server и представлял собой версию Sybase Data. Server для OS/2. Роль Ashton-Tate заключалась в том, что эта фирма предоставила d. BASE IV, используемую для разработки приложений.
• 1989 — Oracle реализовала поддержку OLTP, продукты фирмы стали доступны в 86 странах мира. В мае этого года увидела свет первая версия Ashton-Tate/Microsoft SQL Server. • 1990 — выпущен SQL Server v 1. 1 с поддержкой как OS/2, так и новой графической оболочки фирмы — Microsoft Windows 3. 0. • 1991 — Microsoft получила доступ к исходному коду SQL Server и начала работу над новой версией продукта. В мае Microsoft и IBM объявили о завершении совместной работы над OS/2.
• 1992 — выпущена версия Oracle 7 для Unix. Эта СУБД поддерживала распределенные запросы, удаленное администрирование, осуществляла поддержку различных сетевых протоколов. В этом же году был выпущен SQL Server 4. 2 — 16 -разрядная СУБД, результат совместной работы Microsoft и Sybase. В этой СУБД были реализованы клиентские библиотеки для MS-DOS, Windows и OS/2, помимо этого в нее впервые были включены средства администрирования с графическим интерфейсом под управлением Windows. Компания Microsoft приняла решение сосредоточиться на развитии версий SQL Server только для Windows NT и остановить развитие версий для Unix. В октябре была выпущена бета-версия SQL Server для Windows NT.
• 1994 — выпущена версия Oracle 7 для IBM PC (до этого времени компания Oracle не рассматривала данную платформу как серверную, ограничиваясь лишь созданием для нее клиентских частей своих СУБД). В этом же году закончилось сотрудничество Microsoft и Sybase, и далее эти две компании стали разрабатывать свои серверные СУБД независимо друг от друга. В конце года был выпущен сервер Sybase SQL Server System 10. • 1995 — в начале года выпущен Microsoft SQL Server 6. 0. Oracle объявила о выпуске Discoverer 2000 — набора средств для анализа корпоративных данных.
• 1996 — выпущен SQL Server 6. 5, обладавший встроенной поддержкой Web-приложений, средствами распределенного администрирования, наличием динамических блокировок. Oracle выпустила Oracle 7. 3 Universal Server. • 1997 — выпущена версия Oracle 8, основными особенностями которой стали более высокая надежность по сравнению с предыдущей версией, а также поддержка большего числа пользователей и больших объемов данных. Выпущены версии Oracle Designer/2000 2. 1 и Oracle Developer/2000, которые существенно облегчили создание приложений, работающих с базами данных, а также Oracle Applications for the. Web.
• 1998 — выпущен Microsoft SQL Server 7. 0 с радикально измененной архитектурой. Это была первая версия SQL Server, не содержавшая унаследованного кода, оставшегося со времен сотрудничества с Sybase. Особо стоит отметить появление в этой версии OLAP-служб в составе продукта (до этого серверные OLAP-средства, производимые поставщиками серверных СУБД, включая и Oracle, продавались исключительно как отдельные продукты и относились к категории весьма дорогостоящего программного обеспечения).
• 1999 — выпущена версия Oracle 8 i (Oracle 8. 1), которая во многом была основана на применении Java: виртуальная Java-машина находится в самой СУБД, на этом же языке написаны клиентские утилиты, инсталлятор, средства администрирования. В конце того же года выпущена вторая версия Oracle 8 i (Oracle 8. 1. 6), поддерживающая XML и содержащая некоторые новшества, связанные с созданием хранилищ данных. • 2000 — выпущена третья версия Oracle 8 i (Oracle 8. 1. 7), содержащая Java Virtual Machine Accelerator, а также Internet File System. В этом же году выпущен Microsoft SQL Server 2000, поддерживающий Web-приложения, XML, а также содержащий множество нововведений в административных утилитах.
Сравнение особенностей Поддержка различных платформ Настольные и однопользовательские версии – Personal Orнle, Oracle Lite ( не поддерживает PL/SQL) Поддержка только платформы NT Настольные и однопользовательские версии – Microsoft Data Engine. Oracle MS SQL
Сравнение особенностей Полная стоимость владения обычно выше Инструменты и утилиты производились третьими фирмами, но теперь ситуация изменилась Полная стоимость владения обычно ниже Простота администрирования – Enterprise Manager. Oracle MS SQL
Сравнение особенностей Производительность – входит в 5 ку по данным Transaction Processing Performance Council (TPC; http: //www. tpc. org / ) Поддержка Java и XML, встроенный язык для написания скриптов PL/SQL Производительность – лидер по данным Transaction Processing Performance Council (TPC; http: //www. tpc. org / ) Поддержка XML , встроенный язык для написания скриптов – Transact SQL (T-SQL)Oracle MS SQL
Возможности MS SQL 2000 SQL Server 2000 позволяет использовать на одном компьютере несколько одновременно работающих серверов. Помимо этого можно использовать несколько SQL Server 2000 и один SQL Server 7. 0. В версии SQL Server 2000 появилась поддержка пользовательских функций, которые можно создавать средствами языка Transact SQL. Помимо скалярных значений такие функции могут возвращать и таблицы.
Возможности MS SQL 2000 В рамках поддержки ссылочной целостности, в SQL Server 2000 реализованы каскадные удаления и обновления (CASCADE DELETE, CASCADE UPDATE). Добавлена поддержка языка XML, включая ключевое слово FOR XML для извлечения данных в виде XML-потоков
Возможности MS SQL 2000 Для повышения производительности теперь можно создавать индексы для представлений (Indexed Views). Возможность обновлять данные через представления ( Updatable Views ) П еремещение протоколов транзакций с одного сервера на другой в целях полной поддержки отсоединенных баз данных (standby databases).
Возможности MS SQL 2000 Репликация Служба трансформации данных DTS В Microsoft SQL Server 7 были впервые включены средства анализа данных (OLAP) в качестве компонента сервера. В SQL Server 2000 эти средства получили дальнейшее развитие: компонент Analysis Services включает как средства анализа данных, так и средства поиска закономерностей (Data Mining).
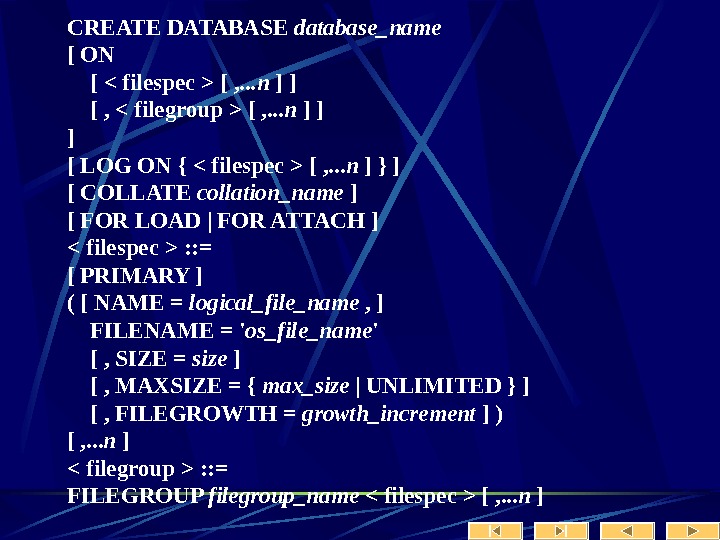
Архитектура сервера SQL Server использует для хранения баз данных набор файлов операционной системы, при этом для каждой из них создается собственный файл. Первичный файл данных (Primary data file) Этот файл — отправная точка базы данных. Всякая база данных имеет только один первичный файл данных. Рекомендуемое расширение —. mdf.
Архитектура сервера Вторичные файлы данных (Secondary data files) Эти файлы являются необязательными и могут хранить все данные и объекты, не вошедшие в первичный файл данных. Некоторые базы данных могут вообще не иметь вторичных файлов данных, а другие иметь множество таких файлов. Рекомендуемое расширение —. ndf.
Архитектура сервера Файлы журнала (Log files) В этих файлах фиксируется вся информация о транзакциях, которая используется для восстановления базы данных. Каждая база данных имеет, по крайней мере, один файл журнала. Рекомендуемое расширение —. ldf.
Архитектура сервера При создании базы данных все входящие в ее состав файлы «обнуляются» (заполняются нулями), чтобы стереть все данные, которые остались на диске от ранее удаленных файлов. Хотя это приводит к увеличению продолжительности создания БД, это избавляет Windows NT от необходимости очистки файлов при записи данных в них (поскольку они уже «обнулены») во время нормальной работы с базой данных, что повышает производительность системы.
Архитектура сервера Данные таблиц хранятся в наборе страниц данных. Каждая страница имеет заголовок, который содержит такую системную информацию, как идентификатор владеющей данной страницей таблицы и указатели на следующую и предыдущую страницы в связанном списке. В конце страницы расположена таблица смещений строк; остальное пространство страницы занято строками данных.
Типы данных Bigint Binary Bit Char Cursor Datetime Decimal Float Image • Intmoney • Nchar • Ntext • Nvarchar • Real • Smalldatetime • Smallint • Smallmoney • Text • Timestamp • Tinyint • Varbinary • Varchar • uniqueidentifier
Авторизация MS SQL поддерживает windows- авторизацию (пользователь авторизуется контроллером домена) и sql- авторизацию (пользователь заводится на sql- сервере) Имеется встроенный пользователь sa – System Administrator При любом типе авторизации пользователю могут быть розданы права как на всю базу так и на отдельные объекты базы. Пользователь -dbowner базы имеет право делать с базой все что угодно. Более подробно вопросы авторизации и безопасности будут рассмотрены позднее
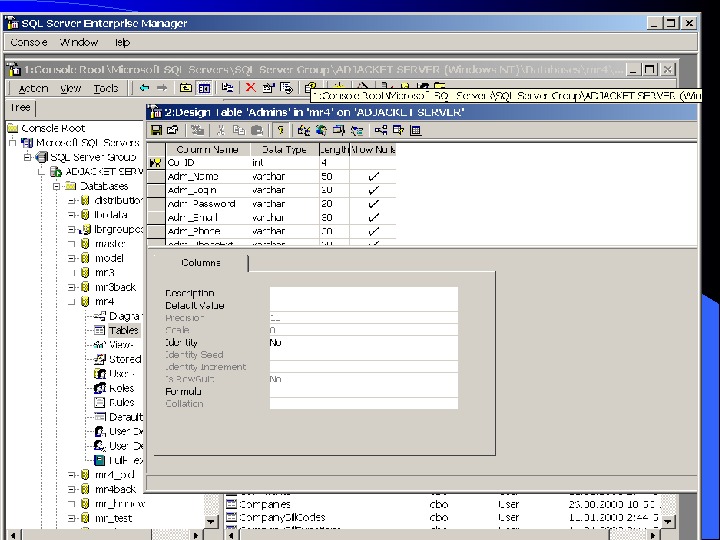
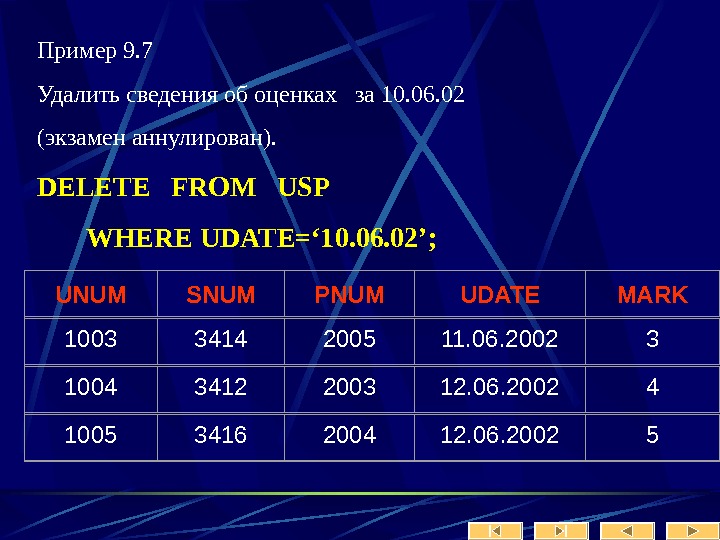
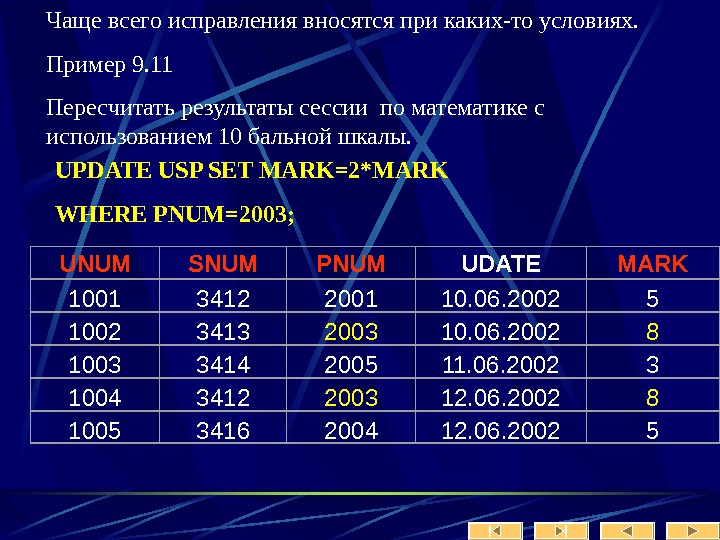
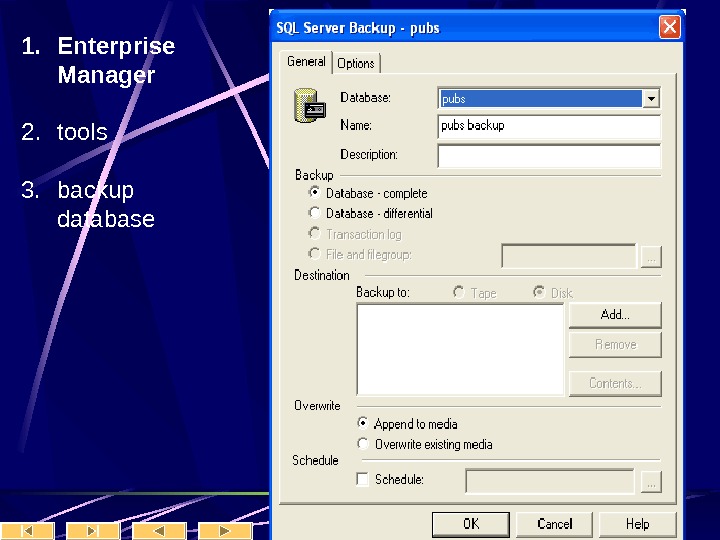
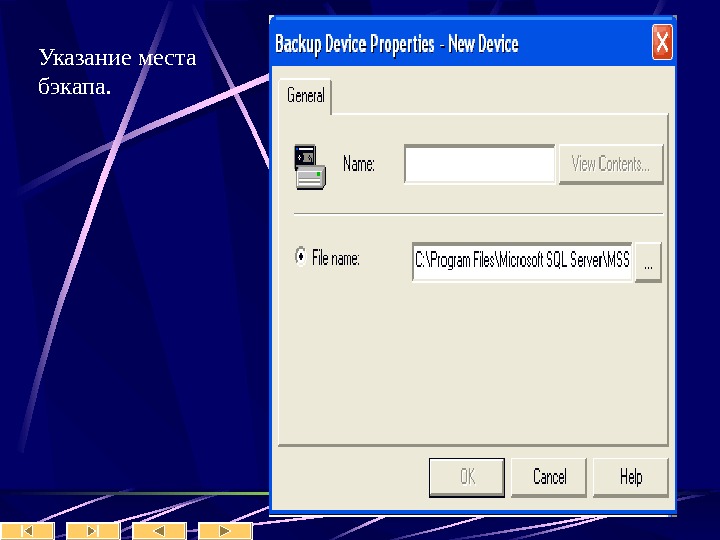
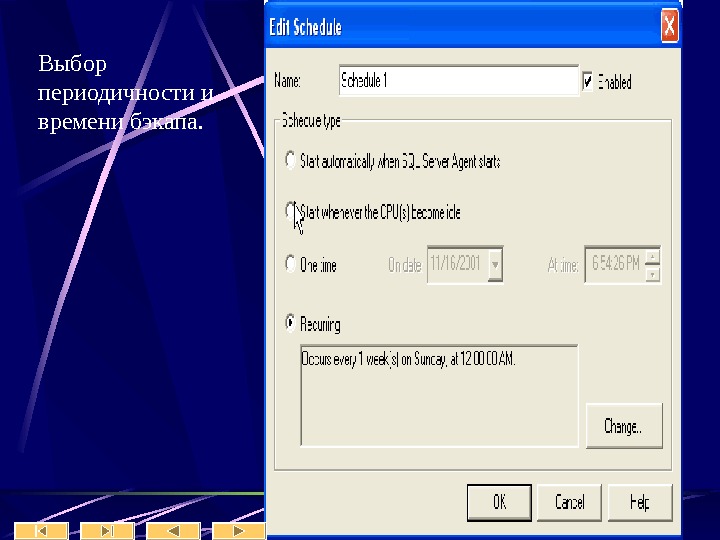
Клиенты Query Analyzer – для запуска запросов Enterprise Manager – набор wizard’ ов для управления базой Таким образом создание таблиц и заполнение их данными может производиться как через графический интерфейс, так и скриптом. Инструкции DDL – data defining language для создания таблицы не имеют принципиальных отличий от инструкций Oracle
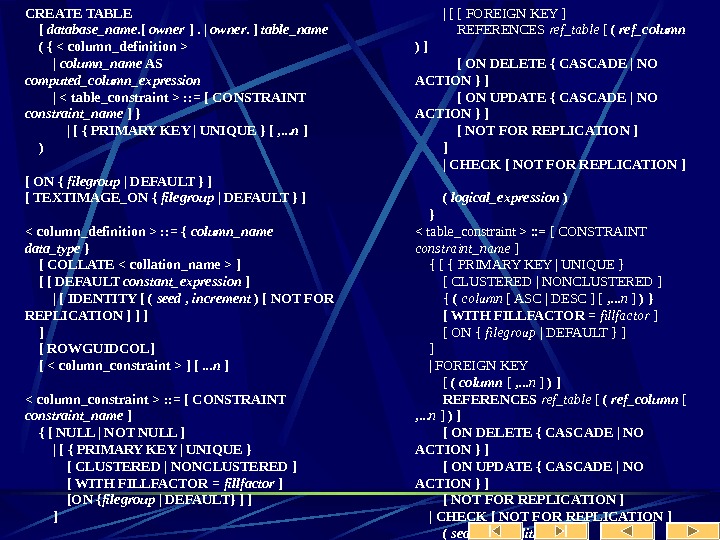
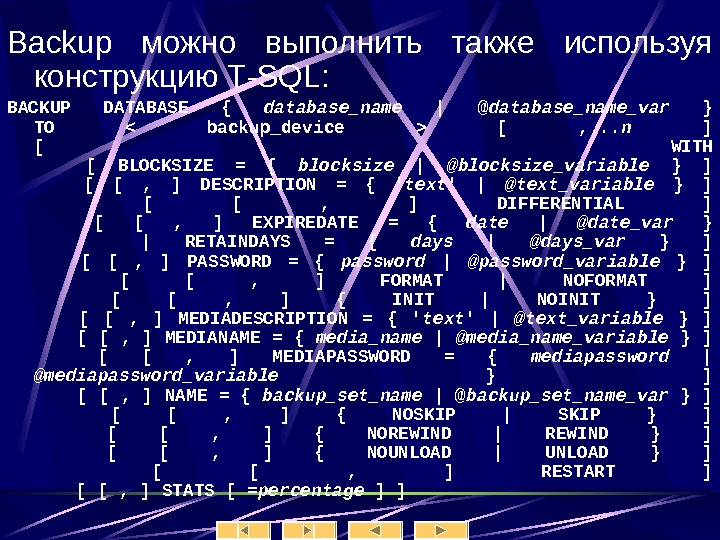
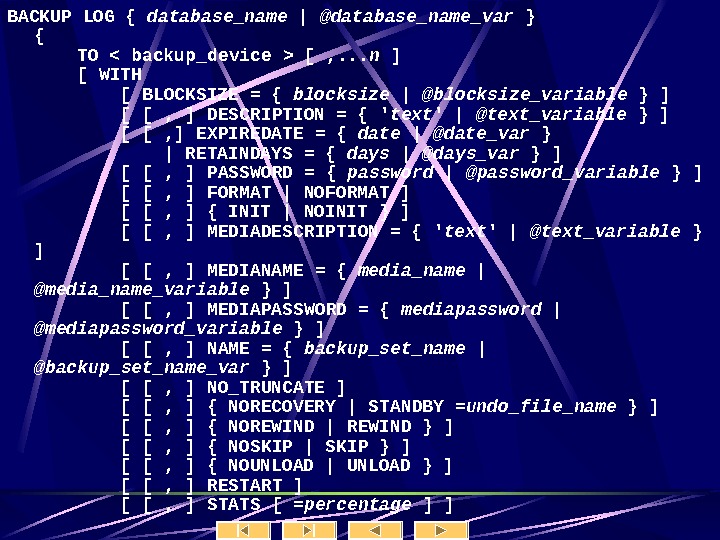
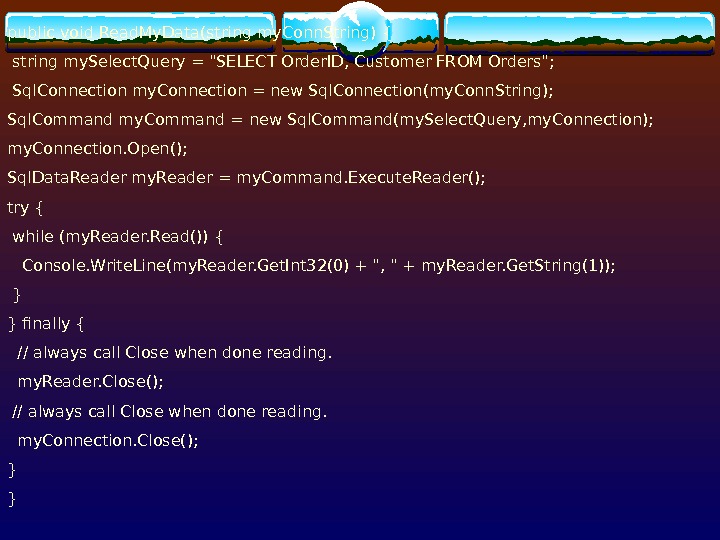
Синтаксис Create Table CREATE TABLE [ database_name. [ owner ] . | owner. ] table_name ( { | column_name AS computed_column_expression |