Базы данных. Тема 1.ppt
- Количество слайдов: 72



Управление данными Часть 1. Базы данных Тема 1. Введение в БД. Основы теории реляционных БД д. т. н. , профессор НИУ ВШЭ Акопов А. С. 1

Литература по курсу БД Диго. С. М. Базы данных. Проектирование и создание Мартин Грабер. SQL. Справочное руководство. 2

Литература по курсу БД Акопов А. С. Учебно-методическое пособие по курсу БД MS Access наиболее полное руководство
 1. БАЗЫ ДАННЫХ 1. 1 Основы теории реляционных")
Структура курса по БД (базам данных) 1. БАЗЫ ДАННЫХ 1. 1 Основы теории реляционных баз данных 1. 2 Проектирование баз данных на основе ER-модели – концептуальное моделирование 1. 3 Проектирование баз данных – логическое и физическое моделирование 1. 4 Обеспечение целостности данных. Введение в язык запросов. 1. 5 1. 7 Язык SQL Роль и функции администратора БД Триггеры и хранимые процедуры 1. 8 Разработка клиентских приложений баз данных под Windows 1. 9 Введение в промышленные базы данных (на примере, My. SQL Server и Oracle) 1. 6 4
 2. 2. 1 2. 4 2. 5 2.")
Структура курса по ХД (хранилищам данных) 2. 2. 1 2. 4 2. 5 2. 6 2. 7 ХРАНИЛИЩА ДАННЫХ Технология хранения данных принятии решений Хранилище данных (Data Warehousing) в виде ненормализованных баз данных Многомерные системы управления базами данных - МСУБД Заполнение хранилища данными Cоздание многомерного хранилища данных (куба) Технология аналитической обработки данных (OLAP) Аналитические возможности Analysis Manager 2. 8 Интеграция Web - технологии и технологии Хранилища 2. 9 Язык MDX (Multidimensional Expressions)- непроцедурный язык для формулирования запросов к многомерным базам данных 2. 2 2. 3 5

Контрольное задание по курсу 1. Разработка проекта домашней БД (например, БД интернет-магазина, БД библиотеки, БД вокзала и т. д. ) в системе MS Access с интерфейсом на VBA (Visual Basic for Application). 2. Разработка прототипа ХД на основе проекта домашней БД в MS SQL Server с разработанным интерфейсом для визуализации KPI (с использованием PHP, ASP, C# и т. д. ). Проект представляется в виде отчета (MS Word) на 20 – 25 стр. с подробным описанием схемы БД (ER-диаграммы), описанием и обоснованием выбора программных средств, листингом программ, описанием разработанных для БД интерфейсов ( «скриншоты» из системы) и Списком Литературы. 6

1. 1. Информационные системы Области использования вычислительной техники: 1. Выполнение численных расчетов 2. Автоматические или автоматизированные информационные системы Информационная система (ИС) это совокупность структурированных данных и комплекса программно-аппаратных средств для хранения данных и манипулирования ими. 7
 системы 8")
Классификация информационных систем Информационно-аналитические системы Аналитические (исторические) системы 8

Классы информационных систем Класс 1. Информационно-поисковые системы – ориентация на поиск данных из общего множества по определенному поисковому критерию. – пользователя интересует в большей степени извлекаемая информация, а технология обработки этих сведений. 9

Классы информационных систем Класс 2. Системы обработки данных – ориентация на обработку данных; – пользователя интересует результат обработки данных, а не сами данные; – вывод информации необязателен; 10
 анализ данных, а")
Классы информационных систем Класс 3. Информационно-аналитические системы – ориентация на (многомерный) анализ данных, а не на их первичную обработку; – пользователя интересует результат анализа (сводные таблицы, графики, KPI); – вывод информации обязателен; 11

Виды информационных систем Вид 1. Фактографические системы – регистрация конкретных значений данных объектов реального мира; – информация имеет четкую структуру (формат); – однозначные ответы на поставленные вопросы 12

Виды информационных систем Вид 2. Документальные системы – совокупность неструктурированных документов (текстовых и графических); – нет однозначных ответов на поставленные вопросы. Результат - список документов или объектов, в какой-то мере удовлетворяющих сформулированным в запросе условиям. 13
")
Виды информационных систем Вид 3. Аналитические системы – совокупность структурированных данных (текстовых и графических) с результатами их аналитики (KPI); – наличие ответов на поставленные вопросы. Результат - список объектов (графики, отчеты, KPI), в полной мере удовлетворяющих информационным потребностям предприятия. 14

Терминология Объект - это нечто существующее и различимое, то есть имеется способ отличить один подобный объект от другого. Данные - это определенные (исходные) показатели, которые характеризуют объект и принимают для конкретного экземпляра этого объекта некоторое значение. KPI это ключевые показатели вычислимые на основе первичных данных

Структура данных Структурирование информации это введение каких-либо соглашений о способах представления данных (установка формата, т. е. определенного типа, длины значений данных). Пример неструктурированных данных: «Табельный номер 1234 Иванович, дата рождения 10 мая 1967 года. Номер по табелю Петрова Сергея Александровича № 8191, д. р. 18. 10. 1972 г. Табель № 3451 Сидорова Алексея Петровича, родившегося 5 июля 1964 года. » Пример структурированных данных: 16

1. 2. Традиционный подход к организации данных. Файлы и файловые системы Файл это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. С точки зрения пользователя файл содержит линейную последовательность записей Стандартные операции: • создать файл (требуемого типа и размера); • открыть ранее созданный файл; • прочитать из файла некоторую запись (текущую, следующую, предыдущую, первую, последнюю); • записать в файл на место текущей записи новую, добавить новую запись в конец файла. 17

Типы файлов Файл последовательного доступа Представляет собой последовательность записей данных в виде строк произвольной длины, разделенных запятыми или специальными символами, обозначающими переход на новую строку. Особенности: – отсутствие возможности упорядочить хранимые записи; – размещение и извлечение записей в такой файл производится построчно в определенной последовательности. Файл произвольного доступа Состоит из записей фиксированной длины, которая указывается при его создании. Особенности: – все записи в упорядочены, каждая имеет свой номер; – возможность быстрого перемещения на любую запись, минуя 18 предыдущие.

Пример традиционного подхода к организации данных ПОЛЬЗОВАТЕЛИ ПРИЛОЖЕНИЯ ФАЙЛЫ ДАННЫХ Гранулометрический состав железорудных материалов Выбор системы загрузки Режимные и конструктивные параметры всех печей цеха Величина подачи Режим загрузки Гранулометрический состав железорудных материалов МАСТЕР ПЕЧИ Управление тепловым режимом Рудная нагрузка Химический состав чугуна Свойства шлака Управление газодинамическим режимом Гранулометрический состав железорудных материалов Режим загрузки 19

Пример традиционного подхода к организации данных ПОЛЬЗОВАТЕЛИ ПРИЛОЖЕНИЯ Учет материалов ФАЙЛЫ ДАННЫХ Состав шихтовых материалов Расход шихтовых материалов ОТДЕЛ СНАБЖЕНИЯ Учет топливноэнергетических ресурсов Расход топливноэнергетических ресурсов Состав топливноэнергетических ресурсов Дутьевые параметры Расчет шихтовых материалов Состав шихтовых материалов Расход шихтовых материалов ТЕХНОЛОГИЧЕ СКАЯ ГРУППА Оптимальное распределение комбинированного дутья между печами цеха Режимные и конструктивные параметры всех печей цеха Расход топливноэнергетических ресурсов по всех печам цеха 20

Недостатки традиционного подхода 1. Избыточность данных 2. Проблемы непротиворечивости данных 3. Ограниченная доступность данных 4. Сложности в организации и управлении 5. Недостаточность средств защиты хранимых данных 6. Низкопроизводительная работа в многопользовательской среде 7. Отсутствие процедур восстановления данных после возникновения отказов; 8. Отсутствие средств манипулирования данными; 9. Высокая стоимость программирования и сопровождения; 10. Негибкость к изменениям и др. 21

1. 3. Организация данных с использованием БД Данные это любая информация об объектах окружающего мира, представленная в формализованном виде, пригодном для ее передачи, хранения и обработки при помощи некоторого процесса с использованием средств вычислительной техники. База данных (БД) это именованная совокупность данных, организованных по определенным правилам, предусматривающим общие принципы описания, хранения и манипулирования данными, не зависимая от прикладных программ. Предметная область это часть реального мира, подлежащего изучению для организации управления и, в конечном счете, автоматизации. 22
 это совокупность языковых и")
Организация данных с использованием БД Система управления базами данных (СУБД) это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями. Банк данных (Бн. Д) это система специальным образом организованных данных – баз данных, программных, технических, языковых, организационнометодических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных. 23

Пример организации баз данных ПОЛЬЗОВАТЕЛИ ПРИЛОЖЕНИЯ ДАННЫЕ Выбор системы загрузки МАСТЕР ПЕЧИ Управление тепловым режимом Управление газодинамическим режимом Учет материалов ОТДЕЛ СНАБЖЕНИЯ Учет топливноэнергетических ресурсов Расчет шихтовых материалов ТЕХНОЛОГИЧЕСКАЯ ГРУППА Оптимальное распределение комбинированного дутья между печами цеха СУБД База данных АБД 24
 Внешний уровень (индивидуальные")
1. 4. Архитектура базы данных, предложенная ANSI (American National Standards Institute) Внешний уровень (индивидуальные представления пользователей) I II III Внешняя модель данных 1 Внешняя модель данных 2 …… Внешняя модель данных N Концептуальный уровень (обобщенное представление пользователей) База данных Внутренний уровень (представление во внешней памяти) 25

1. 5. Компоненты системы баз данных База данных . . . Файлы данных . . . Система управления базой данных (СУБД) Прикладные программы Конечные пользователи 26

Фрагмент организации данных в базе данных Файлы ДОМЕННАЯ ПЕЧЬ ШИХТОПОДАЧА Номер печи Номер подачи Высота Диаметр колошника …. . Записи данных Тип материала …. . 27

Языковые средства СУБД • DDL – Data Definition Language, Язык Определения Данных, ЯОД • DML – Data Management Language, Язык Манипулирования Данными, ЯМД • Язык запросов (SQL, Structured Query Language) 28
, администраторы базы")
Категории пользователей • Конечные пользователи • Прикладные программисты • Администраторы данных (АД), администраторы базы данных (АБД), 29

1. 6. Основные функции группы администратора БД 1. Анализ предметной области. 2. Проектирование структуры БД. 3. Задание ограничений целостности при описании структуры БД и процедур обработки БД. 4. Первоначальная загрузка и ведение БД. 5. Защита данных. 6. Обеспечение восстановления БД. 7. Анализ обращений пользователей БД. 8. Анализ эффективности функционирования БД. 9. Работа с конечными пользователями. 10. Подготовка и поддержание системных средств. 30

1. 7. Преимущества и недостатки современного подхода к организации данных Преимущества 1. Сокращение избыточности данных. 2. Устранение противоречивости данных. 3. Общий доступ к данным. 4. Соблюдение стандартов. 5. Введение ограничений для обеспечения безопасности. 6. Обеспечение целостности данных. 31

Недостатки современного подхода к организации данных 1. Потеря пользователями права единоличного владения данными. 2. Повышение вероятности нарушений защиты данных. 3. Повышенная угроза секретности хранимой информации. 32

Требования к современной СУБД • Эффективное выполнение различных функций предметной области • Минимизация и контроль избыточности хранимых данных • Предоставление для принятия решений непротиворечивой (согласованной) информации • Обеспечение возможности одновременного доступа к базе данных нескольких уполномоченных пользователей • Обеспечение управления безопасностью • Простая физическая реорганизация, т. е. изменение структуры данных в базе данных • Возможность централизованного управления базой данных 33

1. 8. Классификация систем баз данных По характеру использования Однопользовательские системы –- это системы, в которых в одно и то же время к базе данных может получить доступ не более одного пользователя, так называемые базы данных с локальным доступом Многопользовательские системы –- это системы, в которых к базе данных могут получить доступ одновременно несколько пользователей, так называемые базы данных с удаленным (сетевым) доступом 34

Классификация систем баз данных По технологии обработки данных Централизованные системы –- база данных физически хранится в памяти одного компьютера. Распределенная система баз данных –- состоит из нескольких, возможно, пересекающихся или даже дублирующих друга частей БД, хранимых в различных компьютерах-серверах, которые в общем случае могут быть удалены географически друг от друга на значительные расстояния, т. е. территориально 35 распределены
 и")
Архитектуры построения централизованных систем Схема обработки информации в БД по принципу файл/сервер (а) и клиент/сервер (б) 36

Фрагмент архитектуры построения распределенных систем Полная распределенная система обработки БД 37

Реляционная модель данных. Связи в РБД. В реляционной модели данных информация хранится в одной или нескольких связанных таблицах. Отдельная таблица (отношение) обычно представляет совокупность (группу) либо реальных объектов, либо некоторых абстрактных концепций, либо событий одного типа. Каждая запись в таблице идентифицирует один объект группы. Таблица состоит из строк и столбцов, называемых соответственно записями и полями (кортежами и атрибутами).

Таблицы обладают следующими свойствами: 1. Каждая ячейка таблицы представляет собой один элемент данных, совокупность значений в одном столбце одной строки недопустима. 2. Все столбцы в таблице однородные. Это означает, что элементы столбца имеют одинаковую природу. Столбцам присвоены имена. 3. В таблице нет двух одинаковых строк. 4. Порядок размещения строк и столбцов в таблице может быть произвольным. В операциях с такой таблицей ее строки и столбцы могут просматриваться в любом порядке безотносительно к их информационному содержанию и смыслу.
. Но")
Таблицы, обладающие такими свойствами, являются точным прообразом математического двухмерного множества - отношения (relation). Но эти два понятия не эквивалентны. Отношение - это абстрактный математический объект, а таблица - конкретное изображение этого абстрактного объекта. Различие проявляется в их свойствах. В отношении строки и столбцы не могут быть упорядочены, а в таблице строки упорядочены сверху вниз, столбцы - слева направо. В таблице могут повторяться строки, а в отношении - нет. В реляционной модели каждая строка таблиц уникальна. Это обеспечивается применением ключей, которые содержат одно или несколько полей таблицы, Ключи хранятся в упорядоченном виде, обеспечивающем прямой доступ к записям таблицы во время поиска. Связь между таблицами осуществляется посредством значений одного или нескольких совпадающих полей (преимущественно ключевых).

Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение. Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как "деньги"), а также специальных "темпоральных" данных (дата, время, временной интервал). Достаточно активно развивается подход к расширению возможностей реляционных систем абстрактными типами данных (соответствующими возможностями обладают, например, системы семейства Ingres/Postgres). В нашем примере мы имеем дело с данными трех типов: строки символов, целые числа и "деньги".

Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с подтипами в некоторых языках программирования. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат "истина", то элемент данных является элементом домена. Наиболее правильной интуитивной трактовкой понятия домена является понимание домена как допустимого потенциального множества значений данного типа. Например, домен "Имена" в нашем примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать имя (в частности, такие строки не могут начинаться с мягкого знака). Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. Например, значения доменов "Номера пропусков" и "Номера групп" относятся к типу целых чисел, но не являются сравнимыми. Заметим, что в большинстве реляционных СУБД понятие домена не используется, хотя в Oracle оно уже поддерживается.

Атрибут - это свойство, характеризующее объект. В структуре таблицы каждый атрибут именуется и ему соответствует заголовок некоторого столбца таблицы. Количество атрибутов называется степенью отношения. Схема отношения - это именованное множество пар {имя атрибута, имя домена (или типа, если понятие домена не поддерживается)}. Степень или "арность" схемы отношения - мощность этого множества. Если все атрибуты одного отношения определены на разных доменах, осмысленно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это является всего лишь удобным способом именования и не устраняет различия между понятиями домена и атрибута). Схема БД (в структурном смысле) - это набор именованных схем отношений.
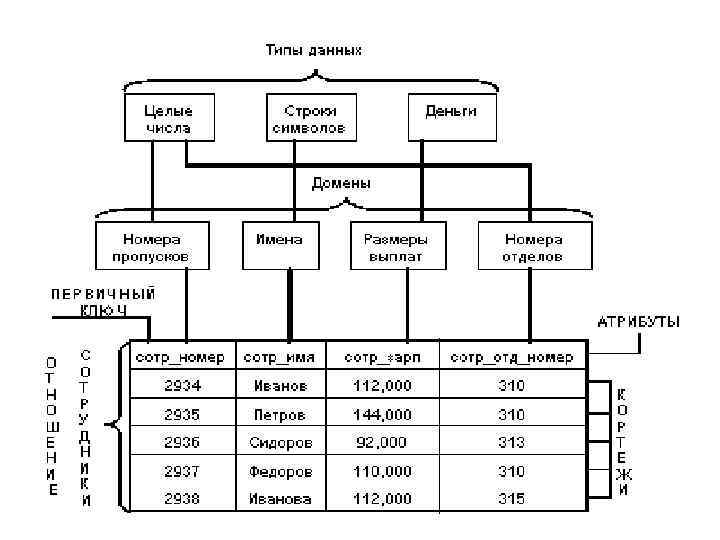

Кортеж, соответствующий данной схеме отношения, - это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. "Значение" является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым, степень или "арность" кортежа, т. е. число элементов в нем, совпадает с "арностью" соответствующей схемы отношения. Попросту говоря, кортеж это набор именованных значений заданного типа. Отношение - это множество кортежей, соответствующих одной схеме отношения. Иногда, чтобы не путаться, говорят "отношение-схема" и "отношение-экземпляр", иногда схему отношения называют заголовком отношения, а отношение как набор кортежей - телом отношения. На самом деле, понятие схемы отношения ближе всего к понятию структурного типа данных в языках программирования. Было бы вполне логично разрешать отдельно определять схему отношения, а затем одно или несколько отношений с данной схемой.

Однако в реляционных базах данных это не принято. Имя схемы отношения в таких базах данных всегда совпадает с именем соответствующего отношения-экземпляра. В классических реляционных базах данных после определения схемы базы данных изменяются только отношения-экземпляры. В них могут появляться новые и удаляться или модифицироваться существующие кортежи. Однако во многих реализациях допускается и изменение схемы базы данных: определение новых и изменение существующих схем отношения. Это принято называть эволюцией схемы базы данных. Обычным житейским представлением отношения является таблица, заголовком которой является схема отношения, а строками - кортежи отношения-экземпляра; в этом случае имена атрибутов именуют столбцы этой таблицы. Поэтому иногда говорят "столбец таблицы", имея в виду "атрибут отношения". Когда мы перейдем к рассмотрению практических вопросов организации реляционных баз данных и средств управления, мы будем учитывать эту житейскую терминологию. Этой терминологии придерживаются в большинстве коммерческих реляционных СУБД.

Реляционная база данных - это набор отношений, имена которых совпадают с именами схем отношений в схеме БД. Как видно, основные структурные понятия реляционной модели данных (если не считать понятия домена) имеют очень простую интуитивную интерпретацию, хотя в теории реляционных БД все они определяются абсолютно формально и точно. Фундаментальные свойства отношений: -Отсутствие кортежей-дубликатов -Отсутствие упорядоченности кортежей -Отсутствие упорядоченности атрибутов -Атомарность значений атрибутов

Отсутствие кортежей-дубликатов То свойство, что отношения не содержат кортежей-дубликатов, следует из определения отношения как множества кортежей. В классической теории множеств по определению каждое множество состоит из различных элементов. Из этого свойства вытекает наличие у каждого отношения так называемого первичного ключа - набора атрибутов, значения которых однозначно определяют кортеж отношения. Для каждого отношения по крайней мере полный набор его атрибутов обладает этим свойством. Однако при формальном определении первичного ключа требуется обеспечение его "минимальности", т. е. в набор атрибутов первичного ключа не должны входить такие атрибуты, которые можно отбросить без ущерба для основного свойства - однозначно определять кортеж. Понятие первичного ключа является исключительно важным в связи с понятием целостности баз данных. Забегая вперед, заметим, что во многих практических реализациях РСУБД допускается нарушение свойства уникальности кортежей для промежуточных отношений, порождаемых неявно при выполнении запросов. Такие отношения являются не множествами, а мультимножествами, что в ряде случаев позволяет добиться определенных преимуществ, но иногда приводит к серьезным проблемам.

Отсутствие упорядоченности кортежей Свойство отсутствия упорядоченности кортежей отношения также является следствием определения отношения-экземпляра как множества кортежей. Отсутствие требования к поддержанию порядка на множестве кортежей отношения дает дополнительную гибкость СУБД при хранении баз данных во внешней памяти и при выполнении запросов к базе данных. Это не противоречит тому, что при формулировании запроса к БД, например, на языке SQL можно потребовать сортировки результирующей таблицы в соответствии со значениями некоторых столбцов. Такой результат, вообще говоря, не отношение, а некоторый упорядоченный список кортежей.

Отсутствие упорядоченности атрибутов Атрибуты отношений не упорядочены, поскольку по определению схема отношения есть множество пар {имя атрибута, имя домена}. Для ссылки на значение атрибута в кортеже отношения всегда используется имя атрибута. Это свойство теоретически позволяет, например, модифицировать схемы существующих отношений не только путем добавления новых атрибутов, но и путем удаления существующих атрибутов. Однако в большинстве существующих систем такая возможность не допускается, и хотя упорядоченность набора атрибутов отношения явно не требуется, часто в качестве неявного порядка атрибутов используется их порядок в линейной форме определения схемы отношения.

Атомарность значений атрибутов Значения всех атрибутов являются атомарными. Это следует из определения домена как потенциального множества значений простого типа данных, т. е. среди значений домена не могут содержаться множества значений (отношения). Принято говорить, что в реляционных базах данных допускаются только нормализованные отношения или отношения, представленные в первой нормальной форме. Ненормализованное отношение ОТДЕЛЫ.

Заметим, что отношение СОТРУДНИКИ является нормализованным вариантом отношения ОТДЕЛЫ: СОТР_НОМЕР СОТР_ИМЯ СОТР_ЗАРП СОТР_ОТД_НОМЕР 2934 Иванов 112, 000 310 2935 Петров 144, 000 310 2936 Сидоров 92, 000 313 2937 Федоров 110, 000 310 2938 Иванова 112, 000 315 Нормализованные отношения составляют основу классического реляционного подхода к организации баз данных. Они обладают некоторыми ограничениями (не любую информацию удобно представлять в виде плоских таблиц), но существенно упрощают манипулирование данными.

Рассмотрим, например, два идентичных оператора занесения кортежа: Зачислить сотрудника Кузнецова (пропуск номер 3000, зарплата 115, 000) в отдел номер 320 и Зачислить сотрудника Кузнецова (пропуск номер 3000, зарплата 115, 000) в отдел номер 310. Если информация о сотрудниках представлена в виде отношения СОТРУДНИКИ, оба оператора будут выполняться одинаково (вставить кортеж в отношение СОТРУДНИКИ). Если же работать с ненормализованным отношением ОТДЕЛЫ, то первый оператор выразится в занесение кортежа, а второй - в добавление информации о Кузнецове в множественное значение атрибута ОТДЕЛ кортежа с первичным ключом 310. Отношение ОТДЕЛЫ Отношение СОТРУДНИКИ СОТР_НО МЕР СОТР_ИМЯ СОТР_ЗАРП СОТР_ОТД_Н ОМЕР 2934 Иванов 112, 000 310 2935 Петров 144, 000 310 2936 Сидоров 92, 000 313 2937 Федоров 110, 000 310 2938 Иванова 112, 000 315

Наиболее распространенная трактовка реляционной модели данных, по-видимому, принадлежит Дейту, который воспроизводит ее (с различными уточнениями) практически во всех своих книгах. Согласно Дейту, реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части. В структурной части модели фиксируется, что единственной структурой данных, используемой в реляционных БД, является нормализованное nарное отношение. (E. F. Codd) Кодд разработал язык манипулирования данными, представленными в виде отношений. Он предложил два эквивалентных по своим выразительным возможностям варианта языка манипулирования данными: реляционная алгебра и реляционное исчисление.

1. Реляционная алгебра. Это процедурный язык, так как отношение, являющееся результатом запроса к реляционной БД, вычисляется при выполнении последовательности реляционных операторов, применяемых к отношениям. Операторы состоят из операндов, в роли которых выступают отношения и реляционные операции. Результатом реляционной операции является отношение. Операции можно разделить на две группы. Первую группу составляют операции над множествами, к которым относятся операции объединения, пересечения, разности, деления и декартова произведения. Вторую группу составляют специальные операции над отношениями: проекция, выборка и соединение.

Введение в БАЗЫ ДАННЫХ Операции над множествами Основными операциями над множествами являются объединение, пересечение и разность. Определение 1. Объединением двух множеств называется новое множество Определение 2. Пересечением двух множеств называется новое множество Определение 3. Разностью двух множеств называется новое множество Если класс объектов, на которых определяются различные множества обозначить , то дополнением множества A называют разность

2. Реляционное исчисление. Это непроцедурный язык описательного или декларативного характера, содержащий лишь информацию о желаемом результате. Процесс получения этого результата скрыт от пользователя. К языкам такого типа относятся SQL и QBE. Первый основан на реляционном исчислении кортежей, второй - на реляционном исчислении доменов. С помощью этих языков можно извлекать подмножество столбцов и строк таблицы, создавая таблицы меньшей размерности, а также объединять связанные данные из нескольких таблиц, создавая при этом таблицы большей размерности. Результат каждой (реляционной) операции над отношениями также является отношением. Это реляционное свойство получило название свойства замкнутости. Следовательно, различные пользователи могут выделять в реляционной БД различные наборы данных и связей между ними. Этот способ представления данных наиболее удобен для конечного пользователя. Реляционная модель данных очень гибкая, поскольку любое представление данных с некоторой избыточностью можно свести к двухмерным таблицам.

Целостность сущности и ссылок Наконец, в целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД : требования целостности сущностей и целостности по ссылкам. Первое требование – целостности сущностей. Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений. Конкретно требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т. е. другими словами, любое отношение должно обладать первичным ключом. Как мы видели в предыдущем разделе, это требование автоматически удовлетворяется, если в системе не нарушаются базовые свойства отношений.

Второе требование - целостности по ссылкам, является несколько более сложным. Очевидно, что при соблюдении нормализованности отношений сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений. Например, представим, что нам требуется представить в реляционной базе данных сущность ОТДЕЛ с атрибутами ОТД_НОМЕР (номер отдела), ОТД_КОЛ (количество сотрудников) и ОТД_СОТР (набор сотрудников отдела). Для каждого сотрудника нужно хранить СОТР_НОМЕР (номер сотрудника), СОТР_ИМЯ (имя сотрудника) и СОТР_ЗАРП (заработная плата сотрудника). Как мы вскоре увидим, при правильном проектировании соответствующей БД в ней появятся два отношения: ОТДЕЛЫ ( ОТД_НОМЕР, ОТД_КОЛ ) (первичный ключ - ОТД_НОМЕР) и СОТРУДНИКИ ( СОТР_НОМЕР, СОТР_ИМЯ, СОТР_ЗАРП, СОТР_ОТД_НОМ ) (первичный ключ - СОТР_НОМЕР).

Как видно, атрибут СОТР_ОТД_НОМ появляется в отношении СОТРУДНИКИ не потому, что номер отдела является собственным свойством сотрудника, а лишь для того, чтобы иметь возможность восстановить при необходимости полную сущность ОТДЕЛ (произведя выборку по всем совпадающим значениям атрибута). Значение атрибута СОТР_ОТД_НОМ в любом кортеже отношения СОТРУДНИКИ должно соответствовать значению атрибута ОТД_НОМ в некотором кортеже отношения ОТДЕЛЫ. Атрибут такого рода называется внешним ключом, поскольку его значения однозначно характеризуют сущности, представленные кортежами некоторого другого отношения (т. е. задают значения их первичного ключа). Говорят, что отношение, в котором определен внешний ключ, ссылается на соответствующее отношение, в котором такой же атрибут является первичным ключом. Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т. е. ни на что не указывать). Для нашего примера это означает, что если для сотрудника указан номер отдела, то этот отдел должен существовать.

Ограничения целостности сущности и по ссылкам должны поддерживаться СУБД. Для соблюдения целостности сущности достаточно гарантировать отсутствие в любом отношении кортежей с одним и тем же значением первичного ключа. С целостностью по ссылкам дела обстоят несколько более сложно. Понятно, что при обновлении ссылающегося отношения (вставке новых кортежей или модификации значения внешнего ключа в существующих кортежах) достаточно следить за тем, чтобы не появлялись некорректные значения внешнего ключа. Но как быть при удалении кортежа из отношения, на которое ведет ссылка? Здесь существуют три подхода, каждый из которых поддерживает целостность по ссылкам.

Первый подход заключается в том, что запрещается производить удаление кортежа, на который существуют ссылки (т. е. сначала нужно либо удалить ссылающиеся кортежи, либо соответствующим образом изменить значения их внешнего ключа). При втором подходе при удалении кортежа, на который имеются ссылки, во всех ссылающихся кортежах значение внешнего ключа автоматически становится неопределенным. Наконец, третий подход (каскадное удаление) состоит в том, что при удалении кортежа из отношения, на которое ведет ссылка, из ссылающегося отношения автоматически удаляются все ссылающиеся кортежи. В развитых реляционных СУБД обычно можно выбрать способ поддержания целостности по ссылкам для каждой отдельной ситуации определения внешнего ключа. Конечно, для принятия такого решения необходимо анализировать требования конкретной прикладной области.

Кроме ссылочной целостности, можно сформулировать еще три ограничителя целостности для реляционной БД: • ограничители домена (domain constraints), запрещающие ввод значений трибутов, не принадлежащих домену. К ним можно отнести также все ограничители значений (тип, формат, задание списка и диапазона значении); • ограничители ключей (key constraints), обеспечивающие уникальность значений потенциальных ключей (обеспечивается применением уникальных индексов); • ограничители записи (entity constraints), запрещающие NULL значения для первичных ключей, так как в противном случае будет нарушено требование идентифицируемости записи.

Отношение между объектами определяет тип связи между таблицами. Поддерживаются связи четырех типов: «один к одному» , «один ко многим» , «многие к одному» и «многие ко многим» . Рассмотрим подробнее типы связей в применении к реляционной модели данных. «Один к одному» . Связь «один к одному» означает, кто каждой записи из первой таблицы соответствует одна и только одна запись из другой таблицы. Рассмотрим таблицы, содержащие персональные и служебные сведения о работниках некоторой фирмы. Между таблицами «Персональные сведения» и «Служебные сведения» существует связь «один к одному» , поскольку для одного человека, работающего в определенной фирме, может существовать только одна запись о служебном положении. Табельные номера «Код_пс» и «Код_сс» служат для однозначной идентификации записей. Эти же поля и приняты в качестве первичных ключей. Связь между этими таблицами поддерживаются при помощи совпадающих значений полей. Легко убедиться, что между двумя ключевыми полями может существовать только связь «один к одному» , поскольку любые дублирования одного и того же табельного номера исключены с обеих сторон.

Служебные сведения Место работы Должность Персональные сведения Разряд Код ее Паспорт Фамилия Имя 1 АВ 2358955 Сидоров Сергей 2 ВВ 2456886 Петров Петр 3 МА 8654212 Иванов Иван Код пс 1 Бухгалтерия Бухгалтер 3 2 Цех № 2 Токарь 7 3 Лаборатория Начальник отдела

«Один ко многим» и «многие к одному» . Связь «один ко многим» означает, что каждой записи из первой таблицы может соответствовать одна либо много записей из другой таблицы. Связи «один ко многим» и «многие к одному» являются обратимыми, поэтому подробнее остановимся на связи «один ко многим» . Рассмотрим таблицы, содержащие сведения о клиентах некоторой фирмы и сделанных ими заказах. Предполагается что один и тот же клиент может сделать несколько заказов. Для установления связи необходимо в таблицу «Заказы» ввести поле «Код_клиента» , которое будет являться для данной таблицы внешним ключом. Связь между таблицами будет осуществляться на основании значений полей «Клиенты. Код_клиента» и «Заказы. Код_клиента» . Причем подчеркнем, что связь устанавливается на основе значений совпадающих полей, а не их наименований. Таким образом, если связь устанавливается между ключевым полем одной таблицы и неключевым полем второй таблицы, то это будет связь типа «один ко многим» .
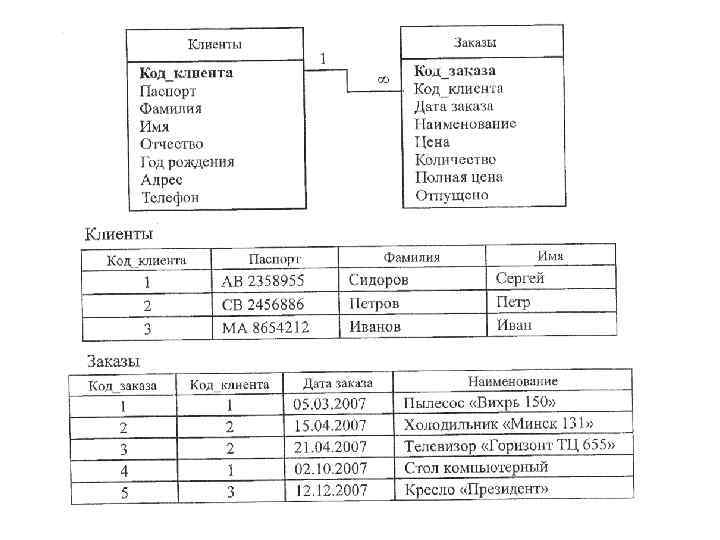

«Многие ко многим» . Связь «многие ко многим» возникает между двумя таблицами в тех случаях, когда каждой записи из первой таблицы может соответствовать одна либо много записей из второй таблицы и, наоборот, одной записи из второй таблицы может соответствовать одна либо много записей из первой таблицы. Типичным примером является связь между клиентами некой фирмы и покупаемыми ими товарами. Каждый товар может быть куплен несколькими клиентами и, наоборот, один клиент может купить несколько товаров. Такая связь может быть реализована с помощью дополнительной таблицы, содержащей ключевые поля обеих таблиц, участвующих в связи (являющимися для нее внешними ключами).
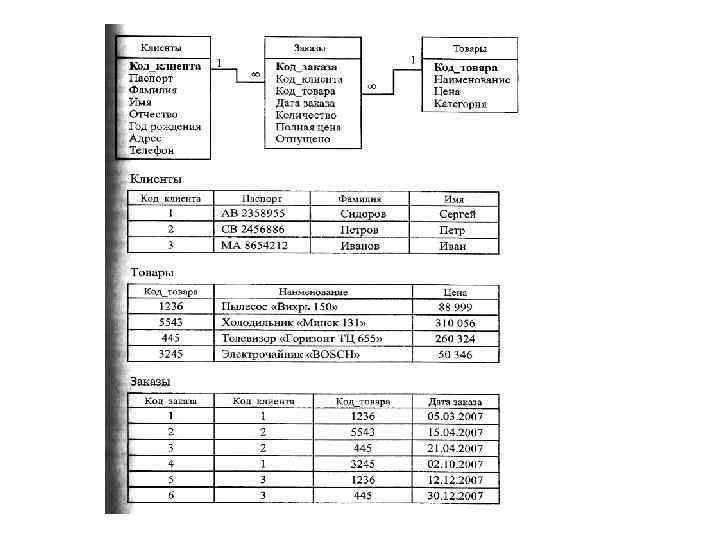

Связь «многие ко многим» также автоматически возникает между таблицами, связанными посредством неключевых полей. Пусть первая таблица содержит информацию о том, на каких станках могут работать рабочие некоторой бригады. Вторая таблица содержит сведения о том, кто из бригады ремонтников какие станки обслуживает. Такой вид связи «многие ко многим» характеризуется как слабый вид связи или даже как ее отсутствие, поскольку никакого контроля за целостностью данных в этом случае не осуществляется.

Информация, размещенная в связанных таблицах, может быть легко объединена с помощью естественного соединения (по значениям внешних ключей). Кроме вышеупомянутых связей, в реляционной модели возможны также рекурсивные связи. Предположим, мы должны хранить информацию о сотрудниках некоторой компании с указанием отношений подчиненности между отдельными сотрудниками. Поскольку один экземпляр объекта «Сотрудники» ссылается на другой экземпляр того же объекта, который в свою очередь может ссылаться на третий экземпляр, то связь будет унарной и рекурсивной. Данная связь легко реализуется путем введения внешнего ключа, ссылающегося на первичный ключ той же таблицы.

Спасибо за внимание
Базы данных. Тема 1.ppt