

b9c9817c17a59f953216c408b162f60c.ppt
- Количество слайдов: 24
 Transcription methods for consistency, volume and efficiency Meghan Lammie Glenn, Stephanie M. Strassel, Haejoong Lee, Kazuaki Maeda, Ramez Zakhary, Xuansong Li
Transcription methods for consistency, volume and efficiency Meghan Lammie Glenn, Stephanie M. Strassel, Haejoong Lee, Kazuaki Maeda, Ramez Zakhary, Xuansong Li
 Outline u Introduction u Manual transcription overview l u Approaches, genres, languages Inter-transcriber consistency analysis l l u Results Discussion Conclusions and future work
Outline u Introduction u Manual transcription overview l u Approaches, genres, languages Inter-transcriber consistency analysis l l u Results Discussion Conclusions and future work
 Introduction u u u Linguistic Data Consortium supports language-related education, research and technology development Programs that call for manual transcription include DARPA GALE, Phanotics, and NIST LRE, SRE, and RT Transcription is a core component of many HLT research tasks, such as machine translation Manual transcription efforts have been undertaken many languages, such as Chinese, English, Modern Standard Arabic, Arabic dialects, Pashto, Urdu, Farsi, Korean, Thai, Russian, and Spanish LDC makes recommendations about transcription approaches for individual projects by balancing efficiency, cost, program needs to make such recommendations l u Evaluation vs. training data? Genre? Timeline? Current consistency study is informative for transcription teams l Could be used to establish baseline human performance for each task
Introduction u u u Linguistic Data Consortium supports language-related education, research and technology development Programs that call for manual transcription include DARPA GALE, Phanotics, and NIST LRE, SRE, and RT Transcription is a core component of many HLT research tasks, such as machine translation Manual transcription efforts have been undertaken many languages, such as Chinese, English, Modern Standard Arabic, Arabic dialects, Pashto, Urdu, Farsi, Korean, Thai, Russian, and Spanish LDC makes recommendations about transcription approaches for individual projects by balancing efficiency, cost, program needs to make such recommendations l u Evaluation vs. training data? Genre? Timeline? Current consistency study is informative for transcription teams l Could be used to establish baseline human performance for each task
 Transcription spectrum overview u All manual transcripts share the same core elements l l Speaker identification l Transcript l u Time alignment at some level of granularity Created in XTrans, LDC’s in-house transcription tool Transcription methodologies target a range of data needs: l Small volumes (2 hours) vs. large volumes (thousands of hours) l Quick content transcript vs. meticulous transcription of all speaker utterances or noises l Auto time alignment vs. manual word- or phoneme-level alignment
Transcription spectrum overview u All manual transcripts share the same core elements l l Speaker identification l Transcript l u Time alignment at some level of granularity Created in XTrans, LDC’s in-house transcription tool Transcription methodologies target a range of data needs: l Small volumes (2 hours) vs. large volumes (thousands of hours) l Quick content transcript vs. meticulous transcription of all speaker utterances or noises l Auto time alignment vs. manual word- or phoneme-level alignment
 Quick transcription
Quick transcription
 QTR example
QTR example
 Quick-rich transcription
Quick-rich transcription
 QRTR example
QRTR example
 Careful transcription
Careful transcription
 CTR example
CTR example
 Comparison of methods
Comparison of methods
 Transcription consistency studies u Design overview l l Identical time-alignment l Scored with NIST’s SCLITE toolkit (Fiscus, 2006) l u Pair-wise comparison of independent dual transcripts For English subset, differences adjudicated with in-house adjudication tool Background study: EARS RT 03 l English broadcast news (BN) and conversational telephone speech (CTS) l Careful transcription approach l All discrepancies adjudicated
Transcription consistency studies u Design overview l l Identical time-alignment l Scored with NIST’s SCLITE toolkit (Fiscus, 2006) l u Pair-wise comparison of independent dual transcripts For English subset, differences adjudicated with in-house adjudication tool Background study: EARS RT 03 l English broadcast news (BN) and conversational telephone speech (CTS) l Careful transcription approach l All discrepancies adjudicated
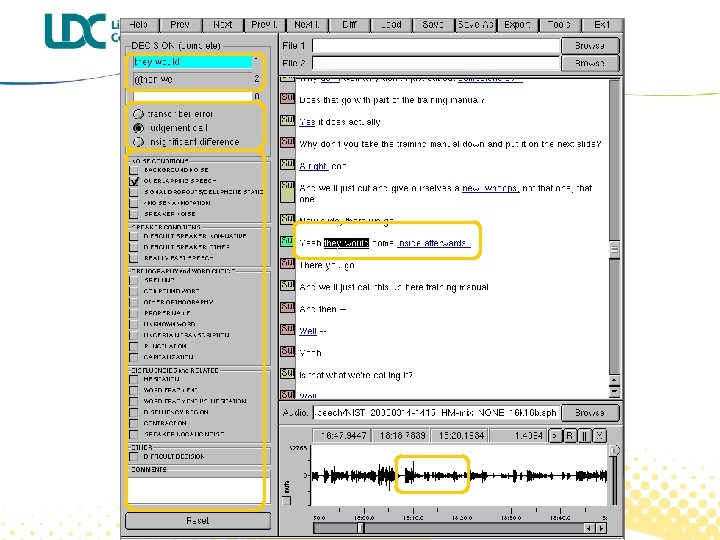
 Results of RT 03 study u Error expressed in terms of “Word Disagreement Rate”, though derived from Word Error Rate l Not all transcription “errors” are truly mistakes, so “disagreement” is a more accurate term. (Strassel, 2004)
Results of RT 03 study u Error expressed in terms of “Word Disagreement Rate”, though derived from Word Error Rate l Not all transcription “errors” are truly mistakes, so “disagreement” is a more accurate term. (Strassel, 2004)
 Overview of current study
Overview of current study
 Current consistency study u Basic assumptions l l u Same as previous For the purposes of the current study, LDC ignored stylistic differences such as capitalization or punctuation Subset of English transcripts further analyzed using LDC’s in-house adjudication tool. l Approximately n 65% of the differences across all the English quick transcripts were labeled insignificant differences n 20% were labeled judgment calls n 15% were labeled transcriber errors
Current consistency study u Basic assumptions l l u Same as previous For the purposes of the current study, LDC ignored stylistic differences such as capitalization or punctuation Subset of English transcripts further analyzed using LDC’s in-house adjudication tool. l Approximately n 65% of the differences across all the English quick transcripts were labeled insignificant differences n 20% were labeled judgment calls n 15% were labeled transcriber errors
 Results of 2010 study
Results of 2010 study
 Results of 2010 study
Results of 2010 study
 Genre effect u Spontaneous, conversational genres are worse overall than broadcast news l BN is often very scripted n u Unplanned speech is hard! l l l u Limited overlapping speech Overlapping speech or cross-talk Background noise Fast speech More regions of disfluency Dialect or accent Meeting, interview and telephone domains also add l l Jargon about specific topics Challenging acoustic conditions
Genre effect u Spontaneous, conversational genres are worse overall than broadcast news l BN is often very scripted n u Unplanned speech is hard! l l l u Limited overlapping speech Overlapping speech or cross-talk Background noise Fast speech More regions of disfluency Dialect or accent Meeting, interview and telephone domains also add l l Jargon about specific topics Challenging acoustic conditions
 Conversational style
Conversational style
 Disfluencies u Regions of disfluency are by far the most prevalent contributors to transcriber disagreement l Hesitation sounds l Stammering l Restarts
Disfluencies u Regions of disfluency are by far the most prevalent contributors to transcriber disagreement l Hesitation sounds l Stammering l Restarts
 Dialect poses a") Dialect u u Arabic transcription typically targets Modern Standard Arabic (MSA) Dialect poses a particular challenge in transcribing Arabic conversations l l Real data contains significant volumes of dialectal Arabic, especially in the broadcast conversation domain Transcribers may differ in their rendering of non-MSA regions n n In the following examples, Non-MSA regions are underlined. Discrepancies are highlighted
Dialect u u Arabic transcription typically targets Modern Standard Arabic (MSA) Dialect poses a particular challenge in transcribing Arabic conversations l l Real data contains significant volumes of dialectal Arabic, especially in the broadcast conversation domain Transcribers may differ in their rendering of non-MSA regions n n In the following examples, Non-MSA regions are underlined. Discrepancies are highlighted
 Conclusions and future work u Cross-language, cross-genre inter-annotator analysis showed agreement in the 90 -100% range l l u u u Agreement is strongly conditioned by genre and language When choosing a transcription approach for a project, LDC must balance efficiency, consistency, and cost More investigation into what’s going on with Chinese is necessary l l u Transcripts for planned speech are generally more consistent than those for spontaneous speech Careful transcription methods result in higher rates of agreement than quick transcription methods Future study on larger datasets Examination of selection sample The data discussed here ultimately will be compiled into one corpus and distributed to via the LDC catalog
Conclusions and future work u Cross-language, cross-genre inter-annotator analysis showed agreement in the 90 -100% range l l u u u Agreement is strongly conditioned by genre and language When choosing a transcription approach for a project, LDC must balance efficiency, consistency, and cost More investigation into what’s going on with Chinese is necessary l l u Transcripts for planned speech are generally more consistent than those for spontaneous speech Careful transcription methods result in higher rates of agreement than quick transcription methods Future study on larger datasets Examination of selection sample The data discussed here ultimately will be compiled into one corpus and distributed to via the LDC catalog
 Acknowledgments u u u Many thanks to the LDC transcription team for their hard work and analysis for the 2010 consistency study Thanks to Jonathan Fiscus for his guidance in running SCLITE This work was supported in part by the Defense Advanced Research Projects Agency, GALE Program Grant No. HR 0011 -06 -1 -0003. The content of this paper does not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.
Acknowledgments u u u Many thanks to the LDC transcription team for their hard work and analysis for the 2010 consistency study Thanks to Jonathan Fiscus for his guidance in running SCLITE This work was supported in part by the Defense Advanced Research Projects Agency, GALE Program Grant No. HR 0011 -06 -1 -0003. The content of this paper does not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.