e5746ed0888e452e4fd5743f43d6dd95.ppt
- Количество слайдов: 28



ТЕОРИЯ ПОДОБИЯ КОНЕЧНЫХ ПОСЛЕДОВАТЕЛЬНОСТЕЙ В ЗАДАЧАХ ИДЕНТИФИКАЦИИ СООБЩЕНИЙ Н. В. Северин n_severin@ukr. net

Пути выхода на сайты, содержащие запрещенный, аморальный или травмирующий психику контент • ввод URL в строке браузера • переход по баннеру (реклама) • переход по результату запроса в поисковой системе

Безопасный поисковый сервис • http: //www. google. ru/preferences - настройка уровня фильтрации непристойного текста • http: //yandex. ua/familysearch - семейный поиск • http: //search. icensor. ru/ - интернет ЦЕНЗОР (безопасная поисковая система) • другие поисковые системы

Надежность безопасных поисковых систем: СЕКС или СЕКИС ? ? ?
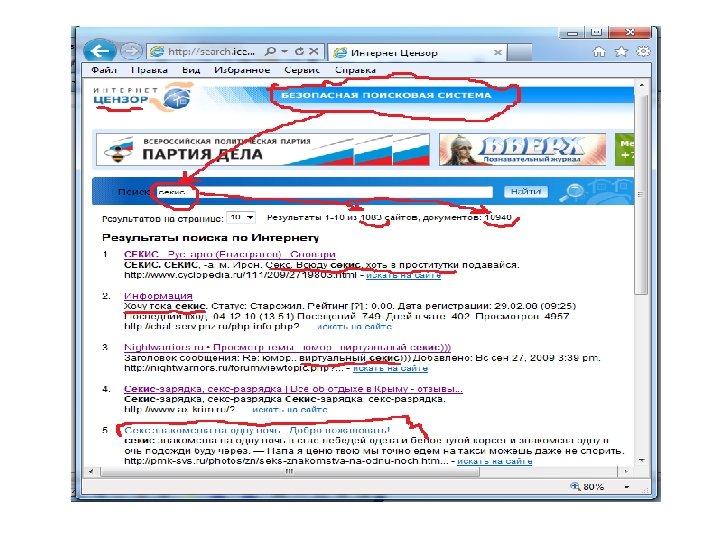

NO COMMENTS:

СЕКИС – мнение интернет-сообщества

порнозвезда или опрнозвезда ? ? ?
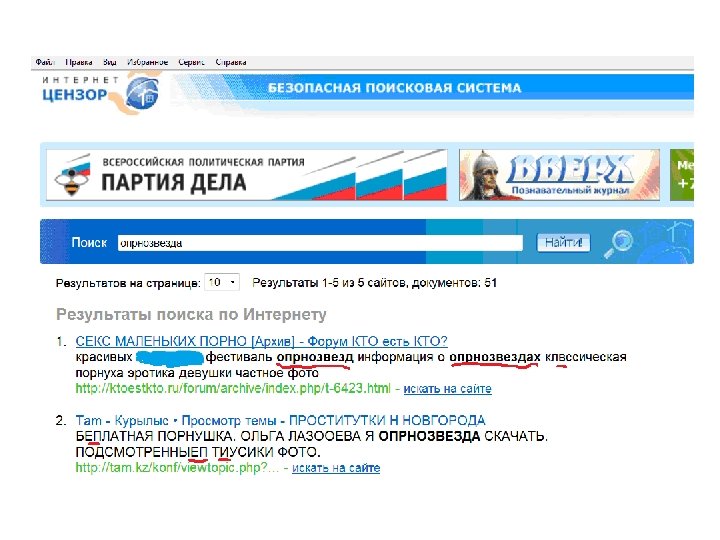
; • пропуск символа(ов);")
Типы ошибок, допускаемых при «ручном» наборе • искажения символа (нескольких символов); • пропуск символа(ов); • вставка «лишнего» символа(ов); • перестановки нескольких (часто – рядом стоящих) символов.
 Пусть M 0 – нулевой уровень представляющий")
Краткий обзор теории подобия конечных последовательностей (ТПКП) Пусть M 0 – нулевой уровень представляющий множество букв (например, естественного языка). Тогда объекты 1 -го уровня – это слова этого языка, а объекты 2 го уровня – его предложения. Два виды подобий для объектов a и b принадлежащих одному уровню (например, 1 -му): 1) подобие в широком смысле (Fw): объекты a и b подобны, если число их подобных суб-объектов достаточно велико; 2) подобие в узком смысле (Fs): a и b подобны, если длиннейшая подпоследовательность их подобных суб-объектов, сохраняющая порядок следования этих суб-объектов в составе как a, так и b, достаточно длинна.

Определение численных мер для каждого из двух видов подобия Если a и b – два объекта одного и того же ненулевого уровня, то Fw(a, b) = dw(a, b)/max(|a|, |b|) Fs(a, b) = ds(a, b)/max(|a|, |b|), где dw(a, b)– число сходных суб-объектов у a и b; ds(a, b) – длина длиннейшей подпоследовательности сходных субобъектов в a и b; |a| – длина (число суб-объектов) объекта a. Например, пусть M 0 – множество букв латинского алфавита a = analogy b = analogia c = naalogia – – Fw(a, b) = Fs(a, b) = 6/8 = 0. 75; Fw(a, b) = 0. 75; Fs(a, b) = 5/8=0. 625.

Выбор меры для определения подобия • Узкую меру подобия Fs, разумно применять к Fs объектам 1 -го уровня. Перемешивание символов в слове изменяет его значение • Широкая мера подобия Fw, более приемлема для Fw объектов 2 -го уровня. Так как в большинстве натуральных языков порядок слов в предложении может изменяться без изменения его смысла.

Узкая мера подобия Fs хорошо справляется с задачами в которых следует учитывать: • искажение символа (нескольких символов); • пропуск символа(ов); • вставку «лишнего» символа(ов); • сдвиг и/или перестановку нескольких символов. • (возможность изменения длины слова)
 W* (искаженное слово)")
Оценки близости слов, полученные при использовании узкой меры подобия Fs(W, W*) W* (искаженное слово) W (правильная форма слова) очепятка очепатка потенциаотно опреляться несовдимость тестсе констркцуии опечатка потенциально определяться несводимость тексте конструкции информационно-посиковых информационно-поисковых кажествся мсенно сосбенностей произзюстрируем сосовупность екобходимы довайти взгялов фундаметральной кажется именно особенностей проиллюстрируем совокупность необходимы давайте взглядов фундаментальной Оценка сходства W и W* в ТПКП – Fs(W, W*) Распознавание MS Word ( «+» – есть замена, «–» – нет) 0. 625 0. 750 0. 833 0. 917 0. 833 0. 909 0. 957 0. 778 0. 833 0. 927 0. 867 0. 833 0. 900 0. 714 0. 875 0. 933 – + – – + + (тесте) – – – +(сменно) – – – –

Повышение порога оценки мер подобия Занижение порога может приводить к неоправданной идентификации «близких» слов Решение - повышения порога за счет ввода «взвешенных» мер ТПКП. «Взвешенные» меры – ввод различных весов для суб-объектов из объекта a Вес любого суб-объекта - отражение его «существенности» для объекта a сравнительно с другими суб-объектами из a. изобретение 11111000000 При этом степени аналогичности ( «взвешенного» подобия) будут иметь одно и то же значение 0. 92 как для пары слов {изобретение, изобрели}, так и для {изобретение, изобритение}.
веса слов и (2)“сплоченности” слов в ИГ Вопрос")
Оценка меры подобия предложений с учетом (1)веса слов и (2)“сплоченности” слов в ИГ Вопрос Каково наиболее значительное достижение в области математики конца XVII в. ; и кто его автор? Ответ с расставленными весами (эталон): {Ньютон и Лейбниц} {изобрели} {математический анализ} 25 0 25 10 30 Именные группы (ИГ) выделены фигурными скобками. - Оценка подобия производится с учетом веса слов в предложении - В ожидаемых ответах не учитывается порядок слов внутри именных групп, но чередование слов разных ИГ снижает оценку «подобия» ответа эталону

Оценка системой контроля знаний CONTROL Ньютон и Лейбниц изобрели математический анализ -- положительный ответ -Матем. наализ – это изобритение и Ляйбница, и Невтона. (1. 00) Лейбниц и Ньютон – изобретатели матанализа. (1. 00) Мат. анализ был создан Ньютоном и Лейбницем. (1. 00) Лейбниц, а также Ньютон, открыли анализ. (0. 85) Мат. анализ Ньютон открыл, и Лейбниц. (0. 80) Матанализ, Лейбниц, Ньютон. (0. 95) -- неудовлетворительный -Математика Ньютона открыла Лейбницев анализ. (0. 39) Открыт и Ньютон анализом Лейбница. (0. 65) Ньютон придумал Лейбница и создал анализ. (0. 63) Ньютон открыл математику, Лейбниц – анализ и. (0. 46)

Серверы статистики ключевых запросов • wordstat. yandex. ru • adwords. google. com/select/Keyword. Tool. External • stat. go. mail. ru • adstat. rambler. ru • серверы других поисковых систем
")
Выборочная статистика популярности запросов (http: //wordstat. yandex. ru/)

Спрос и предложения на очепятки
 max(|a|, |b|)")
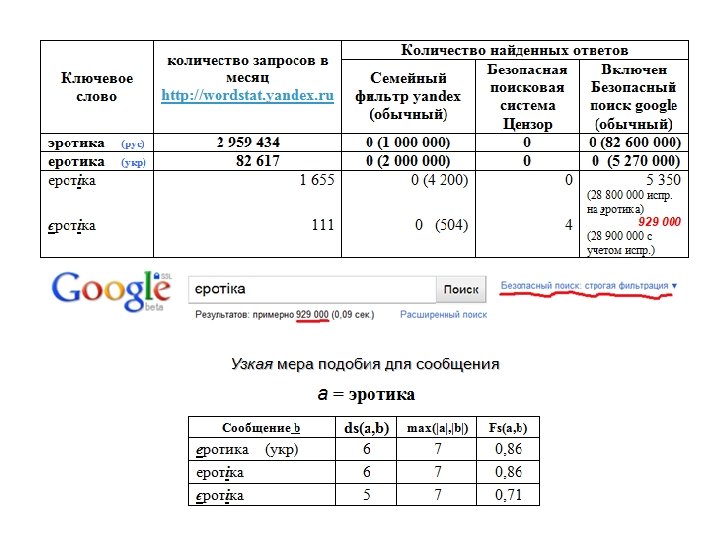
Узкая мера подобия для сообщения a = сексуально Сообщение b ds(a, b) max(|a|, |b|) Fs(a, b) сесуально 9 10 0, 90 секуально 9 10 0, 90 ексуально 9 10 0, 90 скесуально 9 10 0, 90 есксуально 9 10 0, 90
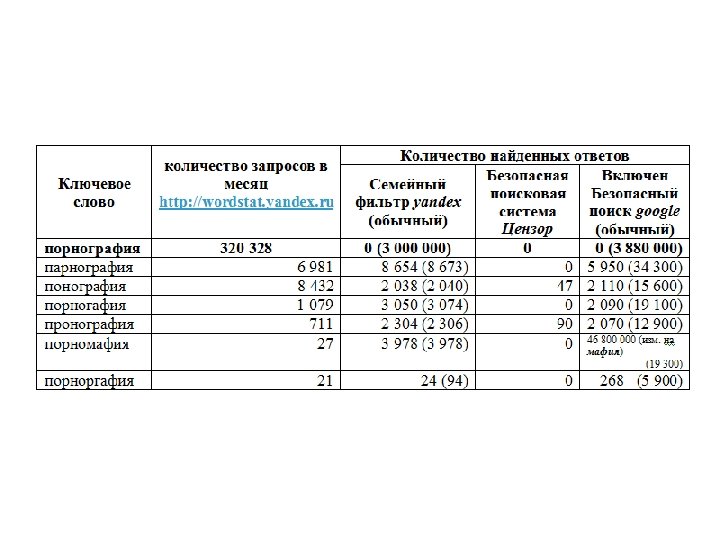

, отсутствующих в слове-эталоне; 2.")
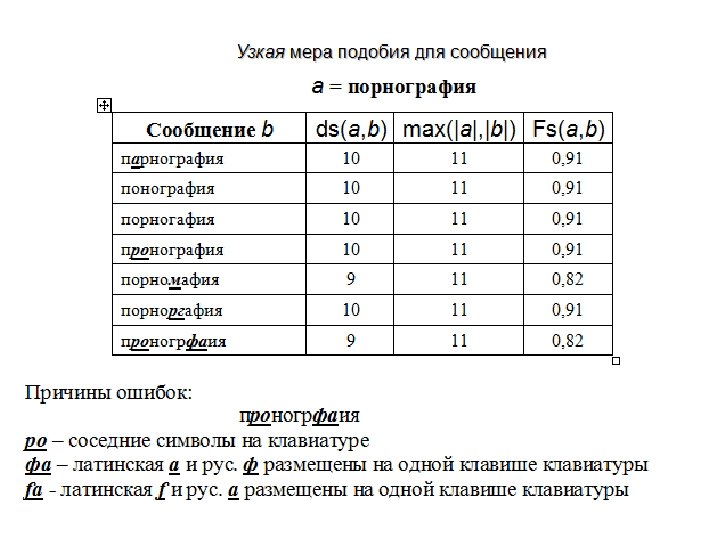
Причины малого веса подобия Порноиндустрия 1. слишком много букв (индуст), отсутствующих в слове-эталоне; 2. грамматически правильное длинное составное слово и можно рекомендовать включить его в список эталонов, наряду с порнографией.

Грамматически правильное длинное составное слово эталон a 1= порнозвезда при распределении весов (тоже, что и для эталона порнография) порнозвезда 212 11000000 будем иметь: Gs(a 1, порно-звезда, L) = 0. 917 Gs(a 1, порно-звездища, L) = 0. 786 Gs(a 1, порно-звездочка, L) = 0. 733 Наличие ожидаемых в ответе (запросе) символов, даже при их нулевых весах, приводит к существенному росту подобия.
e5746ed0888e452e4fd5743f43d6dd95.ppt