

29_04_2013_ Непараметрические тесты.ppt
- Количество слайдов: 59
 Тема 10: Непараметричні тести
Тема 10: Непараметричні тести
 План лекції 1. Порівняння параметричних та непараметричних критеріїв 2. Розрахунок U-критерію Манна-Уітні 3. Непараметричні тести в пакеті SPSS
План лекції 1. Порівняння параметричних та непараметричних критеріїв 2. Розрахунок U-критерію Манна-Уітні 3. Непараметричні тести в пакеті SPSS
 1. Параметричні та непараметричні критерії розбіжностей n n Критерій розбіжності називають параметричним, якщо він ґрунтується на наявному вигляді розподілу генеральної сукупності (як правило, нормальному) або використовує параметри цієї сукупності (середні, дисперсії тощо). Критерій розбіжності називають непараметричним, якщо він не базується на припущенні щодо виду розподілу генеральної сукупності та не використовує параметри цієї сукупності.
1. Параметричні та непараметричні критерії розбіжностей n n Критерій розбіжності називають параметричним, якщо він ґрунтується на наявному вигляді розподілу генеральної сукупності (як правило, нормальному) або використовує параметри цієї сукупності (середні, дисперсії тощо). Критерій розбіжності називають непараметричним, якщо він не базується на припущенні щодо виду розподілу генеральної сукупності та не використовує параметри цієї сукупності.
 n n За умови нормального розподілу генеральної сукупності параметричні критерії мають більшу потужність у порівнянні з непараметричними, вони здатні з більшою вірогідністю відкидати нульову гіпотезу, якщо вона невірна. Тому у випадках, коли вибірки взято з нормально розподілених генеральних сукупностей, варто віддавати перевагу параметричним критеріям. Проте практика показує, що розподіл переважної більшості даних, одержуваних у соціологічних опитуваннях, не відповідає нормальному розподілу, тому застосування параметричних критеріїв для аналізу результатів соціологічних досліджень може призвести до помилок у статистичних висновках. У таких випадках зазвичай застосовують непараметричні критерії.
n n За умови нормального розподілу генеральної сукупності параметричні критерії мають більшу потужність у порівнянні з непараметричними, вони здатні з більшою вірогідністю відкидати нульову гіпотезу, якщо вона невірна. Тому у випадках, коли вибірки взято з нормально розподілених генеральних сукупностей, варто віддавати перевагу параметричним критеріям. Проте практика показує, що розподіл переважної більшості даних, одержуваних у соціологічних опитуваннях, не відповідає нормальному розподілу, тому застосування параметричних критеріїв для аналізу результатів соціологічних досліджень може призвести до помилок у статистичних висновках. У таких випадках зазвичай застосовують непараметричні критерії.
 У порівнянні з параметричними тестами непараметричне тестування має як певні переваги, так і недоліки. Переваги n Непараметричне тестування не потребує ніяких припущень щодо характеру розподілу генеральної сукупності, з якої взято досліджувану вибірку. n Методи непараметричного тестування можуть застосовуватися навіть тоді, коли вибірка дуже мала. Недоліки n У порівнянні з параметричними тестами отримані дані використовуються менш ефективно. Потужність (тобто ймовірність відхилення нульової гіпотези, коли вірна альтернативна) непараметричних тестів нижча, ніж параметричних. Із цієї причини аналітики вважають, що застосування параметричних тестів є бажанішим у тих випадках, коли може бути зроблено необхідні припущення щодо генеральної сукупності.
У порівнянні з параметричними тестами непараметричне тестування має як певні переваги, так і недоліки. Переваги n Непараметричне тестування не потребує ніяких припущень щодо характеру розподілу генеральної сукупності, з якої взято досліджувану вибірку. n Методи непараметричного тестування можуть застосовуватися навіть тоді, коли вибірка дуже мала. Недоліки n У порівнянні з параметричними тестами отримані дані використовуються менш ефективно. Потужність (тобто ймовірність відхилення нульової гіпотези, коли вірна альтернативна) непараметричних тестів нижча, ніж параметричних. Із цієї причини аналітики вважають, що застосування параметричних тестів є бажанішим у тих випадках, коли може бути зроблено необхідні припущення щодо генеральної сукупності.
 n Треба пам’ятати, що непараметричні методи найбільш прийнятні, коли обсяг вибірок малий. Якщо даних багато (наприклад, n >100), то можна застосовувати параметричні статистики, оскільки для великих вибірок вибіркові середні підкоряються нормальному закону, навіть якщо досліджувана змінна не є нормальною. Таким чином, параметричні методи, які мають вищу статистичну потужність, завжди підходять для великих вибірок. Проте в роботі соціолога інколи виникають ситуації, коли треба дослідити певні малочисленні групи та виділити характерні риси, які відрізняють їх від інших (наприклад, дослідження інтелектуальної еліти). У таких випадках застосування непараметричних тестів може бути дуже корисним для виявлення статистичної значущості розбіжностей.
n Треба пам’ятати, що непараметричні методи найбільш прийнятні, коли обсяг вибірок малий. Якщо даних багато (наприклад, n >100), то можна застосовувати параметричні статистики, оскільки для великих вибірок вибіркові середні підкоряються нормальному закону, навіть якщо досліджувана змінна не є нормальною. Таким чином, параметричні методи, які мають вищу статистичну потужність, завжди підходять для великих вибірок. Проте в роботі соціолога інколи виникають ситуації, коли треба дослідити певні малочисленні групи та виділити характерні риси, які відрізняють їх від інших (наприклад, дослідження інтелектуальної еліти). У таких випадках застосування непараметричних тестів може бути дуже корисним для виявлення статистичної значущості розбіжностей.
 –") 2. U-тест Манна-Уітні n U-тест Манна - Уітні (англ. Mann – Whitney Utest) – статистичний критерій, що застосовується для оцінки розбіжностей між двома вибірками за рівнем деякої ознаки, що виміряна інтервальною або порядковою шкалою. Інші назви: критерій Манна – Уітні – Уілкоксона (англ. Mann –Whitney – Wilcoxon, MWW), критерій суми рангів Уілкоксона (англ. Wilcoxon rank-sum test), критерій Уілкоксона – Манна – Уітні (англ. Wilcoxon – Mann – Whitney test). Це найвідоміший і найпоширеніший тест непараметричного порівняння двох незалежних вибірок.
2. U-тест Манна-Уітні n U-тест Манна - Уітні (англ. Mann – Whitney Utest) – статистичний критерій, що застосовується для оцінки розбіжностей між двома вибірками за рівнем деякої ознаки, що виміряна інтервальною або порядковою шкалою. Інші назви: критерій Манна – Уітні – Уілкоксона (англ. Mann –Whitney – Wilcoxon, MWW), критерій суми рангів Уілкоксона (англ. Wilcoxon rank-sum test), критерій Уілкоксона – Манна – Уітні (англ. Wilcoxon – Mann – Whitney test). Це найвідоміший і найпоширеніший тест непараметричного порівняння двох незалежних вибірок.
 Розглянемо принцип, який є основою U-тесту. Для цього методом випадкового відбору виберемо 15 анкет з масиву st 09. sav (див. рис. ), та перевіримо гіпотезу про більш негативне ставлення жінок до абортів у порівнянні з чоловіками. n Анкети, що їх випадково витягнуто з масиву st 09. sav (Р 99 – ознака «ставлення до абортів» , Р 296 – «стать» )
Розглянемо принцип, який є основою U-тесту. Для цього методом випадкового відбору виберемо 15 анкет з масиву st 09. sav (див. рис. ), та перевіримо гіпотезу про більш негативне ставлення жінок до абортів у порівнянні з чоловіками. n Анкети, що їх випадково витягнуто з масиву st 09. sav (Р 99 – ознака «ставлення до абортів» , Р 296 – «стать» )
 n Позначимо кожний елемент першої групи символом x, а другий - символом y. Тоді загальний упорядкований за зростанням чисельних величин ряд можна представити так: y x y y y x y x - елементи першої (x) та другої (y) вибірки. 1 1 1 2 2 2 3 3 3 4 4 5 - значення досліджуваної ознаки. Якби впорядкований ряд, складений за даними двох вибірок, прийняв би вигляд x x x x x y y y, то дві вибірки значуще розрізнялися б між собою. Таке розташування називається ідеальним. Критерій U базується на підрахунку порушень у розташуванні чисел в упорядкованому емпіричному ряді в порівнянні з ідеальним рядом. n
n Позначимо кожний елемент першої групи символом x, а другий - символом y. Тоді загальний упорядкований за зростанням чисельних величин ряд можна представити так: y x y y y x y x - елементи першої (x) та другої (y) вибірки. 1 1 1 2 2 2 3 3 3 4 4 5 - значення досліджуваної ознаки. Якби впорядкований ряд, складений за даними двох вибірок, прийняв би вигляд x x x x x y y y, то дві вибірки значуще розрізнялися б між собою. Таке розташування називається ідеальним. Критерій U базується на підрахунку порушень у розташуванні чисел в упорядкованому емпіричному ряді в порівнянні з ідеальним рядом. n
 Розглянемо застосування U-критерію Манна. Уітні для нашої вибірки та розрахуємо його вручну та в SPSS.
Розглянемо застосування U-критерію Манна. Уітні для нашої вибірки та розрахуємо його вручну та в SPSS.
 Для застосування U-критерію Манна - Уітні потрібно виконати наступні операції. n 1. Скласти з обох вибірок єдиний ранжований ряд (порівняти вибірки між собою, розставивши їх елементи за ступенем наростанням ознаки й приписавши меншому значенню менший ранг). Потім треба розділити єдиний ранжований ряд на два, що містять відповідно одиниці з першої та другої вибірок (див. табл. 1). При цьому треба мати на увазі, що загальна кількість рангів дорівнює N = n 1 + n 2, де n 1 – кількість одиниць у першій вибірці, а n 2 – кількість одиниць у другій вибірці.
Для застосування U-критерію Манна - Уітні потрібно виконати наступні операції. n 1. Скласти з обох вибірок єдиний ранжований ряд (порівняти вибірки між собою, розставивши їх елементи за ступенем наростанням ознаки й приписавши меншому значенню менший ранг). Потім треба розділити єдиний ранжований ряд на два, що містять відповідно одиниці з першої та другої вибірок (див. табл. 1). При цьому треба мати на увазі, що загальна кількість рангів дорівнює N = n 1 + n 2, де n 1 – кількість одиниць у першій вибірці, а n 2 – кількість одиниць у другій вибірці.
 Перш за все представимо емпіричні дані у вигляді таблиці, яка допоможе нам розрахувати суми рангів.
Перш за все представимо емпіричні дані у вигляді таблиці, яка допоможе нам розрахувати суми рангів.
 Перш за все зазначимо, що для розрахунку U-критерію при ранжуванні меншому значенню нараховується менший ранг. У випадку, якщо кілька значень рівні, їм нараховується ранг, що представляє собою середнє значення з тих рангів, які вони одержали б, якби не були рівними. Так, в нашому прикладі перші шість респондентів відповіли, що вважають аборти зовсім не припустимими (альтернатива 1), тобто середній ранг буде розрахований як середнє значення: (1 + 2 + 3 + 4 + 5 + 6) / 6 = 3, 5.
Перш за все зазначимо, що для розрахунку U-критерію при ранжуванні меншому значенню нараховується менший ранг. У випадку, якщо кілька значень рівні, їм нараховується ранг, що представляє собою середнє значення з тих рангів, які вони одержали б, якби не були рівними. Так, в нашому прикладі перші шість респондентів відповіли, що вважають аборти зовсім не припустимими (альтернатива 1), тобто середній ранг буде розрахований як середнє значення: (1 + 2 + 3 + 4 + 5 + 6) / 6 = 3, 5.
 Для застосування U-критерію Манна - Уітні потрібно виконати наступні операції. n 2. Підрахувати окремо суму рангів, що відповідають елементам першої вибірки, і окремо – елементам другої вибірки. Визначити більшу із двох рангових сум (Rmax).
Для застосування U-критерію Манна - Уітні потрібно виконати наступні операції. n 2. Підрахувати окремо суму рангів, що відповідають елементам першої вибірки, і окремо – елементам другої вибірки. Визначити більшу із двох рангових сум (Rmax).
 Сума рангів: Перевіримо правильність нашого ранжування. Ми отримали суму рангів: 43, 5 + 76, 5 = 120. Сума рангів розраховується за формулою: Розрахункові суми випадків збігаються, значить, ранжування було проведено правильно. У таблиці можна побачити, що рангова сума в першій групі R 1 = 43, 4, а в другій R 2 = 76, 5.
Сума рангів: Перевіримо правильність нашого ранжування. Ми отримали суму рангів: 43, 5 + 76, 5 = 120. Сума рангів розраховується за формулою: Розрахункові суми випадків збігаються, значить, ранжування було проведено правильно. У таблиці можна побачити, що рангова сума в першій групі R 1 = 43, 4, а в другій R 2 = 76, 5.
 Для застосування U-критерію Манна - Уітні потрібно виконати наступні операції. n 3. Визначити емпіричне значення U-критерію Манна-Уітні. Для цього обчислюємо два значення: де n 1 – кількість респондентів у першій вибірці, n 2 – кількість респондентів у другій вибірці, R 1 – сума рангів у першій вибірці, R 2 – сума рангів у другій вибірці. Емпіричним значенням U-критерію Манна-Уітні вважається найменше з U 1 і U 2.
Для застосування U-критерію Манна - Уітні потрібно виконати наступні операції. n 3. Визначити емпіричне значення U-критерію Манна-Уітні. Для цього обчислюємо два значення: де n 1 – кількість респондентів у першій вибірці, n 2 – кількість респондентів у другій вибірці, R 1 – сума рангів у першій вибірці, R 2 – сума рангів у другій вибірці. Емпіричним значенням U-критерію Манна-Уітні вважається найменше з U 1 і U 2.
 Обчислюємо емпіричне значення U-критерію. Uемп = min {U 1; U 2}
Обчислюємо емпіричне значення U-критерію. Uемп = min {U 1; U 2}
 Для застосування U-критерію Манна - Уітні потрібно виконати наступні операції. 4. За таблицею визначити критичне значення критерію для n 1 та n 2 для обраного рівня статистичної значущості. Якщо отримане значення Uемп менше табличного або дорівнює йому, це означає наявність істотної розбіжності між рівнем ознаки у розглянутих вибірках. Якщо ж отримане значення Uемп більше табличного, приймається нульова гіпотеза - робиться висновок, що розбіжностей не виявлено. При цьому вірогідність розходжень тим вища, чим менше значення Uемп. n
Для застосування U-критерію Манна - Уітні потрібно виконати наступні операції. 4. За таблицею визначити критичне значення критерію для n 1 та n 2 для обраного рівня статистичної значущості. Якщо отримане значення Uемп менше табличного або дорівнює йому, це означає наявність істотної розбіжності між рівнем ознаки у розглянутих вибірках. Якщо ж отримане значення Uемп більше табличного, приймається нульова гіпотеза - робиться висновок, що розбіжностей не виявлено. При цьому вірогідність розходжень тим вища, чим менше значення Uемп. n
. Число на перетині розміру найбільшої (sіze") n Шукаємо критичне значення у таблиці (див. далі). Число на перетині розміру найбільшої (sіze of the largest sample) і найменшої (sіze of the smallest sample) з наших вибірок є критичним значенням коефіцієнта Манна-Уитни. У нашому випадку розмір найбільшої вибірки 10, найменшої – 5. Критичне значення Uкрит = 11 за p≤ 0, 05, Uкрит = 6 за p≤ 0, 01.
n Шукаємо критичне значення у таблиці (див. далі). Число на перетині розміру найбільшої (sіze of the largest sample) і найменшої (sіze of the smallest sample) з наших вибірок є критичним значенням коефіцієнта Манна-Уитни. У нашому випадку розмір найбільшої вибірки 10, найменшої – 5. Критичне значення Uкрит = 11 за p≤ 0, 05, Uкрит = 6 за p≤ 0, 01.
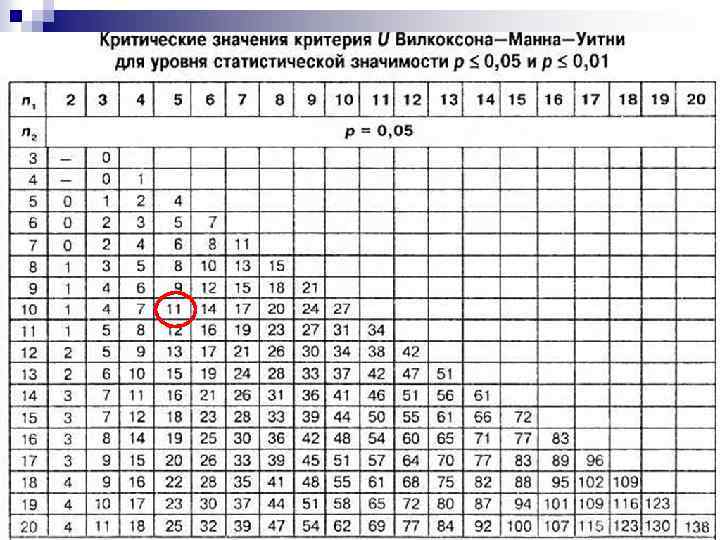
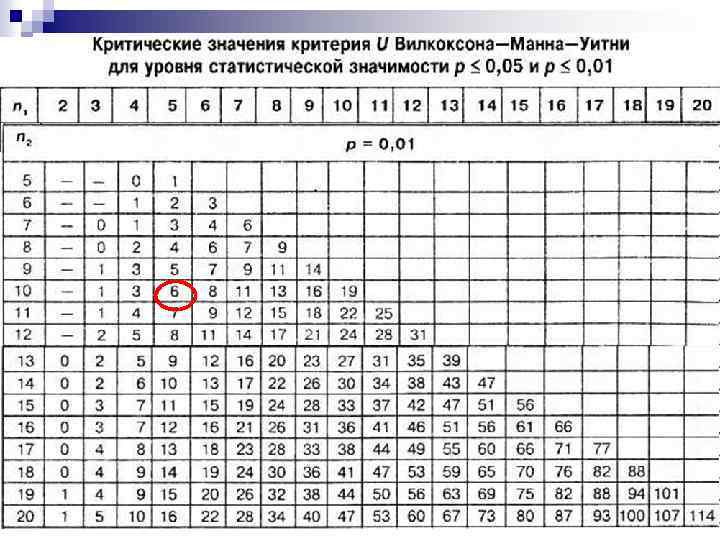
 Висновок. Отримане емпіричне значення Uемп = 21, 5 є більшим за критичне, тобто статистично значущих розбіжностей не виявлено (див. рис. ).
Висновок. Отримане емпіричне значення Uемп = 21, 5 є більшим за критичне, тобто статистично значущих розбіжностей не виявлено (див. рис. ).
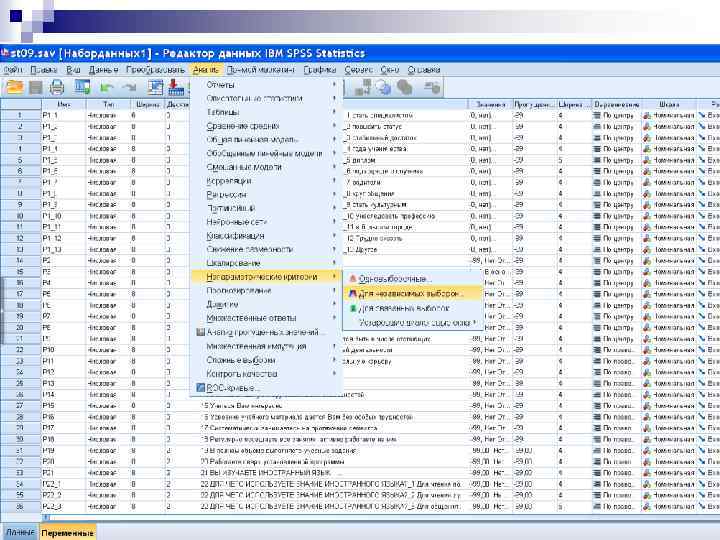
 3. Розрахунок значущості розбіжностей середніх для двох незалежних вибірок в пакеті SPSS: непараметричні тести
3. Розрахунок значущості розбіжностей середніх для двох незалежних вибірок в пакеті SPSS: непараметричні тести
 Процедура «Критерії для двох незалежних вибірок» порівнює дві групи спостережень однієї змінної. n Дані - кількісні змінні з упорядкованими значеннями. n
Процедура «Критерії для двох незалежних вибірок» порівнює дві групи спостережень однієї змінної. n Дані - кількісні змінні з упорядкованими значеннями. n
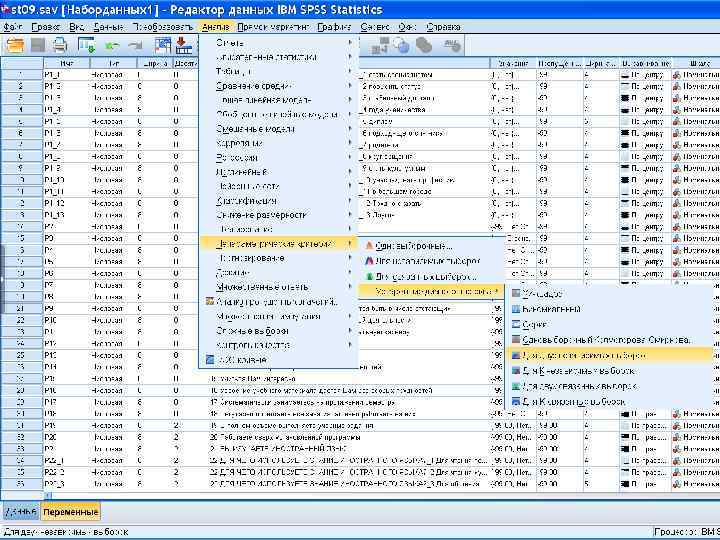
 У полі визначення груп задаються коди альтернатив, тобто потрібні значення групуючої змінної.
У полі визначення груп задаються коди альтернатив, тобто потрібні значення групуючої змінної.
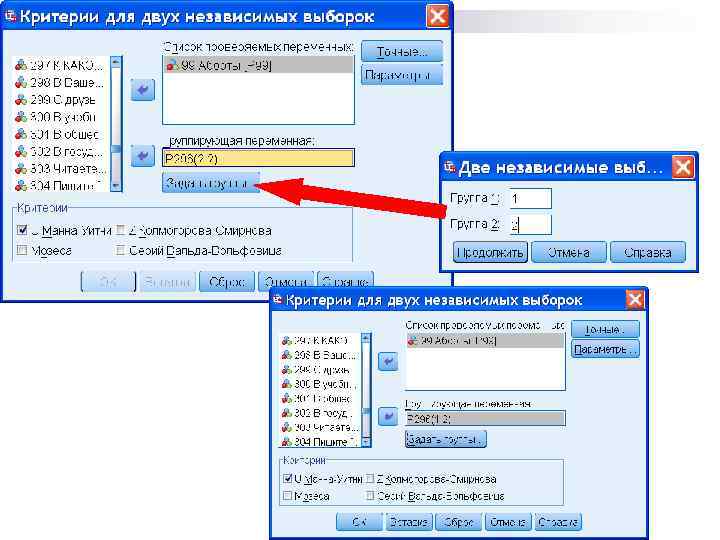
 Виведені результати включають наступні показники: n n n кількість спостережень, усереднені ранги й рангова сума для двох вибірок (причому більшим значенням привласнюються нижчі рангові місця), тестову величину U, що розрахована за допомогою тесту Манна й Уітні, W-тест Уілкоксона, точне значення ймовірності помилки р за умови кількості спостережень, меншої 30, тестову величину z, виявлену тестом Колмогорова-Смірнова, а також ймовірність помилки р стосовно неї, яку застосовують за умови кількості спостережень, більшої 30.
Виведені результати включають наступні показники: n n n кількість спостережень, усереднені ранги й рангова сума для двох вибірок (причому більшим значенням привласнюються нижчі рангові місця), тестову величину U, що розрахована за допомогою тесту Манна й Уітні, W-тест Уілкоксона, точне значення ймовірності помилки р за умови кількості спостережень, меншої 30, тестову величину z, виявлену тестом Колмогорова-Смірнова, а також ймовірність помилки р стосовно неї, яку застосовують за умови кількості спостережень, більшої 30.
 Проінтерпретуйте результат!
Проінтерпретуйте результат!
 Інші непараметричні тести для незалежних вибірок ШКритерій Манна. Уітні ШКритерій екстремальних реакцій Мозеса ШДвовибірковий критерій Колмогорова. Смірнова ШКритерій серій Вальда. Вольфовіца
Інші непараметричні тести для незалежних вибірок ШКритерій Манна. Уітні ШКритерій екстремальних реакцій Мозеса ШДвовибірковий критерій Колмогорова. Смірнова ШКритерій серій Вальда. Вольфовіца
 n. Критерій Z Колмогорова-Смірнова та критерій серій Вальда-Вольфовіца носять більш загальний характер та виявляють розбіжності між розподілами у їхньому розташуванні та формі. Критерій серій об'єднує та ранжує спостереження з обох груп. Якщо обидві вибірки узято з однієї генеральної сукупності, обидві групи мають бути випадково розкидані за проранжованими даними.
n. Критерій Z Колмогорова-Смірнова та критерій серій Вальда-Вольфовіца носять більш загальний характер та виявляють розбіжності між розподілами у їхньому розташуванні та формі. Критерій серій об'єднує та ранжує спостереження з обох груп. Якщо обидві вибірки узято з однієї генеральної сукупності, обидві групи мають бути випадково розкидані за проранжованими даними.
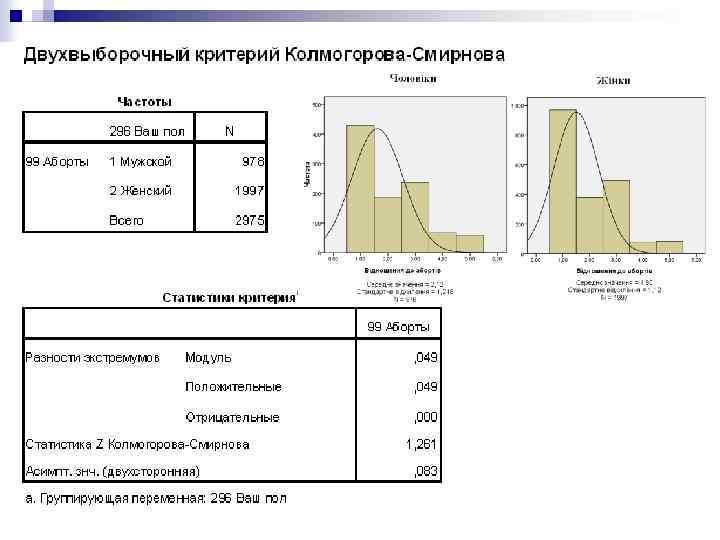
 Двовибірковий тест Колмогорова-Смірнова Зверніть увагу! Одновибірковий та двовибірковий тести Колмогорова-Смірнова мають різну мету. Двовибірковий тест Колмогорова-Смірнова призначений для перевірки гіпотези про співпадіння розподілу в двох вибірках. Він ґрунтується на максимумі модуля різниці між емпіричними функціями розподілу для обох вибірок. Якщо ця різниця є значущо великою, розподіли вважаються різноманітними. Статистика критерію - абсолютна величина (модуль) різниці емпіричних функцій розподілу у вказаних вибірках: де N 1 и N 2 - обсяги вибірок.
Двовибірковий тест Колмогорова-Смірнова Зверніть увагу! Одновибірковий та двовибірковий тести Колмогорова-Смірнова мають різну мету. Двовибірковий тест Колмогорова-Смірнова призначений для перевірки гіпотези про співпадіння розподілу в двох вибірках. Він ґрунтується на максимумі модуля різниці між емпіричними функціями розподілу для обох вибірок. Якщо ця різниця є значущо великою, розподіли вважаються різноманітними. Статистика критерію - абсолютна величина (модуль) різниці емпіричних функцій розподілу у вказаних вибірках: де N 1 и N 2 - обсяги вибірок.
 n Критерій екстремальних реакцій Мозеса передбачає вплив експериментальної змінної на деякі об'єкти в одному напрямі, а на інші – у протилежному. Критерій виявляє екстремальні у порівнянні з контрольною групою реакції. Він зосереджується навколо розмаху контрольної групи, та показує силу впливу на цей розмах екстремальних значень з експериментальної групи, коли експериментальна та контрольна групи об'єднано. Контрольна група задається значенням для групи 1 у діалоговому вікні «Дві незалежні вибірки: задати групи» . Спостереження з обох груп об'єднуються та ранжуються. Розмах контрольної групи обчислюється як різниця рангів найбільшого та найменшого значень у контрольній групі, збільшена на 1. Оскільки випадкові винятки можуть легко викривити величину розмаху, 5% спостережень з кожного кінця розподілу контрольної групи автоматично відсікаються.
n Критерій екстремальних реакцій Мозеса передбачає вплив експериментальної змінної на деякі об'єкти в одному напрямі, а на інші – у протилежному. Критерій виявляє екстремальні у порівнянні з контрольною групою реакції. Він зосереджується навколо розмаху контрольної групи, та показує силу впливу на цей розмах екстремальних значень з експериментальної групи, коли експериментальна та контрольна групи об'єднано. Контрольна група задається значенням для групи 1 у діалоговому вікні «Дві незалежні вибірки: задати групи» . Спостереження з обох груп об'єднуються та ранжуються. Розмах контрольної групи обчислюється як різниця рангів найбільшого та найменшого значень у контрольній групі, збільшена на 1. Оскільки випадкові винятки можуть легко викривити величину розмаху, 5% спостережень з кожного кінця розподілу контрольної групи автоматично відсікаються.
 Література n n n Бююль А. , Цёфель П. SPSS: искусство обработки информации. Анализ статистических данных и восстановление скрытых закономерностей. – СПб. : ООО «Диа. Софт. ЮП» , 2002. – С. 233 -255. Наследов А. SPSS: компьютерный анализ в психологии и социальных науках. – Питер, 2005. – С. 157 -177. Толстова Ю. Н. Математико-статистические модели в социологии (математическая статистика для социологов) : учеб. пособие / Ю. Н. Толстова. – 2 -е изд. М. : ГУ-ВШЭ, 2008. – С. 113 -119.
Література n n n Бююль А. , Цёфель П. SPSS: искусство обработки информации. Анализ статистических данных и восстановление скрытых закономерностей. – СПб. : ООО «Диа. Софт. ЮП» , 2002. – С. 233 -255. Наследов А. SPSS: компьютерный анализ в психологии и социальных науках. – Питер, 2005. – С. 157 -177. Толстова Ю. Н. Математико-статистические модели в социологии (математическая статистика для социологов) : учеб. пособие / Ю. Н. Толстова. – 2 -е изд. М. : ГУ-ВШЭ, 2008. – С. 113 -119.
 Дисперсійний аналіз
Дисперсійний аналіз
 План лекції n 1. Однофакторний дисперсійний аналіз
План лекції n 1. Однофакторний дисперсійний аналіз
 Дисперсійний аналіз дозволяє визначити статистичну достовірність розбіжностей між кількома вибірками шляхом порівняння середніх значень. Іншими словами, дисперсійний аналіз може слугувати перевіркою гіпотези про розбіжність середніх значень у декількох групах та дозволяє розподілити всю сукупність груп на певну кількість кластерів, які значуще відрізняються за значенням середніх (тест Дункана, докладніше див. : Бююль А. , Цёфель П. SPSS: Искусство обработки информации, анализ статистических данных и восстановление скрытых закономерностей, гл. 13, п. 3).
Дисперсійний аналіз дозволяє визначити статистичну достовірність розбіжностей між кількома вибірками шляхом порівняння середніх значень. Іншими словами, дисперсійний аналіз може слугувати перевіркою гіпотези про розбіжність середніх значень у декількох групах та дозволяє розподілити всю сукупність груп на певну кількість кластерів, які значуще відрізняються за значенням середніх (тест Дункана, докладніше див. : Бююль А. , Цёфель П. SPSS: Искусство обработки информации, анализ статистических данных и восстановление скрытых закономерностей, гл. 13, п. 3).
 Розглянемо застосування дисперсійного аналізу для дослідження статусних домагань українських студентів (масив st 06. sav). В даному випадку фактором (групуючою змінною) виступає заздалегідь виконаний розподіл респондентів за ціннісними орієнтаціями (докладніше про це у темі “Кластерний аналіз”). Сукупність середніх значень по групах (кластерах) тут розглядається в якості розподілу умовної залежної змінної. Розрахунок середніх значень по групах можна здійснити за допомогою простого розрахунку середніх, або ж задати вивід статистик безпосередньо у виконанні процедури однофакторного дисперсійного аналізу.
Розглянемо застосування дисперсійного аналізу для дослідження статусних домагань українських студентів (масив st 06. sav). В даному випадку фактором (групуючою змінною) виступає заздалегідь виконаний розподіл респондентів за ціннісними орієнтаціями (докладніше про це у темі “Кластерний аналіз”). Сукупність середніх значень по групах (кластерах) тут розглядається в якості розподілу умовної залежної змінної. Розрахунок середніх значень по групах можна здійснити за допомогою простого розрахунку середніх, або ж задати вивід статистик безпосередньо у виконанні процедури однофакторного дисперсійного аналізу.
 Інструментом вимірювання статусних домагань є питання № 249, котре в анкеті виглядає так:
Інструментом вимірювання статусних домагань є питання № 249, котре в анкеті виглядає так:
 До початку обробки даних вкажіть, що 10 – це код Немає Відповіді (Якщо цього не зробити, середні значення будуть обчислені неправильно)
До початку обробки даних вкажіть, що 10 – це код Немає Відповіді (Якщо цього не зробити, середні значення будуть обчислені неправильно)
 Щоб обчислити середні значення ознаки «Соціальна сходинка, куди хотіли б потрапити» , необхідно виконати команду Analyze → Compare Means → Means
Щоб обчислити середні значення ознаки «Соціальна сходинка, куди хотіли б потрапити» , необхідно виконати команду Analyze → Compare Means → Means
 Виконання та інтерпретація цієї процедури досить прості, проте не дозволяють визначити статистичну значущість розбіжностей середніх. Для цього використовується дисперсійний аналіз.
Виконання та інтерпретація цієї процедури досить прості, проте не дозволяють визначити статистичну значущість розбіжностей середніх. Для цього використовується дисперсійний аналіз.
 Перевірка гіпотези щодо розбіжностей у статусних домаганнях представників 7 -ми кластерів здійснюється за допомогою однофакторного дисперсійного аналізу (команда Analyze → Compare Means → One-Way ANOVA), де у полі Factor задається незалежна (групуюча) змінна, а у полі Dependent List – залежна, тобто та, для якої визначаються оцінювані середні значення.
Перевірка гіпотези щодо розбіжностей у статусних домаганнях представників 7 -ми кластерів здійснюється за допомогою однофакторного дисперсійного аналізу (команда Analyze → Compare Means → One-Way ANOVA), де у полі Factor задається незалежна (групуюча) змінна, а у полі Dependent List – залежна, тобто та, для якої визначаються оцінювані середні значення.
 Діалогове вікно ANOVA => Options У ньому можна додатково задати вивід описових статистик за групами (Descriptive) та лінійчатих графіків середніх значень (Means plot), а також перевірку на гомогенність дисперсій за допомогою тесту Левіна (Homogeneity of variance test).
Діалогове вікно ANOVA => Options У ньому можна додатково задати вивід описових статистик за групами (Descriptive) та лінійчатих графіків середніх значень (Means plot), а також перевірку на гомогенність дисперсій за допомогою тесту Левіна (Homogeneity of variance test).
 Результати застосування однофакторного дисперсійного аналізу для виявлення статистичної значущості розбіжностей середніх значень ознаки, що характеризує статусні домагання, в 7 -ми кластерах демонструють найвищу можливу значущість (Sig. <0, 001)
Результати застосування однофакторного дисперсійного аналізу для виявлення статистичної значущості розбіжностей середніх значень ознаки, що характеризує статусні домагання, в 7 -ми кластерах демонструють найвищу можливу значущість (Sig. <0, 001)
 Багатофакторний дисперсійний аналіз – дисперсійний аналіз із двома чи більше факторами. Багатофакторний дисперсійний аналіз застосовується у тих випадках, коли досліджується залежність середніх значень однієї змінної (у нашому прикладі – середніх значень статусних домагань груп респондентів) від кількох факторів. У нашому прикладі: Залежна змінна – статусні домагання. Фактори (незалежні змінні): 1) матеріальне положення сім‘ї; 2) соціальне положення батьків.
Багатофакторний дисперсійний аналіз – дисперсійний аналіз із двома чи більше факторами. Багатофакторний дисперсійний аналіз застосовується у тих випадках, коли досліджується залежність середніх значень однієї змінної (у нашому прикладі – середніх значень статусних домагань груп респондентів) від кількох факторів. У нашому прикладі: Залежна змінна – статусні домагання. Фактори (незалежні змінні): 1) матеріальне положення сім‘ї; 2) соціальне положення батьків.
 → General Linear Model (Загальна лінійна модель) → Univariate. . . (Одновимірна).") Analyze (Анализ) → General Linear Model (Загальна лінійна модель) → Univariate. . . (Одновимірна). Відкриється діалогове вікно Univariate (Одновимірна)
Analyze (Анализ) → General Linear Model (Загальна лінійна модель) → Univariate. . . (Одновимірна). Відкриється діалогове вікно Univariate (Одновимірна)
 Двофакторний дисперсійний аналіз дає можливість відповісти на наступні питання: 1. Чи існує статистично значуща відмінність статусних домагань 9 -ти груп студентів, чиї батьки займають 9 різних щаблів уявних соціальних сходів? 2. Чи існує статистично значуща відмінність статусних домагань між 5 -тьма групами з різним матеріальним станом? 3. Чи існує статистично значуща взаємодія змінних «Матеріальний стан сім'ї» та «Соціальне положення батьків» ?
Двофакторний дисперсійний аналіз дає можливість відповісти на наступні питання: 1. Чи існує статистично значуща відмінність статусних домагань 9 -ти груп студентів, чиї батьки займають 9 різних щаблів уявних соціальних сходів? 2. Чи існує статистично значуща відмінність статусних домагань між 5 -тьма групами з різним матеріальним станом? 3. Чи існує статистично значуща взаємодія змінних «Матеріальний стан сім'ї» та «Соціальне положення батьків» ?
 не спричиняє статистично") Результати виконання процедури багатофакторного дисперсійного аналізу Змінна р247 (матеріальний стан родини) не спричиняє статистично значущого впливу на розподіл залежної змінної (Sig = 0, 196 > 0, 05). Змінна р248 (соціальний щабель батьків) спричиняє статистично значущий вплив на розподіл залежної змінної ( Sig = 0, 000 < 0, 05). Не виявлено статистично значущої взаємодії між змінними р247 та р248 ( Sig = 0, 404 > 0, 05).
Результати виконання процедури багатофакторного дисперсійного аналізу Змінна р247 (матеріальний стан родини) не спричиняє статистично значущого впливу на розподіл залежної змінної (Sig = 0, 196 > 0, 05). Змінна р248 (соціальний щабель батьків) спричиняє статистично значущий вплив на розподіл залежної змінної ( Sig = 0, 000 < 0, 05). Не виявлено статистично значущої взаємодії між змінними р247 та р248 ( Sig = 0, 404 > 0, 05).
 Змістовно проінтерпретуйте отримані результати: змінна «Матеріальне становище сім'ї» не спричиняє статистично значущого впливу на розподіл змінної «Соціальна сходинка, на яку хотіли б потрапити» .
Змістовно проінтерпретуйте отримані результати: змінна «Матеріальне становище сім'ї» не спричиняє статистично значущого впливу на розподіл змінної «Соціальна сходинка, на яку хотіли б потрапити» .
 Змістовно проінтерпретуйте отримані результати: змінна «Соціальна сходинка батьків» спричиняє статистично значущий вплив на розподіл змінної «Соціальна сходинка, на яку хотіли б потрапити» .
Змістовно проінтерпретуйте отримані результати: змінна «Соціальна сходинка батьків» спричиняє статистично значущий вплив на розподіл змінної «Соціальна сходинка, на яку хотіли б потрапити» .
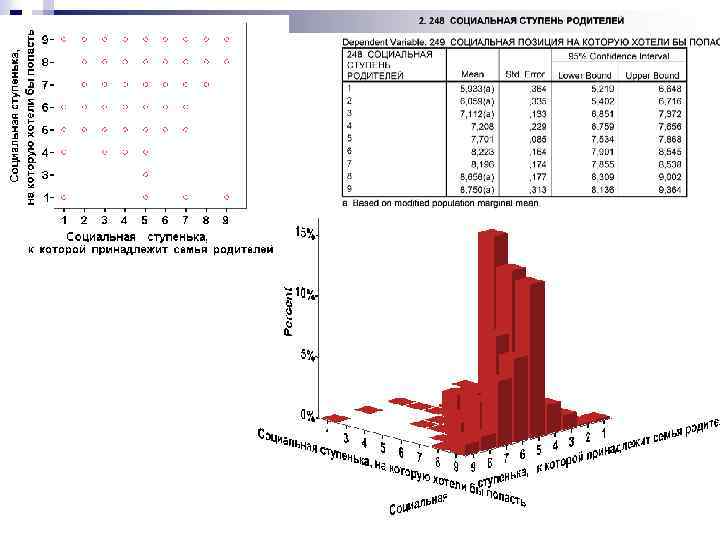
 Змістовно проінтерпретуйте отримані результати: не виявлено статистично значущої взаємодії між змінними «Матеріальне становище сім'ї» та «Соціальна сходинка, на яку хотіли б потрапити» , між змінними є слабка кореляція. Як пояснити цей факт з урахуванням сучасних українських реалій?
Змістовно проінтерпретуйте отримані результати: не виявлено статистично значущої взаємодії між змінними «Матеріальне становище сім'ї» та «Соціальна сходинка, на яку хотіли б потрапити» , між змінними є слабка кореляція. Як пояснити цей факт з урахуванням сучасних українських реалій?
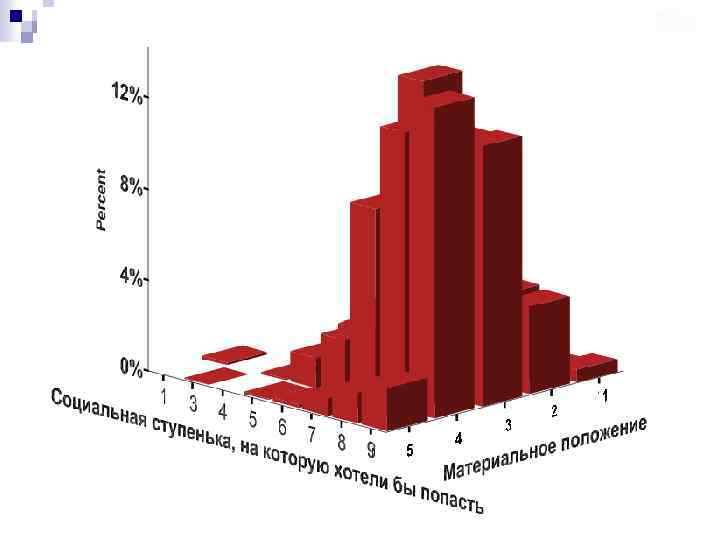
 Графік поверхні, що візуалізує взаємозв'язок ознак «Соціальна сходинка, на яку хотіли б потрапити» , «Соціальна сходинка батьків» та «Матеріальне становище сім'ї» (візуалізація у пакеті STATISTICA)
Графік поверхні, що візуалізує взаємозв'язок ознак «Соціальна сходинка, на яку хотіли б потрапити» , «Соціальна сходинка батьків» та «Матеріальне становище сім'ї» (візуалізація у пакеті STATISTICA)
 Література n n Бююль А. , Цёфель П. SPSS: искусство обработки информации. Анализ статистических данных и восстановление скрытых закономерностей. – СПб. : ООО «Диа. Софт. ЮП» , 2002. – С. 323 -340. Крыштановский А. О. Анализ социологических данных с помощью пакета SPSS. – М. : Изд. дом ГУ ВШЭ, 2007. - С. 99 -114. Наследов А. SPSS: компьютерный анализ в психологии и социальных науках. – Питер, 2005. – С. 178 -206. Толстова Ю. Н. Математико-статистические модели в социологии (математическая статистика для социологов) : учеб. пособие / Ю. Н. Толстова. – 2 -е изд. М. : ГУВШЭ, 2008. – С. 179 -196.
Література n n Бююль А. , Цёфель П. SPSS: искусство обработки информации. Анализ статистических данных и восстановление скрытых закономерностей. – СПб. : ООО «Диа. Софт. ЮП» , 2002. – С. 323 -340. Крыштановский А. О. Анализ социологических данных с помощью пакета SPSS. – М. : Изд. дом ГУ ВШЭ, 2007. - С. 99 -114. Наследов А. SPSS: компьютерный анализ в психологии и социальных науках. – Питер, 2005. – С. 178 -206. Толстова Ю. Н. Математико-статистические модели в социологии (математическая статистика для социологов) : учеб. пособие / Ю. Н. Толстова. – 2 -е изд. М. : ГУВШЭ, 2008. – С. 179 -196.