

СИ_ч2 - уск.ppt
- Количество слайдов: 199

 Текстовые данные В языке С++ текстовая информация представляется двумя типами данных: с помощью символов и строк - массивов символов. Символьная переменная объявляется с помощью ключевого слова char, например: char cr; char x= ‘!’ ; char a, b, c; printf("Введите исходные данные"); cin>>a>>b>>c;
Текстовые данные В языке С++ текстовая информация представляется двумя типами данных: с помощью символов и строк - массивов символов. Символьная переменная объявляется с помощью ключевого слова char, например: char cr; char x= ‘!’ ; char a, b, c; printf("Введите исходные данные"); cin>>a>>b>>c;
 СТРОКИ Строки в с++ позволяют нам работать с символьными данными. В С++ существует 2 типа строк. Первый из них - это массив переменных типа char. Например: char name[50]; cout<< "Enter your name "; cin>>name; cout<<"Hello "<
СТРОКИ Строки в с++ позволяют нам работать с символьными данными. В С++ существует 2 типа строк. Первый из них - это массив переменных типа char. Например: char name[50]; cout<< "Enter your name "; cin>>name; cout<<"Hello "<
 СТРОКИ Второй из вариантов, более удобный - это специальный класс string Для этого в начале программы подключить заголовочный файл string: #include
СТРОКИ Второй из вариантов, более удобный - это специальный класс string Для этого в начале программы подключить заголовочный файл string: #include
 Для записи в строку можно использовать оператор = s="Hello"; Для ввода-вывода можно использовать функции cin и cout. Для их использование подключите заголовочный файл "iostream" : #include "iostream " string name; Пример работы с классом string: cout<< "Enter your name ; string name; cin>>name; cout<<"Enter your name"<
Для записи в строку можно использовать оператор = s="Hello"; Для ввода-вывода можно использовать функции cin и cout. Для их использование подключите заголовочный файл "iostream" : #include "iostream " string name; Пример работы с классом string: cout<< "Enter your name ; string name; cin>>name; cout<<"Enter your name"<
. Например: getline(cin, s);") Для ввода предложений, в которых слова разделяются пробелами используют функция getline(). Например: getline(cin, s); Существует множество функций для работы со строками: int len=s. length()-записывает в len длину строки s. find(str, позиция) - ищет строку str начиная с заданной позиции s. clear() - отчищает строку, т. е. удаляет все элементы в ней s. find (str, позиция) - ищет строку str начиная с заданной позиции
Для ввода предложений, в которых слова разделяются пробелами используют функция getline(). Например: getline(cin, s); Существует множество функций для работы со строками: int len=s. length()-записывает в len длину строки s. find(str, позиция) - ищет строку str начиная с заданной позиции s. clear() - отчищает строку, т. е. удаляет все элементы в ней s. find (str, позиция) - ищет строку str начиная с заданной позиции
 Например: Дано предложение. Определите количество слов в нем. #include "stdafx. h" #include "string" #include "iostream" using namespace std; int _tmain(int argc, _TCHAR* argv[]) { string s; int i, k=1; cout<<"Enter text: "<
Например: Дано предложение. Определите количество слов в нем. #include "stdafx. h" #include "string" #include "iostream" using namespace std; int _tmain(int argc, _TCHAR* argv[]) { string s; int i, k=1; cout<<"Enter text: "<
" src="https://present5.com/presentation/40458383_441578515/image-8.jpg" alt="Пример. В заданной фамилии определить порядковый номер символа ‘n’. #include "stdafx. h" #include
 памяти, с которыми программы") Работа с файлами Файлы представляют собой именованные области внешней (дисковой) памяти, с которыми программы могут обмениваться информацией. Файлы предназначены только для хранения информации, а обработка этой информации осуществляется программами.
Работа с файлами Файлы представляют собой именованные области внешней (дисковой) памяти, с которыми программы могут обмениваться информацией. Файлы предназначены только для хранения информации, а обработка этой информации осуществляется программами.
 Файлы позволяют пользователю считывать большие объемы данных непосредственно с диска, не вводя их с клавиатуры. Существуют два основных типа файлов: текстовые и двоичные. Текстовыми называются файлы, состоящие из любых символов. Они организуются по строкам, каждая из которых заканчивается символом «конца строки» . Конец самого файла обозначается символом «конца файла» .
Файлы позволяют пользователю считывать большие объемы данных непосредственно с диска, не вводя их с клавиатуры. Существуют два основных типа файлов: текстовые и двоичные. Текстовыми называются файлы, состоящие из любых символов. Они организуются по строкам, каждая из которых заканчивается символом «конца строки» . Конец самого файла обозначается символом «конца файла» .
 Для работы с файлами используются специальные типы данных, называемые потоками. Поток ifstream служит для работы с файлами в режиме чтения, а ofstream в режиме записи. Для работы с файлами необходимо подключить заголовочный файл fstream. В fstream определены несколько классов и подключены заголовочные файлы
Для работы с файлами используются специальные типы данных, называемые потоками. Поток ifstream служит для работы с файлами в режиме чтения, а ofstream в режиме записи. Для работы с файлами необходимо подключить заголовочный файл fstream. В fstream определены несколько классов и подключены заголовочные файлы
 Для того чтобы записывать данные в текстовый файл, необходимо: • описать переменную типа ofstream. • открыть файл с помощью функции open. • вывести информацию в файл. • обязательно закрыть файл. Например: #include "stdafx. h" #include
Для того чтобы записывать данные в текстовый файл, необходимо: • описать переменную типа ofstream. • открыть файл с помощью функции open. • вывести информацию в файл. • обязательно закрыть файл. Например: #include "stdafx. h" #include
 { setlocale(0, "RUS"); ofstream fout; //создаём объект класса ofstream fout. open(“prim. txt"); /* связываем его с файлом cppstudio. txt*/ fout<< "Работа с файлами в С++"; // запись строки в файл fout. close(); // закрываем файл cout<<"Файл создан"<<"n"; return 0; } Создать текстовый файл можно в текстовом редакторе.
{ setlocale(0, "RUS"); ofstream fout; //создаём объект класса ofstream fout. open(“prim. txt"); /* связываем его с файлом cppstudio. txt*/ fout<< "Работа с файлами в С++"; // запись строки в файл fout. close(); // закрываем файл cout<<"Файл создан"<<"n"; return 0; } Создать текстовый файл можно в текстовом редакторе.

 Для считывания данных из текстового файла, необходимо: • описать переменную типа ifstream. • открыть файл с помощью функции open. • считать информацию из файла, при считывании каждой порции данных необходимо проверять, достигнут ли конец файла. • закрыть файл.
Для считывания данных из текстового файла, необходимо: • описать переменную типа ifstream. • открыть файл с помощью функции open. • считать информацию из файла, при считывании каждой порции данных необходимо проверять, достигнут ли конец файла. • закрыть файл.
: fin. get(a); где") Читать данных из текстового файла можно: - По символьно, функцией get(): fin. get(a); где а –переменная типа char, fin - поток ввода из файла - По словам: fin>>a; где а- массив символов (char a[10]; ) или переменная типа string a; - По строкам, функцией getline(): getline(fin, a); где а – переменная типа string.
Читать данных из текстового файла можно: - По символьно, функцией get(): fin. get(a); где а –переменная типа char, fin - поток ввода из файла - По словам: fin>>a; где а- массив символов (char a[10]; ) или переменная типа string a; - По строкам, функцией getline(): getline(fin, a); где а – переменная типа string.
 #include "stdafx. h" #include "string" #include "iostream" #include "fstream" using namespace std; int _tmain(int argc, _TCHAR* argv[]) {setlocale(0, "Rus"); ifstream fin; string a; fin. open("prim. txt"); while (!fin. eof()) { fin>>a; cout<
#include "stdafx. h" #include "string" #include "iostream" #include "fstream" using namespace std; int _tmain(int argc, _TCHAR* argv[]) {setlocale(0, "Rus"); ifstream fin; string a; fin. open("prim. txt"); while (!fin. eof()) { fin>>a; cout<
 Можно организовать посимвольное чтение файла. Например, подсчитайте количество * в файле: int _tmain(int argc, _TCHAR* argv[]) {setlocale(0, "Rus"); ifstream fin; char a; int k=0; fin. open("prim. txt"); while (!fin. eof()) { fin. get(a); if(!fin. eof()) if(a== '*')k++; } cout<
Можно организовать посимвольное чтение файла. Например, подсчитайте количество * в файле: int _tmain(int argc, _TCHAR* argv[]) {setlocale(0, "Rus"); ifstream fin; char a; int k=0; fin. open("prim. txt"); while (!fin. eof()) { fin. get(a); if(!fin. eof()) if(a== '*')k++; } cout<
 Структуры данных Очень часто при обработке информации приходится работать с блоками данных, в которых присутствуют разные типы данных. Структура - это тип данных, который может включать в себя несколько полей – элементов разных типов. В общем случае при работе со структурами следует выделить четыре момента: - объявление и определение типа структуры, - объявление структурной переменной, - инициализация структурной переменной, - использование структурной переменной.
Структуры данных Очень часто при обработке информации приходится работать с блоками данных, в которых присутствуют разные типы данных. Структура - это тип данных, который может включать в себя несколько полей – элементов разных типов. В общем случае при работе со структурами следует выделить четыре момента: - объявление и определение типа структуры, - объявление структурной переменной, - инициализация структурной переменной, - использование структурной переменной.
 Структура состоит из фиксированного числа элементов, называемых полями. Например, структурой можно считать строку экзаменационной ведомости: Андреева С. В. 4 5 5 Данная структура состоит из четырех полей: одно поле - строка (ФИО студента) и три числовых поля (оценки студента по предметам).
Структура состоит из фиксированного числа элементов, называемых полями. Например, структурой можно считать строку экзаменационной ведомости: Андреева С. В. 4 5 5 Данная структура состоит из четырех полей: одно поле - строка (ФИО студента) и три числовых поля (оценки студента по предметам).
 Описание типа структуры делается так: struct Имя { <тип> <имя 1 -го поля>; <тип> <имя 2 -го поля>; ………… <тип> <имя последнего поля>; }; Например, задание типа записи строки экзаменационной ведомости выглядит так: struct student { char fam[20]; int mathematics, informatics, history; };
Описание типа структуры делается так: struct Имя { <тип> <имя 1 -го поля>; <тип> <имя 2 -го поля>; ………… <тип> <имя последнего поля>; }; Например, задание типа записи строки экзаменационной ведомости выглядит так: struct student { char fam[20]; int mathematics, informatics, history; };
 Тогда при описании переменных можно использовать этот тип: student X; Здесь X - переменная типа структура; student - тип; fam, mathematics, informatics, history - поля структуры. .
Тогда при описании переменных можно использовать этот тип: student X; Здесь X - переменная типа структура; student - тип; fam, mathematics, informatics, history - поля структуры. .
 Для обращения к отдельным полям переменной типа структура используется составное имя: <имя переменной>. <имя поля> Например, для переменной X обращения к полям записываются следующим образом: X. fam, X. mathematics, X. informatics, X. history. Структурную переменную можно инициализировать явно при объявлении: student X={"Андреева С. В. ", 4, 5, 5};
Для обращения к отдельным полям переменной типа структура используется составное имя: <имя переменной>. <имя поля> Например, для переменной X обращения к полям записываются следующим образом: X. fam, X. mathematics, X. informatics, X. history. Структурную переменную можно инициализировать явно при объявлении: student X={"Андреева С. В. ", 4, 5, 5};
struct STUD // описание структуры { string fam; int" src="https://present5.com/presentation/40458383_441578515/image-24.jpg" alt="#include "stdafx. h" #include
 Для структурного типа возможно присваивание значений одной структурной переменной другой структурной переменной, при этом обе переменные должны иметь один и тот же тип. STUD X, Y; . . . Y=X; // копирование информации из Х в Y. . . Работа со структурной переменной обычно сводится к работе с отдельными полями структуры. Такие операции, как ввод с клавиатуры, сравнение полей и вывод на экран применимы только к отдельным полям.
Для структурного типа возможно присваивание значений одной структурной переменной другой структурной переменной, при этом обе переменные должны иметь один и тот же тип. STUD X, Y; . . . Y=X; // копирование информации из Х в Y. . . Работа со структурной переменной обычно сводится к работе с отдельными полями структуры. Такие операции, как ввод с клавиатуры, сравнение полей и вывод на экран применимы только к отдельным полям.
 Для записи информации в файл создайте новый проект и введите следующую программу: #include "stdafx. h" #include "string" #include "iostream" #include "fstream" using namespace std; struct sotrudnik {string fam; int otdel; int vozr; char pol; int virab; };
Для записи информации в файл создайте новый проект и введите следующую программу: #include "stdafx. h" #include "string" #include "iostream" #include "fstream" using namespace std; struct sotrudnik {string fam; int otdel; int vozr; char pol; int virab; };
![int _tmain(int argc, _TCHAR* argv[]) {int i; sotrudnik s[]={{](https://present5.com/presentation/40458383_441578515/image-27.jpg "int _tmain(int argc, _TCHAR* argv[]) {int i; sotrudnik s[]={{") int _tmain(int argc, _TCHAR* argv[]) {int i; sotrudnik s[]={{"Петров", 1, 21, 'м', 102}, {"Иванов", 2, 52, 'м', 98}, {"Махова", 1, 41, 'ж', 110}, {"Егорова", 1, 31, 'ж', 99}, {"Огарев", 1, 22, 'м', 101}, {"Гокова", 2, 28, 'ж', 120}, {"Сотник", 3, 48, 'м', 111}, {"Лебедев", 3, 26, 'м', 87}, {"Димова", 2, 55, 'ж', 105}, {"Комов", 1, 48, 'м', 118}}; ofstream fout; fout. open("svedenia. txt"); for(i=0; i<10; i++) fout<
int _tmain(int argc, _TCHAR* argv[]) {int i; sotrudnik s[]={{"Петров", 1, 21, 'м', 102}, {"Иванов", 2, 52, 'м', 98}, {"Махова", 1, 41, 'ж', 110}, {"Егорова", 1, 31, 'ж', 99}, {"Огарев", 1, 22, 'м', 101}, {"Гокова", 2, 28, 'ж', 120}, {"Сотник", 3, 48, 'м', 111}, {"Лебедев", 3, 26, 'м', 87}, {"Димова", 2, 55, 'ж', 105}, {"Комов", 1, 48, 'м', 118}}; ofstream fout; fout. open("svedenia. txt"); for(i=0; i<10; i++) fout<
 СПАСИБО за ВНИМАНИЕ FIN
СПАСИБО за ВНИМАНИЕ FIN
 Для работы с файлами в программах используется специальный тип данных – структура FILE, предназначенная для хранения атрибутов файлов (указатель (адрес) текущей позиции файла, признак конца файла, и др. ). В программе описывается переменная указатель типа FILE, которая будет представителем данного файла: FILE *f; где *f – переменная-указатель на файл.
Для работы с файлами в программах используется специальный тип данных – структура FILE, предназначенная для хранения атрибутов файлов (указатель (адрес) текущей позиции файла, признак конца файла, и др. ). В программе описывается переменная указатель типа FILE, которая будет представителем данного файла: FILE *f; где *f – переменная-указатель на файл.
 Открытие файла fl=fopen(") 1) Открытие файла fl=fopen("путь к файлу", "режим работы файла"); Параметр "путь к файлу" указывает размещение файла на диске. Он обязательно содержит имя файла и может содержать путь к нему. Параметр "режим работы файла" показывает, как будет использоваться файл: "w" – для записи данных (вывод); "r" – для чтения данных (ввод); "a" – для добавления данных к существующим записям.
1) Открытие файла fl=fopen("путь к файлу", "режим работы файла"); Параметр "путь к файлу" указывает размещение файла на диске. Он обязательно содержит имя файла и может содержать путь к нему. Параметр "режим работы файла" показывает, как будет использоваться файл: "w" – для записи данных (вывод); "r" – для чтения данных (ввод); "a" – для добавления данных к существующим записям.
 Пример открытия файла для записи: FILE * fo; fo = fopen("test. txt", "w"); Можно задать и полный путь к файлу, например: fo = fopen("c: tmptest. txt", "w"); Функция fopen() возвращает значение указателя на структуру типа файл. Если файл по каким-либо причинам не открывается, функция fopen() возвращает значение NULL.
Пример открытия файла для записи: FILE * fo; fo = fopen("test. txt", "w"); Можно задать и полный путь к файлу, например: fo = fopen("c: tmptest. txt", "w"); Функция fopen() возвращает значение указателя на структуру типа файл. Если файл по каким-либо причинам не открывается, функция fopen() возвращает значение NULL.
 Одновременно с открытием файла можно проверять, успешно ли это сделано: if( (fo=fopen("c: tmptest. txt", "w")) == 0 ) { . . . // ошибка! } Если файл открывается в режиме добавления данных "a", то указатель текущей позиции устанавливается на конец файла.
Одновременно с открытием файла можно проверять, успешно ли это сделано: if( (fo=fopen("c: tmptest. txt", "w")) == 0 ) { . . . // ошибка! } Если файл открывается в режиме добавления данных "a", то указатель текущей позиции устанавливается на конец файла.
") В С++ файл можно открыть для чтения и/или записи в текстовом или бинарном (двоичном) режиме. Поэтому можно указать дополнительные условия режима открытия файла: "b" – двоичный поток; "t" – текстовый поток; "+" – обновление файла.
В С++ файл можно открыть для чтения и/или записи в текстовом или бинарном (двоичном) режиме. Поэтому можно указать дополнительные условия режима открытия файла: "b" – двоичный поток; "t" – текстовый поток; "+" – обновление файла.
 Обработка открытого файла Для ввода/вывода в С++ используются следующие функции: Чтение (ввод) Запись") 2) Обработка открытого файла Для ввода/вывода в С++ используются следующие функции: Чтение (ввод) Запись (вывод) fgetc() fputc() fscanf() fprintf() fgets() fputs() fread() fwrite() При каждой операции ввода/вывода указатель текущей позиции файла смещается на одну позицию в сторону конца файла.
2) Обработка открытого файла Для ввода/вывода в С++ используются следующие функции: Чтение (ввод) Запись (вывод) fgetc() fputc() fscanf() fprintf() fgets() fputs() fread() fwrite() При каждой операции ввода/вывода указатель текущей позиции файла смещается на одну позицию в сторону конца файла.
 Закрытие файла После завершения обработки файла его следует закрыть с помощью функции fclose().") 3) Закрытие файла После завершения обработки файла его следует закрыть с помощью функции fclose(). При этом разрывается связь указателя на файл c внешним набором данных. Освободившийся указатель можно использовать для другого файла. Формат вызова функции: fclose(fо);
3) Закрытие файла После завершения обработки файла его следует закрыть с помощью функции fclose(). При этом разрывается связь указателя на файл c внешним набором данных. Освободившийся указатель можно использовать для другого файла. Формат вызова функции: fclose(fо);
 Работа с текстовыми файлами Файлы бывают текстовые (в которых можно записывать только буквы, цифры) и двоичные (в которых могут храниться любые символы из таблицы). В текстовых файлах символы конца строки 0 x 13 (возврат каретки, CR) и 0 x 10 (перевод строки LF) преобразуются при вводе в одиночный символ перевода строки (при выводе выполняется обратное преобразование. При обнаружении в текстовом файле символа с кодом 26 (0 x 26), т. е. признака конца файла, чтение файла в текстовом режиме заканчивается.
Работа с текстовыми файлами Файлы бывают текстовые (в которых можно записывать только буквы, цифры) и двоичные (в которых могут храниться любые символы из таблицы). В текстовых файлах символы конца строки 0 x 13 (возврат каретки, CR) и 0 x 10 (перевод строки LF) преобразуются при вводе в одиночный символ перевода строки (при выводе выполняется обратное преобразование. При обнаружении в текстовом файле символа с кодом 26 (0 x 26), т. е. признака конца файла, чтение файла в текстовом режиме заканчивается.
 Рассмотрим пример вывода в файл значения переменной: #include "stdafx. h" int _tmain(int argc, _TCHAR* argv[]) {int n=10; char st[25] = "значение переменной n="; FILE *fo; fo = fopen("test. txt", "wt"); fprintf( fo, "Вывод: %s %d", st, n ); fclose(fo); return 0; }
Рассмотрим пример вывода в файл значения переменной: #include "stdafx. h" int _tmain(int argc, _TCHAR* argv[]) {int n=10; char st[25] = "значение переменной n="; FILE *fo; fo = fopen("test. txt", "wt"); fprintf( fo, "Вывод: %s %d", st, n ); fclose(fo); return 0; }
 Проверка признака конца файла Так как при каждой операции ввода/вывода происходит перемещение указателя в файле, в какой-то момент указатель достигает конца файла. Функция feof() проверяет состояние индикатора конца файла и возвращает значение 0, если конец файла не был достигнут, или значение, отличное от нуля, если был достигнут конец файла. Пример вызова функции в команде if: if (! feof(fо))…
Проверка признака конца файла Так как при каждой операции ввода/вывода происходит перемещение указателя в файле, в какой-то момент указатель достигает конца файла. Функция feof() проверяет состояние индикатора конца файла и возвращает значение 0, если конец файла не был достигнут, или значение, отличное от нуля, если был достигнут конец файла. Пример вызова функции в команде if: if (! feof(fо))…
Посимвольный ввод/вывод: fgetc()/fputc() Функция getc() выбирает из файла очередной символ; ей нужно") Функции ввода/вывода 1)Посимвольный ввод/вывод: fgetc()/fputc() Функция getc() выбирает из файла очередной символ; ей нужно только знать указатель на файл, например, char S=fgetc(f); Где f –файловая переменная; Функция putc() заносит значение символа S в файл, на который указывает указатель f. Формат вызова функции: fputc(S, f);
Функции ввода/вывода 1)Посимвольный ввод/вывод: fgetc()/fputc() Функция getc() выбирает из файла очередной символ; ей нужно только знать указатель на файл, например, char S=fgetc(f); Где f –файловая переменная; Функция putc() заносит значение символа S в файл, на который указывает указатель f. Формат вызова функции: fputc(S, f);
 Пример1. Текст из файла my_char. txt выводится на экран. #include "stdafx. h" int main() {FILE *ptr; //описание указателя на файл char ch; ptr=fopen("my_char. txt", "r"); //открытие файла ch=fgetc(ptr); //чтение первого символа while (!feof(ptr)) //цикл до конца файла { printf("%c", ch); //вывод символа на экран ch=fgetc(ptr); //чтение следующего символа } fclose(ptr); //закрытие файла return 0; }
Пример1. Текст из файла my_char. txt выводится на экран. #include "stdafx. h" int main() {FILE *ptr; //описание указателя на файл char ch; ptr=fopen("my_char. txt", "r"); //открытие файла ch=fgetc(ptr); //чтение первого символа while (!feof(ptr)) //цикл до конца файла { printf("%c", ch); //вывод символа на экран ch=fgetc(ptr); //чтение следующего символа } fclose(ptr); //закрытие файла return 0; }
 Построковый ввод/вывод: fgets()/fputs() Функция fputs( ) записывает строку символов в файл. Она отличается") 2) Построковый ввод/вывод: fgets()/fputs() Функция fputs( ) записывает строку символов в файл. Она отличается от функции puts( ) тем, что в качестве второго параметра должна быть указана переменная файлового типа. Например: fputs("Ехаmple", f); Функция fgets( ) читает строку символов из файла. fgets(string, n, f); Пример2. Создать текстовый файл на диске.
2) Построковый ввод/вывод: fgets()/fputs() Функция fputs( ) записывает строку символов в файл. Она отличается от функции puts( ) тем, что в качестве второго параметра должна быть указана переменная файлового типа. Например: fputs("Ехаmple", f); Функция fgets( ) читает строку символов из файла. fgets(string, n, f); Пример2. Создать текстовый файл на диске.
 #include "stdafx. h" #include "string. h" int _tmain(int argc, _TCHAR* argv[]) {int n=10; char st[25]; FILE *fo; fo = fopen("test. txt", "wt"); while(strcmp(st, "end")!=0) {gets(st); if(strcmp(st, "end")!=0) fputs(st, fo); }printf("конец создания файла"); fclose(fo); return 0; }
#include "stdafx. h" #include "string. h" int _tmain(int argc, _TCHAR* argv[]) {int n=10; char st[25]; FILE *fo; fo = fopen("test. txt", "wt"); while(strcmp(st, "end")!=0) {gets(st); if(strcmp(st, "end")!=0) fputs(st, fo); }printf("конец создания файла"); fclose(fo); return 0; }
 форматированный ввод/вывод: fscanf()/fprintf() Чтение из файла выполняет функция fscanf(): fscanf(f, ”строка формата”, список") 2) форматированный ввод/вывод: fscanf()/fprintf() Чтение из файла выполняет функция fscanf(): fscanf(f, ”строка формата”, список адресов перем-х); где f –файловая переменная; Запись в файл осуществляет функция fprintf(): fprintf(f, "строка формата", список переменных); С помощью этих функция можно вводить и выводить значения переменных любого стандартного типа
2) форматированный ввод/вывод: fscanf()/fprintf() Чтение из файла выполняет функция fscanf(): fscanf(f, ”строка формата”, список адресов перем-х); где f –файловая переменная; Запись в файл осуществляет функция fprintf(): fprintf(f, "строка формата", список переменных); С помощью этих функция можно вводить и выводить значения переменных любого стандартного типа
 Пример 3. Записать массив в файл: #include "stdafx. h " int main() { int i; int array[]={5, 135, 3}; //описание и инициализация FILE *out; //описание указателя на файл out=fopen("num_arr. txt", "w"); //открытие файла for(i=0; i<4; i++) fprintf(out, "%5 d", array[i]); //запись в файл элемента fclose(out); //закрытие файла return 0; } 5 1 3 5 5 3 1 5 1 3 5 3
Пример 3. Записать массив в файл: #include "stdafx. h " int main() { int i; int array[]={5, 135, 3}; //описание и инициализация FILE *out; //описание указателя на файл out=fopen("num_arr. txt", "w"); //открытие файла for(i=0; i<4; i++) fprintf(out, "%5 d", array[i]); //запись в файл элемента fclose(out); //закрытие файла return 0; } 5 1 3 5 5 3 1 5 1 3 5 3
 удаляет файл с заданным именем: remove(") Функция remove( ) удаляет файл с заданным именем: remove("my_file. txt"); Здесь "my_file. txt" – имя удаляемого файла. При успешном завершении возвращается нуль, в противном случае возвращается ненулевое значение. Функция rewind( ) устанавливает указатель текущей позиции в начало файла и имеет следующий прототип: rewind(fp); Где fp - файловая переменная
Функция remove( ) удаляет файл с заданным именем: remove("my_file. txt"); Здесь "my_file. txt" – имя удаляемого файла. При успешном завершении возвращается нуль, в противном случае возвращается ненулевое значение. Функция rewind( ) устанавливает указатель текущей позиции в начало файла и имеет следующий прототип: rewind(fp); Где fp - файловая переменная
 переименовывает существующий файл : rename(") Функция rename( ) переименовывает существующий файл : rename("old_file. txt", "new_file. txt"); Пример 4. Файл содержит текст в котором есть цифры. Удалить цифры из файла. #include "stdafx. h" #include
Функция rename( ) переименовывает существующий файл : rename("old_file. txt", "new_file. txt"); Пример 4. Файл содержит текст в котором есть цифры. Удалить цифры из файла. #include "stdafx. h" #include
) //Цикл пока не конец файла { ch=fgetc(f); // Чтение символа ch из") while (!feof(f)) //Цикл пока не конец файла { ch=fgetc(f); // Чтение символа ch из файла if (!(ch >='0'&&ch<='9')&& !feof(f)) /*Если прочитанный символ не цифра и не конец файла*/ fputc(ch, r); // Запись в файл r символа ch } fclose(f); fclose(r); remove("FIL 1. txt"); rename("FIL 2. txt", "FIL 1. txt"); return 0; }
while (!feof(f)) //Цикл пока не конец файла { ch=fgetc(f); // Чтение символа ch из файла if (!(ch >='0'&&ch<='9')&& !feof(f)) /*Если прочитанный символ не цифра и не конец файла*/ fputc(ch, r); // Запись в файл r символа ch } fclose(f); fclose(r); remove("FIL 1. txt"); rename("FIL 2. txt", "FIL 1. txt"); return 0; }
 Обработка бинарных файлов Если файл открыт в бинарном режиме, его можно записывать или считывать побайтно. Бинарный файл – это файл произвольного доступа. Функция fseek() позволяет переходить к любой позиции в файле, обеспечивая возможность произвольного доступа. Функция fseek( ) имеет формат: fseek(fp, count, access);
Обработка бинарных файлов Если файл открыт в бинарном режиме, его можно записывать или считывать побайтно. Бинарный файл – это файл произвольного доступа. Функция fseek() позволяет переходить к любой позиции в файле, обеспечивая возможность произвольного доступа. Функция fseek( ) имеет формат: fseek(fp, count, access);
 где fp - указатель на файл; count - номер байта относительно заданной позиции, начиная с которого будут затем выполняться операции; access - способ задания начальной позиции. Переменная access может принимать следующие значения: 0 - начальная позиция задана в начале файла; 1 - начальная позиция считается текущей; 2 - начальная позиция задана в конце файла. При успешном завершении возвращается нуль, при ошибке - ненулевое значение.
где fp - указатель на файл; count - номер байта относительно заданной позиции, начиная с которого будут затем выполняться операции; access - способ задания начальной позиции. Переменная access может принимать следующие значения: 0 - начальная позиция задана в начале файла; 1 - начальная позиция считается текущей; 2 - начальная позиция задана в конце файла. При успешном завершении возвращается нуль, при ошибке - ненулевое значение.
 предназначена для чтения блоков данных из") Функции ввода-вывода для бинарных файлов Функция fread( ) предназначена для чтения блоков данных из потока: fread( ptr, size, n, fp); Она читает n элементов данных, длиной size байт каждый, из файла fp в переменную с адресом ptr. Общее число прочитанных байтов равно произведению n*size. При успешном завершении функция fread( ) возвращает число прочитанных элементов данных, при ошибке - 0.
Функции ввода-вывода для бинарных файлов Функция fread( ) предназначена для чтения блоков данных из потока: fread( ptr, size, n, fp); Она читает n элементов данных, длиной size байт каждый, из файла fp в переменную с адресом ptr. Общее число прочитанных байтов равно произведению n*size. При успешном завершении функция fread( ) возвращает число прочитанных элементов данных, при ошибке - 0.
 предназначена для записи в файл блоков данных: fwrite(ptr, size, n, fp);") Функция fwrite( ) предназначена для записи в файл блоков данных: fwrite(ptr, size, n, fp); Она добавляет n элементов данных, длиной size байт каждый, в заданный выходной файл fp. Данные записываются из переменной с адресом ptr. При успешном завершении операции функция fwrite( ) возвращает число записанных элементов данных, при ошибке - неверное число элементов данных.
Функция fwrite( ) предназначена для записи в файл блоков данных: fwrite(ptr, size, n, fp); Она добавляет n элементов данных, длиной size байт каждый, в заданный выходной файл fp. Данные записываются из переменной с адресом ptr. При успешном завершении операции функция fwrite( ) возвращает число записанных элементов данных, при ошибке - неверное число элементов данных.
 Пример 5. Составим программу создания нового файла с информацией о городах: код, название, численность жителей. #include "stdafx. h” typedef struct city { int kod; char name[10]; long c; } town; town t; int main() { char c; FILE *f; char ch;
Пример 5. Составим программу создания нового файла с информацией о городах: код, название, численность жителей. #include "stdafx. h” typedef struct city { int kod; char name[10]; long c; } town; town t; int main() { char c; FILE *f; char ch;
 f=fopen("file 1. dat", "wb"); //открытие для записи printf("n Ввод информации о городе "); do { printf("n. Код: "); scanf("%d", &t. kod); printf("nназвание: "); scanf("%s", t. name); printf("nкол-во жителей: "); scanf("%ld", &t. c); fwrite(&t, sizeof(t), 1, f); //запись в файл стр-ры t printf("n END Закончить? ( y/n): "); ch=getch(); } while (ch != 'y'); fclose(f); }
f=fopen("file 1. dat", "wb"); //открытие для записи printf("n Ввод информации о городе "); do { printf("n. Код: "); scanf("%d", &t. kod); printf("nназвание: "); scanf("%s", t. name); printf("nкол-во жителей: "); scanf("%ld", &t. c); fwrite(&t, sizeof(t), 1, f); //запись в файл стр-ры t printf("n END Закончить? ( y/n): "); ch=getch(); } while (ch != 'y'); fclose(f); }
 Пример 6. Вывести на экран список городов, количество жителей в которых превышает миллион человек. #include "stdafx. h " typedef struct city { int kod; char name[10]; long c; } town; town t; int main() { FILE *f;
Пример 6. Вывести на экран список городов, количество жителей в которых превышает миллион человек. #include "stdafx. h " typedef struct city { int kod; char name[10]; long c; } town; town t; int main() { FILE *f;
 f=fopen("file 1. dat", "rb"); //открытие файла для чтения fread(&t, sizeof(t), 1, f); //чтение из файла t while (!feof(f)) { if(t. c>1000000) printf("n %10 s количество жителей: %ld", t. name, t. c); fread(&t, sizeof(t), 1, f); } fclose(f); }
f=fopen("file 1. dat", "rb"); //открытие файла для чтения fread(&t, sizeof(t), 1, f); //чтение из файла t while (!feof(f)) { if(t. c>1000000) printf("n %10 s количество жителей: %ld", t. name, t. c); fread(&t, sizeof(t), 1, f); } fclose(f); }
 Динамические структуры данных Любая программа предназначена для обработки данных, от способы организации которых зависят алгоритмы работы. Поэтому выбор структур данных должен предшествовать разработке алгоритма. Под структурой данных в общем случае понимают множество элементов данных и множество связей между ними. В зависимости от локализации принято различать оперативные и файловые структуры. По признаку изменчивости различают статические и динамические структуры.
Динамические структуры данных Любая программа предназначена для обработки данных, от способы организации которых зависят алгоритмы работы. Поэтому выбор структур данных должен предшествовать разработке алгоритма. Под структурой данных в общем случае понимают множество элементов данных и множество связей между ними. В зависимости от локализации принято различать оперативные и файловые структуры. По признаку изменчивости различают статические и динамические структуры.

 Память под данные выделяется либо на этапе компиляции (в этом случае необходимый объем должен быть известен до начала выполнения программы), либо во время выполнения программы. Если до начала работы с данными невозможно определить, сколько памяти потребуется, то память выделяется динамически. В С++ используется 2 способа работы с динамической памятью: 1) Использование функция malloc() и free(); 2) Использование операций new и delete.
Память под данные выделяется либо на этапе компиляции (в этом случае необходимый объем должен быть известен до начала выполнения программы), либо во время выполнения программы. Если до начала работы с данными невозможно определить, сколько памяти потребуется, то память выделяется динамически. В С++ используется 2 способа работы с динамической памятью: 1) Использование функция malloc() и free(); 2) Использование операций new и delete.
 Из динамических структур в программах чаще всего используются линейные списки, стеки, очереди и бинарные деревья. Динамические структуры характеризуются: -Непостоянством и непредсказуемостью размера структуры в процессе обработки. -Отсутствием физической смежности элементов структуры. Для установления связи между элементами структуры используются указатели, через которые устанавливаются явные связи между элементами.
Из динамических структур в программах чаще всего используются линейные списки, стеки, очереди и бинарные деревья. Динамические структуры характеризуются: -Непостоянством и непредсказуемостью размера структуры в процессе обработки. -Отсутствием физической смежности элементов структуры. Для установления связи между элементами структуры используются указатели, через которые устанавливаются явные связи между элементами.
 Элемент динамической структуры состоит из нескольких полей: - информационного поля или поля данных, в котором содержатся те данные, ради которых и создается структура (в общем случае информационное поле само является структурой, массивом и т. п. ); - полей связок, в которых содержатся одна или несколько указателей, связывающий данный элемент с другими элементами структуры;
Элемент динамической структуры состоит из нескольких полей: - информационного поля или поля данных, в котором содержатся те данные, ради которых и создается структура (в общем случае информационное поле само является структурой, массивом и т. п. ); - полей связок, в которых содержатся одна или несколько указателей, связывающий данный элемент с другими элементами структуры;
 Связные линейные списки Связный список – такая структура данных, элементами которой служат записи с одним и тем же форматом, связанные друг с другом с помощью указателей, хранящихся в самих элементах. Простейшим связным списком является односвязный список. где INF - информационное поле или поле данных, NEXT - указатель на следующий элемент списка.
Связные линейные списки Связный список – такая структура данных, элементами которой служат записи с одним и тем же форматом, связанные друг с другом с помощью указателей, хранящихся в самих элементах. Простейшим связным списком является односвязный список. где INF - информационное поле или поле данных, NEXT - указатель на следующий элемент списка.
 Каждый список должен иметь особый элемент, называемый указателем начала списка или головой списка. Пользуясь указателем, можно получить доступ к следующему элементу списка, а из следующего элемента – к очередному. Поле указателя последнего элемента должно содержать специальный признак нулевого или пустого указателя (NULL), свидетельствующего о конце списка.
Каждый список должен иметь особый элемент, называемый указателем начала списка или головой списка. Пользуясь указателем, можно получить доступ к следующему элементу списка, а из следующего элемента – к очередному. Поле указателя последнего элемента должно содержать специальный признак нулевого или пустого указателя (NULL), свидетельствующего о конце списка.
 В программах элемент списка должен быть описан как структура, например: #define list struct spisok list { data inf; //информационная часть list *next; //указатель на следующий элемент };
В программах элемент списка должен быть описан как структура, например: #define list struct spisok list { data inf; //информационная часть list *next; //указатель на следующий элемент };
; -Добавление элемента") Над списками можно выполнять следующие операции: -Создание первого элемента (начальное формирование списка); -Добавление элемента в конец списка; -Вставка элемента в заданное место списка; -Удаление элемента с заданным ключом; -Упорядочивание элементов списка; -Просмотр элементов списка. Каждый элемент списка содержит ключ, идентифицирующий этот элемент.
Над списками можно выполнять следующие операции: -Создание первого элемента (начальное формирование списка); -Добавление элемента в конец списка; -Вставка элемента в заданное место списка; -Удаление элемента с заданным ключом; -Упорядочивание элементов списка; -Просмотр элементов списка. Каждый элемент списка содержит ключ, идентифицирующий этот элемент.
 Создать элемент – это выделить память для его хранения и инициализировать поля: list *cur= (list*)malloc(sizeof(list)); //создание cur->info=x; cur->next=0; или list *x=new list; Связать два элемента: t->next=cur; Переместиться по списку: t=t->next;
Создать элемент – это выделить память для его хранения и инициализировать поля: list *cur= (list*)malloc(sizeof(list)); //создание cur->info=x; cur->next=0; или list *x=new list; Связать два элемента: t->next=cur; Переместиться по списку: t=t->next;
 Просмотр элементов списка При просмотре осуществляется последовательный доступ к элементам списка - ко всем до конца списка или до нахождения искомого элемента. Например: void display(list *head) //head - указатель на начало {list *t= head; //t- указатель установлен на начало списка while(t) {// обработка t=t->next; // переход на следующий элемент } }
Просмотр элементов списка При просмотре осуществляется последовательный доступ к элементам списка - ко всем до конца списка или до нахождения искомого элемента. Например: void display(list *head) //head - указатель на начало {list *t= head; //t- указатель установлен на начало списка while(t) {// обработка t=t->next; // переход на следующий элемент } }
 В цикле может выполняться обработка содержимого списка. Обработка может заключаться : üв печати содержимого списка; üв модификации информационных полей списка; üв сравнении информационных полей с образцом при поиске по ключу; üв подсчете итераций цикла при поиске по номеру; üи т. д. , и т. п.
В цикле может выполняться обработка содержимого списка. Обработка может заключаться : üв печати содержимого списка; üв модификации информационных полей списка; üв сравнении информационных полей с образцом при поиске по ключу; üв подсчете итераций цикла при поиске по номеру; üи т. д. , и т. п.
 Вставка элемента в список Вставка элемента в середину односвязного списка показана на рисунке Поясним обозначения на рисунке: prev - адрес предыдущего элемента; сur – адрес вставляемого элемента.
Вставка элемента в список Вставка элемента в середину односвязного списка показана на рисунке Поясним обозначения на рисунке: prev - адрес предыдущего элемента; сur – адрес вставляемого элемента.
 Приведем фрагмент программы для вставки элемента в середину списка: list *cur; // адрес нового элемента cur= (list*)malloc(sizeof(list)); //создание нового эл-та cur->info=x; //запись данные элемент cur->next=prev->next; /*элемент, следовавший за предыдущим теперь будет следовать за новым*/ prev->next=cur; // предыдущий элемент связан с новым
Приведем фрагмент программы для вставки элемента в середину списка: list *cur; // адрес нового элемента cur= (list*)malloc(sizeof(list)); //создание нового эл-та cur->info=x; //запись данные элемент cur->next=prev->next; /*элемент, следовавший за предыдущим теперь будет следовать за новым*/ prev->next=cur; // предыдущий элемент связан с новым
 Приведенные примеры обеспечивают вставку в середину списка, но не могут быть применены для вставки в начало списка. При вставке элемента в начало сначала создается новый элемент, затем в его поле next записывается адрес начала списка head, а потом указатель head устанавливается на вставляемый элемент.
Приведенные примеры обеспечивают вставку в середину списка, но не могут быть применены для вставки в начало списка. При вставке элемента в начало сначала создается новый элемент, затем в его поле next записывается адрес начала списка head, а потом указатель head устанавливается на вставляемый элемент.
 Следующий фрагмент программы выполняет вставку элемента в любое место односвязного списка. list *cur; // адрес нового элемента cur= (list*)malloc(sizeof(list)); //создание нового эл-та cur->info=x; //запись данных в новый элемент if (prev) // есть ли предыдущий элемент? { cur->next=prev->next; // вставка в середину списка prev->next=cur; } else {cur->next=head; // вставка в начало списка head=cur; /*если head=0, то новый элемент будет первым и последним элементом списка*/ }
Следующий фрагмент программы выполняет вставку элемента в любое место односвязного списка. list *cur; // адрес нового элемента cur= (list*)malloc(sizeof(list)); //создание нового эл-та cur->info=x; //запись данных в новый элемент if (prev) // есть ли предыдущий элемент? { cur->next=prev->next; // вставка в середину списка prev->next=cur; } else {cur->next=head; // вставка в начало списка head=cur; /*если head=0, то новый элемент будет первым и последним элементом списка*/ }
 ПОВТОРИМ: Создать элемент – это выделить память для его хранения и инициализировать поля: list *cur= (list*)malloc(sizeof(list)); //создание cur->info=x; cur->next=0; или list *x=new list; cur t Связать два элемента: t->next=cur; Переместиться по списку: t=t->next;
ПОВТОРИМ: Создать элемент – это выделить память для его хранения и инициализировать поля: list *cur= (list*)malloc(sizeof(list)); //создание cur->info=x; cur->next=0; или list *x=new list; cur t Связать два элемента: t->next=cur; Переместиться по списку: t=t->next;
 Удаление элемента из списка Удаление элемента из односвязного списка показано на рисунке
Удаление элемента из списка Удаление элемента из односвязного списка показано на рисунке
 процедуру удаления легко выполнить, если известен адрес элемента, предшествующего удаляемому элементу: list *del; . . . del=prev->next; /* запомнили адрес удаляемого элемента*/ prev->next=del->next; /* связали предыдущий элемент с элементом, стоящим после удаляемого*/ free(del); // удалили элемент освободив память
процедуру удаления легко выполнить, если известен адрес элемента, предшествующего удаляемому элементу: list *del; . . . del=prev->next; /* запомнили адрес удаляемого элемента*/ prev->next=del->next; /* связали предыдущий элемент с элементом, стоящим после удаляемого*/ free(del); // удалили элемент освободив память
 Пример 1. Создать односвязный список из целых чисел и вывести его на экран. Решение: //1. Опишем структуру для создания списка #define list struct spisok list { int info; list *next; }; list *head; // head-указатель на начало списка
Пример 1. Создать односвязный список из целых чисел и вывести его на экран. Решение: //1. Опишем структуру для создания списка #define list struct spisok list { int info; list *next; }; list *head; // head-указатель на начало списка
 //d –число добавляемое в список") //2. Функция создания элемента списка list * first(int d) //d –число добавляемое в список {list *t=new list; t->next=0; t->info=d; return t; } //3. Функция добавления элемента в конец списка void insert(list **s, int x) { list *t=*s; list *p=0; list *r;
//2. Функция создания элемента списка list * first(int d) //d –число добавляемое в список {list *t=new list; t->next=0; t->info=d; return t; } //3. Функция добавления элемента в конец списка void insert(list **s, int x) { list *t=*s; list *p=0; list *r;
 { p=t; t=t->next; } r=first(x); if(p==0) *s=r; else p->next=r; }") while(t!=0) { p=t; t=t->next; } r=first(x); if(p==0) *s=r; else p->next=r; }
while(t!=0) { p=t; t=t->next; } r=first(x); if(p==0) *s=r; else p->next=r; }
 {list *t=s; while(t) { printf(") //4. Функция вывод списка на экран void display(list *s) {list *t=s; while(t) { printf("%4 d", t->info); t=t->next; } }
//4. Функция вывод списка на экран void display(list *s) {list *t=s; while(t) { printf("%4 d", t->info); t=t->next; } }
"); scanf("%d", &x); head=first(x); //создание первого эл-та" src="https://present5.com/presentation/40458383_441578515/image-79.jpg" alt="//5. Главная программа int main() {int x; printf("->"); scanf("%d", &x); head=first(x); //создание первого эл-та" />
//5. Главная программа int main() {int x; printf("->"); scanf("%d", &x); head=first(x); //создание первого эл-та do // цикл ввода эл-тов списка { scanf("%d", &x); insert(&head, x); } while(x!=0) ; display(head); return 0; }
,") Пример 2. Создать список с информацией о студентах (№, ФИО, группа, балл в КС), упорядочив по алфавиту. Удалить из списка студента по его номеру и вывести список на экран. Решение: #define stud struct student #define list struct spisok stud{ int nom; char fio[20]; char grup[5]; float ball; }; list { stud info; list *next; };
Пример 2. Создать список с информацией о студентах (№, ФИО, группа, балл в КС), упорядочив по алфавиту. Удалить из списка студента по его номеру и вывести список на экран. Решение: #define stud struct student #define list struct spisok stud{ int nom; char fio[20]; char grup[5]; float ball; }; list { stud info; list *next; };
 //d –информация о студенте") list *head; //указатель на начало списка list * first(stud d) //d –информация о студенте {list *t=new list; t->next=0; t->info=d; return t; } void insert(list **s, stud x) { list *t=*s; list *p=0; list *r;
list *head; //указатель на начало списка list * first(stud d) //d –информация о студенте {list *t=new list; t->next=0; t->info=d; return t; } void insert(list **s, stud x) { list *t=*s; list *p=0; list *r;
<0) {p=t; t=t->next; } r=first(x); r->next= t; if(p==0) *s=r; else") while(t!=0&&strcmp(t->info. fio, x. fio)<0) {p=t; t=t->next; } r=first(x); r->next= t; if(p==0) *s=r; else p->next=r; }
while(t!=0&&strcmp(t->info. fio, x. fio)<0) {p=t; t=t->next; } r=first(x); r->next= t; if(p==0) *s=r; else p->next=r; }
 {list *t=s; while(t) {if(t->info. nom==x.") //Поиск элемента по ключу list *find(list *s, stud x) {list *t=s; while(t) {if(t->info. nom==x. nom) break; t=t->next; } return t; }
//Поиск элемента по ключу list *find(list *s, stud x) {list *t=s; while(t) {if(t->info. nom==x. nom) break; t=t->next; } return t; }
 {list *t=*s; list *u=find(t, x); if (u!=0&&u!=*s)") //Удаление элемента void remove(list **s, stud x) {list *t=*s; list *u=find(t, x); if (u!=0&&u!=*s) {while(t->next!=u) {t=t->next; } t->next=u->next; delete u; } else if(u==*s) {*s=(*s)->next; delete u; } }
//Удаление элемента void remove(list **s, stud x) {list *t=*s; list *u=find(t, x); if (u!=0&&u!=*s) {while(t->next!=u) {t=t->next; } t->next=u->next; delete u; } else if(u==*s) {*s=(*s)->next; delete u; } }
 {list *t=s; while(t) { printf(") //4. Функция вывод списка на экран void display(list *s) {list *t=s; while(t) { printf("%d %s %s %5. 2 fn", t->info. nom, t->info. fio, t->info. grup, t->info. ball); t=t->next; } }
//4. Функция вывод списка на экран void display(list *s) {list *t=s; while(t) { printf("%d %s %s %5. 2 fn", t->info. nom, t->info. fio, t->info. grup, t->info. ball); t=t->next; } }
 {stud a; printf(") int main() {stud a; printf("vvedi svedenija o 5 studentax"); for(int i=1; i<=5; i++) {scanf("%d", &a. nom); scanf("%s", a. fio); scanf("%s", a. grup); scanf("%f", &a. ball); insert(&head, a); } display(head); printf("vvedi nomer studenta dlja udalenia"); scanf("%d", &a. nom); remove(&head, a); display(head); return 0; }
int main() {stud a; printf("vvedi svedenija o 5 studentax"); for(int i=1; i<=5; i++) {scanf("%d", &a. nom); scanf("%s", a. fio); scanf("%s", a. grup); scanf("%f", &a. ball); insert(&head, a); } display(head); printf("vvedi nomer studenta dlja udalenia"); scanf("%d", &a. nom); remove(&head, a); display(head); return 0; }

 Двухсвязные списки Обработка односвязного списка не всегда удобна, так как отсутствует возможность продвижения в противоположную сторону. Такую возможность обеспечивает двухсвязный список, каждый элемент которого содержит два указателя: на следующий и предыдущий элементы списка.
Двухсвязные списки Обработка односвязного списка не всегда удобна, так как отсутствует возможность продвижения в противоположную сторону. Такую возможность обеспечивает двухсвязный список, каждый элемент которого содержит два указателя: на следующий и предыдущий элементы списка.
 В программах элемент двухсвязного списка должен быть описан как структура, например: #define dlist struct spisok dlist { data inf; //информационная часть dlist *next; //указатель на следующий элемент dlist *prev; //указатель на предыдущий элемент };
В программах элемент двухсвязного списка должен быть описан как структура, например: #define dlist struct spisok dlist { data inf; //информационная часть dlist *next; //указатель на следующий элемент dlist *prev; //указатель на предыдущий элемент };
 Создать элемент – это выделить память для его хранения и инициализировать поля: dlist *cur=new dlist; //создание cur->info=x; cur->next=0; cur->prev=0; Связать два элемента: t->next=cur; cur->prev=t; Переместиться по списку: t=t->next; или t=t->prev;
Создать элемент – это выделить память для его хранения и инициализировать поля: dlist *cur=new dlist; //создание cur->info=x; cur->next=0; cur->prev=0; Связать два элемента: t->next=cur; cur->prev=t; Переместиться по списку: t=t->next; или t=t->prev;
 Нелинейные связные структуры Двусвязный список может и не быть линейным, если второй указатель каждого элемента списка задает порядок произвольного вида, не являющийся обратным по отношению к порядку, устанавливаемому первым указателем.
Нелинейные связные структуры Двусвязный список может и не быть линейным, если второй указатель каждого элемента списка задает порядок произвольного вида, не являющийся обратным по отношению к порядку, устанавливаемому первым указателем.
 ЗАДАНИЕ Написать программу, строящую списочную структуру, состоящую из трехнаправленного и двух однонаправленных списков, связанных между собой. Информационное поле элемента однонаправленного списка заполняется вводимой последовательностью целых чисел: а 1 , а 2 , . . . , а n , 0, в которой 0 отмечает конец ввода, число N не вводится, а подсчитывается при вводе последовательности.
ЗАДАНИЕ Написать программу, строящую списочную структуру, состоящую из трехнаправленного и двух однонаправленных списков, связанных между собой. Информационное поле элемента однонаправленного списка заполняется вводимой последовательностью целых чисел: а 1 , а 2 , . . . , а n , 0, в которой 0 отмечает конец ввода, число N не вводится, а подсчитывается при вводе последовательности.

 #define st struct st #define list struct spisok list { int info; list *next; }; st {list *up; list *down; st *right; }; list*t 1, *p 1, *t 2, *p 2; st *s, *t, *p;
#define st struct st #define list struct spisok list { int info; list *next; }; st {list *up; list *down; st *right; }; list*t 1, *p 1, *t 2, *p 2; st *s, *t, *p;
"); scanf("%d", &a); n=1; if" src="https://present5.com/presentation/40458383_441578515/image-95.jpg" alt="int main() { int a, n; char y, c; printf("->"); scanf("%d", &a); n=1; if" />
int main() { int a, n; char y, c; printf("->"); scanf("%d", &a); n=1; if (a==0) printf("list pust"); else {

 {t=new st; t->up=0; t->right=0; t->down=0; t 1=new list; t 1 ->next=0; t 1") while(a!=0) {t=new st; t->up=0; t->right=0; t->down=0; t 1=new list; t 1 ->next=0; t 1 ->info=a; t->up=t 1; if(s==0)s=t; else { p->right=t; p 1 ->next=t 1; }
while(a!=0) {t=new st; t->up=0; t->right=0; t->down=0; t 1=new list; t 1 ->next=0; t 1 ->info=a; t->up=t 1; if(s==0)s=t; else { p->right=t; p 1 ->next=t 1; }

next=0; t 2" src="https://present5.com/presentation/40458383_441578515/image-99.jpg" alt=" scanf("%d", &a); n++; if(a!=0) { t 2=new list; t 2 ->next=0; t 2" />
scanf("%d", &a); n++; if(a!=0) { t 2=new list; t 2 ->next=0; t 2 ->info=a; t->down=t 2; if(n!=2) p 2 ->next=t 2; p=t; p 2=t 2; p 1=t 1; scanf("%d", &a); n++; }}
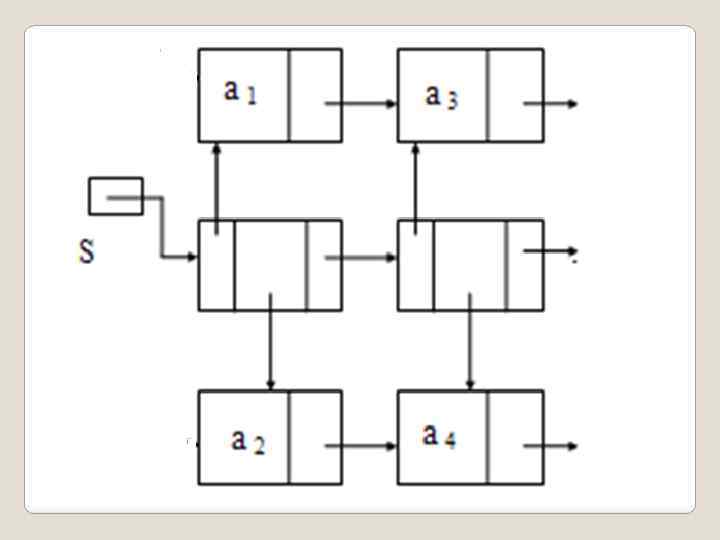
 { printf(") t 2 ->next=s->down; t 1 ->next=s->up; y='y'; while(y=='y') { printf("nvvod upravleniyan"); n=0; p=s; p 1=0; p 2=0; c=getch(); while(c!='1') {
t 2 ->next=s->down; t 1 ->next=s->up; y='y'; while(y=='y') { printf("nvvod upravleniyan"); n=0; p=s; p 1=0; p 2=0; c=getch(); while(c!='1') {
down; } else printf("Pusto downn");" src="https://present5.com/presentation/40458383_441578515/image-102.jpg" alt="if (c=='2') //down { if(n==0) {if (p->down!=0) {printf("vnizn"); p 2=p->down; } else printf("Pusto downn");" />
if (c=='2') //down { if(n==0) {if (p->down!=0) {printf("vnizn"); p 2=p->down; } else printf("Pusto downn"); n=2; } else printf("No downn"); }
up; } else printf("Pusto upn");" src="https://present5.com/presentation/40458383_441578515/image-103.jpg" alt="if (c=='8') //up { if(n==0) {if (p->up!=0) {printf("vverxn"); p 1=p->up; } else printf("Pusto upn");" />
if (c=='8') //up { if(n==0) {if (p->up!=0) {printf("vverxn"); p 1=p->up; } else printf("Pusto upn"); n=1; } else printf("No upn"); }
"); p=p->right; } else printf("end"); } if(n==1) {if(p 1!=0) {printf("|" src="https://present5.com/presentation/40458383_441578515/image-104.jpg" alt="if(c=='6') {if (n==0) {if(p!=0) {printf("->"); p=p->right; } else printf("end"); } if(n==1) {if(p 1!=0) {printf("|" />
if(c=='6') {if (n==0) {if(p!=0) {printf("->"); p=p->right; } else printf("end"); } if(n==1) {if(p 1!=0) {printf("| %d |", p 1 ->info); p 1=p 1 ->next; } else printf("end up"); }
info); p 2=p 2 ->next;" src="https://present5.com/presentation/40458383_441578515/image-105.jpg" alt=" if(n==2) {if(p 2!=0) {printf("| %d |", p 2 ->info); p 2=p 2 ->next;" />
if(n==2) {if(p 2!=0) {printf("| %d |", p 2 ->info); p 2=p 2 ->next; } else printf("end down"); } } c=getch(); } printf("nbegin ? (y/n)"); y=getch(); } } return 0; }
 Стеки Стек - это частный случай однонаправленного списка, добавление и удаление элементов в который выполняется с одного конца, называемого вершиной стека. Говорят, что стек реализует принцип обслуживания LIFO (last in – first out). Стеки широко применяются в системах программирования, компиляторах, в различных рекурсивных алгоритмах.
Стеки Стек - это частный случай однонаправленного списка, добавление и удаление элементов в который выполняется с одного конца, называемого вершиной стека. Говорят, что стек реализует принцип обслуживания LIFO (last in – first out). Стеки широко применяются в системах программирования, компиляторах, в различных рекурсивных алгоритмах.
 На рисунке приведем логическую структуру стека.
На рисунке приведем логическую структуру стека.
 Важнейшие операции доступа к стеку – включение и исключение элементов – осуществляются с вершины стека, причем в каждый момент для исключения доступен элемент En, находящийся на вершине стека. Вершина адресуется с помощью специального указателя.
Важнейшие операции доступа к стеку – включение и исключение элементов – осуществляются с вершины стека, причем в каждый момент для исключения доступен элемент En, находящийся на вершине стека. Вершина адресуется с помощью специального указателя.
 Для включения нового элемента в стек указатель сначала перемещается вверх на длину слота, а затем по значению указателя в стек помещается информация о новом элементе. При исключении элемента из стека сначала прочитывается информация об исключаемом элементе по значению указателя, а затем указатель смещается «вниз» на один слот.
Для включения нового элемента в стек указатель сначала перемещается вверх на длину слота, а затем по значению указателя в стек помещается информация о новом элементе. При исключении элемента из стека сначала прочитывается информация об исключаемом элементе по значению указателя, а затем указатель смещается «вниз» на один слот.
 – добавление в стек") Две основные операции работы со стеком реализуются функциями: Push(втолкнуть) – добавление в стек нового элемента Pop (вытолкнуть) – удалить из стека элементы, включенные туда последними. Для наглядности рассмотрим программу, демонстрирующий принцип включения элементов в стек и исключения элементов из стека.
Две основные операции работы со стеком реализуются функциями: Push(втолкнуть) – добавление в стек нового элемента Pop (вытолкнуть) – удалить из стека элементы, включенные туда последними. Для наглядности рассмотрим программу, демонстрирующий принцип включения элементов в стек и исключения элементов из стека.
 #include "stdafx. h" #define stack struct STACK stack { int info; stack *next; }; stack *V; //указатель на вершину стека void push(stack **top, int x) //добавление в стек { stack *r; r= new stack; r->info=x; r->next=*top; *top=r; }
#include "stdafx. h" #define stack struct STACK stack { int info; stack *next; }; stack *V; //указатель на вершину стека void push(stack **top, int x) //добавление в стек { stack *r; r= new stack; r->info=x; r->next=*top; *top=r; }
 { int temp=(*top)->info; stack *t=*top; *top=(*top)->next; delete t; return temp; }") int pop(stack **top) { int temp=(*top)->info; stack *t=*top; *top=(*top)->next; delete t; return temp; } int _tmain(int argc, _TCHAR* argv[]) { for (int i=1; i<=5; i++) push(&V, i); printf("STACK: "); while(V) printf("%3 d", pop(&V)); printf("n"); return 0; }
int pop(stack **top) { int temp=(*top)->info; stack *t=*top; *top=(*top)->next; delete t; return temp; } int _tmain(int argc, _TCHAR* argv[]) { for (int i=1; i<=5; i++) push(&V, i); printf("STACK: "); while(V) printf("%3 d", pop(&V)); printf("n"); return 0; }
 Очередь - это частный случай однонаправленного списка, добавление элементов в который выполняется с одного конца а удаление с другого конца. Говорят, что очередь реализует принцип обслуживания FIFO (first in – first out). Очереди применяются при моделировании систем массового обслуживания, диспетчеризации задач операционной системой, буферизованном вводе/выводе.
Очередь - это частный случай однонаправленного списка, добавление элементов в который выполняется с одного конца а удаление с другого конца. Говорят, что очередь реализует принцип обслуживания FIFO (first in – first out). Очереди применяются при моделировании систем массового обслуживания, диспетчеризации задач операционной системой, буферизованном вводе/выводе.
 Та сторона очереди, с которой осуществляется добавление, называется хвостом, или концом, очереди, другая – голова. Для индикации хвоста и головы организуются два указателя.
Та сторона очереди, с которой осуществляется добавление, называется хвостом, или концом, очереди, другая – голова. Для индикации хвоста и головы организуются два указателя.
 Рассмотрим пример формирования очереди из целых чисел и вывода ее на экран. #include "stdafx. h" #define och struct OCH och { int info; och *next; }; och *p 1, *p 2;
Рассмотрим пример формирования очереди из целых чисел и вывода ее на экран. #include "stdafx. h" #define och struct OCH och { int info; och *next; }; och *p 1, *p 2;
 { och *r=new och; r->info=x; r->next=0; if((*head)==0)") void add(och **head, och **tail, int x) { och *r=new och; r->info=x; r->next=0; if((*head)==0) *head=*tail=r; else { (*tail)->next=r; *tail=r; } }
void add(och **head, och **tail, int x) { och *r=new och; r->info=x; r->next=0; if((*head)==0) *head=*tail=r; else { (*tail)->next=r; *tail=r; } }
 { int temp=0; och *r; if((*head)!=0) {if(*head==*tail) {temp=(*head)->info; delete") int del(och **head, och **tail) { int temp=0; och *r; if((*head)!=0) {if(*head==*tail) {temp=(*head)->info; delete (*head); *head=*tail=0; } else {temp=(*head)->info; r=*head; (*head)=(*head)->next; delete r; } return temp; } else return 0; }
int del(och **head, och **tail) { int temp=0; och *r; if((*head)!=0) {if(*head==*tail) {temp=(*head)->info; delete (*head); *head=*tail=0; } else {temp=(*head)->info; r=*head; (*head)=(*head)->next; delete r; } return temp; } else return 0; }
![int _tmain(int argc, _TCHAR* argv[]) { for (int i=1; i<=5; i++) add(&p 1, &p](https://present5.com/presentation/40458383_441578515/image-118.jpg "int _tmain(int argc, _TCHAR* argv[]) { for (int i=1; i<=5; i++) add(&p 1, &p") int _tmain(int argc, _TCHAR* argv[]) { for (int i=1; i<=5; i++) add(&p 1, &p 2, i); printf("OCHERED: "); while(p 1) printf("%3 d", del(&p 1, &p 2)); printf("n"); return 0; }
int _tmain(int argc, _TCHAR* argv[]) { for (int i=1; i<=5; i++) add(&p 1, &p 2, i); printf("OCHERED: "); while(p 1) printf("%3 d", del(&p 1, &p 2)); printf("n"); return 0; }
 Деревья Частный случай многосвязных списков – древовидные структуры или просто деревья. Деревом – называется структура, которая характеризуется следующими свойствами: 1) Существует единственный элемент, или узел, на который не ссылается никакой другой элемент и который называется корнем. 2) Начиная с корня и следуя по определенной цепочке указателей, содержащихся в элементах, можно осуществить доступ к любому элементу структуры.
Деревья Частный случай многосвязных списков – древовидные структуры или просто деревья. Деревом – называется структура, которая характеризуется следующими свойствами: 1) Существует единственный элемент, или узел, на который не ссылается никакой другой элемент и который называется корнем. 2) Начиная с корня и следуя по определенной цепочке указателей, содержащихся в элементах, можно осуществить доступ к любому элементу структуры.
 На каждый элемент кроме корня, имеется единственная ссылка, т. е. каждый элемент адресуется") 3) На каждый элемент кроме корня, имеется единственная ссылка, т. е. каждый элемент адресуется единственным указателем. 4) Узлы могут быть любого типа, за исключением файлового. Линия связи между парой узлов дерева называется ветвью. Те узлы, которые не ссылаются ни на какие другие, называются листьями. Те узлы, которые не являются листьями или корнем, называются узлами ветвления. Исходящие узлы называются предками, входящие – потомками.
3) На каждый элемент кроме корня, имеется единственная ссылка, т. е. каждый элемент адресуется единственным указателем. 4) Узлы могут быть любого типа, за исключением файлового. Линия связи между парой узлов дерева называется ветвью. Те узлы, которые не ссылаются ни на какие другие, называются листьями. Те узлы, которые не являются листьями или корнем, называются узлами ветвления. Исходящие узлы называются предками, входящие – потомками.
 Корень дерева расположен на 1 уровне. Максимальный уровень дерева называется высотой или глубиной.
Корень дерева расположен на 1 уровне. Максимальный уровень дерева называется высотой или глубиной.
 Число потомков – есть степень исхода узла. В определении дерева не накладывалось ограничений на степень исхода. Но на практике чаще всего мы имеем дело с бинарными деревьями. Бинарное дерево – это динамическая структура данных, состоящая из узлов, каждый из которых содержит, кроме данных, не более двух ссылок на различные поддеревья. Такое дерево можно реализовать в виде двухсвязного списка.
Число потомков – есть степень исхода узла. В определении дерева не накладывалось ограничений на степень исхода. Но на практике чаще всего мы имеем дело с бинарными деревьями. Бинарное дерево – это динамическая структура данных, состоящая из узлов, каждый из которых содержит, кроме данных, не более двух ссылок на различные поддеревья. Такое дерево можно реализовать в виде двухсвязного списка.
 #define TREE struct tree TREE { int key; tree *left, *right; }; TREE *t;
#define TREE struct tree TREE { int key; tree *left, *right; }; TREE *t;
 Если дерево организовано таким образом, что для каждого узла все ключи его левого поддерева меньше ключа этого узла, а все ключи его правого поддерева – больше, оно называется деревом поиска. Одинаковых ключей в таком дереве не допускается. В дереве поиска можно найти элемент по значению его ключа, двигаясь от корня и переходя на левое или правое поддерево в зависимости от значения ключа. Такой поиск значительно эффективнее поиска по списку.
Если дерево организовано таким образом, что для каждого узла все ключи его левого поддерева меньше ключа этого узла, а все ключи его правого поддерева – больше, оно называется деревом поиска. Одинаковых ключей в таком дереве не допускается. В дереве поиска можно найти элемент по значению его ключа, двигаясь от корня и переходя на левое или правое поддерево в зависимости от значения ключа. Такой поиск значительно эффективнее поиска по списку.
 Добавление узлов всегда происходит в лист дерева. 12
Добавление узлов всегда происходит в лист дерева. 12
 Важнейшие операции над бинарными деревьями: обход его узлов, добавление и исключение некоторых узлов. Операция обхода используется для систематического последовательного просмотра узлов дерева. Эта операция может быть использована для контроля информации, хранящейся в древовидной структуре, а также как составная часть для выполнения остальных операций над деревом. Для обхода обычно используется одна из следующих трех процедур: обход сверху, обход слева направо и обход снизу.
Важнейшие операции над бинарными деревьями: обход его узлов, добавление и исключение некоторых узлов. Операция обхода используется для систематического последовательного просмотра узлов дерева. Эта операция может быть использована для контроля информации, хранящейся в древовидной структуре, а также как составная часть для выполнения остальных операций над деревом. Для обхода обычно используется одна из следующих трех процедур: обход сверху, обход слева направо и обход снизу.
 Обработка") Каждая из трех процедур включает в себя в различном порядке следующие шаги: 1) Обработка узла дерева (просмотр). 2) Обход левого поддерева обработанного узла. 3) Обход правого поддерева обработанного узла. Если перечисленные шаги выполняются в порядке 1, 2, 3, то это обход сверху. Если шаги выполняются в порядке 2, 1, 3, - это обход слева направо, а в порядке 2, 3, 1 – обход снизу. Обработка на 1 шаге может быть произвольной и заключаться, например, в распечатке ключа узла.
Каждая из трех процедур включает в себя в различном порядке следующие шаги: 1) Обработка узла дерева (просмотр). 2) Обход левого поддерева обработанного узла. 3) Обход правого поддерева обработанного узла. Если перечисленные шаги выполняются в порядке 1, 2, 3, то это обход сверху. Если шаги выполняются в порядке 2, 1, 3, - это обход слева направо, а в порядке 2, 3, 1 – обход снизу. Обработка на 1 шаге может быть произвольной и заключаться, например, в распечатке ключа узла.
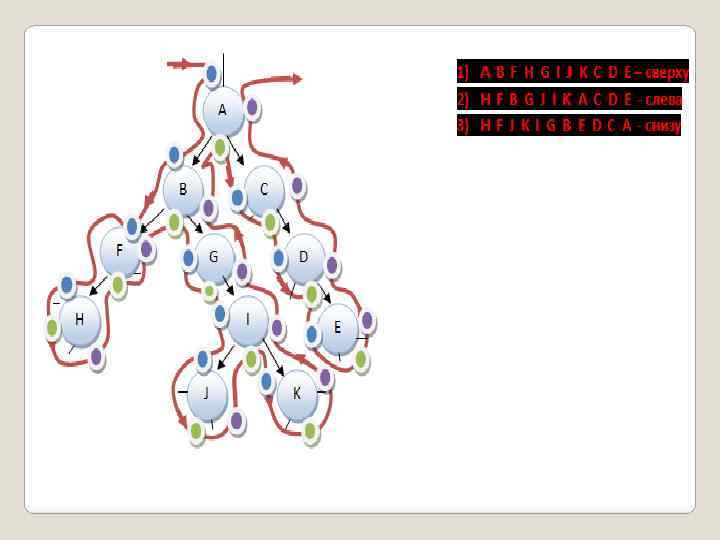
 Дерево является рекурсивной структурой данных, поскольку каждое поддерево также является деревом. Действия с такими структурами изящнее всего описываются с помощью рекурсивных алгоритмов. void display (TREE *s) { if(s) { . . . // Обработка узла display(s->left); // Обход левого поддерева display(s->right); // Обход правого поддерева } }
Дерево является рекурсивной структурой данных, поскольку каждое поддерево также является деревом. Действия с такими структурами изящнее всего описываются с помощью рекурсивных алгоритмов. void display (TREE *s) { if(s) { . . . // Обработка узла display(s->left); // Обход левого поддерева display(s->right); // Обход правого поддерева } }
 Дано дерево поиска. Рассмотрите последовательность вывода узлов. 12
Дано дерево поиска. Рассмотрите последовательность вывода узлов. 12
 Рассмотрим пример создания дерева поиска. #define TREE struct tree TREE { int key; TREE *left, *right; }; TREE *t 1; void insert (TREE **s, TREE *x) {if (*s==0) { *s=new TREE; (*s)->key=x->key; (*s)->left=(*s)->right=0; } else if (x->key<(*s)->key) insert(&(*s)->left, x); else if (x->key>(*s)->key) insert (&(*s)->right, x); }
Рассмотрим пример создания дерева поиска. #define TREE struct tree TREE { int key; TREE *left, *right; }; TREE *t 1; void insert (TREE **s, TREE *x) {if (*s==0) { *s=new TREE; (*s)->key=x->key; (*s)->left=(*s)->right=0; } else if (x->key<(*s)->key) insert(&(*s)->left, x); else if (x->key>(*s)->key) insert (&(*s)->right, x); }
key); display(s->left); display(s->right); } }" src="https://present5.com/presentation/40458383_441578515/image-132.jpg" alt="void display (TREE *s) { if(s) {printf("%4 d ", s->key); display(s->left); display(s->right); } }" />
void display (TREE *s) { if(s) {printf("%4 d ", s->key); display(s->left); display(s->right); } } int main() {int n; TREE *t 2=new TREE; for(n=1; n<=6; n++) { cin>>t 2 ->key; insert(&t 1, t 2); } display(t 1); return 0; }
 { if ((*s 1)->right!=0) delet (&(*s 1)->right); else {q->key=(*s 1)->key;") void delet(TREE **s 1) { if ((*s 1)->right!=0) delet (&(*s 1)->right); else {q->key=(*s 1)->key; q=(*s 1); (*s 1)=(*s 1)->left; } } void del(TREE **s, TREE *x) { if ((*s)!=0) { if (x->key<(*s)->key) del(&(*s)->left, x); else if (x->key>(*s)->key) del (&(*s)->right, x); else
void delet(TREE **s 1) { if ((*s 1)->right!=0) delet (&(*s 1)->right); else {q->key=(*s 1)->key; q=(*s 1); (*s 1)=(*s 1)->left; } } void del(TREE **s, TREE *x) { if ((*s)!=0) { if (x->key<(*s)->key) del(&(*s)->left, x); else if (x->key>(*s)->key) del (&(*s)->right, x); else
 (*s)=q->left; else if (q->left==0) (*s)=q->right; else delet(&q->left); delete q; }}} int") {q=*s; if (q->right==0) (*s)=q->left; else if (q->left==0) (*s)=q->right; else delet(&q->left); delete q; }}} int main() {int n; TREE *t 2=new TREE; for(n=1; n<=6; n++) {scanf("%d", &t 2 ->key); insert(&t 1, t 2); } display(t 1); printf("nvvod uzla dlya udaleniya: "); scanf("%d", &t 2 ->key); del(&t 1, t 2); printf("nderevo 2: "); display(t 1); return 0; }
{q=*s; if (q->right==0) (*s)=q->left; else if (q->left==0) (*s)=q->right; else delet(&q->left); delete q; }}} int main() {int n; TREE *t 2=new TREE; for(n=1; n<=6; n++) {scanf("%d", &t 2 ->key); insert(&t 1, t 2); } display(t 1); printf("nvvod uzla dlya udaleniya: "); scanf("%d", &t 2 ->key); del(&t 1, t 2); printf("nderevo 2: "); display(t 1); return 0; }
. Класс является типом данных определяемым") Объектно-ориентированное программирование Идея классов является основой объектноориентированного программирования (ООП). Класс является типом данных определяемым пользователем. В классе задаются свойства и поведение какоголибо предмета или процесса в виде полей данных (аналогично структуре) и функций для работы с ними (методов).
Объектно-ориентированное программирование Идея классов является основой объектноориентированного программирования (ООП). Класс является типом данных определяемым пользователем. В классе задаются свойства и поведение какоголибо предмета или процесса в виде полей данных (аналогично структуре) и функций для работы с ними (методов).
 Интерфейсом класса являются заголовки его методов. Конкретные величины типа данных «класс» называются экземплярами класса, или объектами. Основными принципами ООП являются: 1. Инкапсуляция; 2. Наследование; 3. Полиморфизм.
Интерфейсом класса являются заголовки его методов. Конкретные величины типа данных «класс» называются экземплярами класса, или объектами. Основными принципами ООП являются: 1. Инкапсуляция; 2. Наследование; 3. Полиморфизм.
 Описание класса Класс является абстрактным типом данных, определяемым пользователем, и представляет собой модель реального объекта в виде данных и функций для работы с ними. Данные класса называются полями (свойствами), а функции класса — методами. Поля и методы называются элементами класса.
Описание класса Класс является абстрактным типом данных, определяемым пользователем, и представляет собой модель реального объекта в виде данных и функций для работы с ними. Данные класса называются полями (свойствами), а функции класса — методами. Поля и методы называются элементами класса.
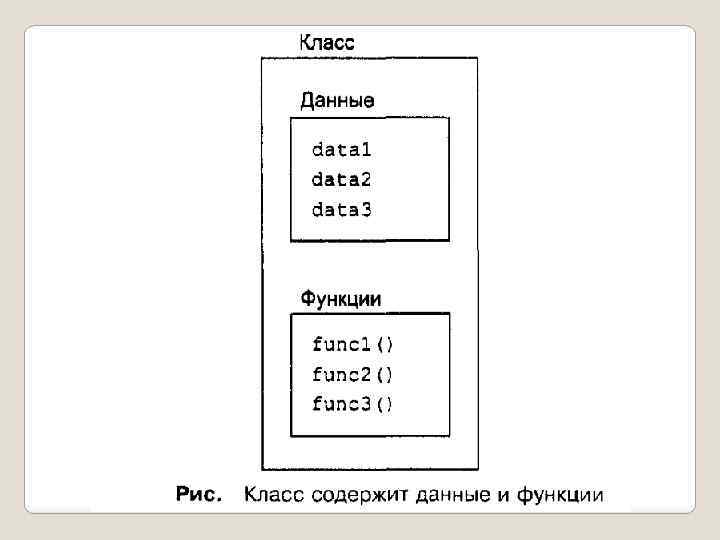
 При описании класса реализуется один из ключевых понятий ООП - инкапсуляция. Для начала приведу формальное определение этого понятия: Инкапсуляция - это механизм, который объединяет данные и методы, манипулирующие этими данными, и защищает и то и другое от внешнего вмешательства или неправильного использования. Когда методы и данные объединяются таким способом, создается объект.
При описании класса реализуется один из ключевых понятий ООП - инкапсуляция. Для начала приведу формальное определение этого понятия: Инкапсуляция - это механизм, который объединяет данные и методы, манипулирующие этими данными, и защищает и то и другое от внешнего вмешательства или неправильного использования. Когда методы и данные объединяются таким способом, создается объект.
![Описание класса выглядит так: class <имя>{ [ private: ] <описание скрытых элементов> public: <описание](https://present5.com/presentation/40458383_441578515/image-140.jpg "Описание класса выглядит так: class <имя>{ [ private: ] <описание скрытых элементов> public: <описание") Описание класса выглядит так: class <имя>{ [ private: ] <описание скрытых элементов> public: <описание доступных элементов> } ; Где спецификаторы доступа private и publiс управляют видимостью элементов класса. Элементы, описанные после служебного слова private, видимы только внутри класса. Этот вид доступа принят в классе по умолчанию.
Описание класса выглядит так: class <имя>{ [ private: ] <описание скрытых элементов> public: <описание доступных элементов> } ; Где спецификаторы доступа private и publiс управляют видимостью элементов класса. Элементы, описанные после служебного слова private, видимы только внутри класса. Этот вид доступа принят в классе по умолчанию.
 Термин private понимается в том смысле, что данные заключены внутри класса и защищены от несанкционированного доступа функций, расположенных вне класса. Такие данные доступны только внутри класса. Данные, описанные ключевым словом publiс, напротив, доступны за пределами класса.
Термин private понимается в том смысле, что данные заключены внутри класса и защищены от несанкционированного доступа функций, расположенных вне класса. Такие данные доступны только внутри класса. Данные, описанные ключевым словом publiс, напротив, доступны за пределами класса.

 Поля класса: • могут иметь любой тип, кроме типа этого же класса (но могут быть указателями или ссылками на этот класс); • могут быть описаны с модификатором const, при этом они инициализируются только один раз (с помощью конструктора) и не могут изменяться. Инициализация полей при описании не допускается. Методы класса – это функции входящие в состав класса.
Поля класса: • могут иметь любой тип, кроме типа этого же класса (но могут быть указателями или ссылками на этот класс); • могут быть описаны с модификатором const, при этом они инициализируются только один раз (с помощью конструктора) и не могут изменяться. Инициализация полей при описании не допускается. Методы класса – это функции входящие в состав класса.
 Описание объектов Конкретные переменные типа «класс» называются экземплярами класса, или объектами. Время жизни и видимость объектов зависит от вида и места их описания и подчиняется общим правилам С++. Формат: class <имя> переменная; Замечание: Объект находится в таком же отношении к своему классу, в каком переменная находится по отношению к своему типу.
Описание объектов Конкретные переменные типа «класс» называются экземплярами класса, или объектами. Время жизни и видимость объектов зависит от вида и места их описания и подчиняется общим правилам С++. Формат: class <имя> переменная; Замечание: Объект находится в таком же отношении к своему классу, в каком переменная находится по отношению к своему типу.
: 1) Точка характеризуется координатами: Х и У") Пример1. Рассмотрим пример описания класса TPoint (точка): 1) Точка характеризуется координатами: Х и У – это свойства объекта; 2) Над точкой можно выполнять следующие действия: - можно задать её координаты; - точку можно переместить (изменив координаты); - можно получить координаты точки.
Пример1. Рассмотрим пример описания класса TPoint (точка): 1) Точка характеризуется координатами: Х и У – это свойства объекта; 2) Над точкой можно выполнять следующие действия: - можно задать её координаты; - точку можно переместить (изменив координаты); - можно получить координаты точки.
 #include "stdafx. h " class TPoint { private: int x, y; public: void Init. Point ( int newx, int newy) { x = newx; y = newy ; } void relmove ( int dx, int dy ) {x+= dx; y += dy ; } int getx ( void ) { return x ; } int gety ( void ) { return y ; } };
#include "stdafx. h " class TPoint { private: int x, y; public: void Init. Point ( int newx, int newy) { x = newx; y = newy ; } void relmove ( int dx, int dy ) {x+= dx; y += dy ; } int getx ( void ) { return x ; } int gety ( void ) { return y ; } };
 { class TPoint p; p. Init. Point(10, 10); printf(") int main() { class TPoint p; p. Init. Point(10, 10); printf("x=%d, y=%dn", p. getx(), p. gety()); p. relmove(5, 10); printf("x=%d, y=%dn", p. getx(), p. gety()); return 0; } В этом классе два скрытых поля — x и y, получить значения которых извне можно с помощью методов getx() и gety(). Все методы класса имеют непосредственный доступ к его скрытым полям.
int main() { class TPoint p; p. Init. Point(10, 10); printf("x=%d, y=%dn", p. getx(), p. gety()); p. relmove(5, 10); printf("x=%d, y=%dn", p. getx(), p. gety()); return 0; } В этом классе два скрытых поля — x и y, получить значения которых извне можно с помощью методов getx() и gety(). Все методы класса имеют непосредственный доступ к его скрытым полям.
 и локальными (объявленными внутри блока, например,") Классы могут быть глобальными (объявленными вне любого блока) и локальными (объявленными внутри блока, например, функции или другого класса). МЕТОДЫ КЛАССА Вызов методов класса При вызове методов необходимо связать метод с объектом этого класса. Поэтому имена объектов ( p ) связаны с именем функции (метода) операцией точка (. ): p. Init. Point(10, 10); p. relmove(5, 10); Замечание: Это напоминает доступ к полям структуры.
Классы могут быть глобальными (объявленными вне любого блока) и локальными (объявленными внутри блока, например, функции или другого класса). МЕТОДЫ КЛАССА Вызов методов класса При вызове методов необходимо связать метод с объектом этого класса. Поэтому имена объектов ( p ) связаны с именем функции (метода) операцией точка (. ): p. Init. Point(10, 10); p. relmove(5, 10); Замечание: Это напоминает доступ к полям структуры.
 и relmove() приводило к изменению значений полей Х и У.") Вызов методов Init. Point() и relmove() приводило к изменению значений полей Х и У. В следующем примере задание полей в методе Vvod() будет осуществляться с клавиатуры: class TPoint { private: int x, y; public: void Init. Point ( int newx, int newy) { x = newx; y = newy ; } void Vvod() {printf("Vvedi X Y: "); scanf("%d%d", &x, &y); }. . . }; Тогда вызов этого метода будет: p. Vvod();
Вызов методов Init. Point() и relmove() приводило к изменению значений полей Х и У. В следующем примере задание полей в методе Vvod() будет осуществляться с клавиатуры: class TPoint { private: int x, y; public: void Init. Point ( int newx, int newy) { x = newx; y = newy ; } void Vvod() {printf("Vvedi X Y: "); scanf("%d%d", &x, &y); }. . . }; Тогда вызов этого метода будет: p. Vvod();
 Конструкторы B отличии от предыдущего примера удобнее инициализировать поля объекта автоматически в момент его создания, а не явно вызовом соответствующего метода. Такой способ реализуется с помощью особого метода класса, называемого конструктором. Конструктор - это метод, выполняющийся автоматически в момент создания объекта. Конструктор отличается от других методов: 1) Имя конструктора совпадает с именем класса; 2) У конструктора не существует возвращаемого значения.
Конструкторы B отличии от предыдущего примера удобнее инициализировать поля объекта автоматически в момент его создания, а не явно вызовом соответствующего метода. Такой способ реализуется с помощью особого метода класса, называемого конструктором. Конструктор - это метод, выполняющийся автоматически в момент создания объекта. Конструктор отличается от других методов: 1) Имя конструктора совпадает с именем класса; 2) У конструктора не существует возвращаемого значения.
 // конструктор") class TPoint { private: int x, y; public: TPoint(int newx, int newy) // конструктор {x=newx; y=newy; } void relmove ( int dx, int dy ) {x+= dx; y += dy ; } int getx ( void ) { return x ; } int gety ( void ) { return y ; } }; int main(int argc, char *argv[]) { class TPoint p(10, 10); //инициализация объекта р printf("x=%d, y=%dn", p. getx(), p. gety()); …}
class TPoint { private: int x, y; public: TPoint(int newx, int newy) // конструктор {x=newx; y=newy; } void relmove ( int dx, int dy ) {x+= dx; y += dy ; } int getx ( void ) { return x ; } int gety ( void ) { return y ; } }; int main(int argc, char *argv[]) { class TPoint p(10, 10); //инициализация объекта р printf("x=%d, y=%dn", p. getx(), p. gety()); …}
 Пример 2. В качестве примера создадим класс Counter, объекты которого могут хранить количественную меру какой-либо изменяющейся величины. При наступлении некоторого события счетчик увеличивается на единицу. Обращение к счетчику происходит, как правило, для того, чтобы узнать текущее значение той величины, для изменения которой он предназначен.
Пример 2. В качестве примера создадим класс Counter, объекты которого могут хранить количественную меру какой-либо изменяющейся величины. При наступлении некоторого события счетчик увеличивается на единицу. Обращение к счетчику происходит, как правило, для того, чтобы узнать текущее значение той величины, для изменения которой он предназначен.
: count(0){ } void inc_count") class Counter { private: int count; public: Counter ( ): count(0){ } void inc_count ( ) {count++; } int get_count( ) { return count; } }; int _tmain(int argc, _TCHAR* argv[]) { Counter c 1, c 2; std: : cout<
class Counter { private: int count; public: Counter ( ): count(0){ } void inc_count ( ) {count++; } int get_count( ) { return count; } }; int _tmain(int argc, _TCHAR* argv[]) { Counter c 1, c 2; std: : cout<
 Одной из наиболее часто возлагаемых на конструктор задач является инициализация полей объекта. Инициализация полей обычно реализуется с помощью списка инициализации, который располагается между заголовком и телом функции-конструктора. После заголовка ставится двоеточие. Инициализирующие значения помещены в круглые скобки после имени поля. Counter ( ): count(0) {/* тело функции*/ } Если инициализируются несколько полей, то значения разделяются запятыми.
Одной из наиболее часто возлагаемых на конструктор задач является инициализация полей объекта. Инициализация полей обычно реализуется с помощью списка инициализации, который располагается между заголовком и телом функции-конструктора. После заголовка ставится двоеточие. Инициализирующие значения помещены в круглые скобки после имени поля. Counter ( ): count(0) {/* тело функции*/ } Если инициализируются несколько полей, то значения разделяются запятыми.
 Деструкторы Кроме специального метода конструктор, который вызывается при создании объекта, существует другой особый метод, автоматически вызываемый при уничтожении объекта, называемый деструктором. Деструктор имеет имя, совпадающее с именем конструктора, перед которым стоит тильда ~. class Prim { private: int dat; public: Prim(): dat(0) { } ~Prim() { } };
Деструкторы Кроме специального метода конструктор, который вызывается при создании объекта, существует другой особый метод, автоматически вызываемый при уничтожении объекта, называемый деструктором. Деструктор имеет имя, совпадающее с именем конструктора, перед которым стоит тильда ~. class Prim { private: int dat; public: Prim(): dat(0) { } ~Prim() { } };
 Наиболее распространённое применение деструкторов – освобождение памяти, выделенной конструктором при создании объекта. Определение методов может быть реализовано как внутри самого класса, так и вне класса. Во втором случае внутри класса содержится лишь прототип функции, а сама функция определяется позже. Тогда перед именем функции указывается имя класса и символ : :
Наиболее распространённое применение деструкторов – освобождение памяти, выделенной конструктором при создании объекта. Определение методов может быть реализовано как внутри самого класса, так и вне класса. Во втором случае внутри класса содержится лишь прототип функции, а сама функция определяется позже. Тогда перед именем функции указывается имя класса и символ : :
 {x=newx; y=newy;") class TPoint { private: int x, y; public: TPoint(int newx, int newy) {x=newx; y=newy; } void relmove ( int dx, int dy ); int getx ( void ) { return x ; } int gety ( void ) { return y ; } ~Tpoint( ) { } }; void TPoint: : relmove(int dx, int dy) {x+= dx; y += dy ; }
class TPoint { private: int x, y; public: TPoint(int newx, int newy) {x=newx; y=newy; } void relmove ( int dx, int dy ); int getx ( void ) { return x ; } int gety ( void ) { return y ; } ~Tpoint( ) { } }; void TPoint: : relmove(int dx, int dy) {x+= dx; y += dy ; }
Класс может иметь несколько конструкторов с разными параметрами для разных видов инициализации. 2)Конструктор,") ЗАМЕЧАНИЯ: 1)Класс может иметь несколько конструкторов с разными параметрами для разных видов инициализации. 2)Конструктор, вызываемый без параметров, называется конструктором по умолчанию. 3)Деструктор вызывается автоматически, когда объект выходит из области видимости: • для локальных объектов — при выходе из блока, в котором они объявлены; • для глобальных — как часть процедуры выхода из main( ); • для объектов, заданных через указатели деструктор вызывается неявно при использовании операции delete.
ЗАМЕЧАНИЯ: 1)Класс может иметь несколько конструкторов с разными параметрами для разных видов инициализации. 2)Конструктор, вызываемый без параметров, называется конструктором по умолчанию. 3)Деструктор вызывается автоматически, когда объект выходит из области видимости: • для локальных объектов — при выходе из блока, в котором они объявлены; • для глобальных — как часть процедуры выхода из main( ); • для объектов, заданных через указатели деструктор вызывается неявно при использовании операции delete.
 Деструктор: • не имеет аргументов и возвращаемого значения; • не может быть объявлен как const или static; • не наследуется; • может быть виртуальным. Вернемся к примеру 2, где был создан class Counter. При решении разных задач может возникнуть необходимость инициализации счетчика разными значениями, а не только нулем. Для этого создадим еще один конструктор.
Деструктор: • не имеет аргументов и возвращаемого значения; • не может быть объявлен как const или static; • не наследуется; • может быть виртуальным. Вернемся к примеру 2, где был создан class Counter. При решении разных задач может возникнуть необходимость инициализации счетчика разными значениями, а не только нулем. Для этого создадим еще один конструктор.
: count(0){ } Counter (int") class Counter { private: int count; public: Counter ( ): count(0){ } Counter (int c): count(c){ } void inc_count ( ) {count++; } int get_count( ) { return count; } ~Counter( ){} }; int _tmain(int argc, _TCHAR* argv[]) { Counter c 1, c 2(3); std: : cout<
class Counter { private: int count; public: Counter ( ): count(0){ } Counter (int c): count(c){ } void inc_count ( ) {count++; } int get_count( ) { return count; } ~Counter( ){} }; int _tmain(int argc, _TCHAR* argv[]) { Counter c 1, c 2(3); std: : cout<
 Наследование – это процесс создания новых классов, называемых наследниками или производными классами, из уже существующих или базовых классов. Производный класс получает все возможности базового класса, но может также быть усовершенствован за счет добавления собственных. Наследование – важная часть ООП. Выигрыш от него состоит в том, что наследование позволяет использовать существующий код несколько раз.
Наследование – это процесс создания новых классов, называемых наследниками или производными классами, из уже существующих или базовых классов. Производный класс получает все возможности базового класса, но может также быть усовершенствован за счет добавления собственных. Наследование – важная часть ООП. Выигрыш от него состоит в том, что наследование позволяет использовать существующий код несколько раз.
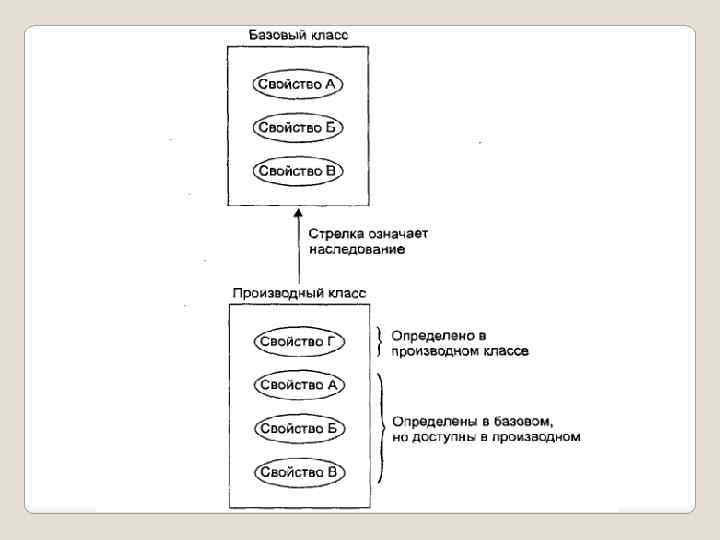
 Простым называется наследование, при котором производный класс имеет одного родителя. Формат описания производного класса: В заголовке производного класса через двоеточие (: ) указывается имя родительского класса. сlass имя_класса : <спецификатор доступа> имя_базоваго_класса { объявление элементов класса }; При описании производного класса надо помнить, что поля и методы родительского класса могут быть унаследованы!!!
Простым называется наследование, при котором производный класс имеет одного родителя. Формат описания производного класса: В заголовке производного класса через двоеточие (: ) указывается имя родительского класса. сlass имя_класса : <спецификатор доступа> имя_базоваго_класса { объявление элементов класса }; При описании производного класса надо помнить, что поля и методы родительского класса могут быть унаследованы!!!
 Рассмотрим правила наследования различных методов: Конструкторы не наследуются, поэтому производный класс должен иметь собственные конструкторы. Если в конструкторе производного класса явный вызов конструктора базового класса отсутствует, автоматически вызывается конструктор базового класса по умолчанию. Деструкторы также не наследуются, и если программист не описал в производном классе деструктор, он формируется по умолчанию. Остальные методы могут наследоваться или
Рассмотрим правила наследования различных методов: Конструкторы не наследуются, поэтому производный класс должен иметь собственные конструкторы. Если в конструкторе производного класса явный вызов конструктора базового класса отсутствует, автоматически вызывается конструктор базового класса по умолчанию. Деструкторы также не наследуются, и если программист не описал в производном классе деструктор, он формируется по умолчанию. Остальные методы могут наследоваться или
 Поля, унаследованные из родительского класса, и которые определены в базовом классе как private, недоступны функциям производного класса. Если они должны использоваться функциям, определенным в производном классе, можно либо описать их в базовом классе как protected, либо явно переопределить их в производном классе. Вернемся к примеру счетчиков. Предположим, что нам понадобился метод, уменьшающий значение счетчика. Разработаем новый класс Count. Down.
Поля, унаследованные из родительского класса, и которые определены в базовом классе как private, недоступны функциям производного класса. Если они должны использоваться функциям, определенным в производном классе, можно либо описать их в базовом классе как protected, либо явно переопределить их в производном классе. Вернемся к примеру счетчиков. Предположим, что нам понадобился метод, уменьшающий значение счетчика. Разработаем новый класс Count. Down.
: count(0){ } Counter(int c):") class Counter { protected: int count; public: Counter ( ): count(0){ } Counter(int c): count(c){ } void inc_count ( ) {count++; } int get_count( ) { return count; } }; class Count. Down: public Counter { public: void dec_count ( ) {count--; } }; Новый класс наследует: поле count и методы get_count( ) и inc_count().
class Counter { protected: int count; public: Counter ( ): count(0){ } Counter(int c): count(c){ } void inc_count ( ) {count++; } int get_count( ) { return count; } }; class Count. Down: public Counter { public: void dec_count ( ) {count--; } }; Новый класс наследует: поле count и методы get_count( ) и inc_count().
![int main(int argc, char *argv[]) { Counter c 1, c 2(3); Count. Down c](https://present5.com/presentation/40458383_441578515/image-168.jpg "int main(int argc, char *argv[]) { Counter c 1, c 2(3); Count. Down c") int main(int argc, char *argv[]) { Counter c 1, c 2(3); Count. Down c 3; std: : cout<
int main(int argc, char *argv[]) { Counter c 1, c 2(3); Count. Down c 3; std: : cout<
; Но можно применять и") Для объекта c 3 доступен новый метод: c 3. dec_count(); Но можно применять и унаследованные методы, например: std: : cout<
Для объекта c 3 доступен новый метод: c 3. dec_count(); Но можно применять и унаследованные методы, например: std: : cout<
 Поэтому, если возникает необходимость инициализации объекта с3 каким-либо другим значением, мы должны написать новый конструктор: class Count. Down: public Counter //определение класса { public: Count. Down ( ): Counter(0){ } Count. Down(int c): Counter(c){ } void dec_count ( ) {count--; } }; Так как действия в конструкторах базового и производного классов совпадают, то мы подключаем вызов конструкторов базового класса, для выполнения нужных действий.
Поэтому, если возникает необходимость инициализации объекта с3 каким-либо другим значением, мы должны написать новый конструктор: class Count. Down: public Counter //определение класса { public: Count. Down ( ): Counter(0){ } Count. Down(int c): Counter(c){ } void dec_count ( ) {count--; } }; Так как действия в конструкторах базового и производного классов совпадают, то мы подключаем вызов конструкторов базового класса, для выполнения нужных действий.
 Иерархия классов На основе принципа наследования может быть построена иерархия классов. Рассмотрим пример базы данных служащих некоторой компании. В ней существует три категории служащих: менеджеры, занимающиеся продажами, ученые, занимающиеся исследованиями и рабочие, занятые изготовлением товаров. Иерархия будет состоять из базового типа: employee и трех производных классов: manager, scientist и laborer.
Иерархия классов На основе принципа наследования может быть построена иерархия классов. Рассмотрим пример базы данных служащих некоторой компании. В ней существует три категории служащих: менеджеры, занимающиеся продажами, ученые, занимающиеся исследованиями и рабочие, занятые изготовлением товаров. Иерархия будет состоять из базового типа: employee и трех производных классов: manager, scientist и laborer.
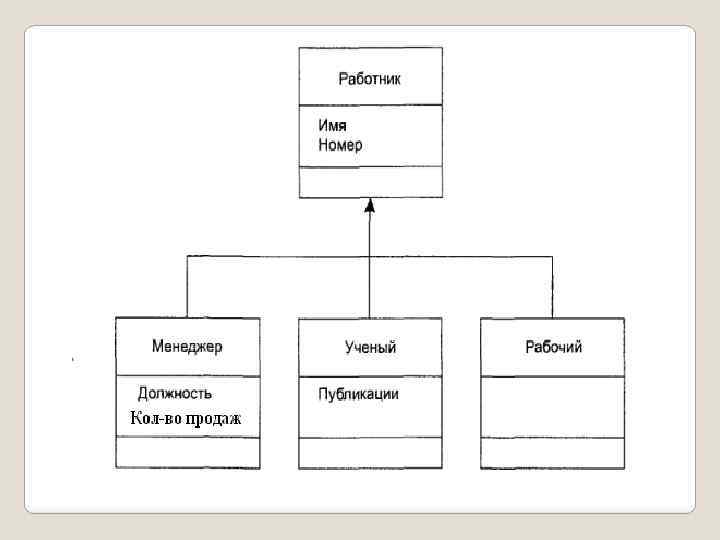
 #include
#include
![class manager: public employee { private: char title[len]; int kol; public: void getdata() {](https://present5.com/presentation/40458383_441578515/image-174.jpg "class manager: public employee { private: char title[len]; int kol; public: void getdata() {") class manager: public employee { private: char title[len]; int kol; public: void getdata() { employee: : getdata(); cout<<"vvod dolgnosty: "; cin>>title; cout<<"vvod kolvo: "; cin>>kol; } void putdata() { employee: : putdata(); cout<<"n dolgnosty: "<
class manager: public employee { private: char title[len]; int kol; public: void getdata() { employee: : getdata(); cout<<"vvod dolgnosty: "; cin>>title; cout<<"vvod kolvo: "; cin>>kol; } void putdata() { employee: : putdata(); cout<<"n dolgnosty: "<
 { employee:") class scientist: public employee { private: int pubs; public: void getdata() { employee: : getdata(); cout<<"vvod kolva pubs: "; cin>>pubs; } void putdata() { employee: : putdata(); cout<<"n publication: "<
class scientist: public employee { private: int pubs; public: void getdata() { employee: : getdata(); cout<<"vvod kolva pubs: "; cin>>pubs; } void putdata() { employee: : putdata(); cout<<"n publication: "<
![int main(int argc, char *argv[]) { employee x; manager y; scientist z; laborer w;](https://present5.com/presentation/40458383_441578515/image-176.jpg "int main(int argc, char *argv[]) { employee x; manager y; scientist z; laborer w;") int main(int argc, char *argv[]) { employee x; manager y; scientist z; laborer w; cout<<"vvod svedenij o 4 sotrudnikax: n"; x. getdata(); y. getdata(); z. getdata(); w. getdata(); cout<<"vivod information about sotrudnikax: n"; x. putdata(); y. putdata(); z. putdata(); w. putdata(); return 0; }
int main(int argc, char *argv[]) { employee x; manager y; scientist z; laborer w; cout<<"vvod svedenij o 4 sotrudnikax: n"; x. getdata(); y. getdata(); z. getdata(); w. getdata(); cout<<"vivod information about sotrudnikax: n"; x. putdata(); y. putdata(); z. putdata(); w. putdata(); return 0; }
 Производный класс может являться базовым для других производных классов. Например: class A { … }; class B: public A { …}; class C: public B {…}; Здесь класс B является производным класса А, а класс С производным класса B.
Производный класс может являться базовым для других производных классов. Например: class A { … }; class B: public A { …}; class C: public B {…}; Здесь класс B является производным класса А, а класс С производным класса B.
 Класс может являться производным как одного базового класса, так и нескольких базовых классов (множественное наследование). Например: class A { … }; class B { …}; class C: public A, public B {…}; Базовые классы перечисляются через запятую после знака :
Класс может являться производным как одного базового класса, так и нескольких базовых классов (множественное наследование). Например: class A { … }; class B { …}; class C: public A, public B {…}; Базовые классы перечисляются через запятую после знака :
 Работа с объектами чаще всего производится через указатели, например: employee *р; Указателю на базовый класс можно присвоить значение адреса объекта любого производного класса: р = new laborer; или p=&y; Где y описана, как: manager y; Обращение к методу через указатель имеет вид: p->getdata(); P->putdata();
Работа с объектами чаще всего производится через указатели, например: employee *р; Указателю на базовый класс можно присвоить значение адреса объекта любого производного класса: р = new laborer; или p=&y; Где y описана, как: manager y; Обращение к методу через указатель имеет вид: p->getdata(); P->putdata();
 Виртуальные методы. Полиморфизм — один из важнейших механизмов ООП. Полиморфизм реализуется с помощью наследования классов и виртуальных методов. Полиморфизм состоит в том, что с помощью одного и того же обращения к методу выполняются различные действия в зависимости от типа, на который ссылается указатель в каждый момент времени. Рассмотрим пример иерархии классов, где каждый класс имеет метод с одним именем.
Виртуальные методы. Полиморфизм — один из важнейших механизмов ООП. Полиморфизм реализуется с помощью наследования классов и виртуальных методов. Полиморфизм состоит в том, что с помощью одного и того же обращения к методу выполняются различные действия в зависимости от типа, на который ссылается указатель в каждый момент времени. Рассмотрим пример иерархии классов, где каждый класс имеет метод с одним именем.
 { cout<<“Родительn") class Base { public: void show() { cout<<“Родительn"; } }; class derv 1: public base {public: void show() { cout<<"Сын первыйn"; } };
class Base { public: void show() { cout<<“Родительn"; } }; class derv 1: public base {public: void show() { cout<<"Сын первыйn"; } };
 { cout<<") class derv 2: public base {public: void show() { cout<<"Сын второйn"; } }; int main(int argc, char *argv[]) { derv 1 s 1; derv 2 s 2; Base *ptr; ptr=&s 1; ptr->show(); ptr=&s 2; ptr->show(); …
class derv 2: public base {public: void show() { cout<<"Сын второйn"; } }; int main(int argc, char *argv[]) { derv 1 s 1; derv 2 s 2; Base *ptr; ptr=&s 1; ptr->show(); ptr=&s 2; ptr->show(); …
 Итак, классы derv 1 и derv 2 являются наследниками класса Base. В каждом из трех классов имеется метод show(). В main() созданы объекты порожденных классов s 1 и s 2 и указатель на класс Base. Затем адрес объекта порожденного класса мы заносим в указатель базового класса: ptr=&s 1; Какая же функция будет выполняться в следующей строке: ptr->show(); Base: : show( ) илиderv 1: : show( )? В этом случае компилятор выбирает метод удовлетворяющий типу указателя (Base: : show())
Итак, классы derv 1 и derv 2 являются наследниками класса Base. В каждом из трех классов имеется метод show(). В main() созданы объекты порожденных классов s 1 и s 2 и указатель на класс Base. Затем адрес объекта порожденного класса мы заносим в указатель базового класса: ptr=&s 1; Какая же функция будет выполняться в следующей строке: ptr->show(); Base: : show( ) илиderv 1: : show( )? В этом случае компилятор выбирает метод удовлетворяющий типу указателя (Base: : show())
 Этот процесс , называется ранним связыванием.
Этот процесс , называется ранним связыванием.
 В C++ реализован механизм позднего связывания, когда разрешение ссылок на метод происходит на этапе выполнения программы в зависимости от конкретного типа объекта, вызвавшего метод. Этот механизм реализован с помощью виртуальных методов. Для определения виртуального метода используется спецификатор virtual, например: class base { public: virtual void show() { cout<<"basen"; } };
В C++ реализован механизм позднего связывания, когда разрешение ссылок на метод происходит на этапе выполнения программы в зависимости от конкретного типа объекта, вызвавшего метод. Этот механизм реализован с помощью виртуальных методов. Для определения виртуального метода используется спецификатор virtual, например: class base { public: virtual void show() { cout<<"basen"; } };
 Этот процесс , называется поздним связыванием.
Этот процесс , называется поздним связыванием.
 Если в базовом классе метод определен как виртуальный, метод, определенный в производном классе с тем же именем и набором параметров, автоматически становится виртуальным, а с отличающимся набором параметров — обычным. Для каждого класса (не объекта!), содержащего хотя бы один виртуальный метод, компилятор создает таблицу виртуальных методов (vtbl), в которой для каждого виртуального метода записан его адрес в памяти.
Если в базовом классе метод определен как виртуальный, метод, определенный в производном классе с тем же именем и набором параметров, автоматически становится виртуальным, а с отличающимся набором параметров — обычным. Для каждого класса (не объекта!), содержащего хотя бы один виртуальный метод, компилятор создает таблицу виртуальных методов (vtbl), в которой для каждого виртуального метода записан его адрес в памяти.
 Рекомендуется делать виртуальными деструкторы для того, чтобы гарантировать правильное освобождение памяти из-под динамического объекта, поскольку в этом случае в любой момент времени будет выбран деструктор, соответствующий фактическому типу объекта. Деструктор передает операции delete размер объекта.
Рекомендуется делать виртуальными деструкторы для того, чтобы гарантировать правильное освобождение памяти из-под динамического объекта, поскольку в этом случае в любой момент времени будет выбран деструктор, соответствующий фактическому типу объекта. Деструктор передает операции delete размер объекта.
 Обзор стандартных библиотек С++ Развитие объектно - ориентированного программирования привело к созданию широкого набора библиотек. Библиотека STL/CLR представляет собой упакованную библиотеку стандартных шаблонов (STL), входящую в состав стандартной библиотеки C++.
Обзор стандартных библиотек С++ Развитие объектно - ориентированного программирования привело к созданию широкого набора библиотек. Библиотека STL/CLR представляет собой упакованную библиотеку стандартных шаблонов (STL), входящую в состав стандартной библиотеки C++.
: определяет вычислительную процедуру. контейнер (container): управляет") Библиотека содержит пять основных видов компонентов: алгоритм (algorithm): определяет вычислительную процедуру. контейнер (container): управляет набором объектов в памяти. итератор (iterator): обеспечивает для алгоритма средство доступа к содержимому контейнера. функциональный объект (function object): инкапсулирует функцию в объекте для использования другими компонентами. адаптер (adaptor): адаптирует компонент для обеспечения различного интерфейса.
Библиотека содержит пять основных видов компонентов: алгоритм (algorithm): определяет вычислительную процедуру. контейнер (container): управляет набором объектов в памяти. итератор (iterator): обеспечивает для алгоритма средство доступа к содержимому контейнера. функциональный объект (function object): инкапсулирует функцию в объекте для использования другими компонентами. адаптер (adaptor): адаптирует компонент для обеспечения различного интерфейса.
 Контейнеры – это") Алгоритмы реализуют большинство методов сортировки, поиска и т. п. (
Алгоритмы реализуют большинство методов сортировки, поиска и т. п. ( , очереди
 Рассмотрим основные методы класса stack: push - метод для добавления элемента в стек. pop – удаляет элемент из стека, но не возвращает удаленное значение. top – возвращает значение с вершины стека. empty – проверяет наличие элементов в стеке.
Рассмотрим основные методы класса stack: push - метод для добавления элемента в стек. pop – удаляет элемент из стека, но не возвращает удаленное значение. top – возвращает значение с вершины стека. empty – проверяет наличие элементов в стеке.
 #include
#include
 Библиотека ATL расшифровывается как Active Template Library. Это библиотека классов и шаблонов, предназначенная для разработки собственных компонетов. Одно из применений этой библиотеки - это создание собственных элементов Active. X. Например, с помощью библиотеки ATL вы можете создать собственную особую кнопку (скажем, круглую) и затем использовать ее в программах. Библиотека MFC (Microsoft Foundation Classes) предназначена в основном для создания приложений с пользовательским интерфейсом (окна, диалоги и т. п. ).
Библиотека ATL расшифровывается как Active Template Library. Это библиотека классов и шаблонов, предназначенная для разработки собственных компонетов. Одно из применений этой библиотеки - это создание собственных элементов Active. X. Например, с помощью библиотеки ATL вы можете создать собственную особую кнопку (скажем, круглую) и затем использовать ее в программах. Библиотека MFC (Microsoft Foundation Classes) предназначена в основном для создания приложений с пользовательским интерфейсом (окна, диалоги и т. п. ).
 Библиотека MFC инкапсулирует многие функции API (Application Programming Interfase),") Afx. Message. Box ( ) Библиотека MFC инкапсулирует многие функции API (Application Programming Interfase), с помощью которых реализуются все необходимые системные действия, такие как выделение памяти, вывод на экран, создание окон и т. п. Библиотека MFC разрабатывалась для упрощения задач, стоящих перед программистом. Кроме этого в языке С++ имеются библиотеки для параллельного программирования: Concurrency Runtime для С++ и Open. MP (Open Multi-Processing).
Afx. Message. Box ( ) Библиотека MFC инкапсулирует многие функции API (Application Programming Interfase), с помощью которых реализуются все необходимые системные действия, такие как выделение памяти, вывод на экран, создание окон и т. п. Библиотека MFC разрабатывалась для упрощения задач, стоящих перед программистом. Кроме этого в языке С++ имеются библиотеки для параллельного программирования: Concurrency Runtime для С++ и Open. MP (Open Multi-Processing).
 Библиотека классов . NET Framework имеет следующие возможности: § библиотека базовых классов, такие как строки, массивы и элементы форматирования; § передача данных по сети; § система безопасности; § удаленная обработка; § диагностика; § ввод/вывод; § базы данных; § язык ХМL; § Web-программирование; § пользовательский интерфейс ОС Windows.
Библиотека классов . NET Framework имеет следующие возможности: § библиотека базовых классов, такие как строки, массивы и элементы форматирования; § передача данных по сети; § система безопасности; § удаленная обработка; § диагностика; § ввод/вывод; § базы данных; § язык ХМL; § Web-программирование; § пользовательский интерфейс ОС Windows.
 Если мы захотим создать Windows – приложение с помощью технологии. NET, то открыв Visual Studio, и выбрав Файл -> Создать -> Проект, выбираем пункт CLR, отмечаем Приложение Windows Forms и даем имя проекта:
Если мы захотим создать Windows – приложение с помощью технологии. NET, то открыв Visual Studio, и выбрав Файл -> Создать -> Проект, выбираем пункт CLR, отмечаем Приложение Windows Forms и даем имя проекта:
 СПАСИБО за ВНИМАНИЕ FIN
СПАСИБО за ВНИМАНИЕ FIN