Сверточные коды.ppt
- Количество слайдов: 26



Сверточные коды Блочные коды являются одним из двух видов кодов с коррекцией ошибок, широко используемых при беспроводной передаче. Второй вид – это сверточные коды. Блочный код (n, k) обрабатывает данные блоками по k бит, генерируя на выходе блок из n бит (n > k) для каждого k -битового блока на входе. Если прием и передача данных происходят относительно непрерывным потоком то блочный код (в частности, с большим значением n) может быть не так удобен как код, который генерирует избыточные биты непрерывно. В последнем случае обнаружение и исправление ошибок выполняется непрерывно, и именно в этом состоит преимущество сверточных кодов. Сверточный код задается тремя параметрами: n, k и К. Код (n, k, К) обрабатывает входящие данные порциями по k бит и генерирует выходную последовательность, состоящую из n бит для каждых k бит входа. До этого момента принципы работы сверточных и блочных кодов не отличаются. Для сверточных кодов n и k, как правило, являются очень малыми числами. Разница между двумя типами кодов состоит в том, что сверточные коды используют память, которая характеризуется длиной кодового ограничения К. По сути, текущая n – битовая выходная последовательность кода (n, k, К) зависит не только от значений текущего входного блока, состоящего из k бит, но также и от предыдущих (К -1) k - битовых блоков. Следовательно, текущая выходная n битовая последовательность является функцией последних (K k) входных битов.

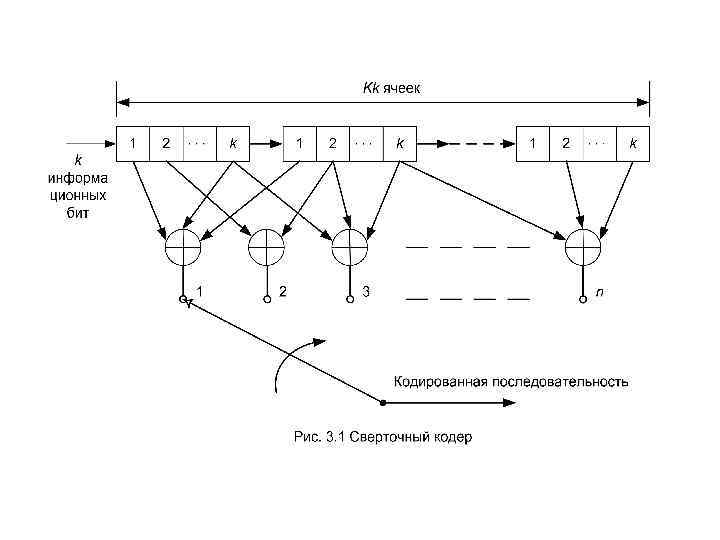
Свёрточный код создаётся прохождением передаваемой информационной последовательности через линейный сдвиговый регистр с конечным числом состояний. В общем, регистр сдвига состоит из К (k битовых) ячеек и линейного преобразователя, состоящего из n функциональных генераторов и выполняющего алгебраические функции как показано на рисунке. 3. 1. Входные данные к кодеру, которые считаются двоичными, продвигаются вдоль регистра сдвига по k бит за раз. Число выходных битов для каждой k - битовой входной последовательности равно n. Следовательно, кодовая скорость, определённая как Rc = k/n, согласуется с определением скорости блочного кода. Параметр К называется длиной кодового ограничения (или кодовым ограничением) свёрточного кода и указывает число разрядов в регистре сдвига. Чтобы иметь возможность описывать сверточный код, необходимо определить кодирующую функцию G(m) так, чтобы по данной входной последовательности m можно было быстро вычислить выходную последовательность U. Для реализации сверточного кодирования используется несколько методов; наиболее распространенными из них являются графическая связь, векторы, полиномы связи, диаграмма состояния, древовидная и решетчатая диаграммы. Все они рассматриваются ниже.
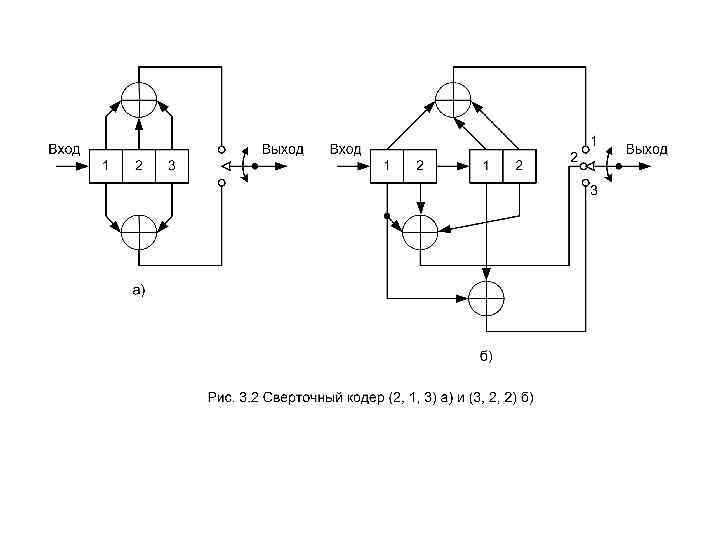

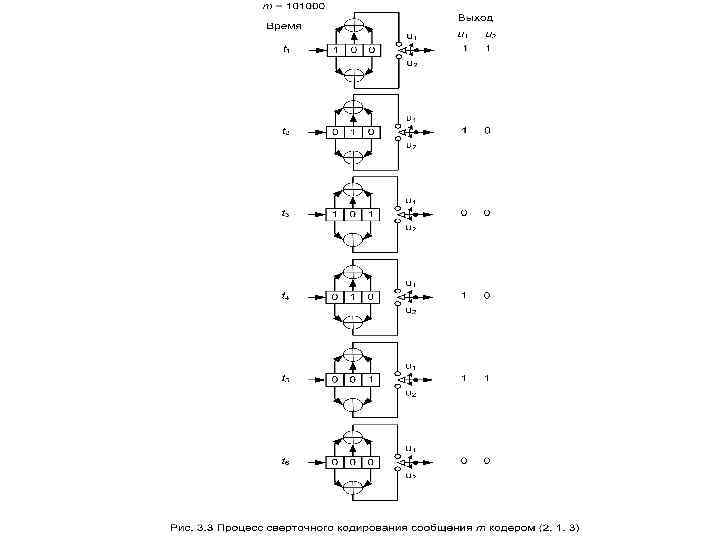
Один из способов реализации кодера заключается в определении п векторов связи, по одному на каждый из п сумматоров по модулю 2. Каждый вектор имеет размерность К и описывает связь регистра сдвига кодера с соответствующим сумматором по модулю 2. Единица на i-й позиции вектора указывает на то, что соответствующий разряд в регистре сдвига связан с сумматором по модулю 2, а нуль в данной позиции указывает, что связи между разрядом регистра и сумматором по модулю 2 не существует. Для кодера на рисунке 3. 2, а можно записать вектор связи (генераторный полином) g 1 для верхних связей, a g 2 – для нижних Аналогичным образом можно записать генераторные полиномы для кодера на рис. 3. 2, б, учитывая, что в этом кодере каждый раз два бита поступают на вход регистров сдвига, а на выходе генерируется три бита Предположим теперь, что вектор сообщения m = 1 0 0 0 закодирован с использованием сверточного кода и кодера, показанного на рис. 3. 2, а.

Сверточный кодер можно представить в виде набора из п полиномиальных генераторов, по одному для каждого из п сумматоров по модулю 2. Каждый полином имеет порядок К - 1 или меньше и описывает связь кодирующего регистра сдвига с соответствующим сумматором по модулю 2, почти так же как и вектор связи. Коэффициенты возле каждого слагаемого полинома порядка (К - 1) равны либо 1, либо 0, в зависимости от того, имеется ли связь между регистром сдвига и сумматором по модулю 2. Для кодера на рис. 3. 2, а можно записать полиномиальный генератор g 1 (X) для верхних связей, a g 2 (X) – для нижних Здесь слагаемое самого нижнего порядка в полиноме соответствует входному разряду регистра. Выходная последовательность находится следующим образом
. Представление кодера,")
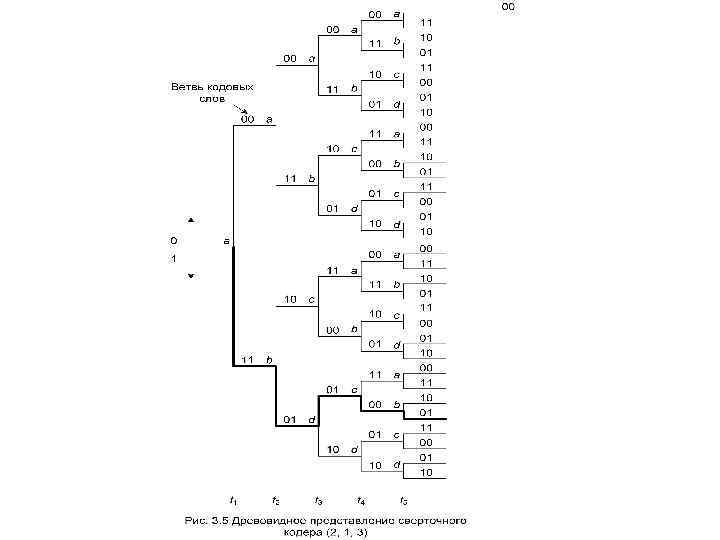
Одним из способов представления простых кодирующих устройств является диаграмма состояния (state diagram). Представление кодера, изображенного на рис. 3. 2, а, в виде диаграммы состояний показано на рис. 3. 4. Состояния, показанные в рамках диаграммы, представляют собой возможное содержимое К - 1 крайних правых разрядов регистра, а пути между состояниями – кодовые слова ветвей на выходе, являющиеся результатом переходов между такими состояниями. Состояния регистра выбраны следующими: а = 00, b = 10, с = 01 и d = 11. Диаграмма, показанная на рис. 3. 4, иллюстрирует все возможные смены состояний для кодера, показанного на рис. 3. 2, а. Существует всего два исходящих из каждого состояния перехода, соответствующие двум возможным входным битам. Далее для каждого пути между состояниями записано кодовое слово на выходе, связанное с переходами между состояниями.

При изображении путей, сплошной линией принято обозначать путь, связанный с нулевым входным битом, а пунктирной линией – путь, связанный с единичным входным битом. Отметим, что за один переход невозможно перейти из данного состояния в любое произвольное. Так как за единицу времени перемещается только один бит, существует только два возможных перехода между состояниями, в которые регистр может переходить за время прохождения каждого бита. Например, если состояние кодера — 00, при следующем смещении возможно возникновение только состояний 00 или 10.
, схема которого представлена на рис. 3.")
Рассмотрим диаграмму состояний сверточного кодера (3, 2, 2), схема которого представлена на рис. 3. 2, б. Первые два входных бита могут быть 00, 01, 10, 11, а соответсвующие выходные биты – 000, 010, 111, 101. Когда следующая пара входных бит водит в кодер, первая пара передвигается в следующую ячейку. Соответствующие выходные биты зависят от пары битов переместившихся во вторую ячейку и новой пары входных битов. Диаграмма состояний для этого кодера приведена на рис. 3. 4. 1

Решетчатая диаграмма, которая использует повторяющуюся структуру, дает более удобное описание работы кодера, по сравнению с древовидной диаграммой. Решетчатая диаграмма для сверточного кодера, изображенного на рис. 3. 2, а показана на рис, 3. 6. При изображении решетчатой диаграммы мы воспользовались теми же условными обозначениями, что и для диаграммы состояния: сплошная линия обозначает выходные данные, генерируемые входным нулевым битом, а пунктирная – выходные данные, генерируемые входным единичным битом. Узлы решетки представляют состояния кодера; первый ряд узлов соответствует состоянию а = 00, второй и последующие – состояниям b = 10, с =01 и d = 11.

В каждый момент времени для представления 2 К-1 возможных состояний кодера решетка требует 2 К-1 узлов. В нашем примере после достижения глубины решетки, равной трем (в момент времени t 4), замечаем, что решетка имеет фиксированную периодическую структуру. В общем случае фиксированная структура реализуется после достижения глубины К. В соответствии с древовидной диаграммой, входная последовательность данных 1 1 0 1 1 представляется жирной линией нарисованной на решетчатой диаграмме рис. 3. 6. Этот путь кодера соответствует выходной последовательности 11 01 01 00 01. Следовательно, с этого момента в каждое состояние можно войти из любого из двух предыдущих состояний. Также из каждого состояния можно перейти в одно из двух состояний. Из двух исходящих ветвей одна соответствует нулевому входному биту, а другая – единичному входному биту. На рис. 3. 6 кодовые слова на выходе соответствуют переходам между состояниями, показанными как метки на ветвях решетки.

В предыдущем разделе было показано, что при решетчатом представлении кода декодер можно построить так, чтобы можно было отказываться от путей, которые не могут быть кандидатами на роль максимально правдоподобной последовательности. Путь декодирования выбирается из некоего сокращенного набора выживших путей. Такой декодер тем не менее является оптимальным; в том смысле, что путь декодирования такой же, как и путь, полученный с помощью декодера критерия максимального правдоподобия, действующего "грубой силой", однако предварительный отказ от неудачных путей снижает сложность декодирования.
} в кодовую последовательность Z и")
Демодулятор преобразует упорядоченный по времени набор случайных переменных {z(T)} в кодовую последовательность Z и подает ее на декодер. Выход демодулятора можно настроить по-разному. Можно реализовать его в виде жесткой схемы принятия решений относительно того, представляет ли z(T) единицу или нуль. В этом случае выход демодулятора квантуется на два уровня, нулевой и единичный, и соединяется с декодером. Поскольку декодер работает в режиме жесткой схемы принятия решений, принятых демодулятором, такое декодирование называется жестким. Аналогично демодулятор можно настроить так, чтобы он подавал на декодер значение z(T), квантованное более чем на два уровня. Такая схема обеспечивает декодер большим количеством информации, чем жесткая схема решений. Если выход демодулятора имеет более двух уровней квантования, то декодирование называется мягким. На рис. 3. 7 на оси абсцисс изображено восемь (3 -битовых) уровней квантования. Если в демодуляторе реализована жесткая схема принятия двоичных решений, он отправляет на декодер только один двоичный символ. Если в демодуляторе реализована мягкая двоичная схема принятия решений, квантованная на восемь уровней, он отправляет на декодер 3 -битовое слово, описывающее интервал, соответствующий z(T). По сути, поступление такого 3 битового слова, вместо одного двоичного символа, эквивалентно передаче декодеру меры достоверности вместе с решением относительно кодового символа.

Согласно рис. 3. 7, если с демодулятора поступила на декодер последовательность 111, это равносильно утверждению, что с очень высокой степенью достоверности кодовым символом была 1, в то время как переданная последовательность 100 равносильна утверждению, что с очень низкой степенью достоверности кодовым символом была 1. Совершенно ясно, что, в конечном счете, каждое решение, принятое декодером и касающееся сообщения, должно быть жестким; в противном случае на распечатках компьютера можно было бы увидеть нечто, подобное следующему: "думаю, это 1", "думаю, это 0" и т. д. То, что после демодулятора не принимается жесткое решение и на декодер поступает больше данных (мягкое принятие решений), можно понимать как промежуточный этап, необходимый для того, чтобы на декодер поступило больше информации, с помощью которой он затем сможет восстановить последовательность сообщения (с более высокой достоверностью передачи сообщения по сравнению с декодированием в рамках жесткой схемы принятия решений). Показанная на рис. 3. 7 8 -уровневая метрика мягкой схемы принятия решений часто обозначается как -7, -5, -3, -1, 1, 3, 5, 7. Такие обозначения вводятся для простоты интерпретации мягкой схемы принятия решения. Знак метрики характеризует решение (например, выбирается s 1 если величина положительна, и s 2, если отрицательна), а величина метрики описывает степень достоверности этого решения. Преимуществом метрики, показанной на рис. 3. 7, является только то, что в ней не используются отрицательные числа.


На рис. 3. 8 показана последовательность кодовых слов U, и искаженная шумом последовательность Z= 11 01 01 10 01. . Как показано на рис. 3. 2 а, кодер характеризуется кодовыми словами, находящимися на ветвях решетки кодера и заведомо известными как кодеру, так и декодеру. Эти слова являются кодовыми символами, которые можно было бы ожидать на выходе кодера в результате каждого перехода между состояниями. Пометки на ветвях решетки декодера накапливаются декодером в процессе. Другими словами, когда получен кодовый символ, каждая ветвь решетки декодера помечается метрикой подобия (расстоянием Хэмминга) между полученным кодовым символом и каждым словом ветви за этот временной интервал. Из полученной последовательности Z, показанной на рис. 3. 8, можно видеть, что кодовые символы, полученные в (следующий) момент времени t 1 – это 11. Чтобы пометить ветви декодера подходящей метрикой расстояния Хэмминга в (прошедший) момент времени t 1 рассмотрим решетку кодера на рис. 3. 6. Видим, что переход между состояниями 00 порождает на выходе ветви слово 00. Однако получено 11. Следовательно, на решетке декодера помечаем переход между состояниями 00 расстоянием Хэмминга между ними, а именно 2. Глядя вновь на решетку кодера, видим, что переход между состояниями 00 10 порождает на выходе кодовое слово 11, точно соответствующее полученному в момент t 1 кодовому символу.

Следовательно, переход на решетке декодера между состояниями 00 10 помечаем расстоянием Хэмминга 0. В итоге, метрика входящих в решетку декодера ветвей описывает разницу (расстояние) между тем, что было получено, и тем, что "могло бы быть" получено, имея кодовые слова, связанные с теми ветвями, с которых они были переданы. По сути, эти метрики описывают величину, подобную корреляциям между полученным кодовым словом и каждым из кандидатов на роль кодового слова. Таким же образом продолжаем помечать ветви решетки декодера по мере получения символов в каждый момент времени ti. В алгоритме декодирования эти метрики расстояния Хэмминга используются для нахождения наиболее вероятного (с минимальным расстоянием) пути через решетку. Смысл декодирования Витерби заключается в следующем. Если любые два пути сливаются в одном состоянии, то при поиске оптимального пути один из них всегда можно исключить Например, на рис. 3. 9 показано два пути, сливающихся в момент времени t 5 в состоянии 00. Определим суммарную метрику пути по Хэммингу для данного пути в момент времени ti, как сумму метрик расстояний Хэмминга ветвей, по которым проходит путь до момента ti.

На рис. 3. 9 верхний путь имеет метрику 4, нижний – метрику 1. Верхний путь нельзя выделить как оптимальный, поскольку нижний путь, входящий в то же состояние, имеет меньшую метрику. Это наблюдение поддерживается Марковской природой состояний кодера. Настоящее состояние завершает историю кодера в том смысле, что предыдущие состояния не могут повлиять на будущие состояния или будущие ветви на выходе.
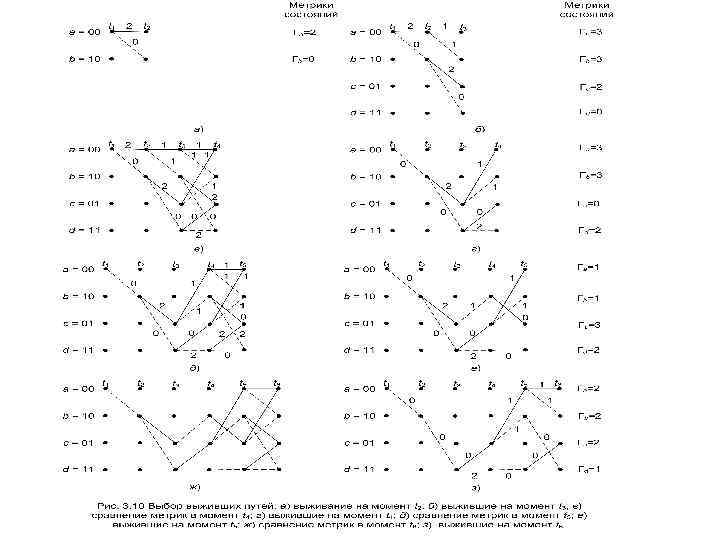

На каждом следующем шаге процесса декодирования всегда будет два пути для каждого состояния; после сравнения метрик путей один из них будет исключен. Этот шаг в процессе декодирования показан на рис. 3. 10, д. В момент t 5 снова имеется по два входных пути для каждого состояния, и один путь из каждой пары подлежит исключению. Выжившие пути на момент t 5 показаны на рис. 3. 10, е. Заметим, что в нашем примере мы еще не можем принять решения относительно второго входного информационного бита, поскольку еще остается два пути, исходящих в момент t 2 из состояния в узле 10. В момент времени t 6 на рис. 3. 10, ж снова можем видеть структуру сливающихся путей, а на рис. 3. 10, з — выжившие пути на момент t 6. Здесь же, на рис. 3. 10, з, на выходе декодера в качестве второго декодированного бита показана единица как итог единственного оставшегося пути между точками t 2 и t 3. Аналогичным образом декодер продолжает углубляться в решетку и принимать решения, касающиеся информационных битов, устраняя все пути, кроме одного. Отсекание сходящихся путей в решетке гарантирует, что у нас никогда не будет путей больше, чем состояний. В этом примере можно проверить, что после каждого отсекания (рис. 3. 10, б—д) остается только 4 пути. Сравните это с попыткой применить "грубую силу" (без привлечения алгоритма Витерби) при использовании для получения последовательности принципа максимального правдоподобия. В этом случае число возможных путей (соответствующее возможным вариантам последовательности) является степенной функцией длины последовательности. Для двоичной последовательности кодовых слов с длиной кодовых слов L имеется 2 L возможные последовательности.
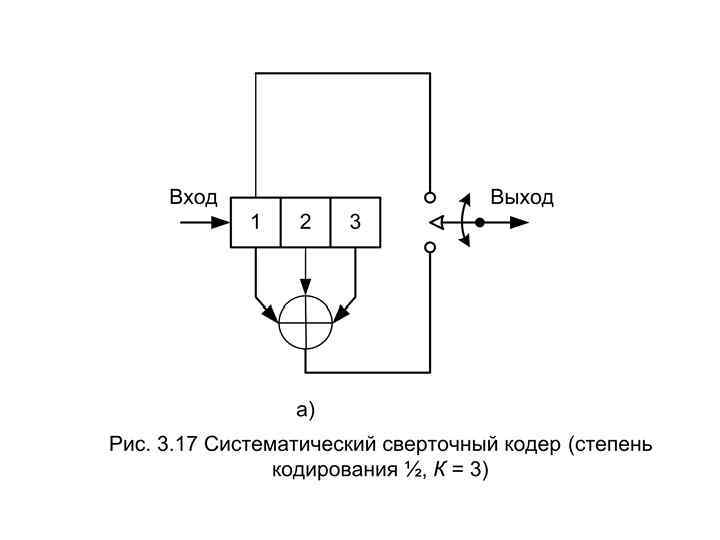

Единственное преимущество описанного ранее систематического кода заключается в том, что он никогда не будет катастрофическим. Однако, исследования несистематических кодов показало, что только небольшая их часть (исключая те, в которых все сумматоры имеют четное количество соединений) является катастрофической. Наиболее известные сверточные коды 1/2 1/3 2/7 3/7 2/3 4/7 2/5 3/4 3/5 3/8 4/5

В таблице 5. 8 приведены значения ЭВК для сверточного кода с Rc = ½ , 32 битовой памятью путей при использовании в гауссовом канале модуляции BPSK, вероятности ошибки 10 -4 при отношении Eb/N 0. = 8, 2 д. Б без использования кодирования. Таблица 5. 8 Значения ЭВК сверточного кода 3 4 5 6 7 8 1. 1 1. 4 1. 9 2. 2 2. 6 3. 0 Глубина кодирован ия, K ЭВК
Сверточные коды.ppt