

1e9dece2c5658481785d889398a1a8f0.ppt
- Количество слайдов: 37
 Structured Management of Digital Content and Licenses Electronic Publishing, Digital Archiving and Licensing workshop Frankfurt October 20 2005 Norman Paskin, International DOI Foundation n. paskin@doi. org
Structured Management of Digital Content and Licenses Electronic Publishing, Digital Archiving and Licensing workshop Frankfurt October 20 2005 Norman Paskin, International DOI Foundation n. paskin@doi. org
 Structured Management of Digital Content and Licenses Outline: • Define terms in the title • Two principles: identification and description. 1. 2. • Identification: resolution, persistence, interoperability • Internet identifiers; URI, URN, is DNS enough? • What do we need to identify? Description: what is it we are identifying? • Metadata: taxonomies, ontologies, folksonomies Summary of key issues
Structured Management of Digital Content and Licenses Outline: • Define terms in the title • Two principles: identification and description. 1. 2. • Identification: resolution, persistence, interoperability • Internet identifiers; URI, URN, is DNS enough? • What do we need to identify? Description: what is it we are identifying? • Metadata: taxonomies, ontologies, folksonomies Summary of key issues
 Structured Management of Digital Content and Licenses Management: • know what it is you are managing – label it • Require a unique label for an entity involved in a DRM transaction • An identifier string, which can do something Digital Content and Licenses: • Enties in transactions: stuff, people, deals (= content, users, licences) – indecs: “people make stuff, people do deals about stuff; stuff is used by people” • Same system for all these entities, using internet standards Structured: • Objective: capable of being used in distributed systems • someone else can come along at another time/place, and may need to link to another system, etc • So must be persistent and interoperable (which means: description)
Structured Management of Digital Content and Licenses Management: • know what it is you are managing – label it • Require a unique label for an entity involved in a DRM transaction • An identifier string, which can do something Digital Content and Licenses: • Enties in transactions: stuff, people, deals (= content, users, licences) – indecs: “people make stuff, people do deals about stuff; stuff is used by people” • Same system for all these entities, using internet standards Structured: • Objective: capable of being used in distributed systems • someone else can come along at another time/place, and may need to link to another system, etc • So must be persistent and interoperable (which means: description)
 Two principles for persistent identification resource ID 1. Obvious: IDENTIFICATION Assign ID to resource Once assigned the number must identify the same resource – Beyond the lifetime of the resource, or the assigner 2. Less obvious: DESCRIPTION Assign Resource to ID The resource must be described – If the Resource is not always securely and exclusively bound to the ID – then: – Describe the resource “content” [with precision] – Failure to do this will ultimately break interoperability How far do we go in each? Depends on what is “good enough” Technologists have focussed on (1) [and “bags of bits/data structures”] – The content/rights world on (2) [and focus on “intellectual content”]: ISBN etc – Both viewpoints valid – (2) is now becoming more relevant – because more open/distributed systems –
Two principles for persistent identification resource ID 1. Obvious: IDENTIFICATION Assign ID to resource Once assigned the number must identify the same resource – Beyond the lifetime of the resource, or the assigner 2. Less obvious: DESCRIPTION Assign Resource to ID The resource must be described – If the Resource is not always securely and exclusively bound to the ID – then: – Describe the resource “content” [with precision] – Failure to do this will ultimately break interoperability How far do we go in each? Depends on what is “good enough” Technologists have focussed on (1) [and “bags of bits/data structures”] – The content/rights world on (2) [and focus on “intellectual content”]: ISBN etc – Both viewpoints valid – (2) is now becoming more relevant – because more open/distributed systems –
 Structured Management of Digital Content and Licenses Outline: • Explaining the terms in the title • Two principles: identification and description 1. Identification: resolution, persistence, interoperability • Internet identifiers; URI, URN, is DNS enough? • What do we need to identify? 2. Description: what is it we are identifying? • Metadata: taxonomies, ontologies, folksonomies • Summary of key issues
Structured Management of Digital Content and Licenses Outline: • Explaining the terms in the title • Two principles: identification and description 1. Identification: resolution, persistence, interoperability • Internet identifiers; URI, URN, is DNS enough? • What do we need to identify? 2. Description: what is it we are identifying? • Metadata: taxonomies, ontologies, folksonomies • Summary of key issues
 Identifiers do something • • Identifier: A unique label for an entity involved in a transaction Note the ambiguity of the word “identifier”: – Label (e. g. ISBN) – Specification (e. g. URN) scheme for making actionable + = Implemented system (e. g. DOI, Bar code) “actionable identifier” • But pure versus actionable identifier is not a clear distinction – any pure identifier may become actionable in the future through new specifications being applied • Resolution: The process in which an identifier is the input (a request) to a network service to receive in return a specific output. • • Both concepts are in principle neutral as to technology implementation Abstract concepts, but implementations typically at least “internet” TCP/IP (the more general the better, e. g. not just “Web”)
Identifiers do something • • Identifier: A unique label for an entity involved in a transaction Note the ambiguity of the word “identifier”: – Label (e. g. ISBN) – Specification (e. g. URN) scheme for making actionable + = Implemented system (e. g. DOI, Bar code) “actionable identifier” • But pure versus actionable identifier is not a clear distinction – any pure identifier may become actionable in the future through new specifications being applied • Resolution: The process in which an identifier is the input (a request) to a network service to receive in return a specific output. • • Both concepts are in principle neutral as to technology implementation Abstract concepts, but implementations typically at least “internet” TCP/IP (the more general the better, e. g. not just “Web”)
 Persistence • "It is intended that the lifetime of a [persistent identifier] be permanent. That is, the [persistent identifier] will be globally unique forever, and may well be used as a reference to a resource well beyond the lifetime of the resource it identifies or of any naming authority involved in the assignment of its name. “ • [Persistent Identifier] = URN in IETF RFC 1737: Functional Requirements for Uniform Resource Names. (http: //www. ietf. org/rfc 1737. txt) Technical and social infrastructure issues
Persistence • "It is intended that the lifetime of a [persistent identifier] be permanent. That is, the [persistent identifier] will be globally unique forever, and may well be used as a reference to a resource well beyond the lifetime of the resource it identifies or of any naming authority involved in the assignment of its name. “ • [Persistent Identifier] = URN in IETF RFC 1737: Functional Requirements for Uniform Resource Names. (http: //www. ietf. org/rfc 1737. txt) Technical and social infrastructure issues
 Interoperability • • Persistence can be seen as just one aspect of this wider concept “persistence is interoperability with the future” We know what we mean, but others may not. – Identifiers assigned in one context may be encountered, and may be re-used, in another place or time [= persistence] - without consulting the assigner. You can’t assume that your assumptions made on assignment will be known to someone else. Interoperability = the possibility of use in services outside the direct control of the issuing assigner This will be key for publishing, archiving and licensing – all assume distributed access
Interoperability • • Persistence can be seen as just one aspect of this wider concept “persistence is interoperability with the future” We know what we mean, but others may not. – Identifiers assigned in one context may be encountered, and may be re-used, in another place or time [= persistence] - without consulting the assigner. You can’t assume that your assumptions made on assignment will be known to someone else. Interoperability = the possibility of use in services outside the direct control of the issuing assigner This will be key for publishing, archiving and licensing – all assume distributed access
 Persistent identifiers on the Internet: DNS • Domain Name System: DNS – designed primarily as a level of indirection for IP addresses: 132. 157. 24. 3 is a machine. Move server. acme. com to another machine, you don't have to tell everyone but just change your DNS records so it now points to 132. 157. 24. 6 instead. • A number of assumptions that were valid at that time now pose problems : – All the data is public: difficult for use in applications like voice over IP. – The data can be implicitly trusted: you need some way to trust that you are talking to who you think you are talking to. – The names can all be in ASCII – but Chinese etc is important after all. – Administration will be done by sys admins sitting at consoles: no need for an administrative protocol. Ownership is then naturally at the level of whoever owns the servers and pays the sys admins. – Control of the naming authority will not be a problem: ICANN, Root zone file is a very active UN row now going on (WSIS) • DNS designed for servers: – When Tim B- L came out with a plan for linking documents it seemed natural to build on DNS: tack file paths on the end of the server names in order to identify the business ends of the links: URLs (now URIs). – But now the documents are identified starting with the names of the organizations that own the servers they sit on. A problem.
Persistent identifiers on the Internet: DNS • Domain Name System: DNS – designed primarily as a level of indirection for IP addresses: 132. 157. 24. 3 is a machine. Move server. acme. com to another machine, you don't have to tell everyone but just change your DNS records so it now points to 132. 157. 24. 6 instead. • A number of assumptions that were valid at that time now pose problems : – All the data is public: difficult for use in applications like voice over IP. – The data can be implicitly trusted: you need some way to trust that you are talking to who you think you are talking to. – The names can all be in ASCII – but Chinese etc is important after all. – Administration will be done by sys admins sitting at consoles: no need for an administrative protocol. Ownership is then naturally at the level of whoever owns the servers and pays the sys admins. – Control of the naming authority will not be a problem: ICANN, Root zone file is a very active UN row now going on (WSIS) • DNS designed for servers: – When Tim B- L came out with a plan for linking documents it seemed natural to build on DNS: tack file paths on the end of the server names in order to identify the business ends of the links: URLs (now URIs). – But now the documents are identified starting with the names of the organizations that own the servers they sit on. A problem.
 Persistent identifiers on the Internet: Handle • DNS is not essential to the underlying TCP/IP network, but just to the current use of that network. One proposed solution to DNS problems; Handle system (1995+) – identify objects, not servers. – objects can be anything identified: accounts, names, ids, phone #s, content… – explicit improvements for identifying very large number of digital objects. – not all the data is public: individual values within a handle can be private. – all transactions can be certified. – any Unicode character set can be used. – separation between who owns and controls the handle versus who happens to run the servers (distributed administration, ownership at the handle level) – gets rid of semantics in the identifier: makes it easy to move ownership across organizations without your objects having someone else's name. – Freely available to be used as engine underneath other named identifiers. Does not need DNS, but can work with DNS. • Basis of DOI system – advantages as above, proven for publishers. Used in Grid computing, US govt applications, DOI, etc though most DOIs are used in translated http proxy form • “The governance of the DNS will not completely encompass future Internet addressing and navigation…The system…is not static but a technology capable of evolving into a better form. As such, the current system should not be treated as sacrosanct, but amenable to innovation”. Kenneth Neil Cukier (Technology Correspondent, The Economist) • However, most identifier methodologies still use the DNS basis: URI, URN
Persistent identifiers on the Internet: Handle • DNS is not essential to the underlying TCP/IP network, but just to the current use of that network. One proposed solution to DNS problems; Handle system (1995+) – identify objects, not servers. – objects can be anything identified: accounts, names, ids, phone #s, content… – explicit improvements for identifying very large number of digital objects. – not all the data is public: individual values within a handle can be private. – all transactions can be certified. – any Unicode character set can be used. – separation between who owns and controls the handle versus who happens to run the servers (distributed administration, ownership at the handle level) – gets rid of semantics in the identifier: makes it easy to move ownership across organizations without your objects having someone else's name. – Freely available to be used as engine underneath other named identifiers. Does not need DNS, but can work with DNS. • Basis of DOI system – advantages as above, proven for publishers. Used in Grid computing, US govt applications, DOI, etc though most DOIs are used in translated http proxy form • “The governance of the DNS will not completely encompass future Internet addressing and navigation…The system…is not static but a technology capable of evolving into a better form. As such, the current system should not be treated as sacrosanct, but amenable to innovation”. Kenneth Neil Cukier (Technology Correspondent, The Economist) • However, most identifier methodologies still use the DNS basis: URI, URN
. Still much wider uptake") URI : observations • Web based (W 3 C led). Still much wider uptake than DOI etc. Takes DNS as basis. Problems: – URLs, as currently understood, are demonstrably not persistent: calling them URIs doesn’t fix that – Inherits DNS problems (last slide) especially the name/place confusion – Many important recent developments are not based on URIs in any way e. g. Vo. IP (Skype), Peer-to-peer – Some are URI based but with different registration requirements (MPEG-21) – The Web is not the end point of evolution: grid computing, mobile computing – The IETF RFC consensus process, and the separate existence of W 3 C, leads to ongoing debate and standards with a vague existence (Cf. ISO standards: W 3 C web site on naming and addressing is “incomplete”) • Persistence = organisation is now becoming recognised, and technical solution should follow – – – e. g. “commitment statement” in archiving is seen as important (ARK) e. g. IDF has established rules for social network support of DOIs Importance of social infrastructure URN mechanism (>10 years old) meant to be solution: But still not implemented – recent renewed interest may help
URI : observations • Web based (W 3 C led). Still much wider uptake than DOI etc. Takes DNS as basis. Problems: – URLs, as currently understood, are demonstrably not persistent: calling them URIs doesn’t fix that – Inherits DNS problems (last slide) especially the name/place confusion – Many important recent developments are not based on URIs in any way e. g. Vo. IP (Skype), Peer-to-peer – Some are URI based but with different registration requirements (MPEG-21) – The Web is not the end point of evolution: grid computing, mobile computing – The IETF RFC consensus process, and the separate existence of W 3 C, leads to ongoing debate and standards with a vague existence (Cf. ISO standards: W 3 C web site on naming and addressing is “incomplete”) • Persistence = organisation is now becoming recognised, and technical solution should follow – – – e. g. “commitment statement” in archiving is seen as important (ARK) e. g. IDF has established rules for social network support of DOIs Importance of social infrastructure URN mechanism (>10 years old) meant to be solution: But still not implemented – recent renewed interest may help
: using DNS to add names to locations") URN: observations • URN (Uniform Resource Name): using DNS to add names to locations • • A single point re-direction to URLs using an http: proxy server Any existing identifier can add the URN spec: – Part of mid 90 s IETF design concept: URL/URN/URC – Still inherits problems of DNS, but better than URL – But not widely used – isbn: 12345678 as a URN = urn: isbn: 123456789. • Assumes a DNS-based Resolution Discovery Service (RDS) • Some have been built for individual communities • functionally gives nothing beyond the functionality achieved by coherent management of the corresponding URLs – – No such widely deployed RDS schemes currently exist: Browsers cannot action URN strings without some additional programming “plug-in”. – Example: Life Science identifier LSID – fine but also needs a social infrastructure – but they work for that community, by adding that coherent management. • URN code or plug-in promised for CENDI (US government users). Some movement to “re-define URN”. If that happens and is taken up, it could be significant.
URN: observations • URN (Uniform Resource Name): using DNS to add names to locations • • A single point re-direction to URLs using an http: proxy server Any existing identifier can add the URN spec: – Part of mid 90 s IETF design concept: URL/URN/URC – Still inherits problems of DNS, but better than URL – But not widely used – isbn: 12345678 as a URN = urn: isbn: 123456789. • Assumes a DNS-based Resolution Discovery Service (RDS) • Some have been built for individual communities • functionally gives nothing beyond the functionality achieved by coherent management of the corresponding URLs – – No such widely deployed RDS schemes currently exist: Browsers cannot action URN strings without some additional programming “plug-in”. – Example: Life Science identifier LSID – fine but also needs a social infrastructure – but they work for that community, by adding that coherent management. • URN code or plug-in promised for CENDI (US government users). Some movement to “re-define URN”. If that happens and is taken up, it could be significant.
 Identifier systems • Each community tends to arrive at its own “good enough for us” solution • Whatever mechanism, resolvable identifiers must provide: • • – less focus now on “what is a persistent identifier? ” More on “how do we build a system… ” – – Agreed numbering syntax Resolution mechanism Data model to define “what it is we are identifying” Technical and social infrastructure to implement (compare physical world bar codes, etc) could be assembled ad hoc, or offered as a packaged system (e. g. DOI)
Identifier systems • Each community tends to arrive at its own “good enough for us” solution • Whatever mechanism, resolvable identifiers must provide: • • – less focus now on “what is a persistent identifier? ” More on “how do we build a system… ” – – Agreed numbering syntax Resolution mechanism Data model to define “what it is we are identifying” Technical and social infrastructure to implement (compare physical world bar codes, etc) could be assembled ad hoc, or offered as a packaged system (e. g. DOI)
 • Licences (some") Identifying entities of all types • Resources: most commonly content (Stuff) • Licences (some music industry applications now looking at this (Deals) • Parties (see earlier Inter. Party project) including Institutions (people): • e. g. exploratory stakeholders' meeting took place Washington DC October 7 to examine the feasibility of an Institution Registry . – Problem: libraries deliver contact names and numbers, IP address ranges, etc to publishers, – Publishers manage this in their access and subscription systems in order to be able to authenticate library users – This exchange of information is usually done individually between publishers and libraries; much duplication of effort, no possibility of synergy – Institution Registry could at minimum provide a central space to hold this information once only
Identifying entities of all types • Resources: most commonly content (Stuff) • Licences (some music industry applications now looking at this (Deals) • Parties (see earlier Inter. Party project) including Institutions (people): • e. g. exploratory stakeholders' meeting took place Washington DC October 7 to examine the feasibility of an Institution Registry . – Problem: libraries deliver contact names and numbers, IP address ranges, etc to publishers, – Publishers manage this in their access and subscription systems in order to be able to authenticate library users – This exchange of information is usually done individually between publishers and libraries; much duplication of effort, no possibility of synergy – Institution Registry could at minimum provide a central space to hold this information once only
 Structured Management of Digital Content and Licenses Outline: • Explaining the terms in the title • Two principles: identification and description 1. Identification: resolution, persistence, interoperability • Internet identifiers; URI, URN, is DNS enough? • What do we need to identify? 2. Description: what is it we are identifying? • Metadata: taxonomies, ontologies, folksonomies • Summary of key issues
Structured Management of Digital Content and Licenses Outline: • Explaining the terms in the title • Two principles: identification and description 1. Identification: resolution, persistence, interoperability • Internet identifiers; URI, URN, is DNS enough? • What do we need to identify? 2. Description: what is it we are identifying? • Metadata: taxonomies, ontologies, folksonomies • Summary of key issues
 Resolution and “What are we identifying? ” • • • Resolution: The process in which an identifier is the input (a request) to a network service to receive in return a specific output Identifier identifies an entity. “what I point to” (resolve to and get) is not always “what is identified”, – Can identify but not “get” directly things that are intangible (works), or fugitive (performances) or that change: (“Todays NY Times”) or people and concepts…. – Pointing and clicking can return different things in different contexts, or give multiple options Entities can be physical, abstract, tangible, intangible, things, people, concepts, colours… Resolution provides a mechanism to describe the resource “content” through a service which delivers a description
Resolution and “What are we identifying? ” • • • Resolution: The process in which an identifier is the input (a request) to a network service to receive in return a specific output Identifier identifies an entity. “what I point to” (resolve to and get) is not always “what is identified”, – Can identify but not “get” directly things that are intangible (works), or fugitive (performances) or that change: (“Todays NY Times”) or people and concepts…. – Pointing and clicking can return different things in different contexts, or give multiple options Entities can be physical, abstract, tangible, intangible, things, people, concepts, colours… Resolution provides a mechanism to describe the resource “content” through a service which delivers a description
 is not") What are we identifying? “what I point to” (resolve to and get) is not always obvious Document on screen Abstract work? Manifestation of abstract work? Version? This HTML file? All/some of these?
What are we identifying? “what I point to” (resolve to and get) is not always obvious Document on screen Abstract work? Manifestation of abstract work? Version? This HTML file? All/some of these?
 Describing what we are managing What precisely are we identifying by this identifier? How are these things related to other things? Common approaches: • Taxonomies • Ontologies • Folksonomies
Describing what we are managing What precisely are we identifying by this identifier? How are these things related to other things? Common approaches: • Taxonomies • Ontologies • Folksonomies
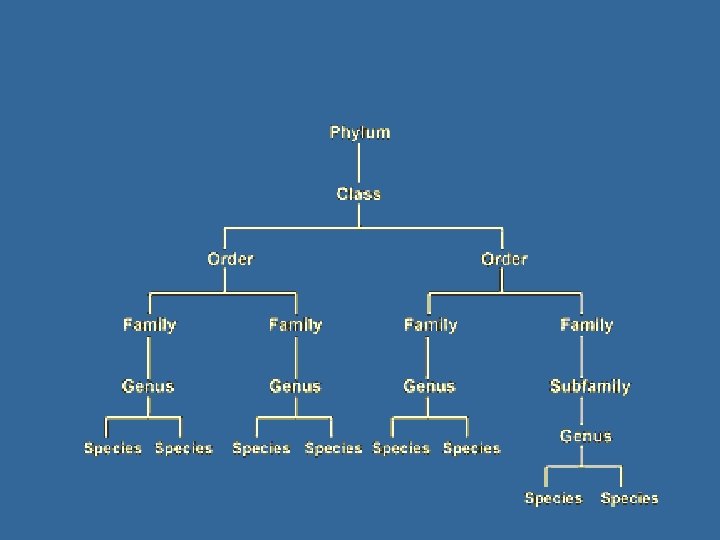
 taxis, arrangement; + -nomie, method Division into ordered groups") Taxonomy • • • (Greek) taxis, arrangement; + -nomie, method Division into ordered groups or categories Hierarchical, parent/child relationships Defined area of interest Gives a good way of being unambiguous within a controlled, defined area • Best example is Linnean taxonomy of life: the classification of organisms in an ordered system that indicates natural relationships • And that illustrates a key point…
Taxonomy • • • (Greek) taxis, arrangement; + -nomie, method Division into ordered groups or categories Hierarchical, parent/child relationships Defined area of interest Gives a good way of being unambiguous within a controlled, defined area • Best example is Linnean taxonomy of life: the classification of organisms in an ordered system that indicates natural relationships • And that illustrates a key point…

 Taxonomy • • “It’s a Robin” Id = Robin. . and we all know what a Robin looks like… “we know what we mean but others may not”
Taxonomy • • “It’s a Robin” Id = Robin. . and we all know what a Robin looks like… “we know what we mean but others may not”
 Chordata | Aves | Passeriform | Turdidae | Erithacus | Rubecula European Robin
Chordata | Aves | Passeriform | Turdidae | Erithacus | Rubecula European Robin
 Chordata | Aves | Passeriform | Turdidae | Turdus | Migratorius American Robin (different genus)
Chordata | Aves | Passeriform | Turdidae | Turdus | Migratorius American Robin (different genus)
") Chordata | Aves | Passeriform | Eopsaltridae | Petroica | Multicolor Scarlet Robin (Australasia) (different family)
Chordata | Aves | Passeriform | Eopsaltridae | Petroica | Multicolor Scarlet Robin (Australasia) (different family)
 (and Batman)") ? | ? | ? | ? Robin (red) (and Batman)
? | ? | ? | ? Robin (red) (and Batman)
") ? | ? | ? | ? Robin Reliant (red)
? | ? | ? | ? Robin Reliant (red)
 component of the") Ontologies • differ from taxonomic approach: • the proposed third (missing) component of the semantic web: – Not just “stamp collecting” but extensible – do not follow a rigid/parent child hierarchical structure: terms may inherit meaning from more than one parent – a more complex relationship is maintained. – Can build on / are more complex than taxonomies – Show taxonomies map to each other – May add inference engines etc – XML allows users to add arbitrary structure to their documents but says nothing about what the structures mean. – RDF enables expression of meaning (sets of triples, each triple being rather like the subject, verb and object) – Ontologies “will enable machines to comprehend semantic documents and data"
Ontologies • differ from taxonomic approach: • the proposed third (missing) component of the semantic web: – Not just “stamp collecting” but extensible – do not follow a rigid/parent child hierarchical structure: terms may inherit meaning from more than one parent – a more complex relationship is maintained. – Can build on / are more complex than taxonomies – Show taxonomies map to each other – May add inference engines etc – XML allows users to add arbitrary structure to their documents but says nothing about what the structures mean. – RDF enables expression of meaning (sets of triples, each triple being rather like the subject, verb and object) – Ontologies “will enable machines to comprehend semantic documents and data"
 Ontologies • Use underlying data model – a “context model” - to express an events-based structure – the accepted ontology approach [context based= events and states] • We often think of metadata as “about” things, people, etc – static views e. g. about “person A” ; “creation B” • Events link things (e. g. to describe rights activities) by relating things and people in the context which generated/used them – dynamic views e. g. “A created B” • Events description is the key to “rights metadata” – all such transactions are contextual (events) – describing the event in context, using formal dictionary terms, enables semantic interoperability • The common methodology with most uptake and promise is the
Ontologies • Use underlying data model – a “context model” - to express an events-based structure – the accepted ontology approach [context based= events and states] • We often think of metadata as “about” things, people, etc – static views e. g. about “person A” ; “creation B” • Events link things (e. g. to describe rights activities) by relating things and people in the context which generated/used them – dynamic views e. g. “A created B” • Events description is the key to “rights metadata” – all such transactions are contextual (events) – describing the event in context, using formal dictionary terms, enables semantic interoperability • The common methodology with most uptake and promise is the
 1998 -2005: Defining what is identified through metadata Development of indecs 1998 -2005 Black = what Red = who 2005 indecs (2000) CONTECS (2001+) EU project -> indecs Framework Ltd IFPI/RIAA, MPA, IDF, Dentsu. MMG, Rightscom ISO MPEG 21 RDD Int DOI Foundation IDF + ONIX indecs. DD Ontology. X Mi 3 p etc
1998 -2005: Defining what is identified through metadata Development of indecs 1998 -2005 Black = what Red = who 2005 indecs (2000) CONTECS (2001+) EU project -> indecs Framework Ltd IFPI/RIAA, MPA, IDF, Dentsu. MMG, Rightscom ISO MPEG 21 RDD Int DOI Foundation IDF + ONIX indecs. DD Ontology. X Mi 3 p etc
 Folksonomies • • Current hot web topic: individuals assign their own keywords to content Examples: – www. flickr. com (photo-sharing); – http: //del. icio. us/ (social bookmarking)
Folksonomies • • Current hot web topic: individuals assign their own keywords to content Examples: – www. flickr. com (photo-sharing); – http: //del. icio. us/ (social bookmarking)

 Folksonomies • • Rough and ready alternative to traditional information organisation Most people use tags first and foremost to organise their own information in a way that makes sense to them – Sharing this creates a side-effect of “vast democratically structured frameworks of organisation” • Not much good for managed structured searching/management: • But don’t write them off: – e. g. “recipe” “cooking” “barbecue” – the Robin problem – cf Wikipedia (people said it would never work…) – imagine some automated organisation/rules/dictionary being added in certain communities – imagine links to Autonomy type searching
Folksonomies • • Rough and ready alternative to traditional information organisation Most people use tags first and foremost to organise their own information in a way that makes sense to them – Sharing this creates a side-effect of “vast democratically structured frameworks of organisation” • Not much good for managed structured searching/management: • But don’t write them off: – e. g. “recipe” “cooking” “barbecue” – the Robin problem – cf Wikipedia (people said it would never work…) – imagine some automated organisation/rules/dictionary being added in certain communities – imagine links to Autonomy type searching
 Structured Management of Digital Content and Licenses Outline: • Explaining the terms in the title • Two principles: identification and description 1. Identification: resolution, persistence, interoperability – Internet identifiers; URI, URN, is DNS enough? – What do we need to identify? 2. Description: what is it we are identifying? – Metadata: taxonomies, ontologies, folksonomies • Summary of key issues
Structured Management of Digital Content and Licenses Outline: • Explaining the terms in the title • Two principles: identification and description 1. Identification: resolution, persistence, interoperability – Internet identifiers; URI, URN, is DNS enough? – What do we need to identify? 2. Description: what is it we are identifying? – Metadata: taxonomies, ontologies, folksonomies • Summary of key issues
![Summary: key issues • • What are we identifying? [content not just bits] What](https://present5.com/presentation/1e9dece2c5658481785d889398a1a8f0/image-36.jpg "Summary: key issues • • What are we identifying? [content not just bits] What") Summary: key issues • • What are we identifying? [content not just bits] What are we resolving to from this identifier? What, if any, explicit metadata are we making available? How will the social infrastructure be provided? The mechanisms must allow: • Identification of entities of all forms – To be used in variety of contexts • Appropriate use of metadata at appropriate level – Development of ontology tools to describe entity relationships The logic chain: Identification Persistent Interoperable Automation Precision Logic
Summary: key issues • • What are we identifying? [content not just bits] What are we resolving to from this identifier? What, if any, explicit metadata are we making available? How will the social infrastructure be provided? The mechanisms must allow: • Identification of entities of all forms – To be used in variety of contexts • Appropriate use of metadata at appropriate level – Development of ontology tools to describe entity relationships The logic chain: Identification Persistent Interoperable Automation Precision Logic
 Structured Management of Digital Content and Licenses Electronic Publishing, Digital Archiving and Licensing workshop Frankfurt October 20 2005 Norman Paskin, International DOI Foundation n. paskin@doi. org
Structured Management of Digital Content and Licenses Electronic Publishing, Digital Archiving and Licensing workshop Frankfurt October 20 2005 Norman Paskin, International DOI Foundation n. paskin@doi. org