

1 NumPy - первая презентация по NumPy.pptx
- Количество слайдов: 30
 print") Строки комментариев в Python # Это комментарий (до конца строки) print "Hello World" # Это тоже комментарий """ Это пример многострочного комментария в Python-е. По своей сути – это анонимный строковый объект. """
Строки комментариев в Python # Это комментарий (до конца строки) print "Hello World" # Это тоже комментарий """ Это пример многострочного комментария в Python-е. По своей сути – это анонимный строковый объект. """
 Python: Научные вычисления
Python: Научные вычисления
 Sci. Py – набор (пакет) библиотек для численных") Пакет библиотек Sci. Py (Scientific Python) Sci. Py – набор (пакет) библиотек для численных и символьных Вычислительные (численные) методы — методы решения математических задач в численном вычислений. виде. Символьные вычисления — это преобразования и работа с математическими равенствами и Представление как исходных данных в задаче, так и её решения — в виде числа или набора формулами как с последовательностью символов. Они отличаются от численных расчётов, 1. чисел. Библиотека Num. Py (Numerical Python) которые оперируют приближёнными численными значениями, стоящими за математическими Num. Py — это расширение языка Python, добавляющее поддержку больших выражениями. Системы символьных вычислений (их так же называют системами компьютерной многомерных массивов и матриц, вместе с большой Основами для вычислительных методов являются: алгебры) могут быть использованы для символьного интегрирования и дифференцирования, библиотекой высокоуровневых математических функций для операций с этими массивами. • решение систем линейных уравнений; подстановки одних выражений в другие, упрощения формул и т. д. • интерполирование и приближённое вычисление функций; 2. численное интегрирование; • Библиотека Mat. Plot. Lib (Math Plotting Library) Компьютерная алгебра (в отличие от численных методов) занимается разработкой и • численное решение системы нелинейных уравнений; реализацией аналитических методов решения математических задач на компьютере и Matplotlib - это библиотека для построения графиков и визуализации данных. Кроме большого количества типов графиков, которые можно построить с помощью этого пакета, приятной • численное решение обыкновенных дифференциальных уравнений; предполагает, что исходные данные, как и результаты решения, сформулированы особенностью Matplotlib является то, что функции для построения графиков напоминают • численное решение уравнений в частных производных (уравнений математической в аналитическом (символьном) виде[1]. функции Matlab. физики); • решение задач оптимизации.
Пакет библиотек Sci. Py (Scientific Python) Sci. Py – набор (пакет) библиотек для численных и символьных Вычислительные (численные) методы — методы решения математических задач в численном вычислений. виде. Символьные вычисления — это преобразования и работа с математическими равенствами и Представление как исходных данных в задаче, так и её решения — в виде числа или набора формулами как с последовательностью символов. Они отличаются от численных расчётов, 1. чисел. Библиотека Num. Py (Numerical Python) которые оперируют приближёнными численными значениями, стоящими за математическими Num. Py — это расширение языка Python, добавляющее поддержку больших выражениями. Системы символьных вычислений (их так же называют системами компьютерной многомерных массивов и матриц, вместе с большой Основами для вычислительных методов являются: алгебры) могут быть использованы для символьного интегрирования и дифференцирования, библиотекой высокоуровневых математических функций для операций с этими массивами. • решение систем линейных уравнений; подстановки одних выражений в другие, упрощения формул и т. д. • интерполирование и приближённое вычисление функций; 2. численное интегрирование; • Библиотека Mat. Plot. Lib (Math Plotting Library) Компьютерная алгебра (в отличие от численных методов) занимается разработкой и • численное решение системы нелинейных уравнений; реализацией аналитических методов решения математических задач на компьютере и Matplotlib - это библиотека для построения графиков и визуализации данных. Кроме большого количества типов графиков, которые можно построить с помощью этого пакета, приятной • численное решение обыкновенных дифференциальных уравнений; предполагает, что исходные данные, как и результаты решения, сформулированы особенностью Matplotlib является то, что функции для построения графиков напоминают • численное решение уравнений в частных производных (уравнений математической в аналитическом (символьном) виде[1]. функции Matlab. физики); • решение задач оптимизации.
 Кроме основных символьных операций вроде упрощения") 3. Библиотека символьных вычислений Sym. Py (Symbol Python) Кроме основных символьных операций вроде упрощения выражений, раскрытия скобок, вычисления пределов и разложения функций в ряд из дробей в пакет Sympy входят следующие модули: • Модуль для работы с матрицами (модуль линейной алгебры). • Модуль геометрии, с помощью которого можно символьно вычислять площадь геометрических фигур, находить точки пересечения прямых, отрезков и лучей. • Модуль статистики, с помощью которого можно получать случайные величины с заданной функцией распределения плотности вероятности. • Модуль для отображения трехмерных поверхностей, заданных в виде уравнений с символьными переменными © Wikipedia
3. Библиотека символьных вычислений Sym. Py (Symbol Python) Кроме основных символьных операций вроде упрощения выражений, раскрытия скобок, вычисления пределов и разложения функций в ряд из дробей в пакет Sympy входят следующие модули: • Модуль для работы с матрицами (модуль линейной алгебры). • Модуль геометрии, с помощью которого можно символьно вычислять площадь геометрических фигур, находить точки пересечения прямых, отрезков и лучей. • Модуль статистики, с помощью которого можно получать случайные величины с заданной функцией распределения плотности вероятности. • Модуль для отображения трехмерных поверхностей, заданных в виде уравнений с символьными переменными © Wikipedia
 Библиотека Num. Py
Библиотека Num. Py
 Подключение библиотеки к программе # Импорт всех методов Num. Py в глобальное пространство имен - не лучший путь from numpy import * # Импорт методов Num. Py в переменную np – более правильный путь import numpy as np
Подключение библиотеки к программе # Импорт всех методов Num. Py в глобальное пространство имен - не лучший путь from numpy import * # Импорт методов Num. Py в переменную np – более правильный путь import numpy as np
 Данные в Num. Py Основным объектом Num. Py является однородный многомерный массив ndarray (ndimensional array). Это многомерный массив элементов (обычно чисел), одного типа. Объект ndarray может быть рассмотрен как вариант списка, но с учетом следующих допущений и возможностей: • В тот момент, когда создается массив, число его элементов должно быть известно. • С Num. Py широкий круг математических операций может быть решен непосредственно с помощью массивов, таким образом исключается потребность в циклах, проходящих по элементам массива. Это свойство носит названия векторизации (vectorization). • Массивы с одним индексом также называют векторами. Массивы с двумя индексами используются для создания матриц и представления табличной информации.
Данные в Num. Py Основным объектом Num. Py является однородный многомерный массив ndarray (ndimensional array). Это многомерный массив элементов (обычно чисел), одного типа. Объект ndarray может быть рассмотрен как вариант списка, но с учетом следующих допущений и возможностей: • В тот момент, когда создается массив, число его элементов должно быть известно. • С Num. Py широкий круг математических операций может быть решен непосредственно с помощью массивов, таким образом исключается потребность в циклах, проходящих по элементам массива. Это свойство носит названия векторизации (vectorization). • Массивы с одним индексом также называют векторами. Массивы с двумя индексами используются для создания матриц и представления табличной информации.
 Типы данных, хранимых в ndarray
Типы данных, хранимых в ndarray
![Создание массивов Num. Py >>> a = np. array( [2, 3, 4] ) >>>](https://present5.com/presentation/-59259194_331257756/image-9.jpg "Создание массивов Num. Py >>> a = np. array( [2, 3, 4] ) >>>") Создание массивов Num. Py >>> a = np. array( [2, 3, 4] ) >>> a array([2, 3, 4]) >>> b = np. array( [ (1. 5, 2, 3), (4, 5, 6) ] ) >>> b array([[ 1. 5, 2. , 3. ], [ 4. , 5. , 6. ]]) # Тип массива может быть явно указан в момент создания: >>> c = np. array( [ [1, 2], [3, 4] ], dtype=complex ) >>> c array([[ 1. + 0. j, 2. + 0. j], [ 3. + 0. j, 4. + 0. j]])
Создание массивов Num. Py >>> a = np. array( [2, 3, 4] ) >>> a array([2, 3, 4]) >>> b = np. array( [ (1. 5, 2, 3), (4, 5, 6) ] ) >>> b array([[ 1. 5, 2. , 3. ], [ 4. , 5. , 6. ]]) # Тип массива может быть явно указан в момент создания: >>> c = np. array( [ [1, 2], [3, 4] ], dtype=complex ) >>> c array([[ 1. + 0. j, 2. + 0. j], [ 3. + 0. j, 4. + 0. j]])
 )") Другие возможности создания массивов: массив единиц и нулей >>> np. zeros( (3, 4) ) # аргумент задает форму массива array([[ 0. , 0. ], [ 0. , 0. ]]) # то есть также может быть задан тип данных dtype >>> np. ones( (2, 3, 4), dtype=int 16 ) array([[[ 1, 1, 1, 1], [ 1, 1, 1, 1], [ 1, 1, 1, 1]], [[ 1, 1, 1, 1], [ 1, 1, 1, 1], [ 1, 1, 1, 1]]], dtype=int 16)
Другие возможности создания массивов: массив единиц и нулей >>> np. zeros( (3, 4) ) # аргумент задает форму массива array([[ 0. , 0. ], [ 0. , 0. ]]) # то есть также может быть задан тип данных dtype >>> np. ones( (2, 3, 4), dtype=int 16 ) array([[[ 1, 1, 1, 1], [ 1, 1, 1, 1], [ 1, 1, 1, 1]], [[ 1, 1, 1, 1], [ 1, 1, 1, 1], [ 1, 1, 1, 1]]], dtype=int 16)
![… и другие варианты >>> np. empty( shape [, dtype] ) # пустой массив](https://present5.com/presentation/-59259194_331257756/image-11.jpg "… и другие варианты >>> np. empty( shape [, dtype] ) # пустой массив") … и другие варианты >>> np. empty( shape [, dtype] ) # пустой массив со случайным содержимым >>> np. arange(10) # диапазон от нуля до n-1 array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> np. arange(2, 10, dtype=np. float) # диапазон от m до n-1 array([ 2. , 3. , 4. , 5. , 6. , 7. , 8. , 9. ]) >>> np. arange(2, 3, 0. 1) # Диапазон с заданным шагом (3 -ий параметр) array([ 2. , 2. 1, 2. 2, 2. 3, 2. 4, 2. 5, 2. 6, 2. 7, 2. 8, 2. 9]) >>> np. linspace(1. , 4. , 6) # Создание ряда чисел в заданном интервале с заданным количеством элементов array([ 1. , 1. 6, 2. 2, 2. 8, 3. 4, 4. ]) >>> np. indices((3, 3)) # Набор перестановок array([[[0, 0, 0], [1, 1, 1], [2, 2, 2]], [[0, 1, 2], [0, 1, 2]]])
… и другие варианты >>> np. empty( shape [, dtype] ) # пустой массив со случайным содержимым >>> np. arange(10) # диапазон от нуля до n-1 array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> np. arange(2, 10, dtype=np. float) # диапазон от m до n-1 array([ 2. , 3. , 4. , 5. , 6. , 7. , 8. , 9. ]) >>> np. arange(2, 3, 0. 1) # Диапазон с заданным шагом (3 -ий параметр) array([ 2. , 2. 1, 2. 2, 2. 3, 2. 4, 2. 5, 2. 6, 2. 7, 2. 8, 2. 9]) >>> np. linspace(1. , 4. , 6) # Создание ряда чисел в заданном интервале с заданным количеством элементов array([ 1. , 1. 6, 2. 2, 2. 8, 3. 4, 4. ]) >>> np. indices((3, 3)) # Набор перестановок array([[[0, 0, 0], [1, 1, 1], [2, 2, 2]], [[0, 1, 2], [0, 1, 2]]])
 >>> # создание единичной матрицы >>> np. eye(2, dtype=int)") … и другие варианты (продолжение) >>> # создание единичной матрицы >>> np. eye(2, dtype=int) array([[1, 0], [0, 1]]) >>> np. eye(3, k=1) array([[ 0. , 1. , 0. ], [ 0. , 1. ], [ 0. , 0. ]]) >>> c = np. arange(10). reshape(2, 5) # метод reshape изменяет форму массива >>> c array([[ 0, 1, 2, 3, 4], [5, 6, 7, 8, 9]])
… и другие варианты (продолжение) >>> # создание единичной матрицы >>> np. eye(2, dtype=int) array([[1, 0], [0, 1]]) >>> np. eye(3, k=1) array([[ 0. , 1. , 0. ], [ 0. , 1. ], [ 0. , 0. ]]) >>> c = np. arange(10). reshape(2, 5) # метод reshape изменяет форму массива >>> c array([[ 0, 1, 2, 3, 4], [5, 6, 7, 8, 9]])
 - текстовый формат,") Создание массивов Num. Py из текстовых файлов CSV (comma separated values) - текстовый формат, предназначенный для представления табличных данных. Каждая строка файла — это одна строка таблицы. Значения отдельных колонок разделяются разделительным символом (delimiter). Исходя из названия формата, разделителем по-умолчанию является «запятая» (, ), но чаще всего если где десятичным разделителем является запятая, в качестве табличного разделителя, как правило, используется точка с запятой. Например, таблица в Microsoft Excel: После экспорта в CSV-файл будет представлена в следующем виде: 1965; Пиксел; E 240 – формальдегид (опасный консервант)!; "красный, зелёный, битый"; 3000, 00 1965; Мышка; "А правильней ""Использовать Ёлочки"""; ; 4900, 00 "Н/д"; Кнопка; Сочетания клавиш; "MUST USE! Ctrl, Alt, Shift"; 4799, 00
Создание массивов Num. Py из текстовых файлов CSV (comma separated values) - текстовый формат, предназначенный для представления табличных данных. Каждая строка файла — это одна строка таблицы. Значения отдельных колонок разделяются разделительным символом (delimiter). Исходя из названия формата, разделителем по-умолчанию является «запятая» (, ), но чаще всего если где десятичным разделителем является запятая, в качестве табличного разделителя, как правило, используется точка с запятой. Например, таблица в Microsoft Excel: После экспорта в CSV-файл будет представлена в следующем виде: 1965; Пиксел; E 240 – формальдегид (опасный консервант)!; "красный, зелёный, битый"; 3000, 00 1965; Мышка; "А правильней ""Использовать Ёлочки"""; ; 4900, 00 "Н/д"; Кнопка; Сочетания клавиш; "MUST USE! Ctrl, Alt, Shift"; 4799, 00
 Создание массивов Num. Py из текстовых файлов # Допустим, так выглядит файл sample. csv ; 12 14 ; 15 32 ; 5 ; 33 4 ; 64 ; 33 23 ; 21 ; 33 -99. 9 ; 4 ; 33 # Какой-то комментарий Содержимое текстового csv-файла d 1 = np. genfromtxt( ‘C: \path\to\folder\to\file\sample. txt', # Имя файла (включая путь до него) [ delimiter=", ", ] # Символ-разделитель столбцов (по-умолчанию - табуляция / пробел) [ comments="#", ] # Строки, начинающиеся с этого символа будут пропущены [ usecols=[0, -1], [ skip_header=M, [ skip_footes=N ) ] # Номера столбцов для загрузки (в примере – 1 ый и последний) ] # Пропуск M-строк в начале файла ] # Пропуск N-строк в конце файла # Все возможные аргументы метода np. genfromtxt описаны в документации (http: //docs. scipy. org/doc/numpy/reference/generated/numpy. genfromtxt. html)
Создание массивов Num. Py из текстовых файлов # Допустим, так выглядит файл sample. csv ; 12 14 ; 15 32 ; 5 ; 33 4 ; 64 ; 33 23 ; 21 ; 33 -99. 9 ; 4 ; 33 # Какой-то комментарий Содержимое текстового csv-файла d 1 = np. genfromtxt( ‘C: \path\to\folder\to\file\sample. txt', # Имя файла (включая путь до него) [ delimiter=", ", ] # Символ-разделитель столбцов (по-умолчанию - табуляция / пробел) [ comments="#", ] # Строки, начинающиеся с этого символа будут пропущены [ usecols=[0, -1], [ skip_header=M, [ skip_footes=N ) ] # Номера столбцов для загрузки (в примере – 1 ый и последний) ] # Пропуск M-строк в начале файла ] # Пропуск N-строк в конце файла # Все возможные аргументы метода np. genfromtxt описаны в документации (http: //docs. scipy. org/doc/numpy/reference/generated/numpy. genfromtxt. html)
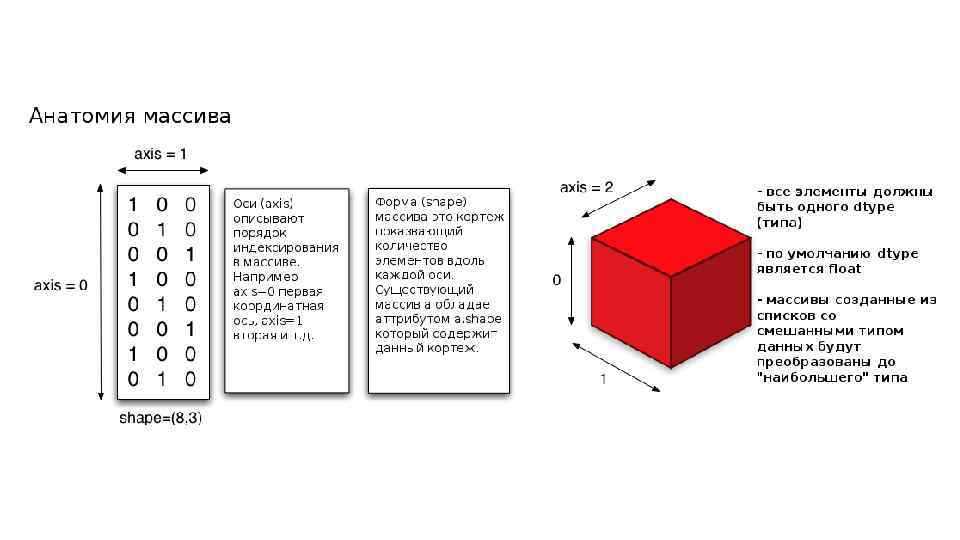
 массива (ранг массива) ndarray. shape —") Свойства объектов ndarray. ndim — число осей (измерений) массива (ранг массива) ndarray. shape — размеры массива, его форма. Это кортеж натуральных чисел, показывающий длину массива по каждой оси. Для матрицы из n строк и m столбов, shape будет (n, m). Число элементов кортежа shape равно рангу массива, то есть ndim. ndarray. size — число всех элементов массива. Равно произведению всех элементов атрибута shape. ndarray. dtype — объект, описывающий тип элементов массива. Можно определить dtype, используя стандартные типы данных Python. По-умолчанию, dtype = float 64
Свойства объектов ndarray. ndim — число осей (измерений) массива (ранг массива) ndarray. shape — размеры массива, его форма. Это кортеж натуральных чисел, показывающий длину массива по каждой оси. Для матрицы из n строк и m столбов, shape будет (n, m). Число элементов кортежа shape равно рангу массива, то есть ndim. ndarray. size — число всех элементов массива. Равно произведению всех элементов атрибута shape. ndarray. dtype — объект, описывающий тип элементов массива. Можно определить dtype, используя стандартные типы данных Python. По-умолчанию, dtype = float 64
 0. 6336371838734877 >>> np. random. sample(3) array([") Массив случайных чисел >>> np. random. sample() 0. 6336371838734877 >>> np. random. sample(3) array([ 0. 53478558, 0. 1441317 , 0. 15711313]) >>> np. random. sample((2, 3)) array([ [ 0. 12915769, 0. 09448946, 0. 58778985], [ 0. 45488207, 0. 19335243, 0. 22129977]]) >>> np. random. uniform(2, 8, (2, 10)) # равномерное распределение чисел в диапазоне 2… 8 с формой 2 x 10 array([[ 3. 1517914 , 3. 10313483, 2. 84007134, 3. 21556436, 4. 64531786, 2. 99232714, 7. 03064897, 4. 38691765, 5. 27488548, 2. 63472454], [ 6. 39470358, 5. 63084131, 4. 69996748, 7. 07260546, 7. 44340813, 4. 10722203, 7. 52956646, 4. 8596943 , 3. 97923973, 5. 64505363]])
Массив случайных чисел >>> np. random. sample() 0. 6336371838734877 >>> np. random. sample(3) array([ 0. 53478558, 0. 1441317 , 0. 15711313]) >>> np. random. sample((2, 3)) array([ [ 0. 12915769, 0. 09448946, 0. 58778985], [ 0. 45488207, 0. 19335243, 0. 22129977]]) >>> np. random. uniform(2, 8, (2, 10)) # равномерное распределение чисел в диапазоне 2… 8 с формой 2 x 10 array([[ 3. 1517914 , 3. 10313483, 2. 84007134, 3. 21556436, 4. 64531786, 2. 99232714, 7. 03064897, 4. 38691765, 5. 27488548, 2. 63472454], [ 6. 39470358, 5. 63084131, 4. 69996748, 7. 07260546, 7. 44340813, 4. 10722203, 7. 52956646, 4. 8596943 , 3. 97923973, 5. 64505363]])
. reshape(100, 100) [[ 0 1 2. .") Вывод «больших» массивов >>> print np. arange(10000). reshape(100, 100) [[ 0 1 2. . . , 97 98 99] [ 100 101 102. . . , 197 198 199] [ 200 201 202. . . , 297 298 299] . . . , [9700 9701 9702. . . , 9797 9798 9799] [9800 9801 9802. . . , 9897 9898 9899] [9900 9901 9902. . . , 9997 9998 9999]]
Вывод «больших» массивов >>> print np. arange(10000). reshape(100, 100) [[ 0 1 2. . . , 97 98 99] [ 100 101 102. . . , 197 198 199] [ 200 201 202. . . , 297 298 299] . . . , [9700 9701 9702. . . , 9797 9798 9799] [9800 9801 9802. . . , 9897 9898 9899] [9900 9901 9902. . . , 9997 9998 9999]]
 Базовые операции с массивами ndarray # # Арифметические операции над массивами выполняются поэлементно. # Создается новый массив, который заполняется результатами действия оператора. # >>> a = np. array( [20, 30, 40, 50] ) >>> b = np. arange( 4 ) >>> c = a-b >>> c array([20, 29, 38, 47]) >>> b**2 array([ 0, 1, 4, 9]) >>> 10*sin(a) array([ 9. 12945251, -9. 88031624, 7. 4511316 , -2. 62374854]) >>> a<35 array([True, False, False], dtype=bool)
Базовые операции с массивами ndarray # # Арифметические операции над массивами выполняются поэлементно. # Создается новый массив, который заполняется результатами действия оператора. # >>> a = np. array( [20, 30, 40, 50] ) >>> b = np. arange( 4 ) >>> c = a-b >>> c array([20, 29, 38, 47]) >>> b**2 array([ 0, 1, 4, 9]) >>> 10*sin(a) array([ 9. 12945251, -9. 88031624, 7. 4511316 , -2. 62374854]) >>> a<35 array([True, False, False], dtype=bool)
 работает тоже поэлементно >>> A = np. array( [[1,") # Стандартная операция умножения (*) работает тоже поэлементно >>> A = np. array( [[1, 1], [ 0, 1]] ) >>> B = np. array( [[2, 0], [3, 4]] ) >>> A*B # поэлементное произведение array([[2, 0], [ 0, 4]]) >>> np. dot(A, B) # матричное произведение array([[5, 4], [3, 4]])
# Стандартная операция умножения (*) работает тоже поэлементно >>> A = np. array( [[1, 1], [ 0, 1]] ) >>> B = np. array( [[2, 0], [3, 4]] ) >>> A*B # поэлементное произведение array([[2, 0], [ 0, 4]]) >>> np. dot(A, B) # матричное произведение array([[5, 4], [3, 4]])
![>>> B = np. arange(3) >>> B array([ 0, 1, 2]) >>> exp(B) array([](https://present5.com/presentation/-59259194_331257756/image-21.jpg ">>> B = np. arange(3) >>> B array([ 0, 1, 2]) >>> exp(B) array([") >>> B = np. arange(3) >>> B array([ 0, 1, 2]) >>> exp(B) array([ 1. , 2. 71828183, 7. 3890561 ]) >>> sqrt(B) array([ 0. , 1. 41421356]) >>> C = array([2. , -1. , 4. ]) >>> np. add(B, C) # Сложение 2 х массивов array([ 2. , 0. , 6. ])
>>> B = np. arange(3) >>> B array([ 0, 1, 2]) >>> exp(B) array([ 1. , 2. 71828183, 7. 3890561 ]) >>> sqrt(B) array([ 0. , 1. 41421356]) >>> C = array([2. , -1. , 4. ]) >>> np. add(B, C) # Сложение 2 х массивов array([ 2. , 0. , 6. ])
, dtype=int) >>> b =") in-place операции c массивами >>> a = np. ones((2, 3), dtype=int) >>> b = np. random((2, 3)) >>> a *= 3 # Умножение всех элементов на 3 >>> a array([[3, 3, 3], [3, 3, 3]]) >>> b += a # Прибавление элементов массива «a» к элементам «b» >>> b array([[ 3. 69092703, 3. 8324276 , 3. 0114541 ], [ 3. 18679111, 3. 3039349 , 3. 37600289]]) >>> a += b # b конвертируется к типу int >>> a array([[6, 6, 6], [6, 6, 6]])
in-place операции c массивами >>> a = np. ones((2, 3), dtype=int) >>> b = np. random((2, 3)) >>> a *= 3 # Умножение всех элементов на 3 >>> a array([[3, 3, 3], [3, 3, 3]]) >>> b += a # Прибавление элементов массива «a» к элементам «b» >>> b array([[ 3. 69092703, 3. 8324276 , 3. 0114541 ], [ 3. 18679111, 3. 3039349 , 3. 37600289]]) >>> a += b # b конвертируется к типу int >>> a array([[6, 6, 6], [6, 6, 6]])
) >>> a array([[ 0. 6903007") Некоторые методы объектов ndarray >>> a = random((2, 3)) >>> a array([[ 0. 6903007 , 0. 39168346, 0. 16524769], [ 0. 48819875, 0. 77188505, 0. 94792155]]) # # По-умолчанию данные методы рассматривают массив, # как список чисел, без учета формы. # Т. е. считают, что массив одномерный. # >>> a. sum() 3. 4552372100521485 >>> a. min() 0. 16524768654743593 >>> a. max() 0. 9479215542670073
Некоторые методы объектов ndarray >>> a = random((2, 3)) >>> a array([[ 0. 6903007 , 0. 39168346, 0. 16524769], [ 0. 48819875, 0. 77188505, 0. 94792155]]) # # По-умолчанию данные методы рассматривают массив, # как список чисел, без учета формы. # Т. е. считают, что массив одномерный. # >>> a. sum() 3. 4552372100521485 >>> a. min() 0. 16524768654743593 >>> a. max() 0. 9479215542670073
. reshape(3, 4)") Параметр axis – индекс оси для расчетов >>> b = np. arange(12). reshape(3, 4) >>> b array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) >>> b. sum(axis= 0) # сумма в каждом столбце array([12, 15, 18, 21]) >>> b. min(axis=1) # наименьшее число в каждой строке array([ 0, 4, 8]) >>> b. cumsum(axis=1) # накопительная сумма каждой строки array([[ 0, 1, 3, 6], [ 4, 9, 15, 22], [ 8, 17, 27, 38]])
Параметр axis – индекс оси для расчетов >>> b = np. arange(12). reshape(3, 4) >>> b array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) >>> b. sum(axis= 0) # сумма в каждом столбце array([12, 15, 18, 21]) >>> b. min(axis=1) # наименьшее число в каждой строке array([ 0, 4, 8]) >>> b. cumsum(axis=1) # накопительная сумма каждой строки array([[ 0, 1, 3, 6], [ 4, 9, 15, 22], [ 8, 17, 27, 38]])
 Индексы, срезы, итерации # Одномерные массивы осуществляют операции индексирования, срезов и итераций # очень схожим образом с обычными списками и другими последовательностями Python. >>> a = np. arange(10)**3 >>> a array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729]) >>> a[2] 8 >>> a[2: 5] array([ 8, 27, 64]) >>> a[: 6: 2] = -1000 # изменить элементы в a >>> a array([-1000, 1, -1000, 27. -1000, 125, 216, 343, 512, 729]) >>> a[: : -1] # перевернуть a array([ 729, 512, 343, 216, 125, -1000, 27, -1000, 1, -1000]) >>> for i in a: print i**(1/3. ), nan 1. 0 nan 3. 0 nan 5. 0 6. 0 7. 0 8. 0 9. 0
Индексы, срезы, итерации # Одномерные массивы осуществляют операции индексирования, срезов и итераций # очень схожим образом с обычными списками и другими последовательностями Python. >>> a = np. arange(10)**3 >>> a array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729]) >>> a[2] 8 >>> a[2: 5] array([ 8, 27, 64]) >>> a[: 6: 2] = -1000 # изменить элементы в a >>> a array([-1000, 1, -1000, 27. -1000, 125, 216, 343, 512, 729]) >>> a[: : -1] # перевернуть a array([ 729, 512, 343, 216, 125, -1000, 27, -1000, 1, -1000]) >>> for i in a: print i**(1/3. ), nan 1. 0 nan 3. 0 nan 5. 0 6. 0 7. 0 8. 0 9. 0
 # У многомерных массивов на каждую ось приходится один индекс.") Индексы, срезы, итерации (продолжение) # У многомерных массивов на каждую ось приходится один индекс. # Индексы передаются в виде последовательности чисел, разделенных запятыми. >>> b = np. array([[ 0, 1, [10, 11, [20, 21, [30, 31, [40, 41, >>> b array([[ 0, 1, 2, 3], [10, 11, 12, 13], [20, 21, 22, 23], [30, 31, 32, 33], [40, 41, 42, 43]]) 2, 3], 12, 13], 22, 23], 32, 33], 42, 43]]) >>> b[2, 3] 23 >>> b[: , 1] # второй столбец массива b array([ 1, 11, 21, 31, 41]) >>> b[1: 3, : ] # вторая и третья строки массива b array([[10, 11, 12, 13], [20, 21, 22, 23]])
Индексы, срезы, итерации (продолжение) # У многомерных массивов на каждую ось приходится один индекс. # Индексы передаются в виде последовательности чисел, разделенных запятыми. >>> b = np. array([[ 0, 1, [10, 11, [20, 21, [30, 31, [40, 41, >>> b array([[ 0, 1, 2, 3], [10, 11, 12, 13], [20, 21, 22, 23], [30, 31, 32, 33], [40, 41, 42, 43]]) 2, 3], 12, 13], 22, 23], 32, 33], 42, 43]]) >>> b[2, 3] 23 >>> b[: , 1] # второй столбец массива b array([ 1, 11, 21, 31, 41]) >>> b[1: 3, : ] # вторая и третья строки массива b array([[10, 11, 12, 13], [20, 21, 22, 23]])
 # # Когда индексов меньше, чем осей, отсутствующие индексы предполагаются") Индексы, срезы, итерации (продолжение) # # Когда индексов меньше, чем осей, отсутствующие индексы предполагаются дополненными с помощью срезов: # >>> b[-1] # последняя строка. Эквивалентно b[-1, : ] array([40, 41, 42, 43]) # # # # b[i] можно читать как b[i, <столько символов ': ', сколько нужно>]. В Num. Py это также может быть записано с помощью точек, как b[i, . . . ]. Например, если x имеет ранг 5 (то есть у него 5 осей), тогда x[1, 2, . . . ] эквивалентно x[1, 2, : , : ], x[. . . , 3] то же самое, что x[: , : , 3] и x[4, . . . , 5, : ] это x[4, : , 5, : ].
Индексы, срезы, итерации (продолжение) # # Когда индексов меньше, чем осей, отсутствующие индексы предполагаются дополненными с помощью срезов: # >>> b[-1] # последняя строка. Эквивалентно b[-1, : ] array([40, 41, 42, 43]) # # # # b[i] можно читать как b[i, <столько символов ': ', сколько нужно>]. В Num. Py это также может быть записано с помощью точек, как b[i, . . . ]. Например, если x имеет ранг 5 (то есть у него 5 осей), тогда x[1, 2, . . . ] эквивалентно x[1, 2, : , : ], x[. . . , 3] то же самое, что x[: , : , 3] и x[4, . . . , 5, : ] это x[4, : , 5, : ].
 массивов") Broadcasting (расширение) массивов """ Термин broadcasting описывает механизм, с помощью которого библиотека Num. Py выполняет посимвольные арифметические операции над массивами разной формы. В общем случае, меньший (по форме и размеру) "расширяется" до размера "большего" массива так, чтобы их форма стала одинаковой. """ # Массивы одинаковой формы и размера >>> a = np. array([1. 0, 2. 0, 3. 0]) >>> b = np. array([2. 0, 2. 0]) >>> a * b # Поэлементное умножение происходит без выполнения broadcasting-а array([ 2. , 4. , 6. ]) >>> a = np. array([1. 0, 2. 0, 3. 0]) >>> b = 3. 0 >>> a * b # Умножение вектора (массива) на скаляр (число) - скаляр при умножении будет расширен до вектора [3. 0, 3. 0] array([ 3. , 6. , 9. ]) # Второй путь (умножение на скаляр) - более эффективный с точки зрения скорости работы и занимаемой памяти
Broadcasting (расширение) массивов """ Термин broadcasting описывает механизм, с помощью которого библиотека Num. Py выполняет посимвольные арифметические операции над массивами разной формы. В общем случае, меньший (по форме и размеру) "расширяется" до размера "большего" массива так, чтобы их форма стала одинаковой. """ # Массивы одинаковой формы и размера >>> a = np. array([1. 0, 2. 0, 3. 0]) >>> b = np. array([2. 0, 2. 0]) >>> a * b # Поэлементное умножение происходит без выполнения broadcasting-а array([ 2. , 4. , 6. ]) >>> a = np. array([1. 0, 2. 0, 3. 0]) >>> b = 3. 0 >>> a * b # Умножение вектора (массива) на скаляр (число) - скаляр при умножении будет расширен до вектора [3. 0, 3. 0] array([ 3. , 6. , 9. ]) # Второй путь (умножение на скаляр) - более эффективный с точки зрения скорости работы и занимаемой памяти
 массивов (продолжение)") Broadcasting (расширение) массивов (продолжение) """ Размеры массивов являются совместимыми (т. е. может быть выполнен broadcasting), когда выполняется одно из условий: • Размеры вдоль оси равны • Размер по одной из осей равен 1 """ # Ни одно из условий не выполнено >>> x = np. arange(4) >>> y = np. ones(5) >>> x. shape (4, ) >>> y. shape (5, ) >>> x + y
Broadcasting (расширение) массивов (продолжение) """ Размеры массивов являются совместимыми (т. е. может быть выполнен broadcasting), когда выполняется одно из условий: • Размеры вдоль оси равны • Размер по одной из осей равен 1 """ # Ни одно из условий не выполнено >>> x = np. arange(4) >>> y = np. ones(5) >>> x. shape (4, ) >>> y. shape (5, ) >>> x + y
 массивов (продолжение) # Условия выполнены, broadcasting возможен >>> x = np. arange(4)") Broadcasting (расширение) массивов (продолжение) # Условия выполнены, broadcasting возможен >>> x = np. arange(4) >>> z = np. ones((3, 4)) >>> x. shape (4, ) >>> z. shape (3, 4) >>> (x + z). shape (3, 4) >>> x + z array([[ 1. , 2. , 3. , 4. ], 4. ]])
Broadcasting (расширение) массивов (продолжение) # Условия выполнены, broadcasting возможен >>> x = np. arange(4) >>> z = np. ones((3, 4)) >>> x. shape (4, ) >>> z. shape (3, 4) >>> (x + z). shape (3, 4) >>> x + z array([[ 1. , 2. , 3. , 4. ], 4. ]])