

 Статистика в Excel
Статистика в Excel
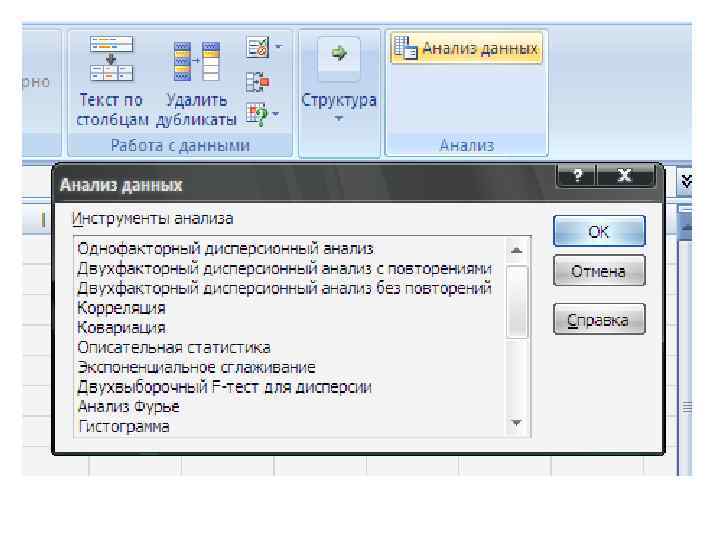
 • В Microsoft Excel представлен список методов статистической обработки данных, вызываемых командой Сервис/Анализ данных. Каждый метод реализован в виде отдельного режима работы. Пакет анализа включает следующие инструменты: • Гистограмма; • Выборка; • Генерация случайных чисел; • Методы проверки статистических гипотез; • Дисперсионный анализ и др. • Наряду с надстройкой «Анализ данных» могут применяться статистические функции.
• В Microsoft Excel представлен список методов статистической обработки данных, вызываемых командой Сервис/Анализ данных. Каждый метод реализован в виде отдельного режима работы. Пакет анализа включает следующие инструменты: • Гистограмма; • Выборка; • Генерация случайных чисел; • Методы проверки статистических гипотез; • Дисперсионный анализ и др. • Наряду с надстройкой «Анализ данных» могут применяться статистические функции.
 Гистограмма. Результат сводки и группировки материалов статистического наблюдения оформляются в виде таблиц и статистических рядов распределения. В зависимости от признака, положенного в основу образования ряда, различают атрибутивные и вариационные ряды распределения. Последние, в свою очередь делятся от характера вариации на дискретные (прерывные) и интервальные (непрерывные). Удобнее всего ряды распределения анализировать с помощью их графического изображения. Наглядное представление о характере изменения частот вариационного ряда дают полигон и гистограмма.
Гистограмма. Результат сводки и группировки материалов статистического наблюдения оформляются в виде таблиц и статистических рядов распределения. В зависимости от признака, положенного в основу образования ряда, различают атрибутивные и вариационные ряды распределения. Последние, в свою очередь делятся от характера вариации на дискретные (прерывные) и интервальные (непрерывные). Удобнее всего ряды распределения анализировать с помощью их графического изображения. Наглядное представление о характере изменения частот вариационного ряда дают полигон и гистограмма.
 Полигон используется для изображения дискретных вариационных рядов. Для построения полигона применяется мастер построения диаграмм
Полигон используется для изображения дискретных вариационных рядов. Для построения полигона применяется мастер построения диаграмм
 Для изображения интервальных вариационных рядов распределения применяют гистограммы. При необходимости гистограмма интегрального ряда распределения может быть преобразована в полигон. Для этого нужно середины верхних сторон прямоугольников соединить прямыми линиями
Для изображения интервальных вариационных рядов распределения применяют гистограммы. При необходимости гистограмма интегрального ряда распределения может быть преобразована в полигон. Для этого нужно середины верхних сторон прямоугольников соединить прямыми линиями
 В практике возникает необходимость в преобразовании ряда распределения в кумулятивные ряды, строящиеся по накопленным частотам. С их помощью можно определять структурные средние и наблюдать за процессом концентрации изучаемого явления (кривые Лоренца)
В практике возникает необходимость в преобразовании ряда распределения в кумулятивные ряды, строящиеся по накопленным частотам. С их помощью можно определять структурные средние и наблюдать за процессом концентрации изучаемого явления (кривые Лоренца)
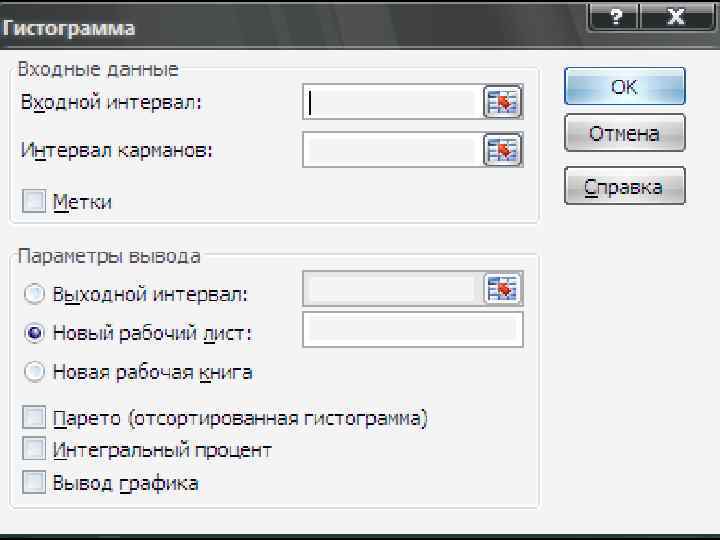
 Режим «Гистограмма» служит для вычисления частот попадания данных в указанные границы интервального вариационного ряда распределения. Параметр Описание Входной интервал Интервал карманов Ссылка на ячейки, содержащие анализируемые данные Метки Задается если первая строка (столбец) во входном диапазоне содержит заголовки. Поле, в которое необходимо ввести ссылку на левую верхнюю ячейку выходного диапазона. Выходной интервал Необязательный параметр. Набор граничных значений, определяющих интервалы. Эти значения должны быть введены в возрастающем порядке. Вычисляется число попаданий в сформированные интервалы, причем границы интервалов являются строгими нижними и нестрогими верхними: а<х b. Если диапазон карманов не задан, то набор интервалов будет создан автоматически.
Режим «Гистограмма» служит для вычисления частот попадания данных в указанные границы интервального вариационного ряда распределения. Параметр Описание Входной интервал Интервал карманов Ссылка на ячейки, содержащие анализируемые данные Метки Задается если первая строка (столбец) во входном диапазоне содержит заголовки. Поле, в которое необходимо ввести ссылку на левую верхнюю ячейку выходного диапазона. Выходной интервал Необязательный параметр. Набор граничных значений, определяющих интервалы. Эти значения должны быть введены в возрастающем порядке. Вычисляется число попаданий в сформированные интервалы, причем границы интервалов являются строгими нижними и нестрогими верхними: а<х b. Если диапазон карманов не задан, то набор интервалов будет создан автоматически.
 Новый рабочий лист Вставка результата анализа на новый рабочий лист начиная с ячейки А 1. Можно задать имя открываемого рабочего листа, указав его в соседней области. Новая Результат анализа выводится в новой рабочая рабочей книге на первом листе начиная с книга ячейки А 1. Парето Устанавливает данные в порядке убывания частоты. Интерваль Выполняет расчет в процентах ный накопленных частот и включает в процент гистограмму графика кумуляты. Вывод Автоматически создает встроенную графика диаграмму на листе содержащем выходной диапазон.
Новый рабочий лист Вставка результата анализа на новый рабочий лист начиная с ячейки А 1. Можно задать имя открываемого рабочего листа, указав его в соседней области. Новая Результат анализа выводится в новой рабочая рабочей книге на первом листе начиная с книга ячейки А 1. Парето Устанавливает данные в порядке убывания частоты. Интерваль Выполняет расчет в процентах ный накопленных частот и включает в процент гистограмму графика кумуляты. Вывод Автоматически создает встроенную графика диаграмму на листе содержащем выходной диапазон.
 пример построения гистограммы и кумуляты, для задачи, в которой представлен общий объем товарооборота по районам Ярославский области.
пример построения гистограммы и кумуляты, для задачи, в которой представлен общий объем товарооборота по районам Ярославский области.
 Дисперсионный анализ – это статистический метод анализа результатов наблюдений, зависящих от различных одновременно действующих факторов и оценка их влияния. В зависимости от количества факторов, включенных в анализ, различают классификацию по одному фактору (однофакторный анализ), по двум признакам (двухфакторный анализ) и многофакторную классификацию, изучением которой занимается многофакторный анализ.
Дисперсионный анализ – это статистический метод анализа результатов наблюдений, зависящих от различных одновременно действующих факторов и оценка их влияния. В зависимости от количества факторов, включенных в анализ, различают классификацию по одному фактору (однофакторный анализ), по двум признакам (двухфакторный анализ) и многофакторную классификацию, изучением которой занимается многофакторный анализ.
 Задачи однофакторного дисперсионного анализа являются самыми простыми, но часто встречаются на практике. Методы дисперсионного анализа основываются на следующем: пусть а 1, а 2, …, аm – математическое ожидание результатов признака соответственно при уровне А(1), А(2), …, А(m) (i=1, 2, , m). Если при изменении уровня фактора групповые математические ожидания не изменяются, т. е. а 1= а 2 =…= аm, то считают, что результативный признак не зависит от фактора А, в противном случае такая зависимость имеется.
Задачи однофакторного дисперсионного анализа являются самыми простыми, но часто встречаются на практике. Методы дисперсионного анализа основываются на следующем: пусть а 1, а 2, …, аm – математическое ожидание результатов признака соответственно при уровне А(1), А(2), …, А(m) (i=1, 2, , m). Если при изменении уровня фактора групповые математические ожидания не изменяются, т. е. а 1= а 2 =…= аm, то считают, что результативный признак не зависит от фактора А, в противном случае такая зависимость имеется.
 Поскольку числовые значения математических ожиданий неизвестны, возникает задача проверки гипотезы H 0: а 1=а 2=…=аm, при выполнении условий: • наблюдения независимы и проводятся в одинаковых условиях; • результативный признак имеет нормальное распределение с постоянной для различных уровней генеральной дисперсией 2.
Поскольку числовые значения математических ожиданий неизвестны, возникает задача проверки гипотезы H 0: а 1=а 2=…=аm, при выполнении условий: • наблюдения независимы и проводятся в одинаковых условиях; • результативный признак имеет нормальное распределение с постоянной для различных уровней генеральной дисперсией 2.
 гипотезы при заданном уровне значимости находиться правосторонняя критическая точка wкр,") Для подтверждения (или опровержения) гипотезы при заданном уровне значимости находиться правосторонняя критическая точка wкр, определяющая критический интервал (wкр; + ). Если w попадает в интервал, то гипотеза H 0: 21= 22=…= 2 m отвергается, иначе принимается.
Для подтверждения (или опровержения) гипотезы при заданном уровне значимости находиться правосторонняя критическая точка wкр, определяющая критический интервал (wкр; + ). Если w попадает в интервал, то гипотеза H 0: 21= 22=…= 2 m отвергается, иначе принимается.
 Если гипотеза H 0: 21= 22=…= 2 m подтверждается, то можно приступить к процедуре дисперсионного анализа, т. е. проверке гипотезы H 0: а 1=а 2=…=аm. В математической статистике доказывается формула: , где - общая выборочная дисперсия, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y фактора А и остаточных факторов; - дисперсия групповых средних, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y фактора А; - средняя групповых дисперсий, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y остаточных факторов.
Если гипотеза H 0: 21= 22=…= 2 m подтверждается, то можно приступить к процедуре дисперсионного анализа, т. е. проверке гипотезы H 0: а 1=а 2=…=аm. В математической статистике доказывается формула: , где - общая выборочная дисперсия, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y фактора А и остаточных факторов; - дисперсия групповых средних, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y фактора А; - средняя групповых дисперсий, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y остаточных факторов.
 В математической статистике доказывается, что если гипотеза H 0: а 1=а 2=…=аm верна, то величина имеет F-распределение с числом степеней свободы k=m-1 и l=n-m. При использовании F-критерия строиться правосторонняя критическая область (Fкр; + ). Если расчетное значение Fр- попадает в интервал, то гипотеза H 0: а 1=а 2=…=аm отвергается, т. е. считается что фактор А влияет на результативный признак Y, иначе влияние фактора А на признак Y не подтверждается.
В математической статистике доказывается, что если гипотеза H 0: а 1=а 2=…=аm верна, то величина имеет F-распределение с числом степеней свободы k=m-1 и l=n-m. При использовании F-критерия строиться правосторонняя критическая область (Fкр; + ). Если расчетное значение Fр- попадает в интервал, то гипотеза H 0: а 1=а 2=…=аm отвергается, т. е. считается что фактор А влияет на результативный признак Y, иначе влияние фактора А на признак Y не подтверждается.
 • Режим «Однофакторный дисперсионный анализ» служит для выяснения факта влияния контролируемого фактора А на результативный признак Y на основе выборочных данных.
• Режим «Однофакторный дисперсионный анализ» служит для выяснения факта влияния контролируемого фактора А на результативный признак Y на основе выборочных данных.
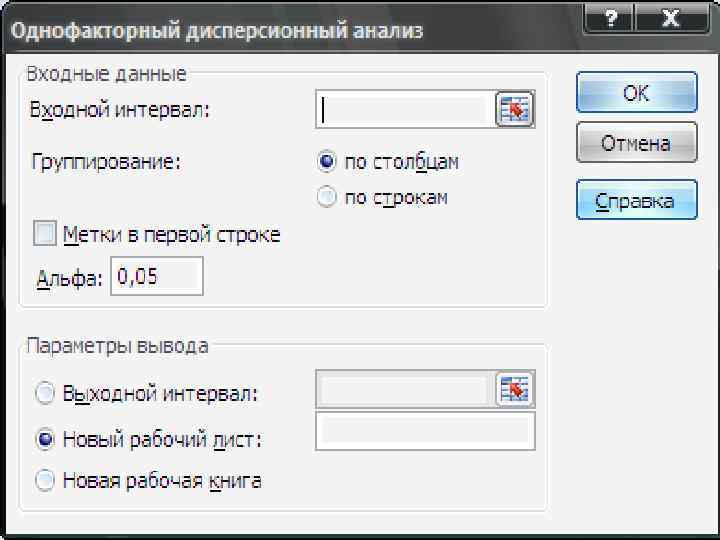
 Параметр Группирование Альфа Описание Устанавливается в положение «По столбцам» , «По строкам» в зависимости от расположения данных во входном диапазоне См. описание в режиме «Двухвыборочный tтест» таб. 13 Входной интервал Метки Выходной интервал Новый рабочий лист Новая рабочая книга См. описание в режиме «Гистограмма»
Параметр Группирование Альфа Описание Устанавливается в положение «По столбцам» , «По строкам» в зависимости от расположения данных во входном диапазоне См. описание в режиме «Двухвыборочный tтест» таб. 13 Входной интервал Метки Выходной интервал Новый рабочий лист Новая рабочая книга См. описание в режиме «Гистограмма»
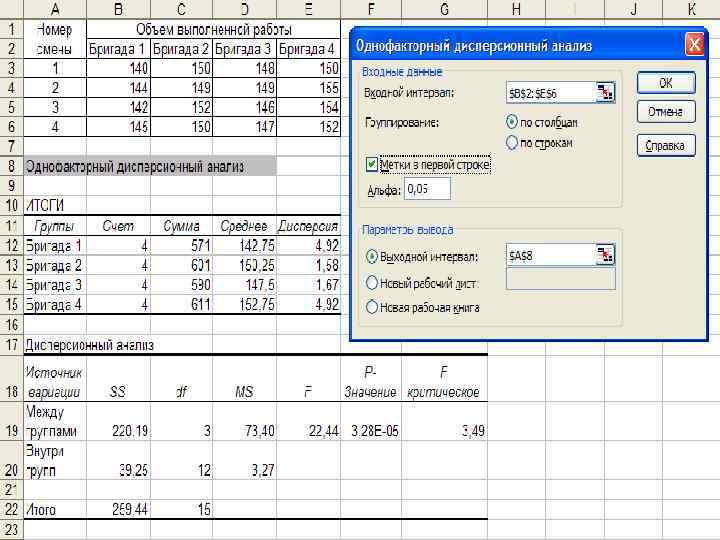
 пример использования режима «Однофакторный дисперсионный анализ» . Известны данные об объеме работ, выполненных на стройке (за смену) четырьмя бригадами. Требуется выяснить, зависит ли объем выполненных работ от работающей бригады при уровне значимости =0, 05. Так как Fр попадает в критическую область, то можно сделать вывод о том, что объем ежедневной выработки зависит от работающей бригады.
пример использования режима «Однофакторный дисперсионный анализ» . Известны данные об объеме работ, выполненных на стройке (за смену) четырьмя бригадами. Требуется выяснить, зависит ли объем выполненных работ от работающей бригады при уровне значимости =0, 05. Так как Fр попадает в критическую область, то можно сделать вывод о том, что объем ежедневной выработки зависит от работающей бригады.
 Двухфакторный дисперсионный анализ без повторений и с повторениями Логика однофакторного и двухфакторного дисперсионного анализа во многом схожа, разница состоит в наличии двух факторов А и В, т. е. проверке следующих гипотез: HА: а 1=а 2=…=аm. А; HВ: b 1=b 2=…=bm. В.
Двухфакторный дисперсионный анализ без повторений и с повторениями Логика однофакторного и двухфакторного дисперсионного анализа во многом схожа, разница состоит в наличии двух факторов А и В, т. е. проверке следующих гипотез: HА: а 1=а 2=…=аm. А; HВ: b 1=b 2=…=bm. В.
 Основой проведения двухфакторного дисперсионного анализа служит комбинационная группировка по двум факторам с последующим разложением дисперсии результативного признака по формуле , где - общая выборочная дисперсия, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y фактора А, фактора В и остаточных факторов; - дисперсия групповых средних по фактору А, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y фактора А; - дисперсия групповых средних по фактору В, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y фактора В; - средняя групповых дисперсий, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y остаточных факторов.
Основой проведения двухфакторного дисперсионного анализа служит комбинационная группировка по двум факторам с последующим разложением дисперсии результативного признака по формуле , где - общая выборочная дисперсия, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y фактора А, фактора В и остаточных факторов; - дисперсия групповых средних по фактору А, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y фактора А; - дисперсия групповых средних по фактору В, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y фактора В; - средняя групповых дисперсий, показатель вариации наблюдаемых «игреков» , вызванной влиянием на Y остаточных факторов.
 На основе данного разложения для генеральной дисперсии 2 находятся четыре несмещенные оценки. Причем оценка является несмещенной в любом случае, оценка - при выполнении гипотезы НА, оценка - при выполнении гипотезы Нв, а оценка - при выполнении гипотезы НА и Нв. В математической статистике доказывается, что если гипотеза HА верна, то величина
На основе данного разложения для генеральной дисперсии 2 находятся четыре несмещенные оценки. Причем оценка является несмещенной в любом случае, оценка - при выполнении гипотезы НА, оценка - при выполнении гипотезы Нв, а оценка - при выполнении гипотезы НА и Нв. В математической статистике доказывается, что если гипотеза HА верна, то величина
(m. B-1). Аналогично рассчитывается") Имеет F-распределение с числом степеней свободы k=m. A-1 и l=(m. A-1)(m. B-1). Аналогично рассчитывается FB. Проверка выдвинутых гипотез осуществляется так же, как и при однофакторном дисперсионном анализе. Двухфакторный дисперсионный анализ имеет две разновидности: без повторений и с повторениями. В первом случае каждому уровню факторов соответствует только одна выборка данных, во втором – определенным уровням может соответствовать более одной выборки.
Имеет F-распределение с числом степеней свободы k=m. A-1 и l=(m. A-1)(m. B-1). Аналогично рассчитывается FB. Проверка выдвинутых гипотез осуществляется так же, как и при однофакторном дисперсионном анализе. Двухфакторный дисперсионный анализ имеет две разновидности: без повторений и с повторениями. В первом случае каждому уровню факторов соответствует только одна выборка данных, во втором – определенным уровням может соответствовать более одной выборки.
 Режимы «Двухфакторный дисперсионный анализ без повторений» и «Двухфакторный дисперсионный анализ с повторениями» служат для выяснения на основе выборочных данных факта влияния контролируемого факторов А и В на результативный признак Y. При этом в режиме «Двухфакторный дисперсионный анализ без повторений» каждому уровню А и В соответствует только одна выборка данных, а в режиме «Двухфакторный дисперсионный анализ с повторениями» каждому уровню одного из факторов А (или В) соответствует более одной выборки данных. В последнем случае число выборок для каждого уровня должно быть одинаковым.
Режимы «Двухфакторный дисперсионный анализ без повторений» и «Двухфакторный дисперсионный анализ с повторениями» служат для выяснения на основе выборочных данных факта влияния контролируемого факторов А и В на результативный признак Y. При этом в режиме «Двухфакторный дисперсионный анализ без повторений» каждому уровню А и В соответствует только одна выборка данных, а в режиме «Двухфакторный дисперсионный анализ с повторениями» каждому уровню одного из факторов А (или В) соответствует более одной выборки данных. В последнем случае число выборок для каждого уровня должно быть одинаковым.
 пример использования режима «Двухфакторный дисперсионный анализ без повторений» . Известны данные о разрывной нагрузке пряжи на разных станках и из разного сырья. Требуется при уровне значимости =0, 05 выяснить, влияют ли на качество пряжи, измеряемое величиной разрывной нагрузки, тип станка и вид сырья.
пример использования режима «Двухфакторный дисперсионный анализ без повторений» . Известны данные о разрывной нагрузке пряжи на разных станках и из разного сырья. Требуется при уровне значимости =0, 05 выяснить, влияют ли на качество пряжи, измеряемое величиной разрывной нагрузки, тип станка и вид сырья.
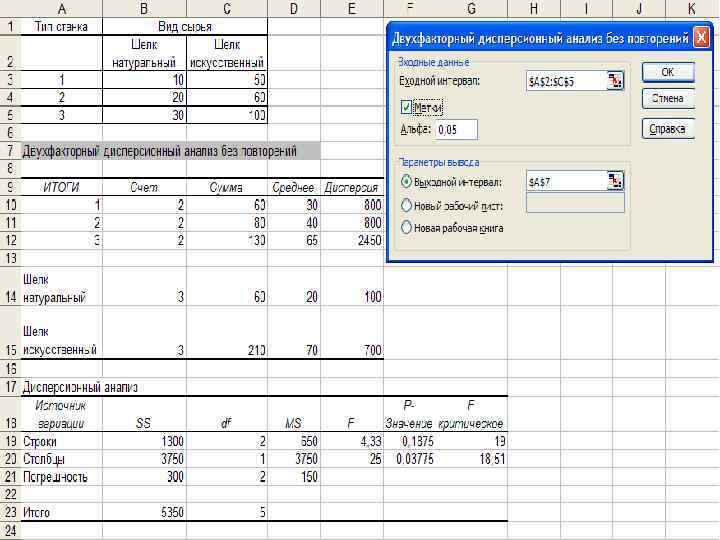
 равное 4, 33 не попадает в правосторонний") Расчетное значение F-критерия фактора А (тип станка) равное 4, 33 не попадает в правосторонний интервал (19, + ), следовательно считаем, что влияние станков на качество пряжи не подтвердилось. А расчетное значение F-критерия фактора В, равное 25 попадает в критическую область (18, 51; + ), следовательно вид сырья влияет на качество пряжи.
Расчетное значение F-критерия фактора А (тип станка) равное 4, 33 не попадает в правосторонний интервал (19, + ), следовательно считаем, что влияние станков на качество пряжи не подтвердилось. А расчетное значение F-критерия фактора В, равное 25 попадает в критическую область (18, 51; + ), следовательно вид сырья влияет на качество пряжи.
 приведен пример использования режима «Двухфакторный дисперсионный анализ с повторениями» . Известны данные об урожайности пшеницы, выращенной на участках, на которых вносились различные виды удобрений и которые подвергались различной химической обработке. Требуется при уровне значимости =0, 05 выяснить, влияют ли на урожайность пшеницы вид удобрения и способ химической почвы.
приведен пример использования режима «Двухфакторный дисперсионный анализ с повторениями» . Известны данные об урожайности пшеницы, выращенной на участках, на которых вносились различные виды удобрений и которые подвергались различной химической обработке. Требуется при уровне значимости =0, 05 выяснить, влияют ли на урожайность пшеницы вид удобрения и способ химической почвы.
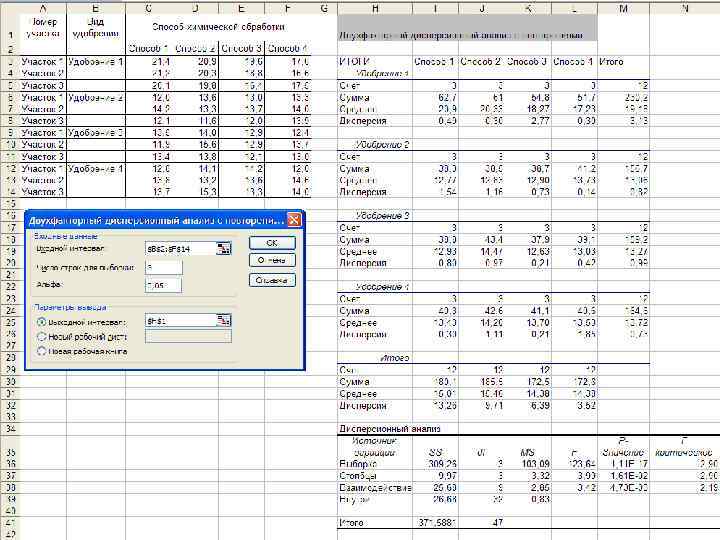
 равное 123, 64 попадает в") Так как расчетное значение F-критерия фактора А (вид удобрения) равное 123, 64 попадает в критическую область (2, 9; + ), то считаем, что вид удобрения влияет на урожайность. И расчетное значение F-критерия фактора В, равное 3, 99 попадает в критическую область (2, 9; + ), следовательно способ химической обработки так же влияет на урожайность пшеницы.
Так как расчетное значение F-критерия фактора А (вид удобрения) равное 123, 64 попадает в критическую область (2, 9; + ), то считаем, что вид удобрения влияет на урожайность. И расчетное значение F-критерия фактора В, равное 3, 99 попадает в критическую область (2, 9; + ), следовательно способ химической обработки так же влияет на урожайность пшеницы.