

e553ddddea26dffa7e20497194e23b1b.ppt
- Количество слайдов: 113
 Statistical Language Models for Information Retrieval
Statistical Language Models for Information Retrieval






 1 + +- - + + --- 0 + +- + ++ - - -- - + - -
1 + +- - + + --- 0 + +- + ++ - - -- - + - -



 Retrieval Engine Updated query Document collection top 10
Retrieval Engine Updated query Document collection top 10



 Noisy Channel Receiver (decoder) Destination") Source Transmitter (encoder) Noisy Channel Receiver (decoder) Destination
Source Transmitter (encoder) Noisy Channel Receiver (decoder) Destination

 Sampling
Sampling
 Estimation Total #words =100
Estimation Total #words =100








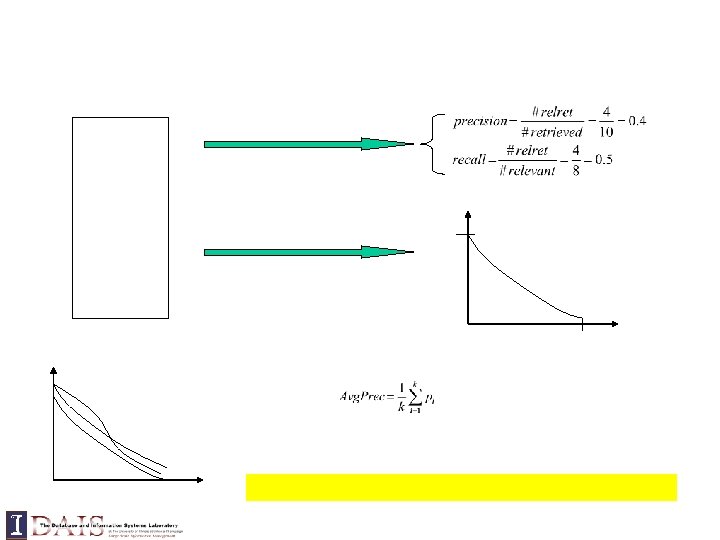
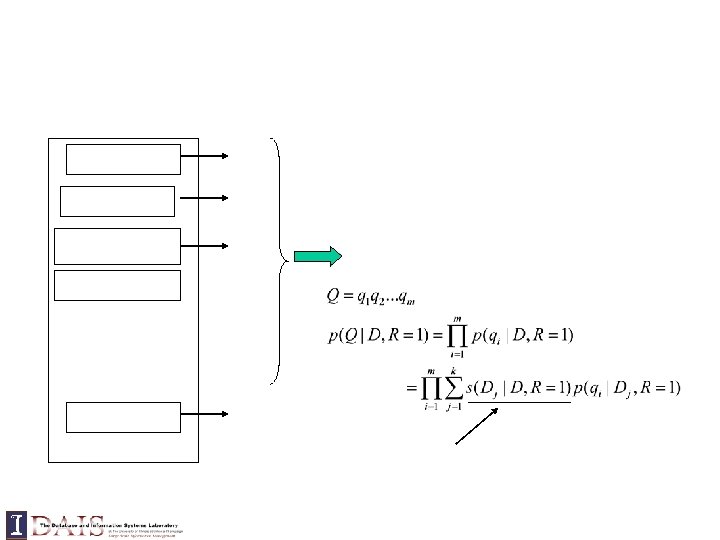
 Query = “data mining algorithms” Which model would most likely have generated this query?
Query = “data mining algorithms” Which model would most likely have generated this query?
 Doc LM Query likelihood
Doc LM Query likelihood



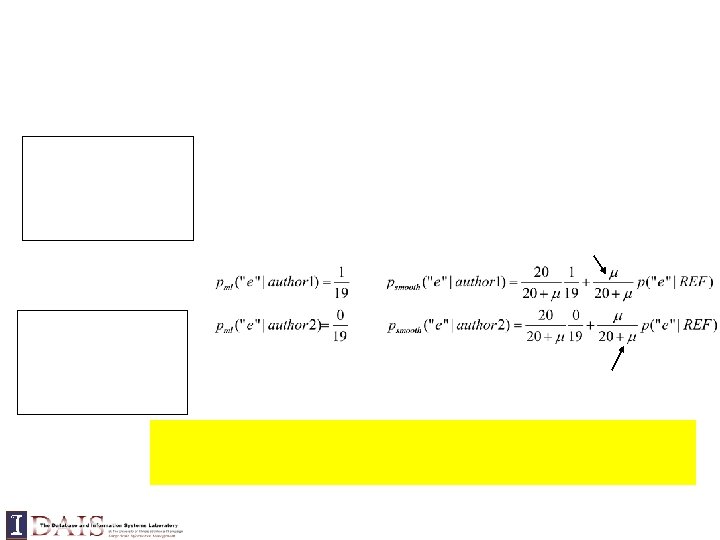
 Max. Likelihood Estimate Smoothed LM
Max. Likelihood Estimate Smoothed LM
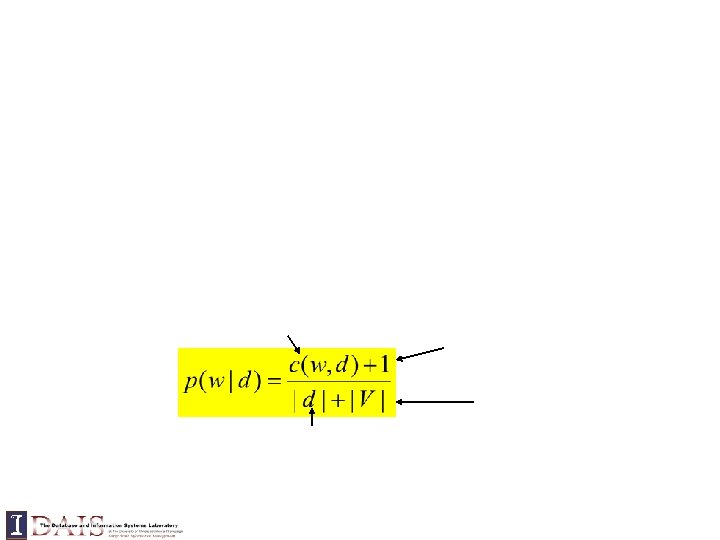





 TF weighting Words in both query and doc IDF-like weighting Ignore for ranking
TF weighting Words in both query and doc IDF-like weighting Ignore for ranking
 long Verbose queries long short Keyword queries
long Verbose queries long short Keyword queries
 = p(“algorithm”|d 2) p(") Query = “the algorithms for data mining” p( “algorithms”|d 1) = p(“algorithm”|d 2) p( “data”|d 1) < p(“data”|d 2) p( “mining”|d 1) < p(“mining”|d 2) Query = “the algorithms for data mining”
Query = “the algorithms for data mining” p( “algorithms”|d 1) = p(“algorithm”|d 2) p( “data”|d 1) < p(“data”|d 2) p( “mining”|d 1) < p(“mining”|d 2) Query = “the algorithms for data mining”
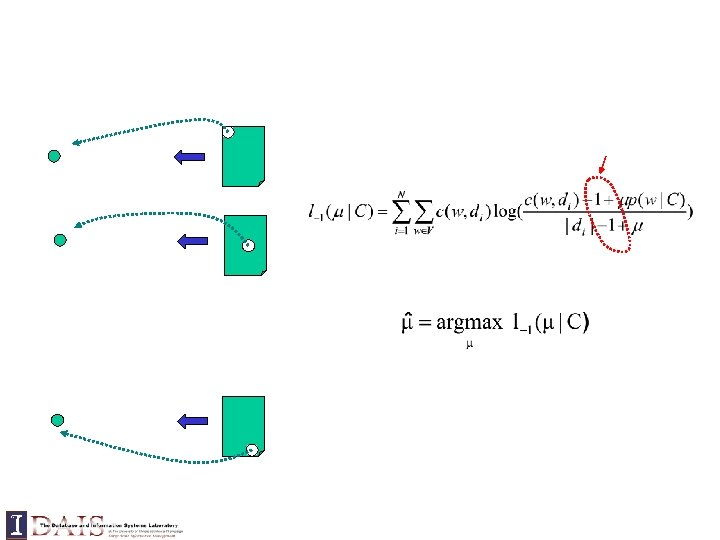
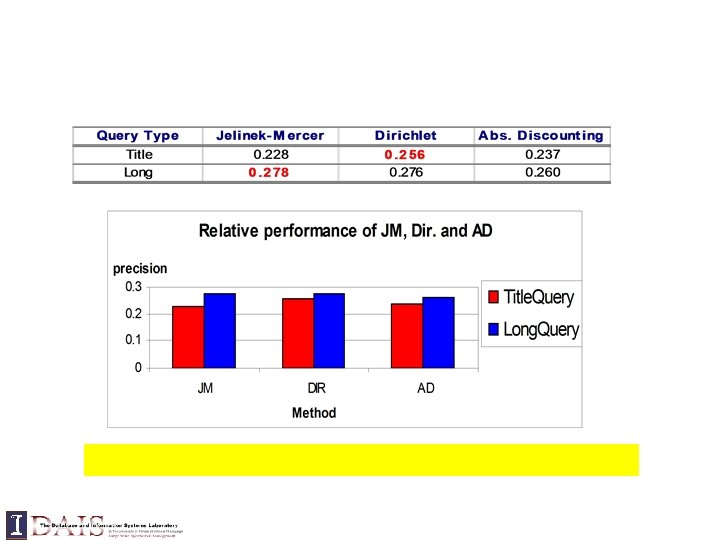
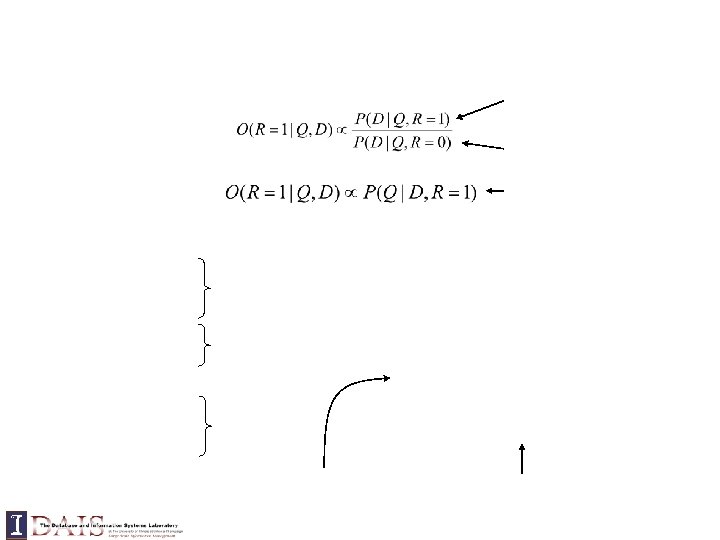
 Relevance
Relevance
 Ignored for ranking D
Ignored for ranking D
 Document prior
Document prior


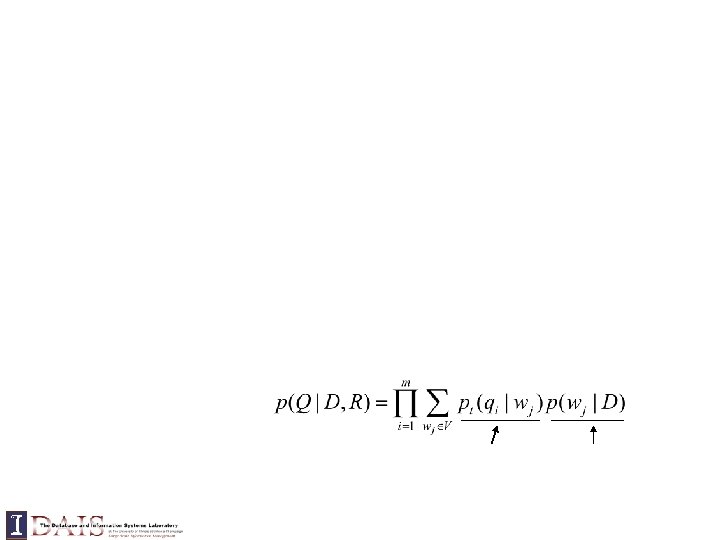




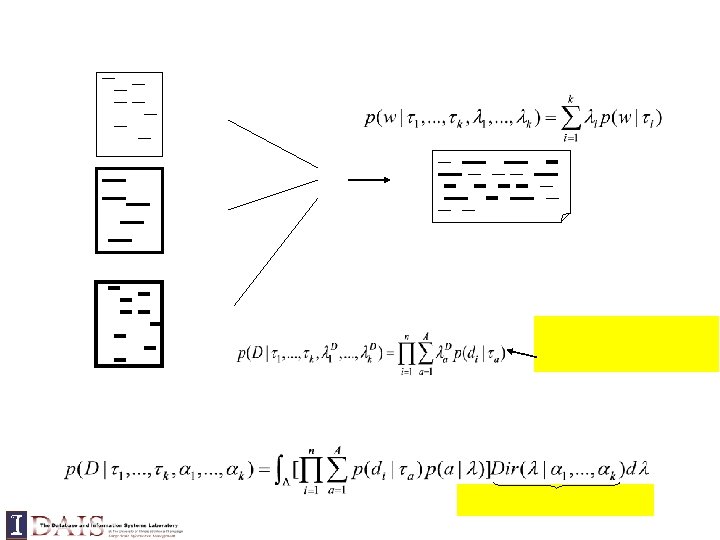
 An infinite mixture model Kernel-based density function
An infinite mixture model Kernel-based density function

 Document D Query Q
Document D Query Q
 Background words Topic words
Background words Topic words
 Empirical divergence Divergence minimization
Empirical divergence Divergence minimization
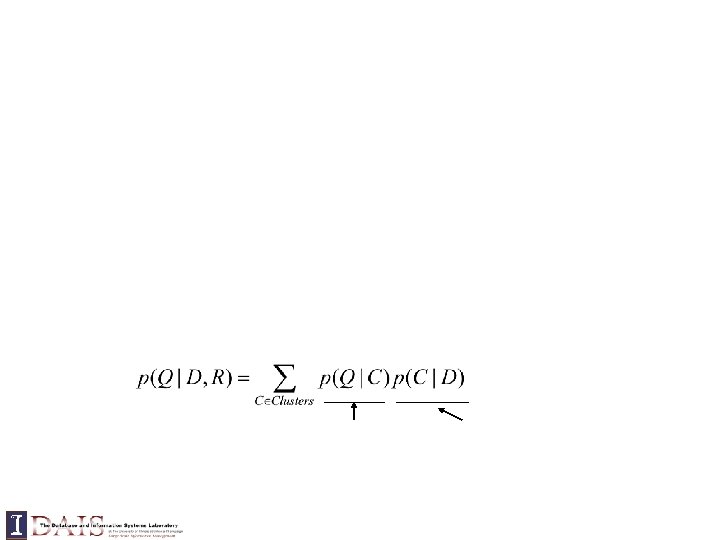
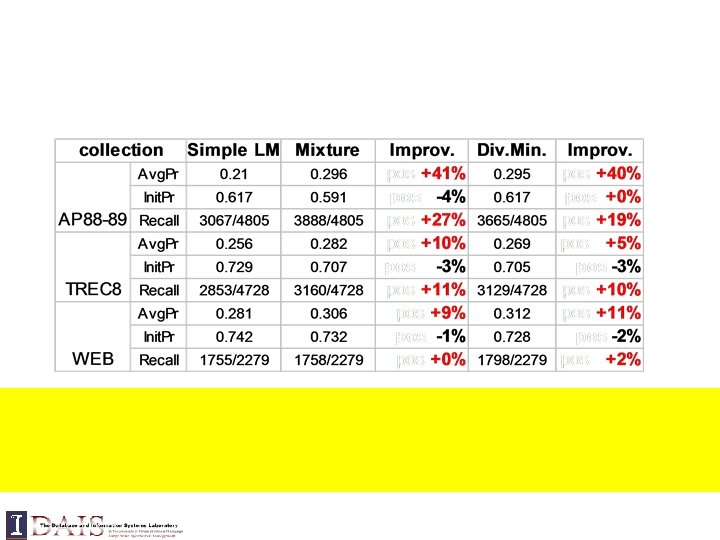
 Trec topic 412: “airport security” Mixture model approach Web database Top 10 docs
Trec topic 412: “airport security” Mixture model approach Web database Top 10 docs
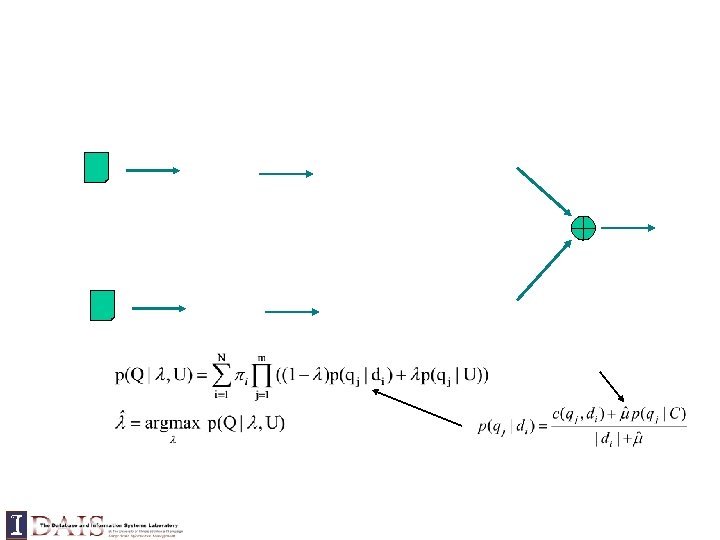
 Estimate with a bilingual lexicon Or Parallel corpora
Estimate with a bilingual lexicon Or Parallel corpora



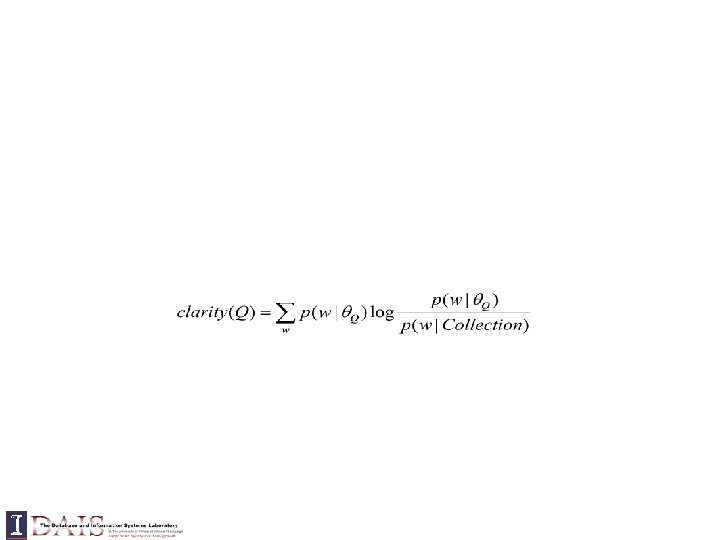
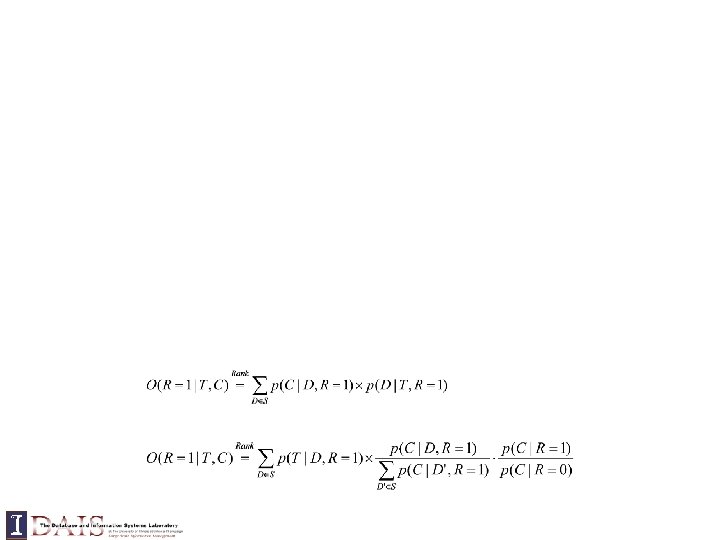




 QUERY MODELING Query Language Model Query USER MODELING Retrieval Decision: Documents Document Language Models DOC MODELING Loss Function
QUERY MODELING Query Language Model Query USER MODELING Retrieval Decision: Documents Document Language Models DOC MODELING Loss Function
 Us er Sourc e Query Document
Us er Sourc e Query Document

 Boolean model Probabilistic relevance model Generative Relevance Theory Vector-space Model Two-stage LM KL-divergence model Subtopic retrieval model
Boolean model Probabilistic relevance model Generative Relevance Theory Vector-space Model Two-stage LM KL-divergence model Subtopic retrieval model


 Estimate Query Estimate Documents Query model parameters Query Language Model User model parameters Document Language Models Loss Function Set
Estimate Query Estimate Documents Query model parameters Query Language Model User model parameters Document Language Models Loss Function Set




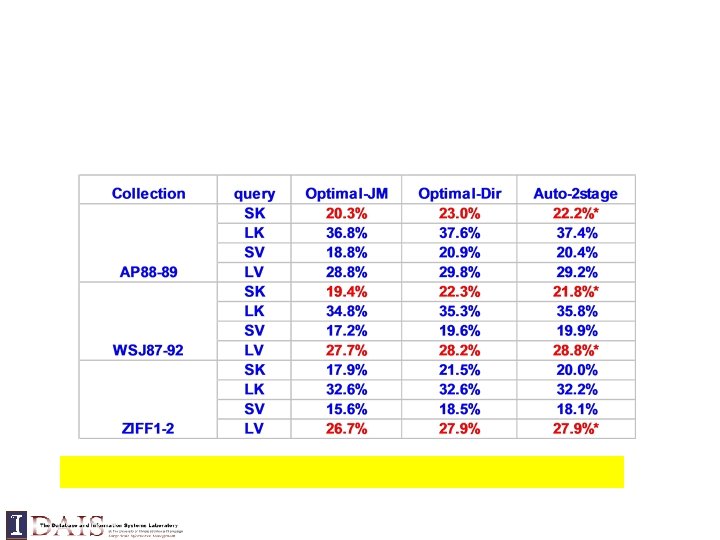
 outperform traditional methods without sacrificing efficiency? Can we do much") Can LMs consistently (convincingly) outperform traditional methods without sacrificing efficiency? Can we do much better by going beyond unigram LMs?
Can LMs consistently (convincingly) outperform traditional methods without sacrificing efficiency? Can we do much better by going beyond unigram LMs?
 How can we learn effectively from past relevance judgments? How can we break the document unit in a principled way?
How can we learn effectively from past relevance judgments? How can we break the document unit in a principled way?
 How can we exploit user information and search context to improve search? What role can LMs play when combining text with relational data?
How can we exploit user information and search context to improve search? What role can LMs play when combining text with relational data?
 How can we develop an effective unified retrieval model for Web search? How can we exploit LMs to develop models for complex retrieval tasks?
How can we develop an effective unified retrieval model for Web search? How can we exploit LMs to develop models for complex retrieval tasks?







