24698a134bceb406362ea7069073f8af.ppt
- Количество слайдов: 37



Современные тенденции визуализации коллекций научных публикаций Апанович З. В. ИСИ СО РАН Новосибирск

• Визуализация документов - это класс методов визуализации информации, преобразующих текстовую информацию в визуальную форму, позволяя уменьшать нагрузку на пользователей при работе с большими коллекциями текстовых документов. • Если ранние методы визуализации документов концентрировались больше на визуализации метаданных, таких как сети цитирования, сети ко-цитирования и сети соавторства, то в последнее время появляется все больше публикаций, совместно анализирующих и визуализирующих текстовые данные и метаданные.

Наши визуализации разных свойств текстовых коллекций 3

Визуальный обзор публикаций по визуализации текстов http: //textvis. lnu. se/
 Данные Визуализация")
Таксономия, на которой основан сайт Аналитические задачи Задачи визуализации Область (типы текстов) Данные Визуализация

Document. Cards 2008

Survis – программа для подготовки визуальных обзоров

Свойства визуальных обзоров Достоинства: если человек хочет разобраться в предмете, у него есть список литературы, с которым можно поработать Недостатки: • не всегда доступен текст статьи, • рисунок трудно интерпретировать, не прочитав статью • таксономия не дает представления об алгоритмах анализа и визуализации, • не избавляет от необходимости чтения всех этих статей. • Нужно разбираться как методы анализа связаны с алгоритмами визуализации!!! • Создаются вручную – размер коллекции 100 -300 публикаций • Для больших коллекций используются другие методы.

Векторная модель коллекции документов • Документ – это вектор, состоящий из частот слов, в нем встречающихся (Матрица терм-документ) • T – множество термов, всего термов – |T| = N • d = (w 1, w 2 , . . . , w. N) – векторное представление текста. • Wij = 0 если ti dj, иначе wij > 0
 tfidf (term frequency-inverse document frequency) Где |D| – общее")
tf-idf (term frequency-inverse document frequency) tfidf (term frequency-inverse document frequency) Где |D| – общее количество документов, nt – количество документов, содержащих терм t Существуют и другие способы оценки важности терминов В качестве меры близости между двумя документами чаще всего используют косинусную близость:

Понижение размерности векторного пространства документов Для снижения размерности матрицы терм-документ была предложена группа методов под общим названием Вероятностное моделирование тем Probabilistic Latent Semantc Indexing (p. LSI, p. LSA) Hoffman, 1999 Latent Dirichlet Allocation (LDA) Blei et al 2003 Nonnegative matrix factorisation (NMF) Lee&Seung, 1999 Также позволяют изучать: Изменение коллекции во времени Иерархическая организация коллекции (BRT, NMF) и др
 Mark Steyvers , Tom Griffiths Probabilistic Topic Models,")
Вероятностное моделирование тем (p. LSi, LDA) Mark Steyvers , Tom Griffiths Probabilistic Topic Models, 2012

Пример четырех тем

Стандартный NMF • Дан набор документов, представленный матрицей X R+m × n, который содержит N документов, состоящих из m слов. • Для заданного количества тем, k << min (m, n), NMF вычисляет низкоуровневое приближение матрицы X: • где W R+m × k Матрица W представляет собой набор из k тем, состоящих из ключевых слов • H R+k × n. Матрица H представляет собой набор из n документов, взвешенная комбинация k тем.

Задачи и тенденции систем визуализации научных коллекций • При визуализации коллекций документов принято выделять следующие подзадачи: • визуализация основного контента коллекции документов, • визуализация тем коллекции документов, • визуализация отношений между документами, в частности визуализации сходства документов и кластеризация документов на основе различных оценок сходства, • визуализация эволюции коллекции документов во времени. • Как правило, эти задачи взаимосвязаны, и тесно соседствуют в одной и той же программе визуализации.

Навигатор на основе LDA, представляющий ранжированные списки тем и документов Chaney, A. J. -B. and Blei, D. M. (2012). Visualizing topic models. In ICWSM

Глобальные отношения между темами и документами Ashwinkumar Ganesan, Kiante Brantley. Shimei Pan. Jian Chen LDAExplore: Visualizing Topic Models Generated Using Latent Dirichlet Allocation. 2017
, визуализация: stacked graph (Tiara, 2012) 1. 2. 3. 4.")
Эволюция тем во времени (LDA), визуализация: stacked graph (Tiara, 2012) 1. 2. 3. 4. 5. Подзадачи: Вычисление геометрии слоев Подбор цветов для отражения разницы между темами Упорядочение слоев Расстановка меток в слоях

Иерархические и динамические изображения тематических моделей визуализация: sankey diagram Темы не только меняют размеры, но могут возникать и исчезать, сливаться и разделяться. Также на каждом временном интервале иерархия тем представлена деревом небольшой глубины
")
Интерактивное иерархическое исследование коллекции документов (Topic. Lens, 2017)

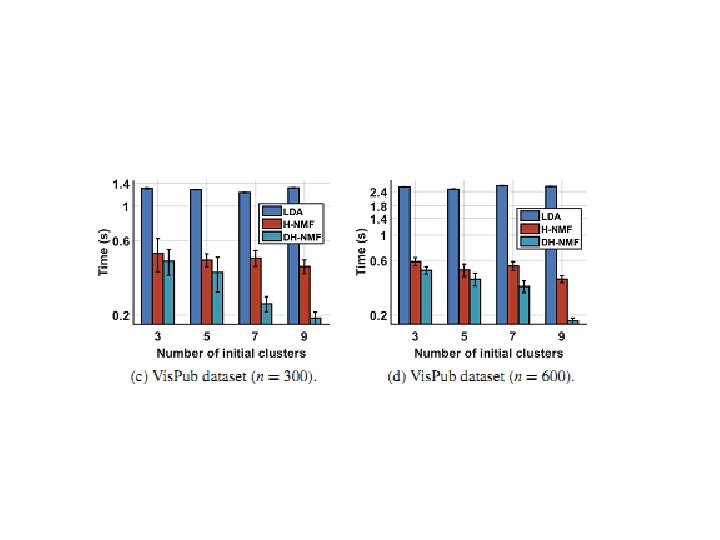
Иерархический NMF • H-NMF выполняет иерархическую кластеризацию данного документа путем построения H-NMF приближение низкого ранга с • K = 2. • Если надо получить k тем, такой рекурсивный процесс расщепления H-NMF продолжается до тех пор, пока общее число листовых узлов в двоичном дереве тем не станет равным k. Используя специальные алгоритмические характеристики NMF с • K = 2, H-NMF работает значительно быстрее, чем стандартный NMF при генерации того же числа тем.

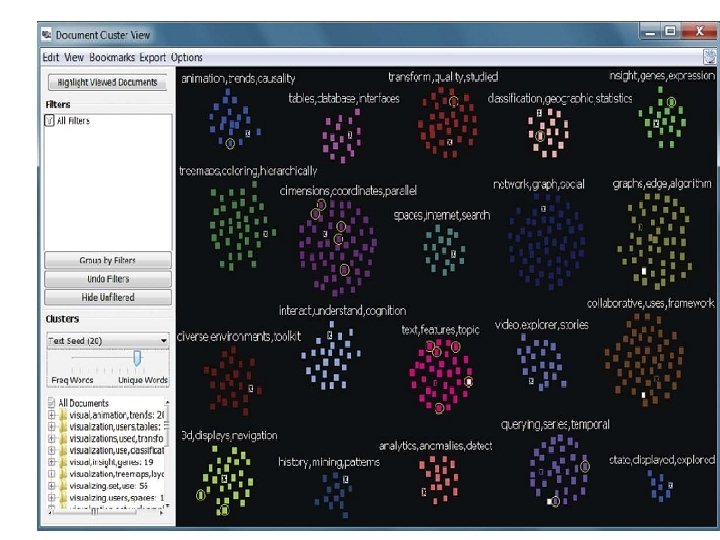
Topic Lens Начальное разбиение на кластеры
")
Topic Lens анализ области (2)
")
Topic Modeling of Document Metadata for Visualizing Collaborations over Time (2016)

Cite. Rivers 2017
 • Каковы основные темы исследовательских областей разных конференций? • Как")
Jigsaw, 2014 (взаимосвязанные изображения) • Каковы основные темы исследовательских областей разных конференций? • Как эти темы меняются со временем? • Кто является заметным исследователем? • Какие исследователи специализируются в каких областях? • Как найти специфические статьи, имеющие отношение к моей текущей области интересов ?
 Представление списков сущностей и их взаимосвязей. В центральном столбце выбран один")
Jigsaw (List View) Представление списков сущностей и их взаимосвязей. В центральном столбце выбран один автор, а в соседних столбцах высвечены сущности, связанные с этим автором. Слева – годы публикаций, справа, тематика (термины) его работ, Размер прямоугольника показывает значимость каждого элемента
")
Jigsaw (Document View)

• Наконец, еще одна модель представления текста, порождающая векторные пространства относительно небольшой размерности, стала чрезвычайно популярной в последние годы. • Программный инструмент word 2 vec основан на дистрибутивной семантике и векторном представлении СЛОВ. • Векторное представление слов основывается на контекстной близости: слова, встречающиеся в тексте рядом с одинаковыми словами (и, значит, имеющие схожий смысл), в векторном представлении будут иметь близкие координаты.

Дистрибутивная семантика • Векторная модель – матрицы вида терм-контекст. • Счетные модели размерность матрицы |V|*|V| • Предсказательные модели word 2 vec (CBOW, skip-gram) CBOW skip-gram

Совместный анализ слов и документов Cite 2 vec

Cite 2 vec

Cite 2 vec

Cite 2 vec Для современного этапа визуализации коллекций научных документов характерны следующие тенденции:

Заключение • комплексный подход, основанный на нескольких алгоритмах анализа текстов документов и взаимосвязанных интерактивных визуализациях. • совместное использование методов анализа текста и метаданных для визуализации • тесная интеграция множественных представлений • интерактивный характер визуализации (визуализация изменяется в результате взаимодействия с пользователем). • При анализе больших коллекций научных публикаций хорошая визуализация может упростить жизнь пользователей, НО • Пока что объемы визуализируемых коллекций отстают от реально существующих коллекций!!!
24698a134bceb406362ea7069073f8af.ppt