Л10.1. Мат. стат. Конспект.ppt
- Количество слайдов: 36



Случайные величины. Обзор материала • 1. Закон и функция распределения СВ Закон распределения СВ- зависимость между СВ х и ее вероятностью р. Для непрерывной СВ – плотность распределения f(x) 2. Функция распределения СВ – вероятность того, что случайная величина x меньше величины Х. F(x) =p (x < X) Исследованы и широко применяются в статистических исследованиях : - нормальное распределение Гаусса - распределение Стьюдента - распределение Пирсона (хи – квадрат) - распределение Фишера и др.
 играет особую роль в")
• Нормальное распределение • • Нормальное распределение (распределение Гаусса) играет особую роль в теории вероятностей и ее приложениях. Это наиболее часто встречающийся закон распределения. Нормальному закону подчиняется, при соблюдении определенных условий, распределение суммы достаточно большого числа случайных величин, каждая из которых может иметь произвольное распределение. Нормальное распределение задается параметрами: математическим ожиданием m и среднеквадратическим отклонением • Плотность вероятности f(X): σ Функция вероятности F(x)

• • • Параметрами, определяющими нормальное распределение, являются m – математическое ожидание и среднеквадратическое отклонение σ. Изменение параметра m приводит к параллельному переносу графика плотности вероятности вдоль оси OX. Изменение параметра σ приводит к тому, что при уменьшении σ возрастает максимальное значение плотности вероятности и график становится уже, при возрастании σ график ниже и шире. При этом площадь фигуры, ограниченная графиком плотности вероятности и осью OX в силу требования выполнения условия нормировки, постоянна и равна 1. Интеграл от плотности вероятности нормального распределения не имеет точного представления через элементарные функции. Поэтому функция распределения выражается через функцию Лапласа Φ(x), значения которой можно найти из таблиц
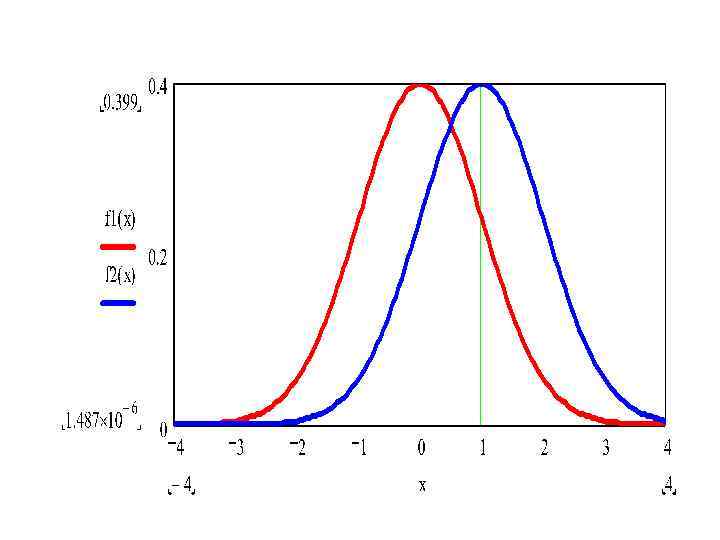
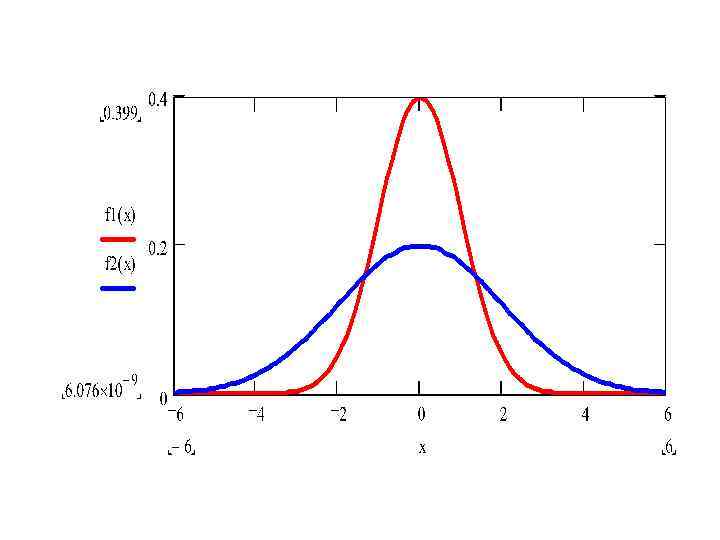

• Стандартное нормальное распределение • Как было сказано, нормальное распределение задается математическим ожиданием m, среднеквадратическим отклонением σ и дисперсией D = σ2. При нормировке • Плотность вероятности f(z) : • Математическое ожидание и дисперсия равны: Функция вероятности F(z)

Вероятность попадания случайной величины в заданный интервал: Применяя это соотношение и получают так называемое правило трех . Для этого найдем Таким образом, практически достоверно то, что нормально распределенная величина примет значение, отличающееся от ее математического ожидания по модулю не более чем на 3 , или практически невозможно появления значения, выходящего за пределы этого интервала. Последнее обстоятельство находит широкое применение в практических приложениях.

Элементы математической статистики • Математическая статистика – раздел математики, в котором изучаются методы сбора, систематизации, обработки и анализа результатов наблюдений массовых случайных явлений для выявления существующих закономерностей. • Первой задачей математической статистики является определение способов сбора и систематизации статистической информации. • Вторая задача математической статистики состоит в разработке методов обработки и анализа статистических данных

Этапы моделирования эмпирических данных вероятностными моделями 1. 2. 3. 4. 5. Предварительная обработка данных: группировка, анализ засоренности и независимости данных, Расчет выборочных характеристик (параметров выборки) Точечное и интервальное оценивание параметров выборки Описание данных вероятностными моделями Точечное и интервальное оценивание параметров модели Проверка гипотез о согласии модели и экспериментальных (эмпирических) данных

Основные понятия При изучении некоторого явления проводится исследование некоторой совокупности однородных объектов. Для этого измеряются качественные или количественные признаки, характеризующего эти объекты. Все изучаемые объекты формируют генеральную совокупность (ГС)данных. Объем генеральной совокупности обозначают N. ГС ассоциируется со случайной величиной, с Процессом, исследуемым явлением. Генеральная совокупность обычно содержит слишком много данных и поэтому сплошное обследование невозможно или связано с уничтожением объекта. Если сплошное обследование невозможно, то применяют выборочное обследование, выборочный метод обследования. В этом случае из Генеральной совокупности выбирают ограниченное число объектов и их подвергают изучению. Выборка – ограниченный набор данных из генеральной совокупности. Объем выборки обозначают n Задачей исследования явления (генеральной совокупности) заключается в анализе того, насколько результаты выборочного обследования будут справедливы для всей генеральной совокупности.

• Для того чтобы по данным выборки можно было достаточно уверенно судить об интересующем нас признаке генеральной совокупности, необходимо, чтобы объекты выборки правильно его представляли. • Это требование звучит так: выборка должна быть репрезентативной (представительной). Для этого каждый из её объектов должен быть отобран из генеральной совокупности случайным образом, то есть все объекты генеральной совокупности должны иметь одинаковую вероятность попасть в выборку. • Существуют специальные приёмы отбора, обеспечивающие репрезентативность выборки, и мы будем, в дальнейшем предполагать, что это требование выполнено.

Пусть из генеральной совокупности извлечена выборка объёма n, причём количественный признак величины х1, наблюдался n 1, раз, … , xk - nk раз. Наблюдаемые значения количественного признака хi, называются вариантами, Последовательность вариант, записанных в порядке возрастания называется дискретным вариационным рядом. Число наблюдений значения признака хi, , , величина ni, называется частотой vi, - отношение ni, к объёму выборки n называется относительной частотой. Справедливы соотношения Соответствие между вариантами хi , записанными в порядке возрастания, и относительными частотами называется статистическим или эмпирическим распределением выборки.

• • Вариационный ряд может содержать большое количество данных наблюдения, т. е. объем выборки n достаточно велик. В этом случае вариационный ряд разбивается на интервалы, т. е. происходит группировка данных. Число интервалов m рассчитывается по определенным формулам (формула Стерджеса). • Данные, разбитые на интервалы, образуют интервальный вариационный ряд. Здесь ni - частота попадания в i– тый интервал, vi, - отношение ni, к объёму выборки n - относительная частота. • Справедливы соотношения

Графическое изображение вариационных рядов • Чаще всего используются: § Точечная диаграмма – для изображения данных дискретных вариационных рядов § Полигон § Гистограмма – для интервальных вариационных рядов § Кумулятивная кривая (кумулята). Представляет собой эмпирическую функцию распределения

Графическое представление экспериментальных данных. Полигон Рис. 3. Полигон

Кумулятивная кривая Рис 4. Кумулятивная кривая

• Существует аналогия между статистическим распределением выборки и законом распределения дискретной случайной величины. • В данном случае вместо возможных значений случайной величины фигурируют варианты, а вместо соответствующих вероятностей - относительные частоты. • В силу этой аналогии по известному эмпирическому распределению можно по тем же формулам, что и для дискретного распределения, найти выборочные аналоги математического ожидания и дисперсии. • Для оценки числовых параметров выборки и , в дальнейшем, генеральной совокупности, в математической статистике используют следующие числовые характеристики – меры процесса: • 1. меры положения – средние значения, медиана, мода; • 2. меры разброса – размах, выборочная дисперсия, выборочное среднеквадратическое отклонение; • 3. меры формы – коэффициент асимметрии, эксцесс

Меры положения: средние Арифметической средней – Xср называют среднее арифметическое значение признака совокупности Xср= Например для ряда xi 1 3 6 16 ni 4 10 5 1 Xср=(1*4+3*10+6*5+16*1)/(4+10+5+1)=4

i. Мера положения - сглаженная средняя - средняя средних • Xсрср=

Меры положения: медиана, мода Модой М 0 называют варианту, которая имеет наибольшую частоту. Например, для ряда Варианта Xi. . 1 4 7 9 Частота ni. . 5 1 20 6 – мода равна 7. Медианой me называют варианту, которая делит вариационный ряд на две части, равные по числу вариант. Если число вариант нечётно, т. е. n = 2 k + 1, то me = Xk+1 при чётном n = 2 k медиана me = (Xk + Xk+1)/2 Например, для ряда Xi = 2 3 5 6 7 медиана me равна 5 Для ряда Xi = 2 3 5 6 7 9 медиана me равна (5+6)/2 = 5, 5.

Меры разброса: размах, дисперсия, Размахом варьирования R – называют разность между наибольшей и наименьшей вариантами: R = xmax - xmin Дисперсией (рассеянием) дискретной случайной величины называют математическое ожидание квадрата отклонения случайной величины от математического ожидания: D(X) = M[(X – M(X))2]

Выборочная дисперсия

Мера разброса: стандартное отклонение, Стандартным отклонением в теории вероятностей называют квадратный корень из дисперсии σ = √D Выборочным стандартным отклонением в математической статистике называют S = √S 2
 - число вариант, меньших х, Зависимость относительной частоты события <х")
• Пусть n(х) - число вариант, меньших х, Зависимость относительной частоты события <х , равной • называют эмпирической функцией распределения и обозначают • В отличие от эмпирической функции распределения • функцию распределения генеральной совокупности F(x) • называют теоретической функцией распределения. • F(x) определяет вероятность события <х, а его относительную частоту. • Эмпирическая функция распределения и ее числовые характеристики для различных выборок будут отличаться друг от друга. • Задача заключается в том, чтобы по полученному экспериментальному материалу сделать выводы о виде и значениях числовых параметров теоретического распределения.

Точечные и интервальные оценки параметров распределения • • Полученные выборочные параметры будут меняться от выборки к выборке. Задача исследования заключается в том, чтобы по полученным по экспериментальным данным выборочным параметрам оценить параметры процесса, т. е. параметры генеральной совокупности. Так, например, если известно, что интересующая нас величина распределена нормально, то оценке подлежат математическое ожидание и среднеквадратическое отклонение (или дисперсия) генеральной совокупности. Задача оценивания параметров теоретического распределения состоит в построении формул, зависящих от выборочных значений x 1 …xn. • Любую функцию • поэтому являющуюся случайной величиной, называют статистикой. , зависящую от выборки и

• Для того, чтобы статистики - оценки неизвестных параметров, давали хорошее приближение неизвестных параметров распределения генеральной совокупности, они должны быть: несмещенными, состоятельными, эффективными и достаточными. 1. Математическое ожидание оценки параметра по всевозможным выборкам данного объёма должно равняться истинному значению определяемого параметра. В этом случае оценку называют несмещенной. • 2. При увеличении объёма выборки оценка должна сходиться по вероятности к истинному значению параметра. В этом случае оценку называют состоятельной. • 3. Несмещенная оценка, имеющая наименьшую дисперсию среди других несмещенных оценок называют эффективной. • 4. Оценка, которая наиболее полно использует данные выборки называется достаточной. В теории оценивания различают точечные и интервальные оценки. Известно много способов получения оценок. Широко применяется метод моментов, которого заключается в приравнивании теоретических характеристик соответствующим эмпирическим характеристикам.

• Точечные оценки параметров нормального распределения • Нормальное распределение определяется двумя параметрами –m и . • Приравнивая теоретические математическое ожидание М( )=m и дисперсию D( )= 2 к соответствующим эмпирическим величинам получим искомые оценки: • Эмпирическое математическое ожидание (среднее) • Эмпирическая дисперсия • Эмпирическое среднеквадратическое отклонение

• Оценка является состоятельной и несмещенной. • Оценки и • • • Исправленные оценки соответственно равны Исправленная дисперсия состоятельные, но смещенные. • Исправленное среднеквадратическое отклонение

• Интервальные оценки • • Точечные оценки параметров распределения являются случайными величинами и могут отличаться от оцениваемых параметров, то возникает необходимость в оценке их точности и надёжности. Необходимо оценить, к каким ошибкам может привести замена неизвестного параметра его точечной оценкой, и с какой уверенностью можно ожидать, что ошибки не выйдут за известные пределы. С этой целью вводятся интервальные оценки. По данным выборки указывается интервал, который с заданной и достаточно близкой к 1 вероятностью (её называют доверительной вероятностью или надёжностью оценки) накрывает неизвестный параметр. Идея, лежащая в основе построения доверительных интервалов, заключается в следующем: - вводится определенная случайная величина, являющаяся функцией выборки и определяемого параметра (статистика), распределение которой заранее известно. - для этой случайной величины строится интервал, в который она попадает с заданной вероятностью . Затем, на основе полученного интервала, строится доверительный интервал для искомого параметра.

• Пример. Для проверки фасовочной установки было отобраны и взвешены 20 упаковок. Были получены следующие результаты (в граммах): 246 • 247. 3 247. 4 251. 7 252. 5 252. 6 2528 252. 9 253 • 247 253. 6 254. 7 254. 8 256. 1 256. 3 256. 8 257. 4 259. 2 Найти точечные оценки математического ожидания, выборочной дисперсии и выборочного среднеквадратического отклонения. Решение. Сначала найдем точечные оценки m и :

• Для построения доверительного интервала для математического ожидания m применяют распределение Стьюдента. Определяем по таблице распределения Стьюдента для доверительной вероятности =0, 95 и числу степеней свободы (n-1)=19 соответствующее значение t =2. 093, и по формуле • находим искомый интервал: • Для построения доверительного интервала для с надёжностью =0. 9 находим по таблице распределения 2 с (n-1)=19 степенями свободы числа h 1, и h 2, из условий: • • В результате получим h 1, =10. 117 и h 2, =30. 144. Отсюда искомый доверительный интервал, накрывающий с надёжностью , равен (2. 9 5. 0). •

10. 3. Сглаживание экспериментальных зависимостей методом наименьших квадратов • • Пусть экспериментально исследуется зависимость двух физических величин (у от х). Предположим, что величины у и х связаны функциональной зависимостью у= (х). вид которой требуется определить из опыта. Предположим, что зависимость у= (х) известна и в результате опыта получен ряд экспериментальных точек (xi, yj). Обычно эти точки не ложатся точно на график функции у= (х). Всегда имеется некоторый разброс, то есть обнаруживаются случайные отклонения от этой функциональной зависимости. Эти отклонения связаны с неизбежными при любом опыте ошибками. Требуется, не зная зависимости у= (х), наилучшим образом воспроизвести эту зависимость по полученным экспериментальным данным. Вид этой зависимости будет меняться от одной серии измерений к другой. Возникает типичная для практики задача сглаживания экспериментальных зависимостей. Задача сглаживания - требуется найти такую функцию у= (х), чтобы она некоторым наилучшим образом отражала функциональную зависимость у от х, и вместе с тем были бы сглажены случайные, незакономерные отклонения измерений, связанные с неизбежными погрешностями самих измерений.

• Между значениями yi , полученными теоретически и экспериментально существует разность, которая может быть как положительной, так и отрицательной. Чтобы минимизировать разность этих отклонений (невязок), используют метод наименьших квадратов • Задача сводится к решению системы двух уравнений, которая при линейной теоретической функции сводится к системе •

• Пример. Проведена серия опытов по определению влияния дозы внесённых удобрений на повышение урожайности пшеницы. • Соответствующие данные приведены в первых трёх столбцах таблицы (х - внесённая доза удобрений в центнерах на гектар, у - прирост урожайности в центнерах с гектара). • Требуется по методу наименьших квадратов подобрать линейную функцию, выражающую у через х. • Решение. Искомые величины связаны линейной зависимостью: у=ах+Ь, коэффициенты а и b которой и требуется определить. • Сумма квадратов невязок равна: • Система нормальных уравнений

i xi yi xi 2 yi 2 xiyi 1 0, 342 2, 10 0, 1170 4, 41 0, 718 2 0, 417 4, 70 0, 1739 22, 09 1, 960 3 0, 675 6, 05 0, 4556 36, 60 4, 084 4 0, 867 8, 65 0, 7517 74, 82 7, 500 5 1, 000 10, 00 1, 0000 100, 00 10, 000 6 1, 158 12, 60 1, 3410 158, 76 14, 591 7 1, 283 12, 08 1, 6461 145, 93 15, 499 8 1, 500 14, 68 2, 2500 215, 50 22, 020 9 1, 733 16, 65 3, 0033 277, 22 28, 854 10 2, 008 19, 25 4, 0321 370, 56 38, 654 11 2, 083 19, 98 4, 3389 399, 20 41, 618 12 2, 242 23, 20 5, 0266 538, 24 52, 014 13 2, 508 23, 93 6, 2901 572, 64 60, 016 1, 370 13, 37 224, 31 22, 887 2, 3405

• Раскрывая скобки и группируя, в результате получим следующую систему двух линейных уравнений для определения коэффициентов а и Ь: • Решая эту систему, получим: а=9. 86; Ь=-0. 14 y=9. 89 x-0. 14
Л10.1. Мат. стат. Конспект.ppt