b4020f083c6c4c115ac5c0e3a175eb69.ppt
- Количество слайдов: 28



Size matters: quality vs. quantity Traditionally, libraries spent a lot of effort on selection, choosing what to buy. They then spent a lot of effort organizing and indexing the material. The Internet is the other extreme: everything is available, nothing is organized. There are two fundamental changes: low-cost disks full-text indexing Selection is expensive, storage is cheap; organizing is expensive, searching is cheap.

Bush’s memex As visualized by Life Magazine in 1945.

Size matters: the Internet Archive The Internet Archive sweeps the Web roughly every two months and saves whatever pages it can find. It buys about 10 TB of disk each month, and now has about 100 TB total. There are two copies of the Archive (neither quite up to date): one at the Library of Congress and one at the Biblioteca Alexandrina. In addition to the general Web collection, the Archive has also gathered "curated" collections where specialists chose web sites, e. g. , the 2000 Election website for the Library of Congress.

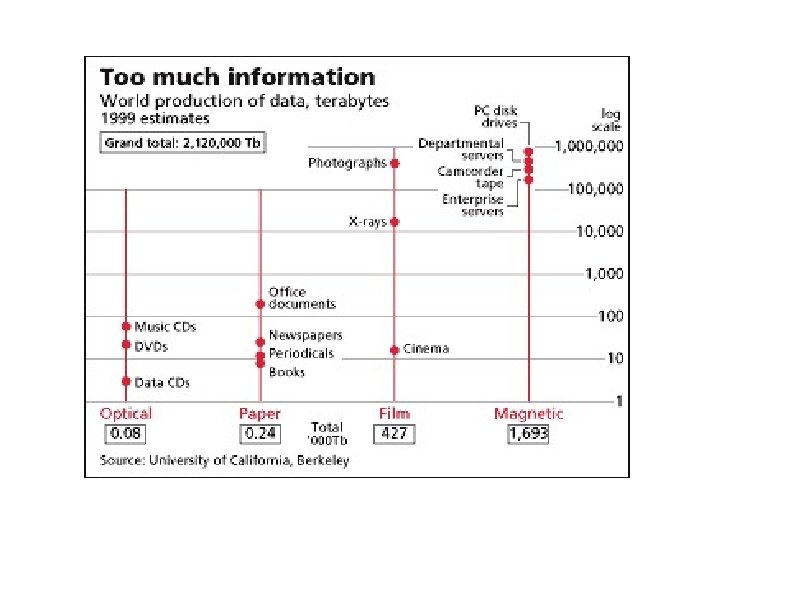
More than the Web: universal access to human knowledge It is now credible to imagine that all of our creative activity is placed on line. For example, perhaps 100 M books have been published; digital versions of these would fit in 1 "petabyte" (the step after the terabyte) and a petabyte of disk today is $1 M. The Internet Archive supports, for example: The Million Book Project (Profs. Raj Reddy & N. Balakrishnan) The Prelinger Archive and the Television Archive (moving images) The "etree. org" music files. Software collections, working with Macromedia. The Internet Bookmobile.

From John Mc. Callum

What to keep: lessons from history Once upon a time libraries didn't give full respect to: Vernacular literature (before the Renaissance) Plays, instead of poetry Non-European languages Films and television scripts and recordings Today the distinctions between libraries, archives and museums are eroding. Undergraduates are using primary materials online, which they would not have been able to use on paper; even in schools some of these are useful. As time goes on it is cheaper to collect but more expensive to select; it is cheaper to search and more expensive to organize.

Google vs. ACM DL Query: neural nets ACM: 554 hits Bounds for the computational power & learning complexity. . Neural networks & open texture Efficient simulation of finite automata. . Parallel construction of minimal perfect hashing. . . Google: 131, 000 hits Lecture notes from Msc course on neural nets Neural networks at PNNL Old neural net FAQ for comp. ai. neural-nets ACM dates 1991 -1993, Google 1995 -2001. On balance Google pages better as an introduction; ACM hits too specialized (ACM DL does not have monographs).

Google vs. ACM DL Query: rsa cryptography ACM: 12 hits Hardware speedups in long integer multiplication. Dynamically reconfigurable architecture for image proc. Representation of ASN. 1 in APL nested structures Architectural tradeoff in implementing RSA procs. Google: 117, 000 hits RSA Laboratories cryptography FAQ RSA Labs algorithm simulation center (Javascript) RSA Cryptography Today FAQ RSA cryptography spec 2. 0 Again, the ACM hits are very specialized; as an introduction the pages found by Google are better.

Google vs. Art Index Query: paleography Art Index: 72 hits Cuneiform: The Evolution of a Multimedia Cuneiform Database Une Priere de Vengane sur une Tablette de Plomb a Delos. More help from Syria: introducing Emar to biblical study The death of Niphururiya and its aftermath Google: 21, 100 hits Manuscripts, paleography, codicology, introductory bibliography Ductus: an online course in paleography BYZANTIUM: Byzantine Paleography Texts, manuscripts and paleography The same general results, that the “selected” material is too specialized, is also true in art, although the advantage for Google was smaller.

What about art history? I tried four questions in computer science and four questions in art history, Google against the ACM digital library and the Art Index. In general: Google has more general resources Google sometimes gets distracted It’s hard to find a query that the”official” sources do well and Google doesn’t do at all.

Large image libraries There are now some very large image collections: the National Museum of the American Indian has 800, 000 ARTSTOR will have about 250, 000 Commercial sites (e. g. Corbis) have millions of images. Computers are good at matching up images. They are not, today, good at image search: but with a large enough library, the problem will be recognition and not analysis.
")
Image matching (from Andrew Zisserman, Oxford)
")
(Jitendra Malik and David Forsythe, Berkeley)
")
Beauvais Cathedral (from Peter Allen & collaborators at Columbia)

Tom Funkhouser, Princeton

The Internet Bookmobile Van, satellite modem, computers, printer, binding machine; can make a copy of an out of print book for $1, van + equipment costs $15, 000.

The Million Book Project Created by Raj Reddy of Carnegie-Mellon University; also led by Prof. N. Balakrishnan of the Indian Institutes of Sciences. The US provides scanners, disks, and computers (about $4. 5 M is committed); India provides labor (1 -2 thousand staff-years). About 100 Minolta look-down scanners enable non-destructive black&white scanning of books at about one book per hour. With two shifts, for two years, this should scan 1 million books. Scanning is 600 dpi, bitonal, with OCR and some image cleanup. So far about 20, 000 books have been scanned in India; this is about 4 months of activity. Centers are running in Bangalore, Hyderabad, Pune, Chennai, Mumbai, Thirupati, and other places.

Scanning

International Children's Digital Library Curated collection of children's books; research on interfaces by Ben Bederson and Allison Druin; see www. icdlbooks. org, but only about 200 books so far.

Television Archive September 11 broadcasts from around the world; one week, news programs only. Also the Prelinger Archive; about 1, 000 films, typically industrial or government. Online availability caused an increase in commercial licensing.

Internet Archive issues Copyright. The Archive is generally "opt-out"; is this OK? Some US rights holders using DMCA to lean on Google & the Archive. Economics. The Archive does not charge and believes public domain material, in particular, should be free. Will this work in the long run? Technology. The more Web pages fill with Javascript and Flash, the harder it is to save them. The collection of Macromedia's CD-ROMS is particularly vulnerable here. Interfaces. The Archive, in general (ICDL is an exception) does collections but does not do much research on how to use them. Impact. How can we get the most from such resources?

Data lookup, not experiment In the future, many experiments won’t be necessary because the answers will already be online. Data acquisition is being automated and enormous quantities of information are online (petabytes). Molecular biology is first, replacing wet chemistry with lookups in the protein and genome data banks (eg to determine the function of a gene or protein) Astronomy is probably coming next Many earth-observing fields getting ready

National needs Assisting the intelligence agencies • photointerpretation • individual identification • database fusion • large scale data mining

Face spotting

Virtual Cities Above: modern Los Angeles; left, classical Rome. UCLA.

Human motion analysis Jezekiel Ben-Arie, U of Illinois Chicago

Future Issues Can we create dictionaries of interesting items? Can we infer 3 -D from 2 -D, and build 3 -D models? Can we merge speech, text, and databases? Can we summarize mixed-media material? Can we deal with multiple languages? Can we anticipate scientific and defense needs? Can we model earth-observing needs? Can we do this all in real-time?
b4020f083c6c4c115ac5c0e3a175eb69.ppt