

25b025f2faba8ac9a50b4ba76b949a5e.ppt
- Количество слайдов: 18
 Seeding search engines with data from the Australian National Bibliographic Database Tony Boston Assistant Director-General Resource Sharing National Library of Australia 18 September 2006
Seeding search engines with data from the Australian National Bibliographic Database Tony Boston Assistant Director-General Resource Sharing National Library of Australia 18 September 2006
 Outline • • • Why seed search engines? National Library Digital Collections Libraries Australia and the ANBD Results to date Future directions
Outline • • • Why seed search engines? National Library Digital Collections Libraries Australia and the ANBD Results to date Future directions
 Why seed search engines? To provide new discovery pathways for users of Australian libraries and increase exposure of the Libraries Australia Search service on the Internet
Why seed search engines? To provide new discovery pathways for users of Australian libraries and increase exposure of the Libraries Australia Search service on the Internet
 Why people use search engines • Self-service, satisfaction, seamlessness 1 • 89% of US college students start research process via Search Engines 1 • Principle of Least Effort 2 • Poor design of library systems, eg: complexity, lack of relevance ranking 3 12003 OCLC environmental scan: Pattern recognition. C. De Rosa, L. Dempsey and A. Wilson January 2004 2 Improving user access to library catalog and portal information: final report. M. J. Bates 2003 3 Rethinking How We provide Bibliographic Services for the University of California. Final report: December 2005 Bibliographic Services Task Force
Why people use search engines • Self-service, satisfaction, seamlessness 1 • 89% of US college students start research process via Search Engines 1 • Principle of Least Effort 2 • Poor design of library systems, eg: complexity, lack of relevance ranking 3 12003 OCLC environmental scan: Pattern recognition. C. De Rosa, L. Dempsey and A. Wilson January 2004 2 Improving user access to library catalog and portal information: final report. M. J. Bates 2003 3 Rethinking How We provide Bibliographic Services for the University of California. Final report: December 2005 Bibliographic Services Task Force
 National Library Digital Collections • ~ 100, 000 items from the Library’s collection digitised since 1996. • Pictures, maps, sheet music, manuscripts, some books and serials
National Library Digital Collections • ~ 100, 000 items from the Library’s collection digitised since 1996. • Pictures, maps, sheet music, manuscripts, some books and serials
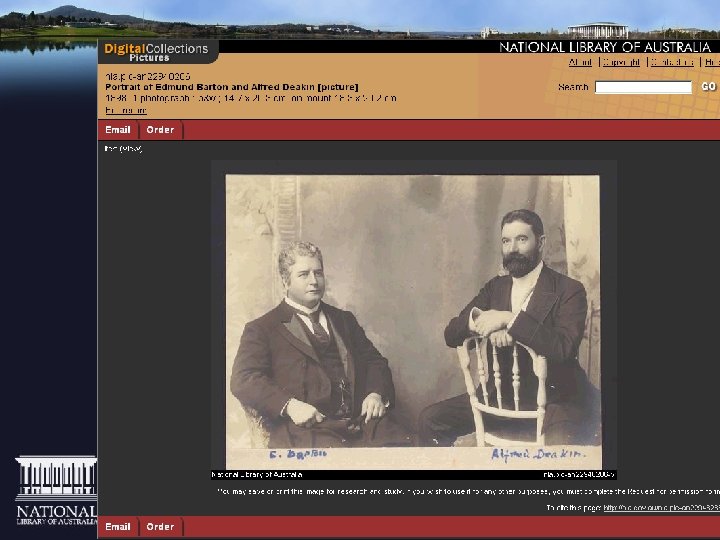
 More pathways, more users • Three major pathways to collection items: – Via the Library’s catalogue – Via federated discovery services, eg: Libraries Australia, Music. Australia, Picture. Australia – Via Internet search engines • URL lists for search engines to harvest • Persistent URLs resolve to a page to be indexed, eg: – http: //nla. gov. au/nla. pic-an 22948286
More pathways, more users • Three major pathways to collection items: – Via the Library’s catalogue – Via federated discovery services, eg: Libraries Australia, Music. Australia, Picture. Australia – Via Internet search engines • URL lists for search engines to harvest • Persistent URLs resolve to a page to be indexed, eg: – http: //nla. gov. au/nla. pic-an 22948286
 Search engine indexing and access paths
Search engine indexing and access paths
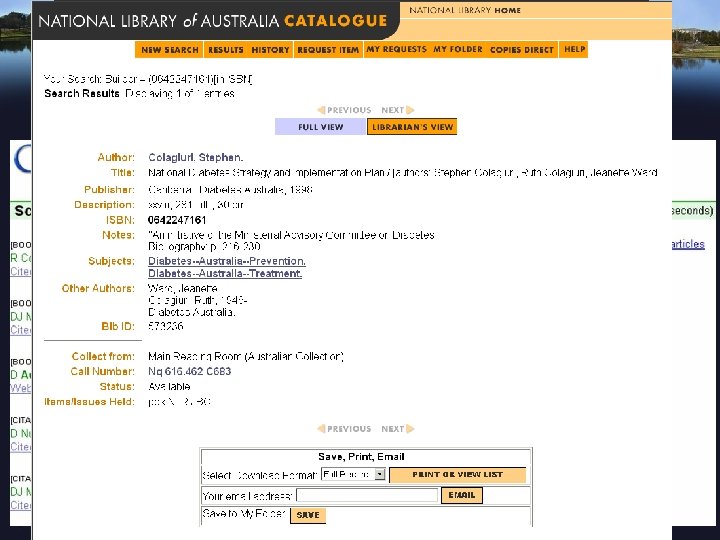
 Libraries Australia and the ANBD • Free Libraries Australia Search service – Launched by Senator Helen Coonan on 27 February 2006 – Freely available to anyone with Internet access – Easy to use, ‘google like’ search • Records exported to Search Engines – March 2006: 700, 000 records matched to Google Scholar • Simple XML format – July 2006: 1. 4 M records matched to Google Scholar • MARCXML format – August 2006: Records added to Google Book Search – End 2006: Records in main google. com and yahoo. com index
Libraries Australia and the ANBD • Free Libraries Australia Search service – Launched by Senator Helen Coonan on 27 February 2006 – Freely available to anyone with Internet access – Easy to use, ‘google like’ search • Records exported to Search Engines – March 2006: 700, 000 records matched to Google Scholar • Simple XML format – July 2006: 1. 4 M records matched to Google Scholar • MARCXML format – August 2006: Records added to Google Book Search – End 2006: Records in main google. com and yahoo. com index
 Google’s Union Catalogue Program • Data obtained from 12 union catalogues: – Australia, China, Czech Republic, Denmark, Ireland, Israel, Hungary, Lithuania, Netherlands, Taiwan, United Kingdom and United States (World. Cat), • Links to union catalogues vary based on IP address of user • Issues: – Unique material – Matching algorithm – Trust, profit and motivation…
Google’s Union Catalogue Program • Data obtained from 12 union catalogues: – Australia, China, Czech Republic, Denmark, Ireland, Israel, Hungary, Lithuania, Netherlands, Taiwan, United Kingdom and United States (World. Cat), • Links to union catalogues vary based on IP address of user • Issues: – Unique material – Matching algorithm – Trust, profit and motivation…

 Libraries and the long tail • 80% of people want just 20% of any collection • 80% of the collection requested rarely – – The long tail of sporadic usage Represents a new business model => Net. Flix Fewer, larger resources => Union Catalogues Better fulfilment: home delivery, universal ‘Get it’ button – Project library services into Web 2. 0 world
Libraries and the long tail • 80% of people want just 20% of any collection • 80% of the collection requested rarely – – The long tail of sporadic usage Represents a new business model => Net. Flix Fewer, larger resources => Union Catalogues Better fulfilment: home delivery, universal ‘Get it’ button – Project library services into Web 2. 0 world
 Future directions • Enhancements to Libraries Australia – – Relevance Ranking Clustering and faceted browsing Annotation and links to value added services Improved getting • Exposure of the ANBD in google. com, yahoo. com • Libraries Australia search box • Relationship with OCLC and Open World. Cat
Future directions • Enhancements to Libraries Australia – – Relevance Ranking Clustering and faceted browsing Annotation and links to value added services Improved getting • Exposure of the ANBD in google. com, yahoo. com • Libraries Australia search box • Relationship with OCLC and Open World. Cat
 Libraries Australia search box
Libraries Australia search box
 Conclusions • Seeding search engines generates: – More discovery pathways => more users • Union catalogues support: – The business of libraries – Comprehensiveness => Exposing the long tail – More specialised services beyond search engines – Improved getting of items
Conclusions • Seeding search engines generates: – More discovery pathways => more users • Union catalogues support: – The business of libraries – Comprehensiveness => Exposing the long tail – More specialised services beyond search engines – Improved getting of items