

c262f0645aa111b984d4c66876ce056c.ppt
- Количество слайдов: 100
 Search Engines How Google Works: Connectivity and Link Analysis Thanks to R. Mooney, S. White, W. Arms C. Manning, P. Raghavan, H. Schutze
Search Engines How Google Works: Connectivity and Link Analysis Thanks to R. Mooney, S. White, W. Arms C. Manning, P. Raghavan, H. Schutze
 What we have covered • • • What is IR Evaluation Tokenization and properties of text Web crawling Query models Vector methods Measures of similarity Indexing Inverted files Web characteristics – Graph, links – Spam, SEO, duplication • Google and Link Analysis
What we have covered • • • What is IR Evaluation Tokenization and properties of text Web crawling Query models Vector methods Measures of similarity Indexing Inverted files Web characteristics – Graph, links – Spam, SEO, duplication • Google and Link Analysis
 What we will cover • Search engines – Classifications – Business models • Ranking by importance – Link analysis (graph search) • Citations • Page. Rank • Hubs/authorities • Google – Role in search – Architecture
What we will cover • Search engines – Classifications – Business models • Ranking by importance – Link analysis (graph search) • Citations • Page. Rank • Hubs/authorities • Google – Role in search – Architecture
 Google search
Google search
 Web Search Goal Provide information discovery for large amounts of open access material on the web Challenges • Volume of material -- several billion items, growing steadily • Items created dynamically or in databases • Great variety -- length, formats, quality control, purpose, etc. • Inexperience of users -- range of needs • Economic models to pay for the service
Web Search Goal Provide information discovery for large amounts of open access material on the web Challenges • Volume of material -- several billion items, growing steadily • Items created dynamically or in databases • Great variety -- length, formats, quality control, purpose, etc. • Inexperience of users -- range of needs • Economic models to pay for the service
 Search Engine Strategies Types of search engines Broad Classes: Subject hierarchies • Yahoo! , dmoz -- use of human indexing Web crawling + automatic indexing • General -- Google, Ask, Exalead, Bing Mixed models • Graphs - Kart. OO; clusters – Clusty (now Yippy) Metasearch New ones evolving
Search Engine Strategies Types of search engines Broad Classes: Subject hierarchies • Yahoo! , dmoz -- use of human indexing Web crawling + automatic indexing • General -- Google, Ask, Exalead, Bing Mixed models • Graphs - Kart. OO; clusters – Clusty (now Yippy) Metasearch New ones evolving
 Many Aspects of a Web Search Service Computational Components • Web crawler • Indexing system • Search system Social Considerations • Economics • Scalability • Legal issues
Many Aspects of a Web Search Service Computational Components • Web crawler • Indexing system • Search system Social Considerations • Economics • Scalability • Legal issues
 Query Engine Index Interface Indexer Users Crawler Web Ranking by web graph A Typical Web Search Engine
Query Engine Index Interface Indexer Users Crawler Web Ranking by web graph A Typical Web Search Engine
") Business Models Subscription Monthly fee with logon provides unlimited access (introduced by Info. Seek) Advertising Access is free, with display advertisements (introduced by Lycos) Can lead to distortion of results to suit advertisers Focused advertising - Google, Overture Licensing Cost of company are covered by fees, licensing of software and specialized services Others?
Business Models Subscription Monthly fee with logon provides unlimited access (introduced by Info. Seek) Advertising Access is free, with display advertisements (introduced by Lycos) Can lead to distortion of results to suit advertisers Focused advertising - Google, Overture Licensing Cost of company are covered by fees, licensing of software and specialized services Others?
 Business models for advertisers • For a related query “tennis shoes” • Your company – Comes up first in SERP – Comes up on the first SERP page • Otherwise, say goodbye to web business • Completely dependent on search engines ranking algorithm for organic SEO • Google changes ranking – Will other search engines follow?
Business models for advertisers • For a related query “tennis shoes” • Your company – Comes up first in SERP – Comes up on the first SERP page • Otherwise, say goodbye to web business • Completely dependent on search engines ranking algorithm for organic SEO • Google changes ranking – Will other search engines follow?
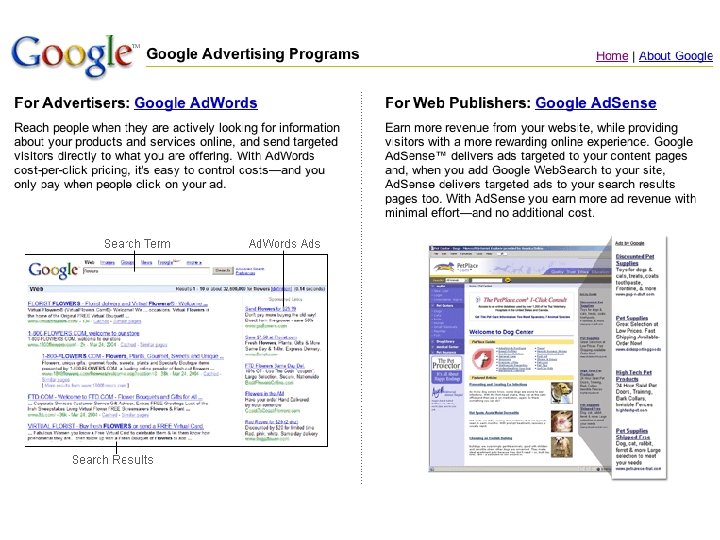
 Generations of search engines • 0 th - Library catalog – Based on human created metadata • 1 st - Altavista – First large comprehensive database – Word based index and ranking • 2 nd - Google – High relevance – Link (connectivity) based importance
Generations of search engines • 0 th - Library catalog – Based on human created metadata • 1 st - Altavista – First large comprehensive database – Word based index and ranking • 2 nd - Google – High relevance – Link (connectivity) based importance
 Motivation for Link Analysis • Early search engines mainly compare content similarity of the query and the indexed pages. I. e. , – They use information retrieval methods, cosine, TF-IDF, . . . • From mid 90’s, it became clear that content similarity alone was no longer sufficient. – The number of pages grew rapidly in the mid-late 1990’s. • Try “classification methods”, Google estimates: millions of relevant pages. • How to choose only 30 -40 pages and rank them suitably to present to the user? – Content similarity is easily spammed. • A page owner can repeat some words and add many related words to boost the rankings of his pages and/or to make the pages relevant to a large number of queries.
Motivation for Link Analysis • Early search engines mainly compare content similarity of the query and the indexed pages. I. e. , – They use information retrieval methods, cosine, TF-IDF, . . . • From mid 90’s, it became clear that content similarity alone was no longer sufficient. – The number of pages grew rapidly in the mid-late 1990’s. • Try “classification methods”, Google estimates: millions of relevant pages. • How to choose only 30 -40 pages and rank them suitably to present to the user? – Content similarity is easily spammed. • A page owner can repeat some words and add many related words to boost the rankings of his pages and/or to make the pages relevant to a large number of queries.
 Early hyperlinks • Starting mid 90’s, researchers began to work on the problem, resorting to hyperlinks. – In Feb, 1997, Yanhong Li (Scotch Plains, NJ) filed a hyperlink based search patent. The method uses words in anchor text of hyperlinks. • Web pages on the other hand are connected through hyperlinks, which carry important information. – Manually made – social network – Some hyperlinks: organize information at the same site. – Other hyperlinks: point to pages from other Web sites. Such out-going hyperlinks often indicate an implicit conveyance of authority to the pages being pointed to. • Those pages that are pointed to by many other pages are likely to contain authoritative information.
Early hyperlinks • Starting mid 90’s, researchers began to work on the problem, resorting to hyperlinks. – In Feb, 1997, Yanhong Li (Scotch Plains, NJ) filed a hyperlink based search patent. The method uses words in anchor text of hyperlinks. • Web pages on the other hand are connected through hyperlinks, which carry important information. – Manually made – social network – Some hyperlinks: organize information at the same site. – Other hyperlinks: point to pages from other Web sites. Such out-going hyperlinks often indicate an implicit conveyance of authority to the pages being pointed to. • Those pages that are pointed to by many other pages are likely to contain authoritative information.
 Hyperlink algorithms • During 1997 -1998, the two most influential hyperlink based search algorithms Page. Rank and HITS were reported. • Both algorithms are related to social networks. They exploit the hyperlinks of the Web to rank pages according to their levels of “prestige” or “authority”. – HITS: Jon Kleinberg (Cornel University), at Ninth Annual ACM-SIAM Symposium on Discrete Algorithms, January 1998 – Page. Rank: Sergey Brin and Larry Page, Ph. D students from Stanford University, at Seventh International World Wide Web Conference (WWW 7) in April, 1998. • Page. Rank powers the Google search engine. • Impact of “Stanford University” in web search – Google: Sergey Brin and Larry Page (Ph. D candidates in CS) – Yahoo!: Jerry Yang and David Filo (Ph. D candidates in EE) – HP, Sun, Cisco, …
Hyperlink algorithms • During 1997 -1998, the two most influential hyperlink based search algorithms Page. Rank and HITS were reported. • Both algorithms are related to social networks. They exploit the hyperlinks of the Web to rank pages according to their levels of “prestige” or “authority”. – HITS: Jon Kleinberg (Cornel University), at Ninth Annual ACM-SIAM Symposium on Discrete Algorithms, January 1998 – Page. Rank: Sergey Brin and Larry Page, Ph. D students from Stanford University, at Seventh International World Wide Web Conference (WWW 7) in April, 1998. • Page. Rank powers the Google search engine. • Impact of “Stanford University” in web search – Google: Sergey Brin and Larry Page (Ph. D candidates in CS) – Yahoo!: Jerry Yang and David Filo (Ph. D candidates in EE) – HP, Sun, Cisco, …
 Other uses • Apart from search ranking, hyperlinks are also useful for finding Web communities. – A Web community is a cluster of densely linked pages representing a group of people with a special interest. • Beyond explicit hyperlinks on the Web, links in other contexts are useful too, e. g. , – for discovering communities of named entities (e. g. , people and organizations) in free text documents, and – for analyzing social phenomena in emails. .
Other uses • Apart from search ranking, hyperlinks are also useful for finding Web communities. – A Web community is a cluster of densely linked pages representing a group of people with a special interest. • Beyond explicit hyperlinks on the Web, links in other contexts are useful too, e. g. , – for discovering communities of named entities (e. g. , people and organizations) in free text documents, and – for analyzing social phenomena in emails. .
 The Web as a Directed Graph Page A Anchor hyperlink Page B Assumption 1: A hyperlink between pages denotes author perceived relevance (quality signal) Assumption 2: The anchor of the hyperlink describes the target page (textual context)
The Web as a Directed Graph Page A Anchor hyperlink Page B Assumption 1: A hyperlink between pages denotes author perceived relevance (quality signal) Assumption 2: The anchor of the hyperlink describes the target page (textual context)
 of each link") Anchor Text Indexing • Extract anchor text (between and ) of each link followed. • Anchor text is usually descriptive of the document to which it points. • Add anchor text to the content of the destination page to provide additional relevant keyword indices. • Used by Google: – Evil Empire – IBM Anchor text
Anchor Text Indexing • Extract anchor text (between and ) of each link followed. • Anchor text is usually descriptive of the document to which it points. • Add anchor text to the content of the destination page to provide additional relevant keyword indices. • Used by Google: – Evil Empire – IBM Anchor text
![Anchor Text WWW Worm - Mc. Bryan [Mcbr 94] • For ibm how to](https://present5.com/presentation/c262f0645aa111b984d4c66876ce056c/image-19.jpg "Anchor Text WWW Worm - Mc. Bryan [Mcbr 94] • For ibm how to") Anchor Text WWW Worm - Mc. Bryan [Mcbr 94] • For ibm how to distinguish between: – IBM’s home page (mostly graphical) – IBM’s copyright page (high term freq. for ‘ibm’) – Rival’s spam page (arbitrarily high term freq. ) “ibm” A million pieces of anchor text with “ibm” send a strong signal “ibm. com” www. ibm. com “IBM home page”
Anchor Text WWW Worm - Mc. Bryan [Mcbr 94] • For ibm how to distinguish between: – IBM’s home page (mostly graphical) – IBM’s copyright page (high term freq. for ‘ibm’) – Rival’s spam page (arbitrarily high term freq. ) “ibm” A million pieces of anchor text with “ibm” send a strong signal “ibm. com” www. ibm. com “IBM home page”
 Indexing anchor text • When indexing a document D, include anchor text from links pointing to D. Armonk, NY-based computer giant IBM announced today www. ibm. com Joe’s computer hardware links Compaq HP IBM Big Blue today announced record profits for the quarter
Indexing anchor text • When indexing a document D, include anchor text from links pointing to D. Armonk, NY-based computer giant IBM announced today www. ibm. com Joe’s computer hardware links Compaq HP IBM Big Blue today announced record profits for the quarter
 Indexing anchor text • Can sometimes have unexpected side effects - e. g. , french military victories • Helps when descriptive text in destination page is embedded in image logos rather than in accessible text. • Many times anchor text is not useful: – “click here” • Increases content more for popular pages with many incoming links, increasing recall of these pages. • May even give higher weights to tokens from anchor text.
Indexing anchor text • Can sometimes have unexpected side effects - e. g. , french military victories • Helps when descriptive text in destination page is embedded in image logos rather than in accessible text. • Many times anchor text is not useful: – “click here” • Increases content more for popular pages with many incoming links, increasing recall of these pages. • May even give higher weights to tokens from anchor text.
 Anchor Text • Other applications – Weighting/filtering links in the graph • HITS [Chak 98], Hilltop [Bhar 01] – Generating page descriptions from anchor text [Amit 98, Amit 00]
Anchor Text • Other applications – Weighting/filtering links in the graph • HITS [Chak 98], Hilltop [Bhar 01] – Generating page descriptions from anchor text [Amit 98, Amit 00]
 Concept of Relevance Document measures Relevance, as conventionally defined, is binary (relevant or not relevant). It is usually estimated by the similarity between the terms in the query and each document. Importance measures documents by their likelihood of being useful to a variety of users. It is usually estimated by some measure of popularity. Web search engines rank documents by combination of relevance and importance. The goal is to present the user with the most important of the relevant documents.
Concept of Relevance Document measures Relevance, as conventionally defined, is binary (relevant or not relevant). It is usually estimated by the similarity between the terms in the query and each document. Importance measures documents by their likelihood of being useful to a variety of users. It is usually estimated by some measure of popularity. Web search engines rank documents by combination of relevance and importance. The goal is to present the user with the most important of the relevant documents.
 Ranking Options 1. Paid advertisers 2. Manually created classification 3. Vector space ranking with corrections for document length 4. Extra weighting for specific fields, e. g. , title, anchors, etc. 5. Popularity or importance, e. g. , Page. Rank Many of these factors are NOT made public.
Ranking Options 1. Paid advertisers 2. Manually created classification 3. Vector space ranking with corrections for document length 4. Extra weighting for specific fields, e. g. , title, anchors, etc. 5. Popularity or importance, e. g. , Page. Rank Many of these factors are NOT made public.
 History of link analysis • Bibliometrics – Citation analysis since the 1960’s – Citation links to and from documents • Basis of pagerank idea
History of link analysis • Bibliometrics – Citation analysis since the 1960’s – Citation links to and from documents • Basis of pagerank idea
 Bibliometrics Techniques that use citation analysis to measure the similarity of journal articles or their importance Bibliographic coupling: two papers that cite many of the same papers Cocitation: two papers that were cited by many of the same papers Impact factor (of a journal): frequency with which the average article in a journal has been cited in a particular year or period Citation frequency
Bibliometrics Techniques that use citation analysis to measure the similarity of journal articles or their importance Bibliographic coupling: two papers that cite many of the same papers Cocitation: two papers that were cited by many of the same papers Impact factor (of a journal): frequency with which the average article in a journal has been cited in a particular year or period Citation frequency
 Citation Graph cites Bibliographic coupling Paper is cited by cocitation Note that academic citations nearly always refer to earlier work.
Citation Graph cites Bibliographic coupling Paper is cited by cocitation Note that academic citations nearly always refer to earlier work.
 Graphical Analysis of Hyperlinks on the Web This page links to many other pages (hub) 1 2 4 3 5 6 Many pages link to this page (authority)
Graphical Analysis of Hyperlinks on the Web This page links to many other pages (hub) 1 2 4 3 5 6 Many pages link to this page (authority)
 Search Engines • What is connectivity/linking? • Role of connectivity in ranking – Academic paper analysis – Hits - IBM – Ask – Facebook – Google Scholar – Cite. Seer (Cite. Seer. X), Chem. XSeer, Arch. Seer, etc –…
Search Engines • What is connectivity/linking? • Role of connectivity in ranking – Academic paper analysis – Hits - IBM – Ask – Facebook – Google Scholar – Cite. Seer (Cite. Seer. X), Chem. XSeer, Arch. Seer, etc –…
, explicit citations to") Bibliometrics: Citation Analysis • Many standard documents include bibliographies (or references), explicit citations to other previously published documents. • Using citations as links, standard corpora can be viewed as a graph. • The structure of this graph, independent of content, can provide interesting information about the similarity of documents and the structure of information. • Impact of paper!
Bibliometrics: Citation Analysis • Many standard documents include bibliographies (or references), explicit citations to other previously published documents. • Using citations as links, standard corpora can be viewed as a graph. • The structure of this graph, independent of content, can provide interesting information about the similarity of documents and the structure of information. • Impact of paper!
") Impact Factor • Developed by Garfield in 1972 to measure the importance (quality, influence) of scientific journals. • Measure of how often papers in the journal are cited by other scientists. • Computed and published annually by the Institute for Scientific Information (ISI). • The impact factor of a journal J in year Y is the average number of citations (from indexed documents published in year Y) to a paper published in J in year Y 1 or Y 2. • Does not account for the quality of the citing article.
Impact Factor • Developed by Garfield in 1972 to measure the importance (quality, influence) of scientific journals. • Measure of how often papers in the journal are cited by other scientists. • Computed and published annually by the Institute for Scientific Information (ISI). • The impact factor of a journal J in year Y is the average number of citations (from indexed documents published in year Y) to a paper published in J in year Y 1 or Y 2. • Does not account for the quality of the citing article.
 Citations vs. Web Links • Web links are a bit different than citations: – Many links are navigational. – Many pages with high in-degree are portals not content providers. – Not all links are endorsements. – Company websites don’t point to their competitors. – Citations to relevant literature is enforced by peer-review.
Citations vs. Web Links • Web links are a bit different than citations: – Many links are navigational. – Many pages with high in-degree are portals not content providers. – Not all links are endorsements. – Company websites don’t point to their competitors. – Citations to relevant literature is enforced by peer-review.
dependence • Query independent ranking – Important pages; no need for queries") Ranking: query (in)dependence • Query independent ranking – Important pages; no need for queries – Trusted pages? – Page. Rank can do this • Query dependent ranking – Combine importance with query evaluation – Hits is query based. – So is Google. Rank (combine Page. Rank with some similarity measure)
Ranking: query (in)dependence • Query independent ranking – Important pages; no need for queries – Trusted pages? – Page. Rank can do this • Query dependent ranking – Combine importance with query evaluation – Hits is query based. – So is Google. Rank (combine Page. Rank with some similarity measure)
 Page. Rank vs Hits • Web site classification – Hubs – Authorities • Hubs & Authorities: Hits • Authorities: Page. Rank
Page. Rank vs Hits • Web site classification – Hubs – Authorities • Hubs & Authorities: Hits • Authorities: Page. Rank
 Authorities • Authorities are pages that are recognized as providing significant, trustworthy, and useful information on a topic. • In-degree (number of pointers to a page) is one simple measure of authority. • However in-degree treats all links as equal. • Should links from pages that are themselves authoritative count more?
Authorities • Authorities are pages that are recognized as providing significant, trustworthy, and useful information on a topic. • In-degree (number of pointers to a page) is one simple measure of authority. • However in-degree treats all links as equal. • Should links from pages that are themselves authoritative count more?
 Hubs • Hubs are index pages that provide lots of useful links to relevant content pages (topic authorities). • Ex: pages are included in the course home page
Hubs • Hubs are index pages that provide lots of useful links to relevant content pages (topic authorities). • Ex: pages are included in the course home page
 HITS • Algorithm developed by Kleinberg in 1998. • IBM search engine project • Attempts to computationally determine hubs and authorities on a particular topic through analysis of a relevant subgraph of the web. • Based on mutually recursive facts: – Hubs point to lots of authorities. – Authorities are pointed to by lots of hubs.
HITS • Algorithm developed by Kleinberg in 1998. • IBM search engine project • Attempts to computationally determine hubs and authorities on a particular topic through analysis of a relevant subgraph of the web. • Based on mutually recursive facts: – Hubs point to lots of authorities. – Authorities are pointed to by lots of hubs.
 Hubs and Authorities • Together they tend to form a bipartite graph: Hubs Authorities
Hubs and Authorities • Together they tend to form a bipartite graph: Hubs Authorities
 HITS Algorithm • Computes hubs and authorities for a particular topic specified by a normal query. – Thus query dependent ranking • First determines a set of relevant pages for the query called the base set S. • Analyze the link structure of the web subgraph defined by S to find authority and hub pages in this set.
HITS Algorithm • Computes hubs and authorities for a particular topic specified by a normal query. – Thus query dependent ranking • First determines a set of relevant pages for the query called the base set S. • Analyze the link structure of the web subgraph defined by S to find authority and hub pages in this set.
 Constructing a Base Subgraph • For a specific query Q, let the set of documents returned by a standard search engine be called the root set R. • Initialize S to R. • Add to S all pages pointed to by any page in R. • Add to S all pages that point to any page in R. S R
Constructing a Base Subgraph • For a specific query Q, let the set of documents returned by a standard search engine be called the root set R. • Initialize S to R. • Add to S all pages pointed to by any page in R. • Add to S all pages that point to any page in R. S R
 Base Limitations • To limit computational expense: – Limit number of root pages to the top 200 pages retrieved for the query. – Limit number of “back-pointer” pages to a random set of at most 50 pages returned by a “reverse link” query. • To eliminate purely navigational links: – Eliminate links between two pages on the same host. • To eliminate “non-authority-conveying” links: – Allow only m (m 4 8) pages from a given host as pointers to any individual page.
Base Limitations • To limit computational expense: – Limit number of root pages to the top 200 pages retrieved for the query. – Limit number of “back-pointer” pages to a random set of at most 50 pages returned by a “reverse link” query. • To eliminate purely navigational links: – Eliminate links between two pages on the same host. • To eliminate “non-authority-conveying” links: – Allow only m (m 4 8) pages from a given host as pointers to any individual page.
 Authorities and In-Degree • Even within the base set S for a given query, the nodes with highest in-degree are not necessarily authorities (may just be generally popular pages like Yahoo or Amazon). • True authority pages are pointed to by a number of hubs (i. e. pages that point to lots of authorities).
Authorities and In-Degree • Even within the base set S for a given query, the nodes with highest in-degree are not necessarily authorities (may just be generally popular pages like Yahoo or Amazon). • True authority pages are pointed to by a number of hubs (i. e. pages that point to lots of authorities).
 Iterative Algorithm • Use an iterative algorithm to slowly converge on a mutually reinforcing set of hubs and authorities. • Maintain for each page p S: – Authority score: ap (vector a) – Hub score: hp (vector h) • Initialize all ap = hp = 1 • Maintain normalized scores:
Iterative Algorithm • Use an iterative algorithm to slowly converge on a mutually reinforcing set of hubs and authorities. • Maintain for each page p S: – Authority score: ap (vector a) – Hub score: hp (vector h) • Initialize all ap = hp = 1 • Maintain normalized scores:
 Convergence • Algorithm converges to a fix-point if iterated indefinitely. • Define A to be the adjacency matrix for the subgraph defined by S. – Aij = 1 for i S, j S iff i j • Authority vector, a, converges to the principal eigenvector of ATA • Hub vector, h, converges to the principal eigenvector of AAT • In practice, 20 iterations produces fairly stable results.
Convergence • Algorithm converges to a fix-point if iterated indefinitely. • Define A to be the adjacency matrix for the subgraph defined by S. – Aij = 1 for i S, j S iff i j • Authority vector, a, converges to the principal eigenvector of ATA • Hub vector, h, converges to the principal eigenvector of AAT • In practice, 20 iterations produces fairly stable results.
 HITS Results • An ambiguous query can result in the principal eigenvector only covering one of the possible meanings. • Non-principal eigenvectors may contain hubs & authorities for other meanings. • Example: “jaguar”: – Atari video game (principal eigenvector) – NFL Football team (2 nd non-princ. eigenvector) – Automobile (3 rd non-princ. eigenvector) • Reportedly first used by Teoma. com
HITS Results • An ambiguous query can result in the principal eigenvector only covering one of the possible meanings. • Non-principal eigenvectors may contain hubs & authorities for other meanings. • Example: “jaguar”: – Atari video game (principal eigenvector) – NFL Football team (2 nd non-princ. eigenvector) – Automobile (3 rd non-princ. eigenvector) • Reportedly first used by Teoma. com
 • In response to a query, instead of an ordered") Hyperlink-Induced Topic Search (HITS) • In response to a query, instead of an ordered list of pages each meeting the query, find two sets of inter-related pages: – Hub pages are good lists of links on a subject. • e. g. , “Bob’s list of cancer-related links. ” – Authority pages occur recurrently on good hubs for the subject. • Best suited for “broad topic” queries rather than for page-finding queries. • Gets at a broader slice of common opinion.
Hyperlink-Induced Topic Search (HITS) • In response to a query, instead of an ordered list of pages each meeting the query, find two sets of inter-related pages: – Hub pages are good lists of links on a subject. • e. g. , “Bob’s list of cancer-related links. ” – Authority pages occur recurrently on good hubs for the subject. • Best suited for “broad topic” queries rather than for page-finding queries. • Gets at a broader slice of common opinion.
 Google Background “Our main goal is to improve the quality of web search engines” • Google googol = 10^100 • Originally part of the Stanford digital library project known as Web. Base, commercialized in 1999
Google Background “Our main goal is to improve the quality of web search engines” • Google googol = 10^100 • Originally part of the Stanford digital library project known as Web. Base, commercialized in 1999
 Initial Design Goals • Deliver results that have very high precision even at the expense of recall • Make search engine technology transparent, i. e. advertising shouldn’t bias results • Bring search engine technology into academic realm in order to support novel research activities on large web data sets • Make system easy to use for most people, e. g. users shouldn’t have to specify more than a couple words
Initial Design Goals • Deliver results that have very high precision even at the expense of recall • Make search engine technology transparent, i. e. advertising shouldn’t bias results • Bring search engine technology into academic realm in order to support novel research activities on large web data sets • Make system easy to use for most people, e. g. users shouldn’t have to specify more than a couple words
 Google Search Engine Features Two main features to increase result precision: • Uses link structure of web (Page. Rank) • Uses text surrounding hyperlinks to improve accurate document retrieval Other features include: • Takes into account word proximity in documents • Uses font size, word position, etc. to weight word • Storage of full raw html pages
Google Search Engine Features Two main features to increase result precision: • Uses link structure of web (Page. Rank) • Uses text surrounding hyperlinks to improve accurate document retrieval Other features include: • Takes into account word proximity in documents • Uses font size, word position, etc. to weight word • Storage of full raw html pages
 Page. Rank in Words Intuition: • Imagine a web surfer doing a simple random walk on the entire web for an infinite number of steps. • Occasionally, the surfer will get bored and instead of following a link pointing outward from the current page will jump to another random page. • At some point, the percentage of time spent at each page will converge to a fixed value. • This value is known as the Page. Rank of the page.
Page. Rank in Words Intuition: • Imagine a web surfer doing a simple random walk on the entire web for an infinite number of steps. • Occasionally, the surfer will get bored and instead of following a link pointing outward from the current page will jump to another random page. • At some point, the percentage of time spent at each page will converge to a fixed value. • This value is known as the Page. Rank of the page.
. • Does") Page. Rank • Link-analysis method used by Google (Brin & Page, 1998). • Does not attempt to capture the distinction between hubs and authorities. • Ranks pages just by authority. • Query independent • Applied to the entire web rather than a local neighborhood of pages surrounding the results of a query.
Page. Rank • Link-analysis method used by Google (Brin & Page, 1998). • Does not attempt to capture the distinction between hubs and authorities. • Ranks pages just by authority. • Query independent • Applied to the entire web rather than a local neighborhood of pages surrounding the results of a query.
 doesn’t account for the") Initial Page. Rank Idea • Just measuring in-degree (citation count) doesn’t account for the authority of the source of a link. • Initial page rank equation for page p: – Nq is the total number of out-links from page q. – A page, q, “gives” an equal fraction of its authority to all the pages it points to (e. g. p). – c is a normalizing constant set so that the rank of all pages always sums to 1.
Initial Page. Rank Idea • Just measuring in-degree (citation count) doesn’t account for the authority of the source of a link. • Initial page rank equation for page p: – Nq is the total number of out-links from page q. – A page, q, “gives” an equal fraction of its authority to all the pages it points to (e. g. p). – c is a normalizing constant set so that the rank of all pages always sums to 1.
 • Can view it as a process of") Initial Page. Rank Idea (cont. ) • Can view it as a process of Page. Rank “flowing” from pages to the pages they cite. . 1 . 05 . 08 . 05. 03. 09 . 03 . 08 . 03
Initial Page. Rank Idea (cont. ) • Can view it as a process of Page. Rank “flowing” from pages to the pages they cite. . 1 . 05 . 08 . 05. 03. 09 . 03 . 08 . 03
 Initial Algorithm • Iterate rank-flowing process until convergence: Let S be the total set of pages. Initialize p S: R(p) = 1/|S| Until ranks do not change (much) (convergence) For each p S: R(p) = c. R´(p) (normalize)
Initial Algorithm • Iterate rank-flowing process until convergence: Let S be the total set of pages. Initialize p S: R(p) = 1/|S| Until ranks do not change (much) (convergence) For each p S: R(p) = c. R´(p) (normalize)
 Sample Stable Fixed Point 0. 4 0. 2
Sample Stable Fixed Point 0. 4 0. 2
 Problem with Initial Idea • A group of pages that only point to themselves but are pointed to by other pages act as a “rank sink” and absorb all the rank in the system. Rank flows into cycle and can’t get out
Problem with Initial Idea • A group of pages that only point to themselves but are pointed to by other pages act as a “rank sink” and absorb all the rank in the system. Rank flows into cycle and can’t get out
 Rank Source • Introduce a “rank source” E that continually replenishes the rank of each page, p, by a fixed amount E(p).
Rank Source • Introduce a “rank source” E that continually replenishes the rank of each page, p, by a fixed amount E(p).
 Page. Rank Algorithm Let S be the total set of pages. Let p S: E(p) = /|S| (for some 0< <1, e. g. 0. 15) Initialize p S: R(p) = 1/|S| Until ranks do not change (much) (convergence) For each p S: R(p) = c. R´(p) (normalize)
Page. Rank Algorithm Let S be the total set of pages. Let p S: E(p) = /|S| (for some 0< <1, e. g. 0. 15) Initialize p S: R(p) = 1/|S| Until ranks do not change (much) (convergence) For each p S: R(p) = c. R´(p) (normalize)
 Random Surfer Model • Page. Rank can be seen as modeling a “random surfer” that starts on a random page and then at each point: – With probability E(p) randomly jumps to page p. – Otherwise, randomly follows a link on the current page. • R(p) models the probability that this random surfer will be on page p at any given time. • “E jumps” are needed to prevent the random surfer from getting “trapped” in web sinks with no outgoing links.
Random Surfer Model • Page. Rank can be seen as modeling a “random surfer” that starts on a random page and then at each point: – With probability E(p) randomly jumps to page p. – Otherwise, randomly follows a link on the current page. • R(p) models the probability that this random surfer will be on page p at any given time. • “E jumps” are needed to prevent the random surfer from getting “trapped” in web sinks with no outgoing links.
 Justifications for using Page. Rank • Attempts to model user behavior • Captures the notion that the more a page is pointed to by “important” pages, the more it is worth looking at • Takes into account global structure of web
Justifications for using Page. Rank • Attempts to model user behavior • Captures the notion that the more a page is pointed to by “important” pages, the more it is worth looking at • Takes into account global structure of web
 Speed of Convergence • Early experiments on Google used 322 million links. • Page. Rank algorithm converged (within small tolerance) in about 52 iterations. • Number of iterations required for convergence is empirically O(log n) (where n is the number of links). • Therefore calculation is quite efficient.
Speed of Convergence • Early experiments on Google used 322 million links. • Page. Rank algorithm converged (within small tolerance) in about 52 iterations. • Number of iterations required for convergence is empirically O(log n) (where n is the number of links). • Therefore calculation is quite efficient.
.") Google Ranking • Complete Google ranking includes (based on university publications prior to commercialization). – – Vector-space similarity component. Keyword proximity component. HTML-tag weight component (e. g. title preference). Page. Rank component. • Details of current commercial ranking functions are trade secrets. – Page. Rank becomes Google. Rank!
Google Ranking • Complete Google ranking includes (based on university publications prior to commercialization). – – Vector-space similarity component. Keyword proximity component. HTML-tag weight component (e. g. title preference). Page. Rank component. • Details of current commercial ranking functions are trade secrets. – Page. Rank becomes Google. Rank!
 by changing E to") Personalized Page. Rank • Page. Rank can be biased (personalized) by changing E to a non-uniform distribution. • Restrict “random jumps” to a set of specified relevant pages. • For example, let E(p) = 0 except for one’s own home page, for which E(p) = • This results in a bias towards pages that are closer in the web graph to your own homepage.
Personalized Page. Rank • Page. Rank can be biased (personalized) by changing E to a non-uniform distribution. • Restrict “random jumps” to a set of specified relevant pages. • For example, let E(p) = 0 except for one’s own home page, for which E(p) = • This results in a bias towards pages that are closer in the web graph to your own homepage.
 a crawler on") Google Page. Rank-Biased Crawling • Use Page. Rank to direct (focus) a crawler on “important” pages. • Compute page-rank using the current set of crawled pages. • Order the crawler’s search queue based on current estimated Page. Rank.
Google Page. Rank-Biased Crawling • Use Page. Rank to direct (focus) a crawler on “important” pages. • Compute page-rank using the current set of crawled pages. • Order the crawler’s search queue based on current estimated Page. Rank.
 Information Retrieval Using Page. Rank • Remember no queries are used with Page. Rank • Page. Rank precomputed (static rank) • Query independent ranking How are queries put into the final ranking? Simple Method Combine term similarity (dynamic rank) with Page. Rank One method: Final rank = R(p) * Similarity Lucene index: add to boasting term
Information Retrieval Using Page. Rank • Remember no queries are used with Page. Rank • Page. Rank precomputed (static rank) • Query independent ranking How are queries put into the final ranking? Simple Method Combine term similarity (dynamic rank) with Page. Rank One method: Final rank = R(p) * Similarity Lucene index: add to boasting term
 Combining Term Weighting with Page. Rank – another approach Combined Method 1. Find all documents that share a term with the query vector. 2. The similarity, using conventional term weighting, between the query and document j is sj. 3. The rank of document j using Page. Rank or other graph ranking is pj. 4. Calculate a combined rank cj = sj + (1 - )pj, where is a constant. 5. Display the hits ranked by cj. This method is used in several commercial systems, but the details have not been published.
Combining Term Weighting with Page. Rank – another approach Combined Method 1. Find all documents that share a term with the query vector. 2. The similarity, using conventional term weighting, between the query and document j is sj. 3. The rank of document j using Page. Rank or other graph ranking is pj. 4. Calculate a combined rank cj = sj + (1 - )pj, where is a constant. 5. Display the hits ranked by cj. This method is used in several commercial systems, but the details have not been published.
 Why we need a fast link-based rank? “…The link structure of the Web is significantly more dynamic than the contents on the Web. Every week, about 25% new links are created. After a year, about 80% of the links on the Web are replaced with new ones. This result indicates that search engines need to update link-based ranking metrics very often…” [ Cho et al. , 04 ]
Why we need a fast link-based rank? “…The link structure of the Web is significantly more dynamic than the contents on the Web. Every week, about 25% new links are created. After a year, about 80% of the links on the Web are replaced with new ones. This result indicates that search engines need to update link-based ranking metrics very often…” [ Cho et al. , 04 ]
 Accelerating Page. Rank • Web Graph Compression to fit in internal memory [Boldi et al. , 04] • Efficient External memory implementation [Haveliwala, 99; Chen et al. , 02] • Mathematical approaches • Combination of the above strategies
Accelerating Page. Rank • Web Graph Compression to fit in internal memory [Boldi et al. , 04] • Efficient External memory implementation [Haveliwala, 99; Chen et al. , 02] • Mathematical approaches • Combination of the above strategies
 Link Analysis Conclusions • Link analysis uses information about the structure of the web graph to aid search. • It is one of the major innovations in web search. • It is the primary reason for Google’s success. • Still lots of research regarding improvements
Link Analysis Conclusions • Link analysis uses information about the structure of the web graph to aid search. • It is one of the major innovations in web search. • It is the primary reason for Google’s success. • Still lots of research regarding improvements
 Limits of Link Analysis • Stability – Adding even a small number of nodes/edges to the graph has a significant impact • Topic drift – A top authority may be a hub of pages on a different topic resulting in increased rank of the authority page • Content evolution – Adding/removing links/content can affect the intuitive authority rank of a page requiring recalculation of page ranks
Limits of Link Analysis • Stability – Adding even a small number of nodes/edges to the graph has a significant impact • Topic drift – A top authority may be a hub of pages on a different topic resulting in increased rank of the authority page • Content evolution – Adding/removing links/content can affect the intuitive authority rank of a page requiring recalculation of page ranks
 Google Architecture - preliminary Implemented in Perl, C and C++ on Solaris and Linux
Google Architecture - preliminary Implemented in Perl, C and C++ on Solaris and Linux
 Preliminary “Hitlist” is defined as list of occurrences of a particular word in a particular document including additional meta info: - position of word in doc - font size - capitalization - descriptor type, e. g. title, anchor, etc.
Preliminary “Hitlist” is defined as list of occurrences of a particular word in a particular document including additional meta info: - position of word in doc - font size - capitalization - descriptor type, e. g. title, anchor, etc.
 Multiple crawlers run in parallel. Each crawler keeps its own") Google Architecture (cont. ) Multiple crawlers run in parallel. Each crawler keeps its own DNS lookup cache and ~300 open connections open at once. Keeps track of URLs that have and need to be crawled Compresses and stores web pages Stores each link and text surrounding link. Converts relative URLs into absolute URLs. Uncompresses and parses documents. Stores link information in anchors file. Contains full html of every web page. Each document is prefixed by doc. ID, length, and URL.
Google Architecture (cont. ) Multiple crawlers run in parallel. Each crawler keeps its own DNS lookup cache and ~300 open connections open at once. Keeps track of URLs that have and need to be crawled Compresses and stores web pages Stores each link and text surrounding link. Converts relative URLs into absolute URLs. Uncompresses and parses documents. Stores link information in anchors file. Contains full html of every web page. Each document is prefixed by doc. ID, length, and URL.
 Maps absolute URLs into doc. IDs stored in Doc Index.") Google Architecture (cont. ) Maps absolute URLs into doc. IDs stored in Doc Index. Stores anchor text in “barrels”. Generates database of links (pairs of doc. Ids). Parses & distributes hit lists into “barrels. ” Partially sorted forward indexes sorted by doc. ID. Each barrel stores hitlists for a given range of word. IDs. In-memory hash table that maps words to word. Ids. Contains pointer to doclist in barrel which word. Id falls into. Creates inverted index whereby document list containing doc. ID and hitlists can be retrieved given word. ID. Doc. ID keyed index where each entry includes info such as pointer to doc in repository, checksum, statistics, status, etc. Also contains URL info if doc has been crawled. If not just contains URL.
Google Architecture (cont. ) Maps absolute URLs into doc. IDs stored in Doc Index. Stores anchor text in “barrels”. Generates database of links (pairs of doc. Ids). Parses & distributes hit lists into “barrels. ” Partially sorted forward indexes sorted by doc. ID. Each barrel stores hitlists for a given range of word. IDs. In-memory hash table that maps words to word. Ids. Contains pointer to doclist in barrel which word. Id falls into. Creates inverted index whereby document list containing doc. ID and hitlists can be retrieved given word. ID. Doc. ID keyed index where each entry includes info such as pointer to doc in repository, checksum, statistics, status, etc. Also contains URL info if doc has been crawled. If not just contains URL.
 2 kinds of barrels. Short barrell which contain hit list") Google Architecture (cont. ) 2 kinds of barrels. Short barrell which contain hit list which include title or anchor hits. Long barrell for all hit lists. New lexicon keyed by word. ID, inverted doc index keyed by doc. ID, and Page. Ranks used to answer queries List of word. Ids produced by Sorter and lexicon created by Indexer used to create new lexicon used by searcher. Lexicon stores ~14 million words.
Google Architecture (cont. ) 2 kinds of barrels. Short barrell which contain hit list which include title or anchor hits. Long barrell for all hit lists. New lexicon keyed by word. ID, inverted doc index keyed by doc. ID, and Page. Ranks used to answer queries List of word. Ids produced by Sorter and lexicon created by Indexer used to create new lexicon used by searcher. Lexicon stores ~14 million words.
 Scalability 10, 000, 000 The growth of the web 1, 000, 000 100, 000 10, 000 1, 000 100, 000 1, 000 10 1 1994 1997 2000
Scalability 10, 000, 000 The growth of the web 1, 000, 000 100, 000 10, 000 1, 000 100, 000 1, 000 10 1 1994 1997 2000
 Scalability Web search services are distributed centralized systems • Over the past 9 years, Moore's Law has enabled the services to keep pace with the growth of the web and the number of users, while adding extra function. • Will this continue? • Possible areas for concern are: staff costs, telecommunications costs, disk access rates.
Scalability Web search services are distributed centralized systems • Over the past 9 years, Moore's Law has enabled the services to keep pace with the growth of the web and the number of users, while adding extra function. • Will this continue? • Possible areas for concern are: staff costs, telecommunications costs, disk access rates.
 Scalability: Performance Very large numbers of commodity computers Algorithms and data structures scale linearly • Storage – Scale with the size of the Web – Compression/decompression • System – Crawling, indexing, sorting simultaneously • Searching – Bounded by disk I/O
Scalability: Performance Very large numbers of commodity computers Algorithms and data structures scale linearly • Storage – Scale with the size of the Web – Compression/decompression • System – Crawling, indexing, sorting simultaneously • Searching – Bounded by disk I/O
 Growth of Google In 2000: 85 people 50% technical, 14 Ph. Ds in Computer Science In 2000: Equipment 2, 500 Linux machines 80 terabytes of spinning disks 30 new machines installed daily A 2005 estimate by Paul Strassmann has 200, 000 servers, while unspecified sources claimed this number to be upwards of 450, 000 in 2006. 2011, 900, 000 servers By fall 2002, Google had grown to over 400 people. In 2004, Google hired 1, 000 new people. 2008, 16, 800 employees, $15 billion in sales => $1 million average earnings/employee 2011, 32, 500 employees, $40 billion in sales 2012, 53, 900 employees, $50 billion in sales
Growth of Google In 2000: 85 people 50% technical, 14 Ph. Ds in Computer Science In 2000: Equipment 2, 500 Linux machines 80 terabytes of spinning disks 30 new machines installed daily A 2005 estimate by Paul Strassmann has 200, 000 servers, while unspecified sources claimed this number to be upwards of 450, 000 in 2006. 2011, 900, 000 servers By fall 2002, Google had grown to over 400 people. In 2004, Google hired 1, 000 new people. 2008, 16, 800 employees, $15 billion in sales => $1 million average earnings/employee 2011, 32, 500 employees, $40 billion in sales 2012, 53, 900 employees, $50 billion in sales
 — Custom Linux-based Web server that Google") Platform Custom Software Google Web Server (GWS) — Custom Linux-based Web server that Google uses for its online services. Storage systems: Google File System and its successor, Colossus Big. Table — structured storage built upon GFS/Colossus Spanner — planet-scale structured storage system, next generation of Big. Table stack Google F 1 — a distributed, quasi-SQL DBMS based on Spanner, substituting a custom version of My. SQL. Chubby lock service Borg — job scheduling and monitoring system Map. Reduce and Sawzall programming language Indexing/search systems: Tera. Google — Google's large search index (launched in early 2006), designed by Anna Paterson of Cuil fame. Caffeine (Percolator) — continuous indexing system (launched in 2010). Private Networks 3 rd largest ISP Data Centers Throughout the world
Platform Custom Software Google Web Server (GWS) — Custom Linux-based Web server that Google uses for its online services. Storage systems: Google File System and its successor, Colossus Big. Table — structured storage built upon GFS/Colossus Spanner — planet-scale structured storage system, next generation of Big. Table stack Google F 1 — a distributed, quasi-SQL DBMS based on Spanner, substituting a custom version of My. SQL. Chubby lock service Borg — job scheduling and monitoring system Map. Reduce and Sawzall programming language Indexing/search systems: Tera. Google — Google's large search index (launched in early 2006), designed by Anna Paterson of Cuil fame. Caffeine (Percolator) — continuous indexing system (launched in 2010). Private Networks 3 rd largest ISP Data Centers Throughout the world
 Scalability: Staff Programming: Have very well trained staff. Isolate complex code. System maintenance: Organize for minimal staff (e. g. , automated log analysis, do not fix broken computers). Customer service: Automate everything possible, but complaints, large collections, etc. require staff.
Scalability: Staff Programming: Have very well trained staff. Isolate complex code. System maintenance: Organize for minimal staff (e. g. , automated log analysis, do not fix broken computers). Customer service: Automate everything possible, but complaints, large collections, etc. require staff.
 of") Evaluation Web Searching Test corpus must be dynamic The web is dynamic (10%-20%) of URLs change every month Spam methods change continually Queries are time sensitive Topic are hot and then not Need to have a sample of real queries New emphasis, 2007, QDF: “query deserves freshness” Languages At least 90 different languages Reflected in cultural and technical differences Amil Singhal, Google, 2004
Evaluation Web Searching Test corpus must be dynamic The web is dynamic (10%-20%) of URLs change every month Spam methods change continually Queries are time sensitive Topic are hot and then not Need to have a sample of real queries New emphasis, 2007, QDF: “query deserves freshness” Languages At least 90 different languages Reflected in cultural and technical differences Amil Singhal, Google, 2004
 Other Uses of Web Crawling and Associated Technology The technology developed for web search services has many other applications. Conversely, technology developed for other Internet applications can be applied in web searching • Related objects (e. g. , Amazon's "Other people bought the following"). • Recommender and reputation systems (e. g. , e. Pinion's reputation system).
Other Uses of Web Crawling and Associated Technology The technology developed for web search services has many other applications. Conversely, technology developed for other Internet applications can be applied in web searching • Related objects (e. g. , Amazon's "Other people bought the following"). • Recommender and reputation systems (e. g. , e. Pinion's reputation system).
 Number of search engine queries - US About half a billion per day Com. Score global share
Number of search engine queries - US About half a billion per day Com. Score global share
 Dec 2012 2 billion internet users
Dec 2012 2 billion internet users

 2012
2012

 Second generation Web search • Ranking using web specific data – HTML tag information – click stream information (Direct. Hit) • people vote with their clicks – directory information (Yahoo! directory) – anchor text – link analysis
Second generation Web search • Ranking using web specific data – HTML tag information – click stream information (Direct. Hit) • people vote with their clicks – directory information (Yahoo! directory) – anchor text – link analysis
 Link Analysis Ranking - Google • Intuition: a link from q to p denotes endorsement – people vote with their links • Popularity count – rank according to the incoming links • Page. Rank algorithm – perform a random walk on the Web graph. The pages visited most often are the ones most important.
Link Analysis Ranking - Google • Intuition: a link from q to p denotes endorsement – people vote with their links • Popularity count – rank according to the incoming links • Page. Rank algorithm – perform a random walk on the Web graph. The pages visited most often are the ones most important.
 Second generation SE performance • Good performance for answering navigational queries – “finding needle in a haystack” • … and informational queries – e. g “oscar winners” • Resistant to text spamming • Generated substantial amount of research • Latest trend: specialized search engines
Second generation SE performance • Good performance for answering navigational queries – “finding needle in a haystack” • … and informational queries – e. g “oscar winners” • Resistant to text spamming • Generated substantial amount of research • Latest trend: specialized search engines
 Result evaluation • recall becomes useless • precision measured over top-10/20 results • Shift of interest from “relevance” to “authoritativeness/reputation” or importance • ranking becomes critical
Result evaluation • recall becomes useless • precision measured over top-10/20 results • Shift of interest from “relevance” to “authoritativeness/reputation” or importance • ranking becomes critical
 What’s coming? • More personal search • Social search • Mobile search • Specialty search • Freshness search 3 rd generation search? Will anyone replace Google? “Search as a problem is only 5% solved” Udi Manber, 1 st Yahoo, 2 nd Amazon, now Google
What’s coming? • More personal search • Social search • Mobile search • Specialty search • Freshness search 3 rd generation search? Will anyone replace Google? “Search as a problem is only 5% solved” Udi Manber, 1 st Yahoo, 2 nd Amazon, now Google
 Are Google rankings fair? Are any search engines rankings fair? • Try out certain queries – “Jew” USA – “Jew” Germany – “tiananmen square” • Google. com • Google. cn • Baidu. com
Are Google rankings fair? Are any search engines rankings fair? • Try out certain queries – “Jew” USA – “Jew” Germany – “tiananmen square” • Google. com • Google. cn • Baidu. com
 What is role of search engines in society • Should these queries be banned? – “how do I make a dirty bomb” – “how do I make a black hole” • Do search engines have a social responsibility?
What is role of search engines in society • Should these queries be banned? – “how do I make a dirty bomb” – “how do I make a black hole” • Do search engines have a social responsibility?
 Social implications of public search engines • What is the web role of search in society – Human flesh search engine – What is the responsibility of search engines? • The googlization of everything • Should governments control search engines – Positions • Search is too important to be left to the private sector • Search will only work from 8 to 5 on weekdays and will be off on holidays. – Restrict Google?
Social implications of public search engines • What is the web role of search in society – Human flesh search engine – What is the responsibility of search engines? • The googlization of everything • Should governments control search engines – Positions • Search is too important to be left to the private sector • Search will only work from 8 to 5 on weekdays and will be off on holidays. – Restrict Google?
 Google vs Bing
Google vs Bing
 Google of the future
Google of the future
 What next? Google. Face or Faceoogle
What next? Google. Face or Faceoogle
 What we covered • Search engines types and business models • Ranking by importance – Link analysis • Citations • Pagerank (query independent; must be combined with a lexical similarity) • Hubs/authorities (query dependent) • Google – Role in search – Architecture • Covered the basics of modern search engines • Search engines are constantly evolving
What we covered • Search engines types and business models • Ranking by importance – Link analysis • Citations • Pagerank (query independent; must be combined with a lexical similarity) • Hubs/authorities (query dependent) • Google – Role in search – Architecture • Covered the basics of modern search engines • Search engines are constantly evolving