

e8bdfb242a9e19d70a3b38a5fa66af09.ppt
- Количество слайдов: 25
 Real-time Storm Surge Modeling in a Grid Environment Howard M. Lander howard@renci. org
Real-time Storm Surge Modeling in a Grid Environment Howard M. Lander howard@renci. org
 SCOOP: A Distributed Laboratory Funded by NOAA & ONR 2005/2006 SCOOP Implementation Team Bedford Institute of Oceanography Gulf of Maine Ocean Observing System Louisiana State University Texas A&M Research Foundation University of Alabama, Huntsville University of Florida University of North Carolina Virginia Institute of Marine Science External Resources e. g. SURAgrid regional grid infrastructure, www. sura. org/suragrid Credits: SCOOP Team Renaissance Computing Institute MCNC Southeastern Universities Research Association
SCOOP: A Distributed Laboratory Funded by NOAA & ONR 2005/2006 SCOOP Implementation Team Bedford Institute of Oceanography Gulf of Maine Ocean Observing System Louisiana State University Texas A&M Research Foundation University of Alabama, Huntsville University of Florida University of North Carolina Virginia Institute of Marine Science External Resources e. g. SURAgrid regional grid infrastructure, www. sura. org/suragrid Credits: SCOOP Team Renaissance Computing Institute MCNC Southeastern Universities Research Association
 Acknowledgements • Funding • SCOOP Partners • SCOOP and SURAGrid resource partners and system administrators – “SURA Coastal Ocean Observing and Prediction (SCOOP) Program”, Office of Naval Research, Award N 00014 -04 -1 -0721, National Oceanic and Atmospheric Administration’s NOAA Ocean Service, Award NA 04 NOS 4730254. – Philip Bogden (SURA and Go. MOOS); Will Perrie, Bash Toulany (BIO); Charlton Purvis, Eric Bridger (Go. MOOS); Greg Stone, Gabrielle Allen, Jon Mac. Laren, Bret Estrada, Chirag Dekate (LSU, Center for Computation and Technology); Gerald Creager, Larry Flournoy, Wei Zhao, Donna Cote and Matt Howard (TAMU); Sara Graves, Helen Conover, Ken Keiser, Matt Smith, and Marilyn Drewry (UAH); Peter Sheng, Justin Davis, Renato Figueiredo, and Vladimir Paramygin (UFL); Harry Wang, Jian Shen and David Forrest (VIMS); Hans Graber, Neil Williams and Geoff Samuels (UMiami); and Mary Fran Yafchak, Kate Barzee, Don Riley, Don Wright and Joanne Bintz (SURA), Rick Luettich (UNC-CH), Brian Blanton(SAIC), Dan Reed, Alan Blatecky, Lavanya Ramakrishnan, Gopi Kandaswamy, Ken Galluppi (RENCI), Steve Thorpe (MCNC) – Steven Johnson (TAMU), Renato J. Figueiredo (UFL), Michael Mc. Eniry (UAH), Ian Chang-Yen (ULL), and Brad Viviano (RENCI), for providing valuable system administrator support
Acknowledgements • Funding • SCOOP Partners • SCOOP and SURAGrid resource partners and system administrators – “SURA Coastal Ocean Observing and Prediction (SCOOP) Program”, Office of Naval Research, Award N 00014 -04 -1 -0721, National Oceanic and Atmospheric Administration’s NOAA Ocean Service, Award NA 04 NOS 4730254. – Philip Bogden (SURA and Go. MOOS); Will Perrie, Bash Toulany (BIO); Charlton Purvis, Eric Bridger (Go. MOOS); Greg Stone, Gabrielle Allen, Jon Mac. Laren, Bret Estrada, Chirag Dekate (LSU, Center for Computation and Technology); Gerald Creager, Larry Flournoy, Wei Zhao, Donna Cote and Matt Howard (TAMU); Sara Graves, Helen Conover, Ken Keiser, Matt Smith, and Marilyn Drewry (UAH); Peter Sheng, Justin Davis, Renato Figueiredo, and Vladimir Paramygin (UFL); Harry Wang, Jian Shen and David Forrest (VIMS); Hans Graber, Neil Williams and Geoff Samuels (UMiami); and Mary Fran Yafchak, Kate Barzee, Don Riley, Don Wright and Joanne Bintz (SURA), Rick Luettich (UNC-CH), Brian Blanton(SAIC), Dan Reed, Alan Blatecky, Lavanya Ramakrishnan, Gopi Kandaswamy, Ken Galluppi (RENCI), Steve Thorpe (MCNC) – Steven Johnson (TAMU), Renato J. Figueiredo (UFL), Michael Mc. Eniry (UAH), Ian Chang-Yen (ULL), and Brad Viviano (RENCI), for providing valuable system administrator support
 Outline • Motivation • Demo Scenario • Grid Technologies – Grid Architecture – Resource Selection • Portlet Tour
Outline • Motivation • Demo Scenario • Grid Technologies – Grid Architecture – Resource Selection • Portlet Tour
 Motivation: Disaster Response • An example close to home: North Carolina – most disasters are weather driven • floods, winds, and ice • Inadequate information – based on national and regional information • High resolution model forecasting for local events – improves planning and preparation – shortens response and recovery time Credits: Ken Galluppi
Motivation: Disaster Response • An example close to home: North Carolina – most disasters are weather driven • floods, winds, and ice • Inadequate information – based on national and regional information • High resolution model forecasting for local events – improves planning and preparation – shortens response and recovery time Credits: Ken Galluppi
 Integrated Response System • Hurricane Season 2005 – 26 named storms, 14 hurricanes, 3 with major impact – billions of dollars economic losses • SURA Coastal Observing and Prediction (SCOOP) Program – provide early and accurate forecasts, dissemination of information – to be able to interact in real-time i. e. evaluate and adapt – provide infrastructure to solve interdisciplinary problems Today …
Integrated Response System • Hurricane Season 2005 – 26 named storms, 14 hurricanes, 3 with major impact – billions of dollars economic losses • SURA Coastal Observing and Prediction (SCOOP) Program – provide early and accurate forecasts, dissemination of information – to be able to interact in real-time i. e. evaluate and adapt – provide infrastructure to solve interdisciplinary problems Today …
 – Finite Element Hydrodynamic Model") ADCIRC: Storm Surge Modeling • Advanced Circulation Model (ADCIRC) – Finite Element Hydrodynamic Model for Coastal Oceans, Inlets, Rivers and Floodplains • Scenarios – Daily operational 24/7/365 forecasts – Real-time ensemble model prediction – Retrospective analysis • Assembling meteorological and other data sets for input – Multiple sources: U. Florida, NCEP, TAMU • Hot-starting the model – NCEP 6 hour operational cycle – previous data is used to jumpstart the model run
ADCIRC: Storm Surge Modeling • Advanced Circulation Model (ADCIRC) – Finite Element Hydrodynamic Model for Coastal Oceans, Inlets, Rivers and Floodplains • Scenarios – Daily operational 24/7/365 forecasts – Real-time ensemble model prediction – Retrospective analysis • Assembling meteorological and other data sets for input – Multiple sources: U. Florida, NCEP, TAMU • Hot-starting the model – NCEP 6 hour operational cycle – previous data is used to jumpstart the model run
 Demo Scenario • Multiple model runs - An ensemble of 11 input files for a single time period. - Plan is to go to 46 members for this year: We need help! - Each member of the ensemble represents a distinct forecast track for the storm. - Multiple model runs for each ensemble member. • Data from Hurricane Katrina August 2005 - Generated on demand at the University of Florida for demo. - Ordinarily generated in response to storm activity in the Atlantic basin. • Portal tracks activity and status in the demo – Status of compute resources – Status of input and output data. – Status of model runs.
Demo Scenario • Multiple model runs - An ensemble of 11 input files for a single time period. - Plan is to go to 46 members for this year: We need help! - Each member of the ensemble represents a distinct forecast track for the storm. - Multiple model runs for each ensemble member. • Data from Hurricane Katrina August 2005 - Generated on demand at the University of Florida for demo. - Ordinarily generated in response to storm activity in the Atlantic basin. • Portal tracks activity and status in the demo – Status of compute resources – Status of input and output data. – Status of model runs.
![Grid Architecture WS-Messenger Broker 11 My. SQL Portal [User initiates a model run] Package](https://present5.com/presentation/e8bdfb242a9e19d70a3b38a5fa66af09/image-9.jpg "Grid Architecture WS-Messenger Broker 11 My. SQL Portal [User initiates a model run] Package") Grid Architecture WS-Messenger Broker 11 My. SQL Portal [User initiates a model run] Package Preparation 5 [Output files] 8. H 1. F NAM UF-WANA LDM NAH . . . [Resource Status] Resource Monitoring Site A [Model Status] 9 1. H [Wind data arrives -forecast] 10 [Prepare the package for the resource] Application Coordinator 8. F [Output files are pushed out] 7 6 [Job finished, Move output files back] [What is the best resource? ] [Get initialization files from archive or run model to generate hotstart file] Visualization Wall Site B [Move the package, initiate the run] 3 2 … Resource Selection 4 [Query site status] Site C
Grid Architecture WS-Messenger Broker 11 My. SQL Portal [User initiates a model run] Package Preparation 5 [Output files] 8. H 1. F NAM UF-WANA LDM NAH . . . [Resource Status] Resource Monitoring Site A [Model Status] 9 1. H [Wind data arrives -forecast] 10 [Prepare the package for the resource] Application Coordinator 8. F [Output files are pushed out] 7 6 [Job finished, Move output files back] [What is the best resource? ] [Get initialization files from archive or run model to generate hotstart file] Visualization Wall Site B [Move the package, initiate the run] 3 2 … Resource Selection 4 [Query site status] Site C
 – standard job submission: Gatekeeper: used to dispatch") Technology Exposition • Grid technologies (Globus) – standard job submission: Gatekeeper: used to dispatch and monitor jobs. – file transfer: Grid. FTP: used to move prepared package to resource and to retrieve results from resource. – queue status: Information Services/MDS: used as an input to the resource selection algorithm and displayed in a portlet. – credential repository: My. Proxy: required for job submission. • Domain products – Local Data Manager (ldm): event driven data transport system: used to receive input files and trigger model runs as well as to insert results. – Open. DAP: format independent network data access protocol.
Technology Exposition • Grid technologies (Globus) – standard job submission: Gatekeeper: used to dispatch and monitor jobs. – file transfer: Grid. FTP: used to move prepared package to resource and to retrieve results from resource. – queue status: Information Services/MDS: used as an input to the resource selection algorithm and displayed in a portlet. – credential repository: My. Proxy: required for job submission. • Domain products – Local Data Manager (ldm): event driven data transport system: used to receive input files and trigger model runs as well as to insert results. – Open. DAP: format independent network data access protocol.
 • Portal Technologies – NSF NMI Open Grid Computing Environment (OGCE): used") Technology Exposition(2) • Portal Technologies – NSF NMI Open Grid Computing Environment (OGCE): used to host the portlets. • Eventing – LEAD WS-Messenger: enables data communication among pieces of the system. Example: the application coordinator sends status information through WS-Messenger. • Web Services – Used to send job and resource status information from a My. SQL database to the portlets. Also used to track flows of data files in the system. • My. SQL – Open source relation database used to store job and resource status information for display and analyses.
Technology Exposition(2) • Portal Technologies – NSF NMI Open Grid Computing Environment (OGCE): used to host the portlets. • Eventing – LEAD WS-Messenger: enables data communication among pieces of the system. Example: the application coordinator sends status information through WS-Messenger. • Web Services – Used to send job and resource status information from a My. SQL database to the portlets. Also used to track flows of data files in the system. • My. SQL – Open source relation database used to store job and resource status information for display and analyses.
 Application Coordinator • Data Management – real-time data movement: LDM, Grid. FTP – previously generated files: SCOOP Catalog [UAH] and archive [TAMU, LSU] • Application Preparation – conversion of data formats – self extracting archive containing binary – identify and retrieve or generate appropriate hotstart files • Extensible – model parameters, template scripts and environment
Application Coordinator • Data Management – real-time data movement: LDM, Grid. FTP – previously generated files: SCOOP Catalog [UAH] and archive [TAMU, LSU] • Application Preparation – conversion of data formats – self extracting archive containing binary – identify and retrieve or generate appropriate hotstart files • Extensible – model parameters, template scripts and environment
 Resource Selection Site A Submit Job Globus Gatekeeper Move self extracting file My. Proxy Globus Grid. FTP Network Weather Service Globus MDS Obtain credential … Job status Site Z Network Weather Service Application Coordinator Move output files Resource Selection My. SQL Globus MDS Globus Gatekeeper Globus Grid. FTP a) Query queue status (free CPUs, length of queue) b) Query bandwidth c) Query current jobs
Resource Selection Site A Submit Job Globus Gatekeeper Move self extracting file My. Proxy Globus Grid. FTP Network Weather Service Globus MDS Obtain credential … Job status Site Z Network Weather Service Application Coordinator Move output files Resource Selection My. SQL Globus MDS Globus Gatekeeper Globus Grid. FTP a) Query queue status (free CPUs, length of queue) b) Query bandwidth c) Query current jobs
 Fault Tolerance and Recovery • Verify correct operation of basic Grid services • Implemented two phase fault recovery – Retry the failed step – Move back one step (e. g. may need to run on different resource) • Proactive Monitoring and notification – Using WS-Messenger and Broker
Fault Tolerance and Recovery • Verify correct operation of basic Grid services • Implemented two phase fault recovery – Retry the failed step – Move back one step (e. g. may need to run on different resource) • Proactive Monitoring and notification – Using WS-Messenger and Broker
 Experiences from 2005 & 2006 • Murphy’s Law – "If anything can go wrong, it will" – debugging is hard • Resource selection – – bandwidth, resource performance, reliability fault tolerance failure recovery • Model specifics – verification of model results Left: ADCIRC max water level for 72 hr forecast starting 29 Aug 2005, driven by the "usual, alwaysavailable” ETA winds. Right: ADCIRC max water level over ALL of UFL ensemble wind fields for 72 hr forecast starting 29 Aug 2005, driven by “UFL always-available” ETA winds. Images credit: Brian O. Blanton, SAIC
Experiences from 2005 & 2006 • Murphy’s Law – "If anything can go wrong, it will" – debugging is hard • Resource selection – – bandwidth, resource performance, reliability fault tolerance failure recovery • Model specifics – verification of model results Left: ADCIRC max water level for 72 hr forecast starting 29 Aug 2005, driven by the "usual, alwaysavailable” ETA winds. Right: ADCIRC max water level over ALL of UFL ensemble wind fields for 72 hr forecast starting 29 Aug 2005, driven by “UFL always-available” ETA winds. Images credit: Brian O. Blanton, SAIC
 Conclusions and Future Work • Foundation for a highly reliable distributed Grid environment for critical applications • Upgrade path to OGCE 2 and Globus 4. 0 – Early work has been done to port to OGCE 2 – Use Globus 4. 0 MDS triggering • Application to other environments – North Carolina Forecasting System – Package standard web services for resource selection and fault tolerant application coordination • More sophisticated resource selection – Use historical and data from concurrent runs to make selections.
Conclusions and Future Work • Foundation for a highly reliable distributed Grid environment for critical applications • Upgrade path to OGCE 2 and Globus 4. 0 – Early work has been done to port to OGCE 2 – Use Globus 4. 0 MDS triggering • Application to other environments – North Carolina Forecasting System – Package standard web services for resource selection and fault tolerant application coordination • More sophisticated resource selection – Use historical and data from concurrent runs to make selections.
 Portal Tour https: //portal. scoop. sura. org/gridsphere End of talk!
Portal Tour https: //portal. scoop. sura. org/gridsphere End of talk!
 More Information • SCOOP – http: //scoop. sura. org • RENCI Projects – NCFS http: //www. renci. org/projects/indexdr. php – SCOOP http: //www. renci. org/projects/scoop. php http: //www. scoop. unc. edu • SURAGrid – https: //gridportal. sura. org/
More Information • SCOOP – http: //scoop. sura. org • RENCI Projects – NCFS http: //www. renci. org/projects/indexdr. php – SCOOP http: //www. renci. org/projects/scoop. php http: //www. scoop. unc. edu • SURAGrid – https: //gridportal. sura. org/
 Design Principles • Scalable real-time system – multiple large scale simulations in parallel – based on Grid technologies and standards • Modular, Extensible – apply in context of other domains • Adaptable – criticality of the application – variability in grid environments • Framework – real-time discovery of available resources – managing the model run on an ad-hoc set of resources – continuous monitoring and adaptation • active monitoring, fault tolerance, failure recovery
Design Principles • Scalable real-time system – multiple large scale simulations in parallel – based on Grid technologies and standards • Modular, Extensible – apply in context of other domains • Adaptable – criticality of the application – variability in grid environments • Framework – real-time discovery of available resources – managing the model run on an ad-hoc set of resources – continuous monitoring and adaptation • active monitoring, fault tolerance, failure recovery
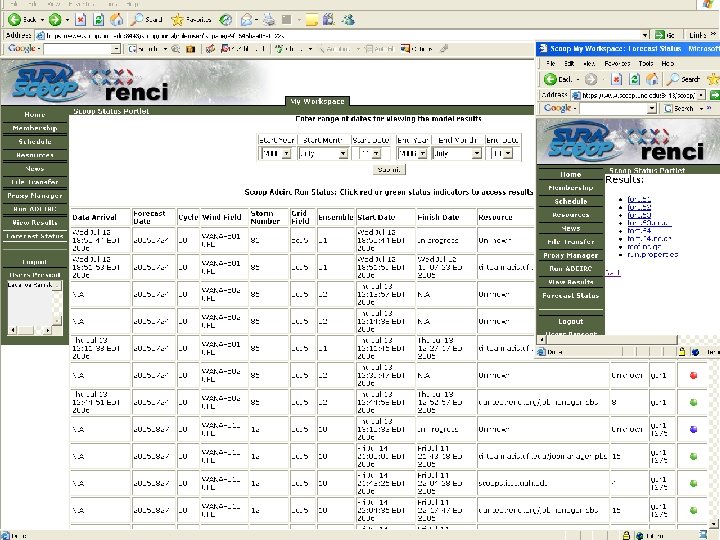
 Portal: Monitoring
Portal: Monitoring
 Resource Pool Management • Resources – Local: RENCI, MCNC – SURAGrid: TAMU, ULL, etc – SCOOP Partners: UAH, UFL • Software – Globus Services – Grid. FTP, GRAM, MDS – NWS • Configuration – Resources Expansion using property files – Automated test suite to check periodically
Resource Pool Management • Resources – Local: RENCI, MCNC – SURAGrid: TAMU, ULL, etc – SCOOP Partners: UAH, UFL • Software – Globus Services – Grid. FTP, GRAM, MDS – NWS • Configuration – Resources Expansion using property files – Automated test suite to check periodically
 Portal: Hindcast Mode Select Run Dates And Model Details
Portal: Hindcast Mode Select Run Dates And Model Details

