

8700da13b88db4a383b22800a2c381b4.ppt
- Количество слайдов: 93
 Real Time Gesture Recognition of Human Hand Wu Hai Atid Shamaie Alistair Sutherland
Real Time Gesture Recognition of Human Hand Wu Hai Atid Shamaie Alistair Sutherland
 Overview: • What are gestures? • What can gestures be used for? • How to find a hand in an image? • How to recognise its shape? • How to recognise its motion? • How to find its position in 3 D space?
Overview: • What are gestures? • What can gestures be used for? • How to find a hand in an image? • How to recognise its shape? • How to recognise its motion? • How to find its position in 3 D space?
 What is Gesture? A movement of a limb or the body as an expression of thought or feeling. --Oxford Concise Dictionary 1995
What is Gesture? A movement of a limb or the body as an expression of thought or feeling. --Oxford Concise Dictionary 1995
 Mood, emotion • Mood and emotion are expressed by body language • Facial expressions • Tone of voice • Allows computers to interact with human beings in a more natural way
Mood, emotion • Mood and emotion are expressed by body language • Facial expressions • Tone of voice • Allows computers to interact with human beings in a more natural way
 Human Computer Interface using Gesture • • Replace mouse and keyboard Pointing gestures Navigate in a virtual environment Pick up and manipulate virtual objects Interact with a 3 D world No physical contact with computer Communicate at a distance
Human Computer Interface using Gesture • • Replace mouse and keyboard Pointing gestures Navigate in a virtual environment Pick up and manipulate virtual objects Interact with a 3 D world No physical contact with computer Communicate at a distance
 Public Display Screens • • Information display screens Supermarkets Post Offices, Banks Allows control without having to touch the device
Public Display Screens • • Information display screens Supermarkets Post Offices, Banks Allows control without having to touch the device
 Sign Language • 5000 gestures in vocabulary • each gesture consists of a hand shape, a hand motion and a location in 3 D space • facial expressions are important • full grammar and syntax • each country has its own Sign language • Irish Sign Language is different from British Sign Language or American Sign Language
Sign Language • 5000 gestures in vocabulary • each gesture consists of a hand shape, a hand motion and a location in 3 D space • facial expressions are important • full grammar and syntax • each country has its own Sign language • Irish Sign Language is different from British Sign Language or American Sign Language
 A C F
A C F
 Datagloves
Datagloves
 Datagloves • Datagloves provide very accurate measurements of hand-shape • But are cumbersome to wear • Expensive • Connected by wires- restricts freedom of movement
Datagloves • Datagloves provide very accurate measurements of hand-shape • But are cumbersome to wear • Expensive • Connected by wires- restricts freedom of movement
 Datagloves - the future • Will get lighter and more flexible • Will get cheaper ~ $100 • Wireless?
Datagloves - the future • Will get lighter and more flexible • Will get cheaper ~ $100 • Wireless?
 • Our vision-based system Wireless & Flexible No specialised hardware Single Camera Real-time
• Our vision-based system Wireless & Flexible No specialised hardware Single Camera Real-time
 Coloured Gloves • • • User must wear coloured gloves Very cheap Easy to put on BUT get dirty Eventually we wish to use natural skin
Coloured Gloves • • • User must wear coloured gloves Very cheap Easy to put on BUT get dirty Eventually we wish to use natural skin
 Colour Segment Noise Removal 32 32 Scale by Area
Colour Segment Noise Removal 32 32 Scale by Area
 Demo • Gesture Video
Demo • Gesture Video
 Feature Space Each point represents a different image Clusters of points represent different hand-shapes Distance between points depends on how similar the images are
Feature Space Each point represents a different image Clusters of points represent different hand-shapes Distance between points depends on how similar the images are
 A continuous gesture creates a trajectory in feature space We can project a new image onto the trajectory
A continuous gesture creates a trajectory in feature space We can project a new image onto the trajectory
 Multiple sub-spaces Classifying a new unknown image Gesture 2 Gesture 1 Global space
Multiple sub-spaces Classifying a new unknown image Gesture 2 Gesture 1 Global space
 3 D spatial position of hand y x camera Subspaces and trajectories calculated with hand at origin We know the image co-ordinates and the area of the hand in the original image We can calculate depth and xy-position
3 D spatial position of hand y x camera Subspaces and trajectories calculated with hand at origin We know the image co-ordinates and the area of the hand in the original image We can calculate depth and xy-position
 Yes/No? A B C Yes/No? Y
Yes/No? A B C Yes/No? Y
 Hierarchical Search • We need to search thousands of images • How to do this efficiently? • We need to use a “coarse-to-fine”search strategy
Hierarchical Search • We need to search thousands of images • How to do this efficiently? • We need to use a “coarse-to-fine”search strategy
 Original image Blurring Factor = 3 Blurring Factor = 1 Blurring Factor = 2
Original image Blurring Factor = 3 Blurring Factor = 1 Blurring Factor = 2
 • Multi-scale Hierarchy Factor = 3. 0 Factor = 2. 0 Factor = 1. 0
• Multi-scale Hierarchy Factor = 3. 0 Factor = 2. 0 Factor = 1. 0
 --- time sequence of images") Motion Recognition • Hidden Markov Model ( HMM ) --- time sequence of images modeling f P(f |HMM 1) P(f |HMM 2) HMM 1 (Hello) HMM 2 (Good) HMM 3(Bad) HMM 4 (House)
Motion Recognition • Hidden Markov Model ( HMM ) --- time sequence of images modeling f P(f |HMM 1) P(f |HMM 2) HMM 1 (Hello) HMM 2 (Good) HMM 3(Bad) HMM 4 (House)
 Prediction and Tracking • Given previous frames we can predict what will happen next • Speeds up search. • occlusions -
Prediction and Tracking • Given previous frames we can predict what will happen next • Speeds up search. • occlusions -
 Co-articulation In fluent dialogue signs are modified by preceding and following signs A intermediate forms B
Co-articulation In fluent dialogue signs are modified by preceding and following signs A intermediate forms B
 • Grammars in Irish Sign Language. --- Sentence Recognition") Future Work: • Occlusions (Atid) • Grammars in Irish Sign Language. --- Sentence Recognition • Body Language.
Future Work: • Occlusions (Atid) • Grammars in Irish Sign Language. --- Sentence Recognition • Body Language.
 Face Recognition
Face Recognition
 A noisy environment
A noisy environment
 Errors
Errors
 Model-based Recognition
Model-based Recognition
 Pose-tracking
Pose-tracking
 Facial Expressions Anger Fear Disgust Happy Sad Surprise
Facial Expressions Anger Fear Disgust Happy Sad Surprise
 Human Body Tracking
Human Body Tracking
 Face Recognition • Summary – Single pose – Multiple pose – Principal components analysis – Model-based recognition – Neural Networks
Face Recognition • Summary – Single pose – Multiple pose – Principal components analysis – Model-based recognition – Neural Networks
 Single Pose • Standard head-and-shoulders view with uniform background • Easy to find face within image
Single Pose • Standard head-and-shoulders view with uniform background • Easy to find face within image
 Aligning Images Alignment – Faces in the training set must be aligned with each other to remove the effects of translation, scale, rotation etc. – It is easy to find the position of the eyes and mouth and then shift and resize images so that are aligned with each other
Aligning Images Alignment – Faces in the training set must be aligned with each other to remove the effects of translation, scale, rotation etc. – It is easy to find the position of the eyes and mouth and then shift and resize images so that are aligned with each other
 Nearest Neighbour • Once the images have been aligned you can simply search for the member of the training set which is nearest to the test image. • There a number of measures of distance including Euclidean distance, and the crosscorrelation
Nearest Neighbour • Once the images have been aligned you can simply search for the member of the training set which is nearest to the test image. • There a number of measures of distance including Euclidean distance, and the crosscorrelation
 Principal Components • PCA reduces the number of dimensions and so the memory requirement is much reduced. • The search time is also reduced
Principal Components • PCA reduces the number of dimensions and so the memory requirement is much reduced. • The search time is also reduced
 • We could apply PCA to the whole") Two ways to apply PCA (1) • We could apply PCA to the whole training set. • Then each face is represented by a point in the PC space • We could then apply nearest neighbour to these points
Two ways to apply PCA (1) • We could apply PCA to the whole training set. • Then each face is represented by a point in the PC space • We could then apply nearest neighbour to these points
 • Alternatively we could apply PCA to the") Two ways to apply PCA (2) • Alternatively we could apply PCA to the set of faces belonging to each person in the training set • Each class (person) is then reprented by a different ellipsoid and Mahalanobis distance can be used to classify a new unknown face • You need a lot of images of each person to do this
Two ways to apply PCA (2) • Alternatively we could apply PCA to the set of faces belonging to each person in the training set • Each class (person) is then reprented by a different ellipsoid and Mahalanobis distance can be used to classify a new unknown face • You need a lot of images of each person to do this
 Problems with PCA • The same person may sometimes appear differently due to – Beards, moustaches – Glasses, – Makeup • These have to be represented by different ellipsoids
Problems with PCA • The same person may sometimes appear differently due to – Beards, moustaches – Glasses, – Makeup • These have to be represented by different ellipsoids
-------(3)-------(4)------- -------(5)-------(6)-------(7)------- -------(8)-------(9)-------(10)-------") -------(2)-------(3)-------(4)------- -------(5)-------(6)-------(7)------- -------(8)-------(9)-------(10)-------
-------(2)-------(3)-------(4)------- -------(5)-------(6)-------(7)------- -------(8)-------(9)-------(10)-------
 Problems with PCA • Facial expressions – Differing facial expressions • • Opening and closing the mouth Raised eyebrows Widening the eyes Smiling, frowing etc, • These mean that the class is no longer ellipsoidal and must be represented by a manifold
Problems with PCA • Facial expressions – Differing facial expressions • • Opening and closing the mouth Raised eyebrows Widening the eyes Smiling, frowing etc, • These mean that the class is no longer ellipsoidal and must be represented by a manifold
 Facial Expressions Anger Fear Disgust Happy Sad Surprise • There are six types of facial expression • We could use PCA on the eyes and mouth – so we could have eigeneyes and eigenmouths
Facial Expressions Anger Fear Disgust Happy Sad Surprise • There are six types of facial expression • We could use PCA on the eyes and mouth – so we could have eigeneyes and eigenmouths
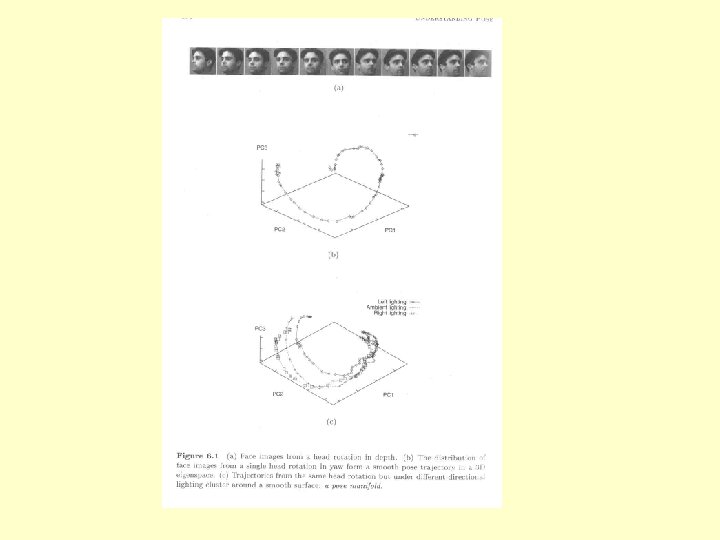
 Multiple Poses • Heads must now be aligned in 3 D world space • Classes now form trajectories in feature space • It becomes difficult to recognise faces because the variation due to pose is greater than the variation between people
Multiple Poses • Heads must now be aligned in 3 D world space • Classes now form trajectories in feature space • It becomes difficult to recognise faces because the variation due to pose is greater than the variation between people

 Model-based Recognition • We can fit a model directly to the face image • Model consists of a mesh which is matched to facial features such as the eyes, nose, mouth and edges of the face. • We use PCA to describe the parameters of the model rather than the pixels.
Model-based Recognition • We can fit a model directly to the face image • Model consists of a mesh which is matched to facial features such as the eyes, nose, mouth and edges of the face. • We use PCA to describe the parameters of the model rather than the pixels.
 Model-based Recognition • The model copes better with multiple poses and changes in facial expression.
Model-based Recognition • The model copes better with multiple poses and changes in facial expression.
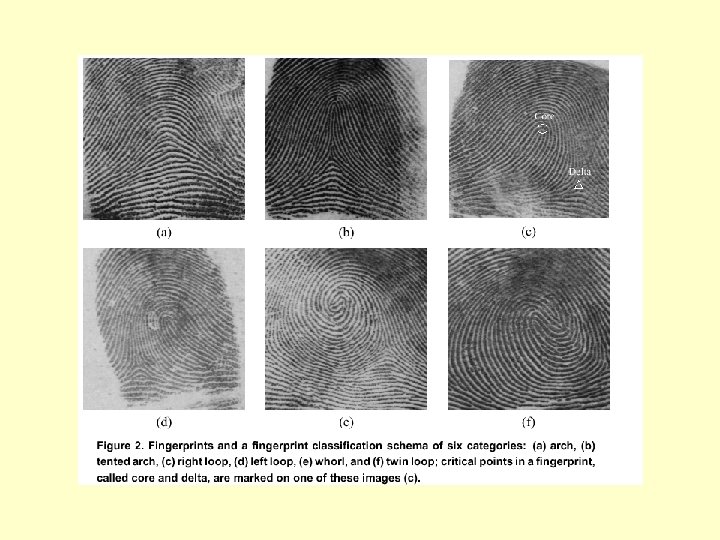
 Coarse Classification • Fingerprints can be divided into 6 basic classes (some systems use other classes) – Arch – Tented Arch – Whorl – Right loop – Left Loop – Double Loop
Coarse Classification • Fingerprints can be divided into 6 basic classes (some systems use other classes) – Arch – Tented Arch – Whorl – Right loop – Left Loop – Double Loop

 Orientation Field • The orientation field gives the ridge direction at each point in the image
Orientation Field • The orientation field gives the ridge direction at each point in the image
 Identifying Core and Delta • The orientation field can be used to identify the core and delta in an image
Identifying Core and Delta • The orientation field can be used to identify the core and delta in an image
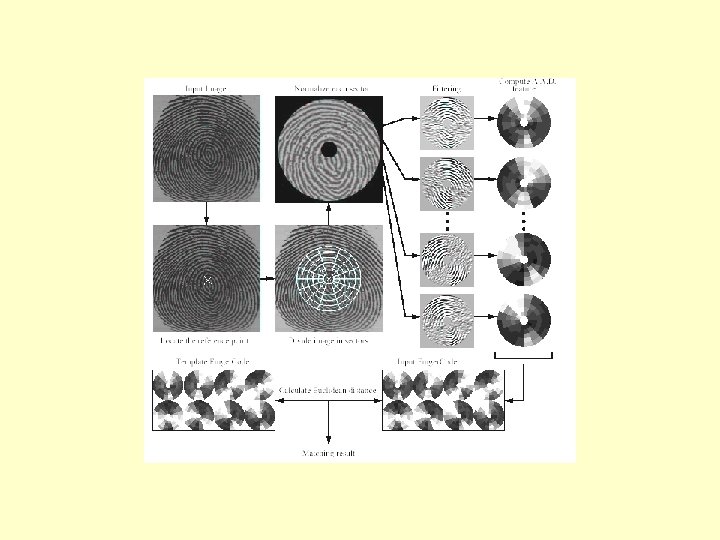
 PCA applied to fingerprints • We can align different images so that their cores line up • We can then apply PCA to the orientation fields just as we did to face images • We can project a new unknown image into the PC space and find the nearest matches in the training set.
PCA applied to fingerprints • We can align different images so that their cores line up • We can then apply PCA to the orientation fields just as we did to face images • We can project a new unknown image into the PC space and find the nearest matches in the training set.
 Accurate Matching • Orientation fields and PCA are not good enough to give an accurate match • They can reduce the number of possible candidates • We can then apply a more accurate but time -consuming technique to the remaining candidate images
Accurate Matching • Orientation fields and PCA are not good enough to give an accurate match • They can reduce the number of possible candidates • We can then apply a more accurate but time -consuming technique to the remaining candidate images
 Minutiae Matching • Minutiae are fine details of the ridges in the fingerprint image such as – Ridge terminations, – Crossovers – Bifurcations etc. • The pattern of minutiae is unique to each individual person
Minutiae Matching • Minutiae are fine details of the ridges in the fingerprint image such as – Ridge terminations, – Crossovers – Bifurcations etc. • The pattern of minutiae is unique to each individual person
 Minutiae Types • Different systems define different types of minutiae • The most common are terminations (ridge endings) and bifurcations(forks)
Minutiae Types • Different systems define different types of minutiae • The most common are terminations (ridge endings) and bifurcations(forks)
 Binarisation and Thinning • Binarisation – Every pixel is set to either 0 or 1 • Thinning – Lines are thinned to a width of 1 pixel
Binarisation and Thinning • Binarisation – Every pixel is set to either 0 or 1 • Thinning – Lines are thinned to a width of 1 pixel
 Identifying minutiae • Each black pixel in the image is classified using its “crossing number”. • The crossing number of pixel p is defined as: cn(p)= Half the sum of the differences between adjacent pixels in the 8 neighbourhood of p
Identifying minutiae • Each black pixel in the image is classified using its “crossing number”. • The crossing number of pixel p is defined as: cn(p)= Half the sum of the differences between adjacent pixels in the 8 neighbourhood of p
 Identifying Minutiae • If the crossing number cn is equal to 2 then the pixel is not a minutia but a normal intraridge pixel • If the crossing number is not equal to 2 then the pixel is some kind of minutia
Identifying Minutiae • If the crossing number cn is equal to 2 then the pixel is not a minutia but a normal intraridge pixel • If the crossing number is not equal to 2 then the pixel is some kind of minutia

 Removing false-minutiae
Removing false-minutiae
 Minutiae on a real image • The position of the minutiae is marked • The direction of the ridge at each minutia is shown as a short line
Minutiae on a real image • The position of the minutiae is marked • The direction of the ridge at each minutia is shown as a short line
 Matching minutiae between fingerprints • We now have to compare minutiae between two different fingerprints to see if they came from the same person • Remember the two images may have been rotated, translated or distorted with respect to one another • We have to find the combination of rotations, translations and distortions which gives the largest number of matched pairs of minutiae
Matching minutiae between fingerprints • We now have to compare minutiae between two different fingerprints to see if they came from the same person • Remember the two images may have been rotated, translated or distorted with respect to one another • We have to find the combination of rotations, translations and distortions which gives the largest number of matched pairs of minutiae
 Two different impressions of the same finger
Two different impressions of the same finger
 Matched pairs of minutiae • Each pair must match position, direction and type
Matched pairs of minutiae • Each pair must match position, direction and type
 Hough Transform • Discretise the range of values for translation, rotation and distortion • Set up an accumulator matrix A in which each element represents a different combination of translation, rotation and distortion • For each possible pair of minutiae calculate the best values of translation, rotation and distortion which makes them match • Increase the corresponding element of A by 1 • At the end of the process the element of A with the largest value represents the best combination
Hough Transform • Discretise the range of values for translation, rotation and distortion • Set up an accumulator matrix A in which each element represents a different combination of translation, rotation and distortion • For each possible pair of minutiae calculate the best values of translation, rotation and distortion which makes them match • Increase the corresponding element of A by 1 • At the end of the process the element of A with the largest value represents the best combination
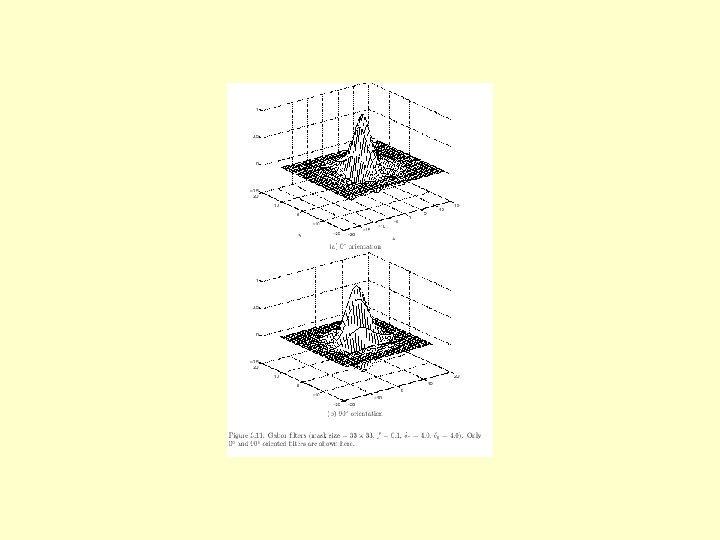
 An alternative to minutiaematching • Finger. Codes – 1. Centre image on core – 2. Divide image into circular zones – 3. Pass each zone through a set of 8 Gabor filters (more about this next week) – 4. Compare the results using Euclidean distance
An alternative to minutiaematching • Finger. Codes – 1. Centre image on core – 2. Divide image into circular zones – 3. Pass each zone through a set of 8 Gabor filters (more about this next week) – 4. Compare the results using Euclidean distance
 Iris Recognition
Iris Recognition
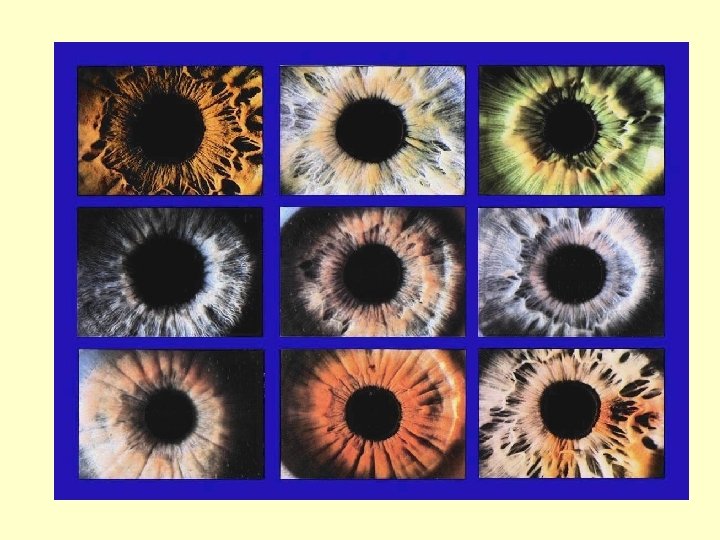
 John Daugman • There is only one iris recognition algorithm in use • The algorithm was developed mainly by John Daugman, Ph. D, OBE • www. CL. cam. ac. uk/users/jgd 1000/ • It is owned by the company Iridian Technologies
John Daugman • There is only one iris recognition algorithm in use • The algorithm was developed mainly by John Daugman, Ph. D, OBE • www. CL. cam. ac. uk/users/jgd 1000/ • It is owned by the company Iridian Technologies
 Advantages of Iris Recognition • Irises do not change with age – unlike faces • Irises do not suffer from scratches, abrasions, grease or dirt – unlike fingerprints • Irises do not suffer from distortion – unlike fingerprints
Advantages of Iris Recognition • Irises do not change with age – unlike faces • Irises do not suffer from scratches, abrasions, grease or dirt – unlike fingerprints • Irises do not suffer from distortion – unlike fingerprints
 Finding the Iris in the Image • It is easy to find the circular boundaries of the iris
Finding the Iris in the Image • It is easy to find the circular boundaries of the iris
 Masking • The boundaries of the eyelids can be found • Eyelashes and specularities (reflections) can be found • These areas can be masked out
Masking • The boundaries of the eyelids can be found • Eyelashes and specularities (reflections) can be found • These areas can be masked out
 Gabor Wavelets
Gabor Wavelets
 Gabor Wavelets • Gabor Wavelets filter out structures at different scales and orientations • For each scale and orientation there is a pair of odd and even wavelets • A scalar product is carried out between the wavelet and the image (just as in the Discrete Fourier Transform) • The result is a complex number
Gabor Wavelets • Gabor Wavelets filter out structures at different scales and orientations • For each scale and orientation there is a pair of odd and even wavelets • A scalar product is carried out between the wavelet and the image (just as in the Discrete Fourier Transform) • The result is a complex number
 Phase Demodulation • The complex number is converted to 2 bits • The modulus is thrown away because it is sensitive to illumination intensity • The phase is converted to 2 bits depending on which quadrant it is in
Phase Demodulation • The complex number is converted to 2 bits • The modulus is thrown away because it is sensitive to illumination intensity • The phase is converted to 2 bits depending on which quadrant it is in
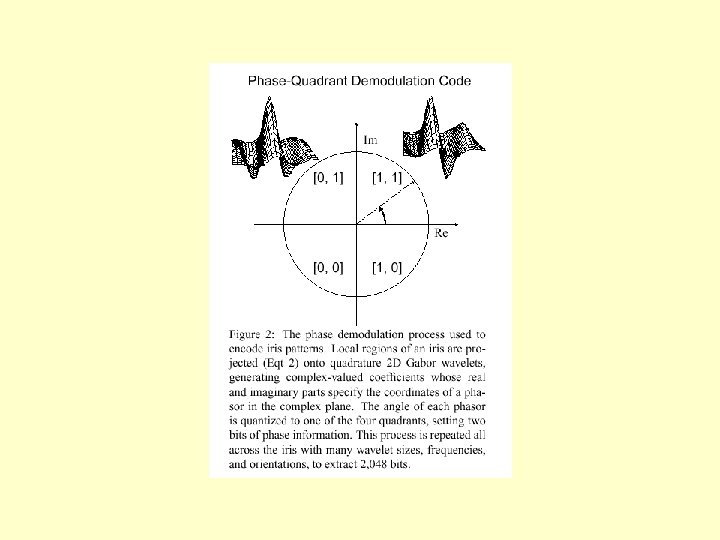
 Iris. Codes • This process is carried out at a number of points throughout the image. • The result is 2048 bits which describe each iris uniquely • Two codes from different irises can be compared by finding the number of bits different between them – this is called the Hamming distance • This is equivalent to computing an XOR between the two codes. This can be done very quickly • To allow for rotation of the iris images the codes can be shifted with respect to each other and the minimum Hamming distance found
Iris. Codes • This process is carried out at a number of points throughout the image. • The result is 2048 bits which describe each iris uniquely • Two codes from different irises can be compared by finding the number of bits different between them – this is called the Hamming distance • This is equivalent to computing an XOR between the two codes. This can be done very quickly • To allow for rotation of the iris images the codes can be shifted with respect to each other and the minimum Hamming distance found
 Hamming Distance
Hamming Distance
 Binomial Distribution • If two codes come from different irises the different bits will be random • The number of different bits will obey a binomial distribution with mean 0. 5
Binomial Distribution • If two codes come from different irises the different bits will be random • The number of different bits will obey a binomial distribution with mean 0. 5
 Identification • If two codes come from the same iris the differences will no longer be random • The Hamming distance will be less than expected than if the differences were random • If the Hamming distance is < 0. 33 the chances of the two codes coming from different irises is 1 in 2. 9 million • So far it has been tried out on 2. 3 million people without a single error
Identification • If two codes come from the same iris the differences will no longer be random • The Hamming distance will be less than expected than if the differences were random • If the Hamming distance is < 0. 33 the chances of the two codes coming from different irises is 1 in 2. 9 million • So far it has been tried out on 2. 3 million people without a single error
 More Advantages of Iris. Codes • Iris. Codes are extremely accurate • Matching is very fast compared to fingerprints or faces • Memory requirments are very low – only 2048 bits per iris
More Advantages of Iris. Codes • Iris. Codes are extremely accurate • Matching is very fast compared to fingerprints or faces • Memory requirments are very low – only 2048 bits per iris
 to acquire from") Disadvantages of the Iris for Identification • Small target (1 cm) to acquire from a distance (1 m) • Moving target. . . within another. . . on yet another • Located behind a curved, wet, reflecting surface • Obscured by eyelashes, lenses, reflections • Partially occluded by eyelids, often drooping • Deforms non-elastically as pupil changes size • Illumination should not be visible or bright • Some negative (Orwellian) connotations
Disadvantages of the Iris for Identification • Small target (1 cm) to acquire from a distance (1 m) • Moving target. . . within another. . . on yet another • Located behind a curved, wet, reflecting surface • Obscured by eyelashes, lenses, reflections • Partially occluded by eyelids, often drooping • Deforms non-elastically as pupil changes size • Illumination should not be visible or bright • Some negative (Orwellian) connotations
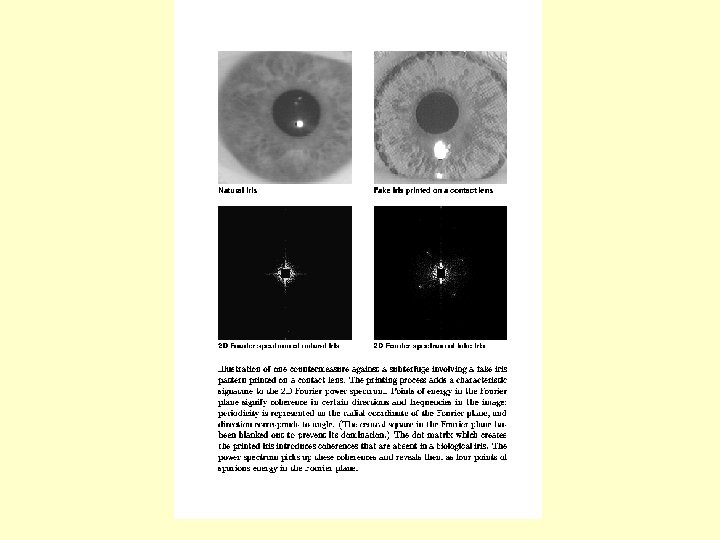
 Fake Iris Attacks
Fake Iris Attacks
 Fake Iris Fourier Spectrum • Due to the dot matrix grid the Fourier Spectrum of the fake iris has 4 extra points
Fake Iris Fourier Spectrum • Due to the dot matrix grid the Fourier Spectrum of the fake iris has 4 extra points

