Лекция_7t_арх_соврем_проц2.ppt
- Количество слайдов: 19


 Порты")
Пункт резервирования (буферы) Порты

МОПы отправляются на исполнение через так называемые порты запуска. Всего таких портов пять: два для арифметико-логических операций, и три — для операций вычисления адресов и для загрузки/выгрузки. К каждому из портов подсоединены соответствующие функциональные устройства. Порт 0 обслуживает устройства целочисленной арифметики и логики, включая блоки для выполнения умножения и деления, а также устройства арифметики с плавающей точкой x 87 и устройство умножения SSE. К порту 1 подсоединено другое устройство целочисленной арифметики и логики, частично дублирующее аналогичное на порту 0, устройство для выполнения переходов, а также устройства сложения и некоторых дополнительных операций SSE. Начиная с процессора P-M, операции умножения и сложения с плавающей точкой x 87 разнесены по разным портам (по аналогии с операциями SSE): умножение осталось на порту 0, а сложение переведено на порт 1. Также добавлены операции SSE 2 с аналогичным распределением между портами.

К портам 2 и 3 подсоединены устройства вычисления адресов для операций загрузки из памяти и выгрузки в память, а К порту 4 —устройство выгрузки, готовящее данные для отсылки в память. В процессоре P-III при декодировании инструкций загрузки из памяти с последующим исполнением (Load-Op) порождаются отдельные МОПы для загрузки и для выполнения. Оба этих МОПа помещаются в буфер переупорядочения ROB и в очередь планировщика RS и обслуживаются по отдельности. Начиная с процессора P-M, в декодере реализован механизм «слияния микроопераций» (micro-ops fusion), когда порождается единый МОП, содержащий два элементарных действия. Разделение на эти элементарные действия, или микрооперации, происходит при их запуске на исполнение (диспетчеризации) из очереди планировщика. Сначала запускается микрооперация загрузки (через порт 2), а затем, в преддверии готовности операнда — функциональная микрооперация (через порт 0 или 1). Аналогично операциям загрузки, для инструкций выгрузки в память в процессоре P-III также порождаются два отдельных МОПа: для вычисления адреса, и для осуществления записи. Эти МОПы запускаются (диспетчеризуются) по отдельности, соответственно через порты 3 и 4. Начиная с процессора P-M, для инструкций выгрузки порождается единый МОП, который разделяется на микрооперации при запуске на исполнение.
, имеющих")
Механизм слияния микроопераций позволяет экономить ресурсы буферов внеочередного исполнения (ROB и RS), имеющих ограниченный размер, и увеличить эффективную пропускную способность трактов процессора. Этот механизм слияния похож на аналогичный механизм в процессорах AMD K 7/K 8, когда любой МОП может содержать в себе как операцию загрузки из памяти (выгрузки в память), так и функциональное действие.

Intel Pentium 4 После считывания из T-кэша группы по три МОПа помещаются в буфер переупорядочения ROB, длина которого составляет 126 элементов. Новая группа МОПов также копируется в очереди планировщика для последующей отправки на исполнение. Очереди планировщика в процессоре P-4 выполнены в виде двухуровневой структуры. Сначала МОПы распределяются по двум предварительным очередям. В одну очередь помещаются МОПы операций загрузки и выгрузки, требующих вычисления адреса для обращения в память, в другую — обычные МОПы. Выборка МОПов из этих очередей и передача их на следующие этапы обработки может осуществляться с разной скоростью, что позволяет, например, начать обрабатывать МОПы обращения к памяти раньше, чем МОПы обычных операций. Таким образом, эти две очереди выполняют амортизирующую функцию перед помещением МОПов в очереди, которые привязаны к функциональным устройствам и из которых операции отсылаются на исполнение

Очередь для операций обращения к памяти Очередь для обычных операций Запускае мых в удвоенн ом темпе Запускае мых в обычном темпе Устройство целочисленной арифметики и логики Запускае мых в удвоенн ом темпе Запускае мых в обычном темпе Устройство целочислен ной арифметик и и логики очередь для операций загрузки и выгрузки Устройство загрузки из вычисления памяти адресов для операций выгрузки в память.

Всего таких очередей пять: две очереди для операций, запускаемых в удвоенном темпе (Fast 0 и Fast 1), две очереди для операций, запускаемых в обычном темпе (Slow 0 и Slow 1), очередь для операций загрузки и выгрузки. Первые четыре очереди соединены с предварительной (амортизирующей) очередью для обычных операций, последняя — с предварительной очередью для операций обращения к памяти.

По мере готовности операндов МОПы из этих очередей отправляются на исполнение в соответствующие функциональные устройства. Отправка операций происходит через так называемые порты запуска. К порту 0 подсоединены очереди Fast 0 и Slow 0, к порту 1 — очереди Fast 1 и Slow 1, к портам 2 и 3 — очередь для операций загрузки и выгрузки. Через порты 0 и 1 могут запускаться на исполнение по две операции в каждом такте (в начале такта — из очереди Slow либо Fast, в середине такта — только из очереди Fast). Таким образом, всего в каждом такте на исполнение может быть отправлено до шести операций. Это вдвое превышает темп поступления операций из T-кэша и темп отставки операций (по три МОПа за такт). К порту 0 подсоединены функциональное устройство целочисленной арифметики и логики, работающее в удвоенном темпе, а также устройство, выполняющее операции пересылок и выгрузки в память для арифметики с плавающей точкой. Порт 1 обслуживает целочисленное устройство с удвоенным темпом работы, частично дублирующее аналогичное устройство на порту 0 и выполняющее операции сложения/вычитания и копирования, а также устройство сдвигов и основное устройство плавающей арифметики, выполняющее арифметические операции x 87, MMX и SSE. К порту 2 подсоединено устройство загрузки из памяти, К порту 3 — устройство вычисления адресов для операций выгрузки в память.
 Общая организация подсистемы внеочередного исполнения операций и функциональных устройств в")
Intel Core (P 8) Общая организация подсистемы внеочередного исполнения операций и функциональных устройств в новом процессоре P 8 напоминает организацию этой подсистемы в процессорах семейства P 6/P 6+ (P-III, P-M, P -M 2) и представляет собой её дальнейшее развитие. Главное отличие от последних представителей старого семейства (P-M и P-M 2) состоит в: расширении всех трактов обработки МОПов с трёх до четырёх, удлинении очередей и буферов, увеличении числа портов запуска и функциональных устройств и в существенном повышении скорости работы функциональных устройств плавающей арифметики SSE, в реализации 64 -битного режима EM 64 T (x 86 -64) для целочисленной и адресной арифметики.

После выхода из декодера сформированные группы по четыре МОПа помещаются в буфер переупорядочения ROB, длина которого составляет (по некоторым данным) 96 элементов. Новая группа МОПов также копируется в очередь планировщика RS, из которой операции будут запускаться на исполнение. В процессоре P 8 используется единая очередь планировщика размером в 32 элемента, общая для всех типов операций. МОПы выбираются на исполнение из этой очереди во внеочередном порядке, по мере готовности аргументов операций
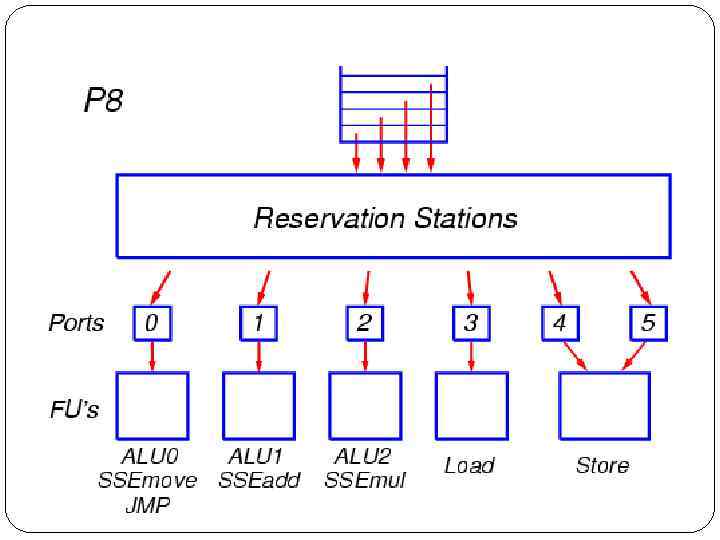

МОПы отправляются на исполнение через порты запуска. Всего имеется три порта для арифметико-логических операций три — для операций вычисления адресов и для загрузки/выгрузки. Каждый из портов обслуживает соответствующие функциональные устройства и может запускать по одной операции за такт. К каждому из трёх первых портов подсоединены устройства, выполняющие операции целочисленной арифметики и логики, а также некоторые операции MMX и SSE. Самые простые операции могут исполняться в устройствах на всех трёх портах, а операции сдвига и операции целочисленного сложения MMX и SSE — на двух портах. К указанным портам подсоединены также специфические функциональные устройства. На одном из портов находится устройство для выполнения операций перехода (включая объединённые операции сравнения и условного перехода), а также так называемое устройство пересылок для арифметики с плавающей точкой, на другом — устройство сложения с плавающей точкой, и на третьем — устройство умножения и деления с плавающей точкой. Некоторые менее частые арифметические и логические операции также исполняются в специализированных функциональных устройствах на соответствующих портах.
 После выхода из декодера сформированные группы по")
AMD Athlon 64 / Opteron (K 8) После выхода из декодера сформированные группы по три МОПа помещаются в буфер переупорядочения ROB, который может содержать до 24 групп (72 МОПа). Новая группа МОПов также копируется в очереди планировщика, из которых операции будут запускаться на исполнение. В процессоре K 8 имеется две очереди (буфера) планировщика: для целочисленных/адресных операций (ALU/AGU), для операций арифметики с плавающей точкой (FPU). МОПы выбираются на исполнение из этих очередей во внеочередном порядке, по мере готовности аргументов операций
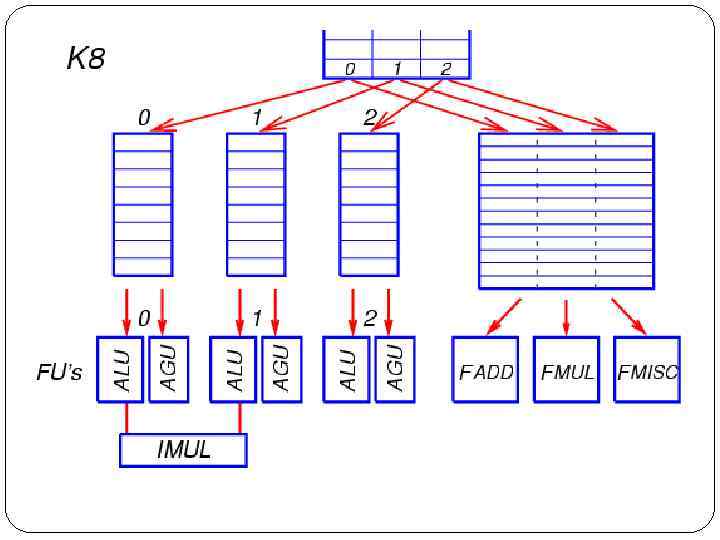
 планировщика для целочисленных и адресных операций состоит из трёх независимых очередей,")
Очередь (буфер) планировщика для целочисленных и адресных операций состоит из трёх независимых очередей, по одной очереди на каждую позицию МОПа в группе. Длина каждой очереди — 8 элементов. Элемент очереди может содержать 2 РОПа (редуцированные операции, микрооперации), на которые расщепляется МОП — один арифметический и один адресный. Простая целочисленная операция преобразуется только в арифметический РОП, операция типа Load-Op, Op-Store или Load-Op-Store — в арифметический и адресный РОПы, а операция загрузки (Load) или выгрузки (Store) — только в адресный РОП. Также выделяется элемент очереди для операции с плавающей точкой с загрузкой (Load) или выгрузкой (Store) — для неё тоже заполняется только адресный РОП. Каждая из трёх очередей связана с двумя отдельными функциональными устройствами, приписанными к этой очереди — целочисленным (ALU) и адресным (AGU). По мере готовности операндов РОПы отсылаются на исполнение в соответствующее устройство. В каждом такте из каждой очереди может быть отправлен на исполнение один арифметический РОП и один адресный РОП (в общем случае из разных элементов очереди). После обработки адресного РОПа в AGU формируется запрос в устройство загрузки/выгрузки (Load/Store Unit) для последующего совершения операции доступа в память. В каждом такте может выполниться до двух операций 64 -битной загрузки из L 1 -кэша либо одна загрузка и одна выгрузка.

IBM Power. PC 970 После выхода из декодера сформированные группы, содержащие до пяти МОПов каждая, помещаются в буфер переупорядочения. Размер буфера переупорядочения составляет 20 групп (до 100 МОПов). Новая группа МОПов также копируется в очереди планировщика, из которых операции будут запускаться на исполнение. В процессоре PPC 970 имеется большое количество очередей планировщика, специфичных для каждой группы функциональных устройств: 4 очереди для устройств арифметики с плавающей точкой (по 5 элементов каждая), 4 очереди для целочисленной арифметики и для адресных операций (по 9 элементов), 2 очереди для операций с регистрами условий (по 5 элементов), 1 очередь для операций перехода (12 элементов), 2 очереди для операций перестановок в векторном блоке VMX (по 8 элементов), 2 очереди для арифметических операций VMX (по 10 элементов)
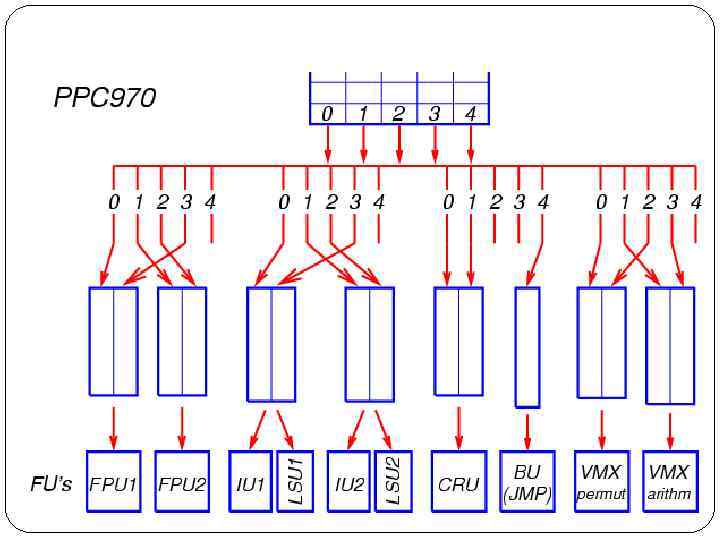

Каждая из этих очередей соответствует определённой позиции МОПа в группе (от 0 до 4). В позицию 4 (последнюю в группе) декодер помещает только операции перехода. Операции арифметики с плавающей точкой, целочисленные и адресные операции могут располагаться в любой из оставшихся четырёх позиций — для каждой из них предназначена отдельная очередь. Операции с регистрами условий декодер всегда помещает в позиции 0 или 1, операции перестановок VMX — в позиции 0 или 2, арифметические операции VMX — в позиции 1 или 3, и операции целочисленного деления — в позиции 1 или 2. Порядок следования операций внутри группы сохраняется. При необходимости декодер оставляет промежуточные позиции в группе незанятыми, что ведёт к неполному заполнению группы. Таким образом, идея статической привязки МОПов к очередям планировщика и функциональным устройствам доведена в процессоре PPC 970 до совершенства. Все очереди планировщика (кроме единственной очереди для операций перехода) сгруппированы по две, и к каждой такой паре очередей подсоединено соответствующее функциональное устройство. Для запуска на исполнение в каждом такте из такой сдвоенной очереди выбирается самый старый из МОПов, аргументы которых уже вычислены либо вычисляются и будут готовы к моменту попадания в функциональное устройство. Из каждой сдвоенной очереди для целочисленных и адресных операций на исполнение может быть отправлено два МОПа — по одному в соответствующее арифметическое (IU 1/IU 2) и адресное (LSU 1/LSU 2) устройства. Из каждой сдвоенной очереди FPU на исполнение отправляется один МОП — в соответствующее устройство FPU 1/FPU 2. По существу, каждая пара очередей проявляет себя как единая очередь двойного размера.
Лекция_7t_арх_соврем_проц2.ppt