


4a6ae0648fd2ba0f7cd3caa3352cc399.ppt
- Количество слайдов: 39
 Proyectos de semántica léxica durante la década de los 90 en Estados Unidos: Redes de relaciones semánticas Word. Net. A lexical database for the English Language (Version 1. 0, June 1991) http: //www. cogsci. princeton. edu/~wn/ Consultas de Word. Net on line: http: //www. cogsci. princeton. edu/cgi-bin/webwn
Proyectos de semántica léxica durante la década de los 90 en Estados Unidos: Redes de relaciones semánticas Word. Net. A lexical database for the English Language (Version 1. 0, June 1991) http: //www. cogsci. princeton. edu/~wn/ Consultas de Word. Net on line: http: //www. cogsci. princeton. edu/cgi-bin/webwn
 tree piano, pianoforte, forte-piano -- (a stringed") Relaciones de hiponimia/hiperonimia Recursively display `hypernym' (superordinate) tree piano, pianoforte, forte-piano -- (a stringed instrument that is played by depressing keys that cause hammers to strike tuned strings and produce sounds) => stringed instrument -- (a musical instrument in which taut strings provide the source of sound) => musical instrument -- (an instrument used to produce music) => instrument -- (a device that requires skill for proper use) => device -- (an instrumentality invented for a particular purpose; "the device is small enough to wear on your wrist"; "a device intended to conserve water") => instrumentality, instrumentation -- (an artifact (or system of artifacts) that is instrumental in accomplishing some end) => artifact, artefact -- (a man-made object) => object, physical object -- (a physical (tangible and visible) entity; "it was full of rackets, balls and other objects") => entity, something -- (anything having existence (living or nonliving))
Relaciones de hiponimia/hiperonimia Recursively display `hypernym' (superordinate) tree piano, pianoforte, forte-piano -- (a stringed instrument that is played by depressing keys that cause hammers to strike tuned strings and produce sounds) => stringed instrument -- (a musical instrument in which taut strings provide the source of sound) => musical instrument -- (an instrument used to produce music) => instrument -- (a device that requires skill for proper use) => device -- (an instrumentality invented for a particular purpose; "the device is small enough to wear on your wrist"; "a device intended to conserve water") => instrumentality, instrumentation -- (an artifact (or system of artifacts) that is instrumental in accomplishing some end) => artifact, artefact -- (a man-made object) => object, physical object -- (a physical (tangible and visible) entity; "it was full of rackets, balls and other objects") => entity, something -- (anything having existence (living or nonliving))
: http: //www. hum.") Réplica del proyecto Word. Net en Europa: Euro. Word. Net (1996/1999): http: //www. hum. uva. nl/~ewn/ Spanish Word. Net, de venta en European Language Resources Association (ELRA): http: //www. icp. inpg. fr/ELRA/cata/text_det. html#eurowordnet http: //www. icp. inpg. fr/ELRA/home. html
Réplica del proyecto Word. Net en Europa: Euro. Word. Net (1996/1999): http: //www. hum. uva. nl/~ewn/ Spanish Word. Net, de venta en European Language Resources Association (ELRA): http: //www. icp. inpg. fr/ELRA/cata/text_det. html#eurowordnet http: //www. icp. inpg. fr/ELRA/home. html
 Proyectos de sintaxis léxica durante la década de los 90 en Estados Unidos (y sus réplicas europeas): COMLEX Syntax (Version 1. 0, May 1994) http: //www. cs. nyu. edu/cs/faculty/grishman/comlex. html PAROLE (Preparatory Action for Linguistic Resources Organization for Language Engineering, 1996/1997) http: //www. ub. es/gilcub/SIMPLE/simple. html PAROLE Spanish Lexicon, de venta en European Language Resources Association (ELRA): http: //www. icp. inpg. fr/ELRA/cata/text_det. html#spanparollex http: //www. icp. inpg. fr/ELRA/home. html SIMPLE (Semantic Information for Multifunctional Plurilingual Lexica, 1998/2000) http: //www. ub. es/gilcub/SIMPLE/simple. html http: //www. ub. es/gilcub/castellano/proyectos/europeos/simple. html#Resumen
Proyectos de sintaxis léxica durante la década de los 90 en Estados Unidos (y sus réplicas europeas): COMLEX Syntax (Version 1. 0, May 1994) http: //www. cs. nyu. edu/cs/faculty/grishman/comlex. html PAROLE (Preparatory Action for Linguistic Resources Organization for Language Engineering, 1996/1997) http: //www. ub. es/gilcub/SIMPLE/simple. html PAROLE Spanish Lexicon, de venta en European Language Resources Association (ELRA): http: //www. icp. inpg. fr/ELRA/cata/text_det. html#spanparollex http: //www. icp. inpg. fr/ELRA/home. html SIMPLE (Semantic Information for Multifunctional Plurilingual Lexica, 1998/2000) http: //www. ub. es/gilcub/SIMPLE/simple. html http: //www. ub. es/gilcub/castellano/proyectos/europeos/simple. html#Resumen
: la teoría de los marcos semánticos") Proyectos de semántica léxica en Estados Unidos (1997/2003): la teoría de los marcos semánticos de Fillmore The Frame. Net Project. Tools for Lexicon Building (1997/2000, 2000/2003): http: //www. icsi. berkeley. edu/~framenet/ Información lingüística detallada sobre el proyecto Frame. Net: http: //www. icsi. berkeley. edu/~framenet/book. html Primera aplicación al español: M. Cristóbal (ICSI) y Laboratorio de Lingüística Informática, UAB: http: //wasabi. icsi. berkeley. edu: 8081/pub/servlet/Index. Spanish
Proyectos de semántica léxica en Estados Unidos (1997/2003): la teoría de los marcos semánticos de Fillmore The Frame. Net Project. Tools for Lexicon Building (1997/2000, 2000/2003): http: //www. icsi. berkeley. edu/~framenet/ Información lingüística detallada sobre el proyecto Frame. Net: http: //www. icsi. berkeley. edu/~framenet/book. html Primera aplicación al español: M. Cristóbal (ICSI) y Laboratorio de Lingüística Informática, UAB: http: //wasabi. icsi. berkeley. edu: 8081/pub/servlet/Index. Spanish
 Los orígenes de la sintaxis léxica en Europa • Laboratoire d'Automatique Documentaire et Linguistique (LADL), Université Paris 7 (actualmente en la Université de Marne-la-Vallée): http: //ladl. univ-mlv. fr/index. html • Primera gramática computacional del francés (Gross 1975) • Primera gramática computacional del español: (Subirats 1981) • Bibliografía de lingüística léxica europea (1987/1998): http: //ladl. univ-mlv. fr/English/biblio. html http: //ladl. univ-mlv. fr/French/bi_suite. html
Los orígenes de la sintaxis léxica en Europa • Laboratoire d'Automatique Documentaire et Linguistique (LADL), Université Paris 7 (actualmente en la Université de Marne-la-Vallée): http: //ladl. univ-mlv. fr/index. html • Primera gramática computacional del francés (Gross 1975) • Primera gramática computacional del español: (Subirats 1981) • Bibliografía de lingüística léxica europea (1987/1998): http: //ladl. univ-mlv. fr/English/biblio. html http: //ladl. univ-mlv. fr/French/bi_suite. html
 Incongruencias de los Proyectos Europeos de lingüística léxica 1. Los recursos lingüísticos creados no están en Internet y no son de libre distribución, a pesar de que la financiación de PAROLE y SIMPLE, p. ej. , ascendía a 5 millones de euros aprox. Los recursos lingüísticos de estos proyectos se tiene que comprar a ELRA (European Language Resources Association) 2. En PAROLE y SIMPLE, no se incorporó ni a los grupos de investigación ni a los investigadores que iniciaron los primeros trabajos sobre lingüística léxica en Europa. 3. En PAROLE y SIMPLE, se incluyó una lengua regional –el catalán–, a pesar de que la financiación de proyectos sobre lenguas regionales no depende de la misma Dirección General que financia los proyectos de lenguas nacionales.
Incongruencias de los Proyectos Europeos de lingüística léxica 1. Los recursos lingüísticos creados no están en Internet y no son de libre distribución, a pesar de que la financiación de PAROLE y SIMPLE, p. ej. , ascendía a 5 millones de euros aprox. Los recursos lingüísticos de estos proyectos se tiene que comprar a ELRA (European Language Resources Association) 2. En PAROLE y SIMPLE, no se incorporó ni a los grupos de investigación ni a los investigadores que iniciaron los primeros trabajos sobre lingüística léxica en Europa. 3. En PAROLE y SIMPLE, se incluyó una lengua regional –el catalán–, a pesar de que la financiación de proyectos sobre lenguas regionales no depende de la misma Dirección General que financia los proyectos de lenguas nacionales.
 La participación de España en los Proyectos Europeos de de ingeniería lingüística ha sido exigua, muy por debajo de la importancia económica del español en el mundo • 1998 y 2002: 53 Proyectos - Alemania: 40 (75%) - Francia: 34 (64%) - Italia: 27 (50%) - España: 17 (32%) • 1994 y 1998: 106 Proyectos - Francia: 70 (66%) - Alemania: 69 (65%) - Italia: 48 (45%) - España: 27 (26%) 1 Cf. A World of Understanding. Language Technologies. 1998. CD-ROM. European Commission, Telematics Applications Programme y A World of Understanding 2000. HLT Observatory. CD-ROM. Information Society Directorate General of the European Commission.
La participación de España en los Proyectos Europeos de de ingeniería lingüística ha sido exigua, muy por debajo de la importancia económica del español en el mundo • 1998 y 2002: 53 Proyectos - Alemania: 40 (75%) - Francia: 34 (64%) - Italia: 27 (50%) - España: 17 (32%) • 1994 y 1998: 106 Proyectos - Francia: 70 (66%) - Alemania: 69 (65%) - Italia: 48 (45%) - España: 27 (26%) 1 Cf. A World of Understanding. Language Technologies. 1998. CD-ROM. European Commission, Telematics Applications Programme y A World of Understanding 2000. HLT Observatory. CD-ROM. Information Society Directorate General of the European Commission.
 Los recursos léxicos de la lengua española • A propósito de la lexicografía oficial: los diccionarios de la Real Academia Española: • Diccionario de la Lengua Española, 21ª edición, 1992, • Edición en CD-ROM (1995)
Los recursos léxicos de la lengua española • A propósito de la lexicografía oficial: los diccionarios de la Real Academia Española: • Diccionario de la Lengua Española, 21ª edición, 1992, • Edición en CD-ROM (1995)
 Palabras de uso común en la lengua española que no figuran en: 1. la edición de 1992 del Diccionario de la Lengua Española de la Real Academia Española (DRAE); 2. la edición en CD-ROM de 1995 del DRAE de 1992 3. los boletines cuatrimestrales (accesibles desde http: //www. rae. es/NIVEL 1/ACADRAE. HTM hasta hace unos meses) en los que la Academia publica una relación de las enmiendas y adiciones al Diccionario que se van aprobando en Sesión plenaria: acientífico, antialérgico, antiterrorista, celulitis, circularidad, clasificable, destacable, enfatización, entreno, finalización, fluctuante, hinchable, indisociable, iniciático, karaoke, lanzamisiles, etc. • Todas estas entradas figuran en el Diccionario del español actual de Manuel Seco de et al. de 1999; (excepciones: decepcionado, inacabado, etc. ).
Palabras de uso común en la lengua española que no figuran en: 1. la edición de 1992 del Diccionario de la Lengua Española de la Real Academia Española (DRAE); 2. la edición en CD-ROM de 1995 del DRAE de 1992 3. los boletines cuatrimestrales (accesibles desde http: //www. rae. es/NIVEL 1/ACADRAE. HTM hasta hace unos meses) en los que la Academia publica una relación de las enmiendas y adiciones al Diccionario que se van aprobando en Sesión plenaria: acientífico, antialérgico, antiterrorista, celulitis, circularidad, clasificable, destacable, enfatización, entreno, finalización, fluctuante, hinchable, indisociable, iniciático, karaoke, lanzamisiles, etc. • Todas estas entradas figuran en el Diccionario del español actual de Manuel Seco de et al. de 1999; (excepciones: decepcionado, inacabado, etc. ).
 de la RAE: http: //www. rae. es/NIVEL") Corpus de Referencia del Español Actual (CREA) de la RAE: http: //www. rae. es/NIVEL 1/CREA. HTM • Composición del CREA: • Basicamente textos literarios y marginalmente textos periodísticos y publicaciones académicas • Composición del British National Corpus (http: //info. ox. ac. uk/bnc/) o el American National Corpus (http: //www. cs. vassar. edu/~ide/anc/) –actualmente en fase de desarrollo–: • Fundamentalmente textos periodísticos y publicaciones académicas y marginalmente textos literarios.
Corpus de Referencia del Español Actual (CREA) de la RAE: http: //www. rae. es/NIVEL 1/CREA. HTM • Composición del CREA: • Basicamente textos literarios y marginalmente textos periodísticos y publicaciones académicas • Composición del British National Corpus (http: //info. ox. ac. uk/bnc/) o el American National Corpus (http: //www. cs. vassar. edu/~ide/anc/) –actualmente en fase de desarrollo–: • Fundamentalmente textos periodísticos y publicaciones académicas y marginalmente textos literarios.
 Miembros del consorcio académico e industrial del British National Corpus: http: //info. ox. ac. uk/bnc/what/index. html • • Publishing Companies Oxford University Press Addison-Wesley Longman Larousse Kingfisher Chambers • • Academic research centers: Oxford University Computing Services Lancaster University's Centre for Computer Research on the English Language British Library's Research and Innovation Centre. • Commercial partners: • Science and Engineering Council (now EPSRC) • DTI under the Joint Framework for Information Technology (JFIT) programme. • Additional support: • British Library • British Academy
Miembros del consorcio académico e industrial del British National Corpus: http: //info. ox. ac. uk/bnc/what/index. html • • Publishing Companies Oxford University Press Addison-Wesley Longman Larousse Kingfisher Chambers • • Academic research centers: Oxford University Computing Services Lancaster University's Centre for Computer Research on the English Language British Library's Research and Innovation Centre. • Commercial partners: • Science and Engineering Council (now EPSRC) • DTI under the Joint Framework for Information Technology (JFIT) programme. • Additional support: • British Library • British Academy
: 5 instituciones académicas y 19 empresas") Miembros del consorcio del American National Corpus (ANC): 5 instituciones académicas y 19 empresas Instituciones académicas: Vassar College New York University Linguistic Data Consortium, University of Pennsylvania International Computer Science Institute, University of California, Berkeley University of Colorado at Boulder
Miembros del consorcio del American National Corpus (ANC): 5 instituciones académicas y 19 empresas Instituciones académicas: Vassar College New York University Linguistic Data Consortium, University of Pennsylvania International Computer Science Institute, University of California, Berkeley University of Colorado at Boulder
: 19 empresas y 5 instituciones académicas") Miembros del consorcio del American National Corpus (ANC): 19 empresas y 5 instituciones académicas Empresas: Pearson Education Random House Reference Langenscheidt Publishing Group Harper. Collins Publishers Cambridge University Press Lexi. Quest Microsoft Corporation Shogakukan Inc. ACL Press Inc. Taishukan Publishing Company Oxford University Press Kenkyusha Ltd. IBM Corporation Obunsha Publishing Co. Ltd. Bloomsbury Publishing Plc Benesse Corporation Sanseido Co. , Ltd. Sony Electronics Inc. Macmillan Publishers
Miembros del consorcio del American National Corpus (ANC): 19 empresas y 5 instituciones académicas Empresas: Pearson Education Random House Reference Langenscheidt Publishing Group Harper. Collins Publishers Cambridge University Press Lexi. Quest Microsoft Corporation Shogakukan Inc. ACL Press Inc. Taishukan Publishing Company Oxford University Press Kenkyusha Ltd. IBM Corporation Obunsha Publishing Co. Ltd. Bloomsbury Publishing Plc Benesse Corporation Sanseido Co. , Ltd. Sony Electronics Inc. Macmillan Publishers
? La") ¿Un consorcio para el desarrollo del Corpus de Referencia del Español Actual (CREA)? La Real Academia es la única institución implicada en la construcción del CREA
¿Un consorcio para el desarrollo del Corpus de Referencia del Español Actual (CREA)? La Real Academia es la única institución implicada en la construcción del CREA
 • No") Problemas del Corpus de Referencia del Español Actual de la RAE (1) • No se ha previsto un plan de viabilidad comercial Þ No se previó inicialmente la adquisición de los derechos de las obras literarias que integraban el CREA (textos españoles a partir de 1975) Þ Ha quedado bloqueada la distribución –comercial o no– del CREA Þ El CREA sólo se puede consultar on line. Þ Dada que la consulta de las bases de datos que albergan un corpus consumen muchos recursos informáticos, el acceso al CREA suele estar saturado por un exceso de consultas.
Problemas del Corpus de Referencia del Español Actual de la RAE (1) • No se ha previsto un plan de viabilidad comercial Þ No se previó inicialmente la adquisición de los derechos de las obras literarias que integraban el CREA (textos españoles a partir de 1975) Þ Ha quedado bloqueada la distribución –comercial o no– del CREA Þ El CREA sólo se puede consultar on line. Þ Dada que la consulta de las bases de datos que albergan un corpus consumen muchos recursos informáticos, el acceso al CREA suele estar saturado por un exceso de consultas.
 • El") Problemas del Corpus de Referencia del Español Actual de la RAE (2) • El CREA se ha etiquetado con el sistema de dominio público MULTEXT (Multilingual Text Tools and Corpora, http: //www. lpl. univ-aix. fr/projects/multext/) Þ se desaprovechan las ventajas para el procesamiento multilingüe del sistema MULTEXT: el CREA es un corpus monolingüe; Þ se tienen que asumir las limitaciones que surgen cuando se utiliza dicho sistema para una aplicación monolingüe para la que no ha sido diseñado.
Problemas del Corpus de Referencia del Español Actual de la RAE (2) • El CREA se ha etiquetado con el sistema de dominio público MULTEXT (Multilingual Text Tools and Corpora, http: //www. lpl. univ-aix. fr/projects/multext/) Þ se desaprovechan las ventajas para el procesamiento multilingüe del sistema MULTEXT: el CREA es un corpus monolingüe; Þ se tienen que asumir las limitaciones que surgen cuando se utiliza dicho sistema para una aplicación monolingüe para la que no ha sido diseñado.
 • MULTEXT") Problemas del Corpus de Referencia del Español Actual de la RAE (3) • MULTEXT no permite reconocer locuciones, como p. ej. , locuciones verbales (adorar el santo por la peana, dar a luz), locuciones nominales (bomba atómica, objeto volante no identificado), etc. • El motor de búsquedas del CREA solo admite búsquedas boolenas, es decir, concatenación de cadenas y/o búsquedas con los operadores y, o; p. ej. , manzanas verdes, manzanas y peras, manzanas verdes o peras. • Existen sistemas de libre distribución con licencia, como CQP (Institut für Maschinelle Sprachverarbeitung, Universität Stuttgart, http: //www. ims. uni-stuttgart. de) que admiten búsquedas con expresiones regulares, que son mucho más potentes y mejor adaptadas para el trabajo lingüístico que el motor de búsquedas del CREA.
Problemas del Corpus de Referencia del Español Actual de la RAE (3) • MULTEXT no permite reconocer locuciones, como p. ej. , locuciones verbales (adorar el santo por la peana, dar a luz), locuciones nominales (bomba atómica, objeto volante no identificado), etc. • El motor de búsquedas del CREA solo admite búsquedas boolenas, es decir, concatenación de cadenas y/o búsquedas con los operadores y, o; p. ej. , manzanas verdes, manzanas y peras, manzanas verdes o peras. • Existen sistemas de libre distribución con licencia, como CQP (Institut für Maschinelle Sprachverarbeitung, Universität Stuttgart, http: //www. ims. uni-stuttgart. de) que admiten búsquedas con expresiones regulares, que son mucho más potentes y mejor adaptadas para el trabajo lingüístico que el motor de búsquedas del CREA.
 Tratamiento automático de la información textual del español: Laboratorio de Lingüística Informática de la Universidad Autónoma
Tratamiento automático de la información textual del español: Laboratorio de Lingüística Informática de la Universidad Autónoma
 aparta, apartar. VPRED: IPRES: 3 s: IIMPE: 2 s apartado, apartado. APRED: m: s, apartado. N: m: s, apartar. VPRED: PP: m: s apartado/de/correos, apartado/de/correos. N: m: s apartados, apartado. APRED: m: p, apartado. N: m: p, apartar. VPRED: PP: m: p apartados/de/correos, apartado/de/correos. N: m: p apartáis, apartar. VPRED: IPRES: 2 p apartamento, apartamento. N: m: s apartamentos, apartamento. N: m: p apartamos, apartar. VPRED: IPRES: IPIND: 1 p Muestra de un diccionario electrónico del español de 600, 000 formas, generado automáticamente a partir de un diccionario de 93, 000 lemas (67 palabras ortográficas y 26 locuciones)
aparta, apartar. VPRED: IPRES: 3 s: IIMPE: 2 s apartado, apartado. APRED: m: s, apartado. N: m: s, apartar. VPRED: PP: m: s apartado/de/correos, apartado/de/correos. N: m: s apartados, apartado. APRED: m: p, apartado. N: m: p, apartar. VPRED: PP: m: p apartados/de/correos, apartado/de/correos. N: m: p apartáis, apartar. VPRED: IPRES: 2 p apartamento, apartamento. N: m: s apartamentos, apartamento. N: m: p apartamos, apartar. VPRED: IPRES: IPIND: 1 p Muestra de un diccionario electrónico del español de 600, 000 formas, generado automáticamente a partir de un diccionario de 93, 000 lemas (67 palabras ortográficas y 26 locuciones)
 aparta, apartar. VPRED: IPRES: 3 s: IIMPE: 2 s apartado, apartado. APRED: m: s, apartado. N: m: s, apartar. VPRED: PP: m: s apartado/de/correos, apartado/de/correos. N: m: s apartados, apartado. APRED: m: p, apartado. N: m: p, apartar. VPRED: PP: m: p apartados/de/correos, apartado/de/correos. N: m: p apartáis, apartar. VPRED: IPRES: 2 p apartamento, apartamento. N: m: s apartamentos, apartamento. N: m: p apartamos, apartar. VPRED: IPRES: IPIND: 1 p Muestra de un diccionario electrónico del español de 600, 000 formas, generado automáticamente a partir de un diccionario de 93, 000 lemas (67, 000 palabras ortográficas y 26, 000 locuciones). El etiquetario de este diccionario esta descrito en http: //seneca. uab. es/lali/etiquetario. html ; más información: http: //seneca. uab. es/lali/Lexicos_electronicos. htm
aparta, apartar. VPRED: IPRES: 3 s: IIMPE: 2 s apartado, apartado. APRED: m: s, apartado. N: m: s, apartar. VPRED: PP: m: s apartado/de/correos, apartado/de/correos. N: m: s apartados, apartado. APRED: m: p, apartado. N: m: p, apartar. VPRED: PP: m: p apartados/de/correos, apartado/de/correos. N: m: p apartáis, apartar. VPRED: IPRES: 2 p apartamento, apartamento. N: m: s apartamentos, apartamento. N: m: p apartamos, apartar. VPRED: IPRES: IPIND: 1 p Muestra de un diccionario electrónico del español de 600, 000 formas, generado automáticamente a partir de un diccionario de 93, 000 lemas (67, 000 palabras ortográficas y 26, 000 locuciones). El etiquetario de este diccionario esta descrito en http: //seneca. uab. es/lali/etiquetario. html ; más información: http: //seneca. uab. es/lali/Lexicos_electronicos. htm
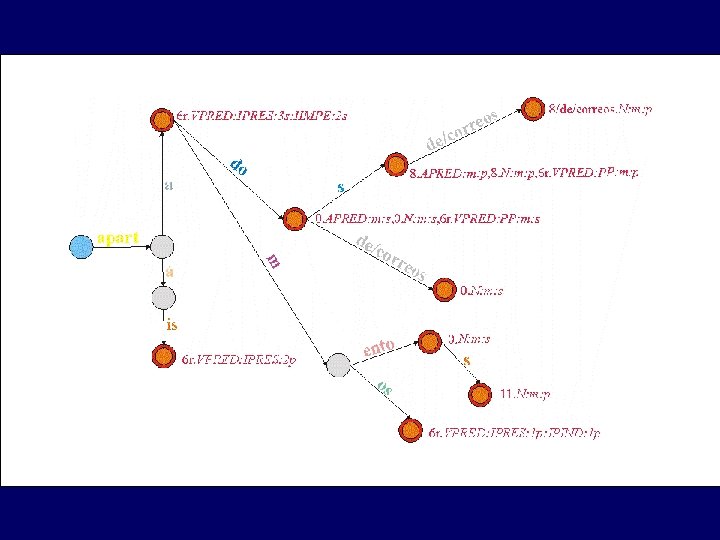
 # Loc. Vpred 1 N N 1_Loc. Vpred_N 2 { dar/a/luz } { engendrar. } $200. 1$ { { (
# Loc. Vpred 1 N N 1_Loc. Vpred_N 2 { dar/a/luz } { engendrar. } $200. 1$ { { (
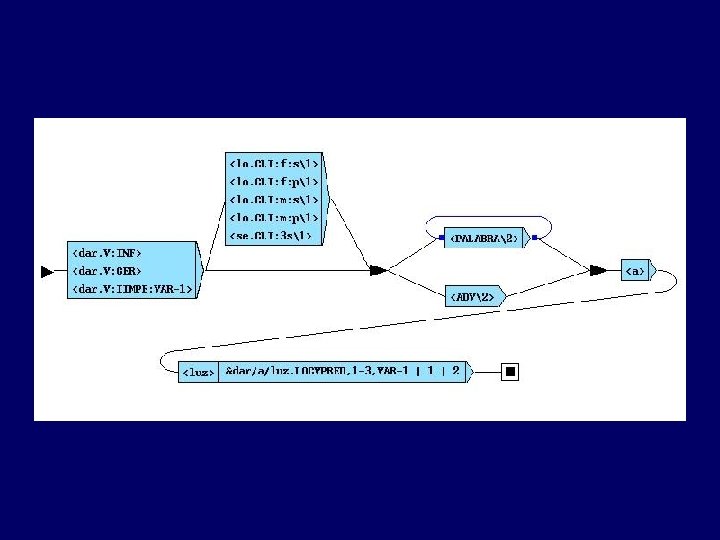
 dar/a/luz 1. Almacenamiento de") Conversión de una gramática computacional (Ortega 2001 y Aragón 2000) dar/a/luz 1. Almacenamiento de los transductores en posiciones de memoria 2. Asociación de las posiciones de memoria al predicado Zona de memoria, donde se almacena la información comprimida 3. Inserción del predicado en el árbol de gramáticas computacionales
Conversión de una gramática computacional (Ortega 2001 y Aragón 2000) dar/a/luz 1. Almacenamiento de los transductores en posiciones de memoria 2. Asociación de las posiciones de memoria al predicado Zona de memoria, donde se almacena la información comprimida 3. Inserción del predicado en el árbol de gramáticas computacionales
 Inserción del predicado en el árbol de gramáticas computacionales GRAMÁTICA COMPUTACIONAL APRED ser/posible VPRED hablar GPPRED estar/de/moda NPRED dar/a/luz ser/un/peligro tener/aires/de /suficiencia
Inserción del predicado en el árbol de gramáticas computacionales GRAMÁTICA COMPUTACIONAL APRED ser/posible VPRED hablar GPPRED estar/de/moda NPRED dar/a/luz ser/un/peligro tener/aires/de /suficiencia
 Intersección de una cadena con un transductor a b b c a b
Intersección de una cadena con un transductor a b b c a b
 Autómata finito Transduce a por b") Intersección de un autómata con un transductor (1) Autómata finito Transduce a por b Transduce b por c Transduce c por a Transductor Autómata resultante de la transducción
Intersección de un autómata con un transductor (1) Autómata finito Transduce a por b Transduce b por c Transduce c por a Transductor Autómata resultante de la transducción
 Autómata finito Transduce a por e") Intersección de un autómata con un transductor (2) Autómata finito Transduce a por e Transduce b por e Transduce c por A y añade un nuevo Transductor subsecuencial estado al que se accede con B Autómata finito con transiciones nulas
Intersección de un autómata con un transductor (2) Autómata finito Transduce a por e Transduce b por e Transduce c por A y añade un nuevo Transductor subsecuencial estado al que se accede con B Autómata finito con transiciones nulas
 Determinización y minimización de un autómata transducido Autómata finito con transiciones nulas Determinización y minimización Autómata finito determinista mínimo sin transiciones nulas
Determinización y minimización de un autómata transducido Autómata finito con transiciones nulas Determinización y minimización Autómata finito determinista mínimo sin transiciones nulas
 Análisis léxico automático Corrió en todo momento un enorme riesgo correr. VPRED: IPIND: 3 s, correrse. VPRED: IPIND: 3 s en/todo/momento. ADV un un. DET: m: s enorme. APRED: m: f: s riesgo. N: m: s
Análisis léxico automático Corrió en todo momento un enorme riesgo correr. VPRED: IPIND: 3 s, correrse. VPRED: IPIND: 3 s en/todo/momento. ADV un un. DET: m: s enorme. APRED: m: f: s riesgo. N: m: s
 correr. VPRED: IPIND: 3 s, correrse. VPRED: IPIND: 3 s en/todo/momento. ADV un un. DET: m: s enorme. APRED: m: f: s riesgo. N: m: s
correr. VPRED: IPIND: 3 s, correrse. VPRED: IPIND: 3 s en/todo/momento. ADV un un. DET: m: s enorme. APRED: m: f: s riesgo. N: m: s
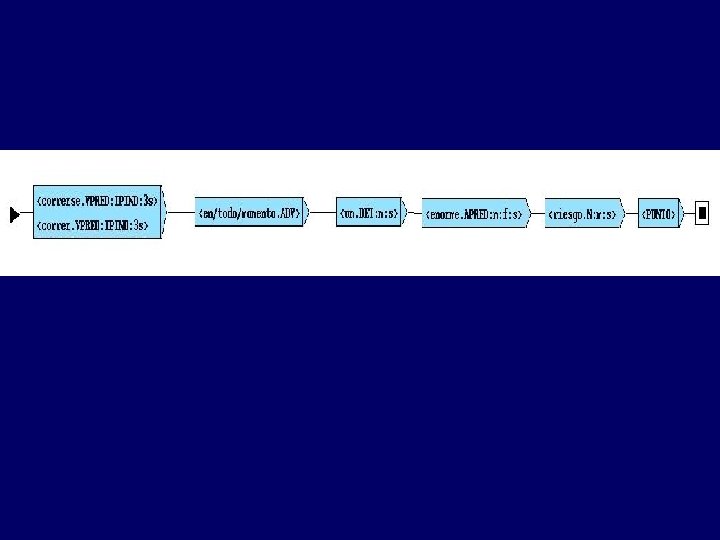
 Análisis léxico automático en forma de autómata finito determinista Corrió en todo momento un enorme riesgo
Análisis léxico automático en forma de autómata finito determinista Corrió en todo momento un enorme riesgo
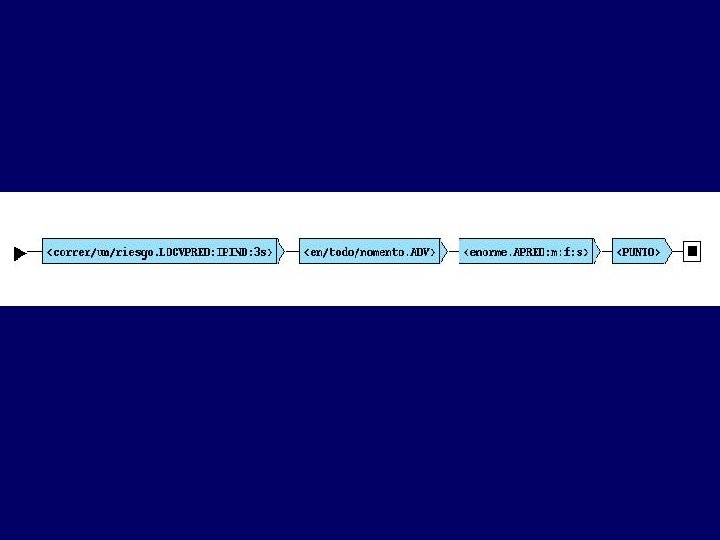
 Transducción de un autómata-texto
Transducción de un autómata-texto
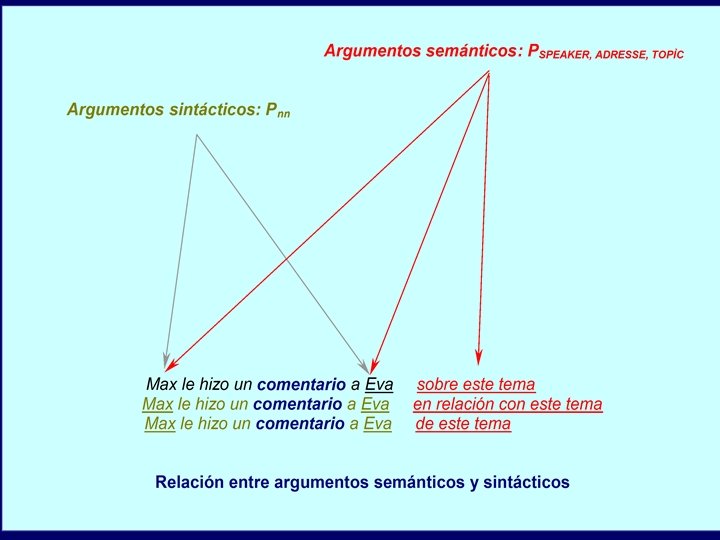
 Estudio de los argumentos semánticos en el léxico • Establecimiento de clases de predicados en el léxico en función de sus argumentos semánticos • Identificación en un corpus de los argumentos semánticos ligados a predicados específicos en el marco de construcciones sintácticas seleccionadas • Utilización del corpus para el entrenamiento de aplicaciones de etiquetación semántica automática de textos • Muestra de Spanish Frame. Net
Estudio de los argumentos semánticos en el léxico • Establecimiento de clases de predicados en el léxico en función de sus argumentos semánticos • Identificación en un corpus de los argumentos semánticos ligados a predicados específicos en el marco de construcciones sintácticas seleccionadas • Utilización del corpus para el entrenamiento de aplicaciones de etiquetación semántica automática de textos • Muestra de Spanish Frame. Net