

Презентация программы Causal-Semantic Matrix.ppt
- Количество слайдов: 43

 Программа-проект: Causal-Semantic Matrix Автор проекта: Давыдов Д. О. (Ул. ГУ, ФГНи. СТ, специальность: «Социология» ) Руководитель по реализации проекта, старший программист: Бондаренко Владислав Сергеевич (Ул. ГТУ, Факультет Информационные Системы и Технологии Специальность: Вычислительные машины и комплексы) Программисты: 1. Романов Василий Николаевич (Ул. ГТУ, Факультет Информационые Системы и Технологии Специальность: Информационные Системы и Технологии. ), 2. Улазов Сергей Николаевич (Ул. ГТУ, Факультет Информационных Систем и Технологий - Авиационные Приборы и Измерительно-Вычислительные Комплексы).
Программа-проект: Causal-Semantic Matrix Автор проекта: Давыдов Д. О. (Ул. ГУ, ФГНи. СТ, специальность: «Социология» ) Руководитель по реализации проекта, старший программист: Бондаренко Владислав Сергеевич (Ул. ГТУ, Факультет Информационные Системы и Технологии Специальность: Вычислительные машины и комплексы) Программисты: 1. Романов Василий Николаевич (Ул. ГТУ, Факультет Информационые Системы и Технологии Специальность: Информационные Системы и Технологии. ), 2. Улазов Сергей Николаевич (Ул. ГТУ, Факультет Информационных Систем и Технологий - Авиационные Приборы и Измерительно-Вычислительные Комплексы).
 Программа Causal-Semantic Matrix – это новый и достаточно перспективный по своим возможностям инструмент качественно-количественной обработки социологической (и не только) информации выраженной в текстовой форме (открытые вопросы анкеты, бланки интервью, личные и официальные документы, письма, данные фокус-групп, даже комментарии в интернете к новостным статьям и т. д. ). Результатом данной процедуры выступает построение каузально-семантической матрицы – компьютерной графической модели того или иного смыслового сектора (семантического пространства, тематической релевантности и т. д. ) общественного сознания, которую можно подвергнуть математической обработке с целью получения дополнительных знаний. Данная программа способна полностью смоделировать общественное сознание по определенным вопросам или смысловым секторам, дополнительно получая индикаторы, которые позволят оперативно вычислять «место в структуре общественного сознания» тех или иных акторов на данной матрице и достраивать содержание их сознания.
Программа Causal-Semantic Matrix – это новый и достаточно перспективный по своим возможностям инструмент качественно-количественной обработки социологической (и не только) информации выраженной в текстовой форме (открытые вопросы анкеты, бланки интервью, личные и официальные документы, письма, данные фокус-групп, даже комментарии в интернете к новостным статьям и т. д. ). Результатом данной процедуры выступает построение каузально-семантической матрицы – компьютерной графической модели того или иного смыслового сектора (семантического пространства, тематической релевантности и т. д. ) общественного сознания, которую можно подвергнуть математической обработке с целью получения дополнительных знаний. Данная программа способна полностью смоделировать общественное сознание по определенным вопросам или смысловым секторам, дополнительно получая индикаторы, которые позволят оперативно вычислять «место в структуре общественного сознания» тех или иных акторов на данной матрице и достраивать содержание их сознания.
 Метод не привязан к теории, теория не ограничивает") Методологические плюсы метода каузальносемантических матриц 1) Метод не привязан к теории, теория не ограничивает выборку фактов, подвергающихся фиксации, и не отбирает «важное» и «не важное» . Наше представление (априорная форма либо «принятая на вооружение теория» ) никак не влияет на собранные данные. Мы исходим из предположения что мы не должны отбрасывать что-либо только потому, что это нам кажется «не важным» исследователь, использующий данный метод может и должен исходить из методологического принципа: «Я знаю, что не знаю ничего» и использовать все качественные текстовые данные в полном объеме (количество конструктов не ограничивается исследователем, их точное количество определяется только после обработки всех данных), «так как они нам даны» в нашем зрительном восприятии текста, не «выбросив» ничего (цель данного принципа - исключить или максимально уменьшить вероятность проявления «черного лебедя» ).
Методологические плюсы метода каузальносемантических матриц 1) Метод не привязан к теории, теория не ограничивает выборку фактов, подвергающихся фиксации, и не отбирает «важное» и «не важное» . Наше представление (априорная форма либо «принятая на вооружение теория» ) никак не влияет на собранные данные. Мы исходим из предположения что мы не должны отбрасывать что-либо только потому, что это нам кажется «не важным» исследователь, использующий данный метод может и должен исходить из методологического принципа: «Я знаю, что не знаю ничего» и использовать все качественные текстовые данные в полном объеме (количество конструктов не ограничивается исследователем, их точное количество определяется только после обработки всех данных), «так как они нам даны» в нашем зрительном восприятии текста, не «выбросив» ничего (цель данного принципа - исключить или максимально уменьшить вероятность проявления «черного лебедя» ).
 Решается проблема интерпретации данных путем непосредственного оперирования к проявленному в собранных текстовых данных") 2) Решается проблема интерпретации данных путем непосредственного оперирования к проявленному в собранных текстовых данных качественному содержанию, что в итоге не делает необходимым априорно сводить полученные данные к каким-то иным образованиям, «стоящим по ту сторону» , которые детерминируют наблюдаемое положение вещей «на самом деле» , но само по себе рассмотрение данных качественных данных, которые мы приняли как факты с учетом их ВЗАИМОСВЯЗЕЙ ограничивает число интерпретаций, и решает ряд методологических проблем касающихся онтологического статуса анализируемых феноменов и их причинной детерминированности, что можно увидеть на следующем графике:
2) Решается проблема интерпретации данных путем непосредственного оперирования к проявленному в собранных текстовых данных качественному содержанию, что в итоге не делает необходимым априорно сводить полученные данные к каким-то иным образованиям, «стоящим по ту сторону» , которые детерминируют наблюдаемое положение вещей «на самом деле» , но само по себе рассмотрение данных качественных данных, которые мы приняли как факты с учетом их ВЗАИМОСВЯЗЕЙ ограничивает число интерпретаций, и решает ряд методологических проблем касающихся онтологического статуса анализируемых феноменов и их причинной детерминированности, что можно увидеть на следующем графике:
 «Один факт можно интерпретировать n-ным числом способов, однако при наличии некоторого числа взаимосвязанных фактов число интерпретаций ограничивается и при увеличении числа данных взаимосвязанных фактов в рамках одного ограниченного универсума смыслового сектора общественного сознания число интерпретаций стремится к 1» , «Если lim x →∞, то lim у → 1, где x – число взаимосвязанных фактов, а у – число интерпретаций» . Этот закон мы обозначим «правилом взаимосвязанного понимания» .
«Один факт можно интерпретировать n-ным числом способов, однако при наличии некоторого числа взаимосвязанных фактов число интерпретаций ограничивается и при увеличении числа данных взаимосвязанных фактов в рамках одного ограниченного универсума смыслового сектора общественного сознания число интерпретаций стремится к 1» , «Если lim x →∞, то lim у → 1, где x – число взаимосвязанных фактов, а у – число интерпретаций» . Этот закон мы обозначим «правилом взаимосвязанного понимания» .
 Все вышеперечисленное соответственно снимает с нас как методологическое обязательство соблюдать такие методологические принципы") 3) Все вышеперечисленное соответственно снимает с нас как методологическое обязательство соблюдать такие методологические принципы как, например, «объяснять социальное социальным» ( и соответственно - не дает возможности объяснять «социальным» то, что социальным не объясняется, но в то же время должно защитить предмет социологии (социальное) от «эпистемических интервенций» других дисциплин (например, психологии) и в то же время снимает и делает нерелевантными кучу иных теоретико-методологических проблем, чем защищает от нападок «проклятых ревизионистов» ). В данном случае мы в описательной форме оперируем именно к тем объяснительным конструктам, которые уже проявлены в общественном сознании, но тем самым не становимся «слепы» к «парадоксам» и «нарушениям» каузальных связей, как например: «Алкоголиков много, потому что нет работы, а работы нет, потому что все алкоголики» – подобные моменты фиксируются нашей каузально-семантической матрицей за счет того, что вся информация сводится к общей структуре матрицы и мы можем наблюдать подобные «ловушки социальной реальности» .
3) Все вышеперечисленное соответственно снимает с нас как методологическое обязательство соблюдать такие методологические принципы как, например, «объяснять социальное социальным» ( и соответственно - не дает возможности объяснять «социальным» то, что социальным не объясняется, но в то же время должно защитить предмет социологии (социальное) от «эпистемических интервенций» других дисциплин (например, психологии) и в то же время снимает и делает нерелевантными кучу иных теоретико-методологических проблем, чем защищает от нападок «проклятых ревизионистов» ). В данном случае мы в описательной форме оперируем именно к тем объяснительным конструктам, которые уже проявлены в общественном сознании, но тем самым не становимся «слепы» к «парадоксам» и «нарушениям» каузальных связей, как например: «Алкоголиков много, потому что нет работы, а работы нет, потому что все алкоголики» – подобные моменты фиксируются нашей каузально-семантической матрицей за счет того, что вся информация сводится к общей структуре матрицы и мы можем наблюдать подобные «ловушки социальной реальности» .
 Данный метод позволяет решить проблему сопоставления и сравнения данных разных исследований (в том") 4) Данный метод позволяет решить проблему сопоставления и сравнения данных разных исследований (в том числе – и тематически совершенно различных). Понять значение цифр можно только в сравнении с другими цифрами, либо, если существуют какие-то интервалы, в которых могут колебаться эти цифры, что говорит опять же о том, что цифры состоят в некотором отношении и сравниваются между собой. При помощи данного метода можно сравнивать не только исследования на одну тематику, но и исследования на разные тематики при условии наличия в них тех или иных общих конструктов. Это даст возможность понять насколько вообще «траспонируемы» те или иные различные смысловые конструкты в различных смысловых тематических секторах общественного сознания и в каком отношении они проявляются. 5) Данный метод обработки решает проблемы «правильности» инструментария и в то же время проблему инструментария, как чего-то «стоящего между социальной реальностью и ученым» очень простым способом – его отсутствием. Это снимает требование, предъявляемые методологией к социологуэмпирику «строить правильный инструментарий» (анкету, бланк интервью, шкалы и пр. ), облегчая и делая «более разнообразной» их работу и в то же время останавливает «интеллектуальное варварство» последних.
4) Данный метод позволяет решить проблему сопоставления и сравнения данных разных исследований (в том числе – и тематически совершенно различных). Понять значение цифр можно только в сравнении с другими цифрами, либо, если существуют какие-то интервалы, в которых могут колебаться эти цифры, что говорит опять же о том, что цифры состоят в некотором отношении и сравниваются между собой. При помощи данного метода можно сравнивать не только исследования на одну тематику, но и исследования на разные тематики при условии наличия в них тех или иных общих конструктов. Это даст возможность понять насколько вообще «траспонируемы» те или иные различные смысловые конструкты в различных смысловых тематических секторах общественного сознания и в каком отношении они проявляются. 5) Данный метод обработки решает проблемы «правильности» инструментария и в то же время проблему инструментария, как чего-то «стоящего между социальной реальностью и ученым» очень простым способом – его отсутствием. Это снимает требование, предъявляемые методологией к социологуэмпирику «строить правильный инструментарий» (анкету, бланк интервью, шкалы и пр. ), облегчая и делая «более разнообразной» их работу и в то же время останавливает «интеллектуальное варварство» последних.
 Данный метод дает возможность проверить эмпирические данные (мы в любой момент можем узнать,") 6) Данный метод дает возможность проверить эмпирические данные (мы в любой момент можем узнать, что же скрывается за обозначением того или иного конструкта, нажав соответствующую клавишу и «пробежавшись» по тем местам текстов респондентов, которые исследователь отнес к данному конструкту и увидеть как они «встроены в контекст» ) и уменьшает вероятность их фальсификации (для того, чтобы сфальсифицировать качественные данные нужна огромная фантазия, плюс – «повышенная сопоставимость» данных резко увеличивает риск «быть раскрытым» для «недобросовестного социолога» ). 7) Я надеюсь, что данный метод внесет свой вклад в методологическую войну «качественников» и «количественников» и в чем-то «примирит» их. 8) Метод дает большие познавательные возможности за счет использования вычислительных мощностей компьютера и применения статистической и специфической (отсутствующей у других методов) математической обработки полученной каузально-семантической матрицы
6) Данный метод дает возможность проверить эмпирические данные (мы в любой момент можем узнать, что же скрывается за обозначением того или иного конструкта, нажав соответствующую клавишу и «пробежавшись» по тем местам текстов респондентов, которые исследователь отнес к данному конструкту и увидеть как они «встроены в контекст» ) и уменьшает вероятность их фальсификации (для того, чтобы сфальсифицировать качественные данные нужна огромная фантазия, плюс – «повышенная сопоставимость» данных резко увеличивает риск «быть раскрытым» для «недобросовестного социолога» ). 7) Я надеюсь, что данный метод внесет свой вклад в методологическую войну «качественников» и «количественников» и в чем-то «примирит» их. 8) Метод дает большие познавательные возможности за счет использования вычислительных мощностей компьютера и применения статистической и специфической (отсутствующей у других методов) математической обработки полученной каузально-семантической матрицы
 Метод позволяет моделировать тематические сектора общественного сознание и") Методологические минусы метода каузальносемантических матриц 1) Метод позволяет моделировать тематические сектора общественного сознание и те смыслы (не важно трансцендентные или повседневные), которые люди придают своим действиям, намерениям и побуждениям, метод вскрывает пласты наиболее распространенных в обществе представлений о реальности (которые не только отражают реальность, но и могут содержать различного рода мифы и иллюзии с научной точки зрения), но это еще не дает нам полной уверенности в том, что «люди будут действовать так же как они говорят» потому что в ряде ситуаций «люди говорят одно, думают другое, делают третье, хотят четвертое (или вообще не понимают и не осознают, что они хотят), а в итоге получают совершенно пятое» . Данный метод лучше использовать в тех ситуациях, где расхождения между тем, «что респонденты думают» , тем «что респонденты говорят» , и тем «что респонденты делают» отсутствует или незначительно. Во всех остальных случаях этот метод может использоваться лишь как дополнительный, например, к методу наблюдения.
Методологические минусы метода каузальносемантических матриц 1) Метод позволяет моделировать тематические сектора общественного сознание и те смыслы (не важно трансцендентные или повседневные), которые люди придают своим действиям, намерениям и побуждениям, метод вскрывает пласты наиболее распространенных в обществе представлений о реальности (которые не только отражают реальность, но и могут содержать различного рода мифы и иллюзии с научной точки зрения), но это еще не дает нам полной уверенности в том, что «люди будут действовать так же как они говорят» потому что в ряде ситуаций «люди говорят одно, думают другое, делают третье, хотят четвертое (или вообще не понимают и не осознают, что они хотят), а в итоге получают совершенно пятое» . Данный метод лучше использовать в тех ситуациях, где расхождения между тем, «что респонденты думают» , тем «что респонденты говорят» , и тем «что респонденты делают» отсутствует или незначительно. Во всех остальных случаях этот метод может использоваться лишь как дополнительный, например, к методу наблюдения.
 Метод предназначен для обработки текстовой информации. Это означает, что изначально в нем не") 2) Метод предназначен для обработки текстовой информации. Это означает, что изначально в нем не заложена фиксация никакого «фреймированного контекста» , «контекста ситуации» , «контекста дискурса» , он предназначен именно для работы с текстовыми данными и вынужден абстрагироваться от иных данных, которые мы можем получить по зрительному каналу (например: фото, видео), а так же всех тех, которые передаются по аудиальному и тактильному чувственным каналам получения информации. Мы отгораживаемся от существенной части внешних проявлений эмоций респондента, несмотря на то, что они могут быть зафиксированы в стиле и модальности его ответа, а так же может быть объективно зафиксирован факт использования тех или иных экспрессивных выражений и жаргонных слов, а так же слов свидетельствующих об особенностях когнитивного стиля, преобладающих в данной смысловом секторе социальной реальности и его субкультурных группах. В этом смысле метод больше направлен на то, чтобы зафиксировать «что сказали респонденты» и очень слабо захватывает то «как они это сказали» (мы ловим лишь то, что респонденты транспонировали и что в принципе переводимо в текстовую форму). Впрочем, это не является критическим недостатком метода, так как большинство других методов его не лишены, а абстрагирование является вынужденным.
2) Метод предназначен для обработки текстовой информации. Это означает, что изначально в нем не заложена фиксация никакого «фреймированного контекста» , «контекста ситуации» , «контекста дискурса» , он предназначен именно для работы с текстовыми данными и вынужден абстрагироваться от иных данных, которые мы можем получить по зрительному каналу (например: фото, видео), а так же всех тех, которые передаются по аудиальному и тактильному чувственным каналам получения информации. Мы отгораживаемся от существенной части внешних проявлений эмоций респондента, несмотря на то, что они могут быть зафиксированы в стиле и модальности его ответа, а так же может быть объективно зафиксирован факт использования тех или иных экспрессивных выражений и жаргонных слов, а так же слов свидетельствующих об особенностях когнитивного стиля, преобладающих в данной смысловом секторе социальной реальности и его субкультурных группах. В этом смысле метод больше направлен на то, чтобы зафиксировать «что сказали респонденты» и очень слабо захватывает то «как они это сказали» (мы ловим лишь то, что респонденты транспонировали и что в принципе переводимо в текстовую форму). Впрочем, это не является критическим недостатком метода, так как большинство других методов его не лишены, а абстрагирование является вынужденным.
 Программный интерфейс Causal-Semantic Matrix и техника проведения исследования методом каузальносемантической матрицы Начальный этап работы с программой Causal-Semantic Matrix начинается с оформления окна исследования.
Программный интерфейс Causal-Semantic Matrix и техника проведения исследования методом каузальносемантической матрицы Начальный этап работы с программой Causal-Semantic Matrix начинается с оформления окна исследования.
 Так выглядит окно добавления дополнительных переменных, которые можно зафиксировать в результате наблюдения или доп. вопроса: пол, возраст, уровень образования и т. д.
Так выглядит окно добавления дополнительных переменных, которые можно зафиксировать в результате наблюдения или доп. вопроса: пол, возраст, уровень образования и т. д.
 Ввод данных
Ввод данных
 Выделять исследовательские конструкты можно как обрабатывая полный объем информации с позиции: «я знаю, что не знаю ничего» , так и опираясь на какую-либо теорию (но первый вариант предпочтительнее). Тем не менее опираясь на теории можно, например, построить следующие типы смысловых пространств: пространство возможностей, пространство потребностей, пространство мотивов, пространство целей и средств, пространство социальных фактов, пространство прогнозов (вариантов развития явления), пространство ценностей, пространство диспозиций, пространство идентификаций, пространство «друзей и врагов» (как вариант – «союзников и противников» ), пространство легитимных социальных институтов, пространство «доверительных источников информации» , пространство «реальности знаний» (не в значении «истинных» , а в значении, «воспринимаемых как реальные» ), пространство ассоциаций, пространство эмоций, пространство «ссылок на первоисточники» (как вариант эмпирического исследования в социологии науки) и т. д.
Выделять исследовательские конструкты можно как обрабатывая полный объем информации с позиции: «я знаю, что не знаю ничего» , так и опираясь на какую-либо теорию (но первый вариант предпочтительнее). Тем не менее опираясь на теории можно, например, построить следующие типы смысловых пространств: пространство возможностей, пространство потребностей, пространство мотивов, пространство целей и средств, пространство социальных фактов, пространство прогнозов (вариантов развития явления), пространство ценностей, пространство диспозиций, пространство идентификаций, пространство «друзей и врагов» (как вариант – «союзников и противников» ), пространство легитимных социальных институтов, пространство «доверительных источников информации» , пространство «реальности знаний» (не в значении «истинных» , а в значении, «воспринимаемых как реальные» ), пространство ассоциаций, пространство эмоций, пространство «ссылок на первоисточники» (как вариант эмпирического исследования в социологии науки) и т. д.
 Конструкты должны быть эмпирически существующими (мы должны выделять") Базовые принципы построения исследовательских конструктов: 1) Конструкты должны быть эмпирически существующими (мы должны выделять их из текста, данного нам в нашем источнике качественной информации). 2) Конструкты должны отвечать, соответствовать, либо быть как-то по смыслу связанными с предметом нашего исследования, либо отвечать на поставленный исследователем вопрос 3) Фразы для построения конструктов должны быть максимально краткими, но замкнутыми по смыслу (например, как мы уже приводили выше пример: «идеальный преподаватель – понимающий преподаватель» - достаточно замкнутая по смыслу фраза ). 4) Если неизвестно, что считать «кратким» конструктом – следует выделить все (2 – больше маловероятно) варианты, поставив между большим и меньшим(и) вариантами связь принадлежности 5) Фразы для построения конструктов должны быть типичными (например, фразы: «идеальный преподаватель осведомлен об интересах современной молодежи» и фраза «идеальный преподаватель находится на одной волне с современной молодежью» - типичные фразы и, несмотря на то, что выражены в различном сочетании слов и символов - имеют идентичное смысловое значение). 6) Слова, сочетания слов и фразы для построения конструктов должны быть относительно самодостаточными без контекста, но применяться в одном контексте (например, фраза, которую мы уже приводили выше: «хачи не люди» не теряет своего смыслового значения в отрыве от контекста, тем не менее, чтобы стать нашим конструктом, она должна применяться в одном схожем контексте). 7) Выделенные конструкты должны в итоге иметь массовый характер, чтобы быть утвержденными в качестве значимого влияющего фактора.
Базовые принципы построения исследовательских конструктов: 1) Конструкты должны быть эмпирически существующими (мы должны выделять их из текста, данного нам в нашем источнике качественной информации). 2) Конструкты должны отвечать, соответствовать, либо быть как-то по смыслу связанными с предметом нашего исследования, либо отвечать на поставленный исследователем вопрос 3) Фразы для построения конструктов должны быть максимально краткими, но замкнутыми по смыслу (например, как мы уже приводили выше пример: «идеальный преподаватель – понимающий преподаватель» - достаточно замкнутая по смыслу фраза ). 4) Если неизвестно, что считать «кратким» конструктом – следует выделить все (2 – больше маловероятно) варианты, поставив между большим и меньшим(и) вариантами связь принадлежности 5) Фразы для построения конструктов должны быть типичными (например, фразы: «идеальный преподаватель осведомлен об интересах современной молодежи» и фраза «идеальный преподаватель находится на одной волне с современной молодежью» - типичные фразы и, несмотря на то, что выражены в различном сочетании слов и символов - имеют идентичное смысловое значение). 6) Слова, сочетания слов и фразы для построения конструктов должны быть относительно самодостаточными без контекста, но применяться в одном контексте (например, фраза, которую мы уже приводили выше: «хачи не люди» не теряет своего смыслового значения в отрыве от контекста, тем не менее, чтобы стать нашим конструктом, она должна применяться в одном схожем контексте). 7) Выделенные конструкты должны в итоге иметь массовый характер, чтобы быть утвержденными в качестве значимого влияющего фактора.
 Внизу под таблицами конструктов находится таблица: «Установите тип связи: » . Можно установить следующие типы связей: 1) Каузальная (где конструкт в таблице А – причина, а конструкт в таблице В – следствие, устанавливается, если респондент утверждает: «из … следует…» , «… является причиной…» , «…отсюда следует…» и т. д. , где субъективно отображается каузальная связь) , 2) Взаимозависимости (если наш респондент (или наш источник, личный документ) утверждает что-то с чем-то взаимосвязано, т. е. наличествует субъективно воспринимаемая взаимозависимость: «все взаимосвязано…» ) , 3) Принадлежности (где конструкт в таблице А принадлежит конструкту в таблице В и с точки зрения респондента что-то включает нечто другое, например «Образование включает воспитание» , «воспитание включает образование» и пр. ), 4)Взаимоуказания (само по себе одновременное указание респондентом каких-то конструктов не является связью в чистом виде, однако тот факт, что, одни респонденты выделяют таким образом одни конструкты (и соответственно – не выделяют другие), а другие – другие конструкты при значимых статистических нагрузках на этот тип связи может свидетельствовать о том, что данная связь в общественном сознании есть) 5) Ассоциации (самый непонятный тип связи, но если наличествует слова по типу «… у меня ассоциируется…» , «ассоциируется» и т. д. , то мы можем утверждать что имеется эдакая некоторая непонятная «до-разумная» связь, которую мы можем зафиксировать).
Внизу под таблицами конструктов находится таблица: «Установите тип связи: » . Можно установить следующие типы связей: 1) Каузальная (где конструкт в таблице А – причина, а конструкт в таблице В – следствие, устанавливается, если респондент утверждает: «из … следует…» , «… является причиной…» , «…отсюда следует…» и т. д. , где субъективно отображается каузальная связь) , 2) Взаимозависимости (если наш респондент (или наш источник, личный документ) утверждает что-то с чем-то взаимосвязано, т. е. наличествует субъективно воспринимаемая взаимозависимость: «все взаимосвязано…» ) , 3) Принадлежности (где конструкт в таблице А принадлежит конструкту в таблице В и с точки зрения респондента что-то включает нечто другое, например «Образование включает воспитание» , «воспитание включает образование» и пр. ), 4)Взаимоуказания (само по себе одновременное указание респондентом каких-то конструктов не является связью в чистом виде, однако тот факт, что, одни респонденты выделяют таким образом одни конструкты (и соответственно – не выделяют другие), а другие – другие конструкты при значимых статистических нагрузках на этот тип связи может свидетельствовать о том, что данная связь в общественном сознании есть) 5) Ассоциации (самый непонятный тип связи, но если наличествует слова по типу «… у меня ассоциируется…» , «ассоциируется» и т. д. , то мы можем утверждать что имеется эдакая некоторая непонятная «до-разумная» связь, которую мы можем зафиксировать).
 исследователь, руководствуясь точкой зрения респондента,") Между двумя конструктами (например, конструктом 1 и конструктом 7) исследователь, руководствуясь точкой зрения респондента, может провести только 1 тип связи. Однако, разные респонденты могут проводить между одними и теми же конструктами различные типы связей, в общественном сознании может существовать путаница по поводу того, что, например является причиной, а что следствием, что чему принадлежит и все это должно и будет учтено в итоге на каузально -семантической матрице. Кроме того, чисто гипотетически, у одного респондента между конструктом, например, 1 и 7 может быть проведена каузальная связь, между конструктом 1, 3, 6 – взаимозависимости, между 8 и 1 – принадлежности и т. д. , а у другого респондента может быть все по другому, в том числе и по другому указано направление причинно-следственной связи между конструктами (мы допускаем такую ситуацию, хоть и ищем в итоге общие моменты). Мы так же учитываем, что явления общественного сознания вполне могут иметь несколько причин и несколько следствий. Так как мы не можем учитывать все типы связей между всеми конструктами по всем респондентам одновременно, а только сосредотачиваться на каждом отдельном документе и имеющихся в нем конструктах и связях – связи будут сохраняться для каждого респондента отдельно в программе, а потом уже при переходе к каузально-семантической матрице она будет подсчитывать общие результаты.
Между двумя конструктами (например, конструктом 1 и конструктом 7) исследователь, руководствуясь точкой зрения респондента, может провести только 1 тип связи. Однако, разные респонденты могут проводить между одними и теми же конструктами различные типы связей, в общественном сознании может существовать путаница по поводу того, что, например является причиной, а что следствием, что чему принадлежит и все это должно и будет учтено в итоге на каузально -семантической матрице. Кроме того, чисто гипотетически, у одного респондента между конструктом, например, 1 и 7 может быть проведена каузальная связь, между конструктом 1, 3, 6 – взаимозависимости, между 8 и 1 – принадлежности и т. д. , а у другого респондента может быть все по другому, в том числе и по другому указано направление причинно-следственной связи между конструктами (мы допускаем такую ситуацию, хоть и ищем в итоге общие моменты). Мы так же учитываем, что явления общественного сознания вполне могут иметь несколько причин и несколько следствий. Так как мы не можем учитывать все типы связей между всеми конструктами по всем респондентам одновременно, а только сосредотачиваться на каждом отдельном документе и имеющихся в нем конструктах и связях – связи будут сохраняться для каждого респондента отдельно в программе, а потом уже при переходе к каузально-семантической матрице она будет подсчитывать общие результаты.
 Щелкнув на тот или иной конструкт в таблице вылетает следующее «окно свойств конструкта» . Здесь, помимо названия отображаются индикаторы конструкта, которые помогают исследователю, можно выбрать «эмоции конструкта» , т. е. по сути его модальность. В «трактовке и описание конструктов исследователь делает запись, которая при набирании конструктом значимых статистистических нагрузок выводится в отчет.
Щелкнув на тот или иной конструкт в таблице вылетает следующее «окно свойств конструкта» . Здесь, помимо названия отображаются индикаторы конструкта, которые помогают исследователю, можно выбрать «эмоции конструкта» , т. е. по сути его модальность. В «трактовке и описание конструктов исследователь делает запись, которая при набирании конструктом значимых статистистических нагрузок выводится в отчет.
 Щелкнув на «Добавить теорию» вы открываете окно добавления теорий. Так как Любая теория состоит из категорий данное окно предоставляет соответствующие возможности введения категорий и индикаторов, которые позволяют утверждать, что данный эмпирический материал описывается на языке данной теории.
Щелкнув на «Добавить теорию» вы открываете окно добавления теорий. Так как Любая теория состоит из категорий данное окно предоставляет соответствующие возможности введения категорий и индикаторов, которые позволяют утверждать, что данный эмпирический материал описывается на языке данной теории.
 Нажатие на клавишу «Добавить связь с вероятностной моделью поведения» открывается следующее окно. Модель поведения строится для определенной ситуации и является скорее «внешним наслоением» на каузально-семантическую матрицу. Модель поведения состоит из вариантов действий акторов.
Нажатие на клавишу «Добавить связь с вероятностной моделью поведения» открывается следующее окно. Модель поведения строится для определенной ситуации и является скорее «внешним наслоением» на каузально-семантическую матрицу. Модель поведения состоит из вариантов действий акторов.
 После того, как все документы забиты исследователь может перейти непосредственно к построению каузально-семантической матрицы. К сожалению у меня пока нет исследования проведенного в программе (но есть исследования проведенные этим же методом вручную) и само отображение каузально-семантической матрицы пока дорабатывается, но схематически окно перехода к Каузально-семантической матрице выглядит следующим образом:
После того, как все документы забиты исследователь может перейти непосредственно к построению каузально-семантической матрицы. К сожалению у меня пока нет исследования проведенного в программе (но есть исследования проведенные этим же методом вручную) и само отображение каузально-семантической матрицы пока дорабатывается, но схематически окно перехода к Каузально-семантической матрице выглядит следующим образом:
 В левом верхнем углу есть столбик «Конструкты» и возможности выделить «Выводить частоты» (производится расчёт и вывод на экран частот, т. е. повторений данных конструктов РАЗНЫМИ респондентами). Такая возможность есть как у конструктов, так и у связей. У конструктов частоты рассчитываются исходя из того, сколько респондентов выбрали данный конструкт (при этом, как мы уже сказали ДЛЯ ЧАСТОТ не важно сколько раз выбран тот или иной конструкт респондентом – он может его указать 1 раз, а может повторять ссылаться на конструкт 255 раз через каждое слово-два (это будет значимо для коэффициентов Min ind, Max ind, Mo ind) – для подсчета частот это абсолютно не важно, а важно только то, отметил тот или иной респондент тот или иной конструкт или связь определенного типа или нет и именно это наличие или отсутствие конструкта/связи у одного респондента, в одном личном документе кодируется как 1 или 0). Так же существует возможность «Выводить коэффициенты вероятности» . При выборе данной возможности производится расчёт коэффициентов вероятности у конструктов и соответственно – у связей. Что такое коэффициенты вероятности? Это количество случаев, в котором тот или иной конструкт или связь проявили свое существование (существуют), деленное на общее число случаев (в данном случае – это наша выборка). Коэффициенты вероятности рассчитываются по следующей формуле: P = Q/R, где P – коэффициент вероятности, Q – частоты, R – размер выборки. Графа «отображать условные обозначения» позволяет выводить вместо некоторых конструктов прикрепленные к ним рисунки, графа «Отображать только имя конструкта» позволяет выбрать отображение на каузальносемантической матрице только имени конструкта в целях удобства (вся дополнительная информация отображается при наведении курсора мыши на соответствующий конструкт в матрице).
В левом верхнем углу есть столбик «Конструкты» и возможности выделить «Выводить частоты» (производится расчёт и вывод на экран частот, т. е. повторений данных конструктов РАЗНЫМИ респондентами). Такая возможность есть как у конструктов, так и у связей. У конструктов частоты рассчитываются исходя из того, сколько респондентов выбрали данный конструкт (при этом, как мы уже сказали ДЛЯ ЧАСТОТ не важно сколько раз выбран тот или иной конструкт респондентом – он может его указать 1 раз, а может повторять ссылаться на конструкт 255 раз через каждое слово-два (это будет значимо для коэффициентов Min ind, Max ind, Mo ind) – для подсчета частот это абсолютно не важно, а важно только то, отметил тот или иной респондент тот или иной конструкт или связь определенного типа или нет и именно это наличие или отсутствие конструкта/связи у одного респондента, в одном личном документе кодируется как 1 или 0). Так же существует возможность «Выводить коэффициенты вероятности» . При выборе данной возможности производится расчёт коэффициентов вероятности у конструктов и соответственно – у связей. Что такое коэффициенты вероятности? Это количество случаев, в котором тот или иной конструкт или связь проявили свое существование (существуют), деленное на общее число случаев (в данном случае – это наша выборка). Коэффициенты вероятности рассчитываются по следующей формуле: P = Q/R, где P – коэффициент вероятности, Q – частоты, R – размер выборки. Графа «отображать условные обозначения» позволяет выводить вместо некоторых конструктов прикрепленные к ним рисунки, графа «Отображать только имя конструкта» позволяет выбрать отображение на каузальносемантической матрице только имени конструкта в целях удобства (вся дополнительная информация отображается при наведении курсора мыши на соответствующий конструкт в матрице).
 У связей так же можно выбирать «Выводить частоты» и «Выводить коэффициенты вероятностей» , но существует различие в подсчете частот – подсчитывается только то, что 2 объекта соединены связью и учитывается их тип (так же подсчитывается «общая связь» с целью проведения определенных математических процедур). Так же существует различие при отображении связей различного типа. Выбрав графу «Отображать тип связи» мы одновременно соглашаемся с 2 -мя действиями на матрице: во-первых, при наведении курсора отображаются все выбранные респондентами типы связей (различные респонденты могут между различными конструктами проводить различные типы связей, а так же – может возникать различное восприятие в каузальных связях и связях принадлежности), во вторых связь на каузально-семантической матрице принимает графическое отображение доминантного типа связи. Различные типы связи на матрице отображаются разными цветами: каузальная – красным, взаимозависимости – фиолетовым, принадлежности – зеленым, взаимоуказания – синим, ассоциации – оранжевым. Так же мы можем в принципе не выводить отдельные типы связей (исключительно для удобства восприятия). Это можно сделать, убрав галочки с соответствующих граф в столбце «Выводить связи следующих типов» . Помимо этого, если вдруг мы сталкиваемся с ситуацией, когда матрица «слишком большая» и не укладывается в нашем восприятии мы можем воспользоваться «методом ортодоксального позитивизма» (реальное в противовес химерическому, полезное в противовес бесполезному, точное в противовес смутному и т. д. ), т. е. в «Свойствах матрицы» отобрать значения, только имеющие определенную статистическую значимость по частотам или вероятностям. Помимо этого мы можем изменить настройки дополнительной информации (информации, отображающейся при наведении курсора мыши на связь или конструкт). И, наконец, мы можем при помощи этой программы иметь возможность проводить связи между конструктами различных баз данных.
У связей так же можно выбирать «Выводить частоты» и «Выводить коэффициенты вероятностей» , но существует различие в подсчете частот – подсчитывается только то, что 2 объекта соединены связью и учитывается их тип (так же подсчитывается «общая связь» с целью проведения определенных математических процедур). Так же существует различие при отображении связей различного типа. Выбрав графу «Отображать тип связи» мы одновременно соглашаемся с 2 -мя действиями на матрице: во-первых, при наведении курсора отображаются все выбранные респондентами типы связей (различные респонденты могут между различными конструктами проводить различные типы связей, а так же – может возникать различное восприятие в каузальных связях и связях принадлежности), во вторых связь на каузально-семантической матрице принимает графическое отображение доминантного типа связи. Различные типы связи на матрице отображаются разными цветами: каузальная – красным, взаимозависимости – фиолетовым, принадлежности – зеленым, взаимоуказания – синим, ассоциации – оранжевым. Так же мы можем в принципе не выводить отдельные типы связей (исключительно для удобства восприятия). Это можно сделать, убрав галочки с соответствующих граф в столбце «Выводить связи следующих типов» . Помимо этого, если вдруг мы сталкиваемся с ситуацией, когда матрица «слишком большая» и не укладывается в нашем восприятии мы можем воспользоваться «методом ортодоксального позитивизма» (реальное в противовес химерическому, полезное в противовес бесполезному, точное в противовес смутному и т. д. ), т. е. в «Свойствах матрицы» отобрать значения, только имеющие определенную статистическую значимость по частотам или вероятностям. Помимо этого мы можем изменить настройки дополнительной информации (информации, отображающейся при наведении курсора мыши на связь или конструкт). И, наконец, мы можем при помощи этой программы иметь возможность проводить связи между конструктами различных баз данных.
 Каузально-семантическая матрица: определение, описание и принцип работы Каузально-семантическая является моделью общественного сознания по определенной тематической релевантности и результатом обработки компьютером всех указанных конструктов и типов связей между ними, она есть результат подсчета статистических частотных нагрузок на конструкты и типы связей между ними. После нажатия кнопки «Перейти к каузально-семантической матрице» программа рассчитывает и строит её нам (К сожалению, я не могу показать точный интерфейс каузально-семантической матрицы, только ее приблизительный и весьма грубые аналоги). В центре располагаются наиболее статистически нагруженные конструкты и связи. Связи проводятся разной толщины (зависит от статистической нагрузки на связь) и разного цвета (зависит от доминантного типа связи). Толщина связей зависит от коэффициента вероятности (допустим, если за 1 мы возьмем толщину связи в 0, 5 см, то толщина связи между 2 -мя конструктами есть 0, 5*P см. , где P – коэффициент вероятности, сосредоточенный в промежутке [0; 1]). Конструкты имеют стандартный вид и окраску в зависимости от эмоциональной окраски: позитивные – зеленым, нейтральные – синим, негативные – красным. Примерную модель интерфейса каузально-семантической матрицы можно увидеть на следующем слайде.
Каузально-семантическая матрица: определение, описание и принцип работы Каузально-семантическая является моделью общественного сознания по определенной тематической релевантности и результатом обработки компьютером всех указанных конструктов и типов связей между ними, она есть результат подсчета статистических частотных нагрузок на конструкты и типы связей между ними. После нажатия кнопки «Перейти к каузально-семантической матрице» программа рассчитывает и строит её нам (К сожалению, я не могу показать точный интерфейс каузально-семантической матрицы, только ее приблизительный и весьма грубые аналоги). В центре располагаются наиболее статистически нагруженные конструкты и связи. Связи проводятся разной толщины (зависит от статистической нагрузки на связь) и разного цвета (зависит от доминантного типа связи). Толщина связей зависит от коэффициента вероятности (допустим, если за 1 мы возьмем толщину связи в 0, 5 см, то толщина связи между 2 -мя конструктами есть 0, 5*P см. , где P – коэффициент вероятности, сосредоточенный в промежутке [0; 1]). Конструкты имеют стандартный вид и окраску в зависимости от эмоциональной окраски: позитивные – зеленым, нейтральные – синим, негативные – красным. Примерную модель интерфейса каузально-семантической матрицы можно увидеть на следующем слайде.
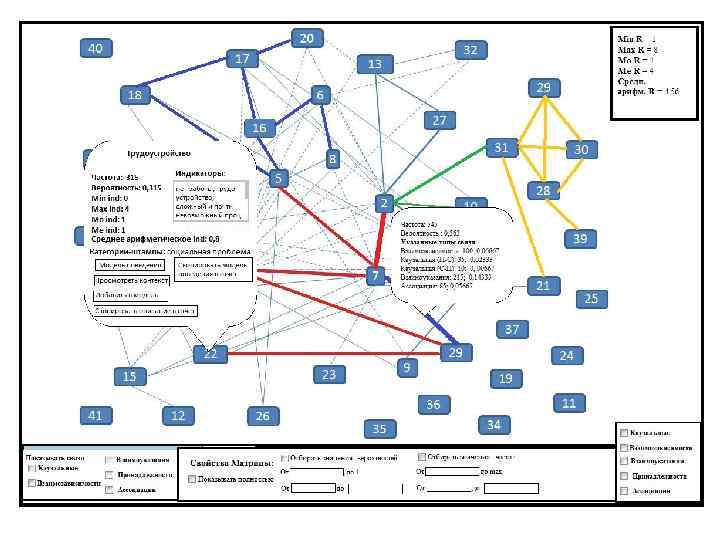
 Название конструкта, 2) Частоту, 3) Вероятность,") Дополнительная информация о конструкте включает в себя: 1) Название конструкта, 2) Частоту, 3) Вероятность, 4) Слова-индикаторы, 5) Фразы-индикаторы, 6) информацию о том, что к данному конструкту прикреплена модель поведения с n-ным количеством вариантов, 7) связи с конструктами других баз данных, 8) Показатели ind (включающие в себя, такие коэффициенты как Min ind, Max ind, Mo ind, Me ind, среднее арифметическое ind, означающие соответственно минимальное, максимальное, модальное, медианное и среднее арифметическое повторение одного и того же конструкта у КАЖДОГО ОТДЕЛЬНОГО респондента по выборке. На этих показателях следует остановиться отдельно и понять «Зачем они нам нужны? » . Суть в том, что для нас важно сколько раз один и тот же респондент повторяет один и тот же конструкт. Если индивид что-то повторяет чуть ли не через слово, то либо это крайне важно для этого индивида, либо этот конструкт стал содержанием сознания индивида относительно недавно (не успел надоесть и стать привычной областью «знания» ) и он, ведя активный мыслительный процесс «смакует» эту новую мысль, либо эта область крайне важна, либо играет какую-то роль именно при коммуникации с другими, выступает основным инструментом аргументации собственной позиции и словестном воздействия на других. В этом смысле эти показатели позволяют выявить «актуальную субъективную значимость» того или иного конструкта непосредственно для респондентов. На матрице помимо связей и конструктов присутствуют еще следующие показатели: Min R, Max R, Mo R, Me R, среднее арифметическое R. Они служат своего рода индикаторами для нахождения границ смысловой зоны Б, о которой речь пойдет чуть далее.
Дополнительная информация о конструкте включает в себя: 1) Название конструкта, 2) Частоту, 3) Вероятность, 4) Слова-индикаторы, 5) Фразы-индикаторы, 6) информацию о том, что к данному конструкту прикреплена модель поведения с n-ным количеством вариантов, 7) связи с конструктами других баз данных, 8) Показатели ind (включающие в себя, такие коэффициенты как Min ind, Max ind, Mo ind, Me ind, среднее арифметическое ind, означающие соответственно минимальное, максимальное, модальное, медианное и среднее арифметическое повторение одного и того же конструкта у КАЖДОГО ОТДЕЛЬНОГО респондента по выборке. На этих показателях следует остановиться отдельно и понять «Зачем они нам нужны? » . Суть в том, что для нас важно сколько раз один и тот же респондент повторяет один и тот же конструкт. Если индивид что-то повторяет чуть ли не через слово, то либо это крайне важно для этого индивида, либо этот конструкт стал содержанием сознания индивида относительно недавно (не успел надоесть и стать привычной областью «знания» ) и он, ведя активный мыслительный процесс «смакует» эту новую мысль, либо эта область крайне важна, либо играет какую-то роль именно при коммуникации с другими, выступает основным инструментом аргументации собственной позиции и словестном воздействия на других. В этом смысле эти показатели позволяют выявить «актуальную субъективную значимость» того или иного конструкта непосредственно для респондентов. На матрице помимо связей и конструктов присутствуют еще следующие показатели: Min R, Max R, Mo R, Me R, среднее арифметическое R. Они служат своего рода индикаторами для нахождения границ смысловой зоны Б, о которой речь пойдет чуть далее.
 Математическая обработка каузально-семантической матрицы. Инструменты для работы с матрицей. Сама по себе каузально-семантическая матрица просто позволяет взглянуть и ответить на вопрос «Каким является общественное сознание по данной тематической релевантности? » . Однако то, что связи и конструкты, а так же показатели на матрице имеют числовое и вероятностное выражение позволяет применить к ее анализу различного рода математические алгоритмы и сделать каузально-семантическую матрицу необходимой и незаменимой на практике. Например, мы можем вычислить содержание сознание того или иного актора, либо сравнить и понять в чем схожи, а в чем отличны социокультурные особенности тех или иных социальных групп – найти общие черты и различия между содержаниями сознания групп и акторов и определить место того или иного актора на общей каузально-семантической матрице данного смыслового сектора. Графически это можно представить следующим образом:
Математическая обработка каузально-семантической матрицы. Инструменты для работы с матрицей. Сама по себе каузально-семантическая матрица просто позволяет взглянуть и ответить на вопрос «Каким является общественное сознание по данной тематической релевантности? » . Однако то, что связи и конструкты, а так же показатели на матрице имеют числовое и вероятностное выражение позволяет применить к ее анализу различного рода математические алгоритмы и сделать каузально-семантическую матрицу необходимой и незаменимой на практике. Например, мы можем вычислить содержание сознание того или иного актора, либо сравнить и понять в чем схожи, а в чем отличны социокультурные особенности тех или иных социальных групп – найти общие черты и различия между содержаниями сознания групп и акторов и определить место того или иного актора на общей каузально-семантической матрице данного смыслового сектора. Графически это можно представить следующим образом:
 Задачу поиска «местонахождения актора на смысловой матрице» мы можем выразить так: «Мы имеем общую каузально-семантическую матрицу и на нашей схеме она обозначена как «Зона А» . Мы имеем, то, что сказал тот или иной интересующий нас субъект (мы, чисто гипотетически, стенографировали или как-то записали это, например, на диктофон) и после того, как мы прогоним эту информацию через аналитические алгоритмы каузально-семантической матрицы мы можем получить «местонахождение того, что мы точно имеем» и на нашей схеме это обозначено, как «Зона В» Мы предполагаем, что содержание сознания актора отнюдь не ограничено тем, что он нам сказал и хотим выяснить то, что он не сказал» . Эта зона «предполагаемо наличествующего, но неизвестного» мы обозначим как «Зона Б» . Конструкты и связи на нашей матрице имеют вероятностное выражение и мы так же можем с определенной долей вероятности (которую мы устанавливаем, как «доверительную» ) определить содержание этой «Зоны Б» . Для того, чтобы «не уйти за границы зоны Б» у нас есть уже приведенные выше показатели: Min R, Max R, Mo R, Me R, среднее арифметическое R, которые показывают количество выделенных РАЗНЫХ конструктов различными респондентами по выборке и служат своего рода индикаторами для нахождения границ зоны Б. Иными словами количество «найденных» конструктов, соответствующее показателю R act не должно превышать границ, определенных показателями Min R, Max R, Mo R, Me R, среднее арифметическое R. На основании изложенного давайте рассмотрим инструменты, с помощью которых мы можем вычислить неизвестное на основе нашей каузальносемантической матрицы.
Задачу поиска «местонахождения актора на смысловой матрице» мы можем выразить так: «Мы имеем общую каузально-семантическую матрицу и на нашей схеме она обозначена как «Зона А» . Мы имеем, то, что сказал тот или иной интересующий нас субъект (мы, чисто гипотетически, стенографировали или как-то записали это, например, на диктофон) и после того, как мы прогоним эту информацию через аналитические алгоритмы каузально-семантической матрицы мы можем получить «местонахождение того, что мы точно имеем» и на нашей схеме это обозначено, как «Зона В» Мы предполагаем, что содержание сознания актора отнюдь не ограничено тем, что он нам сказал и хотим выяснить то, что он не сказал» . Эта зона «предполагаемо наличествующего, но неизвестного» мы обозначим как «Зона Б» . Конструкты и связи на нашей матрице имеют вероятностное выражение и мы так же можем с определенной долей вероятности (которую мы устанавливаем, как «доверительную» ) определить содержание этой «Зоны Б» . Для того, чтобы «не уйти за границы зоны Б» у нас есть уже приведенные выше показатели: Min R, Max R, Mo R, Me R, среднее арифметическое R, которые показывают количество выделенных РАЗНЫХ конструктов различными респондентами по выборке и служат своего рода индикаторами для нахождения границ зоны Б. Иными словами количество «найденных» конструктов, соответствующее показателю R act не должно превышать границ, определенных показателями Min R, Max R, Mo R, Me R, среднее арифметическое R. На основании изложенного давайте рассмотрим инструменты, с помощью которых мы можем вычислить неизвестное на основе нашей каузальносемантической матрицы.
 Линия наибольшей вероятности Расположение: Инструменты/Каузально-семантическая матрица/Линия наибольшей вероятности Самый простейший инструмент. Выбрав графу «Инструменты в верхней части окна мы находим инструмент «Линия наибольшей вероятности» и «ткнув» этим инструментом в любой элемент каузально-семантической матрицы или окна моделирования получаем линию, которая идет из этого элемента по наиболее вероятным, связанным с этим элементом, конструктам и связям вплоть до окончания данного среза матрицы (без перехода на другие базы, если они уже не включены в область моделирования).
Линия наибольшей вероятности Расположение: Инструменты/Каузально-семантическая матрица/Линия наибольшей вероятности Самый простейший инструмент. Выбрав графу «Инструменты в верхней части окна мы находим инструмент «Линия наибольшей вероятности» и «ткнув» этим инструментом в любой элемент каузально-семантической матрицы или окна моделирования получаем линию, которая идет из этого элемента по наиболее вероятным, связанным с этим элементом, конструктам и связям вплоть до окончания данного среза матрицы (без перехода на другие базы, если они уже не включены в область моделирования).
 Отрезок наибольшей вероятности Так же – достаточно простой инструмент. Выбрав его: Инструменты/Каузально-семантическая матрица/Отрезок наибольшей вероятности нам выдается диалоговое окно, в котором мы указываем доверительную вероятность. Допустим, эта доверительная вероятность будет равна 0, 75. Щелкнув инструментом «Отрезок наибольшей вероятности» в любое место нашей каузально-семантической матрицы или окна моделирования мы получаем ту же «линию наибольшей вероятности» , только «обрезанную» . Суть в том, что отрезок развивается по наиболее вероятным конструктам и связям «по пути» перемножая вероятности существования данных конструктов и связей (при этом связанные связь и конструкт не перемножаются, а между ними ищется среднее арифметическое значение, а затем это значение перемножается со следующей связью и конструктом, это делается так, потому что связь не может существовать без конструкта, а конструкт не может быть вычислен без связи) до тех пор, пока результат данных перемножений значений вероятности не станет меньше 0, 75.
Отрезок наибольшей вероятности Так же – достаточно простой инструмент. Выбрав его: Инструменты/Каузально-семантическая матрица/Отрезок наибольшей вероятности нам выдается диалоговое окно, в котором мы указываем доверительную вероятность. Допустим, эта доверительная вероятность будет равна 0, 75. Щелкнув инструментом «Отрезок наибольшей вероятности» в любое место нашей каузально-семантической матрицы или окна моделирования мы получаем ту же «линию наибольшей вероятности» , только «обрезанную» . Суть в том, что отрезок развивается по наиболее вероятным конструктам и связям «по пути» перемножая вероятности существования данных конструктов и связей (при этом связанные связь и конструкт не перемножаются, а между ними ищется среднее арифметическое значение, а затем это значение перемножается со следующей связью и конструктом, это делается так, потому что связь не может существовать без конструкта, а конструкт не может быть вычислен без связи) до тех пор, пока результат данных перемножений значений вероятности не станет меньше 0, 75.
 Метод математической дедукции Расположение: Инструменты/Каузально-семантическая матрица/Метод математической дедукции Применяя метод математической дедукции мы идем дедуктивным методом, т. е. «от общего к частному» - мы предполагаем, что наш актор – «нормальная» модальная личность относительно нашей выборочной совокупности. Для данной «модальной личности» релевантны все значения, которые релевантны для большей части нашего общества, следовательно, варианты, набравшие наибольшие частоты выбора и соответственно – наиболее вероятные относительно общей (либо смоделированной – это нужно указать относительно какого основания мы применяем метод математической дедукции) матрицы. Как работает метод математической дедукции? Для начала, как и в методе «Отрезок наибольшей вероятности» нам надо указать доверительную вероятность. Работает он так же сходным образом, только идет не по наиболее вероятным, а по каждому варианту в отдельности находя средняя арифметическое между вероятностями существования связи и конструкта (так как существование связи бессмысленно без конструкта, а конструкт не может быть вычислен без связи) и перемножая это с другими подобными значениями до тех пор, пока перемноженный результат по каждому из вариантов не станет меньше заданной доверительной вероятности. Метод математической дедукции можно использовать и после использования метода типичных ситуаций – в этом случае существенно повысив вероятность «ближайших» вариантов и отбросив варианты не соответствующие данному типу личности мы утверждаем, что « в остальном актор нормален (модален) относительно нашей выборочной совокупности и уже на основании вероятностей от общей матрицы вычислим оставшееся содержание его сознания и наиболее вероятные варианты действий.
Метод математической дедукции Расположение: Инструменты/Каузально-семантическая матрица/Метод математической дедукции Применяя метод математической дедукции мы идем дедуктивным методом, т. е. «от общего к частному» - мы предполагаем, что наш актор – «нормальная» модальная личность относительно нашей выборочной совокупности. Для данной «модальной личности» релевантны все значения, которые релевантны для большей части нашего общества, следовательно, варианты, набравшие наибольшие частоты выбора и соответственно – наиболее вероятные относительно общей (либо смоделированной – это нужно указать относительно какого основания мы применяем метод математической дедукции) матрицы. Как работает метод математической дедукции? Для начала, как и в методе «Отрезок наибольшей вероятности» нам надо указать доверительную вероятность. Работает он так же сходным образом, только идет не по наиболее вероятным, а по каждому варианту в отдельности находя средняя арифметическое между вероятностями существования связи и конструкта (так как существование связи бессмысленно без конструкта, а конструкт не может быть вычислен без связи) и перемножая это с другими подобными значениями до тех пор, пока перемноженный результат по каждому из вариантов не станет меньше заданной доверительной вероятности. Метод математической дедукции можно использовать и после использования метода типичных ситуаций – в этом случае существенно повысив вероятность «ближайших» вариантов и отбросив варианты не соответствующие данному типу личности мы утверждаем, что « в остальном актор нормален (модален) относительно нашей выборочной совокупности и уже на основании вероятностей от общей матрицы вычислим оставшееся содержание его сознания и наиболее вероятные варианты действий.
 Метод типичных ситуаций Расположение: Инструменты/Каузально-семантическая матрица/Метод типичных ситуаций. Применяя метод типичных ситуаций мы сосредотачиваемся на индивидуально-типичных особенностях нашего актора мы идем путем «от частного к частному» , сосредотачивая внимание на наиболее уникальных особенностях нашего актора. Данный метод используется когда важны различия и уникальные черты. Есть 2 способа применения метода типичных ситуаций: ручной и автоматический. При автоматическом способе мы устанавливаем необходимую степень сходства, выраженную в процентном соотношении (от тех конструктов и связей, которые мы точно имеем) и программа ищет по нашей выборке респондентов, которые указывали такие же конструкты и связи и добавляет другие выделенные этими же респондентами. В результате происходит изменение выборки (выборка из выборки) и соответственно – пересчет вероятностей (мы получаем более точные и с большей вероятностью варианты). При ручном методе типичных ситуаций исследователь должен сам отбирать, что (какие конструкты и связи) компьютер должен искать (иногда это наиболее полезно, поскольку лишь живой субъект способен указать, что его реально интересует, а что не важно и можно опустить). В этом случае так же происходит отбор респондентов из нашей выборки, уменьшение размера выборки в результате «выборки из выборки» и получение наиболее точных и вероятных конструктов. Очень важной возможностью этого алгоритма является именно повышение вероятности у ближайших по матрице вариантов существующих связей и конструктов.
Метод типичных ситуаций Расположение: Инструменты/Каузально-семантическая матрица/Метод типичных ситуаций. Применяя метод типичных ситуаций мы сосредотачиваемся на индивидуально-типичных особенностях нашего актора мы идем путем «от частного к частному» , сосредотачивая внимание на наиболее уникальных особенностях нашего актора. Данный метод используется когда важны различия и уникальные черты. Есть 2 способа применения метода типичных ситуаций: ручной и автоматический. При автоматическом способе мы устанавливаем необходимую степень сходства, выраженную в процентном соотношении (от тех конструктов и связей, которые мы точно имеем) и программа ищет по нашей выборке респондентов, которые указывали такие же конструкты и связи и добавляет другие выделенные этими же респондентами. В результате происходит изменение выборки (выборка из выборки) и соответственно – пересчет вероятностей (мы получаем более точные и с большей вероятностью варианты). При ручном методе типичных ситуаций исследователь должен сам отбирать, что (какие конструкты и связи) компьютер должен искать (иногда это наиболее полезно, поскольку лишь живой субъект способен указать, что его реально интересует, а что не важно и можно опустить). В этом случае так же происходит отбор респондентов из нашей выборки, уменьшение размера выборки в результате «выборки из выборки» и получение наиболее точных и вероятных конструктов. Очень важной возможностью этого алгоритма является именно повышение вероятности у ближайших по матрице вариантов существующих связей и конструктов.
 Метод сравнения структур не является методом для анализа индивидуального поведения акторов – он является методом для сравнения сходств и различий различных групп и статистического поиска социальных законов и закономерностей. Он используется при сравнении баз и статистических нагрузок на общие конструкты этих баз, а так же – при сравнении структур, полученных в результате обработки общей матрицы. Допустим, мы знаем (установили соответствия конструктов), что База 1 и База 56 имеют n-ный набор общих конструктов. В данном случае это может быть сравнением статистических показателей частотных нагрузок конструктов по времени, (например база 2013 и 2014 годов одной и той же ген. совокупности), либо сравнение статистических нагрузок структур двух различных, но сходных по роду деятельности, социализации и образу жизни групп (например «студенты-социологи 2 -го и 3 -го курсов» ). В этом случае задав доверительное отклонение (которое должно равняться показателю ошибки выборки) сравниваем структуры и частотные нагрузки на качественную и количественную идентичность. На основании этого так же можно сделать те или иные выводы. Если у нас есть несколько баз по времени, например 2009, 2010, 2011, 2012, 2013 и т. д. забив эти базы в метод сравнения структур, мы можем обнаружить те или иные тенденции общественного сознания в их динамике и, соответственно, глубже понять суть изучаемого предмета и открыть новые социологические законы
Метод сравнения структур не является методом для анализа индивидуального поведения акторов – он является методом для сравнения сходств и различий различных групп и статистического поиска социальных законов и закономерностей. Он используется при сравнении баз и статистических нагрузок на общие конструкты этих баз, а так же – при сравнении структур, полученных в результате обработки общей матрицы. Допустим, мы знаем (установили соответствия конструктов), что База 1 и База 56 имеют n-ный набор общих конструктов. В данном случае это может быть сравнением статистических показателей частотных нагрузок конструктов по времени, (например база 2013 и 2014 годов одной и той же ген. совокупности), либо сравнение статистических нагрузок структур двух различных, но сходных по роду деятельности, социализации и образу жизни групп (например «студенты-социологи 2 -го и 3 -го курсов» ). В этом случае задав доверительное отклонение (которое должно равняться показателю ошибки выборки) сравниваем структуры и частотные нагрузки на качественную и количественную идентичность. На основании этого так же можно сделать те или иные выводы. Если у нас есть несколько баз по времени, например 2009, 2010, 2011, 2012, 2013 и т. д. забив эти базы в метод сравнения структур, мы можем обнаружить те или иные тенденции общественного сознания в их динамике и, соответственно, глубже понять суть изучаемого предмета и открыть новые социологические законы
 Дополнительные переменные и социометрия В данной программе будут реализованы часть функций SPSS (корреляции, таблицы сопряженности) и задан инструмент для проведения социометрического исследования. Социометрия как инструмент имеет полностью соответствует данному социологическому инструменту получения информации, но при этом связана с каузально-семантической матрицей. В добавление к социометрии и в частности социограмме мы можем связать её с каузально-семантической матрицей. Сделать это можно по принципу – принадлежность к кругу. В частности – вот у нас есть лидер на социограмме, он единственный принадлежит к 1 -ому центральному кругу – нажав на него и выбрав действие мы можем узнать содержание его сознания (в частности связать социометрию и каузально-семантическую матрицу можно так же по порядковому номеру – порядковый номер присваиваемый члену группы соответствует порядковому номеру текстового документа в базе каузально-семантической матрицы), вот у нас есть его «приближенные» - 2 круг, в этом случае опять производится «выборка из выборки» по порядковому номеру и учитывается содержание сознание всех принадлежащих ко 2 -му кругу, затем к 3 -ему и пр. Нам может быть интересно, как содержание сознания «Звезды» и «Отверженного» , так и содержание сознания рядовых членов группы и аутсайдеров. Так же можно связать определенные уровни показателей социометрии для каждого индивида с повторяющимися мнениями других членов группы об этом индивиде и вычленить каким показателям репутации соответствуют какие приписываемые качества. Принадлежность к кругам можно определить путем пропорционального представления индексов.
Дополнительные переменные и социометрия В данной программе будут реализованы часть функций SPSS (корреляции, таблицы сопряженности) и задан инструмент для проведения социометрического исследования. Социометрия как инструмент имеет полностью соответствует данному социологическому инструменту получения информации, но при этом связана с каузально-семантической матрицей. В добавление к социометрии и в частности социограмме мы можем связать её с каузально-семантической матрицей. Сделать это можно по принципу – принадлежность к кругу. В частности – вот у нас есть лидер на социограмме, он единственный принадлежит к 1 -ому центральному кругу – нажав на него и выбрав действие мы можем узнать содержание его сознания (в частности связать социометрию и каузально-семантическую матрицу можно так же по порядковому номеру – порядковый номер присваиваемый члену группы соответствует порядковому номеру текстового документа в базе каузально-семантической матрицы), вот у нас есть его «приближенные» - 2 круг, в этом случае опять производится «выборка из выборки» по порядковому номеру и учитывается содержание сознание всех принадлежащих ко 2 -му кругу, затем к 3 -ему и пр. Нам может быть интересно, как содержание сознания «Звезды» и «Отверженного» , так и содержание сознания рядовых членов группы и аутсайдеров. Так же можно связать определенные уровни показателей социометрии для каждого индивида с повторяющимися мнениями других членов группы об этом индивиде и вычленить каким показателям репутации соответствуют какие приписываемые качества. Принадлежность к кругам можно определить путем пропорционального представления индексов.
 Радикализация по естественным группам Крайне полезный «мягкий» инструмент для работы с каузально-семантической матрицей. Позволит разделить каузально-семантические матрицы на «естественные группы» по принципу содержания их сознания. В этом смысле в отличие от «жестких» инструментов (как, например, «целевая выборка» ), в которых группы выделяются на основе «объективных переменных» и построение каузально-семантических матриц так же на основе их, в этом инструменте на основе общей каузально-семантической матрицы выделяются «группы» и связанные с ними объективные характеристики. Суть в том, что на каузально семантической матрице большую статистическую (и, соответственно, вероятностную нагрузку будут иметь те конструкты, которые отвечают тем или иным потребностям (первичным или вторичным – не важно), интересам, мотивам, привычкам, ценностям и ценностным ориентациям и т. д. , т. е. всего того, что «объективированно» важно (вне зависимости даже от того, что это) и определяет поведение индивида или группы. Инструмент радикализации позволит выделить эти «естественные группы» .
Радикализация по естественным группам Крайне полезный «мягкий» инструмент для работы с каузально-семантической матрицей. Позволит разделить каузально-семантические матрицы на «естественные группы» по принципу содержания их сознания. В этом смысле в отличие от «жестких» инструментов (как, например, «целевая выборка» ), в которых группы выделяются на основе «объективных переменных» и построение каузально-семантических матриц так же на основе их, в этом инструменте на основе общей каузально-семантической матрицы выделяются «группы» и связанные с ними объективные характеристики. Суть в том, что на каузально семантической матрице большую статистическую (и, соответственно, вероятностную нагрузку будут иметь те конструкты, которые отвечают тем или иным потребностям (первичным или вторичным – не важно), интересам, мотивам, привычкам, ценностям и ценностным ориентациям и т. д. , т. е. всего того, что «объективированно» важно (вне зависимости даже от того, что это) и определяет поведение индивида или группы. Инструмент радикализации позволит выделить эти «естественные группы» .
 Представим, что есть некоторое количество респондентов А, указавших «конструкт 1» и есть некоторое число респондентов В, указавших «конструкт 2» . При этом часть респондентов А указала конструкт 2, а часть респондентов В указали конструкт 1 соответственно. Пусть данное число респондентов будет обозначено переменной С. Помимо этого, мы видим, что эти 2 конструкта указала далеко не вся выборка каузально-семантической матрицы, а какая-то ее часть. Эту часть респондентов, которую охватывает существование наших конструктов 1 и 2 мы назовем переменной D. Для удобства восприятия представим это графически:
Представим, что есть некоторое количество респондентов А, указавших «конструкт 1» и есть некоторое число респондентов В, указавших «конструкт 2» . При этом часть респондентов А указала конструкт 2, а часть респондентов В указали конструкт 1 соответственно. Пусть данное число респондентов будет обозначено переменной С. Помимо этого, мы видим, что эти 2 конструкта указала далеко не вся выборка каузально-семантической матрицы, а какая-то ее часть. Эту часть респондентов, которую охватывает существование наших конструктов 1 и 2 мы назовем переменной D. Для удобства восприятия представим это графически:
 Тогда V – показатель связи этих двух конструктов. Показатель V будет вычисляться по формуле: Таким образом, данный показатель сосредоточен в промежутке от 0 до 1. Это простейшая взаимосвязь между конструктами. А теперь переходим к следующей части – программа рассчитывает (но не выводит на экран) подобного рода связи между всеми связанными конструктами на матрице. Далее на основании этих найденных показателей происходит отбор и разделение на группы. Я предполагаю это сделать реализовав следующий механизм: внизу установить эдакую «линейку с передвигающимся флажком» показатель радикализации (Rkz) с шагом передвижения флажка в 0, 001. Выглядеть все это дело будет следующим образом:
Тогда V – показатель связи этих двух конструктов. Показатель V будет вычисляться по формуле: Таким образом, данный показатель сосредоточен в промежутке от 0 до 1. Это простейшая взаимосвязь между конструктами. А теперь переходим к следующей части – программа рассчитывает (но не выводит на экран) подобного рода связи между всеми связанными конструктами на матрице. Далее на основании этих найденных показателей происходит отбор и разделение на группы. Я предполагаю это сделать реализовав следующий механизм: внизу установить эдакую «линейку с передвигающимся флажком» показатель радикализации (Rkz) с шагом передвижения флажка в 0, 001. Выглядеть все это дело будет следующим образом:
 Как мы видим «флажок» на линейке Rkz можно двигать. При этом меняется показатель радикализации. Это нужно для того, чтобы исследователь во-первых мог посмотреть как будет развиваться ситуация в динамике, если к данной тематической релевантности будет повышаться интерес и мотивы, потребности, ценности и пр. каким-то образом придут к столкновению и конфликту.
Как мы видим «флажок» на линейке Rkz можно двигать. При этом меняется показатель радикализации. Это нужно для того, чтобы исследователь во-первых мог посмотреть как будет развиваться ситуация в динамике, если к данной тематической релевантности будет повышаться интерес и мотивы, потребности, ценности и пр. каким-то образом придут к столкновению и конфликту.
 Показатель Rkz тесно связан с коэффициентом доверия, который достаточно часто замеряется социологическими службами и может быть установлен с достаточной степенью точности. В данной модели показатель Rkz – это коэффициент «порога отбора» . Смотрятся все связи между конструктами и отбираются те, которые по показателю V выше коэффициента Rkz. Ближайшие конструкты, связи V между которыми выше порога Rkz объединяются в группы. Количество групп не ограничено. Каждой группе присваивается переменная G с порядковым номером, а внизу идет математическое описание групп. Туда входят следующие характеристики: 1) Численность группы – это общее количество респондентов, которых охватили все конструкты внутри круга ( в чем-то – аналог переменной D, описанной выше, только не для 2 -х конструктов, а для n-ного числа конструктов). 2) Процент от общей выборки = численность группы делить на общий размер выборки и все это умножить на 100 с округлением до 0, 001. Данный показатель нужен нам затем, чтобы если вдруг у нас имеется точное число индивидов, которым релевантна данная тема мы могли найти приблизительную численность каждой из возникших групп (с оглядкой на ошибку выборки, значения которых четко установлены эмпирически). Даже если у нас имеется приблизительное значение, сосредоточенное в определенном промежутке – мы все равно можем приблизительно прикинуть промежуток, в котором будет колебаться численность представителей тех или иных групп и этого может оказаться вполне достаточно для принятия решений и стратегии поведения.
Показатель Rkz тесно связан с коэффициентом доверия, который достаточно часто замеряется социологическими службами и может быть установлен с достаточной степенью точности. В данной модели показатель Rkz – это коэффициент «порога отбора» . Смотрятся все связи между конструктами и отбираются те, которые по показателю V выше коэффициента Rkz. Ближайшие конструкты, связи V между которыми выше порога Rkz объединяются в группы. Количество групп не ограничено. Каждой группе присваивается переменная G с порядковым номером, а внизу идет математическое описание групп. Туда входят следующие характеристики: 1) Численность группы – это общее количество респондентов, которых охватили все конструкты внутри круга ( в чем-то – аналог переменной D, описанной выше, только не для 2 -х конструктов, а для n-ного числа конструктов). 2) Процент от общей выборки = численность группы делить на общий размер выборки и все это умножить на 100 с округлением до 0, 001. Данный показатель нужен нам затем, чтобы если вдруг у нас имеется точное число индивидов, которым релевантна данная тема мы могли найти приблизительную численность каждой из возникших групп (с оглядкой на ошибку выборки, значения которых четко установлены эмпирически). Даже если у нас имеется приблизительное значение, сосредоточенное в определенном промежутке – мы все равно можем приблизительно прикинуть промежуток, в котором будет колебаться численность представителей тех или иных групп и этого может оказаться вполне достаточно для принятия решений и стратегии поведения.
 Целевая выборка Данный «жесткий» инструмент схож с «тестом для исследователя» : отбор осуществляется по целому ряду переменных и исследователь, «заполняя анкету целевой выборки» заранее не знает, какое количество человек соответствует данной «целевой выборке» (это выясняется после проведения данной процедуры). В данном случае так же – из имеющейся у нас выборки отбираются только те респонденты, которые релевантны тем вариантам ответов, которые указал исследователь и на основании этого формируется каузально-семантическая мини -матрица. Так же целесообразно использовать коэффициент девиации (отклонение значений конструктов от общей матрицы).
Целевая выборка Данный «жесткий» инструмент схож с «тестом для исследователя» : отбор осуществляется по целому ряду переменных и исследователь, «заполняя анкету целевой выборки» заранее не знает, какое количество человек соответствует данной «целевой выборке» (это выясняется после проведения данной процедуры). В данном случае так же – из имеющейся у нас выборки отбираются только те респонденты, которые релевантны тем вариантам ответов, которые указал исследователь и на основании этого формируется каузально-семантическая мини -матрица. Так же целесообразно использовать коэффициент девиации (отклонение значений конструктов от общей матрицы).
 В завершении следует отметить, что несмотря на не полную завершенность проекта данный метод был успешно опробован на практике вручную в 2 -х исследованиях: 1) «Идеальный преподаватель, глазами студентов ВУЗА» 2) «Метод каузально-семантических матриц: «Социальные проблемы, релевантные студенческой молодежи Ульяновска» » .
В завершении следует отметить, что несмотря на не полную завершенность проекта данный метод был успешно опробован на практике вручную в 2 -х исследованиях: 1) «Идеальный преподаватель, глазами студентов ВУЗА» 2) «Метод каузально-семантических матриц: «Социальные проблемы, релевантные студенческой молодежи Ульяновска» » .
 Спасибо за внимание!
Спасибо за внимание!