ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ_8.ppt
- Количество слайдов: 63



ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ
 является сложной и плохо формализуемой задачей, требующей детальных")
• Создание информационных систем (ИС) является сложной и плохо формализуемой задачей, требующей детальных знаний о работе автоматизируемой предметной области. При этом никто в организации не знает как она работает в той мере подробности, которая необходима для создания ИС. Поэтому для описания работы предприятия необходимо построить его адекватную модель, содержащую в себе знания всех участников бизнес-процессов организации.

• Реализацию сложных проектов по созданию ИС принято разбивать на стадии анализа, проектирования, кодирования, тестирования и сопровождения. Известно, что исправление ошибок, допущенных на предыдущей стадии, обходится примерно в 10 раз дороже, чем на текущей, следовательно, наиболее критическими являются первые стадии проекта - анализа и проектирования.

• Около 90% всех современных ИС требуют решения целого комплекса задач по хранению данных. В современных условиях, когда объемы обрабатываемых данных высоки и продолжают стремительно возрастать, решение таких задач немыслимо без использования технологий баз данных. Исходная информация для работы системы и результаты ее работы сохраняются в БД, таким образом, создание базы данных выходит на первый план на начальном этапе создания информационной системы.

• При создании БД ИС наиболее важными являются задачи, связанные с созданием правильной логической структуры данных, обеспечивающей решение всего набора требуемых задач. Под правильной логической структурой в данном случае понимается структура, созданная с учетом особенностей организации хранения данных, используемых при решении требуемых задач. • База данных, разработанная без учета того, как она в дальнейшем будет использоваться, оказывается, как правило, неуклюжей и неэффективной. • Создание правильной логической структуры предусматривает комплексный анализ всех факторов, влияющих на формирование и обработку данных.
 часто сталкивается с «сухими» фактами, предоставляемыми")
• При проектировании структуры БД разработчик (проектировщик) часто сталкивается с «сухими» фактами, предоставляемыми заказчиком. Например, заказчик предоставляет проектировщику только формы документов, используемых в работе. Этого явно не достаточно, т. к. не ясны цели проектирования. При простом переносе данных форм в БД неизбежно возникнет ряд проблем, устранение которых повлечет за собой необходимость в перепроектировании структуры всей БД.

• Процесс разработки БД можно разбить на несколько этапов: 1. Исследование предметной области. 2. Создание инфологической модели. 3. Создание даталогической модели. 4. Нормализация даталогической модели. 5. Создание физической модели. • Коротко охарактеризуем каждый из них.

• Исследование предметной области необходимо проводить в целом для разрабатываемой системы, частью которой является и БД. При этом модель данных может быть создана только в случае, если выявлены все объекты системы, логика их взаимодействия, потоки передаваемой информации. • База данных является хранилищем передаваемых данных, которые используются системой при работе.

• Можно сказать, что БД – это фундамент системы, а следовательно к ее созданию нужно подходить очень серьезно. Очень много ошибок при создании БД происходят по причине недостаточной продуманности ее структуры и некачественного выполнения этапа проектирования, который начинается с исследования предметной области.

• Создание системы необходимо начинать c исследования процессов, происходящих в предметной области и используемых ими данных. При этом очень важно определить рамки системы и перечень выполняемых ей функций. Подобный анализ желательно проводить с участием экспертов предметной области и консультантов. При этом работа сводится к поэтапному выделению объектов, значимых функций системы, информационных потоков и системы их взаимосвязей.

• Целью подобного исследования является выделение значимых функций для разрабатываемой системы, их согласование, описание в терминах понятных как разработчику, так и будущему пользователю. • На этом этапе важно понять смысловое значение данных, обрабатываемых в системе, отделить ключевые понятия предметной области от маловажных и вообще несущественных для рассматриваемого случая.

• Очень важно на этапе проектирования достичь взаимопонимания как между разработчиками системы, так и между экспертами предметной области, заказчиками и т. д. , так каждый имеет свое видение проекта. Точки зрения участников разработки по определенным проблемам могут совпадать, однако формы их представления быть различными, что ведет к осложнению совместной работы над одним проектом.

• Важным инструментом в данном случае является использование единой нотации – системы обозначений, правил описания процессов, объектов, явлений и их взаимосвязи, позволяющее всем участникам проекта «говорить на одном языке» . Причем, комплексность подхода и использование единой нотации очень важно, не только на этапе моделирования предметной области, но и на последующих этапах разработки программной системы.

• Результатом проведения исследования предметной области должен стать перечень системных требований, спецификаций, бизнес процессов, информационных потоков и их описание. Очень часто для этого применяются стандартные способы описания предметной области с использованием моделей DFD, SADT, UML.

• Наиболее простым представляется способ функционально-ориентированного проектирования. Основными идеями функциональноориентированной технологии проектирования являются идеи структурного анализа и проектирования ИС. Они заключаются в следующем: 1. декомпозиция всей системы на некоторое множество иерархически подчиненных функций; 2. представление всей системы в виде графической нотации.

• В качестве инструментальных средств структурного анализа и проектирования выступают следующие диаграммы: • BFD (Business Function Diagram) – диаграмма бизнесфункций (функциональные спецификации); • DFD (Data Flow Diagram) – диаграмма потоков данных; • STD (State Transition Diagram) – диаграмма переходов состояний (матрицы перекрестных ссылок); • ERD (Entity Relationship Diagram) – ER-модель данных предметной области (информационно-логические модели «сущность-связь» ); • SSD (System Structure Diagram) – диаграмма структуры программного приложения.

Инфологическое моделирование. • Инфологическая модель создается по результатам проведения исследований предметной области. Инфологическая модель представляет собой описание будущей базы данных, представленное с помощью естественного языка, формул, графиков, диаграмм, таблиц и других средств, понятных как разработчикам БД, так и обычным пользователям.

• Назначение такой модели состоит в адекватном описании процессов, информационных потоков, функций системы с помощью общедоступного и понятного языка, что делает возможным привлечение экспертов предметной области, консультантов, пользователей для обсуждения модели и внесения исправлений. В данном случае под созданием инфологической модели будем понимать именно ее создание для БД. В общем случае, инфологическая модель может создаваться для любой проектируемой системы и представляет ее описание (в общем случае в произвольной форме).

• Создание инфологической модели является естественным продолжением исследований предметной области, но на этом этапе разрабатывается представление БД с точки зрения проектировщика (разработчика). Наглядность представления такой модели позволяет экспертам предметной области оценить ее адекватность и внести исправления. От правильности модели зависит успех дальнейшей разработки.

• Инфологическую модель можно представить в виде словесного описания, однако наиболее наглядным является использование специальных графических нотаций, разработанных для проведения подобного рода моделирования.

• Важно отметить, что создаваемая на этом этапе модель полностью не зависит от физической реализации будущей системы. В случае с БД это означает, что совершенно не важно где физически будут храниться данные: на бумаге, в памяти компьютера и кто или что эти данные будет обрабатывать. • В этом случае, когда структуры данных не зависят от их физической реализации, а моделируются исходя из их смыслового назначения, моделирование называется семантическим.

Даталогическое моделирование. • При даталогическом моделировании используется инфологическая модель предметной области. При этом основной задачей даталогического моделирования является описание свойств понятий предметной области, их взаимосвязь и ограничения, накладываемые на данные. Даталогическая модель является начальным прототипом создаваемой базы данных. Все понятия, выделенные при исследовании предметной области и их взаимосвязи в дальнейшем будут отображены в конкретные структуры какой-либо конкретной базы данных.

• Результатом создания даталогической модели является модель, созданная с учетом выбранной модели данных, полученная путем преобразования инфологической модели с учетом определенных правил.

Нормализация. • Нормализация – это процесс приведения таблиц БД к строгой форме путем последовательного преобразования таблиц к состоянию, в котором они удовлетворяют условиям первой, второй и третьей нормальных форм. • В процессе нормализации происходит последовательное улучшение даталогической модели данных с тем, чтобы обеспечить ее устойчивость к операциям добавления, удаления и изменения данных

Создание физической модели. • Завершающим этапом проектирования БД является создание физической модели. Эта модель создается с учетом конкретной СУБД и должна учитывать все ее особенности. К таким особенностям могут относиться правила именования таблиц и атрибутов, создание связей между таблицами, поддерживаемые типы данных и т. п.
 • DFD являются основным средством моделирования функциональных")
Исследование предметной области. Диаграммы потоков данных (DFD) • DFD являются основным средством моделирования функциональных требований к проектируемой системе. С помощью этих диаграмм требования представляются в виде иерархии функциональных компонентов (процессов), связанных потоками данных. Главная цель такого проектирования – продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами.

• DFD как правило жестко ориентированы на какую-либо технологию обработки данных и отражают передачу информации от одной функции к другой в рамках заданной технологии обработки. В узлах диаграммы потоков данных (кружочки) отражаются процедуры (функции), а стрелками между узлами показываются потоки данных (над стрелками задаются имена передаваемых/используемых единиц информации – документов, экранных форм, файлов).

• DFD показывает внешние по отношению к системе источники данных и адресатов, которые принимают информацию от системы, а также идентифицируют хранилища данных (накопители данных), к которым осуществляется доступ системы. Каждая логическая функция системы (бизнес-функция) описывается своей DFD. Причем эта DFD может иерархически детализировать функцию на ее подфункции.

• Существует две наиболее распространенных нотаций в рамках DFD: • Йордана и Гейна-Сарсона. • Они различаются незначительно, поэтому при дальнейшем рассмотрении будем использовать нотацию Йордана. • Определим основные объекты DFD и их графическое изображение.
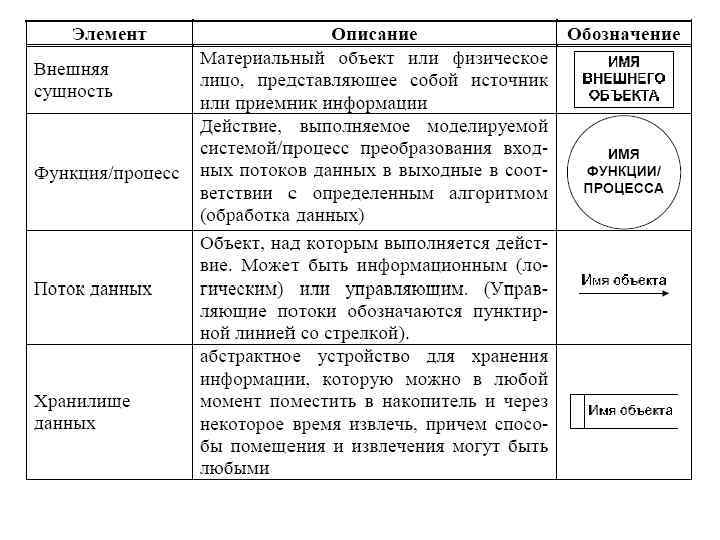

• В соответствии с данными методами модель системы определяется как иерархия диаграмм потоков данных, описывающих асинхронный процесс преобразования информации от ее ввода в систему до выдачи пользователю. • Диаграммы верхних уровней иерархии (контекстные диаграммы) определяют основные процессы или подсистемы с внешними входами и выходами. Они детализируются при помощи диаграмм нижнего уровня. Такая декомпозиция продолжается до тех пор, пока не будет достигнут уровень декомпозиции, на котором процессы становятся элементарными и детализировать их далее невозможно.
 порождают информационные потоки (потоки данных), переносящие информацию к")
• Источники информации (внешние сущности) порождают информационные потоки (потоки данных), переносящие информацию к подсистемам или процессам. Те, в свою очередь, преобразуют информацию и порождают новые потоки, которые переносят информацию к другим процессам или подсистемам, накопителям данных или внешним сущностям – потребителям информации • Главная цель построения иерархии DFD заключается в том, чтобы сделать требования к системе ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними.

• Для достижения этого целесообразно пользоваться следующими рекомендациями: • размещать на каждой диаграмме от 3 до 6 -7 процессов. Верхняя граница соответствует человеческим возможностям одновременного восприятия и понимания структуры сложной системы с множеством внутренних связей, нижняя граница выбрана по соображениям здравого смысла: нет необходимости детализировать процесс диаграммой, содержащей всего один процесс или два;

• не загромождать диаграммы не существенными на данном уровне деталями; • декомпозицию потоков данных осуществлять параллельно с декомпозицией процессов. Эти две работы должны выполняться одновременно, а не одна после завершения другой; • выбирать ясные, отражающие суть дела имена процессов и потоков, при это стараться не использовать аббревиатуры.

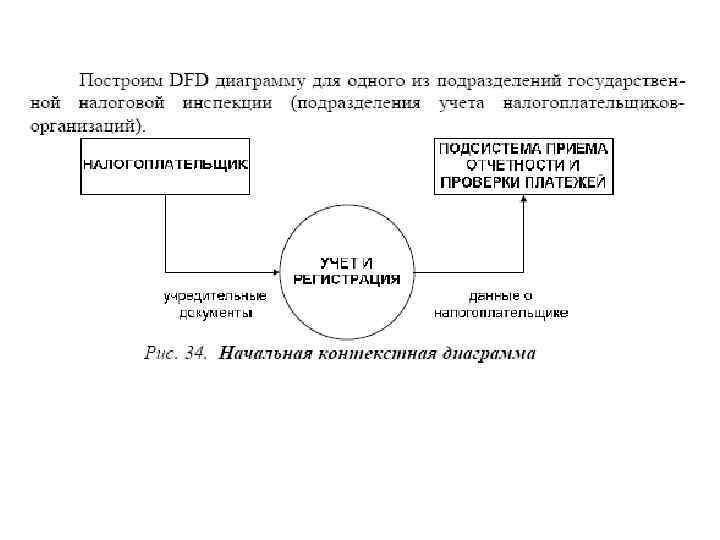
• Первым шагом при построении иерархии DFD является построение контекстных диаграмм. Обычно при проектировании относительно простых систем строится единственная контекстная диаграмма со звездообразной топологией, в центре которой находится так называемый главный процесс, соединенный с приемниками и источниками информации, посредством которых с системой взаимодействуют пользователи и другие внешние системы.
, оказывающие влияние")
• Перед построением контекстной DFD необходимо проанализировать внешние события (внешние сущности), оказывающие влияние на функционирование системы. Количество потоков на контекстной диаграмме должно быть по возможности небольшим, поскольку каждый из них может быть в дальнейшем разбит на несколько потоков на следующих уровнях диаграммы.

• Для проверки контекстной диаграммы можно составить список событий. Список событий должен состоять из описаний действий внешних сущностей (событий) и соответствующих реакций системы на события. Каждое событие должно соответствовать одному (или более) потоку данных: входные потоки интерпретируются как воздействия, а выходные потоки — как реакции системы на входные потоки.

• Если для сложной системы ограничиться единственной контекстной диаграммой, то она будет содержать слишком большое количество источников и приемников информации, которые трудно расположить на листе бумаги нормального формата, и, кроме того, единственный главный процесс не раскрывает структуры такой системы. Признаками сложности (в смысле контекста) могут быть: наличие большого количества внешних сущностей (десять и более), распределенная природа системы, многофункциональность системы с уже сложившейся или выявленной группировкой функций в отдельные подсистемы.

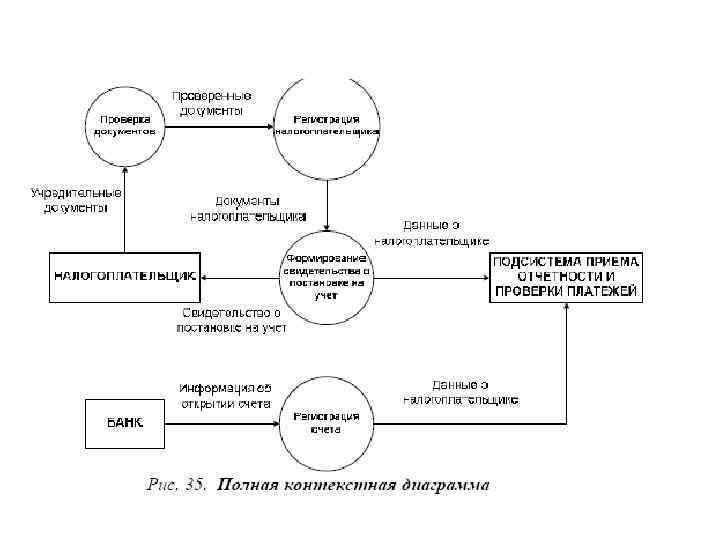
• Для сложных систем строится иерархия контекстных диаграмм. При этом контекстная диаграмма верхнего уровня содержит не единственный главный процесс, а набор подсистем, соединенных потоками данных. Контекстные диаграммы следующего уровня детализируют контекст и структуру подсистем. • Иерархия контекстных диаграмм определяет взаимодействие основных функциональных подсистем как между собой, так и с внешними входными и выходными потоками данных и внешними объектами (источниками и приемниками информации), с которыми взаимодействует система.

• Разработка контекстных диаграмм решает проблему строгого определения функциональной структуры ЭИС на самой ранней стадии ее проектирования, что особенно важно для сложных многофункциональных систем, в создании которых участвуют разные организации и коллективы разработчиков. • После построения контекстных диаграмм полученную модель следует проверить на полноту исходных данных об объектах системы и изолированность объектов (отсутствие информационных связей с другими объектами).

• Для каждой подсистемы, присутствующей на контекстных диаграммах, выполняется ее детализация при помощи DFD. Это можно сделать путем построения диаграммы для каждого события. Каждое событие представляется в виде процесса с соответствующими входными и выходными потоками, накопителями данных, внешними сущностями и ссылки на другие процессы для описания связей между этим процессом и его окружением. Затем все построенные диаграммы сводятся в одну диаграмму нулевого уровня.

• Каждый процесс на DFD, в свою очередь, может быть детализирован при помощи DFD или (если процесс элементарный) спецификации.

• При детализации должно выполняться правило балансировки – при детализации подсистемы или процесса детализирующая диаграмма в качестве внешних источников или приемников данных может иметь только те компоненты (подсистемы, процессы, внешние сущности, накопители данных), с которыми имеют информационную связь детализируемые подсистема или процесс на родительской диаграмме;

• Решение о завершении детализации процесса и использовании спецификации принимается аналитиком исходя из следующих критериев: • наличия у процесса относительно небольшого количества входных и выходных потоков данных (2 – 3 потока); • возможности описания преобразования данных процессом в виде последовательного алгоритма; • выполнения процессом единственной логической функции преобразования входной информации в выходную; • ·возможности описания логики процесса при помощи спецификации небольшого объема (не более 20 – 30 строк).

Спецификации должны удовлетворять следующим требованиям: • для каждого процесса нижнего уровня должна существовать одна и только одна спецификация; • спецификация должна определять способ преобразования входных потоков в выходные; • нет необходимости (по крайней мере на стадии формирования требований) определять метод реализации этого преобразования; • спецификация должна стремиться к ограничению избыточности – не следует переопределять то, что уже было определено на диаграмме; • набор конструкций для построения спецификации должен быть простым и понятным.

• При построении иерархии DFD переходить к детализации процессов следует только после определения содержания всех потоков и накопителей данных, которое описывается с помощью структур данных. Для каждого потока данных формируется список всех его элементов данных, затем элементы данных объединяются в структуры данных, соответствующие более крупным объектам данных (например, строкам документов или объектам предметной области). Каждый объект должен состоять из элементов, являющихся его атрибутами. Структуры данных могут содержать альтернативы, условные вхождения и итерации.

• Условное вхождение показывает, что данный компонент может отсутствовать в структуре (например, структура «данные о страховании» для объекта «служащий» ). Альтернатива означает, что в структуру может входить один из перечисленных элементов. Итерация предусматривает вхождение любого числа элементов в указанном диапазоне (например, элемент «имя ребенка» для объекта «служащий» ). Для каждого элемента данных может указываться его тип (непрерывные или дискретные данные). Для непрерывных данных могут указываться единица измерения (кг, см и т. п. ).

• После построения законченной модели системы ее необходимо верифицировать (проверить на полноту и согласованность). В полной модели все ее объекты (подсистемы, процессы, потоки данных) должны быть подробно описаны и детализированы. Выявленные не детализированные объекты следует детализировать, вернувшись на предыдущие шаги разработки. В согласованной модели для всех потоков данных и накопителей данных должно • выполняться правило сохранения информации: все поступающие куда-либо данные должны быть считаны, а все считываемые данные должны быть записаны.

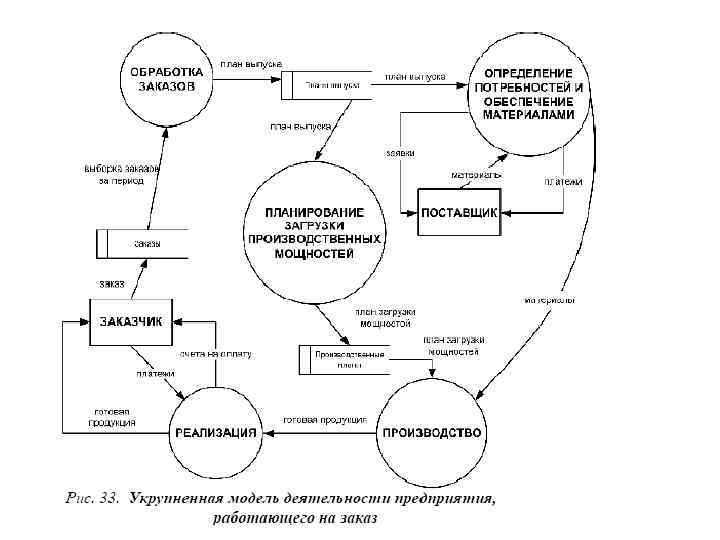
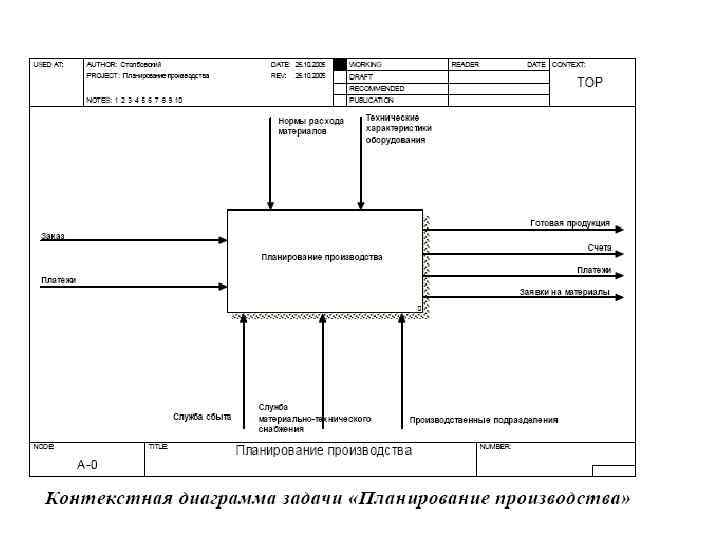
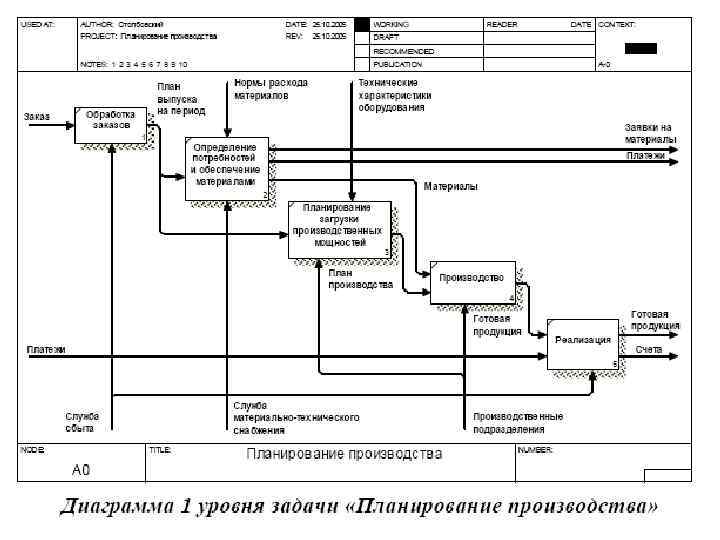
• Приведем несколько примеров построения диаграмм потоков данных: • Построим DFD-диаграмму для предприятия, строящего свою деятельность по принципу «изготовление на заказ» . На основании полученных заказов формируется план выпуска продукции на определенный период. В соответствии с этим планом определяются потребность в комплектующих изделиях и материалах, а также график загрузки производственного оборудования. После изготовления продукции и проведения платежей, готовая продукция отправляется заказчику.
 разработана Дугласом")
Метод функционального моделирования SADT • Методология SADT (Structured Analisys and Design Technique) разработана Дугласом Т. Россом в 1969 -73 годах. Она изначально создавалась для проектирования систем более общего назначения по сравнению с другими структурными методами, выросшими из проектирования программного обеспечения. IDEF 0 (подмножество SADT) используется для моделирования бизнес-процессов в организационных системах и имеет развитые процедуры поддержки коллективной работы.

• В терминах IDEF 0 система представляется в виде комбинации блоков и дуг. Блоки представляют функции системы, дуги представляют множество объектов (физические объекты, информация или действия, которые образуют связи между функциональными блоками). Место соединения дуги с блоком определяет тип интерфейса. Пример изображения функциональных блоков SADT модели изображен ниже.
 преобразует входные объекты в выходные • Управление")
Правила интерпретации модели: • Функциональный блок (функция) преобразует входные объекты в выходные • Управление определяет, когда и как это преобразование может или должно произойти • Исполнитель осуществляет это преобразование
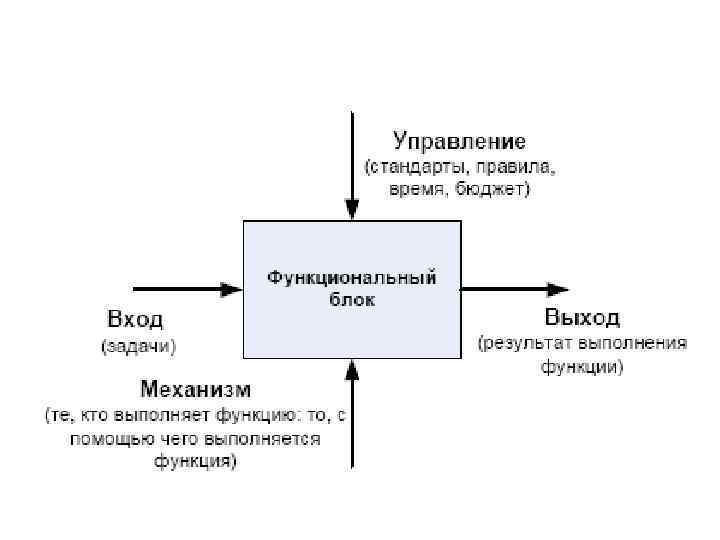

• С дугами связываются метки на естественном языке, описывающие данные, которые они представляют. Дуги показывают, как функции системы связаны между собой, как они обмениваются данными и осуществляют управление другом. Выходы одной функции могут быть входами, управлением или исполнителями другой. • Дуги могут разветвляться и соединяться. Ветвление означает множественность (идентичные копии одного объекта) или расщепление (различные части одного объекта). Соединение означает объединение или слияние объектов

• Каждый блок IDEF 0 -диаграммы может быть представлен несколькими блоками, соединенными интерфейсными дугами, на диаграмме следующего уровня. Эти блоки представляют подфункции (подмодули) исходной функции. Каждый из подмодулей может быть декомпозирован аналогичным образом. Число уровней не ограничивается, зато рекомендуется на одной диаграмме использовать не менее 3 и не более 6 блоков. • На следующем рисунке представлена IDEF 0 -модель деятельности описанного выше предприятия, планирующего производство исходя из поступивших заказов.

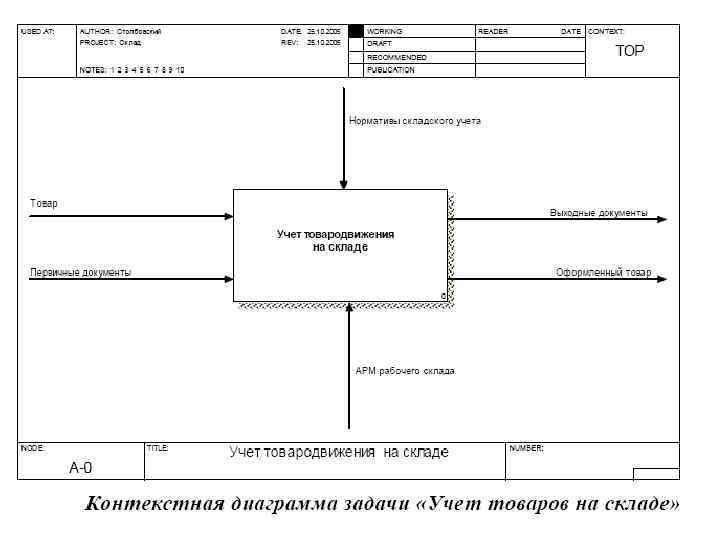
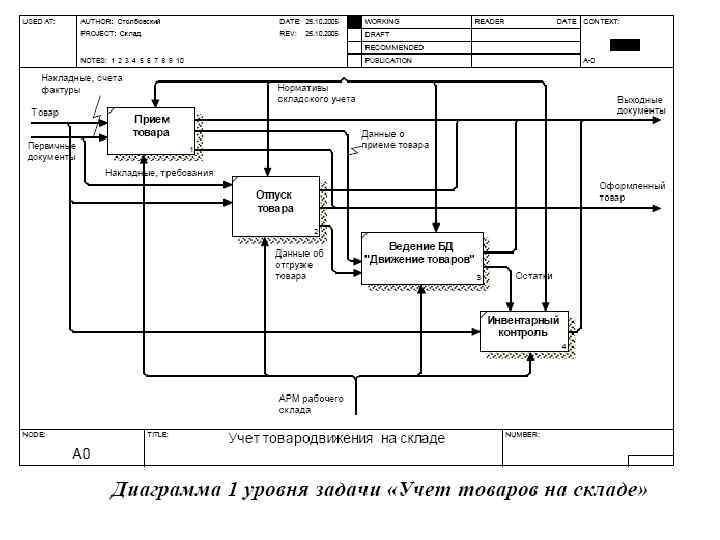
• Для задачи аналитического учета товаров на складе, пример контекстной диаграмма и диаграмма 1 уровня в нотации SADT может выглядеть следующим образом.
ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ_8.ppt