

e60ee5119219fe69b4f03fc550a084e7.ppt
- Количество слайдов: 34
 Predicting Emotion in Spoken Dialogue from Multiple Knowledge Sources Kate Forbes-Riley and Diane Litman Learning Research and Development Center and Computer Science Department University of Pittsburgh
Predicting Emotion in Spoken Dialogue from Multiple Knowledge Sources Kate Forbes-Riley and Diane Litman Learning Research and Development Center and Computer Science Department University of Pittsburgh
 Overview Motivation spoken dialogue tutoring systems Emotion Annotation positive, negative and neutral student states Machine Learning Experiments extract linguistic features from student speech use different feature sets to predict emotions best-performing feature set: speech & text, turn & context 84. 75% accuracy, 44% error reduction
Overview Motivation spoken dialogue tutoring systems Emotion Annotation positive, negative and neutral student states Machine Learning Experiments extract linguistic features from student speech use different feature sets to predict emotions best-performing feature set: speech & text, turn & context 84. 75% accuracy, 44% error reduction
 Motivation u. Bridge Learning Gap between Human Tutors and Computer Tutors u(Aist et al. , 2002): Adding human-provided emotional scaffolding to a reading tutor increases student persistence u. Our Approach: Add emotion prediction and adaptation to ITSPOKE, our Intelligent Tutoring SPOKEn dialogue system (demo paper)
Motivation u. Bridge Learning Gap between Human Tutors and Computer Tutors u(Aist et al. , 2002): Adding human-provided emotional scaffolding to a reading tutor increases student persistence u. Our Approach: Add emotion prediction and adaptation to ITSPOKE, our Intelligent Tutoring SPOKEn dialogue system (demo paper)
, 14 subjects") Experimental Data u. Human Tutoring Spoken Dialogue Corpus 128 dialogues (physics problems), 14 subjects 45 average student and tutor turns per dialogue Same physics problems, subject pool, web interface, and experimental procedure as ITSPOKE
Experimental Data u. Human Tutoring Spoken Dialogue Corpus 128 dialogues (physics problems), 14 subjects 45 average student and tutor turns per dialogue Same physics problems, subject pool, web interface, and experimental procedure as ITSPOKE
 u. Perceived “Emotions” u. Task- and Context-Relative u 3") Emotion Annotation Scheme (Sigdial’ 04) u. Perceived “Emotions” u. Task- and Context-Relative u 3 Main Emotion Classes: negative neutral positive u 3 Minor Emotion Classes: weak negative, weak positive, mixed
Emotion Annotation Scheme (Sigdial’ 04) u. Perceived “Emotions” u. Task- and Context-Relative u 3 Main Emotion Classes: negative neutral positive u 3 Minor Emotion Classes: weak negative, weak positive, mixed
 Tutor: Uh let us talk of one") Example Annotated Excerpt (weak, mixed -> neutral) Tutor: Uh let us talk of one car first. Student: ok. (EMOTION = NEUTRAL) Tutor: If there is a car, what is it that exerts force on the car such that it accelerates forward? Student: The engine. (EMOTION = POSITIVE) Tutor: Uh well engine is part of the car, so how can it exert force on itself? Student: um… (EMOTION = NEGATIVE)
Example Annotated Excerpt (weak, mixed -> neutral) Tutor: Uh let us talk of one car first. Student: ok. (EMOTION = NEUTRAL) Tutor: If there is a car, what is it that exerts force on the car such that it accelerates forward? Student: The engine. (EMOTION = POSITIVE) Tutor: Uh well engine is part of the car, so how can it exert force on itself? Student: um… (EMOTION = NEGATIVE)
 Emotion Annotated Data u 453 student turns, 10 dialogues, 9 subjects u 2 annotators, 3 main emotion classes u 385/453 agreed (84. 99%, Kappa 0. 68) Negative Neutral Positive Negative 90 6 4 Neutral 23 280 30 Positive 0 5 15
Emotion Annotated Data u 453 student turns, 10 dialogues, 9 subjects u 2 annotators, 3 main emotion classes u 385/453 agreed (84. 99%, Kappa 0. 68) Negative Neutral Positive Negative 90 6 4 Neutral 23 280 30 Positive 0 5 15
 – non acoustic-prosodic") Feature Extraction per Student Turn Five feature types – acoustic-prosodic (1) – non acoustic-prosodic • lexical (2) • other automatic (3) • manual (4) – identifiers (5) Research questions – utility of different features – speaker and task dependence
Feature Extraction per Student Turn Five feature types – acoustic-prosodic (1) – non acoustic-prosodic • lexical (2) • other automatic (3) • manual (4) – identifiers (5) Research questions – utility of different features – speaker and task dependence
 Acoustic-Prosodic Features (normalized) § 4 pitch (f 0) : max, min,") Feature Types (1) Acoustic-Prosodic Features (normalized) § 4 pitch (f 0) : max, min, mean, standard dev. § 4 energy (RMS) : max, min, mean, standard dev. § 4 temporal: turn duration (seconds) pause length preceding turn (seconds) tempo (syllables/second) internal silence in turn (zero f 0 frames)
Feature Types (1) Acoustic-Prosodic Features (normalized) § 4 pitch (f 0) : max, min, mean, standard dev. § 4 energy (RMS) : max, min, mean, standard dev. § 4 temporal: turn duration (seconds) pause length preceding turn (seconds) tempo (syllables/second) internal silence in turn (zero f 0 frames)
 Lexical Items § word occurrence vector") Feature Types (2) Lexical Items § word occurrence vector
Feature Types (2) Lexical Items § word occurrence vector
 Other Automatic Features: available from ITSPOKE logs § Turn Begin Time") Feature Types (3) Other Automatic Features: available from ITSPOKE logs § Turn Begin Time (seconds from dialog start) § Turn End Time (seconds from dialog start) § Is Temporal Barge-in (student turn begins before tutor turn ends) § Is Temporal Overlap (student turn begins and ends in tutor turn) § Number of Words in Turn § Number of Syllables in Turn
Feature Types (3) Other Automatic Features: available from ITSPOKE logs § Turn Begin Time (seconds from dialog start) § Turn End Time (seconds from dialog start) § Is Temporal Barge-in (student turn begins before tutor turn ends) § Is Temporal Overlap (student turn begins and ends in tutor turn) § Number of Words in Turn § Number of Syllables in Turn
 Manual Features: (currently) available only from human transcription § Is Prior") Feature Types (4) Manual Features: (currently) available only from human transcription § Is Prior Tutor Question (tutor turn contains “? ”) § Is Student Question (student turn contains “? ”) § Is Semantic Barge-in (student turn begins at tutor word/pause boundary) § Number of Hedging/Grounding Phrases (e. g. “mmhm”, “um”) § Is Grounding (canonical phrase turns not preceded by a tutor question) § Number of False Starts in Turn (e. g. acc-acceleration)
Feature Types (4) Manual Features: (currently) available only from human transcription § Is Prior Tutor Question (tutor turn contains “? ”) § Is Student Question (student turn contains “? ”) § Is Semantic Barge-in (student turn begins at tutor word/pause boundary) § Number of Hedging/Grounding Phrases (e. g. “mmhm”, “um”) § Is Grounding (canonical phrase turns not preceded by a tutor question) § Number of False Starts in Turn (e. g. acc-acceleration)
 Identifier Features § subject ID § problem ID § subject gender") Feature Types (5) Identifier Features § subject ID § problem ID § subject gender
Feature Types (5) Identifier Features § subject ID § problem ID § subject gender
 Experiments u. Weka software: boosted decision trees give best results (Litman&Forbes,") Machine Learning (ML) Experiments u. Weka software: boosted decision trees give best results (Litman&Forbes, ASRU 2003) u. Baseline: Predicts Majority Class (neutral) Accuracy = 72. 74% u. Methodology: 10 runs of 10 -fold cross validation u. Evaluation Metrics Mean Accuracy: %Correct Relative Improvement Over Baseline (RI): error(baseline) – error(x) error(baseline)
Machine Learning (ML) Experiments u. Weka software: boosted decision trees give best results (Litman&Forbes, ASRU 2003) u. Baseline: Predicts Majority Class (neutral) Accuracy = 72. 74% u. Methodology: 10 runs of 10 -fold cross validation u. Evaluation Metrics Mean Accuracy: %Correct Relative Improvement Over Baseline (RI): error(baseline) – error(x) error(baseline)
 outperform majority baseline, but other feature types") Acoustic-Prosodic vs. Other Features Acoustic-prosodic features (“speech”) outperform majority baseline, but other feature types yield even higher accuracy, and the more the better Feature Set speech lexical + automatic + manual -ident 76. 20% 78. 31% 80. 38% 83. 19% u. Baseline = 72. 74%; RI range = 12. 69% - 43. 87%
Acoustic-Prosodic vs. Other Features Acoustic-prosodic features (“speech”) outperform majority baseline, but other feature types yield even higher accuracy, and the more the better Feature Set speech lexical + automatic + manual -ident 76. 20% 78. 31% 80. 38% 83. 19% u. Baseline = 72. 74%; RI range = 12. 69% - 43. 87%
 Acoustic-Prosodic plus Other Features Adding acoustic-prosodic to other feature sets doesn’t significantly improve performance Feature Set -ident speech + lexical 79. 26% speech + lexical + automatic 79. 64% speech + lexical + automatic + manual 83. 69% u. Baseline = 72. 74%; RI range = 23. 29% - 42. 26%
Acoustic-Prosodic plus Other Features Adding acoustic-prosodic to other feature sets doesn’t significantly improve performance Feature Set -ident speech + lexical 79. 26% speech + lexical + automatic 79. 64% speech + lexical + automatic + manual 83. 69% u. Baseline = 72. 74%; RI range = 23. 29% - 42. 26%
: adding contextual features") Adding Contextual Features (Litman et al. 2001, Batliner et al 2003): adding contextual features improves prediction accuracy Local Features: the values of all features for the two student turns preceding the student turn to be predicted Global Features: running averages and total for all features, over all student turns preceding the student turn to be predicted
Adding Contextual Features (Litman et al. 2001, Batliner et al 2003): adding contextual features improves prediction accuracy Local Features: the values of all features for the two student turns preceding the student turn to be predicted Global Features: running averages and total for all features, over all student turns preceding the student turn to be predicted
 Previous Feature Sets plus Context Adding global contextual features marginally improves performance, e. g. Feature Set +context -ident speech + lexical + auto + manual local 82. 44 global 84. 75 local+global 81. 43 u. Same feature set with no context: 83. 69%
Previous Feature Sets plus Context Adding global contextual features marginally improves performance, e. g. Feature Set +context -ident speech + lexical + auto + manual local 82. 44 global 84. 75 local+global 81. 43 u. Same feature set with no context: 83. 69%
 Feature Usage Feature Type Turn + Global Acoustic-Prosodic Temporal Energy Pitch Other Lexical Automatic Manual 16. 26% 13. 80% 2. 46% 0. 00% 83. 74% 41. 87% 9. 36% 32. 51%
Feature Usage Feature Type Turn + Global Acoustic-Prosodic Temporal Energy Pitch Other Lexical Automatic Manual 16. 26% 13. 80% 2. 46% 0. 00% 83. 74% 41. 87% 9. 36% 32. 51%
 Accuracies over ML Experiments
Accuracies over ML Experiments
 Related Research in Emotional Speech u Actor/Native Read Speech Corpora (Polzin & Waibel 1998; Oudeyer 2002; Liscombe et al. 2003) Ø more emotions; multiple dimensions Ø acoustic-prosodic predictors u Naturally-Occurring Speech Corpora (Ang et al. 2002; Lee et al. 2002; Batliner et al. 2003; Devillers et al. 2003; Shafran et al. 2003) Ø less emotions (e. g. E / -E); Kappas < 0. 6 Ø additional (non acoustic-prosodic) predictors u Few address the tutoring domain
Related Research in Emotional Speech u Actor/Native Read Speech Corpora (Polzin & Waibel 1998; Oudeyer 2002; Liscombe et al. 2003) Ø more emotions; multiple dimensions Ø acoustic-prosodic predictors u Naturally-Occurring Speech Corpora (Ang et al. 2002; Lee et al. 2002; Batliner et al. 2003; Devillers et al. 2003; Shafran et al. 2003) Ø less emotions (e. g. E / -E); Kappas < 0. 6 Ø additional (non acoustic-prosodic) predictors u Few address the tutoring domain
 Summary u. Methodology: Annotation of student emotions in spoken human tutoring dialogues, extraction of linguistic features, and use of different feature sets to predict emotions u. Our best-performing feature set contains acousticprosodic, lexical, automatic and hand-labeled features from turn and context (Accuracy = 85%, RI = 44%) u. This research is a first step towards implementing emotion prediction and adaptation in ITSPOKE
Summary u. Methodology: Annotation of student emotions in spoken human tutoring dialogues, extraction of linguistic features, and use of different feature sets to predict emotions u. Our best-performing feature set contains acousticprosodic, lexical, automatic and hand-labeled features from turn and context (Accuracy = 85%, RI = 44%) u. This research is a first step towards implementing emotion prediction and adaptation in ITSPOKE
 Label human") Current Directions Address same questions in ITSPOKE computer tutoring corpus (ACL’ 04) Label human tutor reactions to student emotions to: develop adaptive strategies for ITSPOKE examine the utility of different annotation granularities determine if greater tutor response to student emotions correlates with student learning and other performance measures
Current Directions Address same questions in ITSPOKE computer tutoring corpus (ACL’ 04) Label human tutor reactions to student emotions to: develop adaptive strategies for ITSPOKE examine the utility of different annotation granularities determine if greater tutor response to student emotions correlates with student learning and other performance measures
 Thank You! Questions?
Thank You! Questions?
: propose a") Prior Research: Affective Computer Tutoring (Kort and Reilly and Picard. , 2001): propose a cyclical model of emotion change during learning; developing a non-dialog computer tutor that will use eye-tracking/facial features to predict emotion and support movement into positive emotions. (Aist and Kort and Reilly and Mostow and Picard, 2002): Adding human-provided emotional scaffolding to an automated reading tutor increases student persistence (Evens et al, 2002): for CIRCSIM: computer dialog tutor for physiology problems; hypothesize adaptive strategies for recognized student emotional states; e. g. if detecting frustration, system should respond to hedges and self-deprecation by supplying praise and restructuring the problem. (de Vicente and Pain, 2002): use human observation about student motivational states in videod interaction with non-dialog computer tutor to develop rules for detection (Ward and Tsukahara, 2003): spoken dialog computer “tutor-support” uses prosodic and contextual features of user turn (e. g. “on a roll”, “lively”, “in trouble”) to infer appropriate response as users remember train stations. Preferred over randomly chosen acknowledgments (e. g. “yes”, “right” “that’s it”, “that’s it
Prior Research: Affective Computer Tutoring (Kort and Reilly and Picard. , 2001): propose a cyclical model of emotion change during learning; developing a non-dialog computer tutor that will use eye-tracking/facial features to predict emotion and support movement into positive emotions. (Aist and Kort and Reilly and Mostow and Picard, 2002): Adding human-provided emotional scaffolding to an automated reading tutor increases student persistence (Evens et al, 2002): for CIRCSIM: computer dialog tutor for physiology problems; hypothesize adaptive strategies for recognized student emotional states; e. g. if detecting frustration, system should respond to hedges and self-deprecation by supplying praise and restructuring the problem. (de Vicente and Pain, 2002): use human observation about student motivational states in videod interaction with non-dialog computer tutor to develop rules for detection (Ward and Tsukahara, 2003): spoken dialog computer “tutor-support” uses prosodic and contextual features of user turn (e. g. “on a roll”, “lively”, “in trouble”) to infer appropriate response as users remember train stations. Preferred over randomly chosen acknowledgments (e. g. “yes”, “right” “that’s it”, “that’s it
 ML Experiment 3: Other Evaluation Metrics u alltext + speech + ident: leave-one-out cross-validation (accuracy = 82. 08%) u Best for neutral, better for negatives than positives u Baseline: neutral: . 73, 1, . 84; negatives and positives = 0, 0, 0 Class Precision Recall F-Measure Negative 0. 71 0. 60 0. 65 Neutral 0. 86 0. 92 0. 89 Positive 0. 50 0. 27 0. 35
ML Experiment 3: Other Evaluation Metrics u alltext + speech + ident: leave-one-out cross-validation (accuracy = 82. 08%) u Best for neutral, better for negatives than positives u Baseline: neutral: . 73, 1, . 84; negatives and positives = 0, 0, 0 Class Precision Recall F-Measure Negative 0. 71 0. 60 0. 65 Neutral 0. 86 0. 92 0. 89 Positive 0. 50 0. 27 0. 35
 Experiments u Weka machine-learning software: boosted decision trees give best results") Machine Learning (ML) Experiments u Weka machine-learning software: boosted decision trees give best results (Litman&Forbes, 2003) u Baseline: Predicts Majority Class (neutral) Accuracy = 72. 74% u Methodology: 10 x 10 cross validation u Evaluation Metrics Mean Accuracy: %Correct Standard Error: SE = std(x)/sqrt(n), n=10 runs +/- 2*SE = 95% confidence interval Relative Improvement Over Baseline (RI): error(baseline) – error(x) error(baseline) error(y) = 100 - % Correct
Machine Learning (ML) Experiments u Weka machine-learning software: boosted decision trees give best results (Litman&Forbes, 2003) u Baseline: Predicts Majority Class (neutral) Accuracy = 72. 74% u Methodology: 10 x 10 cross validation u Evaluation Metrics Mean Accuracy: %Correct Standard Error: SE = std(x)/sqrt(n), n=10 runs +/- 2*SE = 95% confidence interval Relative Improvement Over Baseline (RI): error(baseline) – error(x) error(baseline) error(y) = 100 - % Correct
 Outline u. Introduction u. ITSPOKE Project u. Emotion Annotation u. Machine-Learning Experiments u. Conclusions and Current Directions
Outline u. Introduction u. ITSPOKE Project u. Emotion Annotation u. Machine-Learning Experiments u. Conclusions and Current Directions
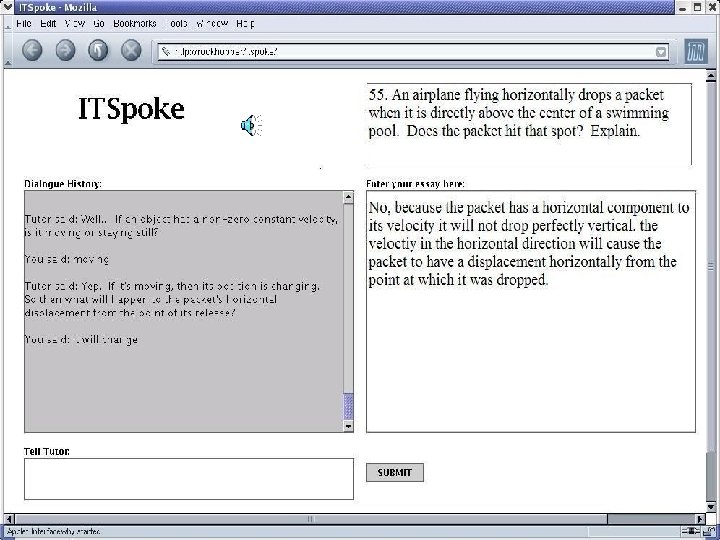
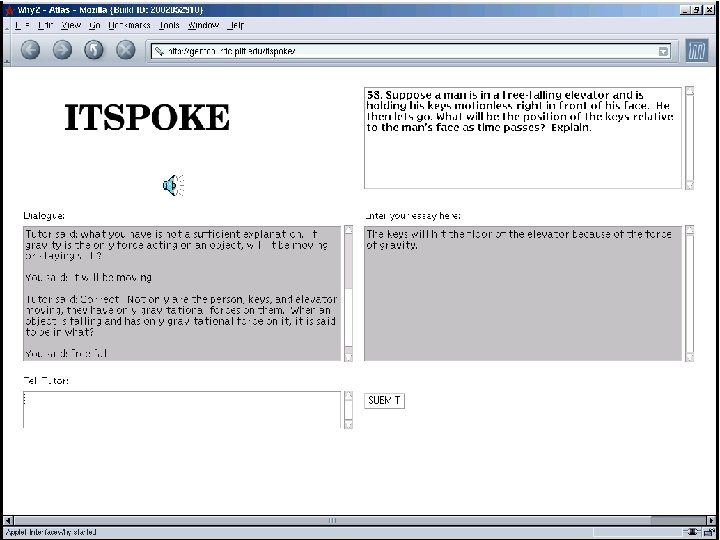
 ITSPOKE: Intelligent Tutoring SPOKEn Dialogue System u. Back-end is text-based Why 2 -Atlas tutorial dialogue system (Van. Lehn et al. , 2002) u. Sphinx 2 speech recognizer u. Cepstral text-to-speech synthesizer u. Try ITSPOKE during demo session !
ITSPOKE: Intelligent Tutoring SPOKEn Dialogue System u. Back-end is text-based Why 2 -Atlas tutorial dialogue system (Van. Lehn et al. , 2002) u. Sphinx 2 speech recognizer u. Cepstral text-to-speech synthesizer u. Try ITSPOKE during demo session !
 Experimental Procedure u. Students take a physics pretest u. Students read background material u. Students use the web and voice interface to work through up to 10 problems with either ITSPOKE or a human tutor u. Students take a post-test
Experimental Procedure u. Students take a physics pretest u. Students read background material u. Students use the web and voice interface to work through up to 10 problems with either ITSPOKE or a human tutor u. Students take a post-test
 ML Experiment 3: 8 Feature Sets + Context u Global context marginally better than local or combined u No significant difference between +/- ident sets u e. g. , speech without context: 76. 20% (-ident), 77. 41% (+ident) Feature Set +context -ident +ident speech local 76. 90 76. 95 speech global 77. 77 78. 02 speech local+global 77. 00 76. 88 Adding context marginally improves some performances
ML Experiment 3: 8 Feature Sets + Context u Global context marginally better than local or combined u No significant difference between +/- ident sets u e. g. , speech without context: 76. 20% (-ident), 77. 41% (+ident) Feature Set +context -ident +ident speech local 76. 90 76. 95 speech global 77. 77 78. 02 speech local+global 77. 00 76. 88 Adding context marginally improves some performances
 8 Feature Sets speech: normalized acoustic-prosodic features lexical: lexical items in the turn autotext: lexical + automatic features alltext: lexical + automatic + manual features +ident: each of above + identifier features
8 Feature Sets speech: normalized acoustic-prosodic features lexical: lexical items in the turn autotext: lexical + automatic features alltext: lexical + automatic + manual features +ident: each of above + identifier features