a9253de0ad65d359092ab3a6564f77a3.ppt
- Количество слайдов: 158



Precise Identification and Citability of Dynamic Data: Recommendations of the RDA Working Group on Data Citation Andreas Rauber Vienna University of Technology Favoritenstr. 9 -11/188 1040 Vienna, Austria rauber@ifs. tuwien. ac. at http: //ww. ifs. tuwien. ac. at/~andi

Motivation Research data is fundamental for science - Results are based on data - Data serves as input for workflows and experiments - Data is the source for graphs and visualisations in publications Data is needed for Reproducibility - Repeat experiments - Verify / compare results Need to provide specific data set - Service for data repositories Source: open. wien. gv. at 1. Put data in data repository, 2. Assign PID (DOI, Ark, URI, …) 3. Make is accessible done!? https: //commons. wikimedia. org/w/index. php? curid=30978545

Identification of Dynamic Data Usually, datasets have to be static - Fixed set of data, no changes: no corrections to errors, no new data being added But: (research) data is dynamic - Adding new data, correcting errors, enhancing data quality, … - Changes sometimes highly dynamic, at irregular intervals Current approaches - Identifying entire data stream, without any versioning - Using “accessed at” date - “Artificial” versioning by identifying batches of data (e. g. annual), aggregating changes into releases (time-delayed!) Would like to identify precisely the data as it existed at a specific point in time

Granularity of Subsets What about the granularity of data to be identified? - Enormous amounts of CSV data - Researchers use specific subsets of data - Need to identify precisely the subset used Current approaches - Storing a copy of subset as used in study -> scalability - Citing entire dataset, providing textual description of subset -> imprecise (ambiguity) - Storing list of record identifiers in subset -> scalability, not for arbitrary subsets (e. g. when not entire record selected) Would like to be able to identify precisely the subset of (dynamic) data used in a process

What we do NOT want… Common approaches to data management… (from Ph. D Comics: A Story Told in File Names, 28. 5. 2010) Source: http: //www. phdcomics. com/comics. php? f=1323

RDA WG Data Citation Research Data Alliance WG on Data Citation: Making Dynamic Data Citeable March 2014 – September 2015 - Concentrating on the problems of large, dynamic (changing) datasets Final version presented Sep 2015 at P 7 in Paris, France Endorsed September 2016 at P 8 in Denver, CO https: //www. rd-alliance. org/groups/data-citation-wg. html
")
RDA WGDC - Solution We have ‒ Data & some means of access („query“)
")
RDA WGDC - Solution We have ‒ Data & some means of access („query“) Make data: time-stamped and versioned Prepare some way of storing the queries
")
RDA WGDC - Solution We have ‒ Data & some means of access („query“) Make data: time-stamped and versioned Prepare some way of storing the queries Data Citation: ‒ Store query with timestamp ‒ Assign the PID to the timestamped query (which, dynamically, leads to the data) Access: Re-execute query on versioned data according to timestamp Dynamic Data Citation: Dynamic data & dynamic citation of data

Data Citation – Deployment Researcher uses workbench to identify subset of data Upon executing selection („download“) user gets - Data (package, access API, …) PID (e. g. DOI) (Query is time-stamped and stored) Hash value computed over the data for local storage Recommended citation text (e. g. Bib. Te. X) PID resolves to landing page - Provides detailed metadata, link to parent data set, subset, … - Option to retrieve original data OR current version OR changes Upon activating PID associated with a data citation - Query is re-executed against time-stamped and versioned DB - Results as above are returned Query store aggregates data usage

Data Citation – Deployment Note: query string provides to identify Researcher uses workbenchexcellent subset of data provenance information („download“) user gets Upon executing selectionon the data set! - Data (package, access API, …) PID (e. g. DOI) (Query is time-stamped and stored) Hash value computed over the data for local storage Recommended citation text (e. g. Bib. Te. X) PID resolves to landing page - Provides detailed metadata, link to parent data set, subset, … - Option to retrieve original data OR current version OR changes Upon activating PID associated with a data citation - Query is re-executed against time-stamped and versioned DB - Results as above are returned Query store aggregates data usage

Data Citation – Deployment Note: query string provides to identify Researcher uses workbenchexcellent subset of data provenance information („download“) user gets Upon executing selectionon the data set! - Data (package, accessimportant advantage over This is an API, …) PID (e. g. DOI) (Query is time-stamped and stored) traditional approaches relying on, e. g. Hash value computed over the data for local storage storing a list of identifiers/DB dump!!! Recommended citation text (e. g. Bib. Te. X) PID resolves to landing page - Provides detailed metadata, link to parent data set, subset, … - Option to retrieve original data OR current version OR changes Upon activating PID associated with a data citation - Query is re-executed against time-stamped and versioned DB - Results as above are returned Query store aggregates data usage

Data Citation – Deployment Note: query string provides to identify Researcher uses workbenchexcellent subset of data provenance information („download“) user gets Upon executing selectionon the data set! - Data (package, accessimportant advantage over This is an API, …) PID (e. g. DOI) (Query is time-stamped and stored) traditional approaches relying on, e. g. Hash value computed over the data for local storage storing a list of identifiers/DB dump!!! Recommended citation text (e. g. Bib. Te. X) PID resolves to landing pageparts of the data are used. Identify which - Provides detailed metadata, link to parent data set, queries If data changes, identify which subset, … - Option to retrieve original data OR current version OR changes (studies) are affected Upon activating PID associated with a data citation - Query is re-executed against time-stamped and versioned DB - Results as above are returned Query store aggregates data usage

Data Citation – Output 14 Recommendations grouped into 4 phases: - Preparing data and query store Persistently identifying specific data sets Resolving PIDs Upon modifications to the data infrastructure 2 -page flyer https: //rd-alliance. org/recommendations-workinggroup-data-citation-revision-oct-20 -2015. html More detailed report: IEEE TCDL 2016 http: //www. ieee-tcdl. org/Bulletin/v 12 n 1/papers/IEEETCDL-DC-2016_paper_1. pdf

Data Citation – Recommendations Preparing Data & Query Store - R 1 – Data Versioning - R 2 – Timestamping - R 3 – Query Store When Data should be persisted - R 4 – Query Uniqueness R 5 – Stable Sorting R 6 – Result Set Verification R 7 – Query Timestamping R 8 – Query PID R 9 – Store Query R 10 – Citation Text When Resolving a PID - R 11 – Landing Page - R 12 – Machine Actionability Upon Modifications to the Data Infrastructure - R 13 – Technology Migration - R 14 – Migration Verification
 Preparing the Data and the Query Store R 1")
Data Citation – Recommendations A) Preparing the Data and the Query Store R 1 – Data Versioning: Apply versioning to ensure earlier states of data sets the data can be retrieved R 2 – Timestamping: Ensure that operations on data are timestamped, i. e. any additions, deletions are marked with a timestamp R 3 – Query Store: Provide means to store the queries and metadata to re-execute them in the future
 Note: Data Citation –& R 2 are already pretty much standard • R")
A) Note: Data Citation –& R 2 are already pretty much standard • R 1 Recommendations in many (RDBMS-) research databases • Different ways to implement • A bit more challenging Preparing the Data and the Query Store for some data types (XML, LOD, …) R 1 – Data Versioning: Apply versioning to ensure earlier states of data sets the data can be retrieved R 2 – Timestamping: Ensure that operations on data are timestamped, i. e. any additions, deletions are marked with a timestamp R 3 – Query Store: Provide means to store the queries and metadata to re-execute them in the future Note: • R 3: query store usually pretty small, even for extremely high query volumes
 Persistently Identify Specific Data sets (1/2) When a data")
Data Citation – Recommendations B) Persistently Identify Specific Data sets (1/2) When a data set should be persisted: R 4 – Query Uniqueness: Re-write the query to a normalized form so that identical queries can be detected. Compute a checksum of the normalized query to efficiently detect identical queries R 5 – Stable Sorting: Ensure an unambiguous sorting of the records in the data set R 6 – Result Set Verification: Compute fixity information/checksum of the query result set to enable verification of the correctness of a result upon re-execution R 7 – Query Timestamping: Assign a timestamp to the query based on the last update to the entire database (or the last update to the selection of data affected by the query or the query execution time). This allows retrieving the data as it existed at query time
 Persistently Identify Specific Data sets (2/2) When a data")
Data Citation – Recommendations B) Persistently Identify Specific Data sets (2/2) When a data set should be persisted: R 8 – Query PID: Assign a new PID to the query if either the query is new or if the result set returned from an earlier identical query is different due to changes in the data. Otherwise, return the existing PID R 9 – Store Query: Store query and metadata (e. g. PID, original and normalized query, query & result set checksum, timestamp, superset PID, data set description and other) in the query store R 10 – Citation Text: Provide citation text including the PID in the format prevalent in the designated community to lower barrier for citing data.
 Resolving PIDs and Retrieving Data R 11 – Landing")
Data Citation – Recommendations C) Resolving PIDs and Retrieving Data R 11 – Landing Page: Make the PIDs resolve to a human readable landing page that provides the data (via query reexecution) and metadata, including a link to the superset (PID of the data source) and citation text snippet R 12 – Machine Actionability: Provide an API / machine actionable landing page to access metadata and data via query re-execution
 Upon Modifications to the Data Infrastructure R 13 –")
Data Citation – Recommendations D) Upon Modifications to the Data Infrastructure R 13 – Technology Migration: When data is migrated to a new representation (e. g. new database system, a new schema or a completely different technology), migrate also the queries and associated checksums R 14 – Migration Verification: Verify successful data and query migration, ensuring that queries can be re-executed correctly

Pilots / Adopters Several adopters - Different types of data, different settings, … - CSV & SQL reference implementation (SBA/TUW) Pilots: - Biomedical Big. Data Sharing, Electronic Health Records (Center for Biomedical Informatics, Washington Univ. in St. Louis) - Marine Research Data Biological & Chemical Oceanography Data Management Office (BCO-DMO) - Vermont Monitoring Cooperative: Forest Ecosystem Monitoring - ARGO Boy Network, British Oceanographic Data Centre (BODC) - Virtual Atomic and Molecular Data Centre (VAMDC) - UK Riverflow Archive, Centre for Ecology and Hydrology

WG Data Citation Pilot CBMI @ WUSTL Cynthia Hudson Vitale, Leslie Mc. Intosh, Snehil Gupta Washington University in St. Luis

Biomedical Adoption Project Goals Implement RDA Data Citation WG recommendation to local Washington U i 2 b 2 Engage other i 2 b 2 community adoptees Contribute source code back to i 2 b 2 community Repository https: //github. com/CBMIWU/Research_Reproducibility Slides http: //bit. ly/2 cn. Wor. U Bibliography https: //www. zotero. org/groups/biomedical_informatics_resrepro

RDA-Mac. Arthur Grant Focus Data Broker Researchers

R 1 and R 2 Implementation 3 1 2 triggers RDC. hist_table* c 1 c 2 c 3 sys_period RDC. table c 1 c 2 c 3 sys_period Postgre. SQL Extension “temporal_tables” *stores history of data changes
 Estimated 20 hours to complete 1 study $150/hr (unsubsidized) $3000")
Return on Investment (ROI) Estimated 20 hours to complete 1 study $150/hr (unsubsidized) $3000 per study 115 research studies per year 14 replication studies

Adoption of Data Citation Outcomes by BCO-DMO Cynthia Chandler, Adam Shepherd
 Marine")
A story of success enabled by RDA An existing repository (http: //bco-dmo. org/) Marine research data curation since 2006 Faced with new challenges, but no new funding e. g. data publication practices to support citation Used the outcomes from the RDA Data Citation Working Group to improve data publication and citation services https: //www. rd-alliance. org/groups/data-citation-wg. html
 Try implementation")
Adoption of Data Citation Outputs Evaluation - Evaluate recommendations (done December 2015) Try implementation in existing BCO-DMO architecture (work began 4 April 2016) Trial - BCO-DMO: R 1 -11 fit well with current architecture; R 12 doable; test as part of Data. ONE node membership; R 13 -14 are consistent with Linked Data approach to data publication and sharing Timeline: - Redesign/protoype completed by 1 June 2016 New citation recommendation by 1 Sep 2016 Report out at RDA P 8 (Denver, CO) September 2016 Final report by 1 December 2016

Vermont Monitoring Cooperative James Duncan, Jennifer Pontius VMC

Ecosystem Monitoring Collaborator Network Data Archive, Access and Integration

USER WORKFLOW TO DATE Modify a dataset changes tracked original data table unchanged Commit to version, assign name computes result hash (table pkid, col names, first col data) and query hash updates data table to new state formalizes version Restore previous version creates new version table from current data table state, walks it back using stored SQL. Garbage collected after a period of time

UK Riverflow Archive Matthew Fry mfry@ceh. ac. uk

UK National River Flow Archive • • • ORACLE Relational database Time series and metadata tables ~20 M daily flow records, + monthly / daily catchment rainfall series Metadata (station history, owners, catchment soils / geology, etc. ) Total size of ~5 GB Time series tables automatically audited, • But reconstruction is complex • Users generally download simple files • But public API is in development / R-NRFA package is out there • Fortunately all access is via single codeset Global Water Information Interest Group meeting RDA 8 th Plenary, 15 th September 2016, Denver

Versioning / citation solution • Automated archiving of entire database – version controlled scripts defining tables, creating / populating archived tables (largely complete) • Fits in with data workflow – public / dev versions – this only works because we have irregular / occasional updates • Simplification of the data model (complete) • API development (being undertaken independently of dynamic citation requirements): • allows subsetting of dataset in a number of ways – initially simply • need to implement versioning (started) to ensure will cope with changes to data structures • Fit to dynamic data citation recommendations? • Largely • Need to address mechanism for users to request / create citable version of a query • Resource required: estimated ~2 person months Global Water Information Interest Group meeting RDA 8 th Plenary, 15 th September 2016, Denver
 Stefan Pröll, SBA")
Reference Implementation for CSV Data (and SQL) Stefan Pröll, SBA

CSV/SQL Reference Implementation 1 38 Reference Implementation available on Github https: //github. com/datascience/RDA-WGDC-CSV-Data-Citation-Prototype Upload interface -->Upload CSV files Migrate CSV file into RDBMS - Generate table structure, identify primary key - Add metadata columns for versioning (transparent) - Add indices (transparent) Dynamic data: upload new version of file - Versioned update / delete existing records in RDBMS Access interface - Track subset creation - Store queries -> PID + Landing Page Barrymieny
 Upload CSV files")
CSV/Git Reference Implementation 2 Based on Git only (no SQL database) Upload CSV files to Git repository SQL-style queries operate on CSV file via API Data versioning with Git Store scripts versioned as well Make subset creation reproducible 39

CSV/Git Reference Implementation 2 Stefan Pröll, Christoph Meixner, Andreas Rauber Precise Data Identification Services for Long Tail Research Data. Proceedings of the intl. Conference on Preservation of Digital Objects (i. PRES 2016), Oct. 3 -6 2016, Bern, Switzerland. Source at Github: https: //github. com/datascience/ RDA-WGDC-CSV-Data-Citation-Prototype Videos: Login: https: //youtu. be/Enra. Iwb. Qf. M 0 Upload: https: //youtu. be/x. Jruif. X 9 E 2 U Subset: https: //www. youtube. com/watch? v=it 4 s. C 5 v. Yi. ZQ Resolver: https: //youtu. be/FHsvjs. UMii. Y Update: https: //youtu. be/c. MZ 0 xo. ZHUy. I 40

Benefits Retrieval of precise subset with low storage overhead Subset as cited or as it is now (including e. g. corrections) Query provides provenance information Query store supports analysis of data usage Checksums support verification Same principles applicable across all settings - Small and large data - Static and dynamic data - Different data representations (RDBMS, CSV, XML, LOD, …) Would work also for more sophisticated/general transformations on data beyond select/project

Interested in implementing? If you have a dataset / are operating a data center that - has dynamic data and / or - allows researchers to select subsets of this data for studies and would like to support precise identification / citability Let us know! - Join RDA WGDC / IG - Support for adoption pilots - Cooperate on implementing and deploying recommendations Collecting feedback, identifying potential issues, …

Thank you! Thanks! https: //rd-alliance. org/working-groups/data-citation-wg. html

The following set of slides was presented by the various adoption pilots at the RDA Plenary in Denver, CO during RDA WGDC break-out session and is also available at the WGDC Repository
 Stefan Pröll, SBA")
Reference Implementation for CSV Data (and SQL) Stefan Pröll, SBA

Large Scale Research Settings RDA recommendations implemented in data infrastructures Required adaptions - Introduce versioning, if not already in place - Capture sub-setting process (queries) - Implement dedicated query store to store queries - A bit of additional functionality (query re-writing, hash functions, …) Done! ? - “Big data”, database driven Well-defined interfaces Trained experts available “Complex, only for professional research infrastructures” ?

Long Tail Research Data Big data, well organized, often used and cited Data set size Amount of data sets Less well organized, “Dark data” non-standardised no dedicated infrastructure [1] Heidorn, P. Bryan. "Shedding light on the dark data in the long tail of science. " Library Trends 57. 2 (2008): 280 -299.

Prototype Implementations Solution for small-scale data - CSV files, no “expensive” infrastructure, low overhead 2 Reference implementations : Git based Prototypes: widely used versioning system - A) Using separate folders - B) Using branches My. SQL based Prototype: - C) Migrates CSV data into relational database Data backend responsible for versioning data sets Subsets are created with scripts or queries via API or Web Interface Transparent to user: always CSV
")
CSV Reference Implementation 2 Git Implementation 1 Upload CSV files to Git repository (versioning) Subsets created via scripting language (e. g. R) Select rows/columns, sort, returns CSV + metadata file Metdata file with script parameters stored in Git (Scripts stored in Git as well) PID assigned to metadata file Use Git to retrieve proper data set version and re-execute script on retrieved file

Git-based Prototype Git Implementation 2 Addresses issues - common commit history, branching data Using Git branching model: Orphaned branches for queries and data - Keeps commit history clean - Allows merging of data files Web interface for queries (CSV 2 JDBC) Use commit hash for identification - Assigned PID hashed with SHA 1 - Use hash of PID as filename (ensure permissible characters)

Git-based Prototype: https: //github. com/Mercynary/recitable Step 1: Select a CSV file in the repository Step 3: Store the query script and metadata Step 2: Create a subset with a SQL query (on CSV data) Step 4: Re-Execute!

My. SQL Prototype Data upload - User uploads a CSV file into the system Data migration from CSV file into RDBMS - Generate table structure - Add metadata columns (versioning) - Add indices (performance) Dynamic data - Insert, update and delete records - Events are recorded with a timestamp Subset creation - User selects columns, filters and sorts records in web interface - System traces the selection process - Exports CSV Barrymieny My. SQL-based Prototype

My. SQL-based Prototype Source at Github: ‒ https: //github. com/datascience/RDA-WGDC-CSV-Data-Citation-Prototype Videos: ‒ ‒ ‒ Login: https: //youtu. be/Enra. Iwb. Qf. M 0 Upload: https: //youtu. be/x. Jruif. X 9 E 2 U Subset: https: //www. youtube. com/watch? v=it 4 s. C 5 v. Yi. ZQ Resolver: https: //youtu. be/FHsvjs. UMii. Y Update: https: //youtu. be/c. MZ 0 xo. ZHUy. I

CSV Reference Implementation 2 Stefan Pröll, Christoph Meixner, Andreas Rauber Precise Data Identification Services for Long Tail Research Data. Proceedings of the intl. Conference on Preservation of Digital Objects (i. PRES 2016), Oct. 3 -6 2016, Bern, Switzerland. Source at Github: https: //github. com/datascience/ RDA-WGDC-CSV-Data-Citation-Prototype Videos: Login: https: //youtu. be/Enra. Iwb. Qf. M 0 Upload: https: //youtu. be/x. Jruif. X 9 E 2 U Subset: https: //www. youtube. com/watch? v=it 4 s. C 5 v. Yi. ZQ Resolver: https: //youtu. be/FHsvjs. UMii. Y Update: https: //youtu. be/c. MZ 0 xo. ZHUy. I

WG Data Citation Pilot CBMI @ WUSTL Cynthia Hudson Vitale, Leslie Mc. Intosh, Snehil Gupta Washington University in St. Luis

Moving Biomedical Big Data Sharing Forward An adoption of the RDA Data Citation of Evolving Data Recommendation to Electronic Health Records Leslie Mc. Intosh, PHD, MPH Cynthia Hudson Vitale, MA 2016 @mcintold @cynhudson RDA P 8 Denver, USA September

Background

Director, Center for Biomedical Informatics Leslie Mc. Intosh, PHD, MPH Data Services Coordinator Cynthia Hudson Vitale, MA

BDaa. S Biomedical Data as a Service Data Broker Biomedical Data Repository i 2 b 2 Application Researchers

Move some of the responsibility of reproducibility Biomedical Researcher Biomedical Pipeline

RDA/Mac. Arthur Grant

Biomedical Adoption Project Goals Implement RDA Data Citation WG recommendation to local Washington U i 2 b 2 Engage other i 2 b 2 community adoptees Contribute source code back to i 2 b 2 community

RDA Data Citation WG Recommendations R 1: Data Versioning R 2: Data Timestamping R 3, R 9: Query Store R 7: Query Timestamping R 8: Query PID R 10: Query Citation

Internal Implementation Requirements Scalable Available for Postgre. SQL Actively supported Easy to maintain Easy for data brokers to use

RDA-Mac. Arthur Grant Focus Data Broker Researchers

R 1 and R 2 Implementation 3 1 2 triggers RDC. hist_table* c 1 c 2 c 3 sys_period RDC. table c 1 c 2 c 3 sys_period Postgre. SQL Extension “temporal_tables” *stores history of data changes

ETL Incrementals Source Data Update? … sys_period 2016 -9 -8 00: 00, 2016 -9 -9 00: 00 RDC. table RDC. hist_table … Insert? Old Data 2016 -9 -9 00: 00, NULL … sys_period 2016 -9 -9 00: 00, NULL

R 3, R 7, R 8, R 9, and R 10 Implementation 1 2 RDC. table RDC. hist_table 3 • functions • triggers • query audit tables Postgre. SQL Extension “temporal_tables” RDC. table_with_history (view)

Data Reproducibility Workflow

Bonus Feature: Determine if Change Occurred

Future Developments Develop a process for sharing Query PID with researchers in an automated way Resolve Query PIDs to a landing page with Query metadata Implement research reproducibility requirements in other systems as possible

Outcomes and Support

Obtained Outcomes Implemented WG recommendations Engaged with other i 2 b 2 adoptees (Harvard, Nationwide Children’s Hospital)
 Scientific manuscript based on our proof of")
Dissemination Poster presentation (Harvard U, July 2016) Scientific manuscript based on our proof of concept to AMIA TBI/CRI 2017 conference Sharing the code with the community
 Estimated 20 hours to complete 1 study $150/hr (unsubsidized) $3000")
Return on Investment (ROI) Estimated 20 hours to complete 1 study $150/hr (unsubsidized) $3000 per study 115 research studies per year 14 replication studies

Funding Support Mac. Arthur Foundation 2016 Adoption Seeds program Foundation through a sub-contract with Research Data Alliance Washington University Institute of Clinical and Translational Sciences NIH CTSA Grant Number UL 1 TR 000448 and UL 1 TR 000448 -09 S 1 Siteman Cancer Center at Washington University NIH/NCI Grant P 30 CA 091842 -14

Center for Biomedical Informatics @WUSTL Teams for Reproducible Research NIH-NLM Supplement Leslie Mc. Intosh Cynthia Hudson-Vitale Anthony Juehne Rosalia Alcoser Xiaoyan ‘Sean’ Liu Brad Evanoff RDA Collaborators Andreas Rauber Stefan Pröll Research Data Alliance Leslie Mc. Intosh Cynthia Hudson-Vitale Anthony Juehne Snehil Gupta Connie Zabarovskaya Brian Romine Dan Vianello

Wash. U CBMI Research Reproducibility Resources Repository https: //github. com/CBMIWU/Research_Reproducibility Slides http: //bit. ly/2 cn. Wor. U Bibliography https: //www. zotero. org/groups/biomedical_informatics_resr epro

Adoption of Data Citation Outcomes by BCO-DMO Cynthia Chandler, Adam Shepherd
 Marine")
A story of success enabled by RDA An existing repository (http: //bco-dmo. org/) Marine research data curation since 2006 Faced with new challenges, but no new funding e. g. data publication practices to support citation Used the outcomes from the RDA Data Citation Working Group to improve data publication and citation services https: //www. rd-alliance. org/groups/data-citation-wg. html

BCO-DMO Curated Data BCO-DMO is a thematic, domain-specific repository funded by NSF Ocean Sciences and Polar Programs BCO-DMO curated data are - Served: http: //bco-dmo. org (URLs, URIs) - Published: at an Institutional Repository (Cross. Ref DOI) http: //dx. doi. org/10. 1575/1912/4847 - Archived: at NCEI, a US National Data Center http: //data. nodc. noaa. gov/cgibin/iso? id=gov. noaa. nodc: 0078575 for Linked Data URI: http: //lod. bco-dmo. org/id/dataset/3046
")
BCO-DMO Dataset Landing Page (Mar ‘ 16)
")
Initial Architecture Design Considerations (Jan 2016)
")
Modified Architecture (March 2016)

BCO-DMO Data Publication System Components BCO-DMO publishes data to WHOAS and a DOI is assigned. The BCO-DMO architecture now supports data versioning.

BCO-DMO Data Citation System Components

BCO-DMO Data Set Landing Page
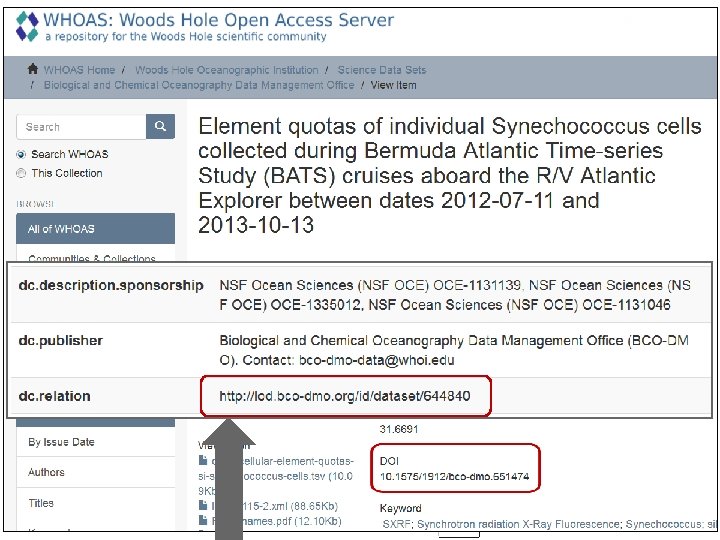

BCO-DMO Data Set Landing Page

Linked to Publication via DOI

New Capabilities … BCO-DMO becoming a Data. ONE Member Node https: //search. dataone. org/

New Capabilities … BCO-DMO Data Set Citation

Thank you … To the Data Citation Working Group for their efforts https: //www. rd-alliance. org/groups/data-citation-wg. html RDA US for funding this adoption project TIMELINE: - Redesign/protoype completed by 1 June 2016 - New citation recommendation by 1 Sep 2016 - Report out at RDA P 8 (Denver, CO) September 2016 - Final report by 1 December 2016 Cyndy Chandler @cyn. DC 42 ORCID: 0000 -0003 -2129 -1647 @bcodmo cchandler@whoi. edu

EXTRA SLIDES Removed these to reduce talk to 10 -15 minutes
 Try implementation")
Adoption of Data Citation Outputs Evaluation - Evaluate recommendations (done December 2015) Try implementation in existing BCO-DMO architecture (work began 4 April 2016) Trial - BCO-DMO: R 1 -11 fit well with current architecture; R 12 doable; test as part of Data. ONE node membership; R 1314 are consistent with Linked Data approach to data publication and sharing NOTE: adoption grant received from RDA US (April 2016)
 of evolving data DC goals: to create identification mechanisms that:")
RDA Data Citation (DC) of evolving data DC goals: to create identification mechanisms that: - allow us to identify and cite arbitrary views of data, from a single record to an entire data set in a precise, machine-actionable manner - allow us to cite and retrieve that data as it existed at a certain point in time, whether the database is static or highly dynamic DC outcomes: 14 recommendations and associated documentation - ensuring that data are stored in a versioned and timestamped manner - identifying data sets by storing and assigning persistent identifiers (PIDs) to timestamped queries that can be reexecuted against the timestamped data store

RDA Data Citation WG Recommendations » » Data Versioning: For retrieving earlier states of datasets the data need to be versioned. Markers shall indicate inserts, updates and deletes of data in the database. » » Data Timestamping: Ensure that operations on data are timestamped, i. e. any additions, deletions are marked with a timestamp. » » Data Identification: The data used shall be identified via a PID pointing to a timestamped query, resolving to a landing page. Oct 2015 version w/ 14 recommendations DC WG chairs: Andreas Rauber, Ari Asmi, Dieter van Uytvanck
 procedure: when a BCO-DMO data set is updated … A copy")
New capability (implemented) procedure: when a BCO-DMO data set is updated … A copy of the previous version is preserved Request a DOI for the new version of data Publish data, and create new landing page for new version of data, with new DOI assigned BCO-DMO database has links to all versions of the data (archived and published) Both archive and published dataset landing pages have links back to best version of full dataset at BCO-DMO data set landing page displays links to all archived and published versions

REFERENCES Extended description of recommendations Altman and Crosas. 2013. “Evolution of Data Citation …” CODATA-ICSTI 2013. “Out of cite, out of mind” FORCE 11 https: //www. force 11. org/about/mission-and-guiding-principles R. E. Duerr, et al. “On the utility of identification schemes for digital earth science data”, ESI, 2011.

Vermont Monitoring Cooperative James Duncan, Jennifer Pontius VMC

Implementation of Dynamic Data Citation James Duncan and Jennifer Pontius 9/16/2016 james. duncan@uvm. edu, www. uvm. edu/vmc

Ecosystem Monitoring Collaborator Network Data Archive, Access and Integration

Many Disciplines, Many Contributors VMC houses any data related to forest ecosystem condition, regardless of affiliation or discipline

Why We Need It Continually evolving datasets Some errors not caught till next field season Frequent reporting and publishing

Dynamic Data Citation – Features Needed Light footprint on database resources Works on top of existing catalog and metadata Works in an institutionally managed PHP/My. SQL environment User-driven control of what quantity of change constitutes a version Integration with management portal Track granular changes in data

User Workflow to Date Modify a dataset - changes tracked - original data table unchanged Commit to version, assign name - computes result hash (table pkid, col names, first col data) and query hash - updates data table to new state - formalizes version Restore previous version - creates new version table from current data table state, - walks it back using stored SQL. - Garbage collected after a period of time

User Workflow, still to come Web-based data editing validation DOI minting integration Public display Subsetting workflow Other methods of data modification? Upgrade to rest of system V 1. 1 DOI: V 1. 2 DOI: V 1. 3 Query 1 Unsaved DOI?

Technical Details Version Info Table Version Datase Version PID t ID Name Version ID 23456 3525 Version 1. 5 23574 3525 Unsaved Person ID Query Hash Result Hash Timesta mp 3 …. …. -1 …. NULL …. Step Tracking Table (Child of Version Info) Step ID Version PID Forward Backward Order 983245 23574 DELETE FROM… INSERT INTO… 1 983245 23574 UPDATE SET site=“Winhall ”… UPDATE SET site=“Lye Brook”… 2

Implementation Challenges and Questions Challenges Large updates Re-creation of past versions, in terms of garbage collection and storage Questions Query uniqueness checking and query normalization Efficient but effective results hashing strategies Linear progression of data, versus branching network

Acknowledgments Adoption seed funding - Mac. Arthur Foundation and the Research Data Alliance The US Forest Service State and Private Forestry program for core operational funding of the VMC Fran Berman, Yolanda Meleco and the other adopters who have been sharing their experiences. All the VMC cooperators that contribute

Thank you!

ARGO Justin Buck, Helen Glaves BODC

RDA P 8 2016, Denver, 16 th September 2016 WG Data Citation: Adoption meeting Argo DOI pilot Justin Buck, National Oceanography Centre (UK), juck@bodc. ac. uk Thierry Carval, Ifremer (France), thierry. carval@ofremer. fr Thomas Loubrieu, Ifremer (France), thomas. loubrieu@ifremer. fr Frederic Merceur, Ifremer (France), frederic. merceur@ifremer. fr

300+ citations per year How to cite Argo data at a given point in time? Possible with a single DOI?
 Raw data Delayed mode quality control Data Assembly Centres (DAC)")
Argo data system (simplified) Raw data Delayed mode quality control Data Assembly Centres (DAC) (national level, 10 of, RT processing and QC) Global data assembly Centres (GDAC) (2 of, mirrored, ftp access, repository of Net. CDF files, no version control, latest version served) Data users GTS (+GTSPP archive)

Key associated milestones 2014 – Introduction of dynamic data into the Data. Cite metadata schema - https: //schema. datacite. org/ - Snapshots were used as an interim solution for Argo 2015 – RDA recommendations on evolving data: - https: //rd-alliance. org/system/files/RDA-DCRecommendations_151020. pdf - Legacy GDAC architecture does not permit full implementation
 Obs time ++")
How to apply a DOI for Argo Archive (collection of snapshots/granules) Obs time ++ ++ + +++ + ++ ++ + Obs time State time ++ State time + Obs time + +++ + ++ + +++ + + ++ To cite a particular snapshot one can potentially cite a time slice of an archive i. e. the snapshot at a given point in time.
. Argo float data and metadata from Global Data Assembly")
New single DOI Argo (2000). Argo float data and metadata from Global Data Assembly Centre (Argo GDAC). SEANOE. http: //doi. org/10. 17882/42182

# key used to identify snapshot

# key used to identify snapshot http: //www. seanoe. org/data/00311/42182/#45420

Step towards RDA recommendation Archive snapshots enables R 1 and R 2 at monthly granularity R 1 – Data Versioning R 2 – Timestamping Argo Pilot effectively uses predetermined referencing of snapshots removing the need for requirements R 3 to R 7. # keys are PIDs for the snapshots and have associated citation texts. R 3 – Query Store Facilities R 4 – Query Uniqueness R 5 – Stable Sorting R 6 – Result Set Verification R 7 – Query Timestamping R 8 – Query PID R 9 – Store Query R 10 – Automated Citation Texts SEANOE landing page architecture means R 11 and R 12 effectively met R 11 – Landing Page R 12 – Machine Actionability Final two requirements untested at this stage R 13 – Technology Migration R 14 – Migration Verification

Summary There is now a single DOI for Argo - Takes account of legacy GDAC architecture - Monthly temporal granularity - Enables both reproducible research and simplifies the tracking of citations - ‘#’ rather than ‘? ’ in identifier takes account of current DOI resolution architecture Extensible to other observing systems such as Ocean. SITES and EGO The concept allows for different subsets of Argo data e. g. ocean basins, Bio-Argo data

Progress on Data Citation within VAMDC C. M. Zwölf and VAMDC Consortium carlo-maria. zwolf@obspm. fr

From RDA Data Citation Recommendations to new paradigms for citing data from VAMDC C. M. Zwölf and VAMDC consortium RDA 8 th Plenary - Denver

The Virtual Atomic and Molecular Data Centre ØFederates 29 heterogeneous databases http: //portal. vamdc. org/ Plasma sciences Lighting technologies Astrophysics VAMDC Health and clinical sciences Single and unique access to heterogeneou s A+M Databases Fusion technologies Environmental sciences Atmospheric Physics ØThe “V” of VAMDC stands for Virtual in the sense that the e-infrastructure does not contain data. The infrastructure is a wrapping for exposing in a unified way a set of heterogeneous databases. ØThe consortium is politically organized around a Memorandum of understanding (15 international members have signed the Mo. U, 1 November 2014) ØHigh quality scientific data come from different Physical/Chemical Communities ØProvides data producers with a large dissemination platform ØRemove bottleneck between dataproducers and wide body of users

The VAMDC infrastructure technical architecture Existing Independent A+M database

The VAMDC infrastructure technical architecture Resource registered into Registry Layer Standard Layer Existing Independent A+M database VAMDC wrapping layer VAMDC Node Accept queries submitted in standard grammar Results formatted into standard XML file (XSAMS)

The VAMDC infrastructure technical architecture Resource registered into Registry Layer Asks for available resources Standard Layer Existing Independent A+M database VAMDC wrapping layer VAMDC Node Accept queries submitted in standard grammar Results formatted into standard XML file (XSAMS) VAMDC Clients (dispatch query on all the registered resources) • Portal • Spec. View • Spect. Col Unique A+M query Set of standard files

The VAMDC infrastructure technical architecture Resource registered into Registry Layer Asks for available resources Standard Layer Existing Independent A+M database VAMDC wrapping layer VAMDC Node • • Accept queries submitted in standard grammar Results formatted into standard XML file (XSAMS) VAMDC Clients (dispatch query on all the registered resources) • Portal • Spec. View • Spect. Col Unique A+M query Set of standard files VAMDC is agnostic about the local data storage strategy on each node. Each node implements the access/query/result protocols. There is no central management system. Decisions about technical evolutions are made by consensus in Consortium. Ø It is both technical and political challenging to implement the WG recommendations.

Let us implement the recommendation!! The problem is more anthropological than technical… Tagging and versioning data What does it really mean data citation?

Let us implement the recommendation!! The problem is more anthropological than technical… Tagging and versioning data What does it really mean data citation?

Let us implement the recommendation!! The problem is more anthropological than technical… We see technically how to do that Ok, but What is the data granularity for tagging? Tagging and versioning data Naturally it is the dataset (A+M data have no meaning outside this given context) But each data provider defines differently what a dataset is. What does it really mean data citation?

Let us implement the recommendation!! The problem is more anthropological than technical… We see technically how to do that Ok, but What is the data granularity for tagging? Tagging and versioning data Naturally it is the dataset (A+M data have no meaning outside this given context) But each data provider defines differently what a dataset is. Everyone knows what it is! Yes, but everyone has its own definition What does it really mean data citation? RDA cite databases record or output files. (an extracted data file may have an H-factor) VAMDC cite all the papers used for compiling the content of a given output file.

Let us implement the recommendation!! Implementation will be an overlay to the standard / output layer, thus independent from any specific data-node Two layers mechanisms Tagging versions of data 1 Fine grained granularity: Evolution of XSAMS output standard for tracking data modifications 2 Coarse grained granularity: At each data modification to a given data node, the version of the Data-Node changes With the second mechanism we know that something changed : in other words, we know that the result of an identical query may be different from one version to the other. The detail of which data changed is accessible using the first mechanisms.

Let us implement the recommendation!! Implementation will be an overlay to the standard / output layer, thus independent from any specific data-node Two layers mechanisms Tagging versions of data 1 Fine grained granularity: Evolution of XSAMS output standard for tracking data modifications 2 Coarse grained granularity: At each data modification to a given data node, the version of the Data-Node changes With the second mechanism we know that something changed : in other words, we know that the result of an identical query may be different from one version to the other. The detail of which data changed is accessible using the first mechanisms. Query Store Is built over the versioning of Data Is plugged over the existing VAMDC data-extraction mechanisms. Due to the distributed VAMDC architecture, the Query Store architecture is similar to a log-service.

Data-Versioning: overview of the fine grained mechanisms We adopted a change of paradigm (weak structuration): Element q … Radiative process 2 … Radiative process 1 Element 2 Radiative process n Collisional process 1 Energy State 2 Collisional process 2 Energy State p … Energy State 1 … Output XSAMS file Element 1 Collisional process m

Data-Versioning: overview of the fine grained mechanisms We adopted a change of paradigm (weak structuration): Radiative process 1 Element 1 Version 1 Radiative process 2 Version 2 Collisional process 1 Energy State 2 (tagged according to infrastructure state & updates) Collisional process 2 Energy State p … Energy State 1 Radiative process n … … Element q (tagged according to infrastructure state & updates) … Output XSAMS file Element 2 Collisional process m

Data-Versioning: overview of the fine grained mechanisms We adopted a change of paradigm (weak structuration): Radiative process 1 Element 1 Version 1 Radiative process 2 Version 2 Collisional process 1 Energy State 2 (tagged according to infrastructure state & updates) Collisional process 2 Energy State p … Energy State 1 Radiative process n … … Element q (tagged according to infrastructure state & updates) … Output XSAMS file Element 2 Collisional process m

Data-Versioning: overview of the fine grained mechanisms We adopted a change of paradigm (weak structuration): This approach has several advantages: • It solves the data tagging granularity problem • It is independent from what is considered a dataset • The new files are compliant with old libraries & processing programs • We add a new feature, an overlay to the existing structure • We induce a structuration, without changing the structure (weak structuration)

Data-Versioning: overview of the fine grained mechanisms We adopted a change of paradigms: This approach has several advantages: • It solves the data tagging granularity problem • It is independent from what is considered a dataset • The new files are compliant with old libraries & processing programs • We add a new feature, an overlay to the existing structure • We induce a structuration, without changing the structure (weak structuration) Technical details described in New model for datasets citation and extraction reproducibility in VAMDC, C. M. Zwölf, N. Moreau, M. -L. Dubernet, In press J. Mol. Spectrosc. (2016), http: //dx. doi. org/10. 1016/j. jms. 2016. 04. 009 Arxiv version: https: //arxiv. org/abs/1606. 00405

Let us focus on the query store: The difficulty we have to cope with: • Handle a query store in a distributed environment (RDA did not design it for these configurations). • Integrate the query store with the existing VAMDC infrastructure.

Let us focus on the query store: The difficulty we have to cope with: • Handle a query store in a distributed environment (RDA did not design it for these configurations). • Integrate the query store with the existing VAMDC infrastructure. The implementation of the query store is the goal of a joint collaboration between VAMDC and RDA-Europe. • Development started during spring 2016. • Final product released during 2017.

Let us focus on the query store: The difficulty we have to cope with: • Handle a query store in a distributed environment (RDA did not design it for these configurations). • Integrate the query store with the existing VAMDC infrastructure. The implementation of the query store is the goal of a jointly collaboration between VAMDC and RDA-Europe. • Development started during spring 2016. • Final product released during 2017. Collaboration with Elsevier for embedding the VAMDC query store into the pages displaying the digital version of papers. Designing technical solution for • Paper / data linking at the paper submission (for authors) • Paper / data linking at the paper display (for readers)

Let us focus on the query store: Sketching the functioning – From the final-user point of view: Sub qu mitt ery ing Data extraction procedure VAMDC portal (query interface) Query VAMDC infrastructur e Computed response Access to the output data file VAMD portal (result part) Digital Unique Identifier associated to the current extraction

Let us focus on the query store: Sketching the functioning – From the final-user point of view: Sub qu mitt ery ing Data extraction procedure VAMDC portal (query interface) Query VAMDC infrastructur e Computed response Access to the output data file VAMD portal (result part) Digital Unique Identifier associated to the current extraction Resolves The original query Version of the infrastructure when the query was processed List of publications needed for answering the query When supported (by the VAMDC federated DB): retrieve the output data-file as it was computed (query re-execution) Query Metadata Landing Page Query Store Date & time where query was processed

Let us focus on the query store: Sketching the functioning – From the final-user point of view: VAMDC portal (query interface) Group arbitrary set of queries (with related DUI) and assign them a DOI to use in publications VAMDC infrastructur e Computed response VAMD portal (result part) Digital Unique Identifier associated to the current extraction The original query Date & time where query was processed Version of the infrastructure when the query was processed List of publications needed for answering the query When supported (by the VAMDC federated DB): retrieve the output data-file as it was computed (query re-execution) Query Metadata Landing Page Query Store Manage queries (with authorisation/authe ntication) Query Access to the output data file Resolves Use DOI in papers Sub qu mitt ery ing Data extraction procedure

Let us focus on the query store: Sketching the functioning – From the final-user point of view: VAMDC portal (query interface) Query Group arbitrary set of queries (with related DUI) and assign them a DOI to use in publications Editors may follow the citation pipeline : credit delegation applies Computed response VAMD portal (result part) Digital Unique Identifier associated to the current extraction The original query Date & time where query was processed Version of the infrastructure when the query was processed List of publications needed for answering the query When supported (by the VAMDC federated DB): retrieve the output data-file as it was computed (query re-execution) Query Metadata Landing Page Query Store Manage queries (with authorisation/authe ntication) VAMDC infrastructur e Access to the output data file Resolves Use DOI in papers Sub qu mitt ery ing Data extraction procedure

Let us focus on the query store: Sketching the functioning – Technical internal point of view: VAMDC Node Notification Query Store Listener Service 1 When a node receives a user query, it notifies to the Listener Service the following information: • • The identity of the user (optional) The used client software The identifier of the node receiving the query The version (with related timestamp) of the node receiving the query The version of the output standard used by the node for replying the results The query submitted by the user The link to the result data.

Let us focus on the query store: Sketching the functioning – Technical internal point of view: VAMDC Node Notification 2 For each received notification, the listener check if it exists an already existing query: • • • Having the same Query Having the same node version Submitted to the same node and having the same node version Query Store Listener Service

Let us focus on the query store: Sketching the functioning – Technical internal point of view: VAMDC Node Notification Query Store Listener Service • • 2 For each received notification, the listener check if it exists an already existing query: • • g tin xis t e Having the same Query Having the same node version Submitted to the same node and having the same node version ex No • • • g in ist Provides the Query with a unique time-stamped identifier Following the link, get data and process them for extracting relevant metadata (ex. Bibtex of references used for compiling the output file) Store these relevant metadata If identity of user is provided, we associate the user with the Query ID • We get the already existing unique identifier and (incrementally) associate the new query timestamp (and if provided the identifier of the user) with the query Identifier

Let us focus on the query store: Sketching the functioning – Technical internal point of view: VAMDC Node Notification Query Store Listener Service Remark on query uniqueness: • The query language supported by the VAMDC infrastructure is VSS 2 (VAMDC SQL Subset 2, http: //vamdc. eu/documents/standards/query. Language/vss 2. html). • We are working on a specific VSS 2 parser (based on Antlr) which should identify, from queries expressed in different ways, the ones that are semantically identical • We are designing this analyzer as an independent module, hoping to extend it to all SQL.

Final remarks: • Our aims: • Provide the VAMDC infrastructure with an operational query store • Share our experience with other data-providers • Provide data-providers with a set of libraries/tools/methods for an easy implementation of a query store. • We will try to build a generic query store (i. e. using generic software blocks)

UK Riverflow Archive Matthew Fry mfry@ceh. ac. uk

UK National River Flow Archive 1500 1000 500 0 1840 1850 1860 1870 1880 1890 1900 1910 1920 1930 1940 1950 1960 1970 1980 1990 2000 2010 Open Stations Curation and dissemination of regulatory river flow data for research and other access Data used for significant research outputs, and a large number of citations annually Updated annually but also regular revision of entire flow series through time (e. g. stations resurveyed) Internal auditing, but history is not exposed to users

UK National River Flow Archive ORACLE Relational database Time series and metadata tables ~20 M daily flow records, + monthly / daily catchment rainfall series Metadata (station history, owners, catchment soils / geology, etc. ) Total size of ~5 GB Time series tables automatically audited, - But reconstruction is complex Users generally download simple files But public API is in development / R-NRFA package is out there Fortunately all access is via single codeset

Our data citation requirements Cannot currently cite whole dataset Allow citation a subset of the data, as it was at the time Fit with current workflow / update schedule, and requirements for reproducibility Fit with current (file download) and future (API) user practices Resilient to gradual or fundamental changes in technologies used Allow tracking of citations in publications

Options for versioning / citation “Regulate” queries: - limitations on service provided Enable any query to be timestamped / cited / reproducible: - does not readily allow verification (e. g. checksum) of queries (R 7), or storage of queries (R 9) Manage which queries can be citable: - limitation on publishing workflow?

Versioning / citation solution Automated archiving of entire database – version controlled scripts defining tables, creating / populating archived tables (largely complete) Fits in with data workflow – public / dev versions – this only works because we have irregular / occasional updates Simplification of the data model (complete) API development (being undertaken independently of dynamic citation requirements): - allows subsetting of dataset in a number of ways – initially simply - need to implement versioning (started) to ensure will cope with changes to data structures Fit to dynamic data citation recommendations? - Largely - Need to address mechanism for users to request / create citable version of a query Resource required: estimated ~2 person months
a9253de0ad65d359092ab3a6564f77a3.ppt