

e2952095f9f4cb2bb0dea77e69c7c7c0.ppt
- Количество слайдов: 88
 Please interrupt me at any point! Online Advertising Open lecture at Warsaw University February 25/26, 2011 Ingmar Weber Yahoo! Research Barcelona ingmar@yahoo-inc. com
Please interrupt me at any point! Online Advertising Open lecture at Warsaw University February 25/26, 2011 Ingmar Weber Yahoo! Research Barcelona ingmar@yahoo-inc. com
 Disclaimers & Acknowledgments • This talk presents the opinions of the author. It does not necessarily reflect the views of Yahoo! Inc. or any other entity. • Algorithms, techniques, features, etc. mentioned here might or might not be in use by Yahoo! or any other company. • Many of the slides in this lecture are based on tables/graphs from the referenced papers. Please see the actual papers for more details.
Disclaimers & Acknowledgments • This talk presents the opinions of the author. It does not necessarily reflect the views of Yahoo! Inc. or any other entity. • Algorithms, techniques, features, etc. mentioned here might or might not be in use by Yahoo! or any other company. • Many of the slides in this lecture are based on tables/graphs from the referenced papers. Please see the actual papers for more details.
 Review from last lecture • Lots of money – Ads essentially pay for the WWW • Mostly sponsored search and display ads – Sp. search: sold using variants of GSP – Disp. ads: sold in GD contracts or on the spot • Many computational challenges – Finding relevant ads, predicting CTRs, new/tail content and queries, detecting fraud, …
Review from last lecture • Lots of money – Ads essentially pay for the WWW • Mostly sponsored search and display ads – Sp. search: sold using variants of GSP – Disp. ads: sold in GD contracts or on the spot • Many computational challenges – Finding relevant ads, predicting CTRs, new/tail content and queries, detecting fraud, …
 Plan for today and tomorrow • So far – Mostly introductory, “text book material” • Now – Mostly recent research papers – Crash course in machine learning, information retrieval, economics, … Hopefully more “think-along” (not sing-along) and not “shut-up-and-listen”
Plan for today and tomorrow • So far – Mostly introductory, “text book material” • Now – Mostly recent research papers – Crash course in machine learning, information retrieval, economics, … Hopefully more “think-along” (not sing-along) and not “shut-up-and-listen”
") But first … • Third party cookies www. bluekai. com (many others …)
But first … • Third party cookies www. bluekai. com (many others …)
 Efficient Online Ad Serving in a Display Advertising Exchange Keving Lang, Joaquin Delgado, Dongming Jiang, et al. WSDM’ 11
Efficient Online Ad Serving in a Display Advertising Exchange Keving Lang, Joaquin Delgado, Dongming Jiang, et al. WSDM’ 11
 Not so simple landscape for D A Advertisers “Buy shoes at nike. com” “Visit asics. com today” “Rolex is great. ” Publishers A running blog The legend of Cliff Young Celebrity gossip Users 32 m, likes running 50 f, loves watches 16 m, likes sports Basic problem: Given a (user, publisher) pair, find a good ad(vertiser)
Not so simple landscape for D A Advertisers “Buy shoes at nike. com” “Visit asics. com today” “Rolex is great. ” Publishers A running blog The legend of Cliff Young Celebrity gossip Users 32 m, likes running 50 f, loves watches 16 m, likes sports Basic problem: Given a (user, publisher) pair, find a good ad(vertiser)
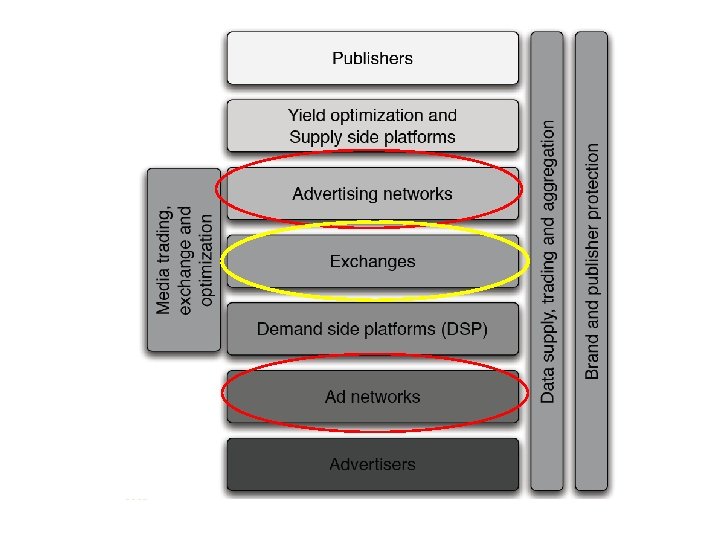
 and demand") Ad networks and Exchanges • Ad networks – Bring together supply (publishers) and demand (advertisers) – Have bilateral agreements via revenue sharing to increase market fluidity • Exchanges – Do the actual real-time allocation – Implement the bilateral agreements
Ad networks and Exchanges • Ad networks – Bring together supply (publishers) and demand (advertisers) – Have bilateral agreements via revenue sharing to increase market fluidity • Exchanges – Do the actual real-time allocation – Implement the bilateral agreements
 D") Middle-aged, middle-income New Yorker visits the web site of Cigar Magazine (P 1) D only known at end. User constraints: no alcohol ads to minors Supply constraints: conservative network doesn’t want left publishers Demand constraints: Premium blogs don’t want spammy ads
Middle-aged, middle-income New Yorker visits the web site of Cigar Magazine (P 1) D only known at end. User constraints: no alcohol ads to minors Supply constraints: conservative network doesn’t want left publishers Demand constraints: Premium blogs don’t want spammy ads
 Valid Paths & Objective Function
Valid Paths & Objective Function
 Depth-first search enumeration Algorithm A Worst case running time? Typical running time?
Depth-first search enumeration Algorithm A Worst case running time? Typical running time?
 Algorithm B US pruning Upper bound Why? Worst case running time? Sum vs. product? Optimizations? D pruning
Algorithm B US pruning Upper bound Why? Worst case running time? Sum vs. product? Optimizations? D pruning
 Reusable Precomputation Cannot fully enforce D Depends on reachable sink … … which depends on U What if space limitations? How would you prioritize?
Reusable Precomputation Cannot fully enforce D Depends on reachable sink … … which depends on U What if space limitations? How would you prioritize?
 Experiments – artificial data
Experiments – artificial data
 Experiments – real data
Experiments – real data
 Competing for Users’ Attention: On the Interplay between Organic and Sponsored Search Results Christian Danescu-Niculescu. Mizil, Andrei Broder, et al. WWW’ 10 What would you investigate? What would you suspect?
Competing for Users’ Attention: On the Interplay between Organic and Sponsored Search Results Christian Danescu-Niculescu. Mizil, Andrei Broder, et al. WWW’ 10 What would you investigate? What would you suspect?
 Things to look at • General bias for near-identical things – Ads are preferred (as further “North”) – Organic results are preferred • Interplay between ad CTR and result CTR – Better search results, less ad clicks? – Mutually reinforcing? • Dependence on type – Navigational query vs. informational query – Responsive ad vs. incidental ad
Things to look at • General bias for near-identical things – Ads are preferred (as further “North”) – Organic results are preferred • Interplay between ad CTR and result CTR – Better search results, less ad clicks? – Mutually reinforcing? • Dependence on type – Navigational query vs. informational query – Responsive ad vs. incidental ad
 Data • One month of traffic for subset of Y! search servers • Only North ads, served at least 50 times • For each query qi most clicked ad Ai* and most clicked organic result Oi* • 63, 789 (qi, Oi*, Ai*) triples • Bias?
Data • One month of traffic for subset of Y! search servers • Only North ads, served at least 50 times • For each query qi most clicked ad Ai* and most clicked organic result Oi* • 63, 789 (qi, Oi*, Ai*) triples • Bias?
Commercial bias? • Look at A* and O* with identical domain • Probably similar") (Non-)Commercial bias? • Look at A* and O* with identical domain • Probably similar quality … • … but (North) ad is higher • What do you think? • In 52% ctr. O > ctr. A
(Non-)Commercial bias? • Look at A* and O* with identical domain • Probably similar quality … • … but (North) ad is higher • What do you think? • In 52% ctr. O > ctr. A
 ctr.") av. ctr. O av. ctr. A Correlation ctr. O For given (range of) ctr. O bucket all ads. ctr. A
av. ctr. O av. ctr. A Correlation ctr. O For given (range of) ctr. O bucket all ads. ctr. A
 av. ctr. O av. ctr. A Navigational vs. non-navigational ctr. O ctr. A Navigational: antagonistic effect Non-navigational: (mild) reinforcement
av. ctr. O av. ctr. A Navigational vs. non-navigational ctr. O ctr. A Navigational: antagonistic effect Non-navigational: (mild) reinforcement
 Dependence on similarity Bag of words for title terms (“Free Radio”, “Pandora Radio – Listen to Free Internet Radio, Find New Music”) = 2/9
Dependence on similarity Bag of words for title terms (“Free Radio”, “Pandora Radio – Listen to Free Internet Radio, Find New Music”) = 2/9
 av. ctr. A Dependence on similarity
av. ctr. A Dependence on similarity
 A simple model Want to model Also need:
A simple model Want to model Also need:
 shape of overlap vs. ad click-through-rate") A simple model Explains basic (quadratic) shape of overlap vs. ad click-through-rate
A simple model Explains basic (quadratic) shape of overlap vs. ad click-through-rate
 Improving Ad Relevance in Sponsored Search Dustin Hillard, Stefan Schroedl, Eren Manavoglu, et al. WSDM’ 10
Improving Ad Relevance in Sponsored Search Dustin Hillard, Stefan Schroedl, Eren Manavoglu, et al. WSDM’ 10
 Ad relevance Ad attractiveness • Relevance – How related is the ad to the search query – q=“cocacola”, ad=“Buy Coke Online” • Attractiveness – Essentially click-through rate – q=“cocacola”, ad=“Coca Cola Company Job” – q=*, ad=“Lose weight fast and easy” Hope: decoupling leads to better (cold-start) CTR predictions
Ad relevance Ad attractiveness • Relevance – How related is the ad to the search query – q=“cocacola”, ad=“Buy Coke Online” • Attractiveness – Essentially click-through rate – q=“cocacola”, ad=“Coca Cola Company Job” – q=*, ad=“Lose weight fast and easy” Hope: decoupling leads to better (cold-start) CTR predictions
 Basic setup • Get relevance from editorial judgments – Perfect, excellent, good, fair, bad – Treat non-bad as relevant • Machine learning approach – Compare query to the ad – Title, description, display URL – Word overlap (uni- and bigram), character overlap (uni - and bigram), cosine similarity, ordered bigram overlap – Query length • Data – 7 k unique queries (stratified sample) – 80 k query-ad judged relevant pairs
Basic setup • Get relevance from editorial judgments – Perfect, excellent, good, fair, bad – Treat non-bad as relevant • Machine learning approach – Compare query to the ad – Title, description, display URL – Word overlap (uni- and bigram), character overlap (uni - and bigram), cosine similarity, ordered bigram overlap – Query length • Data – 7 k unique queries (stratified sample) – 80 k query-ad judged relevant pairs
/(“said ‘yes’”) Recall") Basic results – text only Precision = (“said ‘yes’ and was ‘yes’”)/(“said ‘yes’”) Recall = (“said ‘yes’ and was ‘yes’”)/(“was ‘yes’”) Accuracy = (“said the right thing”)/(“said something”) F 1 -score = 2/(1/P + 1/R) harmonic mean < arithmetic mean What other features?
Basic results – text only Precision = (“said ‘yes’ and was ‘yes’”)/(“said ‘yes’”) Recall = (“said ‘yes’ and was ‘yes’”)/(“was ‘yes’”) Accuracy = (“said the right thing”)/(“said something”) F 1 -score = 2/(1/P + 1/R) harmonic mean < arithmetic mean What other features?
 pair has") Incorporating user clicks • Can use historic CTRs – Assumes (ad, query) pair has been seen • Useless for new ads – Also evaluate in blanked-out setting
Incorporating user clicks • Can use historic CTRs – Assumes (ad, query) pair has been seen • Useless for new ads – Also evaluate in blanked-out setting
 Translation Model In search, translation models are common Here D = ad Good translation = ad click Typical model A query term Maximum likelihood (for historic data) Any problem with this? An ad term
Translation Model In search, translation models are common Here D = ad Good translation = ad click Typical model A query term Maximum likelihood (for historic data) Any problem with this? An ad term
 Digression on MLE • Maximum likelihood estimator – Pick the parameter that‘s most likely to generate the observed data Example: Draw a single number from a hat with numbers {1, …, n}. You observe 7. Maximum likelihood estimator? Underestimates size (c. f. # of species) Underestimates unknown/impossible Unbiased estimator?
Digression on MLE • Maximum likelihood estimator – Pick the parameter that‘s most likely to generate the observed data Example: Draw a single number from a hat with numbers {1, …, n}. You observe 7. Maximum likelihood estimator? Underestimates size (c. f. # of species) Underestimates unknown/impossible Unbiased estimator?
 Remove position bias • Train one model as described before – But with smoothing • Train a second model using expected clicks • Ratio of model for actual and expected clicks • Add these as additional features for the learner
Remove position bias • Train one model as described before – But with smoothing • Train a second model using expected clicks • Ratio of model for actual and expected clicks • Add these as additional features for the learner
 Filtering low quality ads • Use to remove irrelevant ads - Don‘t show ads below relevance threshold Showing fewer ads gave more clicks per search!
Filtering low quality ads • Use to remove irrelevant ads - Don‘t show ads below relevance threshold Showing fewer ads gave more clicks per search!


 Second part of Part 2
Second part of Part 2
 Estimating Advertisability of Tail Queries for Sponsored Search Sandeep Pandey, Kunal Punera, Marcus Fontoura, et al. SIGIR’ 10
Estimating Advertisability of Tail Queries for Sponsored Search Sandeep Pandey, Kunal Punera, Marcus Fontoura, et al. SIGIR’ 10
 Two important questions • Query advertisability – When to show ads at all – How many ads to show • Ad relevance and clickability – Which ads to show where Focus on first problem. Predict: will there be an ad click? Difficult for tail queries!
Two important questions • Query advertisability – When to show ads at all – How many ads to show • Ad relevance and clickability – Which ads to show where Focus on first problem. Predict: will there be an ad click? Difficult for tail queries!
 Word-based Model Query q has words {wi}. Model q‘s click propensity as: Good/bad? Variant w/o bias for long queries: Maximum likelihood attempt to learn these: s(q) = # instances of q with an ad click n(q) = # instances of q without an ad click
Word-based Model Query q has words {wi}. Model q‘s click propensity as: Good/bad? Variant w/o bias for long queries: Maximum likelihood attempt to learn these: s(q) = # instances of q with an ad click n(q) = # instances of q without an ad click
 Word-based Model Then give up …each q only one word
Word-based Model Then give up …each q only one word
 Linear regression model Different model: words contribute linearly Add regularization to avoid overfitting of underdetermined problem Problem?
Linear regression model Different model: words contribute linearly Add regularization to avoid overfitting of underdetermined problem Problem?
 Digression Taken from: http: //www. dtreg. com/svm. htm and http: //www. teco. edu/~albrecht/neuro/html/node 10. html
Digression Taken from: http: //www. dtreg. com/svm. htm and http: //www. teco. edu/~albrecht/neuro/html/node 10. html
 Topical clustering • Latent Dirichlet Allocation – Implicitly uses co-occurrences patterns • Incorporate the topic distributions as features in the regression model
Topical clustering • Latent Dirichlet Allocation – Implicitly uses co-occurrences patterns • Incorporate the topic distributions as features in the regression model
 directly? – “Ground truth” is not") Evaluation • Why not use the observed c(q) directly? – “Ground truth” is not trustworthy – tail queries • Sort things by predicted c(q) – Should have included optimal ordering!
Evaluation • Why not use the observed c(q) directly? – “Ground truth” is not trustworthy – tail queries • Sort things by predicted c(q) – Should have included optimal ordering!
 Learning Website Hierarchies for Keyword Enrichment in Contextual Advertising Pavan Kumar GM, Krishna Leela, Mehul Parsana, Sachin Garg WSDM’ 11
Learning Website Hierarchies for Keyword Enrichment in Contextual Advertising Pavan Kumar GM, Krishna Leela, Mehul Parsana, Sachin Garg WSDM’ 11
 • Keywords extracted for contextual advertising are not always perfect • Many") The problem(s) • Keywords extracted for contextual advertising are not always perfect • Many pages are not indexed – no keywords available. Still have to serve ads • Want a system that for a given URL (indexed or not) outputs good keywords • Key observation: use in-site similarity between pages and content
The problem(s) • Keywords extracted for contextual advertising are not always perfect • Many pages are not indexed – no keywords available. Still have to serve ads • Want a system that for a given URL (indexed or not) outputs good keywords • Key observation: use in-site similarity between pages and content
 Preliminaries • Mapping URLs u to key-value pairs • Represent webpage p as vector of keywords – tf, df, and section where found Goals: 1. Use u to introduce new kw and/or update existing weights 2. For unindexed pages get kw via other pages from same site Latency constraint!
Preliminaries • Mapping URLs u to key-value pairs • Represent webpage p as vector of keywords – tf, df, and section where found Goals: 1. Use u to introduce new kw and/or update existing weights 2. For unindexed pages get kw via other pages from same site Latency constraint!
 What they do • Conceptually: – Train a decision tree with keys K as attribute labels, V as attribute values and pages P as class labels – Too many classes (sparseness, efficiency) • What they do: – Use clusters of web pages as labels
What they do • Conceptually: – Train a decision tree with keys K as attribute labels, V as attribute values and pages P as class labels – Too many classes (sparseness, efficiency) • What they do: – Use clusters of web pages as labels
 Digression: Large scale clustering Syntactic clustering of the Web, Broder et al. , 1997 • How (and why) to detect mirror pages? – “ls man” What would you do? • Want a summarizing “fingerprint”? – Direct hashing won’t work
Digression: Large scale clustering Syntactic clustering of the Web, Broder et al. , 1997 • How (and why) to detect mirror pages? – “ls man” What would you do? • Want a summarizing “fingerprint”? – Direct hashing won’t work
 – “If you are lonely when you") Shingling w-shingles of a document (say, w=4) – “If you are lonely when you are alone, you are in bad company. ” (Sartre) {(if you are lonely), (you are lonely when), (are lonely when you), (lonely when you are), …} Resemblance rw(A, B) = |S(A, w)ÅS(B, w)|/|S(A, w)[S(B, w)| Works well, but how to compute efficiently? !
Shingling w-shingles of a document (say, w=4) – “If you are lonely when you are alone, you are in bad company. ” (Sartre) {(if you are lonely), (you are lonely when), (are lonely when you), (lonely when you are), …} Resemblance rw(A, B) = |S(A, w)ÅS(B, w)|/|S(A, w)[S(B, w)| Works well, but how to compute efficiently? !
 Obtaining a “sketch” • • Fix shingle size w, shingle universe U. Each indvidual shingle is a number (by hashing) Let W be a set of shingles. Define: MINs(W) = The set of s smallest elements in W, if |W|¸s W otherwise Theorem: Let : U!U be a permutation of U chosen uniformly at random. Let M(A) = MINs( (S(A))) and M(B) = MINs( (S(B))). The value |MINs(M(A)[M(B))ÅM(A)ÅM(B)|/|MINs(M(A)[M(B))| is an unbiased estimate of the resemblance of A and B.
Obtaining a “sketch” • • Fix shingle size w, shingle universe U. Each indvidual shingle is a number (by hashing) Let W be a set of shingles. Define: MINs(W) = The set of s smallest elements in W, if |W|¸s W otherwise Theorem: Let : U!U be a permutation of U chosen uniformly at random. Let M(A) = MINs( (S(A))) and M(B) = MINs( (S(B))). The value |MINs(M(A)[M(B))ÅM(A)ÅM(B)|/|MINs(M(A)[M(B))| is an unbiased estimate of the resemblance of A and B.
) has a fixed size (namely s).") Proof Note: Mins(M(A)) has a fixed size (namely s).
Proof Note: Mins(M(A)) has a fixed size (namely s).
 use agglomerative single-linkage clustering with a") Back to where we were • They (essentially) use agglomerative single-linkage clustering with a min similarity stopping threshold Do you know agglomerative clustering? • Splitting criteria – How would you do it?
Back to where we were • They (essentially) use agglomerative single-linkage clustering with a min similarity stopping threshold Do you know agglomerative clustering? • Splitting criteria – How would you do it?
 Not the best criterion? • IG prefers attributes with many values – They claim: high generalization error – They use: Gain Ratio (GR)
Not the best criterion? • IG prefers attributes with many values – They claim: high generalization error – They use: Gain Ratio (GR)
 pages – Class probability = number") Take impressions into account • So far (unweighted) pages – Class probability = number of pages Weight things by impressions. More weight for recent visits:
Take impressions into account • So far (unweighted) pages – Class probability = number of pages Weight things by impressions. More weight for recent visits:
 Stopping criterion • Stop splitting in tree construction when – All children part of the same class – Too few impressions under the node – Statistically not meaningful (Chi-square test) • Now we have a decision tree for URLs (leaves) – What about interior nodes?
Stopping criterion • Stop splitting in tree construction when – All children part of the same class – Too few impressions under the node – Statistically not meaningful (Chi-square test) • Now we have a decision tree for URLs (leaves) – What about interior nodes?
 Obtaining keywords for nodes • Belief propagation – from leaves up …and back down Now we have keywords for nodes. Keywords for matching nodes are used.
Obtaining keywords for nodes • Belief propagation – from leaves up …and back down Now we have keywords for nodes. Keywords for matching nodes are used.
 Evaluation • Two state-of-the-art baselines – Both use the content – JIT uses only first 500 bytes, syntactical – “Semantic” uses topical page hierarchies – All used with cosine similarity to find ads • Relevance evaluation – Human judges evaluated ad relevance
Evaluation • Two state-of-the-art baselines – Both use the content – JIT uses only first 500 bytes, syntactical – “Semantic” uses topical page hierarchies – All used with cosine similarity to find ads • Relevance evaluation – Human judges evaluated ad relevance
 Results n. DCG … slide") (Some) Results n. DCG … slide
(Some) Results n. DCG … slide
 Digression - n. DCG • Normalized Discounted Cumulative Gain • CG: total relevance at positions 1 to p • DCG: the higher the better • n. DCG: take problem difficulty into account
Digression - n. DCG • Normalized Discounted Cumulative Gain • CG: total relevance at positions 1 to p • DCG: the higher the better • n. DCG: take problem difficulty into account
 An Expressive Mechanism for Auctions on the Web Paul Dütting, Monika Henzinger, Ingmar Weber WWW’ 11
An Expressive Mechanism for Auctions on the Web Paul Dütting, Monika Henzinger, Ingmar Weber WWW’ 11
 = vi, j – pj") More general utility functions • Usually – ui, j(pj) = vi, j – pj – Sometimes with (hard) budget bi • We want to allow – ui, j(pj) = vi, j – ci, j¢ pj, i. e. (i, j)-dependent slopes – multiple slopes on different intervals – non-linear utilities altogether
More general utility functions • Usually – ui, j(pj) = vi, j – pj – Sometimes with (hard) budget bi • We want to allow – ui, j(pj) = vi, j – ci, j¢ pj, i. e. (i, j)-dependent slopes – multiple slopes on different intervals – non-linear utilities altogether
-dependent slopes? • Suppose mechanism uses CPC pricing … • … but") Why (i, j)-dependent slopes? • Suppose mechanism uses CPC pricing … • … but a bidder has CPM valuation • Mechanism computes • Guarantees
Why (i, j)-dependent slopes? • Suppose mechanism uses CPC pricing … • … but a bidder has CPM valuation • Mechanism computes • Guarantees
-dependent slopes? • Translating back to impressions …") Why (i, j)-dependent slopes? • Translating back to impressions …
Why (i, j)-dependent slopes? • Translating back to impressions …
 Why different slopes over intervals? • Suppose bidding on a car on ebay – Currently only 1 -at-a-time (or dangerous)! – Utility depends on rates of loan
Why different slopes over intervals? • Suppose bidding on a car on ebay – Currently only 1 -at-a-time (or dangerous)! – Utility depends on rates of loan
 Why non-linear utilities? • Suppose the drop is supra-linear – The higher the price the lower the profit … – … and the higher the uncertainty – Maybe log(Ci, j-pj) – “Risk-averse” bidders • Will use piece-wise linear for approximation – Give approximation guarantees
Why non-linear utilities? • Suppose the drop is supra-linear – The higher the price the lower the profit … – … and the higher the uncertainty – Maybe log(Ci, j-pj) – “Risk-averse” bidders • Will use piece-wise linear for approximation – Give approximation guarantees
 Input definition Set of n bidder I, set of k items J. Items contain a dummy item j 0. Each bidder i has an outside option oi. Each item j has a reserve price rj.
Input definition Set of n bidder I, set of k items J. Items contain a dummy item j 0. Each bidder i has an outside option oi. Each item j has a reserve price rj.
 Problem statement • Compute an outcome • Outcome is feasible if • Outcome is envy free if for all i and (i, j) 2 Ix. J • Bidder optimal if for all other envy free and for all bidders i (strong!)
Problem statement • Compute an outcome • Outcome is feasible if • Outcome is envy free if for all i and (i, j) 2 Ix. J • Bidder optimal if for all other envy free and for all bidders i (strong!)
 Bidder optimality vs. truthfulness Two bidders i 2{1, 2} and two items j 2{1, 2}. rj = 0 for j 2{1, 2}, and oi = 0 for i 2{1, 2} What‘s a bidder optimal outcome? What if bidder 1 underreports u 1, 1(¢)? Note: “degenerate” input! Theorem: General position => Truthfulness. [See paper for definition of “general position”. ]
Bidder optimality vs. truthfulness Two bidders i 2{1, 2} and two items j 2{1, 2}. rj = 0 for j 2{1, 2}, and oi = 0 for i 2{1, 2} What‘s a bidder optimal outcome? What if bidder 1 underreports u 1, 1(¢)? Note: “degenerate” input! Theorem: General position => Truthfulness. [See paper for definition of “general position”. ]
 Main Results Definition:
Main Results Definition:
 Overdemand-preserving directions • Basic idea – Algorithm iteratively increases the prices – Price increases required to solve overdemand • Tricky bits – preserve overdemand (will explain) – show necessity (for bidder optimality) – accounting for unmatching (for running time)
Overdemand-preserving directions • Basic idea – Algorithm iteratively increases the prices – Price increases required to solve overdemand • Tricky bits – preserve overdemand (will explain) – show necessity (for bidder optimality) – accounting for unmatching (for running time)
 Overdemand-preserving directions The simple case 1 10 -p 1 5 -p 3 Bidders 2 8 -p 1 7 -p 2 12 -p 1 11 -p 2 3 2 -p 3 5 p 1=1 9 -p 2 3 -p 3 Explain: First choice graph 1 2 p 2=0 4 Items Explain: Increase required 3 p 3=0 Explain: Path augmentation
Overdemand-preserving directions The simple case 1 10 -p 1 5 -p 3 Bidders 2 8 -p 1 7 -p 2 12 -p 1 11 -p 2 3 2 -p 3 5 p 1=1 9 -p 2 3 -p 3 Explain: First choice graph 1 2 p 2=0 4 Items Explain: Increase required 3 p 3=0 Explain: Path augmentation
 Overdemand-preserving directions The not-so-simple case 1 11 -2 p 1 5 -p 3 Bidders 2 1 p 1=1 9 -p 2 8 -4 p 1 4 -3 p 2 2 p 2=0 3 -p 3 Explain: ci, j matter! 12 -3 p 1 9 -7 p 2 3 2 -p 3 3 p 3=0 Items
Overdemand-preserving directions The not-so-simple case 1 11 -2 p 1 5 -p 3 Bidders 2 1 p 1=1 9 -p 2 8 -4 p 1 4 -3 p 2 2 p 2=0 3 -p 3 Explain: ci, j matter! 12 -3 p 1 9 -7 p 2 3 2 -p 3 3 p 3=0 Items
: – minimize – or equivalently") Finding ov. d-preserv. directions • Key observation (not ours!): – minimize – or equivalently • No longer preserves full first choice graph – But alternating tree • Still allows path augmention
Finding ov. d-preserv. directions • Key observation (not ours!): – minimize – or equivalently • No longer preserves full first choice graph – But alternating tree • Still allows path augmention
 The actual mechanism
The actual mechanism
 Effects of Word-of-Mouth Versus Traditional Marketing: Findings from an Internet Social Networking Site Michael Trusov, Randolph Bucklin, Koen Pauwels Journal of Marketing, 2009
Effects of Word-of-Mouth Versus Traditional Marketing: Findings from an Internet Social Networking Site Michael Trusov, Randolph Bucklin, Koen Pauwels Journal of Marketing, 2009
 The growth of a social network • Driving factors – Paid event marketing (101 events in 36 wks) – Media attention (236 in 36 wks) – Word-of-Mouth (WOM) • Can observe – Organized marketing events – Mentions in the media – WOM referrals (through email invites) – Number of new sign-ups
The growth of a social network • Driving factors – Paid event marketing (101 events in 36 wks) – Media attention (236 in 36 wks) – Word-of-Mouth (WOM) • Can observe – Organized marketing events – Mentions in the media – WOM referrals (through email invites) – Number of new sign-ups
 What could cause what? • • Media coverage => new sign-ups? New sign-ups => media coverage? WOM referrals => new sign-ups? ….
What could cause what? • • Media coverage => new sign-ups? New sign-ups => media coverage? WOM referrals => new sign-ups? ….
 Time series modeling intercept sign-ups WOM referrals Media appearances Promo events Up to 20 days Lots of parameters linear trend holidays day of week
Time series modeling intercept sign-ups WOM referrals Media appearances Promo events Up to 20 days Lots of parameters linear trend holidays day of week
 Time series modeling Overfitting?
Time series modeling Overfitting?
 Granger Causality • Correlation causality – Regions with more storks have more babies – Families with more TVs live longer • Granger causality attempts more – Works for time series – Y and (possible) cause X – First, explain (= linear regression) Y by lagged Y – Explain the rest using lagged X – Significant improvement in fit?
Granger Causality • Correlation causality – Regions with more storks have more babies – Families with more TVs live longer • Granger causality attempts more – Works for time series – Y and (possible) cause X – First, explain (= linear regression) Y by lagged Y – Explain the rest using lagged X – Significant improvement in fit?
 What causes what?
What causes what?
 Response of Sign-Ups to Shock • IRF: impulse response function New to me …
Response of Sign-Ups to Shock • IRF: impulse response function New to me …
 Digression: Bass diffusion New “sales” at time t: Ultimate market potential m is given.
Digression: Bass diffusion New “sales” at time t: Ultimate market potential m is given.
 • 61 test (= out-of-sample)") Model comparison • 197 train (= in-sample) • 61 test (= out-of-sample)
Model comparison • 197 train (= in-sample) • 61 test (= out-of-sample)
 Impressions") Monetary Value of WOM • • • CPM about $. 40 (per ad) Impressions visitor/month about 130 Say 2. 5 ads per impression $. 13 per month per user, or about $1. 50/yr IRF: 10 WOM = 5 new sign-ups over 3 wk 1 WOM worth approx $. 75/yr
Monetary Value of WOM • • • CPM about $. 40 (per ad) Impressions visitor/month about 130 Say 2. 5 ads per impression $. 13 per month per user, or about $1. 50/yr IRF: 10 WOM = 5 new sign-ups over 3 wk 1 WOM worth approx $. 75/yr