

660b5e3a05f3ae84294cb5c643cd29f6.ppt
- Количество слайдов: 70
 Parametric versus Non-parametric Genetic Association Analysis Kristel Van Steen, Ph. D, Sc. D (kristel. vansteen@ugent. be) Université de Liege - Institut Montefiore Ghent University – Step. Gen cvba December 18 th , 2007
Parametric versus Non-parametric Genetic Association Analysis Kristel Van Steen, Ph. D, Sc. D (kristel. vansteen@ugent. be) Université de Liege - Institut Montefiore Ghent University – Step. Gen cvba December 18 th , 2007
 Genetic Association Studies n Aim: detect association between one or more genetic polymorphisms and a trait, which may be n n n measured, dichotomous, time to onset. (Genuine) Genetic associations arise only because human populations share common ancestry
Genetic Association Studies n Aim: detect association between one or more genetic polymorphisms and a trait, which may be n n n measured, dichotomous, time to onset. (Genuine) Genetic associations arise only because human populations share common ancestry
") Terminology (Roche Genetics)
Terminology (Roche Genetics)
") Terminology (Roche Genetics)
Terminology (Roche Genetics)
") Terminology (Courtesy of Ed Silverman)
Terminology (Courtesy of Ed Silverman)
 Genetic Association Studies Reflection I: n In linkage analysis, data from distantly related individuals are more powerful for detecting small effects Increased possibility for linkage to be destroyed by recombination linkage extends over smaller distances denser maps required
Genetic Association Studies Reflection I: n In linkage analysis, data from distantly related individuals are more powerful for detecting small effects Increased possibility for linkage to be destroyed by recombination linkage extends over smaller distances denser maps required
") Linkage Disequilibrium (Roche Genetics)
Linkage Disequilibrium (Roche Genetics)
 Linkage Disequilibrium Marker locus Disease locus 1 D p =p p D 1 2 p. D pd d p 1 p 2
Linkage Disequilibrium Marker locus Disease locus 1 D p =p p D 1 2 p. D pd d p 1 p 2
 Genetic Association Studies Reflection II: n n Association study is special form of linkage study: the extended family is the wider population Association studies have greater power than linkage studies to detect small effects, but require looking at more places (Risch and Merikangas 1996)
Genetic Association Studies Reflection II: n n Association study is special form of linkage study: the extended family is the wider population Association studies have greater power than linkage studies to detect small effects, but require looking at more places (Risch and Merikangas 1996)
 Genetic Association Studies Reflections III: n n Genetic susceptibility to common complex disorders involves many genes, most of which have small effects A large number of “markers” have been identified
Genetic Association Studies Reflections III: n n Genetic susceptibility to common complex disorders involves many genes, most of which have small effects A large number of “markers” have been identified
") Complex Disorders (Roche Genetics)
Complex Disorders (Roche Genetics)
") Markers (Roche Genetics)
Markers (Roche Genetics)
 Genetic Association Disease Phenotype Test for association between phenotype and marker locus LD / correlation Marker DSL: disease susceptibility locus Test for genetic association between the phenotype and the DSL
Genetic Association Disease Phenotype Test for association between phenotype and marker locus LD / correlation Marker DSL: disease susceptibility locus Test for genetic association between the phenotype and the DSL
 Indirect Associations n The polymorphism is a surrogate for the causal locus: n n n Indirect associations are weaker than the direct associations they reflect Essential to type several surrounding markers Try to exclude the possibility that a causal variant exists but is not picked up by the marker set: Genome-wide vs Candidate gene approach
Indirect Associations n The polymorphism is a surrogate for the causal locus: n n n Indirect associations are weaker than the direct associations they reflect Essential to type several surrounding markers Try to exclude the possibility that a causal variant exists but is not picked up by the marker set: Genome-wide vs Candidate gene approach
 Statistical Requirements for a Successful Genome-wide Association Study § LD coverage § Genotyping quality § Sufficient sample sizes § Design of genome-wide association studies § Handling of the multiple testing problem
Statistical Requirements for a Successful Genome-wide Association Study § LD coverage § Genotyping quality § Sufficient sample sizes § Design of genome-wide association studies § Handling of the multiple testing problem
") Study Designs (Cordell and Clayton, 2005)
Study Designs (Cordell and Clayton, 2005)
 Example for Required Sample Sizes Required sample sizes to achieve 80% power in a case/control study for a significance level of 10 -7 Allele freq Odds ratio 1. 25 1. 5 0. 1 0. 2 0. 3 0. 4 8, 859 5, 283 4, 281 3, 886 1. 75 2, 608 1, 616 1, 342 1, 301 1, 350 869 727 750
Example for Required Sample Sizes Required sample sizes to achieve 80% power in a case/control study for a significance level of 10 -7 Allele freq Odds ratio 1. 25 1. 5 0. 1 0. 2 0. 3 0. 4 8, 859 5, 283 4, 281 3, 886 1. 75 2, 608 1, 616 1, 342 1, 301 1, 350 869 727 750
 The interpretation of r^2 r 2 N is the “effective sample size” If a marker M and causal gene G are in LD, then a study with N cases and controls which measures M (but not G) will have the same power to detect an association as a study with r 2 N cases and controls that directly measured G So … The markers that are genotyped should be selected so that they have high r^2 -values (preferable at least 80%) with the marker that are not genotyped A good SNPs selection will be key for the success of GWAs
The interpretation of r^2 r 2 N is the “effective sample size” If a marker M and causal gene G are in LD, then a study with N cases and controls which measures M (but not G) will have the same power to detect an association as a study with r 2 N cases and controls that directly measured G So … The markers that are genotyped should be selected so that they have high r^2 -values (preferable at least 80%) with the marker that are not genotyped A good SNPs selection will be key for the success of GWAs
 Power – a Statistical Concept
Power – a Statistical Concept
;") Online Calculators n n n n General Statistical Calculators Including a Power Calculator (UCLA); Statistical Power Calculator for Frequencies; Retrospective Power Calculation; Genetic Power Calculator; Wise Project Applets: Power Applet; Downloadable calculators: Ca. TS (Skol, 2006), Quanto (sample size or power calculation for association studies of genes, geneenvironment or gene-gene interactions); Calculation of Power for Genetic Association Studies 'Assoc. Pow' (Ambrosius, 2004), PS: Power and Sample Size Calculation; Power & Sample Size Calculations on STATA. (http: //www. dorak. info/epi/glosge. html)
Online Calculators n n n n General Statistical Calculators Including a Power Calculator (UCLA); Statistical Power Calculator for Frequencies; Retrospective Power Calculation; Genetic Power Calculator; Wise Project Applets: Power Applet; Downloadable calculators: Ca. TS (Skol, 2006), Quanto (sample size or power calculation for association studies of genes, geneenvironment or gene-gene interactions); Calculation of Power for Genetic Association Studies 'Assoc. Pow' (Ambrosius, 2004), PS: Power and Sample Size Calculation; Power & Sample Size Calculations on STATA. (http: //www. dorak. info/epi/glosge. html)
 Type I and Type II errors
Type I and Type II errors
") Statistical Analysis depends on Study Design. . . (Cordell and Clayton, 2005)
Statistical Analysis depends on Study Design. . . (Cordell and Clayton, 2005)
 Statistical analysis depends on …
Statistical analysis depends on …
 Assessing Association n Direct association: patterns of genotype-phenotype relationship n From dose-response models to models accounting for epistatic effects n Indirect association: patterns of linkage-disequilibrium n r 2 relates to the power to detect association: ss 0. 56/0. 2 (2. 8) times as large to detect indirect association with A than indirect association with C n Haplotype blocks / haplotype tagging SNPs A 1 0. 2 1 B 0. 5 6 1 C A B C r squared measures of LD; Locus B is assumed to be causal
Assessing Association n Direct association: patterns of genotype-phenotype relationship n From dose-response models to models accounting for epistatic effects n Indirect association: patterns of linkage-disequilibrium n r 2 relates to the power to detect association: ss 0. 56/0. 2 (2. 8) times as large to detect indirect association with A than indirect association with C n Haplotype blocks / haplotype tagging SNPs A 1 0. 2 1 B 0. 5 6 1 C A B C r squared measures of LD; Locus B is assumed to be causal
,") Human Genetic Disorders n Single gene disorder n n Less than 0. 05% (rare), e. g. , Huntington disease, cystic fibrosis Disorders with polygenic or multifactorial inheritance n n 1% or more (common); e. g. , diabetes, obesity Do not show Mendelian modes of transmission Genetically relevant phenotype often unclear Under the influence of multiple interacting genes
Human Genetic Disorders n Single gene disorder n n Less than 0. 05% (rare), e. g. , Huntington disease, cystic fibrosis Disorders with polygenic or multifactorial inheritance n n 1% or more (common); e. g. , diabetes, obesity Do not show Mendelian modes of transmission Genetically relevant phenotype often unclear Under the influence of multiple interacting genes
 Mendelian Traits affected Aa BB Aa bb AA bb affected Locus 2 BB Bb bb Aa Bb AA AABB AABb AAbb Locus 1 Aa Aa. BB Aa. Bb Aabb aa aa. BB aa. Bb aabb affected
Mendelian Traits affected Aa BB Aa bb AA bb affected Locus 2 BB Bb bb Aa Bb AA AABB AABb AAbb Locus 1 Aa Aa. BB Aa. Bb Aabb aa aa. BB aa. Bb aabb affected
 Complex Traits Aa BB affected Aa Bb AA bb Aa Bb Locus 2 BB Bb bb AA AABB AABb AAbb Locus 1 Aa Aa. BB Aa. Bb Aabb aa. BB aa. Bb aabb aa affected
Complex Traits Aa BB affected Aa Bb AA bb Aa Bb Locus 2 BB Bb bb AA AABB AABb AAbb Locus 1 Aa Aa. BB Aa. Bb Aabb aa. BB aa. Bb aabb aa affected
 Genetic Etiology I Independent effect Gene 1 Gene 2 Gene 3 Disease Gene 4 Gene 5 Any one bad gene results in the disease. Genes have no effect on each other. Genetic Heterogeneity
Genetic Etiology I Independent effect Gene 1 Gene 2 Gene 3 Disease Gene 4 Gene 5 Any one bad gene results in the disease. Genes have no effect on each other. Genetic Heterogeneity
 Genetic Etiology II Interactive effect Gene 1 Gene 2 Gene 3 Disease E. g. Any bad gene results in disease. Genes have an effect on other genes in the pathway. Epistasis
Genetic Etiology II Interactive effect Gene 1 Gene 2 Gene 3 Disease E. g. Any bad gene results in disease. Genes have an effect on other genes in the pathway. Epistasis
 Genetic Etiology III Incomplete penetrance Gene 1 Disease Gene 1 No Disease Some individuals with genotype do not manifest trait.
Genetic Etiology III Incomplete penetrance Gene 1 Disease Gene 1 No Disease Some individuals with genotype do not manifest trait.
 Genetic Etiology IV Phenocopy Assuming a dominant model, and disease allele A, normal allele a. AA Disease Aa Disease AA Disease aa Disease Maybe caused by environmental factors
Genetic Etiology IV Phenocopy Assuming a dominant model, and disease allele A, normal allele a. AA Disease Aa Disease AA Disease aa Disease Maybe caused by environmental factors
 And now we should be able to start modeling, testing, estimating, …
And now we should be able to start modeling, testing, estimating, …
 Association Analysis n Case-control studies n n Test for association between marker alleles and the disease phenotype in a group of affected and unaffected individuals randomly from the population Family-based studies n Test for association between marker alleles and the disease phenotype in a group of affected individuals and unaffected family members
Association Analysis n Case-control studies n n Test for association between marker alleles and the disease phenotype in a group of affected and unaffected individuals randomly from the population Family-based studies n Test for association between marker alleles and the disease phenotype in a group of affected individuals and unaffected family members
 Case-control data structure Status SNP 1 SNP 2 SNP 3 SNP 4 SNP 5 SNP 6 SNP 7 SNP 8 SNP 9 SNP 10 1 1 2 2 1 2 1 0 0 0 0 1 0 2 0 1 1 1 2 0 1 1 0 1 2 1 1 0 0 0 0 1 1 1 0 1 2 1 1 0 1 0 2 1 0 0 0 2 0 1 0 1 0 2 1 0 1 0 0 0 1 1 0 2 1 0 0 0 2 0 1 0 2 1 0 1 1 0 0 0 2 0 0 0 1 2 1 0 0 1 2 0 0 1 1 1 2 0 1 1 0 0 2 0 0 1 2 0 0
Case-control data structure Status SNP 1 SNP 2 SNP 3 SNP 4 SNP 5 SNP 6 SNP 7 SNP 8 SNP 9 SNP 10 1 1 2 2 1 2 1 0 0 0 0 1 0 2 0 1 1 1 2 0 1 1 0 1 2 1 1 0 0 0 0 1 1 1 0 1 2 1 1 0 1 0 2 1 0 0 0 2 0 1 0 1 0 2 1 0 1 0 0 0 1 1 0 2 1 0 0 0 2 0 1 0 2 1 0 1 1 0 0 0 2 0 0 0 1 2 1 0 0 1 2 0 0 1 1 1 2 0 1 1 0 0 2 0 0 1 2 0 0
 Standard Method: Genotype Case-Control # copies of ‘ 0’ allele 0 1 2 Total Case r 0 r 1 r 2 R Control s 0 s 1 s 2 S Total n 0 n 1 n 2 N The Bonferroni correction for multiple comparisons 0. 05/(# SNPs tested) (Gibson and Muse, 2002)
Standard Method: Genotype Case-Control # copies of ‘ 0’ allele 0 1 2 Total Case r 0 r 1 r 2 R Control s 0 s 1 s 2 S Total n 0 n 1 n 2 N The Bonferroni correction for multiple comparisons 0. 05/(# SNPs tested) (Gibson and Muse, 2002)
 A Pure Epistatic Inheritance Model AA Aa aa Marginal BB 0 0 0. 2 Bb 0 0. 2 bb 0. 2 0 0 0. 2 Marginal 0. 2 p = 0. 5 q = 0. 5 Comparison of allele or genotype frequencies between cases and controls will not show anything unusual. Virtually no power!
A Pure Epistatic Inheritance Model AA Aa aa Marginal BB 0 0 0. 2 Bb 0 0. 2 bb 0. 2 0 0 0. 2 Marginal 0. 2 p = 0. 5 q = 0. 5 Comparison of allele or genotype frequencies between cases and controls will not show anything unusual. Virtually no power!
 Traditional Method suffers n A large number of SNPs are genotyped n n “multiple comparisons” problem, very small p-values required for significance. Genetic loci may interact (epistasis) in their influence on the phenotype n n loci with small marginal effects may go undetected interested in the interaction itself
Traditional Method suffers n A large number of SNPs are genotyped n n “multiple comparisons” problem, very small p-values required for significance. Genetic loci may interact (epistasis) in their influence on the phenotype n n loci with small marginal effects may go undetected interested in the interaction itself
 Curse of Dimensionality CC SNP 1 AA Aa aa Dd dd SNP 2 SNP 4 DD SNP 2 50 Cases, 50 Controls BB Bb bb SNP 2 N = 100 BB Bb bb SNP 3 Cc SNP 1 AA Aa aa cc SNP 1 AA Aa aa
Curse of Dimensionality CC SNP 1 AA Aa aa Dd dd SNP 2 SNP 4 DD SNP 2 50 Cases, 50 Controls BB Bb bb SNP 2 N = 100 BB Bb bb SNP 3 Cc SNP 1 AA Aa aa cc SNP 1 AA Aa aa
 Adaptive control processes: A guided tour. Princeton") Curse of Dimensionality n Bellman R (1961) Adaptive control processes: A guided tour. Princeton University Press: “. . . Multidimensional variational problems cannot be solved routinely. . This does not mean that we cannot attack them. It merely means that we must employ some more sophisticated techniques. ”
Curse of Dimensionality n Bellman R (1961) Adaptive control processes: A guided tour. Princeton University Press: “. . . Multidimensional variational problems cannot be solved routinely. . This does not mean that we cannot attack them. It merely means that we must employ some more sophisticated techniques. ”
 Traditional Methods suffer Alternatives n Tree-based methods: n n n Pattern recognition methods: n n n Recursive Partitioning (Helix Tree) Random Forests (R, CART) Symbolic Discriminant Analysis (SDA) Mining association rules Neural networks (NN) Support vector machines (SVM) Data reduction methods: n n n DICE (Detection of Informative Combined Effects) MDR (Multifactor Dimensionality Reduction) Logic regression … (e. g. , Onkamo and Toivonen 2006)
Traditional Methods suffer Alternatives n Tree-based methods: n n n Pattern recognition methods: n n n Recursive Partitioning (Helix Tree) Random Forests (R, CART) Symbolic Discriminant Analysis (SDA) Mining association rules Neural networks (NN) Support vector machines (SVM) Data reduction methods: n n n DICE (Detection of Informative Combined Effects) MDR (Multifactor Dimensionality Reduction) Logic regression … (e. g. , Onkamo and Toivonen 2006)
 Independence test x 2") Goodness of fit x 2 1 independent variable Qualitative (categorical) Independence test x 2 2 independent variables Mc. Nemar test Degree of relationship Continuous measurement Type of data Ranks Multiple predictors Quantitative (measurement) Regression Primary interest 1 predictor Relationships Pearson r Form of relationship 2 dependent variables Spearman rs Multiple regression 2 -sample t independent Hypothesis Testing Mann-Whitney U 2 groups dependent Related sample t Wilcoxon T Differences 1 IV independent Multiple IVs Multiple groups Parametric Nonparametric dependent Repeated measures ANOVA Friedman One-way ANOVA Kruskal-Wallis H Factorial ANOVA
Goodness of fit x 2 1 independent variable Qualitative (categorical) Independence test x 2 2 independent variables Mc. Nemar test Degree of relationship Continuous measurement Type of data Ranks Multiple predictors Quantitative (measurement) Regression Primary interest 1 predictor Relationships Pearson r Form of relationship 2 dependent variables Spearman rs Multiple regression 2 -sample t independent Hypothesis Testing Mann-Whitney U 2 groups dependent Related sample t Wilcoxon T Differences 1 IV independent Multiple IVs Multiple groups Parametric Nonparametric dependent Repeated measures ANOVA Friedman One-way ANOVA Kruskal-Wallis H Factorial ANOVA
 logic regression n n") Multi-locus Methods n Parametric methods: Regression n Logistic or (Bagged) logic regression n n Non-parametric methods: n Combinatorial Partitioning Method (CPM) n n Multifactor-Dimensionality Reduction (MDR) n n quantitative phenotypes; interactions qualitative phenotypes; interactions Machine learning and data mining
Multi-locus Methods n Parametric methods: Regression n Logistic or (Bagged) logic regression n n Non-parametric methods: n Combinatorial Partitioning Method (CPM) n n Multifactor-Dimensionality Reduction (MDR) n n quantitative phenotypes; interactions qualitative phenotypes; interactions Machine learning and data mining
 Limitation of Regression n n Having too many independent variables in relation to the number of observed outcome events Main 2 -locus 3 -locus 4 -locus Assuming 10 effect interaction bi-allelic loci: # of Parameters # of 20 Parameters = 180 960 3360
Limitation of Regression n n Having too many independent variables in relation to the number of observed outcome events Main 2 -locus 3 -locus 4 -locus Assuming 10 effect interaction bi-allelic loci: # of Parameters # of 20 Parameters = 180 960 3360
 Limitation of Regression n Fewer than 10 outcome events per independent variable can lead to biased estimates of the regression coefficients and to an increase in Type 1 and Type 2 errors. # of parameters P min(ncase , ncontrol)/10 - 1 n For 200 cases and 200 controls, this formula suggests that no more than 19 (= 200/10 – 1) parameters should be estimated in logistic regression model.
Limitation of Regression n Fewer than 10 outcome events per independent variable can lead to biased estimates of the regression coefficients and to an increase in Type 1 and Type 2 errors. # of parameters P min(ncase , ncontrol)/10 - 1 n For 200 cases and 200 controls, this formula suggests that no more than 19 (= 200/10 – 1) parameters should be estimated in logistic regression model.
 MDR n n n An extension of CPM, which finds the genotype partitions within which a (quantitative) trait variability is much lower than between partitions MDR reduces the dimensionality of multi-locus information to one-dimension, thereby improving the identification of polymorphism combinations associated with disease risk The one-dimensional multi-locus genotype variable is evaluated for its ability to classify and predict disease status through cross-validation and permutation testing
MDR n n n An extension of CPM, which finds the genotype partitions within which a (quantitative) trait variability is much lower than between partitions MDR reduces the dimensionality of multi-locus information to one-dimension, thereby improving the identification of polymorphism combinations associated with disease risk The one-dimensional multi-locus genotype variable is evaluated for its ability to classify and predict disease status through cross-validation and permutation testing
 Two Measures for Selection of Best n-locus model n Misclassification error: The proportion of incorrect classification in the training set. n Prediction error (PE): The proportion of incorrect prediction in the test set.
Two Measures for Selection of Best n-locus model n Misclassification error: The proportion of incorrect classification in the training set. n Prediction error (PE): The proportion of incorrect prediction in the test set.
 10 cross-validation 10 best models. The model with minimum PE is the best n-locus model. MDR Steps 9/10 training data All combinations of 2 factors = 10*9/2 = 45 1/10 test data 10 runs A single model with minimum classification error is the best Model
10 cross-validation 10 best models. The model with minimum PE is the best n-locus model. MDR Steps 9/10 training data All combinations of 2 factors = 10*9/2 = 45 1/10 test data 10 runs A single model with minimum classification error is the best Model
 Best Multi-factor Models Best 2 -factor model Best 3 -factor model Best 4 -factor model Best 5 -factor model Best 6 -factor model. . Best n-factor model
Best Multi-factor Models Best 2 -factor model Best 3 -factor model Best 4 -factor model Best 5 -factor model Best 6 -factor model. . Best n-factor model
 Model Selection and Evaluation n Among the best n-factor models, the best model is: n n n The model with the minimum average PE. The model with the maximum average CVC. Rule of parsimony: If there is a tie, select the smaller model.
Model Selection and Evaluation n Among the best n-factor models, the best model is: n n n The model with the minimum average PE. The model with the maximum average CVC. Rule of parsimony: If there is a tie, select the smaller model.
") MDR Analysis Window (MDR_Overview. pdf)
MDR Analysis Window (MDR_Overview. pdf)
 Significance of the Final Model n Via permutation tests: n n n Randomize the case and control labels in the original dataset multiple times to create a set of permuted datasets. Run MDR on each permuted dataset. Maximum CVC and minimum PE identified for each dataset saved and used to create an empirical distribution for estimation of a P-value.
Significance of the Final Model n Via permutation tests: n n n Randomize the case and control labels in the original dataset multiple times to create a set of permuted datasets. Run MDR on each permuted dataset. Maximum CVC and minimum PE identified for each dataset saved and used to create an empirical distribution for estimation of a P-value.
 n n Average cross-validation") Measures in Selection of Final model n Cross-validation consistency (CVC) n n Average cross-validation consistency n n Average of CVC across all runs. Average misclassification error n n In every run, # of times the same MDR model is identified in m cross-validation. 1 CVC m. Average across all cross-validations and all runs. Average prediction error n Average prediction error across all cross-validations and all runs.
Measures in Selection of Final model n Cross-validation consistency (CVC) n n Average cross-validation consistency n n Average of CVC across all runs. Average misclassification error n n In every run, # of times the same MDR model is identified in m cross-validation. 1 CVC m. Average across all cross-validations and all runs. Average prediction error n Average prediction error across all cross-validations and all runs.
 Simulation I 200 cases and 200 controls; 10 SNPs: 1, 2, 3 , …, 10. Disease etiology due to interaction between SNP 1 and SNP 6. Over 10 CVs and 10 runs
Simulation I 200 cases and 200 controls; 10 SNPs: 1, 2, 3 , …, 10. Disease etiology due to interaction between SNP 1 and SNP 6. Over 10 CVs and 10 runs
 Simulation II 50 replicates of 200 cases and 200 controls; 10 SNPs: 1, 2, 3 , …, 10. Disease risk is dependent on whether two deleterious alleles and two normal alleles are present, from either one locus or both loci. 2 -locus epistatis model; 3 -locus epistatis model; 4 -locus epistatis model; 5 -locus epistatis model.
Simulation II 50 replicates of 200 cases and 200 controls; 10 SNPs: 1, 2, 3 , …, 10. Disease risk is dependent on whether two deleterious alleles and two normal alleles are present, from either one locus or both loci. 2 -locus epistatis model; 3 -locus epistatis model; 4 -locus epistatis model; 5 -locus epistatis model.
 Mean and standard error of the mean calculated from Power 50 replicates. 78% 82% 94% 90% (Ritchie et al, 2001)
Mean and standard error of the mean calculated from Power 50 replicates. 78% 82% 94% 90% (Ritchie et al, 2001)
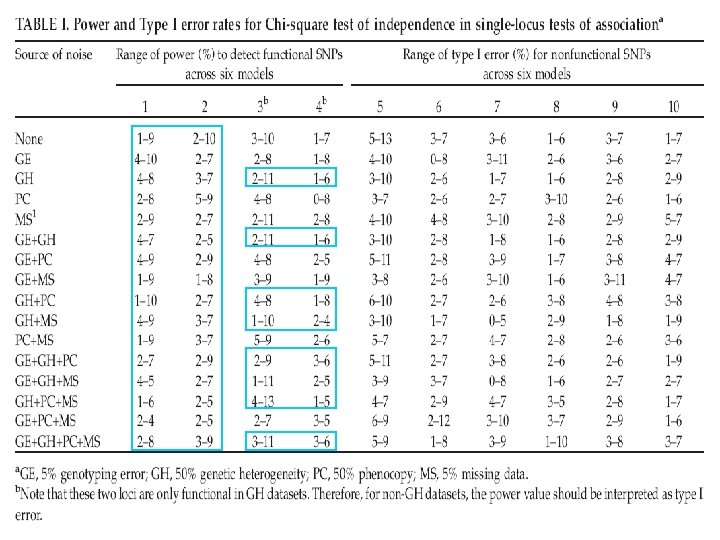
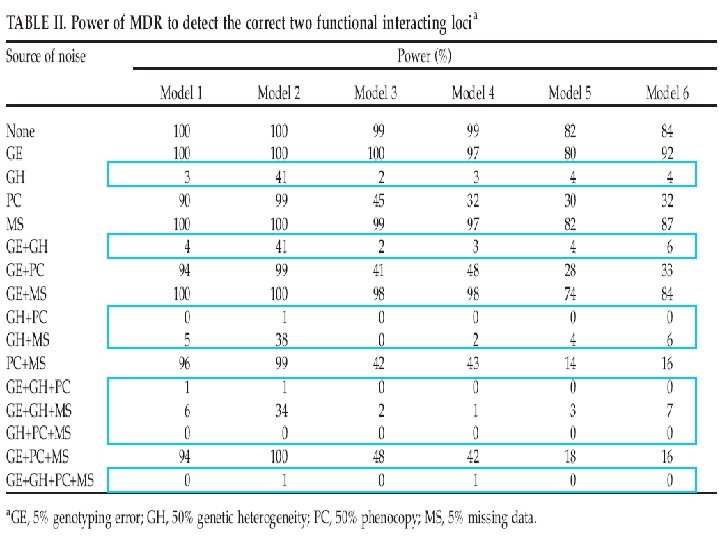
 Power of MDR in Presence of Genotyping Error, Missing Data, Phenocopy, and Genetic Heterogeneity no noise 5% genotyping error -- GE 5% missing data -- MS 50% phenocopy -- PC 50% genetic heterogeneity – GH GE + MS … … GE+MS+PC … … 6 models 4 models GE+MS+PC+GH Total 16 models
Power of MDR in Presence of Genotyping Error, Missing Data, Phenocopy, and Genetic Heterogeneity no noise 5% genotyping error -- GE 5% missing data -- MS 50% phenocopy -- PC 50% genetic heterogeneity – GH GE + MS … … GE+MS+PC … … 6 models 4 models GE+MS+PC+GH Total 16 models
 Advantages of MDR n n Simultaneous detection of multiple genetic loci associated with a discrete clinical endpoint in absence of main effect. Non-parametric: Overcomes “curse of dimensionality” from which logistic regression models suffer. n No particular genetic model n Low false positive rates
Advantages of MDR n n Simultaneous detection of multiple genetic loci associated with a discrete clinical endpoint in absence of main effect. Non-parametric: Overcomes “curse of dimensionality” from which logistic regression models suffer. n No particular genetic model n Low false positive rates
 Disadvantages of MDR n n n Computationally very intensive. Only feasible for relatively small number of factors. Impractical to test very high-dimensional models. When the dimensionality of the best model is relatively high and the sample is relatively small, many observations in the test set can not be predicted. This impacts the SEM of prediction error. Low power in the presence of heterogeneity
Disadvantages of MDR n n n Computationally very intensive. Only feasible for relatively small number of factors. Impractical to test very high-dimensional models. When the dimensionality of the best model is relatively high and the sample is relatively small, many observations in the test set can not be predicted. This impacts the SEM of prediction error. Low power in the presence of heterogeneity
 Issues to Consider n I: Variable selection n II: Model selection n III: Interpretation
Issues to Consider n I: Variable selection n II: Model selection n III: Interpretation
 I: Variable Selection n How can you determine which variables to select? Not computationally feasible to evaluate all possible combinations Need to select correct variables to detect interactions
I: Variable Selection n How can you determine which variables to select? Not computationally feasible to evaluate all possible combinations Need to select correct variables to detect interactions
 How many combinations are there? ~500, 000 SNPs span 80% of common variation in genome (Hap. Map) Number of Possible Combinations 2 x 1026 3 x 1021 5 x 105 1 x 1011 2 x 1016 SNPs in each subset
How many combinations are there? ~500, 000 SNPs span 80% of common variation in genome (Hap. Map) Number of Possible Combinations 2 x 1026 3 x 1021 5 x 105 1 x 1011 2 x 1016 SNPs in each subset
 II: Model Selection n n For each variable subset, evaluate a statistical model Goal is to identify the best subset of variables that compose the best model
II: Model Selection n n For each variable subset, evaluate a statistical model Goal is to identify the best subset of variables that compose the best model
 III: Interpretation n n Selection of best statistical model in a vast search space of possible models Statistical or computational model may not translate into biology n n May not be able to identify prevention or treatment strategies directly Wet lab experiments will be necessary, but may not be sufficient
III: Interpretation n n Selection of best statistical model in a vast search space of possible models Statistical or computational model may not translate into biology n n May not be able to identify prevention or treatment strategies directly Wet lab experiments will be necessary, but may not be sufficient
 Interpretation n Strategies to assess biological interpretation of gene-gene interaction models n n n Consider current knowledge about the biochemistry of the system and the biological plausibility of the models Perform experiments in the wet lab to measure the effect of small perturbations to the system Computer simulation algorithms to model biochemical systems
Interpretation n Strategies to assess biological interpretation of gene-gene interaction models n n n Consider current knowledge about the biochemistry of the system and the biological plausibility of the models Perform experiments in the wet lab to measure the effect of small perturbations to the system Computer simulation algorithms to model biochemical systems
 MDR: To keep in Mind n Candidate SNP selection: n n Selection of the best n-factor model: n n The selection of final model is highly dependent on the selection of n factors at the beginning. Keeping one best n-factor model from all combinations is actually a greedy search algorithm, which might lead to local maximum; yet nice power results and practice has proven its usefulness. Performance when heterogeneity is present in the data: n Phenotypic (diff clinical expressions), genetic (diff inheritance patterns), locus (diff genes), allelic (diff alleles in same gene)
MDR: To keep in Mind n Candidate SNP selection: n n Selection of the best n-factor model: n n The selection of final model is highly dependent on the selection of n factors at the beginning. Keeping one best n-factor model from all combinations is actually a greedy search algorithm, which might lead to local maximum; yet nice power results and practice has proven its usefulness. Performance when heterogeneity is present in the data: n Phenotypic (diff clinical expressions), genetic (diff inheritance patterns), locus (diff genes), allelic (diff alleles in same gene)
 References for MDR n n n n n Ritchie MD, Hahn LW, Roodi N, Bailey LR, Dupont WD, Parl FF, Moore JH. Multifactordimensionality reduction reveals high-order interactions among estrogen-metabolism genes in sporadic breast cancer. Am J Hum Genet. 2001 Jul; 69(1): 138 -47. Ritchie MD, Hahn LW, Moore JH. Power of multifactor dimensionality reduction for detecting gene -gene interactions in the presence of genotyping error, missing data, phenocopy, and genetic heterogeneity. Genet Epidemiol. 2003 Feb; 24(2): 150 -7. Hahn LW, Ritchie MD, Moore JH. Multifactor dimensionality reduction software for detecting gene and gene-environment interactions. Bioinformatics. 2003 Feb 12; 19(3): 376 -82. Moore JH. The ubiquitous nature of epistasis in determining susceptibility to common human diseases. Hum Hered. 2003; 56(1 -3): 73 -82. Cho YM, Ritchie MD, Moore JH, Park JY, Lee KU, Shin HD, Lee HK, Park KS. Multifactordimensionality reduction shows a two-locus interaction associated with Type 2 diabetes mellitus. Diabetologia. 2004 Mar; 47(3): 549 -54. Ritchie MD, Motsinger AA. Multifactor dimensionality reduction for detecting gene-gene and geneenvironment interactions in pharmacogenomics studies. Pharmacogenomics. 2005 Dec; 6(8): 82334. Martin ER, Ritchie MD, Hahn L, Kang S, Moore JH. A novel method to identify gene-gene effects in nuclear families: the MDR-PDT. Genet Epidemiol. 2006 Feb; 30(2): 111 -23. Andrew AS, Nelson HH, Kelsey KT, Moore JH, Meng AC, Casella DP, Tosteson TD, Schned AR, Karagas MR. Concordance of multiple analytical approaches demonstrates a complex relationship between DNA repair gene SNPs, smoking and bladder cancer susceptibility. Carcinogenesis. 2006 May; 27(5): 1030 -7. Moore JH, Gilbert JC, Tsai CT, Chiang FT, Holden T, Barney N, White BC. A flexible computational framework for detecting, characterizing, and interpreting statistical patterns of epistasis in genetic studies of human disease susceptibility. J Theor Biol. 2006 Jul 21; 241(2): 252 -61.
References for MDR n n n n n Ritchie MD, Hahn LW, Roodi N, Bailey LR, Dupont WD, Parl FF, Moore JH. Multifactordimensionality reduction reveals high-order interactions among estrogen-metabolism genes in sporadic breast cancer. Am J Hum Genet. 2001 Jul; 69(1): 138 -47. Ritchie MD, Hahn LW, Moore JH. Power of multifactor dimensionality reduction for detecting gene -gene interactions in the presence of genotyping error, missing data, phenocopy, and genetic heterogeneity. Genet Epidemiol. 2003 Feb; 24(2): 150 -7. Hahn LW, Ritchie MD, Moore JH. Multifactor dimensionality reduction software for detecting gene and gene-environment interactions. Bioinformatics. 2003 Feb 12; 19(3): 376 -82. Moore JH. The ubiquitous nature of epistasis in determining susceptibility to common human diseases. Hum Hered. 2003; 56(1 -3): 73 -82. Cho YM, Ritchie MD, Moore JH, Park JY, Lee KU, Shin HD, Lee HK, Park KS. Multifactordimensionality reduction shows a two-locus interaction associated with Type 2 diabetes mellitus. Diabetologia. 2004 Mar; 47(3): 549 -54. Ritchie MD, Motsinger AA. Multifactor dimensionality reduction for detecting gene-gene and geneenvironment interactions in pharmacogenomics studies. Pharmacogenomics. 2005 Dec; 6(8): 82334. Martin ER, Ritchie MD, Hahn L, Kang S, Moore JH. A novel method to identify gene-gene effects in nuclear families: the MDR-PDT. Genet Epidemiol. 2006 Feb; 30(2): 111 -23. Andrew AS, Nelson HH, Kelsey KT, Moore JH, Meng AC, Casella DP, Tosteson TD, Schned AR, Karagas MR. Concordance of multiple analytical approaches demonstrates a complex relationship between DNA repair gene SNPs, smoking and bladder cancer susceptibility. Carcinogenesis. 2006 May; 27(5): 1030 -7. Moore JH, Gilbert JC, Tsai CT, Chiang FT, Holden T, Barney N, White BC. A flexible computational framework for detecting, characterizing, and interpreting statistical patterns of epistasis in genetic studies of human disease susceptibility. J Theor Biol. 2006 Jul 21; 241(2): 252 -61.
 Acknowledgements Slides content based on material from Jie Chen, Frank Emmert-Streib, Earl F Glynn, Hua Li, Bolan Linghu, Arcady R Mushegian, Yan Meng, Jurg Ott, Marylyn Ritchie, Antonio Salas, Chris Seidel, Matt Mc. Queen, Christoph Lange and discussions with Steve Horvath, Nan M. Laird, Stephen Lake, Christoph Lange, Ross Lazarus, Matthew Mc. Queen, Benjamin Raby, Nuria Malats, Marylyn Ritchie (lab), Edwin K. Silverman, Scott T. Weiss, Xin Xu, …
Acknowledgements Slides content based on material from Jie Chen, Frank Emmert-Streib, Earl F Glynn, Hua Li, Bolan Linghu, Arcady R Mushegian, Yan Meng, Jurg Ott, Marylyn Ritchie, Antonio Salas, Chris Seidel, Matt Mc. Queen, Christoph Lange and discussions with Steve Horvath, Nan M. Laird, Stephen Lake, Christoph Lange, Ross Lazarus, Matthew Mc. Queen, Benjamin Raby, Nuria Malats, Marylyn Ritchie (lab), Edwin K. Silverman, Scott T. Weiss, Xin Xu, …
