

660a571bc2e03036f7bff28eac06250b.ppt
- Количество слайдов: 40
 Arithmetic operations & data System performance Processor") Overview • • Instruction set architecture (MIPS) Arithmetic operations & data System performance Processor • Datapath and control • Pipelining to improve performance • Memory hierarchy • I/O
Overview • • Instruction set architecture (MIPS) Arithmetic operations & data System performance Processor • Datapath and control • Pipelining to improve performance • Memory hierarchy • I/O
 Focus • How computers work • MIPS instruction set architecture • The implementation of MIPS instruction set architecture – MIPS processor design • Issues affecting modern processors • Pipelining – processor performance improvement • Cache – memory system, I/O systems
Focus • How computers work • MIPS instruction set architecture • The implementation of MIPS instruction set architecture – MIPS processor design • Issues affecting modern processors • Pipelining – processor performance improvement • Cache – memory system, I/O systems
 Why Learn Computer Architecture? • You want to call yourself a “computer scientist” • Computer architecture impacts every other aspect of computer science • You need to make a purchasing decision or offer “expert” advice • You want to build software people use – sell many, many copies-(need performance) • Both hardware and software affect performance • • Algorithm determines number of source-level statements Language/compiler/architecture determine machine instructions Processor/memory determine how fast instructions are executed Assessing and understanding performance
Why Learn Computer Architecture? • You want to call yourself a “computer scientist” • Computer architecture impacts every other aspect of computer science • You need to make a purchasing decision or offer “expert” advice • You want to build software people use – sell many, many copies-(need performance) • Both hardware and software affect performance • • Algorithm determines number of source-level statements Language/compiler/architecture determine machine instructions Processor/memory determine how fast instructions are executed Assessing and understanding performance
 translate") Objectives • How programs written in a high-level language (e. g. , Java/C++) translate into the language of the hardware and how the hardware executes them. • The interface between software and hardware and how software instructs hardware to perform the needed functions. • The factors that determine the performance of a program • The techniques that hardware designers employ to improve performance. As a consequence, you will understand what features may make one computer design better than another for a particular application
Objectives • How programs written in a high-level language (e. g. , Java/C++) translate into the language of the hardware and how the hardware executes them. • The interface between software and hardware and how software instructs hardware to perform the needed functions. • The factors that determine the performance of a program • The techniques that hardware designers employ to improve performance. As a consequence, you will understand what features may make one computer design better than another for a particular application
 Evolution… • In the beginning there were only bits… and people spent countless hours trying to program in machine language 011001011001110100 • Finally before everybody went insane, the assembler was invented: write in mnemonics called assembly language and let the assembler translate (a one to one translation) add A, B • This wasn’t for everybody, obviously… (imagine how modern applications would have been possible in assembly), so high-level language were born (and with them compilers to translate to assembly, a many-to-one translation) C= A*(SQRT(B)+3. 0)
Evolution… • In the beginning there were only bits… and people spent countless hours trying to program in machine language 011001011001110100 • Finally before everybody went insane, the assembler was invented: write in mnemonics called assembly language and let the assembler translate (a one to one translation) add A, B • This wasn’t for everybody, obviously… (imagine how modern applications would have been possible in assembly), so high-level language were born (and with them compilers to translate to assembly, a many-to-one translation) C= A*(SQRT(B)+3. 0)
 view") THE BIG IDEA • Levels of abstraction: each layer provides its own (simplified) view and hides the details of the next.
THE BIG IDEA • Levels of abstraction: each layer provides its own (simplified) view and hides the details of the next.
 • ISA: An abstract interface between the hardware and the") Instruction Set Architecture (ISA) • ISA: An abstract interface between the hardware and the lowest level software of a machine that encompasses all the information necessary to write a machine language program that will run correctly, including instructions, registers, memory access, I/O, and so on. “. . . the attributes of a [computing] system as seen by the programmer, i. e. , the conceptual structure and functional behavior, as distinct from the organization of the data flows and controls, the logic design, and the physical implementation. ” – Amdahl, Blaauw, and Brooks, 1964 • Enables implementations of varying cost and performance to run identical software • ABI (application binary interface): The user portion of the instruction set plus the operating system interfaces used by application programmers. Defines a standard for binary portability across computers.
Instruction Set Architecture (ISA) • ISA: An abstract interface between the hardware and the lowest level software of a machine that encompasses all the information necessary to write a machine language program that will run correctly, including instructions, registers, memory access, I/O, and so on. “. . . the attributes of a [computing] system as seen by the programmer, i. e. , the conceptual structure and functional behavior, as distinct from the organization of the data flows and controls, the logic design, and the physical implementation. ” – Amdahl, Blaauw, and Brooks, 1964 • Enables implementations of varying cost and performance to run identical software • ABI (application binary interface): The user portion of the instruction set plus the operating system interfaces used by application programmers. Defines a standard for binary portability across computers.
 Assembly language program (for") High-level to Machine Language Compiler High-level language program (in C) Assembly language program (for MIPS) Assembler Binary machine language program (for MIPS)
High-level to Machine Language Compiler High-level language program (in C) Assembly language program (for MIPS) Assembler Binary machine language program (for MIPS)
 How Do the Pieces Fit Together? Application Operating System Compiler Memory system Firmware Instr. Set Proc. Instruction Set Architecture I/O system Datapath & Control Digital Design Circuit Design • Coordination of many levels of abstraction • Under a rapidly changing set of forces • Design, measurement, and evaluation
How Do the Pieces Fit Together? Application Operating System Compiler Memory system Firmware Instr. Set Proc. Instruction Set Architecture I/O system Datapath & Control Digital Design Circuit Design • Coordination of many levels of abstraction • Under a rapidly changing set of forces • Design, measurement, and evaluation
 Organization of a computer
Organization of a computer
 Datapath (“brawn”) Memory") Anatomy of Computer 5 classic components Personal Computer Processor Control (“brain”) Datapath (“brawn”) Memory (where programs, data live when running) Devices Input Output Keyboard, Mouse Disk (where programs, data live when not running) Display, Printer Datapath: performs arithmetic operation Control: guides the operation of other components based on the user instructions
Anatomy of Computer 5 classic components Personal Computer Processor Control (“brain”) Datapath (“brawn”) Memory (where programs, data live when running) Devices Input Output Keyboard, Mouse Disk (where programs, data live when not running) Display, Printer Datapath: performs arithmetic operation Control: guides the operation of other components based on the user instructions
 Motherboard
Motherboard
 Motherboard
Motherboard
 Motherboard
Motherboard
 Motherboard Layout
Motherboard Layout
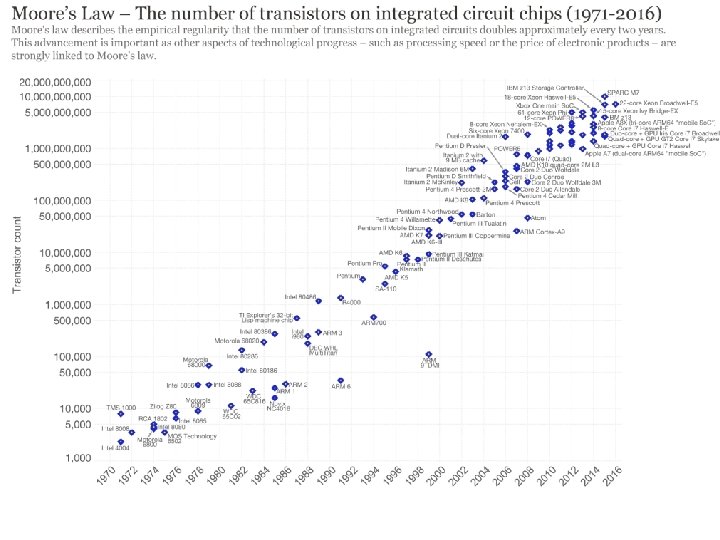
 Moore’s Law • In 1965, Gordon Moore predicted that the number of transistors that can be integrated on a die would double every 18 to 24 months (i. e. , grow exponentially with time). • Amazingly visionary – million transistor/chip barrier was crossed in the 1980’s. 2300 transistors, 1 MHz clock (Intel 4004) - 1971 16 Million transistors (Ultra Sparc III) 42 Million transistors, 2 GHz clock (Intel Xeon) – 2001 55 Million transistors, 3 GHz, 130 nm technology, 250 mm 2 die (Intel Pentium 4) - 2004 • 140 Million transistor (HP PA-8500) • •
Moore’s Law • In 1965, Gordon Moore predicted that the number of transistors that can be integrated on a die would double every 18 to 24 months (i. e. , grow exponentially with time). • Amazingly visionary – million transistor/chip barrier was crossed in the 1980’s. 2300 transistors, 1 MHz clock (Intel 4004) - 1971 16 Million transistors (Ultra Sparc III) 42 Million transistors, 2 GHz clock (Intel Xeon) – 2001 55 Million transistors, 3 GHz, 130 nm technology, 250 mm 2 die (Intel Pentium 4) - 2004 • 140 Million transistor (HP PA-8500) • •
 Moore’s Law • “Cramming More Components onto Integrated Circuits” • # of transistors per cost-effective integrated circuit doubles every 18 months • Gordon Moore, Electronics, 1965 “Transistor capacity doubles every 18 -24 months” Speed 2 x / 1. 5 years (since ‘ 85); 100 X performance in last decade
Moore’s Law • “Cramming More Components onto Integrated Circuits” • # of transistors per cost-effective integrated circuit doubles every 18 months • Gordon Moore, Electronics, 1965 “Transistor capacity doubles every 18 -24 months” Speed 2 x / 1. 5 years (since ‘ 85); 100 X performance in last decade
 2014 2016
2014 2016
 i 9 October 2017 Release
i 9 October 2017 Release
 • The choice for main memory •") Memory • Dynamic Random Access Memory (DRAM) • The choice for main memory • Volatile (contents go away when power is lost) • Fast • Relatively small • DRAM capacity: 2 x / 2 years (since ‘ 96); 64 x size improvement in last decade • Static Random Access Memory (SRAM) • The choice for cache • Much faster than DRAM, but less dense and more costly • Magnetic disks • The choice for secondary memory • Non-volatile • Slower • Relatively large • Capacity: 2 x / 1 year (since ‘ 97) 250 X size in last decade • Solid state (Flash) memory • The choice for embedded computers • Non-volatile
Memory • Dynamic Random Access Memory (DRAM) • The choice for main memory • Volatile (contents go away when power is lost) • Fast • Relatively small • DRAM capacity: 2 x / 2 years (since ‘ 96); 64 x size improvement in last decade • Static Random Access Memory (SRAM) • The choice for cache • Much faster than DRAM, but less dense and more costly • Magnetic disks • The choice for secondary memory • Non-volatile • Slower • Relatively large • Capacity: 2 x / 1 year (since ‘ 97) 250 X size in last decade • Solid state (Flash) memory • The choice for embedded computers • Non-volatile
 Memory • Optical disks • Removable, therefore very large • Slower than disks • Magnetic tape • Even slower • Sequential (non-random) access • The choice for archival
Memory • Optical disks • Removable, therefore very large • Slower than disks • Magnetic tape • Even slower • Sequential (non-random) access • The choice for archival
 DRAM Capacity Growth 128 GB 0. 02µm 2017
DRAM Capacity Growth 128 GB 0. 02µm 2017
 Trend: Memory Capacity • Approx. 2 X every 2 years. year 1980 1983 1986 1989 1992 1996 1998 2000 2002 2006 2010 2014 2017 size (Mbit) 0. 0625 0. 25 1 4 16 64 128 256 512 2 G 8 G 16 G 128 G
Trend: Memory Capacity • Approx. 2 X every 2 years. year 1980 1983 1986 1989 1992 1996 1998 2000 2002 2006 2010 2014 2017 size (Mbit) 0. 0625 0. 25 1 4 16 64 128 256 512 2 G 8 G 16 G 128 G
 Example Machine Organization • Workstation design target • 25% of cost on processor • 25% of cost on memory (minimum memory size) • Rest on I/O devices, power supplies, box Computer CPU Memory Devices Control Input Datapath Output
Example Machine Organization • Workstation design target • 25% of cost on processor • 25% of cost on memory (minimum memory size) • Rest on I/O devices, power supplies, box Computer CPU Memory Devices Control Input Datapath Output
 MIPS R 3000 Instruction Set Architecture Registers • Instruction Categories • • Load/Store Computational Jump and Branch Floating Point • • • R 0 - R 31 coprocessor Memory Management Special PC HI LO 3 Instruction Formats: all 32 bits wide OP rs rt OP rd sa immediate jump target funct
MIPS R 3000 Instruction Set Architecture Registers • Instruction Categories • • Load/Store Computational Jump and Branch Floating Point • • • R 0 - R 31 coprocessor Memory Management Special PC HI LO 3 Instruction Formats: all 32 bits wide OP rs rt OP rd sa immediate jump target funct
 Defining Performance • Which airplane is the best?
Defining Performance • Which airplane is the best?
 Response Time and Throughput • Response time • How long it takes to do a task • Throughput • Total work done per unit time • e. g. , tasks/transactions/… per hour • How are response time and throughput affected by • Replacing the processor with a faster version? • Adding more processors? • We’ll focus on response time for now…
Response Time and Throughput • Response time • How long it takes to do a task • Throughput • Total work done per unit time • e. g. , tasks/transactions/… per hour • How are response time and throughput affected by • Replacing the processor with a faster version? • Adding more processors? • We’ll focus on response time for now…
 Relative Performance • Define Performance = 1/Execution Time • “X is n time faster than Y” q Example: time taken to run a program l 10 s on A, 15 s on B Execution Time. B / Execution Time. A = 15 s / 10 s = 3/2 = 1. 5 l So A is 1. 5 times faster than B l
Relative Performance • Define Performance = 1/Execution Time • “X is n time faster than Y” q Example: time taken to run a program l 10 s on A, 15 s on B Execution Time. B / Execution Time. A = 15 s / 10 s = 3/2 = 1. 5 l So A is 1. 5 times faster than B l
 Measuring Execution Time • Elapsed time • Total response time, including all aspects • Processing, I/O, OS overhead, idle time • Determines system performance • CPU time • Time spent processing a given job • Discounts I/O time, other jobs’ shares • Comprises user CPU time and system CPU time • Different programs are affected differently by CPU and system performance
Measuring Execution Time • Elapsed time • Total response time, including all aspects • Processing, I/O, OS overhead, idle time • Determines system performance • CPU time • Time spent processing a given job • Discounts I/O time, other jobs’ shares • Comprises user CPU time and system CPU time • Different programs are affected differently by CPU and system performance
 CPU Clocking • Operation of digital hardware governed by a constant-rate clock Clock period Clock (cycles) Data transfer and computation Update state q Clock frequency (rate): cycles per second (influenced by CPU design) l q e. g. , 4. 0 GHz = 4000 MHz = 4. 0× 109 Hz Clock period: duration of a clock cycle e. g. , 250 ps = 0. 25 ns = 250× 10– 12 s l also = 1/(clock rate)
CPU Clocking • Operation of digital hardware governed by a constant-rate clock Clock period Clock (cycles) Data transfer and computation Update state q Clock frequency (rate): cycles per second (influenced by CPU design) l q e. g. , 4. 0 GHz = 4000 MHz = 4. 0× 109 Hz Clock period: duration of a clock cycle e. g. , 250 ps = 0. 25 ns = 250× 10– 12 s l also = 1/(clock rate)
 • Performance improved by • Reducing number of") CPU Time (for a particular program) • Performance improved by • Reducing number of clock cycles (cycle count) • Increasing clock rate • Hardware designer must often trade off clock rate against cycle count • Clock Frequency = Clock Rate(GHz) = 1/Clock Period(Cycle Time)
CPU Time (for a particular program) • Performance improved by • Reducing number of clock cycles (cycle count) • Increasing clock rate • Hardware designer must often trade off clock rate against cycle count • Clock Frequency = Clock Rate(GHz) = 1/Clock Period(Cycle Time)
 CPU Time Example • Computer A: 2 GHz clock, 10 s CPU time • Designing Computer B • Aim for 6 s CPU time • Can do faster clock, but causes 1. 2 × clock cycles (A’s) • How fast must Computer B clock be?
CPU Time Example • Computer A: 2 GHz clock, 10 s CPU time • Designing Computer B • Aim for 6 s CPU time • Can do faster clock, but causes 1. 2 × clock cycles (A’s) • How fast must Computer B clock be?
 • Instruction Count per program • Determined") Instruction Count and Cycles Per Instruction (CPI) • Instruction Count per program • Determined by program, ISA and compiler • Average cycles per instruction • Determined by CPU hardware • If different instructions have different CPI • Average CPI affected by instruction mix
Instruction Count and Cycles Per Instruction (CPI) • Instruction Count per program • Determined by program, ISA and compiler • Average cycles per instruction • Determined by CPU hardware • If different instructions have different CPI • Average CPI affected by instruction mix
 CPI Example • Computer A: Cycle Time = 250 ps, CPI = 2. 0 • Computer B: Cycle Time = 500 ps, CPI = 1. 2 • Same ISA • Which is faster, and by how much? A is faster… …by this much
CPI Example • Computer A: Cycle Time = 250 ps, CPI = 2. 0 • Computer B: Cycle Time = 500 ps, CPI = 1. 2 • Same ISA • Which is faster, and by how much? A is faster… …by this much
 CPI in More Detail • If different instruction classes take different numbers of cycles q Weighted average CPI Relative frequency
CPI in More Detail • If different instruction classes take different numbers of cycles q Weighted average CPI Relative frequency
 CPI Example • Alternative compiled code sequences using instructions in classes A, B, C Class B C CPI for class 1 2 3 IC in sequence 1 2 IC in sequence 2 q A 4 1 1 Sequence 1: IC = 5 l l Clock Cycles = 2× 1 + 1× 2 + 2× 3 = 10 Avg. CPI = 10/5 = 2. 0 q Sequence 2: IC = 6 l l Clock Cycles = 4× 1 + 1× 2 + 1× 3 =9 Avg. CPI = 9/6 = 1. 5
CPI Example • Alternative compiled code sequences using instructions in classes A, B, C Class B C CPI for class 1 2 3 IC in sequence 1 2 IC in sequence 2 q A 4 1 1 Sequence 1: IC = 5 l l Clock Cycles = 2× 1 + 1× 2 + 2× 3 = 10 Avg. CPI = 10/5 = 2. 0 q Sequence 2: IC = 6 l l Clock Cycles = 4× 1 + 1× 2 + 1× 3 =9 Avg. CPI = 9/6 = 1. 5
 Performance Summary The BIG Picture • Performance depends on • Algorithm: affects IC, possibly CPI • Programming language: affects IC, CPI • Compiler: affects IC, CPI • Instruction set architecture: affects IC, and CPI CPU Time = IC x CPI x Clock cycle time:
Performance Summary The BIG Picture • Performance depends on • Algorithm: affects IC, possibly CPI • Programming language: affects IC, CPI • Compiler: affects IC, CPI • Instruction set architecture: affects IC, and CPI CPU Time = IC x CPI x Clock cycle time:
 Pitfall: MIPS as a Performance Metric • MIPS: Millions of Instructions Per Second • Doesn’t account for • Differences in ISAs between computers • Differences in complexity between instructions l CPI varies between programs on a given CPU
Pitfall: MIPS as a Performance Metric • MIPS: Millions of Instructions Per Second • Doesn’t account for • Differences in ISAs between computers • Differences in complexity between instructions l CPI varies between programs on a given CPU
 Concluding Remarks • Cost/performance is improving • Due to underlying technology development • Hierarchical layers of abstraction • In both hardware and software • Instruction set architecture • The hardware/software interface • Execution time: the best performance measure • Power is a limiting factor • Use parallelism to improve performance
Concluding Remarks • Cost/performance is improving • Due to underlying technology development • Hierarchical layers of abstraction • In both hardware and software • Instruction set architecture • The hardware/software interface • Execution time: the best performance measure • Power is a limiting factor • Use parallelism to improve performance