Fauler.ppt
- Количество слайдов: 62



Особенности корпоративных систем большой объем хранимых данных ¢ параллельная работа множества пользователей ¢ большое число окон экранного интерфейса ¢ интеграция с другими системами ¢ сложная бизнес логика ¢
 — промежуток времени,")
Характеристики производительности системы ¢ ¢ ¢ ¢ Время отклика (response time) — промежуток времени, который требуется системе, чтобы обработать запрос извне. Быстрота реагирования (responsiveness) — скорость подтверждения запроса Время задержки (latency) — минимальный интервал времени до получения какого либо отклика (даже если от системы более ничего не требуется). Пропускная способность (timeinput) — количество данных (операций), передаваемых (выполняемых) в единицу времени. Загрузка (load) —количество одновременно подключенных пользователей. Параметр загрузки обычно служит контекстом для представления других функциональных характеристик, подобных времени отклика. Чувствительность к загрузке (load sensitivity) — выражение, задающее зависимость времени отклика от загрузки. Эффективность (efficiency) — удельная производительность в пересчете на одну единицу ресурса. Способность к масштабированию (scalability) — свойство, характеризующее поведение системы при добавлении ресурсов (обычно аппаратных).
 — одна из общеупотребительных моделей, используемых разработчиками программного обеспечения для разделения")
Концепция слоев (layers) — одна из общеупотребительных моделей, используемых разработчиками программного обеспечения для разделения сложных систем на более простые части. Слой более высокого уровня пользуется службами, предоставляемыми нижележащим слоем, но тот не "осведомлен" о наличии соседнего верхнего слоя.

Преимущества слоев ¢ ¢ ¢ Отдельный слой можно воспринимать как единое самодостаточное целое, не особенно заботясь о наличии других слоев (скажем, для создание службы FTP необходимо знать протокол TCP, но не тонкости Ethernet). Можно выбирать альтернативную реализацию базовых слоев (приложения FTP способны работать без каких либо изменений в среде Ethernet, по соединению РРР или в любой другой среде передачи информации). Зависимость между слоями можно свести к минимуму. Так, при смене среды передачи информации (при условии сохранения функциональности слоя IP) служба FTP будет продолжать работать как ни в чем не бывало. Каждый слой является удачным кандидатом на стандартизацию (например, TCP и IP — стандарты, определяющие особенности функционирования соответствующих слоев системы сетевых коммуникаций). Созданный слой может служить основой для нескольких различных слоев более высокого уровня (протоколы TCP/IP используются приложениями FTP, telnet, SSH и HTTP).

Недостатки слоев ¢ ¢ Модификация одного слоя подчас связана с необходимостью внесения каскадных изменений в остальные слои. Классический пример из области корпоративных программных приложений: поле, добавленное в таблицу базы данных, подлежит воспроизведению в графическом интерфейсе и должно найти соответствующее отображение в каждом промежуточном слое. Наличие избыточных слоев нередко снижает производительность системы. При переходе от слоя к слою моделируемые сущности обычно подвергаются преобразованиям из одного представления в другое.
. Клиент – отображает информацию и реализует")
Двухуровневая архитектура Двухуровневая – клиент/сервер (90 е годы). Клиент – отображает информацию и реализует бизнес логику, сервер – хранит данные. Неэффективна при сложной бизнес логике, при разработке web приложений.

Трехслойная архитектура ¢ ¢ ¢ Представление Предоставление услуг, отображение данных, обработка событий пользовательского интерфейса (щелчков кнопками мыши и нажатий клавиш), обслуживание запросов HTTP, поддержка функций командной строки и API пакетного выполнения Домен Бизнес логика приложения Источник данных Обращение к базе данных, обмен сообщениями, управление транзакциями и т. д. Бизнес логика и источник данных не должны зависеть от представления
 Минус – скорость. ¢ Представление и")
Размещение слоев ¢ Все на сервере. (Web сайт) Минус – скорость. ¢ Представление и бизнес логика – на рабочей станции, остальное – на сервере. Минус – проблемы с развертыванием.
 ¢ модель предметной области")
Типовые решения организации бизнес логики ¢ сценарий транзакции (Transaction Script) ¢ модель предметной области (Domain Model) ¢ модуль таблицы (Table Module)

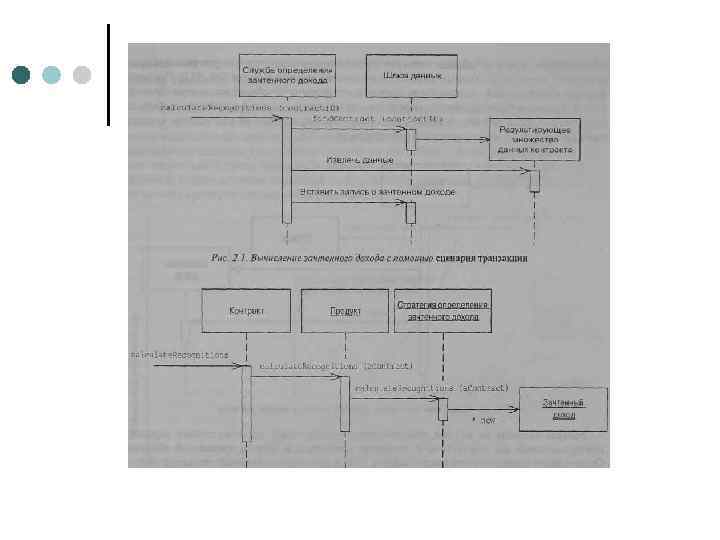
Сценарий транзакции — процедура, которая получает на вход информацию от слоя представления, обрабатывает ее, проводя необходимые проверки и вычисления, сохраняет в базе данных и активизирует операции других систем. Затем процедура возвращает слою представления определенные данные, возможно, осуществляя вспомогательные операции для фоматирования содержимого результата. Бизнес логика в этом случае описывается набором процедур, по одной на каждую (составную) операцию, которую способно выполнять приложение. l l l представляет собой удобную процедурную модель, легко воспринимаемую всеми разработчиками; удачно сочетается с простыми схемами организации слоя источника данных на основе типовых решений шлюз записи данных (Row Data Gateway) и шлюз таблицы данных (Table Data Gateway); определяет четкие границы транзакции. С возрастанием уровня сложности бизнес логики типовое решение сценарий транзак циидемонстрирует и ряд недостатков. Если нескольким транзакциям необходимо осуществлять схожие функции, возникает опасность дублирования фрагментов кода.

Модель предметной области множество объектов, описывающих сущности ¢ требует использования типовых решений объектно реляционного отображения. ¢

Модуль таблицы Объект связан с таблицей в базе данных, применяется совместно с типовым решением множество записей (Record Set). Посылая запросы к базе данных, пользователь прежде всего формирует объект множество записей, а затем создает объект контракта, передавая ему множество записей в качестве аргумента. Если потребуется выполнять операции над отдельным контрактом, следует сообщить объекту соответствующий идентификатор (ID).

Типовые решения источников данных Шлюз таблицы данных ¢ Шлюз записи данных ¢ Активная запись ¢ Преобразователь данных ¢

Шлюз таблицы данных Типовое решение шлюз таблицы данных содержит в себе все команды SQL, необходимые для извлечения, вставки, обновления и удаления данных из таблицы или представления. Методы этого типового решения используются другими объектами для взаимодействия с базой данных. Как правило, для каждой таблицы базы данных создается собственный шлюз таблицы данных. Используется совместно с модулем таблицы или сценарием транзакции.
 Шлюз записи данных выступает в роли объекта, полностью")
Шлюз записи данных (Row Data Gateway) Шлюз записи данных выступает в роли объекта, полностью повторяющего одну запись (одну строку таблицы базы данных). Каждому столбцу таблицы соответствует поле записи. Шлюз прекрасно подходит для применения в сценариях транзакции. Шлюз не включает никакой бизнес логики (иначе это активная запись).

Активная запись ¢ ¢ ¢ В основе типового решения активная запись лежит модель предметной области (Domain Model), классы которой повторяют структуру записей используемой базы данных. Каждая активная запись отвечает за сохранение и загрузку информации в базу данных, а также за логику домена, применяемую к данным. Как правило, типовое решение активная запись включает в себя методы: создание экземпляра активной записи на основе строки, полученной в результате выполнения SQL запроса; создание нового экземпляра активной записи для последующей вставки в таблицу; статические методы поиска, выполняющие стандартные SQL запросы и возвращающие активные записи; обновление базы данных и вставка в нее данных из активной записи; извлечение и установка значений полей (get и set методы); реализация некоторых фрагментов бизнес логики.

Преимущества и недостатки активной записи Преимуществом активной записи является простота ее реализации. Недостаток же состоит в том, что активные записи хороши только тогда, когда точно отображаются на таблицы базы данных. Если бизнес логика приложения достаточно сложна, вам наверняка захочется использовать имеющиеся отношения, коллекции, наследование и т. п. Все это не слишком хорошо отображается на активную запись, а добавление этих элементов "по частям" приведет к страшной неразберихе. В подобных ситуациях лучше воспользоваться преобразователем данных.

Преобразователь данных Типовое решение преобразователь данных представляет собой слой программного обеспечения, которое отделяет объекты, расположенные в оперативной памяти, от базы данных. В функции преобразователя данных входит передача данных между объектами и базой данных и изоляция их друг от друга. Объектымогут даже не "подозревать" о самом факте присутствия базы данных.

Схема извлечения данных

Типовые решения объектно реляционного отображения для моделирования поведения Единица работы ¢ Коллекция объектов ¢ Загрузка по требованию ¢
 Работая с БД нужно отслеживать изменения, чтобы их сохранить.")
Единица работы (Unit of Work) Работая с БД нужно отслеживать изменения, чтобы их сохранить. Созданные объекты необходимо вставлять, а удаленные — уничтожать. Изменения в базу данных можно вносить при каждом изменении, но это снизит производительность. Типовое решение единица работы позволяет контролировать все действия, выполняемые в рамках бизнес транзакции, которые связаны с базой данных. По завершении всех действий оно определяет окончательные результаты работы, которые и будут внесены в базу данных.

Коллекция объектов Типовое решение коллекция объектов хранит в себе данные обо всех объектах, загруженных из базы данных в пределах одной бизнес транзакции. Она позволяет устранить проблему повторной загрузки. Коллекция объектов обычно помещается в объект единица работы.

Загрузка по требованию При загрузке данных загружаются связанные с ним объекты. Типовое решение загрузка по требованию прерывает процесс загрузки, оставляя метку в структуре объектов. Это позволяет загрузить необходимые данные только тогда, когда они действительно понадобятся.

Типовые решения объектно реляционного отображения для моделирования структуры ¢ ¢ ¢ ¢ ¢ Поле идентификации (Identity Field) Отображение внешних ключей (Foreign Key Mapping) Отображение с помощью таблицы ассоциаций (Association Table Mapping) Отображение зависимых объектов (Dependent Mapping) Внедренное значение (Embedded Value) Сериализованный крупный объект (Serialized LOB) Наследование с одной таблицей (Single Table Inheritance) Наследование с таблицами для каждого класса (Class Table Inheritance) Наследование с таблицами для каждого конкретного класса (Concrete Table Inheritance) Преобразователи наследования (Inheritance Mappers)

Поле идентификации — сохраняет значение ключа для поддержки соответствия между объектом и строкой в таблице. По полю связываются объекты в оперативной памяти. Ключ может быть уникальным для таблицы или для всей БД в целом. Для нового объекта ключ генерирует СУБД или программист. При втором способе используется таблица ключей.

Отображение внешних ключей отображает объектную ссылку на внешний ключ базы данных. Для обеспечения целостности при изменении одного из объектов применяют обратные ссылки.

Отображение с помощью таблицы ассоциаций Объекты могут хранить коллекции. В БД каждое поле содержит одно значение. Для отображения связи типа «многие ко многим» нужно создать дополнительную таблицу отношений, а затем воспользоваться типовым решением отображение с помощью таблицы ассоциаций. Таблица отношений содержит только значения внешних ключей двух таблиц, связанных отношением. Каждой паре взаимосвязанных объектов соответствует одна строка таблицы отношений.

Отображение зависимых объектов При композиции ответственность за сохранение в БД зависимых объектов несет преобразователь владельца. Зависимые объекты не имеют полей идентификации, их нельзя найти без владельца.

Внедренное значение Внедренные объекты мелкие, им не соответствует таблица, их значения заносятся в поля таблицы для владельца.

Сериализованный крупный объект В объектных моделях часто встречаются сложные графы небольших объектов. Объекты не обязательно хранить в виде связанных между собой строк таблицы. Еще одной формой хранения объектов является сериализация, при которой весь граф объектов записывается в базу данных в виде так называемого крупного объекта (Large Object — LOB). На объекты не должно быть ссылок и запросов.

Наследование с одной таблицей Представляет иерархию наследования классов в виде одной таблицы, столбцы которой соответствуют всем полям классов, входящих в иерархию. Преимущества: только одна таблица, не нужно соединение таблиц. Недостатки: расход памяти, много полей и индексов в одной таблице

Наследование с таблицами для каждого класса Каждому классу соответствует своя таблица базы данных. Поля класса домена отображаются на столбцы таблицы. При связи строки из таблиц, соответствующих базовому и производному классам, используются ключи.

Наследование с таблицами для каждого конкретного класса создание отдельной таблицы для каждого конкретного класса. При этом таблица содержит столбцы, соответствующие полям конкретного класса и всех его "предков", а потому поля базового класса дублируются во всех таблицах его производных классов.

Шаблоны, предназначенные для представления данных в Web ¢ ¢ ¢ ¢ Модель представление контроллер (Model View Controller) Контроллер страниц (Page Controller) Контроллер запросов (Front Controller) Контроллер приложения (Application Controller) Представление по шаблону (Template View) Представление с преобразованием (Transform View) Двухэтапное представление (Two Step View)
 ¢ ¢ ¢ Модель это объект, предоставляющий некоторую")
Модель представление контроллер (Model View Controller) ¢ ¢ ¢ Модель это объект, предоставляющий некоторую информацию о домене. Содержит в себе все данные и поведение и не связана с пользовательским интерфейсом. Представление отображает содержимое модели средствами графического интерфейса. Все изменения информации обрабатываются контроллером. Получая входные данные от пользователя, он выполняет операции над моделью и указывает представлению на необходимость соответствующего обновления.
")
Модель представление контроллер (Model View Controller)
 ¢ ¢ ¢ Объект, который обрабатывает запрос к Web странице")
Контроллер страниц (Page Controller) ¢ ¢ ¢ Объект, который обрабатывает запрос к Web странице или выполнение конкретного действия на Web сайте. Предполагает наличие отдельного контроллера для каждой логической страницы Web сайта. Может быть реализован в виде сценария (сценария CGI, сервлета и т. п. ) или страницы сервера (ASP, PHP, JSP и т. п. ). Контроллер страниц хорошо применять для сайтов с достаточно простой логикой контроллера.
")
Контроллер страниц (Page Controller)
 ¢ ¢ Контроллер, который обрабатывает все запросы к Web сайту.")
Контроллер запросов (Front Controller) ¢ ¢ Контроллер, который обрабатывает все запросы к Web сайту. Он объединяет все действия по обработке запросов в одном месте, распределяя их выполнение посредством единственного объекта обработчика. Как правило этот объект реализует общее поведение, которое может быть изменено во время выполнения с помощью декораторов (Decorator). Для выполнения конкретного запроса обработчик вызывает соответствующий объект команды (Command). Выбор команды может происходить статически или динамически.
")
Контроллер запросов (Front Controller)
 ¢ ¢ ¢ Контроллер приложения выполняет две основные функции: выбор")
Контроллер приложения (Application Controller) ¢ ¢ ¢ Контроллер приложения выполняет две основные функции: выбор логики домена, которую нужно применить в конкретной ситуации, и выбор представления, которое следует отобразить в ответ на запрос. Для осуществления этих функций контроллер приложения поддерживает две коллекции ссылок на классы одну для команд, выполняющихся в слое домена, и одну для представлений. Основное преимущество данного типового решения состоит именно в определении порядка отображения страниц и выборе тех или иных представлений в зависимости от состояний объектов.
")
Контроллер приложения (Application Controller)
 ¢ ¢ ¢ Преобразует результат выполнения запрос в формат")
Представление по шаблону (Template View) ¢ ¢ ¢ Преобразует результат выполнения запрос в формат HTML путём внедрения маркеров в HTML страницу. В основном выполняется вставка маркеров в текст готовой статической HTML страницы, при вызове которой для обслуживания запроса эти маркеры будут преобразованы в вызовы функций, предоставляющих динамическую информацию. Для избежания внедрения в страницу большого количества программной логики применяют вспомогательный объект (Helper Object). Он будет содержать в себе всю фактическую логику домена, а сама страница только вызовы вспомогательного объекта. Это значительно упростит структуру страницы и максимально приблизит её к "чистой" форме представления по шаблону.
")
Представление по шаблону (Template View)
 ¢ ¢ Представление, которое поочередно обрабатывает элементы данных домена")
Представление с преобразованием (Transform View) ¢ ¢ Представление, которое поочередно обрабатывает элементы данных домена и преобразует их в код HTML. При этом программа последовательно проходит по структуре данных домена и, обнаруживая новый фрагмент данных создает их описание в терминах HTML. Представление с преобразованием ориентировано на использование отдельных преобразований для каждого вида входных данных. Преобразованиями управляет нечто наподобие простого цикла, который поочередно просматривает каждый входной элемент, подбирает для него подходящее преобразование и применяет это преобразование. Преобразования изначально направлены на визуализацию данных в формат HTML, что позволяет избежать внедрения в представление слишком большого количества логики.
")
Представление с преобразованием (Transform View)
 ¢ ¢ На первом этапе информация, полученная от модели,")
Двухэтапное представление (Two Step View) ¢ ¢ На первом этапе информация, полученная от модели, организуется в некую логическую структуру, которая описывает визуальные элементы будущего отображения, однако еще не содержит кода HTML. На втором этапе полученная логическая структура преобразуется в код HTML. В двухэтапном представлении визуализация данных выполняется в два этапа, что требует по одному представлению первого этапа для каждой страницы приложения и единственное представление второго этапа для всего приложения. Последняя схема значительно облегчает изменение внешнего вида сайта на втором этапе, поскольку каждое такое изменение распространяется сразу на весь сайт.
 Олег")
Двухэтапное представление (Two Step View) Олег
 Объект переноса")
Типовые решения распределенной обработки данных ¢ ¢ Интерфейс удаленного доступа (Remote Facade) Объект переноса данных (Data Transfer Object)
 ¢ ¢ Предоставляет интерфейс с низкой степенью детализации для")
Интерфейс удаленного доступа (Remote Facade) ¢ ¢ Предоставляет интерфейс с низкой степенью детализации для доступа к объектам, имеющим интерфейс с высокой степенью детализации, в целях повышения эффективности работы в сети. Не включает логику домена

Реализация удаленного доступа на платформе. NET – web службы using System; using System. Web. Services; namespace Forecast { public class Forecast. Service : Web. Service { [Web. Method] public bool Has. Forecast. For(String location) { … } [Web. Method] public Conditions Get. Conditions(String location) { … } } } <%@ Web. Service Class=“Forecast. Service, Forecast" %> Имя типа Имя сборки
 ¢ ¢ Применяется для переноса данных между процессами")
Объект переноса данных (Data Transfer Object) ¢ ¢ Применяется для переноса данных между процессами в целях уменьшения количества вызовов Должен содержать в себе все данные, которые могут понадобиться удаленному объекту через какое то время.
 ¢")
Реализация объекта переноса данных ¢ Объект специального класса ¢ Множество записей (Data. Set) ¢ Коллекция произвольных данных – массив или словарь ¢ Сериализованный объект в текстовом или двоичном виде

Сборка объекта переноса данных ¢ Добиться независимости модели домена от объекта переноса данных можно путем реализации отдельного объекта сборщика, который будет создавать объект переноса данных на основе данных домена и наоборот — обновлять модель домена данными из объекта переноса данных
")
Типовые решения обработки задач автономного параллелизма ¢ ¢ Оптимистическая автономная блокировка (Optimistic Offline Lock) Пессимистическая автономная блокировка (Pessimistic Offline Lock) Блокировка с низкой степенью детализации (Coarse Grained Lock) Неявная блокировка (Implicit Lock)
 ¢ ¢ ¢ Предотвращает возникновение конфликтов между параллельными")
Оптимистическая автономная блокировка (Optimistic Offline Lock) ¢ ¢ ¢ Предотвращает возникновение конфликтов между параллельными бизнес транзакциями путем обнаружения конфликта и отката транзакции Сеансу разрешается зафиксировать изменение записи в базе данных, если со времени, прошедшего после загрузки этой записи текущим сеансом, она не была изменена никаким другим сеансом. Оптимистическая автономная блокировка может быть применена в любое время, однако срок ее действия ограничивается системной транзакцией, в процессе которой она была установлена.
")
Оптимистическая автономная блокировка (Optimistic Offline Lock)

Реализация блокировки с использованием номера версии

Применение OOLock ¢ Оптимистическое блокирование применяется тогда, когда вероятность возникновения конфликта между двумя параллельными бизнес транзакциями мала. В противном случае данная схема окажется весьма недружелюбной по отношению к пользователю, поскольку о том, что фиксация изменений невозможна, ему сообщат только тогда, когда он закончит выполнять все свои действия. Таким образом, если ве роятность конфликта довольно высока или откат проделанных изменений неприемлем, имеет смысл прибегнуть к пессимистической автономной блокировке.
 ¢ ¢ Предотвращает возникновение конфликтов между параллельными бизнес")
Пессимистическая автономная блокировка (Pessimistic Offline Lock) ¢ ¢ Предотвращает возникновение конфликтов между параллельными бизнес транзакциями, предоставляя доступ к данным в конкретный момент времени только одной бизнес транзакции Первый возможный тип блокировки — это монопольная блокировка записи (exclusive write lock), которая требует наложения блокировки только для редактирования данных. Монопольная блокировка чтения (exclusive read lock). В этом случае бизнес транзакция накладывает блокировку на данные уже при загрузке последних. . Блокировка чтения/записи (read/write lock) имеет немного более сложную схему, чем первые два типа. Чтение и запись взаимоисключающие, но допускаются параллельные блокировки чтения.
 ¢ ¢ Блокирует группу взаимосвязанных объектов")
Блокировка с низкой степенью детализации (Coarse Grained Lock) ¢ ¢ Блокирует группу взаимосвязанных объектов как единый элемент Реализуется с помощью единого номера версии
Fauler.ppt