


Основы работы с базой данных Лекция 8

l Коммерческая информация, хранящаяся в базе данных, имеет безусловно ценный характер. Ее утеря, повреждение, либо утечка могут иметь для владельца информации самые катастрофические последствия, поэтому вполне естественным было желание возложить обеспечение конфиденциальности информации на системы хранения

l Способы обеспечения конфиденциальности информации достаточно разнообразны – начиная от разграничения доступа к данным и заканчивая шифрованием информации, передаваемой по линиям связи.

l. В итоге длительного исторического развития средств хранения и доступа к информации сформировался определенный набор свойств, которым должна удовлетворять система хранения информации: l модель представления данных (как правило, реляционная); l понятие метаданных (т. е. разделение описания данных от
; l понятие транзакции (группа")
l понятие целостности данных (т. е. удовлетворение их определенным критериям); l понятие транзакции (группа последовательных изменений данных, выполняемая либо «сразу» как единое целое, либо не выполняемая вовсе); l средства обеспечения конфиденциальности информации. Системы, обладающие указанным набором свойств, носят название

ОСНОВНЫЕ ПОНЯТИЯ РЕЛЯЦИОННОЙ АЛГЕБРЫ l Реляционная модель данных базируется на строгом математическом аппарате. Реляционная база данных, в общем случае состоит из набора таблиц (в реляционной алгебре таблица носит название отношение).
 состоит из записей (которые называются кортежами), а записи – из полей")
Каждая таблица (отношение) состоит из записей (которые называются кортежами), а записи – из полей (которые называются атрибутами). l Каждый атрибут имеет имя и значение. Значение атрибута может быть определенного типа (принадлежать определенному домену). Значение атрибута не обязано присутствовать в каждой записи (кортеже) – в некоторые кортежи этот атрибут может не входить. l Факт отсутствия атрибута в кортеже обозначается специальной конструкцией NULL. Конструкция NULL обозначает не l
, требуется, чтобы каждый кортеж")
Для того, чтобы не возникали неоднозначности в идентификации записей (кортежей), требуется, чтобы каждый кортеж имел свой уникальный набор значений атрибутов. l Обычно выделяют один или несколько атрибутов, уникальность значений которых гарантируется (например, с помощью специальных программных средств). l Этот атрибут (или несколько атрибутов) носит название первичный ключ (PRIMARY KEY) и позволяет однозначно выбрать по его значению (набору значений) соответствующую запись (кортеж) в таблице (отношении). l

l. В реляционных СУБД в качестве единственного первичного ключа используется специальным образом формируемое поле (типа «счетчик» , либо сгенерированное с помощью объекта SEQUENCE), обычно числовое. l Это обстоятельство следует иметь в виду при проектировании реляционных СУБД.
 в базе данных обязана присутствовать и схема отношения (описание")
l Помимо собственно отношения (таблицы) в базе данных обязана присутствовать и схема отношения (описание таблицы). l Схема отношения является метаданными, т. е. данными, описывающими данные. l Таблиц (отношений) и схем (описаний) в базе данных может быть произвольное число (ограничения накладываются только конкретной реализацией той или иной СУБД), но каждой таблице (отношению) обязательно должна соответствовать ровно одна схема
 в БД определены следующие операции: l операция ограничения отношения; l операция")
Над таблицами (отношениями) в БД определены следующие операции: l операция ограничения отношения; l операция проекции отношения; l операция прямого (или декартова) произведения отношений; l операция соединения отношений; l операция объединения отношений; l операция пересечения отношений; l операция взятия разности отношений.
 только те записи (кортежи), которые")
l Операция ограничения отношения включает в результирующую таблицу (отношение) только те записи (кортежи), которые удовлетворяют заданным условиям. В языке SQL этой операции соответствует конструкция WHERE оператора SELECT.
 только те поля (атрибуты), которые")
l Операция проекции отношения включает в результирующую таблицу (отношение) только те поля (атрибуты), которые были явно заданы в операции. В языке SQL список полей (атрибутов) явно задается в списке выборки оператора SELECT.

l Операция прямого произведения отношений является фундаментальной операцией реляционных СУБД. l Если имеется две таблицы (отношения), то эта операция выполняется следующим образом : прямое произведение таблиц (отношений) представляет собой поочередную комбинацию каждой записи из Табл 1 с каждой записью Табл 2.

Следует иметь в виду, что таким и только таким образом соединяются в реляционной СУБД все таблицы. Если в одной таблице у Вас имеется 1000 строк, и в другой таблице имеется 1000 строк, в итоговой таблице у Вас будет 1000000 записей. Три таблицы по 1000 записей дадут 100000 (миллиард!) записей. Такая особенность работы – главная причина невысокой производительности реляционных СУБД на многотабличных запросах. l В языке SQL операция прямого произведения задается в виде списка соединяемых таблиц в l

l Операция соединения отношений является разновидностью операции прямого произведения. В отличие от прямого произведения, которое генерирует все возможные комбинации двух или нескольких таблиц, операция соединения выбирает из всех получившихся комбинаций только «осмысленные» . l Если, к примеру, в одной таблице у нас находятся шапки счетов-фактур, а в другой – строки счетов-фактур, то операция прямого произведения даст нам всевозможные комбинации строк и шапок, а операция соединения – только реальные счета-фактуры, в которых

l Поскольку операция соединения является разновидностью операции прямого произведения, в языке SQL она задается в виде списка соединяемых таблиц (как операция прямого произведения) и в виде специальных конструкций INNER JOIN, LEFT JOIN и RIGHT JOIN, в которых задается условие (способ) соединения таблиц. l В некоторых диалектах SQL (в частности, в СУБД ORACLE) вместо этих конструкций условия соединения можно указывать непосредственно в опции WHERE оператора SELECT.
, т. е. результирующая")
Операция объединения отношений представляет по сути своей слияние двух отношений (таблиц), т. е. результирующая таблица (отношение) будет содержать все записи и из первой, и из второй таблицы. l Существует две разновидности операции объединения, одна из которых представлена конструкцией UNION, а другая – UNION ALL оператора SELECT. l В первом случае требуется, чтобы в результирующей выборке не было одинаковых записей (кортежей) их двух разных таблиц (отношений). l Вторая разновидность – это слияние двух таблиц «не глядя» . Следует отметить, что не во всех диалектах SQL эти операции реализованы в полном объеме. В любом случае операция UNION (в отличие от UNION ALL) – гораздо более медленная, что необходимо учитывать при проектировании базы l
,")
l Операция пересечения отношений – это слияние данных из двух и более отношений (таблиц), причем в результирующее отношение попадают только те записи, которые есть в обоих таблицах (отношениях). l В языке SQL эта операция представлена конструкцией INTERSECT. Эта конструкция реализована не во всех диалектах SQL и, как и UNION, достаточно медленная.
 из первого отношения (таблицы), а")
Операция взятия разности отношений заключается в выборке кортежей (записей) из первого отношения (таблицы), а затем исключении из нее всех записей, которые встречаются в другой таблице (отношении). l В языке SQL эта операция представлена конструкцией MINUS оператора SELECT. Эта конструкция реализована не во всех диалектах SQL и также достаточно медленная. l Как и обычная операция вычитания, операция MINUS некоммутативна, т. е. в отличие от UNION и INTERSECT результат ее работы зависит от порядка следования таблиц (отношений). l

ДОСТУП К SQL-ОРИЕНТИРОВАННЫМ СУБД l Каждая СУБД обеспечивает пользователя различными средствами доступа к информации, находящейся в базе данных. Помимо специфических средств доступа, таких как SQL*Plus СУБД ORACLE или Microsoft Access, существует и ряд общепринятых способов доступа к информации, находящейся в БД.
 или аналогичную систему BDE (фирма Borland). l Доскональное")
Протокол ODBC (Open Data. Base Connection) или аналогичную систему BDE (фирма Borland). l Доскональное знание этих средств доступа не является обязательным для работы с SQLориентированными СУБД, но общее понимание принципа их работы позволит повысить эффективность работы с СУБД, а также искать и устранять тонкие ошибки, неизбежно возникающие при написании программного обеспечения, взаимодействующего с СУБД. l l Порядок работы с СУБД будем рассматривать на примере протокола ODBC
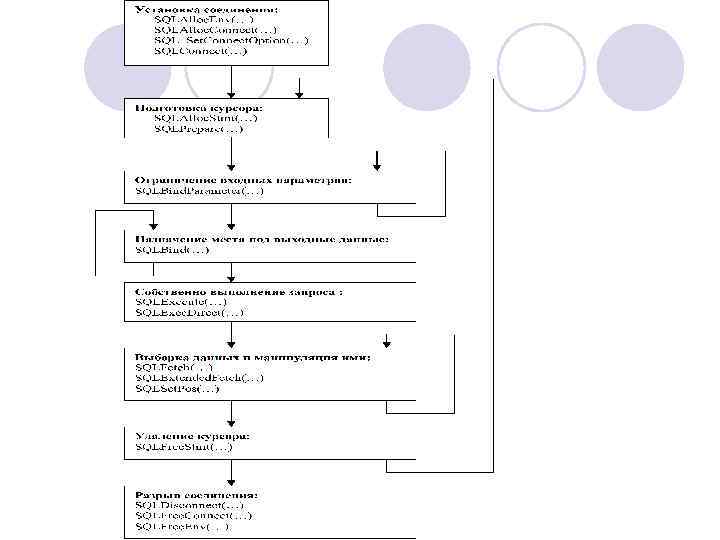

l l l первое действие при работе с реляционными СУБД – установка соединения. В момент установки СУБД проверяет права пользователя (требуется указывать имя пользователя и пароль) и настраивает программное обеспечения для работы с новым соединением. В протоколе ODBC этим действиям соответствует вызов следующих функций: SQLAlloc. Env(. . . ) SQLAlloc. Connect(. . . ) SQLSet. Connect. Option(. . . ) // Может повториться многократно. SQLConnect(. . . ) или SQLDriver. Connect(. . . )

l После успешного выполнения указанной последовательности вызовов соединение программы с реляционной СУБД установлено и пользователь может начинать работу с информацией. l Для выполнения тех или иных действий программа посылает СУБД различного рода запросы, написанные на языке SQL, и получает запрошенную информацию (если она требуется).
, во время которого проверяется")
Каждый запрос к СУБД проходит следующие стадии: l разбор (parse), во время которого проверяется синтаксис запроса, подтверждаются права пользователя на выполнение этого запроса и строится т. н. план запроса. В протоколе ODBC этому этапу соответствует функция SQLAlloc. Stmt(. . . ) и SQLPrepare(. . . ) Приведенные здесь имена функций соответствуют версии 2 протокола ODBC. В версию 3 протокола внесены достаточно существенные изменения (в частности, и в имена некоторых функций), но общий принцип работы с СУБД остался прежний.

ограничение переменных-параметров. Указанная возможность позволяет использовать ранее разобранный запрос многократно, просто подставляя в него все новые и новые значения определяющих параметров. l В синтаксисе SQL для указания параметровпеременных существуют специальные конструкции (при работе через ODBC – знак вопроса, при работе через OCI - конструкция вида : <Имя> или : <Номер> и т. д. ). l Этот этап не является обязательным. В протоколе ODBC ему соответствует вызов (возможно, многократный) функции l

l собственно выполнение запроса. В протоколе ODBC ему соответствует вызов функций SQLExecute(. . . ) или SQLExec. Direct(. . . ) l подготовка области памяти для приема выбранной информации. Этот этап характерен искючительно для оператора SELECT. В протоколе ODBC ему соответствует вызов (возможно, многократный) функции SQLBind. Col(. . . )

l собственно работа с выбранными данными. Физическая пересылка данных из БД в программу выполняется в протоколе ODBC с помощью функций SQLFetch(. . . ) или SQLExtended. Fetch(. . . ). Также используется только с оператором SELECT. l операции с выбранными данными (например, изменение полей, удаление или добавление записи). Эти операции выполняются в протоколе ODBC функцией SQLSet. Pos(. . . ).
. Этот порядок")
l завершение работы с выборкой – функция SQLFree. Stmt(. . . ). Этот порядок многократно повторяется на каждый запрос к СУБД. При завершении работы программы выполняется закрытие соединения с СУБД: l SQLDisconnect(. . . ) l SQLFree. Connect(. . . ) l SQLFree. Env(. . . )

При написании запросов к реляционным СУБД следует иметь в виду следующее: l Запросы на сервер базы данных передаются всегда в текстовом виде, т. е. сервер баз данных всегда работает как интерпретатор. Это позволяет формировать текст запроса непосредственно в программе.
 и SQLPrepare(. . .")
l Стадия разбора запроса (функции SQLAlloc. Stmt(. . . ) и SQLPrepare(. . . ), а также SQLExec. Direct(. . . )) являются чрезвычайно медленными операциями, поскольку они не только выполняют синтаксический анализ и компиляцию запроса, но и проверяют полномочия пользователя на его выполнения (это требует длительных поисков в словарях данных, в которых расписаны запреты и разрешения для каждого пользователя с точностью до отдельного поля в отдельной таблице).

l Операция также строит т. н. план запроса, т. е. последовательность его выполнения (это зачастую требует тонкого анализа по каждой таблице с привлечением автоматически собираемой статистики по количеству записей в таблице, частоте встречи того или иного ключа и т. д). Поэтому при написании программ необходимо, по возможности, выполнять однократную компиляцию запроса.

l Поскольку стадия разбора запроса является чрезвычайно медленной, большинство СУБД, не надеясь на грамотность разработчиков ПО, помещает все разобранные запросы в специальный системный кэш. Факт присутствия в различных СУБД проверяется по-разному: СУБД ORACLE требует полного текстуального совпадения, SQL Server – совпадения с точностью до констант и т. д.

l Если новый запрос, поступивший от пользователя, уже присутствует в кэше, он повторно не разбирается. Для того, чтобы воспользоваться этой возможностью, существует общее правило – никогда без крайней необходимости не прописывать в часто выполняемых запросах никаких констант. Все вхождения констант следует заменять символом переменной-параметра, и затем ограничивать его с помощью соответствующих функций
 носит название курсора. Существует")
l Выборка, полученная при выполнении оператора SELECT (и только его!) носит название курсора. Существует две разновидности курсоров – т. н. FORWARD_ONLY и «все остальные» . Главная особенность FORWARD_ONLYкурсоров – то, что по ним возможно движение только вперед на одну запись (по аналогии с x. Base – только операция SKIP). Остальные курсоры допускают движение во всех направлениях и на любое количество записей (SKIP +/-<Число записей>, GOTO TOP, GOTO BOTTOM, GOTO <Номер записи>).

Необходимо иметь в виду следующее: курсоры FORWARD_ONLY работают намного быстрее. Их, по возможности, следует использовать везде, где это допустимо – в первую очередь, при печати итоговых документов. l не все СУБД (особенно ранние версии) поддерживают не-FORWARD_ONLY-курсоры. В этих случаях протокол ODBC (или аналогичные ему средства) моделирует их «поведение» путем «выкачивания» на локальную машину выбранной информации с помощью FORWARD_ONLY-курсора. Рискнув посмотреть всего-навсего первую запись в «миллионной» таблице, можно в лучшем случае подвесить на несколько часов локальную машину, в худшем – выбить сервер. В любом случае, нельзя организовывать выборки большого размера, не убедившись предварительно, что СУБД (именно СУБД, а не протоколы типа ODBC или BDE) «умеет» работать с не-FORWARD_ONLYкурсорами. l
 та")
У пользователя нет никакого способа узнать, в каком «месте» находится в таблице (отношении) та или иная запись (кортеж). В частности, при работе функции SQLSet. Pos(. . . ) в готовую выборку можно производить добавление новых записей, при этом стандарт протокола ODBC специально подчеркивает, что нет способа узнать, в каком месте выборки эта запись окажется. Несмотря на то, что таких средств нет, большинство разработчиков драйверов ODBC для своих СУБД, руководствуясь здравым смыслом, помещает эту запись в конец выборки. Единственное исключение из этого правила, СУБД Paradox фирмы Borland. . . l

В силу этого некоторые программные средства добавляют новые записи в таблицы БД весьма экзотическим образом – к примеру, записывая в таблицу запись со всеми пустыми полями, а затем организуя ее поиск и выборку. Именно таким образом, в частности, было организовано добавление записей в ранних версиях BDE. Мало того – предусмотрительные разработчики от Borland специально проверяли, чтобы такая запись в БД была ровно одна – чтобы, не дай Бог, не попортить чужую. Результатом такого решения было, что

ОСНОВНЫЕ ОПЕРАТОРЫ ЯЗЫКА SQL ОБЩИЕ ПОЛОЖЕНИЯ Согласно существующему стандарту в языке SQL насчитывается насколько десятков операторов. Синтаксис их весьма пространен и по «болтливости» напоминает КОБОЛ, но разработчику программ для эффективной работы с базой данных достаточно знать всего 8 операторов языка SQL: l оператор SELECT l оператор INSERT l оператор UPDATE l оператор DELETE l оператор CREATE TABLE l оператор DROP TABLE l оператор CREATE INDEX l оператор DROP INDEX l оператор CREATE VIEW l оператор DROP VIEW

ОПЕРАТОР SELECT l Оператор SELECT является основным и наиболее часто используемым оператором языка SQL. Назначение его простое – выбрать из базы данных запрошенную информацию и передать ее пользователю для работы. Оператор SELECT – один из наиболее сложных операторов языка.
![Синтаксис его описывается следующим образом: SELECT <Список выборки> FROM <Список таблиц> [WHERE <Условие выборки>]](https://present5.com/presentation/220084987_302295621/image-42.jpg "Синтаксис его описывается следующим образом: SELECT <Список выборки> FROM <Список таблиц> [WHERE <Условие выборки>]")
Синтаксис его описывается следующим образом: SELECT <Список выборки> FROM <Список таблиц> [WHERE <Условие выборки>] [GROUP BY <Список группировки> [HAVING <Условие вторичной выборки>]] {UNION [ALL] <Новый SELECT>. . . | INTERSECT <Новый SELECT>. . . | MINUS <Новый SELECT>} [ORDER BY <Список сортировки>]

Как видно из описания, обязательными частями оператора SELECT является только список выборки и опция FROM. l В большинстве диалектов SQL опции должны располагаться именно в том порядке, в котором они здесь описаны. l Список выборки соответствует в реляционной алгебре операции проекции отношения, опция FROM используется для реализации операций прямого произведения и соединения отношений, а опция WHERE – для операции ограничения отношения. l

l Оператор SELECT выполняется как «единая и неделимая» единица. l Порядок выполнения частей SELECT следующий: l Вначале выполняется опция FROM, т. е. строится либо декартово произведение, либо соединение отношений. В частном случае список опции FROM может состоять всего из одной таблицы, при этом никаких операций на первом шаге не делается.
 выполняется опция WHERE (операция ограничения отношения), если она присутствует.")
На полученной результирующей таблице (отношении) выполняется опция WHERE (операция ограничения отношения), если она присутствует. l Сформированная на первом шаге и ограниченная на втором шаге результирующая таблица подвергается обработке опцией GROUP BY (если она присутствует). Поскольку опция GROUP BY накладывает определенные ограничения на список выборки, можно утверждать, что при ее наличии выполняется и операция проекции l
 повторно ограничивается опцией")
l Полученная на четвертом шаге итоговая таблица (если четвертый шаг был) повторно ограничивается опцией HAVING (если она присутствует). Опция HAVING без GROUP BY не употребляется. Ее роль в отношении итоговой таблицы в точности такая же, как и опции WHERE в отношении исходных таблиц.
 с полученной на первых шагах")
l Выполняется она из теоретикомножественных операций (UNION, INTERSECT, MINUS) с полученной на первых шагах таблицей и новыми таблицами (если она присутствует). То, что в описании названо <Новый SELECT>, представляет собой в точности новый оператор выборки, из которого просто выброшено ключевое слово SELECT.
.")
Полученная на предыдущих этапах таблица сортируется с помощью опции ORDER BY (если она присутствует). Опция ORDER BY при наличии теоретикомножественных операций может присутствовать только в единственном экземпляре – в самом конце оператора SELECT. Аналога этой операции в реляционной алгебре нет, но смысл ее представляется очевидным. Следует отметить, что опция GROUP BY в силу принципа своей работы тоже фактически выполняет сортировку итоговой таблицы, но применение опции ORDER BY в любом случае приведет к упорядочению таблицы именно так, как указано в ней, независимо l

В реальности план намного более сложен и детален, поскольку порядок выполнения тех или иных операций, а также специальные возможности базы данных (например, наличие индексов) самым существенным образом на него влияют. l Для оптимизации работы сама СУБД при построении плана выполнения запроса может распараллеливать отдельные части оператора SELECT, может изменять порядок тех или иных действий, но в любом случае итог работы оператора SELECT будет именно такой, как если бы он выполнялся на сервере базы данных именно в том порядке, который мы рассмотрели. l
")
l Изучения плана выполнения запроса (практически все серьезные СУБД имеют для этого соответствующие средства) позволяет определить «узкие места» в системе, особенно при работе с большими и сверхбольшими объемами данных, и, как следствие, значительно ускорить работу программ пользователя.

Опция FROM оператора SELECT l Опция FROM оператора SELECT наиболее проста, но в различных диалектах SQL она существует в одном из двух вариантов (иногда допустимы оба): l. . . FROM {<Таблица> [AS <Алиас>] | (SELECT. . . ) AS <Алиас>}, . . . Первый вариант – просто перечисленный через запятую список используемых таблиц (в частном случае – одна таблица).
![. . . FROM {<Таблица> [AS <Алиас>] | (SELECT. . . ) AS <Алиас>}](https://present5.com/presentation/220084987_302295621/image-52.jpg ". . . FROM {<Таблица> [AS <Алиас>] | (SELECT. . . ) AS <Алиас>}")
. . . FROM {<Таблица> [AS <Алиас>] | (SELECT. . . ) AS <Алиас>} [{INNER|LEFT|RIGHT} JOIN <Другая таблица>. . . [ON <Условие соединения>]] l Особенность опции FROM оператора SELECT – возможность указания в ней не только имен постоянно существующих в базе данных таблиц, но и имен только что созданных выборок – ведь данные, полученные из БД с помощью оператора SELECT, представляют собой ни что иное, как таблицу! Таким образом, в опции FROM возможно применение вложенных операторов SELECT. Такие операторы SELECT, вложенные в основной оператор SELECT, носят название подзапросов.

SELECT FIOS. FAMILIYA, FIOS. IMYA, FIOS. OTCHESTVO FROM (SELECT FAM AS FAMILIYA, NAM AS IMYA, OTCH AS OTCHESTVO FROM FIO_ORG) AS FIOS l поскольку таблица, полученная с помощью оператора SELECT, не имеет имени, сразу за закрывающей круглой скобкой появляется конструкция AS <Имя> (в данном примере – AS FIOS). Это – пример применения операции переименования (только в данном случае не атрибутов, а отношений). Теперь, на время выполнения оператора SELECT, таблица, созданная внутренним оператором SELECT, получает имя FIOS, поле FAM из этой таблицы получает имя FAMILIA и т. д. Именно под этими именами эта таблица и эти поля будут известна во внешнем операторе SELECT.

l Стандарт SQL позволяет не указывать ключевое слово AS, т. е. конструкция SELECT FAM AS FAMILIYA и SELECT FAMILIYA с точки зрения синтаксиса языка равноценны, но не следует привыкать к такому стилю программирования. l Если для внутреннего оператора SELECT мы бы не указали ключевых слов AS, то таблица FIOS имела бы поля FAM, NAM и OTCH. Для всех вложенных подзапросов обязательно следует задавать имена будущих полей в явном виде, не надеясь на

l Опция FROM, в которой употреблена конструкция INNER JOIN без опции ON, полностью эквивалентна перечислению таблиц через запятую. l В большинстве диалектов SQL, поддерживающих обе конструкции, и та, и другая форма записи являются взаимозаменяемыми. В том случае, когда в конструкции INNER JOIN присутствует опция ON, операция произведения отношений превращается в операцию соединения отношений.

l Пример: SELECT. . . FROM SHAPKA_SCHETA INNER JOIN STROKA_SCHETA. . . В этом случае в результирующей выборке будет находиться шапка счета № 1 в комбинации со всеми строками счета № 1, шапка счета № 1 в комбинации[ со всеми строками счета № 2 (явный бред!), шапка счета № 2 в комбинации со всеми строками счета № 1 (тоже явный бред!), шапка счета № 2 в комбинации со строками счета № 2 (нормальные данные) и т. д.

Другой пример: SELECT. . . FROM SHAPKA_SCHETA INNER JOIN STROKA_SCHETA ON SHAPKA_SCHETA. NOMER_SCHETA=STROKA_SCHE TA. NOMER_SCHETA AND SHAPKA_SCHETA. DATA_SCHETA=STROKA_SCHETA. DATA_SCHETA. . . l В этом случае в результирующую выборку попадет шапка счета № 1 со всеми строками счета № 1 (потому что у них одни и те же номера и даты выписки счетов – условие стыковки двух таблиц), шапка счета № 2 со всеми строками счета № 2 (у них тоже одинаковые номера) и т. д. l В этом основное отличие операций произведения и соединения отношения – первая порождает всевозможные комбинации записей таблиц (в том числе заведомо бессмысленные), вторая – строго определенные. l

l Конструкция INNER JOIN носит название внутреннего произведения. Кроме внутреннего, существует и т. н. внешнее произведение, для описания которого используются конструкции LEFT JOIN (вариант LEFT OUTER JOIN) и RIGHT JOIN (вариант RIGHT OUTERT JOIN).

Список выборки оператора SELECT, согласно реляционной алгебре, задает проекцию отношения. На самом деле список выборки представляет собой список параметров (в качестве которых используются арифметические или строковые выражения), разделенный запятыми: SELECT {ALL|DISTINCT|<пусто>}<Выражение> [AS <Алиас>], . . . FROM. . . l

В качестве арифметических выражений можно использовать все, что обычно используется в таких случаях: l константы числовые и символьные (символьные константы в большинстве диалектов SQL ограничиваются апострофами, а не кавычками) l имена полей (возможно, квалифицированные, т. е. <Имя таблицы>. <Имя поля>) Поскольку рабочее пространство базы данных делится на схемы данных, которые в свою очередь содержат таблицы, которые содержат поля. Т. е. в качестве имени Вам вполне может встретиться конструкция My. Schema. My. Table. My. Field@Foreign. Server.
 l знаки")
l знаки арифметических операций: +, -, *, /, % (остаток от деления) l знаки конкатенации символьных строк || (только в некоторых диалектах SQL) l функции, записанные по общепринятым правилам: <Имя функции>(<Параметры>, . . . ) l круглые скобки для изменения порядка вычисления операций l а также все, что можно образовать из всего ранее перечисленного.

ОПЦИЯ WHERE ОПЕРАТОРА SELECT Основное назначение опции WHERE оператора SELECT – ограничение отношения. Опция WHERE представляет собой логическое выражение, которое поочередно проверяется для каждой записи (кортежа) таблицы (отношения). Если результат проверки истинен, запись (кортеж) оставляется в отношении, в противном случае – исключается из отношения. Так же, как при операции MINUS, исключение записи (кортежа) из таблицы (отношения) не следует понимать так, что она будет откуда-то «удалена» . l

Логическое выражение в опции WHERE может содержать: l любые операции сравнения (они будут описаны позже) l знаки логических операций l круглые скобки для изменения порядка вычисления выражения

В качестве знаков логических операций используются традиционные операции булевой алгебры, а именно: l операция AND, или «логическое И» , истинная только если оба ее операнда истинны; l операция OR, или «логическое ИЛИ» , истинная, если любой из ее операндов истинен; l операция NOT, или «логическое НЕ» , изменяющая истинность операнда на противоположную.

В качестве операций сравнения в опции WHERE могут быть использованы следующие конструкции: l традиционные операции сравнения (проверка на больше/меньше/равно) l операции проверки на попадание в диапазон l операции проверки на значение из списка l операции проверки на значения типа NULL l операции проверки на соответствие заданному шаблону Традиционные операции сравнения представлены в языке SQL операциями (>), (>=), (<=), (<>).

Спасибо за внимание