

Vvedenie.2008.09.14.ppt
- Количество слайдов: 38
 Основы параллельного программирования Посыпкин Михаил Анатольевич
Основы параллельного программирования Посыпкин Михаил Анатольевич
 Параллельное программирование n n n Приложения требуют увеличения производительности компьютеров. Производительность процессора и памяти ограничена физическими характеристиками применяемых материалов. Многие задачи содержат независимые компоненты, которые могут решаться одновременно (т. е. параллельно).
Параллельное программирование n n n Приложения требуют увеличения производительности компьютеров. Производительность процессора и памяти ограничена физическими характеристиками применяемых материалов. Многие задачи содержат независимые компоненты, которые могут решаться одновременно (т. е. параллельно).
 Параллельное программирование Перечисленное приводит к естественному решению – увеличивать число компонент оборудования, участвующего в решении задач. В частности, увеличивается число функциональных устройств одного процессора и общее число процессоров.
Параллельное программирование Перечисленное приводит к естественному решению – увеличивать число компонент оборудования, участвующего в решении задач. В частности, увеличивается число функциональных устройств одного процессора и общее число процессоров.
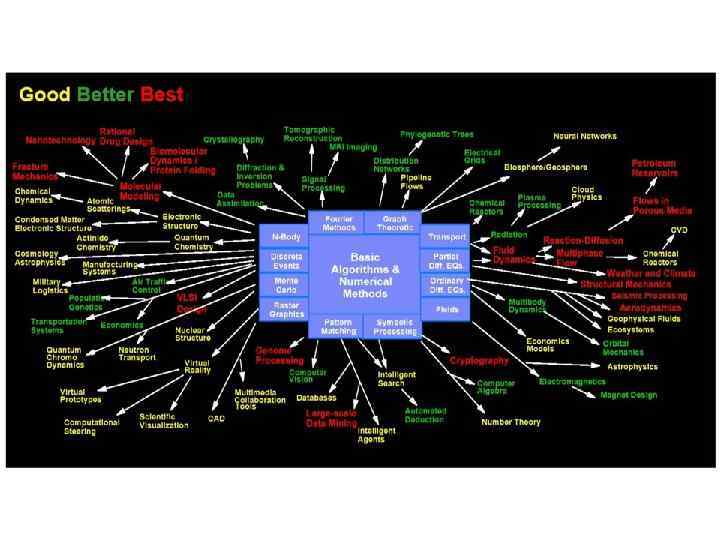
 Спектр задач параллельного программирования n Математическое моделирование: n n n Оптимизация: n n n Газовая и гидро-динамика. Химическая физика. Процессы в полупроводниках. Имитационное моделирование в экономике. Биология. Дискретное и линейное программирование. Общая задача нахождения экстремума. Оптимальный поиск: n n n Дискретная оптимизация. Распознавание образов. Автоматическая верификация и доказательство теорем.
Спектр задач параллельного программирования n Математическое моделирование: n n n Оптимизация: n n n Газовая и гидро-динамика. Химическая физика. Процессы в полупроводниках. Имитационное моделирование в экономике. Биология. Дискретное и линейное программирование. Общая задача нахождения экстремума. Оптимальный поиск: n n n Дискретная оптимизация. Распознавание образов. Автоматическая верификация и доказательство теорем.
 n n n Различные функциональные устройства. Конвейерная обработка. Векторные сопроцессоры.") Параллелизм внутри процессора (ядра) n n n Различные функциональные устройства. Конвейерная обработка. Векторные сопроцессоры.
Параллелизм внутри процессора (ядра) n n n Различные функциональные устройства. Конвейерная обработка. Векторные сопроцессоры.
 процессоров, взаимодействующих между собой.") Многопроцессорный параллелизм В решении задачи принимает участие несколько (более одного) процессоров, взаимодействующих между собой. CPU CPU
Многопроцессорный параллелизм В решении задачи принимает участие несколько (более одного) процессоров, взаимодействующих между собой. CPU CPU
 Виды многопроцессорного параллелизма. Общая память Распределенная память
Виды многопроцессорного параллелизма. Общая память Распределенная память
-го уровня Оперативная память Дисковая память") Иерархия памяти Регистры Кэш 1 -го уровня Кэш 2(3)-го уровня Оперативная память Дисковая память
Иерархия памяти Регистры Кэш 1 -го уровня Кэш 2(3)-го уровня Оперативная память Дисковая память
 Аппаратные ресурсы МСЦ n Общая память: n n n HP V-Class HP Superdome Гибридная память: n n n MVS-1000 M (768 x Alpha 21264) MVS 15000 BM (768 x IBM Power 970) кластеры Athlon, Xeon, IBM
Аппаратные ресурсы МСЦ n Общая память: n n n HP V-Class HP Superdome Гибридная память: n n n MVS-1000 M (768 x Alpha 21264) MVS 15000 BM (768 x IBM Power 970) кластеры Athlon, Xeon, IBM
 Архитектура HP-Superdome
Архитектура HP-Superdome
 Архитектура HP-Superdome: общая орагнизация: cc. Numa ячейка коммутатор ячейка коммутатор ячейка ячейка
Архитектура HP-Superdome: общая орагнизация: cc. Numa ячейка коммутатор ячейка коммутатор ячейка ячейка
 Архитектура HP-Superdome: Ячейка – SMP система I/O CPU Коммутатор Memory CPU Контроллер CPU
Архитектура HP-Superdome: Ячейка – SMP система I/O CPU Коммутатор Memory CPU Контроллер CPU

 Характеристики Mare. Nostrum n n n Пиковая производительность: 94, 21 TFlops 10240 Power. PC processors Оперативная память: 20 Tb Дисковая память: 480 Tb Коммуникации n n Myrinet (вычисления) Gigabit Ethernet (загрузка, управление)
Характеристики Mare. Nostrum n n n Пиковая производительность: 94, 21 TFlops 10240 Power. PC processors Оперативная память: 20 Tb Дисковая память: 480 Tb Коммуникации n n Myrinet (вычисления) Gigabit Ethernet (загрузка, управление)
 Архитектура Blade Center Blade Server 29 x IBM Rack JS 320
Архитектура Blade Center Blade Server 29 x IBM Rack JS 320
 Многоядерные процессоры Intel
Многоядерные процессоры Intel
 Есть возможность динамического переупорядочивания инструкций (REORDER BUFFER) с целью максимальной загрузки") Одно ядро (Pentium-M) Есть возможность динамического переупорядочивания инструкций (REORDER BUFFER) с целью максимальной загрузки функциональных устройств
Одно ядро (Pentium-M) Есть возможность динамического переупорядочивания инструкций (REORDER BUFFER) с целью максимальной загрузки функциональных устройств
 Процессор Woodcrest Общий L 2 -кэш, TLB и L 1 -кэш индивидуальн ый для каждого CPU
Процессор Woodcrest Общий L 2 -кэш, TLB и L 1 -кэш индивидуальн ый для каждого CPU
 Два двухядерных модуля Woodcrest L 1 и L 2") Intel Clovertown (серия Xeon 5300) Два двухядерных модуля Woodcrest L 1 и L 2 кэши разные
Intel Clovertown (серия Xeon 5300) Два двухядерных модуля Woodcrest L 1 и L 2 кэши разные
 Библиотеки общего назначения Проблемноориентирован ные библиотеки Традиционны е языки программиро вания Специальные расширения языков Внутрипроцес сорный параллелизм -+ + + +- Многопроцесс орный параллелизм + +- - +-
Библиотеки общего назначения Проблемноориентирован ные библиотеки Традиционны е языки программиро вания Специальные расширения языков Внутрипроцес сорный параллелизм -+ + + +- Многопроцесс орный параллелизм + +- - +-
 Средства параллельного программирования Общая память Распределенная память Системные средства Языки threads C/C++, Fortran 95 Специальные Open. MP библиотеки и пакеты процессы + сокеты HPF, DVM, mp. C, Charm ++, Occam MPI PVM
Средства параллельного программирования Общая память Распределенная память Системные средства Языки threads C/C++, Fortran 95 Специальные Open. MP библиотеки и пакеты процессы + сокеты HPF, DVM, mp. C, Charm ++, Occam MPI PVM
 ОСНОВНЫЕ ХАРАКТЕРИСТИКИ ПРОИЗВОДИТЕЛЬНОСТИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ
ОСНОВНЫЕ ХАРАКТЕРИСТИКИ ПРОИЗВОДИТЕЛЬНОСТИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ
 -время параллельных вычислений -время последовательны вычислений") Ускорение (наблюдаемое) -время параллельных вычислений -время последовательны вычислений
Ускорение (наблюдаемое) -время параллельных вычислений -время последовательны вычислений
 Производительность пиковая и реальная Пиковая производительность – максимальное количество операций, которые вычислительное устройство может выполнить за единицу времени. Реальная производительность – количество операций, которое вычислительное устройство реально выполняет. Загруженность = (реальная производительность)/(пиковая производительность)
Производительность пиковая и реальная Пиковая производительность – максимальное количество операций, которые вычислительное устройство может выполнить за единицу времени. Реальная производительность – количество операций, которое вычислительное устройство реально выполняет. Загруженность = (реальная производительность)/(пиковая производительность)
 Линейное и «сверхлинейное» ускорение Линейное ускорение: S = n. Эффект «сверхлинейного» ускорения: наблюдаемое ускорение больше числа процессоров: S > n. Причина – не учитывается загруженность процессоров, либо изменение количества операций.
Линейное и «сверхлинейное» ускорение Линейное ускорение: S = n. Эффект «сверхлинейного» ускорения: наблюдаемое ускорение больше числа процессоров: S > n. Причина – не учитывается загруженность процессоров, либо изменение количества операций.
 Закон Амдала -доля последовательных вычислений -общий объем работы
Закон Амдала -доля последовательных вычислений -общий объем работы
 Эффективность – отношение ускорения к числу процессоров. Показывает насколько эффективно используются аппаратные ресурсы.
Эффективность – отношение ускорения к числу процессоров. Показывает насколько эффективно используются аппаратные ресурсы.
: кластер из 8 компьютеров Эффективность и ускорение при разном количестве процессоров.") Тест LINPACK (LU-разложение): кластер из 8 компьютеров Эффективность и ускорение при разном количестве процессоров. (информация с сайта Кемеровского ГУ)
Тест LINPACK (LU-разложение): кластер из 8 компьютеров Эффективность и ускорение при разном количестве процессоров. (информация с сайта Кемеровского ГУ)
 Информационные зависимости Зависимость по данным: 1: a = 1; 2: b = a; 1 2 Зависимость по управлению: 1 1: 2: 3: 4: 2 if(a) { x = c + d; y = 1; } 3
Информационные зависимости Зависимость по данным: 1: a = 1; 2: b = a; 1 2 Зависимость по управлению: 1 1: 2: 3: 4: 2 if(a) { x = c + d; y = 1; } 3
 Граф зависимостей Операции, соединенные путем из дуг, не могут выполняться одновременно. 0 1 2 3 4 5 Другие операции могут выполняться одновременно при наличии требуемых функциональн ых устройств.
Граф зависимостей Операции, соединенные путем из дуг, не могут выполняться одновременно. 0 1 2 3 4 5 Другие операции могут выполняться одновременно при наличии требуемых функциональн ых устройств.
 Концепция неограниченного параллелизма CPU CPU . . . Количество процессоров неограниченно. Концепция может применяться для исследования максимально возможного ускорения.
Концепция неограниченного параллелизма CPU CPU . . . Количество процессоров неограниченно. Концепция может применяться для исследования максимально возможного ускорения.
 Упрощенная модель параллельной машины с общей памятью CPU MEMORY CPU Процессоры работают синхронно по шагам: на каждом шаге выполняется операция (выборка операндов + арифметичекая операция + запись в память). Шаг занимает 1 такт.
Упрощенная модель параллельной машины с общей памятью CPU MEMORY CPU Процессоры работают синхронно по шагам: на каждом шаге выполняется операция (выборка операндов + арифметичекая операция + запись в память). Шаг занимает 1 такт.
 Лемма Брента Пусть q – число операций алгоритма, выполнение каждой операции занимает в точности одну единицу времени (такт), t – время выполнения на системе с достаточным числом одинаковых процессоров, то на системе, содержащей n процессоров, алгоритм может быть выполнен за время, не превосходящее t + (q – t)/n.
Лемма Брента Пусть q – число операций алгоритма, выполнение каждой операции занимает в точности одну единицу времени (такт), t – время выполнения на системе с достаточным числом одинаковых процессоров, то на системе, содержащей n процессоров, алгоритм может быть выполнен за время, не превосходящее t + (q – t)/n.
 Асимптотические свойства формулы Брента
Асимптотические свойства формулы Брента
 Количество CPU не ограничено CPU II 1 1 2 2 3 4
Количество CPU не ограничено CPU II 1 1 2 2 3 4
 Пусть для бесконечного числа процессоров на i-м шаге выполнялось si операций, тогда при наличии n процессоров потребуется не более операций.
Пусть для бесконечного числа процессоров на i-м шаге выполнялось si операций, тогда при наличии n процессоров потребуется не более операций.