

dd8f624ae2a9ab9cc2f3cce1a84b6d7e.ppt
- Количество слайдов: 31
 Оптимизации для параллельных вычислений Ануфриенко Андрей Идрисов Ренат
Оптимизации для параллельных вычислений Ануфриенко Андрей Идрисов Ренат
 Тенденция в развитии микропроцессоров: Последовательное выполнение инструкций Параллельное выполнение инструкций • Конвейеризация • Суперскалярность • Векторные операции • Многоядерные и многопроцесорные решения Оптимизирующий компилятор – инструмент, транслирующий исходный код программы в исполняемый модуль, а так же инструмент, оптимизирующий исходный код для получения лучшей производительности. Распараллеливание – трансформация последовательно исполняемой программы в программу, в которой наборы инструкций выполняются одновременно и сохраняется результат работы.
Тенденция в развитии микропроцессоров: Последовательное выполнение инструкций Параллельное выполнение инструкций • Конвейеризация • Суперскалярность • Векторные операции • Многоядерные и многопроцесорные решения Оптимизирующий компилятор – инструмент, транслирующий исходный код программы в исполняемый модуль, а так же инструмент, оптимизирующий исходный код для получения лучшей производительности. Распараллеливание – трансформация последовательно исполняемой программы в программу, в которой наборы инструкций выполняются одновременно и сохраняется результат работы.
![Одна из технологий распараллеливания программы – векторизация циклов C[1] C[2] C[3] C[4] = =](https://present5.com/presentation/dd8f624ae2a9ab9cc2f3cce1a84b6d7e/image-3.jpg "Одна из технологий распараллеливания программы – векторизация циклов C[1] C[2] C[3] C[4] = =") Одна из технологий распараллеливания программы – векторизация циклов C[1] C[2] C[3] C[4] = = A[1] A[2] A[3] A[4] A[1]+B[1] A[2]+B[2] A[3]+B[3] A[4]+B[4] Векторизация A[1] A[2] A[3] A[4] + B[1] B[2] B[3] B[4] = C[1] C[2] C[3] C[4] B[1] B[2] B[3] B[4]
Одна из технологий распараллеливания программы – векторизация циклов C[1] C[2] C[3] C[4] = = A[1] A[2] A[3] A[4] A[1]+B[1] A[2]+B[2] A[3]+B[3] A[4]+B[4] Векторизация A[1] A[2] A[3] A[4] + B[1] B[2] B[3] B[4] = C[1] C[2] C[3] C[4] B[1] B[2] B[3] B[4]
 Типичная векторная инструкция представляет собой операцию над двумя векторами в памяти или в регистрах фиксированной длины. Векторные регистры могут быть загружены из памяти за одну операцию или по частям. Векторизация - это компиляторная оптимизация, которая заменяет скалярный код на векторный. Эта оптимизация «упаковывает» данные в вектора и заменяет скалярные операции на операции с такими векторами (пакетами). A(1: n: k) – секция массива в Фортране. for(i=0; i
Типичная векторная инструкция представляет собой операцию над двумя векторами в памяти или в регистрах фиксированной длины. Векторные регистры могут быть загружены из памяти за одну операцию или по частям. Векторизация - это компиляторная оптимизация, которая заменяет скалярный код на векторный. Эта оптимизация «упаковывает» данные в вектора и заменяет скалярные операции на операции с такими векторами (пакетами). A(1: n: k) – секция массива в Фортране. for(i=0; i
 –") MMX, SSE Векторные инструкции и векторизация Первоначально была предложена технология MMX (Multimedia Extensions) – набор инструкций, выполняющих характерные для процессов кодирования/декодирования потоковых аудио/видео данных действия. MMM 0 -MMM 7 64 битные регистры для работы с целыми числами концепция пакетов, каждый из этих регистров мог хранить 2 – 32 битных целых числа 4 - 16 битных 8 - 8 битных 47 инструкций, которые деляться на несколько груп: перемещение данных арифметические сравнения конвертации логические распаковки сдвига пустые инструкции получения состояния
MMX, SSE Векторные инструкции и векторизация Первоначально была предложена технология MMX (Multimedia Extensions) – набор инструкций, выполняющих характерные для процессов кодирования/декодирования потоковых аудио/видео данных действия. MMM 0 -MMM 7 64 битные регистры для работы с целыми числами концепция пакетов, каждый из этих регистров мог хранить 2 – 32 битных целых числа 4 - 16 битных 8 - 8 битных 47 инструкций, которые деляться на несколько груп: перемещение данных арифметические сравнения конвертации логические распаковки сдвига пустые инструкции получения состояния
 это набор инструкций, позволяющий работать с множеством") SSE (Streaming SIMD Extensions, потоковое SIMDрасширение процессора) это набор инструкций, позволяющий работать с множеством данных – SIMD(Single Instruction, Multiple Data, Одна инструкция — множество данных). • • поддерживает 8 128 -битных регистров (xmm 0 до xmm 7) производит операции со скалярными и упакованными типами данны набор инструкций, который х. Технология EMM 64 T добавляла к этому набору еще 8 128 битных регистра (xmm 8 до xmm 15). SSE 2, SSE 3, SSE 4 – последующие расширения этой идеи. SSE 2 добавил тип упакованных данных с плавающей точкой двойной точности. AVX новое расширение системы команд (Advanced vector extensions) AVX предоставляет различные улучшения, новые инструкции и новую схему кодирования машинных кодов. Размер векторных регистров SIMD увеличивается с 128 до 256 бит. Регистры YMM 0 -YMM 15 Существующие 128 -битные инструкции используют младшую половину YMM регистров.
SSE (Streaming SIMD Extensions, потоковое SIMDрасширение процессора) это набор инструкций, позволяющий работать с множеством данных – SIMD(Single Instruction, Multiple Data, Одна инструкция — множество данных). • • поддерживает 8 128 -битных регистров (xmm 0 до xmm 7) производит операции со скалярными и упакованными типами данны набор инструкций, который х. Технология EMM 64 T добавляла к этому набору еще 8 128 битных регистра (xmm 8 до xmm 15). SSE 2, SSE 3, SSE 4 – последующие расширения этой идеи. SSE 2 добавил тип упакованных данных с плавающей точкой двойной точности. AVX новое расширение системы команд (Advanced vector extensions) AVX предоставляет различные улучшения, новые инструкции и новую схему кодирования машинных кодов. Размер векторных регистров SIMD увеличивается с 128 до 256 бит. Регистры YMM 0 -YMM 15 Существующие 128 -битные инструкции используют младшую половину YMM регистров.
 Данные различных типов могут быть упакованы в векторные регистры следующим образом: Упакованный тип данных signed bytes unsigned bytes signed words unsigned words signed doublewords unsigned doublewords signed quadwords unsigned quadwords single-precision fps double-precision fps Длина вектора 16 16 8 8 4 4 2 2 4 2 Число битов на элемент 8 8 16 16 32 32 64 64 32 64 Область значений типа -2**7 до 2**7 -1 0 до 2**8 -1 -2**15 до 2**15 -1 0 до 2**16 -2**31 до 2**31 -1 0 до 2**32 -1 -2**63 до 2*63 -1 0 до 2**64 -1 2**-126 до 2**127 2**-1022 до 2**1023 Выбор подходящего для вычислений типа данных может существенно сказаться на производительности приложения.
Данные различных типов могут быть упакованы в векторные регистры следующим образом: Упакованный тип данных signed bytes unsigned bytes signed words unsigned words signed doublewords unsigned doublewords signed quadwords unsigned quadwords single-precision fps double-precision fps Длина вектора 16 16 8 8 4 4 2 2 4 2 Число битов на элемент 8 8 16 16 32 32 64 64 32 64 Область значений типа -2**7 до 2**7 -1 0 до 2**8 -1 -2**15 до 2**15 -1 0 до 2**16 -2**31 до 2**31 -1 0 до 2**32 -1 -2**63 до 2*63 -1 0 до 2**64 -1 2**-126 до 2**127 2**-1022 до 2**1023 Выбор подходящего для вычислений типа данных может существенно сказаться на производительности приложения.
 Optimization with Switches SIMD – SSE, SSE 2, SSE 3, SSE 4. 2 Support 2 x doubles 4 x floats 1 x dqword SSE 4. 2 SSE 3 SSE 2 16 x bytes SSE 8 x words MMX* 4 x dwords 2 x qwords * MMX actually used the x 87 Floating Point Registers - SSE, SSE 2, and SSE 3 use the new SSE registers 8
Optimization with Switches SIMD – SSE, SSE 2, SSE 3, SSE 4. 2 Support 2 x doubles 4 x floats 1 x dqword SSE 4. 2 SSE 3 SSE 2 16 x bytes SSE 8 x words MMX* 4 x dwords 2 x qwords * MMX actually used the x 87 Floating Point Registers - SSE, SSE 2, and SSE 3 use the new SSE registers 8
 Три набора опций для использования процессорноспецифических расширений 1. Опции –Qx
Три набора опций для использования процессорноспецифических расширений 1. Опции –Qx
 Допустимость векторизации Векторизация – перестановочная оптимизация. Операции меняют порядок выполнения. Перестановочные оптимизации допустимы, если не изменяется порядок зависимостей. Таким образом мы получили критерий допустимости векторизации в терминах зависимостей. Простейший вариант – зависимостей в векторизуемом цикле нет. Зависимости в векторизуемом цикле есть, но их порядок после векторизации совпадает с порядком в невекторизованном цикле.
Допустимость векторизации Векторизация – перестановочная оптимизация. Операции меняют порядок выполнения. Перестановочные оптимизации допустимы, если не изменяется порядок зависимостей. Таким образом мы получили критерий допустимости векторизации в терминах зависимостей. Простейший вариант – зависимостей в векторизуемом цикле нет. Зависимости в векторизуемом цикле есть, но их порядок после векторизации совпадает с порядком в невекторизованном цикле.
![/Qvec-report[n] control amount of vectorizer diagnostic information n=0 no diagnostic information n=1 indicate vectorized](https://present5.com/presentation/dd8f624ae2a9ab9cc2f3cce1a84b6d7e/image-11.jpg "/Qvec-report[n] control amount of vectorizer diagnostic information n=0 no diagnostic information n=1 indicate vectorized") /Qvec-report[n] control amount of vectorizer diagnostic information n=0 no diagnostic information n=1 indicate vectorized loops (DEFAULT) n=2 indicate vectorized/non-vectorized loops n=3 indicate vectorized/non-vectorized loops and prohibiting data dependence information n=4 indicate non-vectorized loops n=5 indicate non-vectorized loops and prohibiting data dependence information Использование: icl -c -Qvec_report 3 loop. c Примеры диагностики: C: loopsloop 1. c(5) (col. 1): remark: LOOP WAS VECTORIZED. C: loopsloop 3. c(5) (col. 1): remark: loop was not vectorized: vectorization possible but seems inefficient. C: loopsloop 6. c(5) (col. 1): remark: loop was not vectorized: nonstandard loop is not a vectorization candidate. 10/17/10
/Qvec-report[n] control amount of vectorizer diagnostic information n=0 no diagnostic information n=1 indicate vectorized loops (DEFAULT) n=2 indicate vectorized/non-vectorized loops n=3 indicate vectorized/non-vectorized loops and prohibiting data dependence information n=4 indicate non-vectorized loops n=5 indicate non-vectorized loops and prohibiting data dependence information Использование: icl -c -Qvec_report 3 loop. c Примеры диагностики: C: loopsloop 1. c(5) (col. 1): remark: LOOP WAS VECTORIZED. C: loopsloop 3. c(5) (col. 1): remark: loop was not vectorized: vectorization possible but seems inefficient. C: loopsloop 6. c(5) (col. 1): remark: loop was not vectorized: nonstandard loop is not a vectorization candidate. 10/17/10
 Фортран активно используется в описании векторизации, поскольку имеет удобное понятие секции массива. В упрощенном виде: DO I=1, N A(I)=… END DO при векторизации переводится в DO I=1, N/K A(I: I+K)=… END DO где K – число элементов матрицы A размещаемых в векторном регистре. Наглядным критерием возможности векторизации является то факт, что введение секций массива не порождает зависимостей. DO I=1, N/K A(I)=A(I)+C => A(I: I+K) = A(I: I+K)+C END DO Может быть векторизован. DO I=1, N/K A(I+1)=A(I)+C => A(I+1: I+1+K)=A(I: I+K)+C END DO Не может быть векторизован.
Фортран активно используется в описании векторизации, поскольку имеет удобное понятие секции массива. В упрощенном виде: DO I=1, N A(I)=… END DO при векторизации переводится в DO I=1, N/K A(I: I+K)=… END DO где K – число элементов матрицы A размещаемых в векторном регистре. Наглядным критерием возможности векторизации является то факт, что введение секций массива не порождает зависимостей. DO I=1, N/K A(I)=A(I)+C => A(I: I+K) = A(I: I+K)+C END DO Может быть векторизован. DO I=1, N/K A(I+1)=A(I)+C => A(I+1: I+1+K)=A(I: I+K)+C END DO Не может быть векторизован.
 PROGRAM TEST_VEC INTEGER, PARAMETER : : N=1000 #ifdef PERF INTEGER, PARAMETER : : P=4 #else INTEGER, PARAMETER : : P=3 #endif INTEGER A(N) DO I=1, N-P A(I+P)=A(I) END DO PRINT *, A(50) END Предположение: Цикл можно векторизовать, если дистанция для зависимости >= K, где K – количество элементов массива, входящих в векторный регистр. Проверяем утверждение с помощью компилятора: ifort test. F 90 -o a. out –vec_report 3 echo ------------------ifort test. F 90 -DPERF -o b. out –vec_report 3. /build. sh test. F 90(11): (col. 1) remark: loop was not vectorized: existence of vector dependence. ------------------test. F 90(11): (col. 1) remark: LOOP WAS VECTORIZED.
PROGRAM TEST_VEC INTEGER, PARAMETER : : N=1000 #ifdef PERF INTEGER, PARAMETER : : P=4 #else INTEGER, PARAMETER : : P=3 #endif INTEGER A(N) DO I=1, N-P A(I+P)=A(I) END DO PRINT *, A(50) END Предположение: Цикл можно векторизовать, если дистанция для зависимости >= K, где K – количество элементов массива, входящих в векторный регистр. Проверяем утверждение с помощью компилятора: ifort test. F 90 -o a. out –vec_report 3 echo ------------------ifort test. F 90 -DPERF -o b. out –vec_report 3. /build. sh test. F 90(11): (col. 1) remark: loop was not vectorized: existence of vector dependence. ------------------test. F 90(11): (col. 1) remark: LOOP WAS VECTORIZED.
 Представил технологию двойного ядра") Многоядерные/многопроцессорные Intel архитектуры Intel® Pentium® Processor Extreme Edition (2005 -2007) Представил технологию двойного ядра (dual core) Intel® Xeon® Processor 5100, 5300 Series Intel® Core™ 2 Processor Family (2006 -) Появились двухпроцессорные архитектуры. Процессоры поддерживают четыре ядра(quad-core) Intel® Xeon® Processor 5200, 5400, 7400 Series Intel® Core™ 2 Processor Family (2007 -) Есть семейства в которых количество ядер на процессоре доведено до 6. 2 -4 процессора. Intel® Atom™ Processor Family (2008 -) Процессор с высокой энергоэффективностью. Intel® Core™i 7 Processor Family (2008 -) Hyperthreading технология. Системы с неоднородным доступом к памяти. 10/17/10
Многоядерные/многопроцессорные Intel архитектуры Intel® Pentium® Processor Extreme Edition (2005 -2007) Представил технологию двойного ядра (dual core) Intel® Xeon® Processor 5100, 5300 Series Intel® Core™ 2 Processor Family (2006 -) Появились двухпроцессорные архитектуры. Процессоры поддерживают четыре ядра(quad-core) Intel® Xeon® Processor 5200, 5400, 7400 Series Intel® Core™ 2 Processor Family (2007 -) Есть семейства в которых количество ядер на процессоре доведено до 6. 2 -4 процессора. Intel® Atom™ Processor Family (2008 -) Процессор с высокой энергоэффективностью. Intel® Core™i 7 Processor Family (2008 -) Hyperthreading технология. Системы с неоднородным доступом к памяти. 10/17/10
 Одной из главных особенностей многоядерной архитектуры является то, что ядра совместно используют часть подсистемы памяти и шину данных 10/17/10
Одной из главных особенностей многоядерной архитектуры является то, что ядра совместно используют часть подсистемы памяти и шину данных 10/17/10
 Классификация многопроцессорных систем по использованию памяти 1. Массивно-параллельные компьютеры или системы с распределенной памятью. (MPP системы). Каждый процессор полностью автономен. Существует некоторая коммуникационная среда. Достоинства: хорошая масштабируемость Недостатки: медленное межпроцедурное взаимодействие 2. Системы с общей памятью (SMP системы) Все процессоры равноудалены от памяти. Связь с памятью осуществляется через общую шину данных. Достоинства: хорошее межпроцессорное взаимодействие Недостатки: плохая масштабируемость большие затраты на синхронизацию подсистем кэшей 3. Системы с неоднородным доступом к памяти (NUMA) Память физически распределена между процессорами. Единое адресное пространство поддерживается на аппаратном уровне. Достоинства: Недостатки: хорошее межпроцессорное взаимодействие и масштабируемость разное время доступа к разным сегментам памяти. 10/17/10
Классификация многопроцессорных систем по использованию памяти 1. Массивно-параллельные компьютеры или системы с распределенной памятью. (MPP системы). Каждый процессор полностью автономен. Существует некоторая коммуникационная среда. Достоинства: хорошая масштабируемость Недостатки: медленное межпроцедурное взаимодействие 2. Системы с общей памятью (SMP системы) Все процессоры равноудалены от памяти. Связь с памятью осуществляется через общую шину данных. Достоинства: хорошее межпроцессорное взаимодействие Недостатки: плохая масштабируемость большие затраты на синхронизацию подсистем кэшей 3. Системы с неоднородным доступом к памяти (NUMA) Память физически распределена между процессорами. Единое адресное пространство поддерживается на аппаратном уровне. Достоинства: Недостатки: хорошее межпроцессорное взаимодействие и масштабируемость разное время доступа к разным сегментам памяти. 10/17/10
 Intel Quick. Path Architecture 10/17/10
Intel Quick. Path Architecture 10/17/10
 Нестабильность работы приложений на многопроцессорных машинах с неоднородным доступом к памяти 10/17/10
Нестабильность работы приложений на многопроцессорных машинах с неоднородным доступом к памяти 10/17/10
 Плюсы и минусы использования многопоточных приложений ++: Вычислительные ресурсы увеличиваются пропорционально колву используемых реальных ядер. --: Усложнение разработки Необходимость синхронизировать потоки Потоки конкурируют за ресурсы Создание потоков имеет свою цену Вывод: В случае разработки бизнес-приложений четко осознавайте цели и цену распараллеливания вашей программы. 10/17/10
Плюсы и минусы использования многопоточных приложений ++: Вычислительные ресурсы увеличиваются пропорционально колву используемых реальных ядер. --: Усложнение разработки Необходимость синхронизировать потоки Потоки конкурируют за ресурсы Создание потоков имеет свою цену Вывод: В случае разработки бизнес-приложений четко осознавайте цели и цену распараллеливания вашей программы. 10/17/10
, использующий несколько ядер") Автоматическое распараллеливание процесс автоматического преобразования последовательного программного кода в многопоточный (multi-threaded), использующий несколько ядер одновременно. Цель автоматического распараллеливания – освободить программистов от тяжелой и нудной ручной работы по разделению вычислений на различные потоки. /Qparallel enable the auto-parallelizer to generate multi-threaded code for loops that can be safely executed in parallel
Автоматическое распараллеливание процесс автоматического преобразования последовательного программного кода в многопоточный (multi-threaded), использующий несколько ядер одновременно. Цель автоматического распараллеливания – освободить программистов от тяжелой и нудной ручной работы по разделению вычислений на различные потоки. /Qparallel enable the auto-parallelizer to generate multi-threaded code for loops that can be safely executed in parallel
, b(1000, 1000), c(1000,") Выгодность автоматического распараллеливания на простом примере REAL : : a(1000, 1000), b(1000, 1000), c(1000, 1000) integer i, j, rep_factor DO I=1, 1000 DO J=1, 1000 A(J, I) = I B(J, I) = I+J C(J, I) = 0 END DO DO rep_factor=1, 1000 C=B/A+rep_factor END DO END 10/17/10
Выгодность автоматического распараллеливания на простом примере REAL : : a(1000, 1000), b(1000, 1000), c(1000, 1000) integer i, j, rep_factor DO I=1, 1000 DO J=1, 1000 A(J, I) = I B(J, I) = I+J C(J, I) = 0 END DO DO rep_factor=1, 1000 C=B/A+rep_factor END DO END 10/17/10
![Хорошо и плохо масштабируемые алгоритмы void matrix_mul_matrix(int n, float C[n][n], float A[n][n], float B[n][n])](https://present5.com/presentation/dd8f624ae2a9ab9cc2f3cce1a84b6d7e/image-23.jpg "Хорошо и плохо масштабируемые алгоритмы void matrix_mul_matrix(int n, float C[n][n], float A[n][n], float B[n][n])") Хорошо и плохо масштабируемые алгоритмы void matrix_mul_matrix(int n, float C[n][n], float A[n][n], float B[n][n]) { int i, j, k; for (i=0; i
Хорошо и плохо масштабируемые алгоритмы void matrix_mul_matrix(int n, float C[n][n], float A[n][n], float B[n][n]) { int i, j, k; for (i=0; i
![Плохо масштабируемые алгоритмы void matrix_add(int n, float Res[n][n], float A 1[n][n], float A 2[n][n],](https://present5.com/presentation/dd8f624ae2a9ab9cc2f3cce1a84b6d7e/image-24.jpg "Плохо масштабируемые алгоритмы void matrix_add(int n, float Res[n][n], float A 1[n][n], float A 2[n][n],") Плохо масштабируемые алгоритмы void matrix_add(int n, float Res[n][n], float A 1[n][n], float A 2[n][n], float A 3[n][n], float A 4[n][n], float A 5[n][n], float A 6[n][n], float A 7[n][n], float A 8[n][n]) { int i, j; for (i=0; i
Плохо масштабируемые алгоритмы void matrix_add(int n, float Res[n][n], float A 1[n][n], float A 2[n][n], float A 3[n][n], float A 4[n][n], float A 5[n][n], float A 6[n][n], float A 7[n][n], float A 8[n][n]) { int i, j; for (i=0; i
 Допустимость автоматического распараллеливания Это преобразование – перестановочная оптимизация циклической конструкции. Упорядоченное выполнение итераций => неопределенный порядок выполнения итераций. Необходимое условие – отсутствие любых зависимостей внутри цикла. /Qpar-report{0|1|2|3} control the auto-parallelizer diagnostic level /Qpar-report 3 сообщает причины по которым компилятор не распараллеливает тот или иной цикл, в том числе сообщает какие зависимости препятствуют этому. 10/17/10
Допустимость автоматического распараллеливания Это преобразование – перестановочная оптимизация циклической конструкции. Упорядоченное выполнение итераций => неопределенный порядок выполнения итераций. Необходимое условие – отсутствие любых зависимостей внутри цикла. /Qpar-report{0|1|2|3} control the auto-parallelizer diagnostic level /Qpar-report 3 сообщает причины по которым компилятор не распараллеливает тот или иной цикл, в том числе сообщает какие зависимости препятствуют этому. 10/17/10
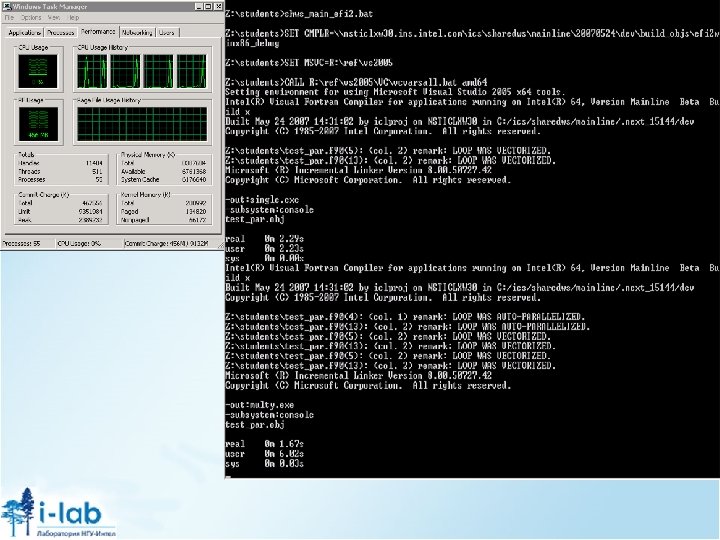
 (col. 1): remark:") Выгодность распараллеливания /Qpar_report 3 информирует, если распараллеливание невыгодно C: test_par. c(27) (col. 1): remark: loop was not parallelized: insufficient computational work. Точное определение выгодности таких преобразований во время компиляции достаточно тяжелая задача. Существуют эффекты производительности, которые сложно оценить, например «эффект первого прикосновения» . В большинстве случаев компилятор может не иметь представления о количестве итераций в цикле. Используйте директивы распараллеливания при экспериментах с производительностью. 10/17/10
Выгодность распараллеливания /Qpar_report 3 информирует, если распараллеливание невыгодно C: test_par. c(27) (col. 1): remark: loop was not parallelized: insufficient computational work. Точное определение выгодности таких преобразований во время компиляции достаточно тяжелая задача. Существуют эффекты производительности, которые сложно оценить, например «эффект первого прикосновения» . В большинстве случаев компилятор может не иметь представления о количестве итераций в цикле. Используйте директивы распараллеливания при экспериментах с производительностью. 10/17/10
 #pragma concurrent – игнорировать предполагаемые зависимости в следующем цикле #pragma concurrent call – вызов функции в следующем цикле безопасен для параллельного выполнения. #pragma concurrentize – параллелизовать следующий цикл #pragma no concurrentize - не параллелизовать следующий цикл #pragma prefer concurrent параллелизовать следующий цикл, если это безопасно #pragma prefer serial – предложить компилятору не параллелизовать следующий цикл #pragma serial – заставить компилятор параллелизовать следующий цикл
#pragma concurrent – игнорировать предполагаемые зависимости в следующем цикле #pragma concurrent call – вызов функции в следующем цикле безопасен для параллельного выполнения. #pragma concurrentize – параллелизовать следующий цикл #pragma no concurrentize - не параллелизовать следующий цикл #pragma prefer concurrent параллелизовать следующий цикл, если это безопасно #pragma prefer serial – предложить компилятору не параллелизовать следующий цикл #pragma serial – заставить компилятор параллелизовать следующий цикл
 – это программный интерфейс, который") Автоматическое распараллеливание осуществляется использованием интерфейса Open. MP (Open Multi-Processing) – это программный интерфейс, который поддерживает многоплатформенное многопроцессорное программирование с общей памятью на C/C++ и Фортране на многих архитектурах. Количество потоков, используемых вашим приложением, может изменяться с помощью установки переменной окружения OMP_NUM_THREADS (по умолчанию будут использоваться все доступные ядра) 8 Threads 16 Threads
Автоматическое распараллеливание осуществляется использованием интерфейса Open. MP (Open Multi-Processing) – это программный интерфейс, который поддерживает многоплатформенное многопроцессорное программирование с общей памятью на C/C++ и Фортране на многих архитектурах. Количество потоков, используемых вашим приложением, может изменяться с помощью установки переменной окружения OMP_NUM_THREADS (по умолчанию будут использоваться все доступные ядра) 8 Threads 16 Threads
![/Qpar-runtime-control[n] Control parallelizer to generate runtime check code for effective automatic parallelization. n=0 no](https://present5.com/presentation/dd8f624ae2a9ab9cc2f3cce1a84b6d7e/image-29.jpg "/Qpar-runtime-control[n] Control parallelizer to generate runtime check code for effective automatic parallelization. n=0 no") /Qpar-runtime-control[n] Control parallelizer to generate runtime check code for effective automatic parallelization. n=0 no runtime check based auto-parallelization n=1 generate runtime check code under conservative mode (DEFAULT when enabled) n=2 generate runtime check code under heuristic mode n=3 generate runtime check code under aggressive mode 10/17/10
/Qpar-runtime-control[n] Control parallelizer to generate runtime check code for effective automatic parallelization. n=0 no runtime check based auto-parallelization n=1 generate runtime check code under conservative mode (DEFAULT when enabled) n=2 generate runtime check code under heuristic mode n=3 generate runtime check code under aggressive mode 10/17/10
 Взаимодействие с другими оптимизациями циклических конструкций • Объединение циклов и создание больших циклов • Автоматическое распараллеливание • Оптимизация цикла в поточной функции в соответствии с обычными соображениями. (развертка, векторизация, разбиение на несколько циклов и т. п. ) Эти соображения можно использовать при написании программы. Стремитесь создавать большие циклы без зависимостей, т. е. такие чтобы итерации могли выполняться в произвольном порядке. 10/17/10
Взаимодействие с другими оптимизациями циклических конструкций • Объединение циклов и создание больших циклов • Автоматическое распараллеливание • Оптимизация цикла в поточной функции в соответствии с обычными соображениями. (развертка, векторизация, разбиение на несколько циклов и т. п. ) Эти соображения можно использовать при написании программы. Стремитесь создавать большие циклы без зависимостей, т. е. такие чтобы итерации могли выполняться в произвольном порядке. 10/17/10
 Спасибо за внимание!
Спасибо за внимание!