ПрИС Лекция 14.ppt
- Количество слайдов: 23
 Операторы PIVOT и UNPIVOT осуществляют переворот значений в столбцы и столбцов в значения. PIVOT переворачивает значения в столбцы. UNPIVOT переворачивает столбцы в значения.
Операторы PIVOT и UNPIVOT осуществляют переворот значений в столбцы и столбцов в значения. PIVOT переворачивает значения в столбцы. UNPIVOT переворачивает столбцы в значения.
 Оператор APPLY позволяет осуществлять в запросе SELECT объединение таблицы с результатом функции, возвращающим таблицу. При этом функция считается для каждой строки объединяемой таблицы. Есть два варианта этого оператора: CROSS APPLY и OUTER APPLY. Их смысл тот же, что и у операторов INNER и OUTER JOIN. Рассмотрим пример. CREATE FUNCTION Sales. Most. Recent. Orders (@Cust. ID AS int) RETURNS TABLE AS RETURN SELECT TOP(3) Sales. Order. ID, Order. Date FROM Sales. Order. Header WHERE Customer. ID = @Cust. ID ORDER BY Order. Date DESC SELECT Name AS Customer, MR. * FROM Sales. Store CROSS APPLY Sales. Most. Recent. Orders(Customer. ID) AS MR Пример 7. Оператор APPLY
Оператор APPLY позволяет осуществлять в запросе SELECT объединение таблицы с результатом функции, возвращающим таблицу. При этом функция считается для каждой строки объединяемой таблицы. Есть два варианта этого оператора: CROSS APPLY и OUTER APPLY. Их смысл тот же, что и у операторов INNER и OUTER JOIN. Рассмотрим пример. CREATE FUNCTION Sales. Most. Recent. Orders (@Cust. ID AS int) RETURNS TABLE AS RETURN SELECT TOP(3) Sales. Order. ID, Order. Date FROM Sales. Order. Header WHERE Customer. ID = @Cust. ID ORDER BY Order. Date DESC SELECT Name AS Customer, MR. * FROM Sales. Store CROSS APPLY Sales. Most. Recent. Orders(Customer. ID) AS MR Пример 7. Оператор APPLY
 Общее табличное выражение (CTE) – это именованный временный") Общие табличные выражения (Common Table Expressions) Общее табличное выражение (CTE) – это именованный временный результат, основанный на запросе SELECT. WITH Top. Sales (Sales. Person. ID, Num. Sales) AS (SELECT Sales. Person. ID, Count(*) FROM Sales. Order. Header GROUP BY Sales. Person. Id) SELECT Login. ID, Num. Sales FROM Human. Resources. Employee e INNER JOIN Top. Sales ON Top. Sales. Person. ID = e. Employee. ID ORDER BY Num. Sales DESC Пример 5. Общее табличное выражение
Общие табличные выражения (Common Table Expressions) Общее табличное выражение (CTE) – это именованный временный результат, основанный на запросе SELECT. WITH Top. Sales (Sales. Person. ID, Num. Sales) AS (SELECT Sales. Person. ID, Count(*) FROM Sales. Order. Header GROUP BY Sales. Person. Id) SELECT Login. ID, Num. Sales FROM Human. Resources. Employee e INNER JOIN Top. Sales ON Top. Sales. Person. ID = e. Employee. ID ORDER BY Num. Sales DESC Пример 5. Общее табличное выражение
 Функция Описание Возвращает ранг каждой строки в пределах группы RANK результирующего") Функции упорядочивания (ranking) Функция Описание Возвращает ранг каждой строки в пределах группы RANK результирующего отношения Возвращает последовательный ранг каждой строки в DENSE_RANK пределах группы результирующего отношения Возвращает порядковый номер для каждой строки в ROW_NUMBER пределах группы результирующего отношения Разделяет строки в каждой группе результата по специальным номерам ранга, основанным на значении NTILE переданного параметра SELECT P. Name Product, P. List. Price, PSC. Name Category, RANK() OVER(PARTITION BY PSC. Name ORDER BY P. List. Price DESC) AS Price. Bank FROM Production. Product P JOIN Production. Product. Sub. Category PSC ON P. Product. Sub. Category. ID=PSC. Product. Sub. Category. ID Пример 8. Функция RANK
Функции упорядочивания (ranking) Функция Описание Возвращает ранг каждой строки в пределах группы RANK результирующего отношения Возвращает последовательный ранг каждой строки в DENSE_RANK пределах группы результирующего отношения Возвращает порядковый номер для каждой строки в ROW_NUMBER пределах группы результирующего отношения Разделяет строки в каждой группе результата по специальным номерам ранга, основанным на значении NTILE переданного параметра SELECT P. Name Product, P. List. Price, PSC. Name Category, RANK() OVER(PARTITION BY PSC. Name ORDER BY P. List. Price DESC) AS Price. Bank FROM Production. Product P JOIN Production. Product. Sub. Category PSC ON P. Product. Sub. Category. ID=PSC. Product. Sub. Category. ID Пример 8. Функция RANK
 Обработка структурированных исключений давно присутствует в большинстве объектно‐ ориентированных") Обработка структурированных исключений (structured exception) Обработка структурированных исключений давно присутствует в большинстве объектно‐ ориентированных языков. Как и в этих языках, в Transact SQL она реализована в виде конструкции TRY…CATCH. Рассмотрим на примере работу с этим блоком и дополнительными средствами обработки ошибок. CREATE TABLE dbo. Data. Table (Col. A int PRIMARY KEY, Col. B int) CREATE TABLE dbo. Error. Log (Col. A int, Col. B int, error int, datetime) GO EXEC dbo. Add. Data 1, 1 CREATE PROCEDURE dbo. Add. Data @a int, @b int EXEC dbo. Add. Data 2, 2 AS EXEC dbo. Add. Data 1, 3 SET XACT_ABORT ON GO BEGIN TRY SELECT * FROM dbo. Error. Log BEGIN TRAN Пример 9. Обработка структурированных исключений INSERT INTO dbo. Data. Table VALUES (@a, @b) COMMIT TRAN END TRY BEGIN CATCH DECLARE @err int SET @err = @@error ROLLBACK TRAN INSERT INTO dbo. Error. Log VALUES (@a, @b, @err, GETDATE()) END CATCH GO
Обработка структурированных исключений (structured exception) Обработка структурированных исключений давно присутствует в большинстве объектно‐ ориентированных языков. Как и в этих языках, в Transact SQL она реализована в виде конструкции TRY…CATCH. Рассмотрим на примере работу с этим блоком и дополнительными средствами обработки ошибок. CREATE TABLE dbo. Data. Table (Col. A int PRIMARY KEY, Col. B int) CREATE TABLE dbo. Error. Log (Col. A int, Col. B int, error int, datetime) GO EXEC dbo. Add. Data 1, 1 CREATE PROCEDURE dbo. Add. Data @a int, @b int EXEC dbo. Add. Data 2, 2 AS EXEC dbo. Add. Data 1, 3 SET XACT_ABORT ON GO BEGIN TRY SELECT * FROM dbo. Error. Log BEGIN TRAN Пример 9. Обработка структурированных исключений INSERT INTO dbo. Data. Table VALUES (@a, @b) COMMIT TRAN END TRY BEGIN CATCH DECLARE @err int SET @err = @@error ROLLBACK TRAN INSERT INTO dbo. Error. Log VALUES (@a, @b, @err, GETDATE()) END CATCH GO
 SQL Server 2008. Шифрование данных Как настроить прозрачное шифрование данных? Необходимо выполнить следующую последовательность действий: 1. В базе данных master необходимо создать главный ключ базы данных, например с помощью следующего выражения: CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'ваш пароль' 2. В базе данных master создать сертификат, который будет использоваться для защиты ключа шифрования: CREATE CERTIFICATE tde. Cert WITH SUBJECT = 'TDE Certificate' 3. Сделать резервную копию сертификата. Разумеется этот шаг не обязателен, но без него наша база данных может стать недоступной при повреждении master BACKUP CERTIFICATE tde. Cert TO FILE = 'путь к файлу' WITH PRIVATE KEY ( FILE = 'путь к файлу', ENCRYPTION BY PASSWORD = 'ваш пароль') 4. Создать в вашей базе данных ключ шифрования базы данных: CREATE DATABASE ENCRYPTION KEY WITH ALGORITHM = AES_256 ENCRYPTION BY SERVER CERTIFICATE tde. Cert 5. Включить шифрование: ALTER DATABASE my. Database SET ENCRYPTION ON После того, как вы включаете шифрование с помощью выражения ALTER TABLE, база данных начинает зашифровываться. В большой базе данных этот процесс может занять значительное время и существенно увеличить нагрузку на ваш сервер. Для того, чтобы определить, закончилось ли шифрование, вы можете использовать представление sys. dm_database_encryption_keys. Столбец encryption_state показывает, в каком состоянии находится процесс шифрования (1‐ база данных не зашифрована, 2 – идет шифрование, 3 – база данных зашифрована полностью).
SQL Server 2008. Шифрование данных Как настроить прозрачное шифрование данных? Необходимо выполнить следующую последовательность действий: 1. В базе данных master необходимо создать главный ключ базы данных, например с помощью следующего выражения: CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'ваш пароль' 2. В базе данных master создать сертификат, который будет использоваться для защиты ключа шифрования: CREATE CERTIFICATE tde. Cert WITH SUBJECT = 'TDE Certificate' 3. Сделать резервную копию сертификата. Разумеется этот шаг не обязателен, но без него наша база данных может стать недоступной при повреждении master BACKUP CERTIFICATE tde. Cert TO FILE = 'путь к файлу' WITH PRIVATE KEY ( FILE = 'путь к файлу', ENCRYPTION BY PASSWORD = 'ваш пароль') 4. Создать в вашей базе данных ключ шифрования базы данных: CREATE DATABASE ENCRYPTION KEY WITH ALGORITHM = AES_256 ENCRYPTION BY SERVER CERTIFICATE tde. Cert 5. Включить шифрование: ALTER DATABASE my. Database SET ENCRYPTION ON После того, как вы включаете шифрование с помощью выражения ALTER TABLE, база данных начинает зашифровываться. В большой базе данных этот процесс может занять значительное время и существенно увеличить нагрузку на ваш сервер. Для того, чтобы определить, закончилось ли шифрование, вы можете использовать представление sys. dm_database_encryption_keys. Столбец encryption_state показывает, в каком состоянии находится процесс шифрования (1‐ база данных не зашифрована, 2 – идет шифрование, 3 – база данных зашифрована полностью).
 Новые типы данных • Date – предназначен для хранения даты в диапазоне 01. 0001 до 01. 9999. • Time(n) – предназначен для хранения времени отдельно от даты. В скобках указывается точность хранения долей секунды. Максимальная точность – 7 разрядов после запятой, т. е. с точностью до 100 пикосекунд. • Date. Time. Offset(n) – хранит дату, время и часовой пояс. Точность хранения времени задается точно так же как и для типа Time – от 0 до 7 знаков после запятой. • Date. Time 2(n) – хранит и дату и время. По сути это аналог datetime, но он позволяет хранить более широкий диапазон дат (от 01. 0001 до 01. 9999) и выбирать точность хранения времени, так же как и Time. Этот тип данных в точности соответствует типу данных Date. Time в среде. Net. • sysdatetime() – возвращает текущее время и дату в формате datetime 2 с точностью 7 знаков после запятой в секундах. • sysdatetimeoffset() – возвращает текущее время, дату и часовой пояс в формате datetimeoffset c точностью 7 знаков после запятой. • switchoffset – позволяет изменить часовой пояс в типе данных Date. Time. Offset
Новые типы данных • Date – предназначен для хранения даты в диапазоне 01. 0001 до 01. 9999. • Time(n) – предназначен для хранения времени отдельно от даты. В скобках указывается точность хранения долей секунды. Максимальная точность – 7 разрядов после запятой, т. е. с точностью до 100 пикосекунд. • Date. Time. Offset(n) – хранит дату, время и часовой пояс. Точность хранения времени задается точно так же как и для типа Time – от 0 до 7 знаков после запятой. • Date. Time 2(n) – хранит и дату и время. По сути это аналог datetime, но он позволяет хранить более широкий диапазон дат (от 01. 0001 до 01. 9999) и выбирать точность хранения времени, так же как и Time. Этот тип данных в точности соответствует типу данных Date. Time в среде. Net. • sysdatetime() – возвращает текущее время и дату в формате datetime 2 с точностью 7 знаков после запятой в секундах. • sysdatetimeoffset() – возвращает текущее время, дату и часовой пояс в формате datetimeoffset c точностью 7 знаков после запятой. • switchoffset – позволяет изменить часовой пояс в типе данных Date. Time. Offset
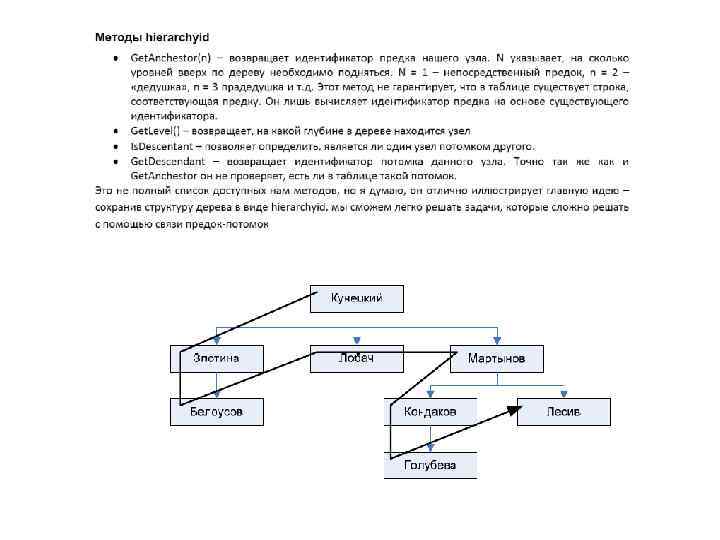
 Иерархические структуры и тип hierarchyid
Иерархические структуры и тип hierarchyid
 Табличный тип данных Вначале создать свой собственный тип данных: CREATE TYPE lookup. Table AS TABLE (ID int, Caption varchar(50)) Теперь его можно использовать как для создания переменных, так и для объявления параметров хранимых процедур и функций: CREATE PROCEDURE Get. Measure. With. Lookup @lookup_tab READONLY AS BEGIN. . . END Существует правда небольшое ограничение – табличный параметр нельзя изменять (его обязательно нужно объявить с ключевым словом READONLY).
Табличный тип данных Вначале создать свой собственный тип данных: CREATE TYPE lookup. Table AS TABLE (ID int, Caption varchar(50)) Теперь его можно использовать как для создания переменных, так и для объявления параметров хранимых процедур и функций: CREATE PROCEDURE Get. Measure. With. Lookup @lookup_tab READONLY AS BEGIN. . . END Существует правда небольшое ограничение – табличный параметр нельзя изменять (его обязательно нужно объявить с ключевым словом READONLY).
 Хранение больших файлов в базе данных Как сохранить varbinary в файл По умолчанию возможность хранить varbinary в виде отдельных файлов отключена. Что нужно сделать чтобы включить ее? Прежде всего, необходимо сконфигурировать экземпляр SQL Server с помощью специальной хранимой процедуры: EXEC sp_filestream_configure @enable_level = 1 Что такое @enable_level? Это параметр, который определяет, что именно мы собираемся сделать: • 0 – отключить • 1 – включить и открыть доступ только через T‐SQL. • 2 – включить и открыть доступ через выражения T‐SQL и локальную файловую систему • 3 – включить и открыть доступ через выражения T‐SQL, локальную файловую систему и сетевое окружение
Хранение больших файлов в базе данных Как сохранить varbinary в файл По умолчанию возможность хранить varbinary в виде отдельных файлов отключена. Что нужно сделать чтобы включить ее? Прежде всего, необходимо сконфигурировать экземпляр SQL Server с помощью специальной хранимой процедуры: EXEC sp_filestream_configure @enable_level = 1 Что такое @enable_level? Это параметр, который определяет, что именно мы собираемся сделать: • 0 – отключить • 1 – включить и открыть доступ только через T‐SQL. • 2 – включить и открыть доступ через выражения T‐SQL и локальную файловую систему • 3 – включить и открыть доступ через выражения T‐SQL, локальную файловую систему и сетевое окружение
 ALTER DATABASE Picture. DB ADD FILEGROUP Photos CONTAINS FILESTREAM GO ALTER database Picture. DB ADD FILE ( NAME= 'Photos', FILENAME = 'D: File. Storage' ) TO FILEGROUP Todays. Photo. Shoot GO CREATE TABLE Photos ( Photo. ID uniqueidentifier rowguidcol NOT NULL UNIQUE, Original. Name varchar(200) null, Photo varbinary(max) filestream )
ALTER DATABASE Picture. DB ADD FILEGROUP Photos CONTAINS FILESTREAM GO ALTER database Picture. DB ADD FILE ( NAME= 'Photos', FILENAME = 'D: File. Storage' ) TO FILEGROUP Todays. Photo. Shoot GO CREATE TABLE Photos ( Photo. ID uniqueidentifier rowguidcol NOT NULL UNIQUE, Original. Name varchar(200) null, Photo varbinary(max) filestream )
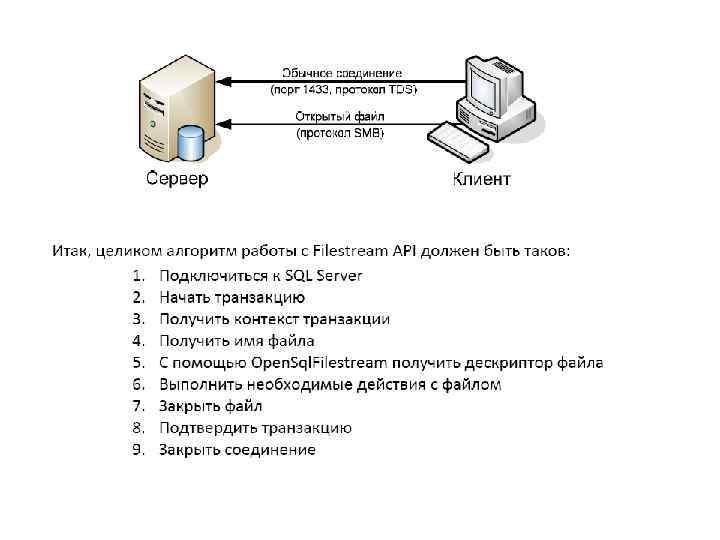
 разработчик клиентского приложения может обратиться к ячейке filestream как к обычному файлу. Для этого разработчику понадобится SQL Native Client десятой версии, а точнее ему понадобится функция Open. Sql. Filestream в библиотеке sqlncli 10. dll. Этой функции нужно передать несколько параметров, среди которых нас интересуют только два: путь к файлу и контекст транзакции. Что это такое, и, главное, откуда их взять? • Путь к файлу – общий смысл этого параметра я думаю, ясен, но нужно сделать одно важное уточнение: Это не реальный путь к файлу на диске, а специальный путь к общей папке, через которую SQL Server обеспечивает доступ к файлам‐ячейкам. Для того, чтобы узнать этот путь нужно воспользоваться методом Path. Name(), например так: SELECT Photo. Path. Name() FROM filestream_example. dbo. Photos WHERE Original. Name = 'softline. jpg‘ • Контекст транзакции это специальное значение, по которому SQL Server может узнать, в какой транзакции происходит обращение к файлу. Для получения этого значения используется T‐SQL функция GET_FILESTREAM_TRANSACTION_CONTEXT().
разработчик клиентского приложения может обратиться к ячейке filestream как к обычному файлу. Для этого разработчику понадобится SQL Native Client десятой версии, а точнее ему понадобится функция Open. Sql. Filestream в библиотеке sqlncli 10. dll. Этой функции нужно передать несколько параметров, среди которых нас интересуют только два: путь к файлу и контекст транзакции. Что это такое, и, главное, откуда их взять? • Путь к файлу – общий смысл этого параметра я думаю, ясен, но нужно сделать одно важное уточнение: Это не реальный путь к файлу на диске, а специальный путь к общей папке, через которую SQL Server обеспечивает доступ к файлам‐ячейкам. Для того, чтобы узнать этот путь нужно воспользоваться методом Path. Name(), например так: SELECT Photo. Path. Name() FROM filestream_example. dbo. Photos WHERE Original. Name = 'softline. jpg‘ • Контекст транзакции это специальное значение, по которому SQL Server может узнать, в какой транзакции происходит обращение к файлу. Для получения этого значения используется T‐SQL функция GET_FILESTREAM_TRANSACTION_CONTEXT().
 Разреженные таблицы Давайте представим себе такую задачу: мы создаем базу данных для магазина одежды. Нам нужно хранить количество каждого товара на складе и набор его характеристик цвет, размер, фирму-производителя и т. п. При этом у разных предметов одежды набор характеристик разный для штанов нужно хранить длину и ширину, для обуви - только размер, для зимних курток размер и температуру, при которой в ней будет комфортно. Нам нужно решить, как хранить эту информацию. Существует несколько хорошо известных решений этой задачи, но мы рассмотрим только два: • хранение всех атрибутов в одной таблице • создание так называемой таблицы (сущность-атрибут-значение) (Entity Attribute Value, EAV).
Разреженные таблицы Давайте представим себе такую задачу: мы создаем базу данных для магазина одежды. Нам нужно хранить количество каждого товара на складе и набор его характеристик цвет, размер, фирму-производителя и т. п. При этом у разных предметов одежды набор характеристик разный для штанов нужно хранить длину и ширину, для обуви - только размер, для зимних курток размер и температуру, при которой в ней будет комфортно. Нам нужно решить, как хранить эту информацию. Существует несколько хорошо известных решений этой задачи, но мы рассмотрим только два: • хранение всех атрибутов в одной таблице • создание так называемой таблицы (сущность-атрибут-значение) (Entity Attribute Value, EAV).
 Новый способ хранения В SQL Server 2008 появился новый способ хранения столбцов, предназначенный именно для тех случаев, когда большую часть места занимают значения NULL. Любой столбец в таблице можно пометить ключевым соловом sparse, после чего значения NULL вообще перестанут занимать место! Правда ячейки, в которых значение указано, наоборот, будут занимать несколько больше места. Это не панацея, а лишь способ оптимизации для специальных случаев. CREATE TABLE Store. Item ( Store. Item. ID int identity not null primary key, Name varchar(50) not null, Amount int not null, … Size int sparse, ‐‐разреженный столбец Length int sparse, ‐‐null указывать не нужно … )
Новый способ хранения В SQL Server 2008 появился новый способ хранения столбцов, предназначенный именно для тех случаев, когда большую часть места занимают значения NULL. Любой столбец в таблице можно пометить ключевым соловом sparse, после чего значения NULL вообще перестанут занимать место! Правда ячейки, в которых значение указано, наоборот, будут занимать несколько больше места. Это не панацея, а лишь способ оптимизации для специальных случаев. CREATE TABLE Store. Item ( Store. Item. ID int identity not null primary key, Name varchar(50) not null, Amount int not null, … Size int sparse, ‐‐разреженный столбец Length int sparse, ‐‐null указывать не нужно … )
 Давайте посмотрим на полный список достоинств и недостатков. Плюсы: • NULL не занимает место • Количество столбцов не ограничено • Можно представить все заполненные столбцы как один XML столбец • Клиентские приложения не видят разницы между обычными и разреженными столбцами • Транзакционная репликация работает • Работает Change Data Capture Минусы • Заполненные ячейки занимают на 4 байта больше • Поддерживаются не все типы данных: нельзя использовать text, ntext, image, timestamp, geometry, geography, varbinary(max) с filestream. • Вычисляемые столбцы не могут быть разреженными • Не работает репликация слиянием • Не поддерживается сжатие данных Как видно недостатки тоже очень существенные: целых четыре байта на заполненную ячейку. Кстати, мы можем определить, когда выгодно использовать sparse: если каждая заполненная ячейка занимает на 4 байта больше, а выигрыш на незаполненной составляет 1 бит, то заполнены должны быть не более 1/32 всех столбцов.
Давайте посмотрим на полный список достоинств и недостатков. Плюсы: • NULL не занимает место • Количество столбцов не ограничено • Можно представить все заполненные столбцы как один XML столбец • Клиентские приложения не видят разницы между обычными и разреженными столбцами • Транзакционная репликация работает • Работает Change Data Capture Минусы • Заполненные ячейки занимают на 4 байта больше • Поддерживаются не все типы данных: нельзя использовать text, ntext, image, timestamp, geometry, geography, varbinary(max) с filestream. • Вычисляемые столбцы не могут быть разреженными • Не работает репликация слиянием • Не поддерживается сжатие данных Как видно недостатки тоже очень существенные: целых четыре байта на заполненную ячейку. Кстати, мы можем определить, когда выгодно использовать sparse: если каждая заполненная ячейка занимает на 4 байта больше, а выигрыш на незаполненной составляет 1 бит, то заполнены должны быть не более 1/32 всех столбцов.
 Сжатие базы данных SQL Server 2008 позволяет индивидуально сжимать кластерные и некластерные индексы, а так же индексированные представления. Если в таблице нет кластерного индекса, и она хранится в виде кучи, то ее тоже можно сжать. Если таблица или индекс секционирован, то мы можем индивидуально сжимать отдельную секцию. Существует два способа сжатия данных: сжатие страниц и сжатие строк. Сжатие строк При построчном сжатии SQL Server сохраняет менее компактные типы данных как более компактные, если это не приводит к потерям точности. Например обнаружив, что в ячейку типа int (4 байта) записано значение меньше 256, он сохранит эту ячейку в виде tinyint (1 байт). Столбцы типа char(n) всегда хранятся как varchar(n), а в столбцах float и real отбрасываются все нулевые младшие разряды в мантиссе (вместо 1, 52000000 хранится 1, 52). В столбцах binary(n) отбрасываются нули в конце блока данных. Столбцы bit наоборот увеличиваются в размерах – вместо одного получается четыре бита. Это связано с тем что SQL Server хранит служебную информацию о строке в новом формате, оптимизированном для хранения значений переменной длины и как следствие неоптимальном для bit. Устаревшие типы данных, например text или image не сжимаются. Кроме того, некоторые типы данных, например uniqueidentifier или varchar(n) сжать таким способом невозможно – они и так максимально компактны.
Сжатие базы данных SQL Server 2008 позволяет индивидуально сжимать кластерные и некластерные индексы, а так же индексированные представления. Если в таблице нет кластерного индекса, и она хранится в виде кучи, то ее тоже можно сжать. Если таблица или индекс секционирован, то мы можем индивидуально сжимать отдельную секцию. Существует два способа сжатия данных: сжатие страниц и сжатие строк. Сжатие строк При построчном сжатии SQL Server сохраняет менее компактные типы данных как более компактные, если это не приводит к потерям точности. Например обнаружив, что в ячейку типа int (4 байта) записано значение меньше 256, он сохранит эту ячейку в виде tinyint (1 байт). Столбцы типа char(n) всегда хранятся как varchar(n), а в столбцах float и real отбрасываются все нулевые младшие разряды в мантиссе (вместо 1, 52000000 хранится 1, 52). В столбцах binary(n) отбрасываются нули в конце блока данных. Столбцы bit наоборот увеличиваются в размерах – вместо одного получается четыре бита. Это связано с тем что SQL Server хранит служебную информацию о строке в новом формате, оптимизированном для хранения значений переменной длины и как следствие неоптимальном для bit. Устаревшие типы данных, например text или image не сжимаются. Кроме того, некоторые типы данных, например uniqueidentifier или varchar(n) сжать таким способом невозможно – они и так максимально компактны.
 Сжатие страниц При сжатии страниц SQL Server ищет внутри страницы повторяющиеся фрагменты данных, выносит эти фрагменты в заголовок страницы а вместо них подставляет ссылку на этот фрагмент. По сути, разработчики SQL Server применили сжатие с использованием словаря, хотя и сделали это существенно иначе, чем в широко распространенном алгоритме Лемпела‐Зива. Более подробное описание алгоритма сжатия можно найти в MSDN, нас же сейчас интересует только область применения постраничного сжатия. Несложно догадаться, что этот способ полезен в тех случаях, когда в таблице часто встречаются повторяющиеся значения, например если таблица хранит личные данные о сотрудниках, она будет хорошо сжиматься поскольку имена и отчества часто повторяются.
Сжатие страниц При сжатии страниц SQL Server ищет внутри страницы повторяющиеся фрагменты данных, выносит эти фрагменты в заголовок страницы а вместо них подставляет ссылку на этот фрагмент. По сути, разработчики SQL Server применили сжатие с использованием словаря, хотя и сделали это существенно иначе, чем в широко распространенном алгоритме Лемпела‐Зива. Более подробное описание алгоритма сжатия можно найти в MSDN, нас же сейчас интересует только область применения постраничного сжатия. Несложно догадаться, что этот способ полезен в тех случаях, когда в таблице часто встречаются повторяющиеся значения, например если таблица хранит личные данные о сотрудниках, она будет хорошо сжиматься поскольку имена и отчества часто повторяются.
 Как включить сжатие? Включить сжатие неожиданно легко. Для этого необходимо указать опцию WITH (DATA_COMPRESSION = способ ) в выражении CREATE TABLE, CREATE INDEX, ALTER TABLE или ALTER INDEX. Причем во всех четырех выражениях это делается практически одинаково. Например, если я хочу сжать создаваемую таблицу, то я должен выполнить такую команду: CREATE TABLE Contacts (. . . ) WITH (DATA_COMPRESSION = PAGE) Для сжатия существующего индекса его необходимо перестроить: ALTER INDEX PK_Orders_Order. ID ON Orders REBUILD WITH (DATA_COMPRESSION = PAGE ) Для того чтобы отключить сжатие, необходимо указать DATA_COMPRESSION = NONE
Как включить сжатие? Включить сжатие неожиданно легко. Для этого необходимо указать опцию WITH (DATA_COMPRESSION = способ ) в выражении CREATE TABLE, CREATE INDEX, ALTER TABLE или ALTER INDEX. Причем во всех четырех выражениях это делается практически одинаково. Например, если я хочу сжать создаваемую таблицу, то я должен выполнить такую команду: CREATE TABLE Contacts (. . . ) WITH (DATA_COMPRESSION = PAGE) Для сжатия существующего индекса его необходимо перестроить: ALTER INDEX PK_Orders_Order. ID ON Orders REBUILD WITH (DATA_COMPRESSION = PAGE ) Для того чтобы отключить сжатие, необходимо указать DATA_COMPRESSION = NONE
 Пространственные типы данных В SQL Server 2008 появилось два новых типа данных, предназначенных для гранения географической информации Geometry и Geography. В целом они похожи, но в Geometry геометрические вычисления реализуются на плоскости а координаты отсчитываются от условного «левого верхнего угла» , а в Geography – на эллипсоиде вращения, причем координаты задаются в виде долготы, широты и высоты над поверхностью океана. И geography и geometry являются в некотором роде «полиморфными» типами. Дело в том что внутри ячейки такого типа можно хранить различные типы данных: точку (point), прямую линию (line) и ломаную линию (multiline). Совместимость со стандартами Географические типы данных в SQL Server строго соответствуют стандарту, причем стандарту, придуманному не Microsoft: Они соответствуют Open Geospatial Consortium (OGC) Simple Features for SQL Specification version 1. 1. 0. То есть специальному стандарту, описывающему, как нужно хранить географические данные в базах данных SQL.
Пространственные типы данных В SQL Server 2008 появилось два новых типа данных, предназначенных для гранения географической информации Geometry и Geography. В целом они похожи, но в Geometry геометрические вычисления реализуются на плоскости а координаты отсчитываются от условного «левого верхнего угла» , а в Geography – на эллипсоиде вращения, причем координаты задаются в виде долготы, широты и высоты над поверхностью океана. И geography и geometry являются в некотором роде «полиморфными» типами. Дело в том что внутри ячейки такого типа можно хранить различные типы данных: точку (point), прямую линию (line) и ломаную линию (multiline). Совместимость со стандартами Географические типы данных в SQL Server строго соответствуют стандарту, причем стандарту, придуманному не Microsoft: Они соответствуют Open Geospatial Consortium (OGC) Simple Features for SQL Specification version 1. 1. 0. То есть специальному стандарту, описывающему, как нужно хранить географические данные в базах данных SQL.
 Географические индексы
Географические индексы