Лекция_6t_арх_соврем_проц1.ppt
- Количество слайдов: 21



Общая организация процессоров
 — наиболее типичный представитель 6")
Краткие характеристики распространенных семейств процессоров Intel Pentium III (P-III) — наиболее типичный представитель 6 -го поколения процессорной архитектуры (P 6) компании Intel. Pentium M (PM) и Core Duo (P-M 2)- являются развитием P-III —В связи с наличием серьёзных архитектурных усовершенствований процессоры P-M и P-M 2 будем при необходимости выделять в отдельную подгруппу (P 6+). Intel Pentium 4 (P-4) — представитель 7 -го поколения процессоров (P 7), эту архитектуру также называют Net. Burst. Будет в основном рассматриваться первоначальный вариант микроархитектуры. Развитием семейства является процессор Prescott (P-4 E), имеющий определённые микроархитектурные отличия и поддерживающий 64 битный режим целочисленной и адресной арифметики EM 64 T (x 86 -64). Intel Core (P 8) — процессор новой микроархитектуры, продается под названиями Core 2 Duo и Core 2 Extreme. Известен также под кодовым именем Conroe. Несмотря на то, что этот процессор базируется в основном на архитектурных принципах семейства P 6, он имеет много принципиальных отличий количественного и качественного плана. По этой причине будем считать его представителем 8 -го поколения процессорной архитектуры (P 8) компании Intel.
 — представитель")
Краткие характеристики распространенных семейств процессоров AMD Athlon 64 / Opteron (K 8) — представитель высокопроизводительной микроархитектуры компании AMD. Базируется на архитектурных принципах предыдущего семейства K 7, отличается от него определёнными усовершенствованиями, поддержкой 64 -битного режима AMD 64 (x 86 -64) и наличием встроенного контроллера памяти. IBM Power. PC 970 (PPC 970) — процессор RISCархитектуры IBM Power, известен также под названием G 5. До недавнего времени был основным процессором персональных компьютеров компании Apple (в настоящее время Apple постепенно переводит свои ПК на процессоры компании Intel). Основан на микроархитектуре серверного процессора Power 4.

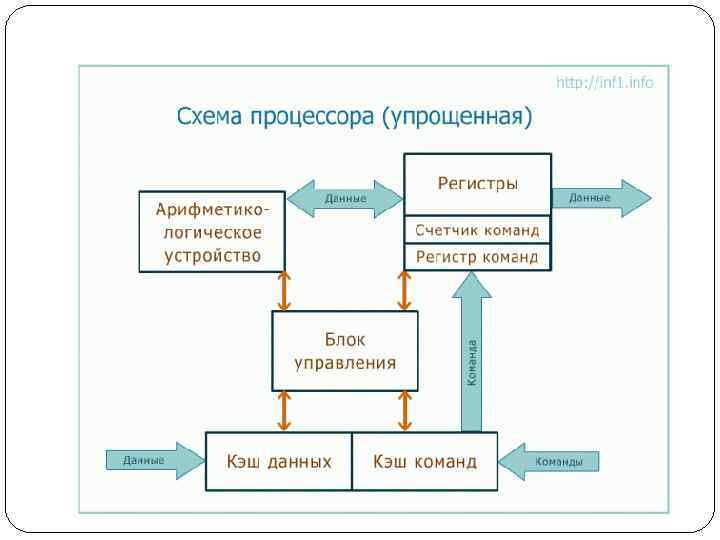
Процессор Большинство современных микропроцессоров относятся к классу конвейерных суперскалярных процессоров с внеочередным исполнением операций.

Конвейерная организация Можно выделить два наиболее важных проявления конвейерной организации процессора: «конвейер процессора» либо «конвейер непредсказанного перехода» - прохождение инструкции от момента считывания из кэша инструкций до полного завершения. латентность - время ожидания результатов операции другой операцией, прохождение операции через функциональное устройство. Большинство простых операций целочисленной арифметики и логики имеют латентность, равную единице — то есть они выполняются в функциональных устройствах синхронно, без конвейеризации.
 при условии, что")
Длина конвейера — это минимальное время прохождения операции (в тактах) при условии, что нет никаких внешних причин для задержек

Суперскалярная организация означает, что на каждом этапе обрабатываются сразу несколько потоков инструкций в параллель — от выборки из кэша инструкций до полного завершения. Суперскалярность наряду с тактовой частотой является важнейшим показателем пропускной способности процессора. Уровень суперскалярности ( «ширина обработки» , гарантированно обеспеченная на всех этапах) в современных производительных процессорах варьируется от 3 (P-III, P-4, K 8) до 4 -5 (P 8, PPC 970).

Внеочередное исполнение операций означает, что операции не обязаны выполняться в функциональных устройствах строго в том порядке, который определён в программном коде. Более поздние (по коду) операции могут исполняться перед более ранними, если не зависят от порождаемых ими результатов. Процессор должен лишь гарантировать, чтобы результаты «внеочередного» выполнения программы совпадали с результатами «правильного» последовательного выполнения. Механизм внеочередного исполнения позволяет в значительной степени сгладить эффект от ожидания считывания данных из кэшей верхних уровней и из оперативной памяти, что может занимать десятки и сотни тактов. Также он позволяет оптимизировать выполнение смежных операций, особенно при наличии сложных зависимостей между ними в условиях высокой латентности исполнения в устройствах и недостаточного количества регистров.

Важной особенностью современных процессоров является также предварительное преобразование машинных инструкций в промежуточные операции (микрооперации), более удобные для обработки и исполнения. Иногда такие операции называют RISCподобными. В рассматриваемых процессорах эти промежуточные микрооперации обозначаются поразному: u. OP (Intel P-III, P-4, P 8), MOP (AMD K 8), IOP (IBM PPC 970). Для унификации в дальнейшем во всех случаях будем называть эти микрооперации «МОПами» (либо просто «операциями» )

«отставка» инструкции- данная инструкция выполнена вместе со всеми инструкциями, которые ей предшествовали в коде программы. Таким образом, операции (инструкции) уходят в отставку строго последовательно, именно в том порядке, который задаётся программой. Процедура отставки инструкции гарантирует, что она была выполнена «правильно» . Спекулятивное выполнение – состояние при катором какая-то операция уже выполнилась в своём функциональном устройстве — но при этом не должна была выполняться, так как было неправильно предсказано направление условного перехода либо были считаны данные с неправильного адреса. Когда будет правильно исполнена предшествующая ей операция перехода или чтения данных, такая неверная спекулятивная ветвь будет отменена, и при необходимости инструкция будет выполнена вновь

Схема тракта данных Регистры Входной регистр АЛУ Входная шина АЛУ Выходной регистр АЛУ

Шаги выполнения команд процессором Вызывает следующую команду из памяти и переносит ее в регистр команд. Меняет положение счетчика команд, который после этого указывает на следующую команду1. Определяет тип вызванной команды. Если команда использует слово из памяти, определяет, где находится это слово. Переносит слово, если это необходимо, в регистр центрального процессора 2. Выполняет команду. Переходит к шагу 1, чтобы начать выполнение следующей команды.

Предсказатель переходов Кэш инструкций Предварительный декодер Кэш 2 го уровня Шина Декодер Устрой ство переи менов ания регист ров и выдел ения ресурс ов Подсистема внеочередного исполнения Буфер переупорядочения Пункт резервирования (буферы) D кеш повтор итель

Подмножество кода программы, наиболее «активно» исполняемое в данный отрезок времени, размещено в кэше инструкций (I-кэше). В зависимости от организации процессора, инструкции в этом кэше могут храниться в исходном неизменённом виде, либо в частично «предекодированном» виде, либо в полностью «декодированном» виде (то есть в виде готовых МОПов). В случае отсутствия в данном кэше нужных инструкций (исходных либо преобразованных) они считываются из кэша 2 -го уровня (L 2 кэша), при необходимости подвергаясь предварительному декодированию перед помещением в I-кэш. Инструкции считываются из I-кэша блоками, с опережающей предвыборкой. Текущий блок инструкций отправляется сразу в два устройства — декодер инструкций и предсказатель переходов. Декодер преобразует исходные (либо частично декодированные) инструкции в микрооперации (МОПы), Предсказатель переходов определяет, есть ли в обрабатываемом блоке инструкции перехода, будут ли эти переходы совершены и по каким адресам. Если какой-либо переход предсказывается как «совершённый» , то немедленно считывается блок инструкций, находящийся по предсказанному адресу.

Тем временем вновь порождённая декодером группа МОПов поступает в устройство переименования регистров и выделения ресурсов (Rename/Allocate). Переименование (или переназначение) регистров — это выделение данному МОПу нового экземпляра внутреннего регистра процессора, куда будут помещены результаты выполнения этого МОПа. Все дальнейшие операции, зависящие от результатов данного МОПа, будут использовать этот регистр в качестве операнда. «Переименованный» регистр ставится в соответствие регистру, который указан в машинной инструкции (так называемому «архитектурному регистру» ). Необходимость в переназначении регистров связана с тем, что архитектурных регистров обычно очень мало, и при использовании столь ограниченного числа регистров невозможно эффективно исполнить поток операций — каждая новая операция, использующая определённый регистр, была бы вынуждена ждать завершения всех предыдущих операций, которые к нему обращаются (даже если ей не нужны результаты этих операций). Наличие большого числа машинных (физических) регистров и механизма переименования позволяет обойти эту проблему. Информация о соответствии регистров хранится в специальных таблицах. В момент отставки МОПа будет произведено обратное преобразование физического регистра в архитектурный.

После преобразования и подготовки регистров поступившая группа МОПов записывается в конец специальной очереди, носящей название «буфер переупорядочения» (Re. Order Buffer, ROB). Эта структура является ключевой в организации внеочередного исполнения операций. В ней хранятся все МОПы и необходимые вспомогательные данные от момента завершения декодирования и выделения ресурсов до момента отставки. Таким образом, длина буфера ROB ограничивает число операций, которые одновременно могут находиться в обрабатывающей части процессора (подсистеме внеочередного исполнения) — от самой «старой» , которая ещё не завершена и поэтому не может «уйти в отставку» , до самой «новой» , которая только что поступила из декодера. В случае переполнения буфера переупорядочения, работа декодера приостанавливается до тех пор, пока не произойдёт отставка операций в начале очереди и освобождение места для новых МОПов.

Одновременно с попаданием в ROB новая группа МОПов передаётся в другую структуру данных, откуда МОПы будут отсылаться на исполнение непосредственно в функциональные устройства. Данная структура, известная под названием «пункт резервирования» , «резервация» (Reservation Station, RS), представляет собой один или несколько буферов, к которым подсоединены эти функциональные устройства. В каждом такте в этих буферах производится поиск операций, которые готовы к исполнению (то есть аргументы которых уже вычислены либо вычисляются и будут готовы к моменту попадания операции в функциональное устройство) вне зависимости от порядка, в котором они записывались в буфера. Устройство, которое осуществляет этот поиск и запуск на исполнение, обычно называют планировщиком, а сами буфера — очередями планировщика. Планировщик отслеживает зависимости между операциями по данным и прогнозирует готовность операций к исполнению в устройствах.

Таким образом, поиск МОПов для внеочередного исполнения всегда производится только в пределах такого буфера планировщика (единого для всех функциональных устройств, либо специфичного для каждой группы устройств), и этот буфер выглядит как «окно» , в котором (при необходимости) происходит изменение порядка выполнения операций. Очередь планировщика представляет собой полностью ассоциативный буфер, с точки зрения поиска операций для исполнения. Но с точки зрения помещения новых МОПов, она ведёт себя как обычная очередь. Все МОПы, находящиеся в какой-то момент в очередях планировщика, одновременно находятся и в буфере ROB. При запуске операции на исполнение в функциональном устройстве соответствующий ей МОП удаляется из очереди планировщика, а в момент завершения операции делается пометка в соответствующем элементе буфера ROB. Когда все МОПы, предшествующие данному, успешно выполнятся и отправятся в отставку, данный МОП также сможет быть отставлен и удалён из буфера ROB. Однако может оказаться, что МОП попал в ошибочную (спекулятивную) ветвь исполнения из-за неверного предсказания перехода — в этом случае вся ветвь будет удалена из буфера переупорядочения после правильного исполнения и отставки данной инструкции перехода. Когда МОП, запущенный на исполнение в устройстве, удаляется из очереди планировщика, в ней освобождается место для приёма нового МОПа. Это означает, что эффективный размер окна для изменения порядка операций превышает длину данной очереди и ограничивается вместимостью буфера ROB.

К каждой очереди планировщика подсоединено одно или несколько специализированных функциональных устройств. Число операций, которые могут быть запущены на исполнение в каждом такте, обычно заметно превышает ширину остальных трактов процессора и варьируется от 5 (P-III) до 10 (PPC 970), что позволяет сглаживать пиковую нагрузку и обеспечить высокую пропускную способность при неоднородной загрузке устройств. Помимо арифметико-логических и адресных функциональных устройств, в каждом процессоре имеются также устройства загрузки и выгрузки (Load/Store), которые производят доступ к кэшам данных и к оперативной памяти. Эти устройства работают асинхронно от других, и их обычно не изображают на блок-схемах. Логически эти устройства связаны с устройствами вычисления адресов чтения/записи (AGU). Устройства загрузки и выгрузки конвейеризованы и могут одновременно обслуживать большое количество запросов. Эти устройства также осуществляют предварительную выборку из оперативной памяти (копирование в кэши тех данных, использование которых ожидается в ближайшее время). На Рисунке группа блоков процессора, образующих подсистему внеочередного исполнения, обведена пунктирной линией.

Intel Pentium III, Pentium M и Core Duo После выхода из декодера сформированные группы по три МОПа помещаются в буфер переупорядочения ROB, длина которого составляет 40 элементов (начиная с процессора P-M размер буфера ROB, по некоторым данным, увеличен до 6080 элементов). Новая группа МОПов также копируется в очередь планировщика RS, из которой операции будут запускаться на исполнение. В процессоре P-III используется единая очередь планировщика размером в 20 элементов (начиная с процессоры P-M — 24 элемента), общая для всех типов операций. МОПы выбираются на исполнение из этой очереди во внеочередном порядке, по мере готовности аргументов операций
Лекция_6t_арх_соврем_проц1.ppt