ed9415fe30b257d9b04e06ec9ed75545.ppt
- Количество слайдов: 78



Multi objective Search result clustering and Word Sense Induction Presented by Dr. Sriparna Saha Department of Computer Science and Engineering IIT Patna INDIA Email: sriparna@iitp. ac. in Webpage: www. iitp. ac. in/~sriparna 17 -03 -2018 1

Clustering algorithm MOO based clustering technique Applications MOO based solution framework for automatic determination of ensemblesubset, classifier type, parameters and features biclus tering Semi supervised approach Applications NER Biblio data Classification Algorithms Stability Symmetry Feature Selection MOO Bio inform atics Image Seg. NLP and IR Corefe Bio medical rence resolu IE tion mi. RNA classifica tion

Information retrieval Bioinformatics Cancer tissue sample classification mi. RNA classificati on symmetry based distance for developing cluster validity indices symmetry based distance on clustering algorithm Automatic determination of appropriate distance measures for classifying cancer and MOO search result clustering WSI Automated Scientific paper review support system

Contents • Search Result clustering • • Introduction Related works Motivation Single objective optimization Vs. Multi objective optimization Single objective clustering vs. Multi-objective clustering Framework of proposed Multi-objective optimization based SRC Results • Extension of SRC task • • WSD vs. WSI Motivation Proposed multi-objective word sense induction methodology Results • Conclusion and future works 17 -03 -2018 4

Collaboration • This work was done in collaboration with University of Caen, France with following researchers, • Sudipta Acharya • Prof. Gael harry Dias • José Guillermo Moreno 17 -03 -2018 5
. Ø Result Information Overload. Multinational brand Forum")
Ø Ambiguous user query (e. g. Puma). Ø Result Information Overload. Multinational brand Forum Web server

Ø Organizing results returned by a search engine in response to a keyword/query Search Engine Results Pages Organize retrieved Web pages from a search Engine Ephemeral Clustering or Search Result Clustering (SRC) On- Line clustering/ clustering for short span of time. GIAN-MOO

• A solution is proposed in Zamir and Etzioni, 1998, which includes labelling process. • Proposed clustering algorithm Suffix Tree Clustering (STC). • Represent data points as a vector of words Web snippets • Evaluation over small set of 10 queries shows STC outperforms Kmeans, Buckshot, Fractionation and Single-Pass algorithms. • In Osinski and Weiss, 2005 authors proposed a clustering algorithm called as LINGO • Also represents datapoints as string as done in Zamir and Etzioni, 1998. • first extract frequent phrases Each phrase represents different classes. • Match group description with extracted phrases and assign relevant documents to them • It performed an experiment on 7 users and a set of 4 search results (2 in Polish and 2 in English). • As such, no conclusive remarks can be drawn. In Carpineto et al. , 2009 VSM representation is done. Similarity between documents Cosine similarity Next partitioning strategy called Fractionation is performed( to discover the number of clusters suggested by the user. ) Although they present the foundations of SRC, the evaluation is based on a small dataset and a limited user study. 17 -03 -2018 8

• In Carpineto and Romano, 2010, authors proposed a meta-clustering process OPTIMSRC • Meta clustering phase is casted to the SOO • Different SOO solutions are combined in order to get final solution • In a very recent work Moreno et al. , 2013 authors adapted the K-means algorithm. • proposed a stopping criterion to automatically determine the “optimal” number of Clusters • Experiments are run over two gold standard data sets, ODP-239 (Carpineto and Romano, 2010) and MORESQUE (Navigli and Crisafulli, 2010) • showed improved results over all state-of-the-art text-based SRC techniques so far. 17 -03 -2018 9

Similarly there are several works on MOO based clustering In Handl and Knowles, 2007, a clustering algorithm named as multiobjective clustering with automatic K-determination (MOCK) It outperforms several single-objective clustering algorithms Two objective functions Connectedness and compactness are chosen Fails to identify overlapped clusters. In Bandyopadhyay et al. , 2007, Mukhopadhyay et al. , 2010, Maulik et al. , 2009, Ripon et al. , 2006 authors proposed different MOO based clustering algorithms. 17 -03 -2018 10

Drawback of Existing SRC Algorithms Ø Labelling clusters. Ø Examples: Yippy, Carrot , i. Boogie, Vipaccess. Ø Too many clusters!! GIAN-MOO

• We propose a Multi-objective based clustering algorithm MOO-clus • automatically determines the number of clusters. • An exhaustive evaluation of MOO-clus algorithm with recent benchmark datasets(ODP-239 and Moresque) w. r. t some evaluation metrics S. Acharya, S. Saha, Jos G. Moreno and G. Dias. ”Multi-Objective Search Results Clustering”. In Proceedings of COLING 2014, the 25 th International Conference on 17 -03 -2018 12 Computational Linguistics, Dublin, Ireland, pg 99 -108, August 2014.
 Optimization based on Single criteria. Ex. Flight price •")
• Single objective optimization(SOO) Optimization based on Single criteria. Ex. Flight price • Multi-objective optimization(MOO) Optimization based on multiple criteria. Ex. Flight price and flight time S. Acharya, S. Saha, Jos G. Moreno and G. Dias. ”Multi-Objective Search Results Clustering”. In Proceedings of COLING 2014, the 25 th International Conference on Computational Linguistics, Dublin, Ireland, pg 99 -108, August 2014.

Multiobjective Optimization: Example of Purchasing A Car • Optimizing criteria • minimizing the cost, insurance premium and weight and • maximizing the feel good factor while in the car. • Constraints • car should have good stereo system, seats for 6 adults and a mileage of 20 kmpl. • Decision variables • the available cars • In many real world problems we have to simultaneously optimize two or more different objectives which are often competitive in nature • finding a single solution in these cases is very difficult. • optimizing each criterion separately may lead to good value of one objective while some unacceptably low value of the other objective(s). 14

Multiobjective Optimization: Mathematical Definition • The multiobjective optimization can be formally stated as: Find the vector of decision variables x=[x 1, x 2…. . xn]T • which will satisfy the m inequality constraints: gi(x) >=0, i=1, 2, …. m, • And the p equality constraints hi(x)=0 , i=1, 2, …. p. • And simultaneously optimizes M objective functions f 1(x), f 2(x)…. f. M(x). 15
 1 Pareto-optimal surface 2 3 4 5 f 1(maximization)")
Dominance and Pareto-Optimality f 2(maximization) 1 Pareto-optimal surface 2 3 4 5 f 1(maximization) • Here solution 1, 2, 3 and 4 are non-dominating to each other. • 5 is dominated by 2, 3 and 4, not by 1. 16

• Produces a set of non-dominating solutions Pareto front • Flexibility in choosing amongst the solution set based on any user-defined criteria.

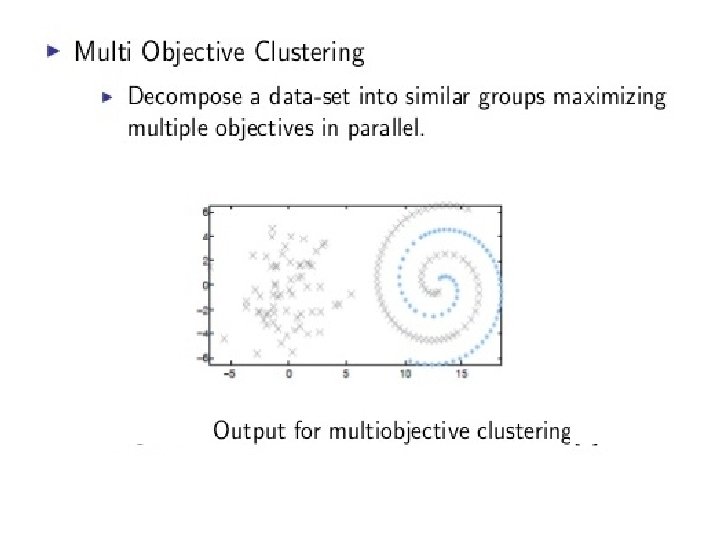
Multiobjective Clustering Techniques • Often for many data sets no unambiguous partitioning exists – Multiple solutions representing different partitionings needed • Existing clustering algorithms optimize only a single measure of cluster quality – Not applicable for different kinds of data sets with different characteristics – Need to optimize simultaneously different cluster quality measures capturing different data properties Pose Clustering as a MOO Problem S. Saha and S. Bandyopadhyay (2010): ``A symmetry based multiobjective clustering technique for automatic evolution of clusters", Pattern Recognition. Volume 43, Issue 3, Pages 738 -751 (impact factor: 2. 607), H-index: 67.

Original data set Two different clustering solutions

Example of Multiple Clustering Solutions for a Data Set
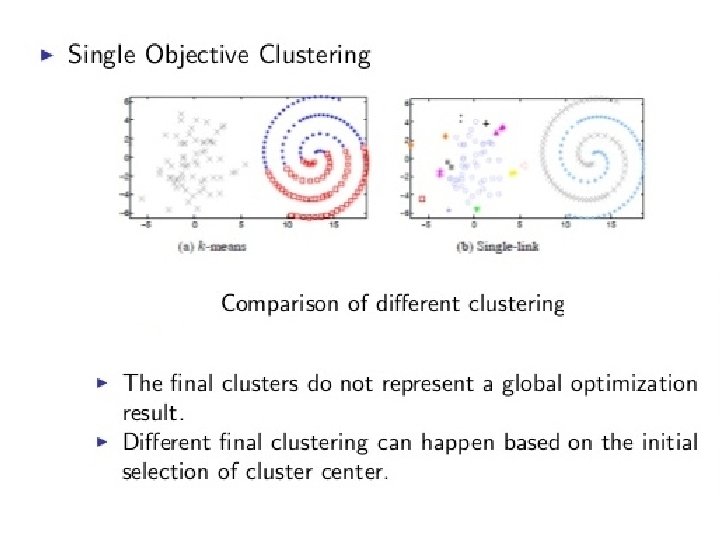

Chosen Objective Functions • Cluster Compactness within cluster similarity maximize • Cluster separation between cluster center similarity minimize PUMA BRAND PUMA ANIMAL
 1 Creating Global Vocabulary Initialize")
Steps of Proposed Algorithm Creating Word Feature Vector(Web snippet) 1 Creating Global Vocabulary Initialize Population of archive_element Creation similarity matrix 2 Apply mutation Loop continues Upto nth loop STOP 7 Compute Objective functions for each solution 4 5 17 -03 -2018 3 6 Input preprocessing Select final solution using Fb 3 measure Compute membership and Update cluster center Form Paretooptimal front 24

• Word feature vector • Based on tf-idf method most significant topical words are selected Query 1: OUTPUT: 4 snippets/documents: d 1 W 1: 1 W 2: 3 W 3: 2 d 2 W 4: 2 W 1: 5 W 5: 1 d 3 W 6: 3 W 3: 3 W 1: 1 W 7: 3 d 4 W 3: 3 W 8: 2 W 9: 2 W 2: 2

Global Vocabulary 1. 2. 3. 4. 5. 6. 7. 8. 9. W 1 W 2 W 3 W 4 W 5 W 6 W 7 W 8 W 9
 W 1 W 2 W 3 W 4")
• Similarity matrix(Symmetric Conditional Probability) W 1 W 2 W 3 W 4 W 5 W 6 W 7 W 8 W 9 W 1 1. 0 0. 8 0. 3 0. 0 0. 2 0. 1 0. 3 0. 0 0. 6 W 2 0. 8 1. 0 . . . W 3 0. 3 . . . . W 4 0. 0 . . . . W 5 0. 2 . . . . W 6 0. 1 . . . . W 7 0. 3 . . . . W 8 0. 0 . . . . W 9 0. 6 . . . .

String encoding of clustering solution and archive initialization Varies between 2 to √N SC SC 1 Wj 2 Wi SC 3 Wk Wl SC SC 1 Wj 2 Wp SC 1 Ws SC Wt 2 Wj SC 3 Wm Wo Wi Wj CC 2 Cluster center dimension SC 3 Wu Wl Wv Wi Wx Wl Where, Kmax= √N Nd= (rand()mod(Kmax-1)) + 2 Wl Complete solution Wm Wi Archive_members

Membership Calculation SC SC 1 Wj 2 Wi SC 3 Wk Wl Wm Wi Wj Wl SC 1 Ws SC Wt 2 SC 3 Wm Wo SC 3 Wu Wl Wi Wx Wl dm 0 1 0 1 0 0 C 4 Wv . . C 2 Wj . . C 1 Wi d 2 C 3 SC SC 1 Wj 2 Wp d 1 0 0 1

• For calculating membership SCP matrix is used to calculate similarity between – Each snippet and encoded cluster centers • To find the SCP measure, each sample is first assigned to the maximum similar cluster center respectively. i. e. i=argmaxk=1…p. S(dj , mk) Where, p=Number of encoded clusters S(dj , mk) = denotes similarity measurement between the point dj and cluster centroid mk defined in equation below

Computing Objective Functions k mk k o Maximize Minimize

Search Operator: Mutation SC SC 1 Wj 2 Wi SC 3 Wk Wl Wm Wi Wj Wl Mutation 1 SC SC 1 Wj 2 Wi SC 3 Wk Wl Wm Wi Ws Wu Mutation 2 SC SC 1 Wj 2 Wi SC 3 Wk Wl Ws Wu Mutation 3 SC SC 1 Wj 2 Wi SC 3 Wk Wl Ws Wu Wx Wz

Our Chosen Datasets: Dataset # of queries # of Snippets ODP-239 25580 11402 (Carpineto and Romano, 2010) MORESQUE (Navigli and Crisafulli, 2010) S. Acharya, S. Saha, Jos G. Moreno and G. Dias. ”Multi-Objective Search Results Clustering”. In Proceedings of COLING 2014, the 25 th International Conference on 17 -03 -2018 33 Computational Linguistics, Dublin, Ireland, pg 99 -108, August 2014.
 , Fb")
Our Chosen Evaluation Metrics: • Fß (for ß = 1, 2, 5) , Fb 3 • Weighted average of Precision and recall • Used to measure cluster quality i. e. , Cluster Completeness, Rag-bag, Homogeneity, and cluster size vs. cluster number constraints. S. Acharya, S. Saha, Jos G. Moreno and G. Dias. ”Multi-Objective Search Results Clustering”. In Proceedings of COLING 2014, the 25 th International Conference on 1 17 -03 -2018 2 34 Computational Linguistics, Dublin, Ireland, pg 99 -108, August 2014.

Results Compared to Other Algorithms S. Acharya, S. Saha, Jos G. Moreno and G. Dias. ”Multi-Objective Search Results Clustering”. In Proceedings of COLING 2014, the 25 th International Conference on 17 -03 -2018 35 Computational Linguistics, Dublin, Ireland, pg 99 -108, August 2014.

Results Compared to Other Algorithms S. Acharya, S. Saha, Jos G. Moreno and G. Dias. ”Multi-Objective Search Results Clustering”. In Proceedings of COLING 2014, the 25 th International Conference on 17 -03 -2018 36 Computational Linguistics, Dublin, Ireland, pg 99 -108, August 2014.

Results by Varying Cluster Center Dimension S. Acharya, S. Saha, Jos G. Moreno and G. Dias. ”Multi-Objective Search Results Clustering”. In Proceedings of COLING 2014, the 25 th International Conference on 17 -03 -2018 37 Computational Linguistics, Dublin, Ireland, pg 99 -108, August 2014.

Results by Varying Cluster Center Dimension S. Acharya, S. Saha, Jos G. Moreno and G. Dias. ”Multi-Objective Search Results Clustering”. In Proceedings of COLING 2014, the 25 th International Conference on 17 -03 -2018 Computational Linguistics, Dublin, Ireland, pg 99 -108, August 2014. 38

Extension of SRC Task • Another challenging task in the field of NLP is Word sense induction. • It can be solved intuitively by solving SRC task • Unlike our previous SRC task, hyperlink based information can be considered as another source of rich information[8]. S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural 17 -03 -2018 39 Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.

• This work was done in collaboration with University of Caen, France with following researchers, • • • Sudipta Acharya Prabhakaran Santhanam Dr. Asif Ekbal Prof. Gael harry Dias José Guillermo Moreno 17 -03 -2018 40
 and Word Sense Induction (WSI) two fundamental")
WSD vs. WSI Word Sense Disambiguation (WSD) and Word Sense Induction (WSI) two fundamental tasks in Natural Language Processing(NLP) Word Sense Disambiguation (WSD) is the task of automatically associating meaning with words. In WSD the possible meanings for a given word are drawn from an existing sense inventory (e. g. , from Word. Net). In contrast, Word Sense Induction (WSI) aims at automatically identifying the meanings of a given word from raw text (see (Navigli, 2009) for a survey of both paradigms). S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural 17 -03 -2018 41 Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.
 • Task of determining the meaning of an ambiguous word")
Word Sense Disambiguation (WSD) • Task of determining the meaning of an ambiguous word in the given context • Bank • Edge of a river or • Financial institution that accepts money • Refers to the resolution of lexical semantic ambiguity and its goal is to attribute the correct senses to words (AI-complete problem) S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.

WSD: Areas of Research • Assigning correct sense to words having electronic dictionary as source of word definitions • Open research field in Natural Language Processing (NLP) • Hard Problem which is a popular area for research • Used in speech synthesis by identifying the correct sense of the word S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.

Drawback of Word sense Disambiguation • predefined sense inventory • Cant work in the absence of predefined sense inventory. S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural 17 -03 -2018 44 Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.

Word Sense Induction • WSI or Word sense induction task of automatically inducing the different senses of a given word • Example: Ø I can hear bass sounds. Low frequency tones Ø They like grilled bass. Type of fish generally in the form of an unsupervised learning task with senses represented as clusters of token instances • WSI Expected capability of modern information retrieval system. S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural 17 -03 -2018 45 Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.

• But most of the existing works solving WSI problem are either content based [1] [2] or hyperlink based [3] [4]. • We have attempted to solve this problem by taking into account both content and hyperlink information of web documents. • As far as our knowledge goes, no existing methodology for WSI uses the hyperlink information and content information in an unified methodology. S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural 17 -03 -2018 46 Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.

Motivation • Contents and hyperlinks existing in the web are important and complimentary source of information. • So neglecting any one of them can loose important information. • Hypothesis Word senses are related to the distribution of words on web pages and the way they are linked together. S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural 17 -03 -2018 47 Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.

• We have proposed a multi objective framework based Search result clustering algorithm Solve WSI problem • Underlying optimization technique is based on AMOSA[7] • Each cluster represents a unique sense • Objective functions are based on both content and hyperlink information of web documents S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural 17 -03 -2018 48 Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.

Chosen Task • Sem. Eval 13 task 11 Provide an evaluation framework for objective evaluation and comparison of Word Sense Disambiguation and induction algorithms in SRC • The aim of this task is to provide an evaluation framework for the objective evaluation and comparison of Word Sense Disambiguation and Induction algorithms in an end-user application, namely Web Search Result Clustering. • Given an ambiguous query, the top ranking snippets returned by a search engine will be provided as bags of words. Systems will be asked to associate a sense id with each bag of words, one for each snippet. Snippets will be clustered based on the output sense associations (either cluster ids for WSI systems or dictionary sense ids for WSD systems) and an evaluation will be performed against a gold-standard clustering obtained on the basis of the manual associations of snippets with Wikipedia senses. S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural 17 -03 -2018 49 Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.
 1 Creating Global Vocabulary Initialize")
Steps of Proposed Algorithm Creating Word Feature Vector(Web snippet) 1 Creating Global Vocabulary Initialize Population of archive_element Creation similarity matrix 2 Apply mutation Loop continues Upto nth loop STOP 7 Compute Objective functions for each solution 4 5 17 -03 -2018 3 6 Input preprocessing Select final solution using F 1 measure Compute membership and Update cluster center Form Paretooptimal front 50

Combining Content and Hyperlink Approaches with a MOO Objective functions Separation Compactness Hyperlink based separation Content based compactness Hyperlink based compactness SCP 17 -03 -2018 PMI Page. Rank Content based separation SCP PMI Page. Rank 51

Combining Content and Hyperlink Approaches with a MOO Objective functions Separation Compactness Hyperlink based separation Content based compactness Hyperlink based compactness SCP 17 -03 -2018 PMI Page. Rank Content based separation SCP PMI Page. Rank 52

Combining Content and Hyperlink Approaches with a MOO Objective functions Separation Compactness Hyperlink based separation Content based compactness Hyperlink based compactness SCP 17 -03 -2018 PMI Page. Rank Content based separation SCP PMI Page. Rank 53

Combining Content and Hyperlink Approaches with a MOO Objective functions Separation Compactness Hyperlink based separation Content based compactness Hyperlink based compactness SCP 17 -03 -2018 PMI Page. Rank Content based separation SCP PMI Page. Rank 54

Combining content and hyperlink approaches with a MOO Objective functions Separation Compactness Hyperlink based separation Content based compactness Hyperlink based compactness SCP 17 -03 -2018 PMI Page. Rank Content based separation SCP PMI Page. Rank 55

Page rank based document similarity 17 -03 -2018 56

Compactness based on content Compactness based on hyperlink 17 -03 -2018 57

Separation based on content Separation based on hyperlink 17 -03 -2018 58

Our chosen evaluation metrices: • F 1, JI, RI, ARI • Baseline: • As content baseline we use the well-known Latent Dirichlet Allocation (LDA) technique over the documents [5]. • As a non-content baseline, we use the results reported by [4] Go S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural 17 -03 -2018 59 Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.

Results 17 -03 -2018 60
 Dimension 5 Dimension 10 S. Acharya, A. Ekbal, S. Saha, P.")
Results(SCP + PR) Dimension 5 Dimension 10 S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural 17 -03 -2018 61 Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.
 Dimension 5 Dimension 10 S. Acharya, A. Ekbal, S. Saha, P.")
Results(PMI + PR) Dimension 5 Dimension 10 S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural 17 -03 -2018 62 Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.
 Dimension 5 Dimension 10 S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J.")
Results(comparative) Dimension 5 Dimension 10 S. Acharya, A. Ekbal, S. Saha, P. Santhanam, J. G. Moreno, G. Dias(2016), "Multi-Objective Word Sense Induction based on Content and Interlink Connections", in the proceedings of 21 st International Conference on Applications of Natural 17 -03 -2018 63 Language to Information Systems(NLDB ), June 22 -24, Manchester, UK.

Conclusion and Future Works • Both content and hyperlink based similarity measure based clustering provides better WSI solutions w. r. t most of the chosen validity measures. • Needs some more sensitivity study of our proposed algorithm as the chosen task was quite complex. 17 -03 -2018 64

References 1. Di Marco, A. , Navigli, R. : Clustering and diversifying web search results with graph-based word sense induction. Computational Linguistics 39(4), 1– 43 (2013) 2. Lau, J. H. , Cook, P. , Baldwin, T. : unimelb: Topic modelling-based word sense induction for web snippet clustering. In: Proceedings of the 7 th International. Workshop on Semantic Evaluation (Sem. Eval 2013) (June 2013) 3. Martins, A. , Smith, N. , Xing, E. , Aguiar, P. , Figueiredo, M. : Nonextensive information theoretic kernels on measures. The Journal of Machine Learning Research 10, 935– 975 (2009) 4. Moreno, J. G. , Dias, G. : Pagerank-based word sense induction within web search results clustering. In: Proceedings of the 14 th ACM/IEEE-CS Joint Conference on Digital Libraries. pp. 465– 466. JCDL ’ 14 (2014) 5. Navigli, R. , Vannella, D. : Semeval-2013 task 11: Word sense induction & disambiguation within an end-user application. In: Proceedings of the International Workshop on Semantic Evaluation (SEMEVAL). pp. 1– 9 (2013) 6. Acharya, S. , Saha, S. , Moreno, J. G. , Dias, G. : Multi-objective search results clustering. In Proceedings of COLING 2014, the 25 th International Conference on Computational Linguistics. p. 99– 108 (2014) 7. S. Bandyopadhyay, S. Saha, U. Maulik, and K. Deb , A simulated annealing-based multiobjective optimization algorithm: Amosa , In IEEE transactions on evolutionary computation, pages 269? 283 , 2008. Baggio, Rodolfo, and Magda Antonioli Corigliano. "On the importance of hyperlinks: A network science approach. " Information and Communication Technologies in Tourism 2009 (2009): 309 -318 8. 17 -03 -2018 65

• A. Bernardini, C. Carpineto, M. D'Amico: Full-Subtopic Retrieval with Keyphrase. Based Search Results Clustering. Web Intelligence (WI) 2009: 206 -213 • R. Navigli. Word Sense Disambiguation: a Survey. ACM Computing Surveys, 41(2), 2009, pp. 1 -69. • R. Navigli, G. Crisafulli. Inducing Word Senses to Improve Web Search Result Clustering. Proc. of the 2010 Conference on Empirical Methods in Natural Language Processing (EMNLP 2010), MIT Stata Center, Massachusets, USA, pp. 116 -126. • A. Di Marco, R. Navigli. Clustering and Diversifying Web Search Results with Graph-Based Word Sense Induction. Computational Linguistics, 39(4), MIT Press, 2013. 17 -03 -2018 66

Thank you!! 17 -03 -2018 67

17 -03 -2018 68

Adjusted rand Index 17 -03 -2018 69

Rand Index 17 -03 -2018 70

Jaccard index 17 -03 -2018 71

F 1 index 17 -03 -2018 72

%Classification accuracy

Fß measure 3/17/2018

3/17/2018

Ratio of the number of relevant Records retrieved to the total Number of irrelevant and relevant Records retrieved. 3/17/2018 Ratio of the number of relevant records Retrieved to the total number of relevant records in the database.

Fb 3 measure Fb 3 is function of B cubed Precision and Recall 3/17/2018

3/17/2018
ed9415fe30b257d9b04e06ec9ed75545.ppt