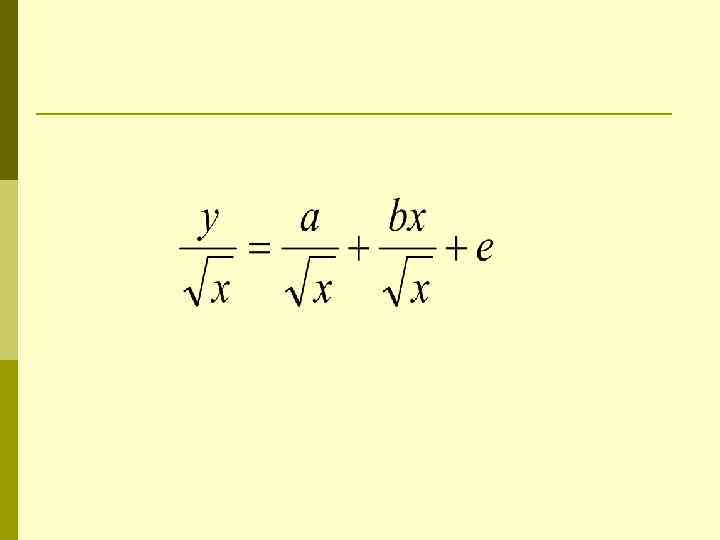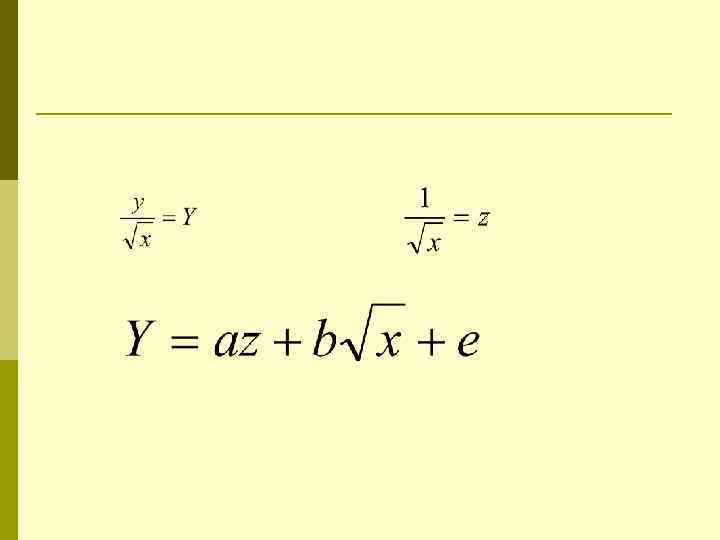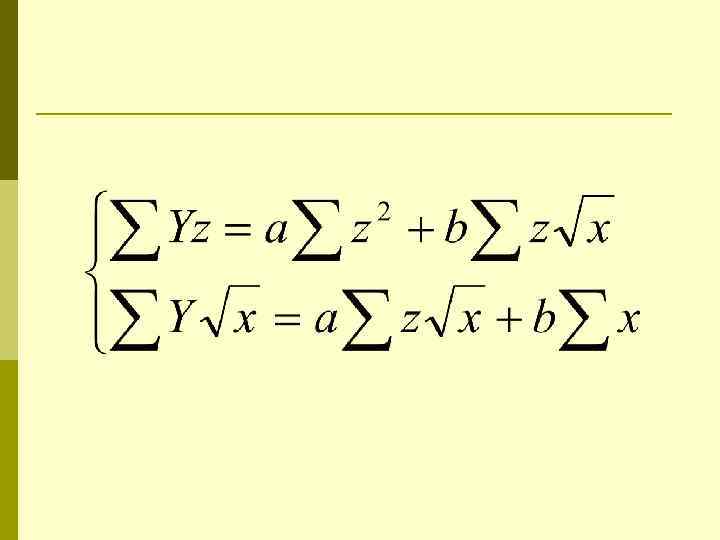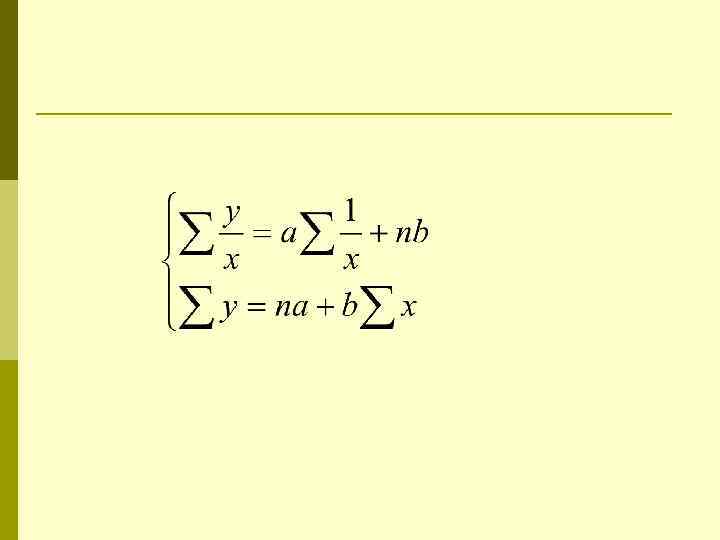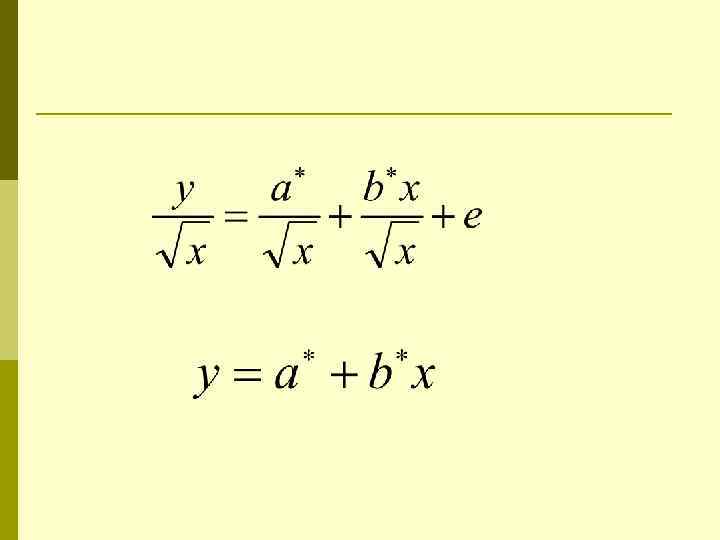Тема 3 Множественная регрессия 2010-2011..ppt
- Количество слайдов: 96
 Множественная регрессия корреляция
Множественная регрессия корреляция
 Множественная регрессия и корреля 1. 2. 3. 4. 5. 6. 7. Смысл множественной регрессии. Отбор факторов при построении модели множественной регрессии и выбор формы уравнения. Оценка параметров уравнения множественной регрессии. Показатели силы связи в модели множественной регрессии. Показатели тесноты связи. Оценка достоверности построенного уравнения. Использование фиктивных переменных в моделях регрессии. Проблемы, возникающие при построении регрессионных моделей: мультиколлинеарность и гетероскедастичность.
Множественная регрессия и корреля 1. 2. 3. 4. 5. 6. 7. Смысл множественной регрессии. Отбор факторов при построении модели множественной регрессии и выбор формы уравнения. Оценка параметров уравнения множественной регрессии. Показатели силы связи в модели множественной регрессии. Показатели тесноты связи. Оценка достоверности построенного уравнения. Использование фиктивных переменных в моделях регрессии. Проблемы, возникающие при построении регрессионных моделей: мультиколлинеарность и гетероскедастичность.
 МНОЖЕСТВЕННАЯ РЕГРЕССИЯ И КОРРЕЛЯЦИЯ
МНОЖЕСТВЕННАЯ РЕГРЕССИЯ И КОРРЕЛЯЦИЯ
 При отборе факторов в уравнение множественной ре необходимо соблюдать следующее условия: в модель нужно включать только существенные факторы, непосредственно формирующие результат p факторы должны быть количественно измерены p факторы не должны находиться в тесной взаимосвязи друг с другом (значение коэффициента корреляции между факторами, входящими в модель должно быть менее 0, 7) p
При отборе факторов в уравнение множественной ре необходимо соблюдать следующее условия: в модель нужно включать только существенные факторы, непосредственно формирующие результат p факторы должны быть количественно измерены p факторы не должны находиться в тесной взаимосвязи друг с другом (значение коэффициента корреляции между факторами, входящими в модель должно быть менее 0, 7) p
 Отбор факторов основан на: p теоретическом анализе взаимосвязи результата с кругом факторов p количественном анализе (на основе матрицы парных коэффициентов корреляции, матрицы частных коэффициентов корреляции, с помощью стандартизованных коэффициентов регрессии, на основе F, t-критериев
Отбор факторов основан на: p теоретическом анализе взаимосвязи результата с кругом факторов p количественном анализе (на основе матрицы парных коэффициентов корреляции, матрицы частных коэффициентов корреляции, с помощью стандартизованных коэффициентов регрессии, на основе F, t-критериев
 Отбор факторов на основе матрицы парн коэффициентов корреляции
Отбор факторов на основе матрицы парн коэффициентов корреляции
") Отбор факторов на основе матрицы парн коэффициентов корреляции (пример)
Отбор факторов на основе матрицы парн коэффициентов корреляции (пример)
 Наиболее часто используются следую функции:
Наиболее часто используются следую функции:
 Оценка параметров p p Для оценки параметров уравнения множественной регрессии применяют метод наименьших квадратов (МНК). Нелинейные функции приводятся к линейному виду по параметрам.
Оценка параметров p p Для оценки параметров уравнения множественной регрессии применяют метод наименьших квадратов (МНК). Нелинейные функции приводятся к линейному виду по параметрам.
 Пример
Пример
 Пример
Пример

 Пример
Пример
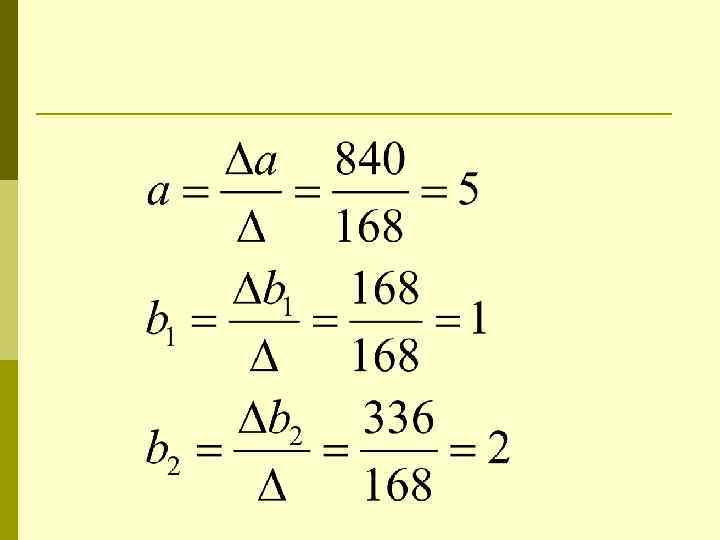
 Пример
Пример
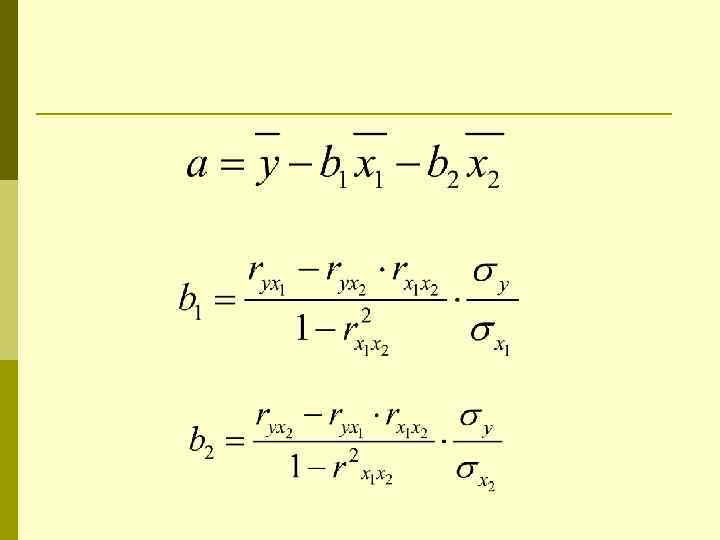
 Показатели силы связи в модели множественной регрессии p Абсолютные p Относительные Стандартизованные коэффициенты регрессии n Частные коэффициенты эластичности n
Показатели силы связи в модели множественной регрессии p Абсолютные p Относительные Стандартизованные коэффициенты регрессии n Частные коэффициенты эластичности n
 Абсолютные показатели силы связи p Показывают, на сколько единиц в среднем изменяется результативный признак при изменении рассматриваемого факторного признака на одну единицу при условии, что остальные факторы зафиксированы на среднем уровне и не меняются
Абсолютные показатели силы связи p Показывают, на сколько единиц в среднем изменяется результативный признак при изменении рассматриваемого факторного признака на одну единицу при условии, что остальные факторы зафиксированы на среднем уровне и не меняются
 Построение уравнения в стандартизованном виде
Построение уравнения в стандартизованном виде
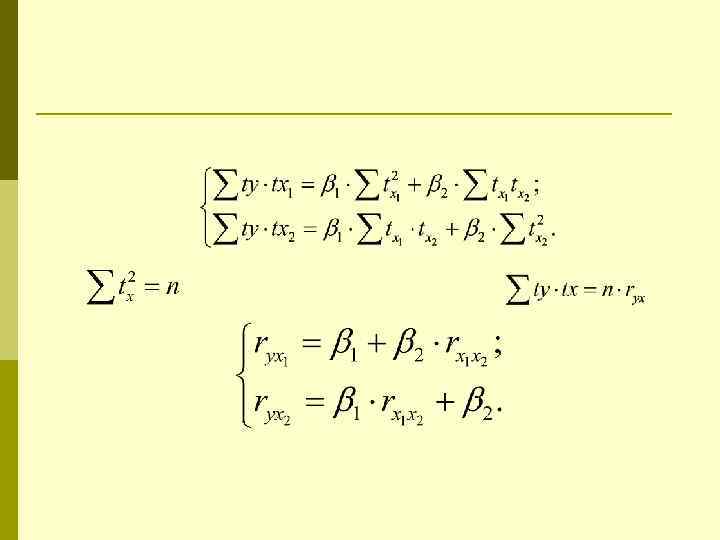
 Стандартизованные коэффициенты регрессии
Стандартизованные коэффициенты регрессии
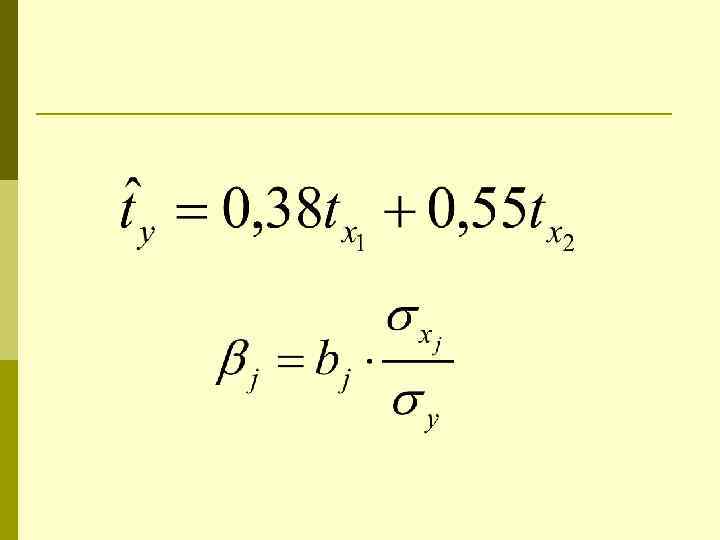
 Частные коэффициенты эластичности
Частные коэффициенты эластичности
 Частные коэффициенты эластичности
Частные коэффициенты эластичности
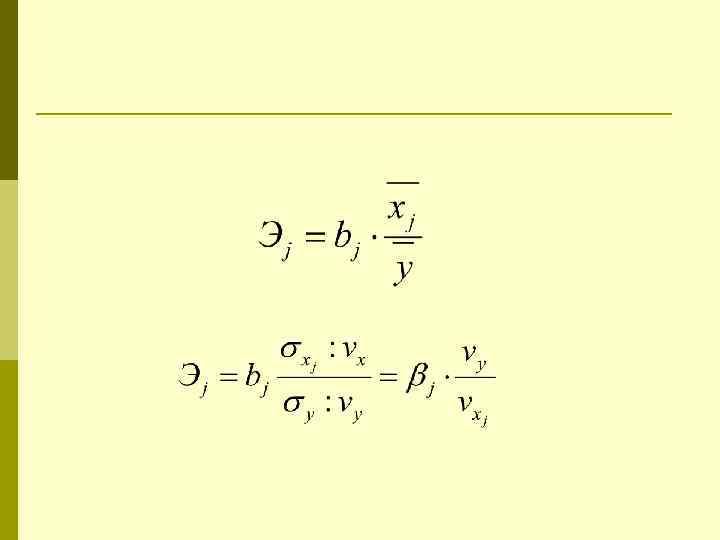
 Коэффициент множественной детерминации
Коэффициент множественной детерминации
 Пример
Пример
 Продолжение примера
Продолжение примера
 Продолжение примера. Расчет коэффициента детерминации для линей функции
Продолжение примера. Расчет коэффициента детерминации для линей функции
 Скорректированный коэффициент детерминации
Скорректированный коэффициент детерминации
 множественной корреляции") Коэффициент (индекс) множественной корреляции
Коэффициент (индекс) множественной корреляции
 Коэффициент множественной корреляции
Коэффициент множественной корреляции
 Показатели частной корреляции p основаны на соотношении сокращения остаточной вариации за счет дополнительно включенного в модель фактора к остаточной вариации до включения в модель соответствующего фактора
Показатели частной корреляции p основаны на соотношении сокращения остаточной вариации за счет дополнительно включенного в модель фактора к остаточной вариации до включения в модель соответствующего фактора
 Пример
Пример
 Продолжение примера
Продолжение примера
 Продолжение примера
Продолжение примера
 Показатели частной корреляции
Показатели частной корреляции
 Показатели частной корреляции
Показатели частной корреляции
 Оценка достоверности модели
Оценка достоверности модели
 Таблица дисперсионного анализа
Таблица дисперсионного анализа
 Оценка достоверности параметров
Оценка достоверности параметров
 Доверительные интервалы для оцениваемых параметров Доверительный интервал позволяет: n n Оценить значимость параметра (параметр будет значим, если в доверительный интервал не входит ноль). Дать экономическую интерпретацию коэффициента регрессии (с вероятностью (1‑α) при единичном изменении независимой переменной xj зависимая переменная у изменится не меньше, чем на bj, min и не больше, чем на bj, max.
Доверительные интервалы для оцениваемых параметров Доверительный интервал позволяет: n n Оценить значимость параметра (параметр будет значим, если в доверительный интервал не входит ноль). Дать экономическую интерпретацию коэффициента регрессии (с вероятностью (1‑α) при единичном изменении независимой переменной xj зависимая переменная у изменится не меньше, чем на bj, min и не больше, чем на bj, max.
 Оценка достоверности параметров
Оценка достоверности параметров
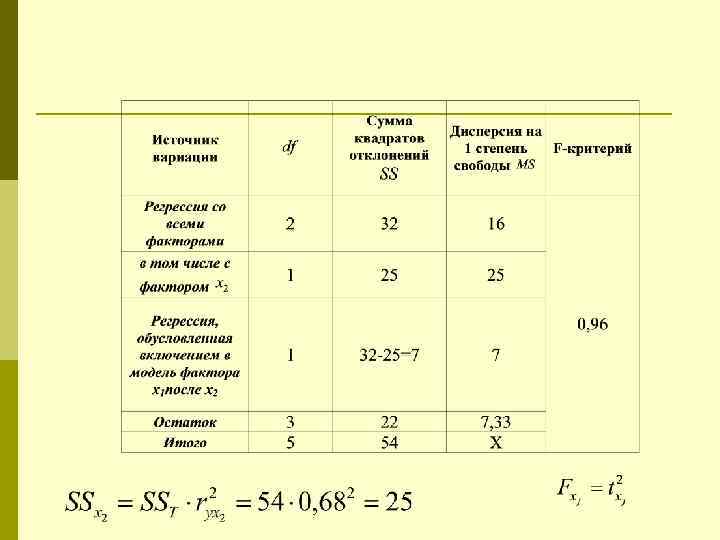
 Частные F-критерии
Частные F-критерии
 p - остаточная сумма квадратов для модели без фактора xj p - остаточная сумма квадратов для модели с фактором xj
p - остаточная сумма квадратов для модели без фактора xj p - остаточная сумма квадратов для модели с фактором xj
 Частные F-критерии
Частные F-критерии
 Критерии выбора наилучшей функц p p Минимальная доля остаточной дисперсии в общей дисперсии, то есть максимальная величина коэффициента детерминации R 2. Если модели регрессии содержат разное количество параметров, вместо R 2 следует сравнивать скорректированные коэффициенты детерминации R 2 скорр. Статистическая значимость всех параметров при независимых переменных. Значимость всей функции в целом. Выполнение требований Гаусса-Маркова, предъявляемых к случайным остаткам модели, в первую очередь, постоянство дисперсии и независимость друг от друга.
Критерии выбора наилучшей функц p p Минимальная доля остаточной дисперсии в общей дисперсии, то есть максимальная величина коэффициента детерминации R 2. Если модели регрессии содержат разное количество параметров, вместо R 2 следует сравнивать скорректированные коэффициенты детерминации R 2 скорр. Статистическая значимость всех параметров при независимых переменных. Значимость всей функции в целом. Выполнение требований Гаусса-Маркова, предъявляемых к случайным остаткам модели, в первую очередь, постоянство дисперсии и независимость друг от друга.

 –это переменные, принимающие два значения") Использование фиктивных переменных моделях регрессии p Фиктивные переменные(dummy variables) –это переменные, принимающие два значения – единица и ноль:
Использование фиктивных переменных моделях регрессии p Фиктивные переменные(dummy variables) –это переменные, принимающие два значения – единица и ноль:
 Использование фиктивных переменных моделях регрессии n при моделировании качественных признаков n для учета структурной неоднородности, к которой приводят качественные признаки n для оценки сезонных колебаний
Использование фиктивных переменных моделях регрессии n при моделировании качественных признаков n для учета структурной неоднородности, к которой приводят качественные признаки n для оценки сезонных колебаний
 Общий вид модели с фиктивными переменными где у – переменная – результат; х1, х2, …хp – количественные переменные-факторы; z 11, z 12 – фиктивные переменные, соответствующие значениям первой неколичественной переменной-фактора; z 21, z 22 – фиктивные переменные, соответствующие значениям второй неколичественной переменной-фактора; zj 1, zj 2 – фиктивные переменные, соответствующие значениям j-й неколичественной переменной-фактора; e – случайный остаток.
Общий вид модели с фиктивными переменными где у – переменная – результат; х1, х2, …хp – количественные переменные-факторы; z 11, z 12 – фиктивные переменные, соответствующие значениям первой неколичественной переменной-фактора; z 21, z 22 – фиктивные переменные, соответствующие значениям второй неколичественной переменной-фактора; zj 1, zj 2 – фиктивные переменные, соответствующие значениям j-й неколичественной переменной-фактора; e – случайный остаток.
 равен: pпри z 11=0") Модели с фиктивной переменной сдвига pпри z 11=1 результат (у) равен: pпри z 11=0 результат (у) равен: . ,
Модели с фиктивной переменной сдвига pпри z 11=1 результат (у) равен: pпри z 11=0 результат (у) равен: . ,
 на результат (у) не зависит от значения") Сила влияния количественного фактора (х 1 ) на результат (у) не зависит от значения фиктивной переменной ( z 11 )
Сила влияния количественного фактора (х 1 ) на результат (у) не зависит от значения фиктивной переменной ( z 11 )
 Пример
Пример
 Пример
Пример
 Пример
Пример
 Пример
Пример
 p; p. Модели регрессии с фиктивными перемен наклона p. При z=1 p. При p. Если z=0 ; ; . рассмотреть это уравнение для z 11=1 и для z 11=0 получим соответственно:
p; p. Модели регрессии с фиктивными перемен наклона p. При z=1 p. При p. Если z=0 ; ; . рассмотреть это уравнение для z 11=1 и для z 11=0 получим соответственно:
 на результат (у) зависит от значения фиктивной") Сила влияния количественного фактора (х 1 ) на результат (у) зависит от значения фиктивной переменной ( z 11 )
Сила влияния количественного фактора (х 1 ) на результат (у) зависит от значения фиктивной переменной ( z 11 )
 Фиктивные переменные в нелинейн моделях y x lny lnx z
Фиктивные переменные в нелинейн моделях y x lny lnx z
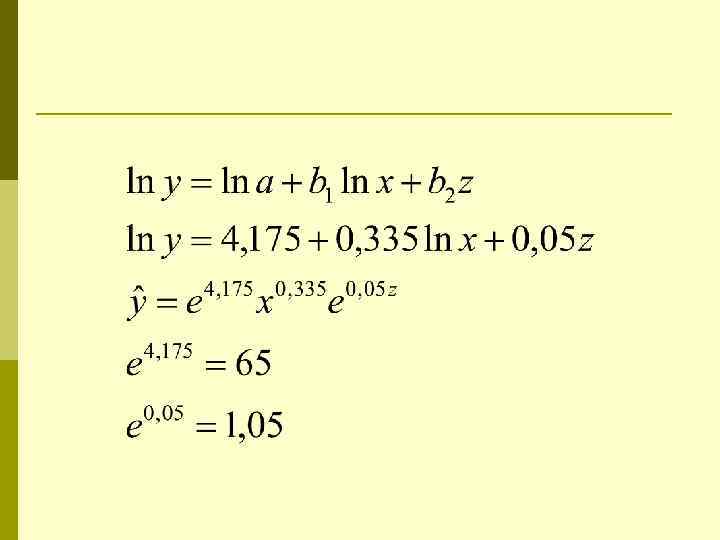
 p Параметр представляет собой среднее значение результативного признака при p Параметр b 1 и b 2 характеризует разность средних уравнений результативного признака для группы 1 и базовой группы 0 Параметр b 2 характеризует разность средних уравнений результативного признака для группы 2 и базовой группы 0 p
p Параметр представляет собой среднее значение результативного признака при p Параметр b 1 и b 2 характеризует разность средних уравнений результативного признака для группы 1 и базовой группы 0 Параметр b 2 характеризует разность средних уравнений результативного признака для группы 2 и базовой группы 0 p
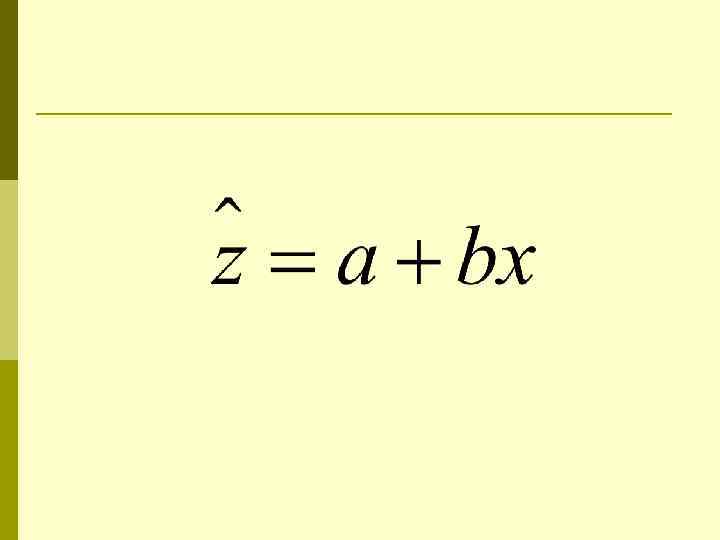
 Пример
Пример
 Исследование структурных изменений помощью теста Чоу p Используется для оценки целесообразности фиктивных переменных. Алгоритм: n n Совокупность разбивается по определенному критерию на две части. Находят параметры трех уравнений регрессии. Первое уравнение строится для всей совокупности наблюдений, второе и третье – для соответствующих выделенных групп. Для каждого трех уравнений находят остаточную сумму квадратов SSЕ (обозначим SS 0 для уравнения по всей совокупности и SS 1 и SS 2 для уравнений по выделенным группам). Определяют фактическое значение F‑критерия по формуле:
Исследование структурных изменений помощью теста Чоу p Используется для оценки целесообразности фиктивных переменных. Алгоритм: n n Совокупность разбивается по определенному критерию на две части. Находят параметры трех уравнений регрессии. Первое уравнение строится для всей совокупности наблюдений, второе и третье – для соответствующих выделенных групп. Для каждого трех уравнений находят остаточную сумму квадратов SSЕ (обозначим SS 0 для уравнения по всей совокупности и SS 1 и SS 2 для уравнений по выделенным группам). Определяют фактическое значение F‑критерия по формуле:
 в") p Где m 1 и m 2 – количество параметров (без свободного члена) в уравнениях, построенных по подмножествам, m – количество параметров (без свободного члена) для уравнения, построенного по всей совокупности, n – число наблюдений по всей совокупности. p Табличное значение F–критерия находят для степеней свободы df 1=m 1+m 2+1‑m и df 2=n-m 1 -m 2 -2. p Если фактическое значение окажется больше табличного, то имеют место структурные сдвиги и целесообразно строить уравнение регрессии с соответствующей фиктивной переменной.
p Где m 1 и m 2 – количество параметров (без свободного члена) в уравнениях, построенных по подмножествам, m – количество параметров (без свободного члена) для уравнения, построенного по всей совокупности, n – число наблюдений по всей совокупности. p Табличное значение F–критерия находят для степеней свободы df 1=m 1+m 2+1‑m и df 2=n-m 1 -m 2 -2. p Если фактическое значение окажется больше табличного, то имеют место структурные сдвиги и целесообразно строить уравнение регрессии с соответствующей фиктивной переменной.
 Пример. Стоимость проезда в электричках и поездах дальнего следования из Сан Петербурга в зависимости от расстояния Расстояние, х1, км Тип поезда, z 11 Стоимость проезда, y, руб. Платформа 39 0 45 Платформа 152 0 144 Мга 42 0 54 М. Вишера 162 0 153 Платформа 44 0 54 Мга 42 1 98, 1 Платформа 47 0 54 Волхов 114 1 124, 9 Платформа 63 0 63 Чудово 118 1 155, 2 Платформа 67 0 72 Приозерск 141 1 137, 4 Платформа 69 0 72 Луга 147 1 137, 4 Платформа 78 0 81 М. Вишера 162 1 145, 5 Волхов 114 0 117 Новгород 192 1 198, 5 Чудово 118 0 117 Тихвин 192 1 157, 6 Платформа 138 0 135 Пикалево 230 1 169, 7 235 1 169, 7 Станция назначения Будогощь 140 0 135 Лодейное поле Приозерск 141 0 135 Подпорожье 272 1 189, 8 Луга 147 0 135 Псков 284 1 189, 8 Платформа 148 0 144 Бологое 319 1 227, 9
Пример. Стоимость проезда в электричках и поездах дальнего следования из Сан Петербурга в зависимости от расстояния Расстояние, х1, км Тип поезда, z 11 Стоимость проезда, y, руб. Платформа 39 0 45 Платформа 152 0 144 Мга 42 0 54 М. Вишера 162 0 153 Платформа 44 0 54 Мга 42 1 98, 1 Платформа 47 0 54 Волхов 114 1 124, 9 Платформа 63 0 63 Чудово 118 1 155, 2 Платформа 67 0 72 Приозерск 141 1 137, 4 Платформа 69 0 72 Луга 147 1 137, 4 Платформа 78 0 81 М. Вишера 162 1 145, 5 Волхов 114 0 117 Новгород 192 1 198, 5 Чудово 118 0 117 Тихвин 192 1 157, 6 Платформа 138 0 135 Пикалево 230 1 169, 7 235 1 169, 7 Станция назначения Будогощь 140 0 135 Лодейное поле Приозерск 141 0 135 Подпорожье 272 1 189, 8 Луга 147 0 135 Псков 284 1 189, 8 Платформа 148 0 144 Бологое 319 1 227, 9
 Пример p p Исследовалась зависимость стоимости проезда от расстояния и типа поезда (в электричках и в поездах дальнего следования. Определим параметры уравнения для массивов данных: n n n для всех данных (n=30); для данных о стоимости проезда в электричках (n=17); для данных о стоимости проезда в поездах дальнего следования (n=13).
Пример p p Исследовалась зависимость стоимости проезда от расстояния и типа поезда (в электричках и в поездах дальнего следования. Определим параметры уравнения для массивов данных: n n n для всех данных (n=30); для данных о стоимости проезда в электричках (n=17); для данных о стоимости проезда в поездах дальнего следования (n=13).
 Уравнения регрессии и значения сумм квадратов остатков p По всем типам поездов: Для проезда в электричках: p Для проезда в поездах дальнего следования: p Фактическое значение F-критерия равно: p Табличное значение F-критерия равно 3, 37 (при =0, 05 и df 1=1+1+1‑ 1=2 и df 2=30 1 1 2=26 степенях свободы). p
Уравнения регрессии и значения сумм квадратов остатков p По всем типам поездов: Для проезда в электричках: p Для проезда в поездах дальнего следования: p Фактическое значение F-критерия равно: p Табличное значение F-критерия равно 3, 37 (при =0, 05 и df 1=1+1+1‑ 1=2 и df 2=30 1 1 2=26 степенях свободы). p
 p Так как фактическое значение Fкритерия больше табличного, следует признать существенность различия характеристик зависимости стоимости проезда от расстояния для разных типов поездов. Следовательно, для каждого типа поезда следует строить свое уравнение регрессии или объединить их в одно, используя фиктивную переменную.
p Так как фактическое значение Fкритерия больше табличного, следует признать существенность различия характеристик зависимости стоимости проезда от расстояния для разных типов поездов. Следовательно, для каждого типа поезда следует строить свое уравнение регрессии или объединить их в одно, используя фиктивную переменную.
 Проблемы, возникающие при построении регрессионных моделей p. Мультиколлинеарность p. Гетероскедастичность
Проблемы, возникающие при построении регрессионных моделей p. Мультиколлинеарность p. Гетероскедастичность
 Симптомы мультиколлинеарности p p p Завышенное значение коэффициента детерминации Высокие стандартные ошибки для коэффициентов регрессии Широкие доверительные интервалы Низкое значение t-критерия Появление при коэффициентах регрессии знаков, противоположных ожидаемым Значительные изменения параметров модели при небольшом сокращении (увеличении) объема исследуемой совокупности
Симптомы мультиколлинеарности p p p Завышенное значение коэффициента детерминации Высокие стандартные ошибки для коэффициентов регрессии Широкие доверительные интервалы Низкое значение t-критерия Появление при коэффициентах регрессии знаков, противоположных ожидаемым Значительные изменения параметров модели при небольшом сокращении (увеличении) объема исследуемой совокупности
 Выявление мультиколлинеарности с помощью матри парных коэффициентов корреляции p p Наличие мультиколлинеарности можно подтвердить, найдя определитель матрицы. Если связь между независимыми переменными полностью отсутствует, то недиагональные элементы будут равны нулю, а определитель матрицы ‑ единице. Если связь между независимыми переменными близка к функциональной (то есть является очень тесной), то определитель матрицы будет близок к нулю.
Выявление мультиколлинеарности с помощью матри парных коэффициентов корреляции p p Наличие мультиколлинеарности можно подтвердить, найдя определитель матрицы. Если связь между независимыми переменными полностью отсутствует, то недиагональные элементы будут равны нулю, а определитель матрицы ‑ единице. Если связь между независимыми переменными близка к функциональной (то есть является очень тесной), то определитель матрицы будет близок к нулю.
 Меры по устранению мультиколлинеарно p p p Удаление из модели переменных с высоким коэффициентом парной корреляции между факторами, если это не противоречит теории, положенной в основу построения модели Увеличение числа наблюдений Изменение функциональной формы модели Функциональные преобразования тесно связанных между собой переменных. Например, поступление налогов в городах зависит от количества жителей и площади города. Очевидно, что эти переменные будут тесно связаны. Их можно заменить одной относительной переменной «плотность населения» Построение моделей по отклонениям от средней величины Использование специальных методов обработки временных рядов
Меры по устранению мультиколлинеарно p p p Удаление из модели переменных с высоким коэффициентом парной корреляции между факторами, если это не противоречит теории, положенной в основу построения модели Увеличение числа наблюдений Изменение функциональной формы модели Функциональные преобразования тесно связанных между собой переменных. Например, поступление налогов в городах зависит от количества жителей и площади города. Очевидно, что эти переменные будут тесно связаны. Их можно заменить одной относительной переменной «плотность населения» Построение моделей по отклонениям от средней величины Использование специальных методов обработки временных рядов
 Гетероскедастичность p Основные предпосылки МНК: n n n случайный характер остатков нулевая средняя остатков, не зависящая от фактора x гомоскедастичность (дисперсия каждого отклонения одинакова для всех значений x) отсутствие автокорреляции остатков остатки должны подчиняться нормальному распределению
Гетероскедастичность p Основные предпосылки МНК: n n n случайный характер остатков нулевая средняя остатков, не зависящая от фактора x гомоскедастичность (дисперсия каждого отклонения одинакова для всех значений x) отсутствие автокорреляции остатков остатки должны подчиняться нормальному распределению
 дисперсия остатков увеличивается с увеличением") Зависимость остатков от выровненного значения результата нет зависимости (гомоскедастичность) дисперсия остатков увеличивается с увеличением выровненного значения результата (один из случаев гетероскедастичности
Зависимость остатков от выровненного значения результата нет зависимости (гомоскедастичность) дисперсия остатков увеличивается с увеличением выровненного значения результата (один из случаев гетероскедастичности
 Причины гетероскедастичности p Неверная функциональная форма модели p Неоднородность совокупности
Причины гетероскедастичности p Неверная функциональная форма модели p Неоднородность совокупности
 Меры по устранению гетероскедастичности Увеличение числа наблюдений p Изменение функциональной формы модели p Разделение исходной совокупности на качественно-однородные группы и проведение анализа в каждой группе p Использование фиктивных переменных, учитывающих неоднородность p Исключение из совокупности единиц, дающих неоднородность p
Меры по устранению гетероскедастичности Увеличение числа наблюдений p Изменение функциональной формы модели p Разделение исходной совокупности на качественно-однородные группы и проведение анализа в каждой группе p Использование фиктивных переменных, учитывающих неоднородность p Исключение из совокупности единиц, дающих неоднородность p
 Тесты, используемые для выявления гетероскедастичности p Гольдфельда-Квандта p Парка p Глейзера p Уайта p Ранговой корреляции Спирмена
Тесты, используемые для выявления гетероскедастичности p Гольдфельда-Квандта p Парка p Глейзера p Уайта p Ранговой корреляции Спирмена
 Тест Гольдфельда-Квандта p Все наблюдения упорядочивают по мере возрастания какого-либо фактора, который, как предполагается, оказывает влияние на возрастание дисперсии остатков. p Упорядоченную совокупность делят на три группы, причем первая и последняя должны быть равного объема с числом единиц, больших, чем число параметров модели регрессии. Число отобранных единиц обозначим k p По первой и третьей группе находят параметры уравнений регрессии и остатки по ним. p Используя данные об остатках моделей первой и третьей группы, рассчитывают фактическое значение F-критерия
Тест Гольдфельда-Квандта p Все наблюдения упорядочивают по мере возрастания какого-либо фактора, который, как предполагается, оказывает влияние на возрастание дисперсии остатков. p Упорядоченную совокупность делят на три группы, причем первая и последняя должны быть равного объема с числом единиц, больших, чем число параметров модели регрессии. Число отобранных единиц обозначим k p По первой и третьей группе находят параметры уравнений регрессии и остатки по ним. p Используя данные об остатках моделей первой и третьей группы, рассчитывают фактическое значение F-критерия
 Тест Гольдфельда-Квандта df 1=df 2=k-m-1
Тест Гольдфельда-Квандта df 1=df 2=k-m-1
 Тест Парка
Тест Парка
 Тест Глейзера p k – какое-либо число, например, k= – 1; – 0, 5; 1
Тест Глейзера p k – какое-либо число, например, k= – 1; – 0, 5; 1
 Тест Уайта
Тест Уайта
 Тест ранговой корреляции Спирмена
Тест ранговой корреляции Спирмена
") Обобщенный метод наименьших квадратов (ОМНК)
Обобщенный метод наименьших квадратов (ОМНК)
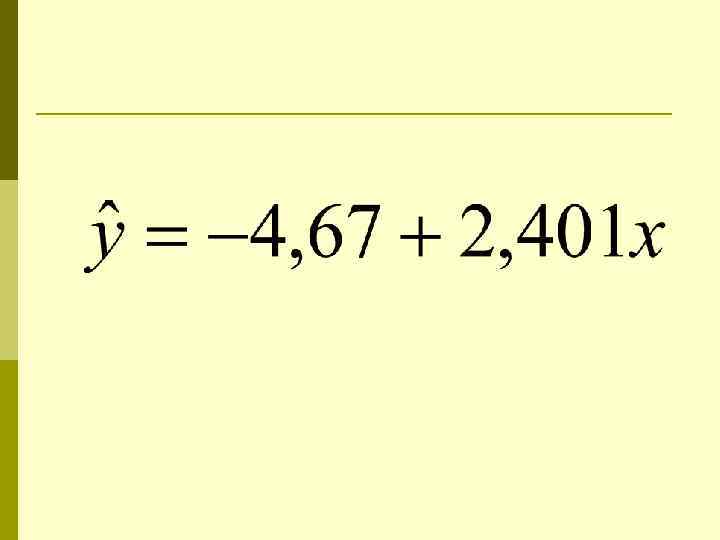
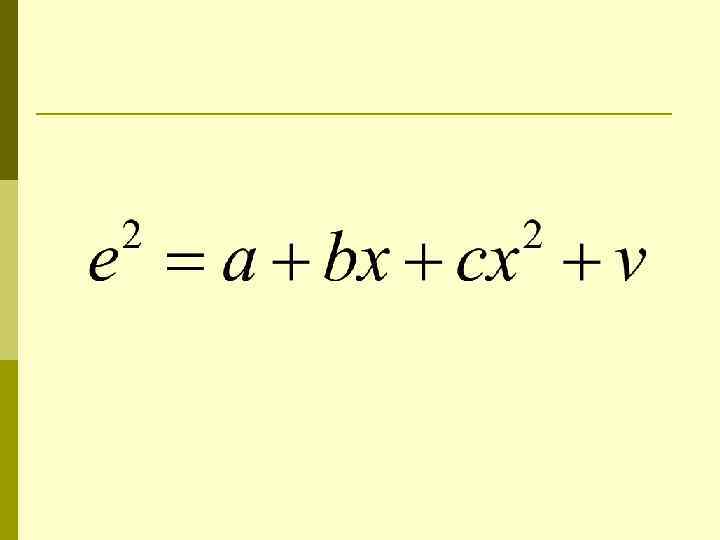
 p Выдвигается гипотеза, что дисперсия остатков пропорциональна x 2
p Выдвигается гипотеза, что дисперсия остатков пропорциональна x 2