0a0ae1a1f869c804e74d2062b0603898.ppt
- Количество слайдов: 122



Methodology of the ResearchМетодология исследования Выбор методов исследования доц. Касимовская Е. Н

Выбор методики исследования На этапе сбора данных следует выделить несколько главных вопросов: Стадия • для каких целей собираются данные? операционализа • что именно нужно измерять? ции проблемы • с какой точностью нужно измерять? • какое количество данных нам требуется? • каким способом следует выбирать данные? Ответы на первые три вопроса должны быть даны на стадии формулирования проблемы, гипотез иили вопросов исследования
 исследования. • Оценка")
Задача построения информационного запроса • Составление структурной схемы показателей предмета (предметов) исследования. • Оценка возможности измерения каждого из показателей конкретным индикатором. Поиск структурных субпоказателей. • Доведение конкретизации показателей до такой ступени, чтобы каждому из них мог соответствовать вопрос анкеты (или переменная).
 Величина (2) Надежность (\"истинность\") Соотношение между")
Масштаб исследования Основные черты зависимости между переменными: (1) Величина (2) Надежность ("истинность") Соотношение между значимостью и количеством испытаний (выполненных анализов)? Слабые связи могут быть значимо доказаны только на больших выборках

Генеральная совокупность и выборка n n n Какое количество данных нам требуется? Определение 1: Исследуемая совокупность единиц называется генеральной совокупностью. Определение 2: Выборка – подмножество единиц генеральной совокупности.

Генеральная совокупность и выборка Генеральная совокупность Выборка Наилучший подход: каждый участник генеральной совокупности имеет равную вероятность быть включенным в выборку
 1. Синоним понятия «выборочная совокупность» — часть населения (популяции, population), которая,")
Понятие «выборка» (sample) 1. Синоним понятия «выборочная совокупность» — часть населения (популяции, population), которая, подвергается опросуисследуется, с тем чтобы полученные результаты могли быть распространены на изучаемую популяцию в целом 2. Процесс отбора единиц наблюдения (технология, способы и методы такого отбора определяют тип выборки)

Построение выборки 1. Определение объема выборки (например, количества человек, которых следует опросить для получения качественной информации) 2. Определение типа выборки — построение конкретной схемы процедуры отбора 3. Оценка качества выборки — определение, с какой вероятностью и степенью точности результаты опроса выборочной совокупности можно будет переносить на ту или иную часть популяции (генеральной совокупности)

Основной вопрос – как велика она должна быть? n n n Абсолютные размеры выборки. Важнее именно абсолютный размер, а не относительный. Чем больше выборка, тем больше вероятность отразить характеристики генеральной совокупности ( меньше вероятность сделать ошибку, это следует из закона больших чисел). Статистики и Central Limit Theorem: чем больше размер выборки, тем ближе распределение к нормальному типу. Минимальный размер стат. Выборки – более 30 наблюдений. Пределы ошибки ( margin error): ожидаемая ошибка связана с размерами выборки. Считается, что ошибка в 5% ( т. е. 95%-ная вероятность) – это допустимый максимум для аккуратного исследования ( больше нельзя!!!)

Продолжение– как велика она должна быть? n n n Время и затраты. Большая выборка требует больше времени и затрат, результат задерживается, маленькая выборка может оказаться нерепрезентативной и не отражать основные закономерности исследуемой совокупности. «Безответность» респондентов. Часть опрашиваемых не заполняет анкеты, другие запоняют неправильно и т. д. Важно определить актуальный уровень ответов и рассчитать размер необходимой выборки с учетом этого. Вариации ( различия) в изучаемой совокупности. Если различия велики, то размер выборки должен быть больше.

Качество информации Репрезентативность - свойство выборочной совокупности воспроизводить характеристики генеральной Надежность - определенная гарантия того, что полученный результат правильно отражает изучаемую действительность Валидность (обоснованность) информации - подтверждение (доказательство), что исследовались (измерялись) именно те явления, которые предполагалось исследовать Проверка устойчивости - основная и контрольная группы
 - одно из ключевых понятий анализа")
Репрезентативность выборки n n Репрезентативная выборка (representative sample) - одно из ключевых понятий анализа данных. Репрезентативная выборка - это выборка из генеральной совокупности с распределением F(x), представляющая основные особенности генеральной совокупности. ПРИМЕР: если в городе проживает 100 000 человек, половина из которых мужчины и половина женщины, то выборка 1000 человек из которых 10 мужчин и 990 женщин, конечно, не будет репрезентативной. Построенный на ее основе опрос общественного мнения, конечно, будет содержать смещение оценок и приводит к фальсификации результатов. Необходимым условием построения репрезентативной выборки является равная вероятность включения в нее каждого элемента генеральной совокупности.

Репрезентативность выборки: как посчитать? ? ? n n n Формула для расчета учитывает доверительный интервал и вероятность ошибки ( обычно на уровне 0. 05, т. е. Ошибка 5%) Он лайн калькуляторы: www. allcalc. ru и пр Пример:

Каким способом следует выбирать данные? • • Выборка имеет больше шансов быть репрезентативной, если она построена таким образом, что (1) каждый объект генеральной совокупности имеет одинаковую вероятность быть отобранным и (2) объекты отбираются независимо друг от друга. Есть несколько методов извлечения выборки: ü применение таблиц случайных чисел, ü метод перемешивания генеральной совокупности, ü стратифицированная случайная выборка, ü систематическая выборка.

Типы выборок n Основной принцип – принцип рандомизации случайности n Случайная выборка -Random Sampling=Probability sampling ( на основе таблицы случайных чисел) n Систематическая случайная выборка – Systemic Sample n Стратифицированная случайная выборка – Stratified sampling ( учитывает конкретные характеристикипеременные в выборке, например, пол, возраст и пр)

Примеры Систематическая выборка: Население: 300 Величина выборки: 10 30010=30 Начинаем со случайного выбора числа в промежутке от 1 до 30. Например, 23. Затем берем каждое 30 е показание, пока не наберем 10: 23, 53, 83, 113, 143, 173, 203, 233, 263, 293 n
 n n Шаг 1. Пронумеруйте все")
Пример: метод перемешивания генеральной совокупности (с использованием Excel) n n Шаг 1. Пронумеруйте все элементы генеральной совокупности от 1 до N и введите эти порядковые номера в первый столбец таблицы Excel. Шаг 2. В верхнюю ячейку второго столбца введите формулу =СЛЧИС() и скопируйте эту ячейку вниз по столбцу, чтобы получить случайное число напротив каждого номера. Шаг 3. Выделив оба столбца (с номером элементов в основе выборки и со случайными числами), выполните команду Данные->Сортировка из меню Excel. Сортировка по столбцу со случайными числами. После этого, числа в первом столбце будут упорядочены случайным образом, и для получения искомой случайной выборки достаточно будет взять первые n элементов.
 Величина выборки: 100 580/850 Х")
Примеры: стратифицированная выборка Население: 850(580 женщин и 270 мужчин) Величина выборки: 100 580/850 Х 100=68 женщин 270/850 Х 100=32 мужчин

Другие типы выборок n n n Convenience Sampling( «до кого легче добраться» , слабо репрезентативна, исп. При пилотных исследованиях) Snowball Sampling Multi-stage cluster sampling ( случайная выборка + геогр. кластеры) Purposive Sampling ( на основе суждения исследователя) Non-Probability Sample И т. д.

Классификация исследований По типу собранных данных методы исследований можно подразделить на • Качественные • Количественные

Качественное исследование Как? Почему? Зачем? Рекомендуется, когда необходимо качественное описание какого-либо процесса. Примеры: Как потребитель осуществляет выбор того или иного товара? Каковы мотивы поведения избирателей?
 Case Studies")
Примеры качественных исследований Опросы анкетирование интервью Фокус-группы ( обычно 6 -8 человек) Case Studies Action Research Наблюдение ( структурированное) Дневник участника Этнографические исследования Эксперимент
")
Типы интервью n n n Structured – на основе опросника ( довольно строго) Semi-structured – на основе опросника, но можно отклоняться + личные впечатления Unstructured (= in-depth interview)
 Осознанная (знания и уверенность (вера)) Поведенческая - предрасположенность (готовность)")
Компоненты «отношения» Эмоциональная (чувства, эмоции) Осознанная (знания и уверенность (вера)) Поведенческая - предрасположенность (готовность) к действиям - намерения - поведенческие ожидания

Мнения и отношения Суждения Отношение Ценности Индивидуальность Социум

Способы измерения «отношения» Ранжирование n Рейтингование n Сортировка n Выбор n

Способы измерения «отношения» Ранжирование – требуется, чтобы опрашиваемые выстроили по порядку небольшое количество объектов на основе какого-то указанного им принципа Рейтинг - требуется, чтобы опрашиваемые определили положение объекта на предложенной им шкале в соответствии с своим восприятием свойств (качеств) объекта. Сортировка – требуется сгруппировать объекты на основе определенного критерия или экспертного знания Выбор – требуется выбрать из двух или более альтернатив Психологические способы измерения – определение отношения без вербального ответа опрашиваемого (например, по изменению кровяного давления)

Требования к анкете - целенаправленность; - простота (четкость, понятность, краткость вопросов, по возможности допускающая ответы «да» или «нет» ); - однозначность понимания вопросов, что предполагает однозначные на них ответы; - нейтральность (невозможность практического использования ответов против опрашиваемого); - логическая последовательность (от простого к сложному, от общего к частному, конкретизирующему)
: общие n n n Списочные– выбрать любой ответ")
Типы анкетвопросов с вариантами ( close-end): общие n n n Списочные– выбрать любой ответ Категориальные – выбрать ОДИН ответ ( multiple choice) Ранжирование ( ranking) – расставить по порядку Рейтингование (rating) – оценить, раставить оценки ответам Количественные – ответить числомвеличиной Табличные (grid) – заполнить матрицу с более чем одним ответом

Доп. Вопросы и техники n n n n Вопросы по персональным данным – возраст, образование, пол, соц. Статус и пр. Рейтинговая шкала Ликерта: сила ответа ( strongly agree – strongly disagree) в кол. выражении Рейтинговая шкала Ликерта: то же самое в вербальной форме Семантический дифференциал – противоположные характеристики на противополжных концах численной шкалы Шкала частот – вербальная или численаямежду «всегда» и «никогда» Данет Верноневерно

ПРИМЕР: шкала Ликерта
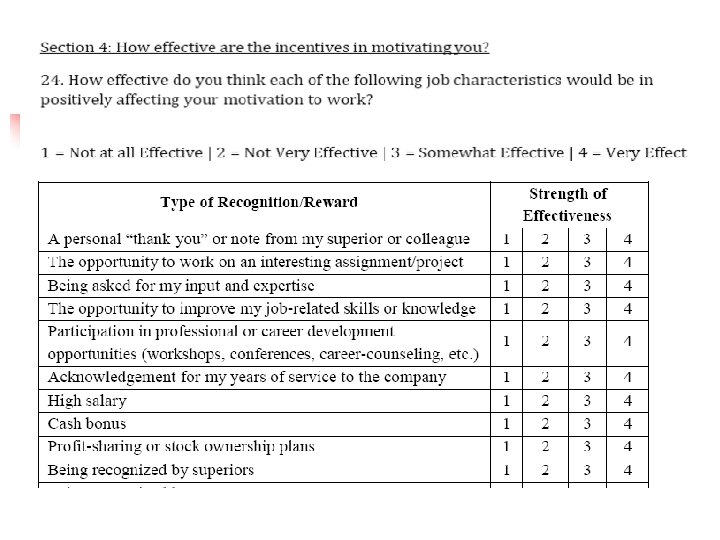

Open question format n n n «Открытый лист» - неск. вопросов без вариантов ответов. Ответ дается в свободной форме Open essay – комментарий в свободной форме. Обычно – в заключение анкеты Вопрос о личном мнении Вопрос о личном поведении Vignette or scenario – вопрос включен в контекст, описание ситуации. Дается в свободной форме

Общие правила анкетирования n n n n n Объясните цель анкетирования участникам Старайтесь, чтобы вопросы были максимально простыми Не используйте слэнг или профессиональный жаргон Избегайте двусмысленности и вопросов в негативной форме Избегайте неконкретных определений типа «большой. Маленький» Задавайте вопросы, ТОЛЬКО связанные с темой ( а не все, которые пришли Вам в голову) Включайте вопросы, которые являются проверочными для ответов на другие вопросы Избегайте вопросов, требующих расчетов Избегайте наводящих вопросов, обидных и агрессивных вопросов Постарайтесь, чтобы список вопросов был как можно короче, но включал все необходимые для достижения цели
 Базовый пакет ( 10 вопросов в")
Полезные ресурсы www. surveymonkey. com (www. zoomerang. com) Базовый пакет ( 10 вопросов в анкете, 100 ответов/опрос) – бесплатно n www. qualtrics. com n www. surveysystem. com n www. statsoft. ru n Электронный учебник по статистике и эконометрике

Программные пакеты для анализа данных качественных исследований n n n CAQDAS – computer-assisted qualitative data analysis software NVivo – www. qsrinternational. com AQUAD 7 – www. aquad. de

Количественное исследование Сколько? Каков вид взаимосвязи? Связано с операционализацией проблемыгипотезы Рекомендуется, когда необходима ( и возможна) количественная оценка существующих взаимосвязей

Количественный анализ данных n n n Статистика - это набор методов и теорий, применяемых для количественного анализа данных ( для принятия решения в условиях неопределенности) Позволяет распознать и оценить ошибки количественного измерения параметров Два типа кол. анализа: n разведочный анализ данных ( или описательная статистика) используется для обобщения и представления данных n подтверждающий анализ ( confirmatory data analysis) позволяет обработать данные , сделать выводы и построить прогнозы
 n n Параметрические методы применяются в случае, когда")
Confirmatory Data Analysis: основные техники (методы) n n Параметрические методы применяются в случае, когда данные характеризуются нормальным распределением ( Normal Distribution) Непараметрические методы применяются в случае возможного искажения данных ( отсутствие нормального распределения), например, при нерепрезентативной выборке
 данных")
Основные моменты, влияющие на выбор метода 1. 2. 3. 4. Тип (вид, форма) данных (разведывательный или подтверждающий) Характер выборки ( нормальное распределение или искаженное): соответственно параметрические или непараметрические инструменты Количество переменных исследования: одномерные и многомерные Шкалы ( типы) измерения: номинальные, порядковые, интервальные, относительные
 n n Интервальные ( абс. И относ): 70 кг,")
Тип данных ( шкалы измерения) n n Интервальные ( абс. И относ): 70 кг, 80 кг. . Равные промежутки Порядковые ( ordinal) – можно расставить по порядку, но промежутки разные Номинальные – не могут быть упорядочены ( холодный-горячий) Дихотомные – да-нет, муж-жен

Тип данных n n Cross-section - данные по к-л показателю для разных однотипных объектов ( страны, регионы) Time series –данные, описывающие один и тот же объект во времени ( инфляция, темпы роста. . . ) n n Характеризуются опр. Тенденциямизависимостями Могут быть временные лаги

Собственное исследование: выбор методов n n Вопрос 1. Какой тип данных рассматривается? Вопрос 2. Сколько переменных?
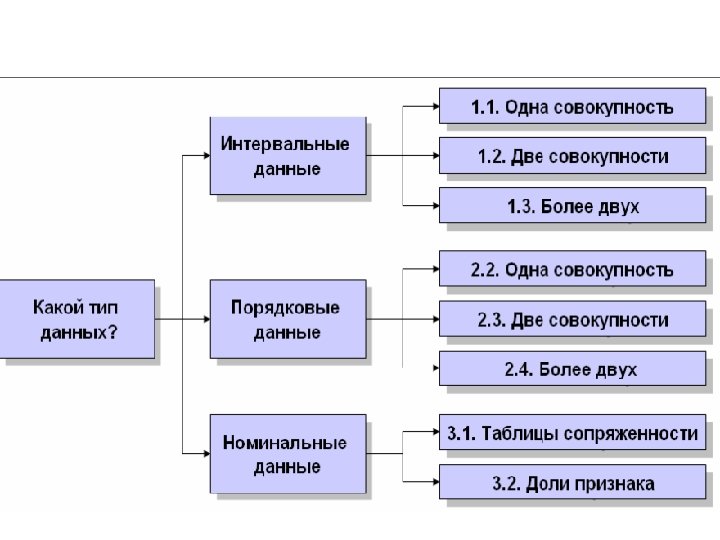

ИНТЕРВАЛЬНЫЕ ДАННЫЕ

Порядковые и номинальные данные
 n n n Описываем")
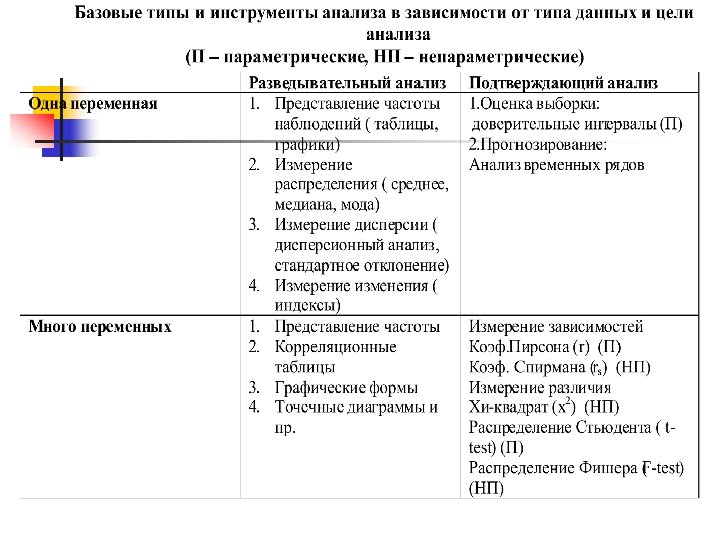
Метод анализа: что хотим увидеть? Одна переменная ( univariante analysis) n n n Описываем конкретное значение Разброс в значениях Основную тенденцию ( графики, гистограммы) Отклонение от среднего ( дисперсию) Смотрим на данные во временном промежутке ( графики) Смотрим на долю в массиве данных ( диаграммы, гистограммы)

Одномерный анализ: осн. Инструменты и формы представления данных n n n Таблицы частоты Графики, гистограммы, диаграммы Имеряем основную тенденцию: n n Среднее ( mean) Медиана (ср. Значение в упорядоч. Списке) Мода Измеряем дисперсию: n n Range (размах, разрыв между мин и макс) Inter-quartile range ( данные д. б. Проранжированы) Standard Deviation ( чем больше значение, тем больше вариация в данных) Коэф. Вариации ( показывает однородностьнеоднородность массива данныхвыборки)
 среднее (х) n Медиана (М)")
Разведывательный анализ: частота наблюдений и распределение Mean – (истинное) среднее (х) n Медиана (М) – то значение, которое располагается строго посередине массива упорядоченных данных n Мода (m) – наиболее часто встречающееся значение Позволяют выявить центральную тенденцию и сделать выводы о характере распределения n

Нормальное распределение n Частота Среднее, мода и медиана Значение переменной

Выводы n n Когда кривая распределения симметрична, значения трех показателей совпадают. Это называется нормальным распределением. Когда кривая искажена, средняя, медиана и мода имеют разные значения При положительном характере искажения данных «хвост» кривой распределения вытянут вправо и большая часть данных концентрируется в диапазоне меньших значений При отрицательном - наоборот
 n В случае мономодальности кривой ( т. е. один пик) и")
Выводы ( продолжение) n В случае мономодальности кривой ( т. е. один пик) и ее относительно слабой искаженности, соотношение показателей выражается: Среднее – Мода = 3(Среднее – Медиана)
 При использовании")
Измерение дисперсии n n n Позволяет описать разброс данных (spread of values) При использовании одновременно с показателями частоты распределения позволяет получить адекватное представление о массиве данных в двух измерениях Два простейших показателя дисперсии данных – range and interquartile range
 это разница между наибольшим и наименьшим значением")
Измерение дисперсии n n Range ( размах) это разница между наибольшим и наименьшим значением параметра Range = Eu – EL Interquartile range = Q 3 – Q 1 Semi-interquartile range = (Q 3 – Q 1)2 Стандартное отклонение ( Standard Deviation)
 1 40. 6 11 38. 5 2 34.")
Пример: потребление нефти, 19 периодов (n=19) 1 40. 6 11 38. 5 2 34. 6 12 37 3 38. 8 13 36 4 39. 7 14 29. 8 5 38. 3 15 32. 6 6 39. 2 16 35. 3 7 38. 3 17 34. 7 8 36. 4 18 30. 2 9 35. 3 19 35. 9 10 37. 7
 1 EL 29. 8 11 37 2 30. 2 12")
Упорядочиваем данные(есть в Excell) 1 EL 29. 8 11 37 2 30. 2 12 37. 7 3 32. 6 13 38. 3 4 34. 6 14 38. 3 5 Q 1 34. 7 15 Q 3 38. 5 6 35. 3 16 38. 8 7 35. 3 17 39. 2 8 35. 9 18 39. 7 9 36 19 Eu 40. 6 10 36. 4
/2=10 – десятое наблюдение упорядоченных данных Quartile = (n+1)/4=(19+1)/4=5, т.")
Расчеты: n n n Среднее=(n+1)/2=10 – десятое наблюдение упорядоченных данных Quartile = (n+1)/4=(19+1)/4=5, т. е. берем каждое пятое наблюдение Range= 40. 6 -29. 8=10. 8 Interquartile range= Q 3 -Q 1=38. 5 -34. 7=3. 8 Semi-interquartile range=(Q 3 -Q 1)/2=1. 9

Выводы: определяем осн. тенденцию n n Нижний квартиль Q 1 показывает потребление нижних 25% 50% ( два средних квартиля) имеют потребление между 34. 7 и 38. 5

Box plot Q 1 M Q 3 34. 7 36. 4 38. 5 50% данных El=29. 8 28 30 Eu=40. 6 32 34 36 38 40 42

Дисперсия, ст. Отклонение и коэффициент вариации

Коэффициент вариации и однородность выборки n n Имея коэффициенты вариации, можно сравнивать однородность самых разных явлений независимо от их масштаба и единиц измерения. Данный факт и делает коэффициент вариации столь популярным. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной.
2 n n n Учитывает все отклонения от")
Ст. отклонение: S = √∑(x – x‾)2 n n n Учитывает все отклонения от ср. показателя Рассчитать St. Dev. Пери од 1 2 3 4 5 6 Значе ние (х) 12 10 8 4 18 8
2 12 2 4 10 0 0 8 -2")
Ответ: X X-X‾ (x – x‾)2 12 2 4 10 0 0 8 -2 4 4 -6 36 18 8 64 8 -2 4 Total Ср. значение = 10 S = √ 1126 = 4. 32 112

Измерение изменений: индексы n n Простые индексы: измерение изменения параметра по отношению к базовому году Базовые и цепные индексы Взвешенные ( композитные или агрегированные) индексы: индекс Пааше, индекс Ласпейреса Прочие индексы

Пример год 2000 2007 объем цена книги рубашки TV 10 10 15 8 27 6 24 7 655 3 425 5 n Индекс потреб. цен: 15*10+24*6+425*3 10*10+27*6+655*3 ≈ 0, 7 n Дефлятор: 15*8+24*7+425*5 10*8+27*7+655*5 ≈ 0, 68

Дополнение: прочие показатели инфляции, используемые в современной международной статистике. n n Циклические колебания на товарных рынках не изменяют общего тренда инфляции. С этой целью в США выделяется показатель «базовой инфляции» (core CPI), для расчета которой из общего индекса инфляции исключаются цены на продукты питания и топливо. В современных условиях спектр торгуемых товаров на мировом рынке расширяется, и колебания инфляции могут быть вызваны не только изменением цен на продовольствие и топливо. Поэтому наряду с показателем базовой инфляции в США рассчитывается показатель «средней инфляции» (mean CPI) или «инфляция без выбросов» (trimmed CPI). Принцип расчета такого индекса состоит в том, что из индекса исключаются не просто отдельные группы товаров, а строится матрица изменения цен по отдельным продуктам на каждый период из общего индекса исключаются определенная доля максимальных и минимальных значений.

Базисный индекс сравнивает цены в любой из рассматриваем ых периодов с одним и тем же базовым периодом: например, цены в марте, в апреле, в мае и т. д. сравниваются с ценами в Базисные индексы

Темпы роста и темпы прироста n n При использовании таких индексов, для того чтобы определить, на сколько изменились цены, к примеру, в марте по сравнению с январем, необходимо: поделить соответствующие базовые индексы: 101/102 = 0, 99 (т. е. уровень цен в марте составил 0, 99, или 99% от январского уровня) или рассчитать процентное их изменение: (101– 102)/102 *100% = – 1% (т. е. цены в марте снизились на 1% по сравнению с январским уровнем). Между двумя полученными величинами имеется взаимно однозначное соответствие. Первую (0, 99) часто называют темпом роста, а вторую (– 1%) — темпом прироста. Темп роста больший 1 (100%) или положительный темп прироста показывает, что цены растут. Темп роста меньший 1 (100%) или отрицательный темп прироста показывает, что цены падают.

На всякий случай: вспоминаем n n n n Абсолютный прирост – размер увеличения показателя за определенный временной период (разница значений показателей между конечным и базовым периодами). Темп роста – отношение конечного значения показателя к базовому. Темп прироста – относительная скорость изменения показателя за определеный временной период. (отношение абсолютного прироста к значению базового периода). Темп прироста = темп роста -1 или 100% Средний темп роста показывает во сколько раз в среднем за единицу времени изменилось значение показателя (корень степени (n-1) из отношения конечного значения показателя к базовому, где n – число рассматриваемых периодов). Средний темп прироста = средний темп роста – 1 или 100% Тенденция – закономерность. Тренд (линия тренда) – графическое изображение тенденции.

Цепной индекс сравнивает цены в рассматриваемый период с предыдущим: например, цены в марте с ценами в феврале, цены в апреле с ценами в марте, цены в мае с ценами в апреле и т. д.

Сравнение двух методов n n n При использовании таких индексов, для того чтобы определить, на сколько изменились цены, к примеру, за два месяца — январь и февраль, необходимо: перемножить соответствующие индексы, которые в данном случае представляют собой темпы роста цен за месяц: 1, 02 * 1, 01 = 1, 03; или сложить соответствующие темпы прироста: 2% +1% = 3% (данная форма вычислений является приблизительной и для больших изменений дает приблизительный ответ с большой погрешностью). Как правило, базисный метод применяется в стабильных условиях и при низкой инфляции. Цепной метод — при нестабильном характере предложения и ассортимента товаров и услуг, за ценами на которые ведется наблюдение, при частой смене организаций, участвующих в наблюдении за ценами.

Прочие индексы n n Индекс Херфиндаля-Хиршмана Индекс внутриотраслевого обмена Грубела. Ллойда (ITT – Intraindustry Trade Index) Коэффициент Джини Индексы конкурентоспособности ВАЖНО! Можно строить собственные индексы в рамках исследования!!

Пример: индекс деловой активности PMI (Purchasing Managers’ Index n n n индекс используется для оценки изменений в области новых производственных заказов, объема промышленного производства, занятости, а также товарных запасов и скорости работы поставщиков. Индикатор измеряется в % в пределах от 0 до 100%, причем в зависимости о значений составляющих: PMI = 0. 30*(New Orders) + 0. 25*(Production) + 0. 20*(Employment) + 0. 15*(Supplier Deliveries) + 0. 10*(Inventories) По динамике PMI index обычно прогнозируют изменения в промышленном производстве, заказах, промышленных ценах, занятости, и, главное, динамика ВВП на полгода вперед - при значении PMI index выше 50% темп роста ВВП будет увеличиваться, если значение ниже 50%, то темпы роста ВВП будут падать и при достижении PMI 44% следует ожидать отрицательного роста ВВП.
, который вычисляется")
PMI: продолжение n Каждый компонент отчета компилируется в диффузный индекс (diffusion index), который вычисляется как сумма простых процентных изменений значений "выше" и "ниже" плюс половина процента ответов "то же" или "никаких изменений". Диффузный индекс может колебаться между 0 и 100% с различной характеристикой диапазонов: значение 50% означает отсутствие какого-либо изменения; выше 50% - улучшение; и ниже 50% означает снижение. Итоговый показатель делового оптимизма является составным диффузным индексом, который называется Индекс Менеджеров по Закупкам (PMI)

PMI: осн. позиции n В вопросник включаются следующие позиции: · Production - Производство ; · New orders (New orders from customers) - Новые заказы ; · New export orders - Новые заказы на экспорт ; · Order backlogs - Отставание Заказов ; · Commodity Prices - Цены на товары ; · Inventories of purchased materials - Запасы покупаемых материалов ; · Imports (New import orders) - Новые заказы импорта ; · Employment - Занятость ; · Vendor Deliveries (Delivery time) - Время поставок ; · Items in short supply (Supplier) - товары краткосрочного предложения.

Подтверждающий анализ данных: многомерные исследования n n n Основные проблемы: n Трудно выявить и учесть ВСЕ переменные n Многие воздействия случайны n Ограниченный набор данных + возможны ошибки Математическая статистика – эконометрика – попытка решить эти проблемы Типы эк. Данных: перекрестные данные (cross-section data) и временные ряды ( time series)

Пример: Методы математической статистики подробнее см. www. statsoft. ru Методы ранжирования Корреляционный анализ Построение регрессии Методы группировки – дисперсионный анализ Методы классификации – кластерный анализ Дискриминантный анализ Факторный анализ Многомерное шкалирование Анализ временных рядов И пр.

Измерение взаимосвязей между переменными n n Выявление взаимосвязи – корреляционный анализ n Коэф. Корреляции Пирсона (r) – параметрический n Коэф. Корреляции Спирмана (rs ) – непараметрический n Коэф. Phi – связь между дихотомными переменными n Коэф. Крамера V – между номин. Переменными ( показывает только силу, всегда положит. ) n Коэф. Eta - связь между интервальными и номинальными переменными, показывает только силу, но не направление, предполагает нелин. зависимость Если связь есть – построение регрессии ( модель)= регрессионный анализ n Коэф. Детерминации ( или коэф. Регрессии = квадрат значения коэф. Пирсона * 100) показывает относит. Зависимость изменений одной переменной от другой

Коэффициент Пирсона: формула где Xi - значения, принимаемые переменной X, Yi - значения, принимаемые переменой Y, X средняя по X, Y - средняя по Y. Или ее преобразовнный аналог
 r 0.")
Анализ линейной стат. связи между переменными: корреляция n Коэф. корреляции Пирсона (r) r 0. 9 -0, 99 Очень высокая пол. корреляция 0. 7 -0. 89 Высокая пол. корреляция 0. 4 -0. 69 Средняя пол. кор 0 -0. 39 Низкая пол. Кор 0 - (-0. 39) -0. 4 – (-0. 69) Низкая отр. Кор Средняя отр. Кор -0. 7 – (-0. 89) Высокая отр. Кор -0. 9 – (-0. 99) Очень высокая отр. кор
 1 Number of calls (y)")
ПРИМЕР: есть ли корреляция? week Number of orders (x) 1 Number of calls (y) 1 10 2 2 14 3 2 12 4 4 20 5 3 18 6 6 20 7 8 26 8 6 24

ОТВЕТ
")
Определить степень корреляции (значение коэфф. и сделать выводы о характере зависимости)
=-0. 655 n 1. На")
Решение: Коэффициент корреляции Пирсона: rxy=37342. 667/(5036. 904 x 11. 317)=-0. 655 n 1. На основании исходных данных, приведенных в таблице, расчитаем средние значения для X и Y: Х=1298. 333, Y=5. 489 № X Y X-Xср Y-Yср (Y-Yср)*(X-Xср)2 1 500 5. 4 -798. 333 -0. 089 71. 052 637335. 579 0. 008 2 790 4. 2 -508. 333 -1. 289 655. 241 258402. 439 1. 662 3 870 4. 0 -428. 333 -1. 489 637. 788 183469. 159 2. 217 4 1500 3. 4 201. 667 -2. 089 -421. 282 40669. 579 4. 364 5 2300 2. 5 1001. 667 -2. 989 -2993. 983 1003336. 779 8. 934 6 5600 1. 0 4301. 667 -4. 489 -19310. 183 18504338. 979 20. 151 7 100 6. 1 -1198. 333 0. 611 -732. 181 1436001. 979 0. 373 8 20 8. 2 -1278. 333 2. 711 -3465. 561 1634135. 259 7. 35 9 5 14. 6 -1293. 333 9. 111 -11783. 557 1672710. 249 83. 01 ∑ - - -37342. 667 25370400 128. 069
 и число степеней свободы n n Доверительный интервал")
Доверительный интервал( уровень значимости, р-уровень ) и число степеней свободы n n Доверительный интервал (confidence interval) – вычисленный на основе выборки интервал значений признака, который с известной вероятностью содержит оцениваемый параметр генеральной совокупности. Доверительная вероятность (или уровень доверия, confidence level) – это вероятность того, что доверительный интервал содержит значение параметра. Доверительную вероятность принято устанавливать на уровнях 90%, 95% и 99%. Будет зависеть от выборки Число степеней свободы: k=m-2 ( где m-размер выборки)

В нашем примере r= 0, 655. Что это значит? ? n n n Размер выборки 9 наблюдений Степень свободы 9 -2=7 Уровень значимости м. б. 90, 95, 99% См. Таблицу критических значений коэфф. корреляции Пирсона Сравниваем полученное значение с табличным: если оно меньше табличного ( т. е. Находится вне зоны значимости), то принимаем альтернативную (нулевую) гипотезу об отсутствии линейной зависимости параметров

Таблица критических значений коэф. Пирсона
 для вычисленного коэффициента:")
Критические значения корреляции rxy Пирсона Инструкция для поиска вероятности ошибки (p) для вычисленного коэффициента: 1. 2. 3. 4. Рассчитайте k (степени свободы) по формуле m– 2, где m – размер выборки; Найдите в таблице строчку с соответствующим либо наиболее близким k; В найденной строке найдите значение коэффициента корреляции большее либо равное тому, которое Вы рассчитали. Таким образом, определите необходимый столбец; Значение в заглавии столбца (0, 05 или 0, 01) будет вероятностью ошибки;
 (Rs) n n n n Непараметрический, используется когда")
Корреляция: коэф. ранговой Корреляции Спирмана (Spearman) (Rs) n n n n Непараметрический, используется когда трудно измерить параметры, но можно их проранжировать. Данные должны быть много ( би)вариантны Проранжированы Формула: Rs D – разница между двумя значениями m – количество наблюдений Rs =1 – абс. Пол. лин кор-я; Rs = 0 – кор-ии нет
 (Rs) n n Непараметрический, используется когда трудно измерить параметры,")
Корреляция: коэф. Корреляции Спирмана (Spearman) (Rs) n n Непараметрический, используется когда трудно измерить параметры, но можно их проранжировать. Данные должны быть много ( би)вариантны Проранжированы Rs=1 - (6∑D 2 )/N(N 2 -1) Формула: n n n D – разница между двумя значениями N – количество наблюдений Rs =1 – абс. Пол. лин кор-я; Rs = 0 – кор-ии нет
 Расход материалов (кг) янв")
Пример: есть ли корреляция Производство и расход материалов Месяц Производство(шт) Расход материалов (кг) янв 13900 290 фев 12700 210 март 10800 180 апр 12200 270 май 11800 230 июнь 11300 140 июль 14700 245
 Произв. Расход 2 3 7 4 5 6")
ОТВЕТ ( при n = 7) Произв. Расход 2 3 7 4 5 6 1 Разница (в квадрате) 1 1 1 5 -2 4 6 1 1 2 2 4 4 1 1 7 -1 1 3 2 4 всего 16 0. 714286

Задание: рассчитать коэф. Спирмана для того же массива данных n В таблице представлены значения признаков X и Y:
/(9*(81 -1)=-1 n X ранг, Rx Y ранг, Ry")
Решение: Коэффициент корреляции Спирмена: ρ=1 -(6*240)/(9*(81 -1)=-1 n X ранг, Rx Y ранг, Ry разность рангов D, Rx. Ry 1 500 4 5. 4 6 -2 4 2 790 5 4. 2 5 0 0 3 870 6 4. 0 4 2 4 4 1500 7 3. 4 3 4 16 5 2300 8 2. 5 2 6 36 6 5600 9 1. 0 1 8 64 7 100 3 6. 1 7 -4 16 8 20 2 8 -6 36 9 5 1 14. 6 9 -8 64 D 2

Проверка значений коэф. Спирмана Значение коэф. = -1 Связь существует, отклоняем нулевую гипотезу. Т. к. По коэф. Пирсона связи нет, а по Спирману есть, то Связь нелинейна

Z-значения для часто используемых доверительных интервалов и формулы для расчетов доверит. интервалов

Минимальный объем выборки, требуемый для получения интервальной оценки с заданной доверительной вероятностью и попадающей в интервал заданного размера:

ПРИМЕР: оценка ср. Возраста магистрантов. Каков д. б. Размер выборки? (оценка должна быть сделана сточностью до 1 года и с вероятностью 99%. ) Из ранее проведенного исследования известно, что стандартное отклонение возраста – 2 года. Решение. Для α = 1 – 0, 99 = 0, 01 z-значение равно 2, 58. Е = 1, σ = 2. Подставим в формулу и получим размер выборки равный 27 человек

А если стандартное отклонение неизвестно и размер выборки меньше 30? ? ? n n Вместо нормального распределения – распределение Стьюдента ( tраспределение) Предложено в 1908 г. В. Госсетом ( опубликовано под псевдонимом Стьюдента)

Основное отличие n n Отличается от стандартного нормального распределения тем, что дисперсия t-распределения больше 1, распределение представляет собой семейство кривых, различающихся числом степеней свободы. Число степеней свободы t-распределения при построении доверительного интервала для среднего равно: df = n – 1. С увеличением объема выборки распределение приближается к нормальному. Для нахождения t-значений используются таблицы

Проверка значений коэф. Спирмана по таблицам Стьюдента n Расчет значимости коэф. По формуле: m- число наблюдений, р-значение коэф. n n =-1*2. 646/(1 --12)=∞ Вывод: получ. Значение превышает табличное, отклоняем нулевую гипотезу
 n n Коэф. Корреляции (Пирсона) измеряет силу связи переменных")
Хи- квадрат ( Chi-squared test) n n Коэф. Корреляции (Пирсона) измеряет силу связи переменных Коэф. Спирмана – то же самое для упорядоченных наблюдений Но иногда данные приводятся в номинальном выражении Непараметрический метод хи-квадрат тест для определения стат. Значимости данных путем проверки случайности( их получения) (contingency)
 n n Коэф. Корреляции (Пирсона) измеряет силу связи переменных")
Хи- квадрат ( Chi-squared test) n n Коэф. Корреляции (Пирсона) измеряет силу связи переменных Коэф. Спирмана – то же самое для упорядоченных наблюдений Но иногда данные приводятся в номинальном выражении Непараметрический метод хи-квадрат тест для определения стат. Значимости данных путем проверки случайности( их получения) (contingency)
2 Е) Где О")
Формула для расчета Расчет хи-квадрат тест Х 2 = сумма ((О-Е)2 Е) Где О – фактические значения Е – ожидаемые значения
")
Пример. Нулевая гипотеза: посещение столовой и прогулы не связаны. Проверяем Факт. Частота наблюдений (О) Посещ. столовую Не посещ. ВСЕГО Кол-во прогульщиков 20 30 50 Кол-во судентов посещ. лекции 80 50 130 ВСЕГО 100 80 180
 Посещ. столовую Не посещ. (100*50)180=28 (80*50)180=22 50 (100*130)180=72 80*130)180=58")
Расчеты: Ожидаемая частота наблюдений (Е) Посещ. столовую Не посещ. (100*50)180=28 (80*50)180=22 50 (100*130)180=72 80*130)180=58 130 100 О ВСЕГО 80 Е 180 (О-Е)2Е 20 286428=2. 286 30 226422=2. 909 80 726472=0. 888 50 586458=1. 103 7. 186 ВСЕГО

Проверка значений хиквадрат теста Таблицы n Доверительный интервал ( например 5%-ный, т. е. наша гипотеза верна на 95%) n Степень свободы: v = (r-1)(c-1), где r – кол-во строк, с – кол-во столбцов ( в нашем случае v =1) В нашем случае крит. Значение = 3. 841, а мы получили значительно больше, след. Нулевая гипотеза отвергается ( т. е. Связь есть) n

Расчетное задание: проверить гипотезу методом хи-квадрат теста n n n Принято считать, что учителя более предвзято относятся к мальчикам, чем к девочкам, Т. е. более склонны хвалить девочек. Гипотеза: гендерная составляющая влияет на оценки учеников. Проверка гипотезы: психологом были проанализированы характеристики учеников, написанные учителями, на предмет частоты встречаемости трех слов: "активный", "старательный", "дисциплинированный", синонимы слов так же подсчитывались. Данные о частоте встречаемости слов были занесены в таблицу:

Решение: Шаг 1. Построим таблицу распределения эмпирических частот, т. е. тех частот, которые мы наблюдаем: "Активный" "Старательный" "Дисциплинирова Итого: нный" Мальчики 10 5 6 21 Девочки 6 12 9 27 Итого: 16 17 15 s=48

Шаг 2: n Построим таблицу теоретических частот. Для этого умножим сумму по строке на сумму по столбцу и разделим получившееся число на общую сумму (s). "Активный" "Старательный" Мальчики (21 * 16)/48 = 7 (21 * 17)/48 = 7. 44 "Дисциплинирова Итого: нный" (21 * 15)/48 = 21 6. 56 Девочки (27 * 16)/48 = 9 (27 * 17)/48 = 9. 56 (27 * 15)/48 = 8. 44 27 Итого: 16 15 s=48 17

Шаг 3: итоговая таблица Категория 1 Мальчики Девочки Категория 2 "Активный" "Старательный" "Дисциплиниров анный" Эмпирич. (Э) 10 5 6 Теоретич. (Т) 7 7, 74 6, 56 (Э - Т)² / Т 1, 28 0, 47 6 12 9 9 9, 56 8, 44 1 0, 62 0, 04 Сумма: 4, 21 В нашем случае хи-квадрат = 4, 21; n = 2. По таблице критических значений критерия находим: при n = 2 и уровне ошибки 0, 05 критическое значение χ2 = 5, 99. Полученное значение меньше критического, а значит принимается нулевая гипотеза.
 n n n Анализ временных рядов Прогноз Две осн.")
Моделирование и прогнозирование ( forecasting) n n n Анализ временных рядов Прогноз Две осн. модели: аддитивная и мультипликативная
: простая лин. Регрессия, скользящее среднее Выделяем")
Основные шаги n n n Предсказываем тренд (T): простая лин. Регрессия, скользящее среднее Выделяем сезонную составляющую (S), рассчитываем сезонные индексы Выделяем циклическую составляющую и случайные колебания ( если возможно) YT*S = C+I

Множественная регрессия: важные понятия Коэффициент детерминации R 2 (0< R 2 <1, чем ближе к 1, тем лучше) n Распределение Стьюдента ( или tстатистика) и распределение Фишера ( F-статистика) n Автокорреляция остатков: статистика Дарбина-Уотсона (DW) n

t-статистика Показывает значимость коэф. Регрессии n Определяется по таблицам распределения Стьюдента, например: t 8; 0, 95 =1. 860 (где 8 – степень свободы, озн. , что имеется 10 наблюдений, 0, 95 – доверит. интервал) n Общее правило: Если t<1 ( <0. 7) – не значим, вероятность наличия связи менее 70% Если 1<t<2 – более или менее Если 2<t<3 – значимая связь, вероятность 95 -99% n

Множественная регрессия: репрезентативность данных n n n n – число наблюдений m – количество объясняющих переменных n > m+1 n=m+1 – минимально необх. число наблюдений n-m-1 – показатель степени свободы

Статистика Дарбина-Уотсона Показывает, случайны ли отклонения от регрессионной прямой: если близок к нулю, то имеется пол. авткорреляция остатков Если DW=2 – отклонения носят случайный характер Если DW = 4 – случай отрицат автокор. ( редко) n

Статистика Дарбина-Уотсона: критические значения ( при n не менее 12 -15 и при 1 -3 переменных в уравнении регрессии) n n n 1<DW<3 – автокорреляция остатков отсутствует и уравнение принимается 1. 2 – 1. 3<DW<2. 7 – 2. 8 – автокорреляция есть, но статистически незначима В целом: если <DW> 1. 5 -2. 0 -2. 5, считается удовл. Если n растет, критич значения DW растут Если растет кол-во переменных, то значение DW уменьшается
 –")
Некоторые доп. понятия n n n Мультиколлинеарность ( только в случае множ. регрессии) – коррелированность двух и более переменных Гомоскедатичность – дисперсия отклонений вокруг среднего стабильна Гетероскедатичность выбор весов параметров вручную

Распространенные сокращения n n n LS метод – метод наименьших квадратов WLS – взвешенный метод наименьших квадратов ( важен для гетероскедатичных данных) МА – Moving Averages ARIMA – Autoregressive Integrated Moving Averages- комбинация авторегрессионных преобразований и скользящего среднего ( обычно в случае автокорреляции остатков) ANOVA – analysis of variation

Пример исследований Моделирование функции спроса на квартиры Прогноз объема продаж с сезоннойсоставляющей (см. Примеры в Excel)
0a0ae1a1f869c804e74d2062b0603898.ppt