2f9b6a1875798ae562904572cf395195.ppt
- Количество слайдов: 123



Mathematics in Search Engines and Internetwork 马志明 2006年 12月 Email: mazm@amt. ac. cn http: //www. amt. ac. cn/member/mazhiming/index. html
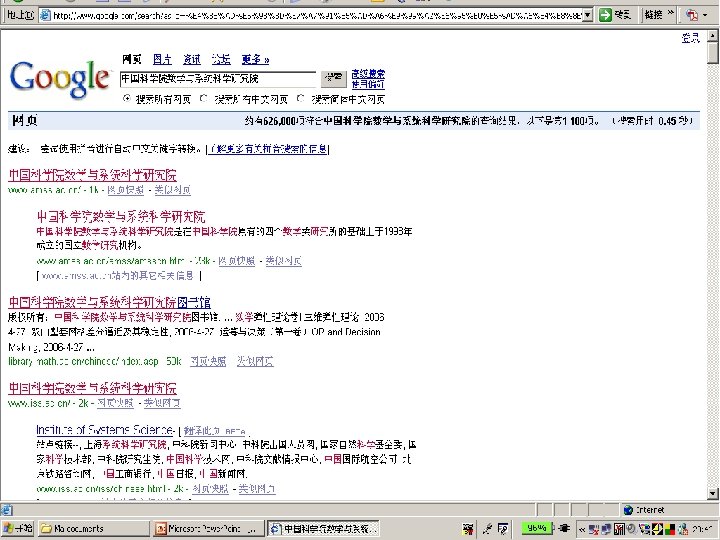
 How can google make")
约有626, 000项符合中国科学院数 学与系统科学研究院的查询结果, 以下是第 1 -100项。 (搜索用时 0. 45 秒) How can google make a ranking of 626, 000 pages in 0. 45 seconds?

Communication networks The Earth is developing an electronic nervous system, a network with diverse nodes and links are -computers -phone lines -routers -TV cables -satellites -EM waves Communication networks: Many non-identical components with diverse connections between them.

Data Mining Determine the importance of vertices from the graph topology.


HITS 1998 Jon Kleinberg Cornell University Page. Rank 1998 Sergey Brin and Larry Page 1999 Stanford University
 Jon Kleinberg • One of Kleinberg‘s most important research achievements focuses on")
Nevanlinna Prize(2006) Jon Kleinberg • One of Kleinberg‘s most important research achievements focuses on the internetwork structure of the World Wide Web. • Prior to Kleinberg‘s work, search engines focused only on the content of web pages,not on the link structure. • Kleinberg introduced the idea of • “authorities” and “hubs”: • An authority is a web page that contains information on a particular topic, • and a hub is a page that contains links to many authorities. Zhuzihu thesis. pdf







Page Rank, the ranking system used by the Google search engine. • Query independent • content independent. • using only the web graph structure

Page Rank, the ranking system used by the Google search engine.
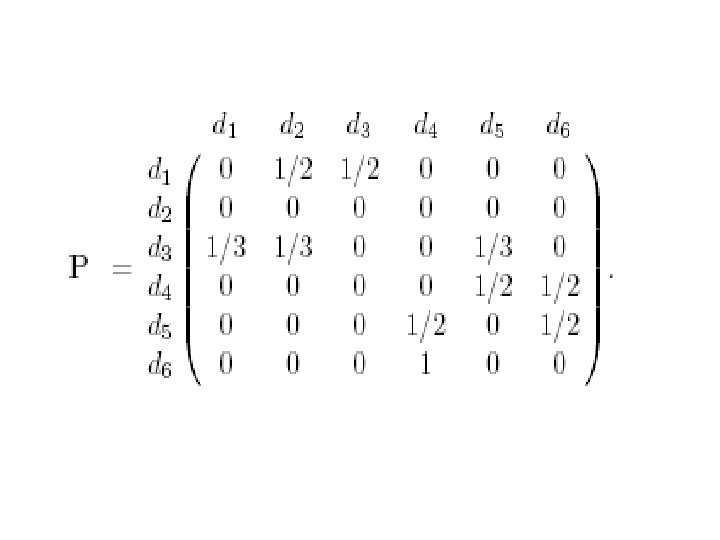
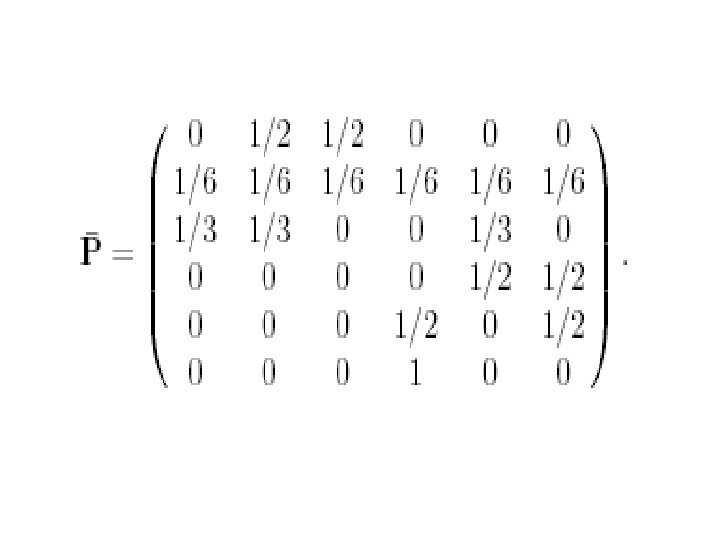

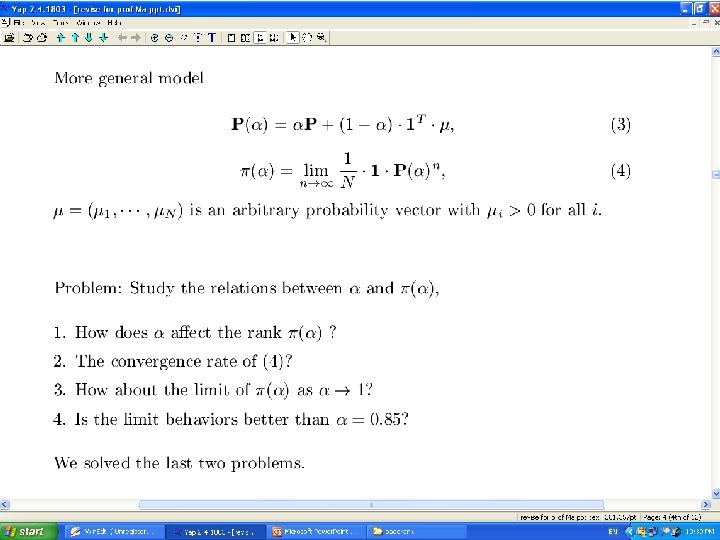
• 对矩阵我们可以有一个直观的解释,设P是具有转移概 率矩阵的马氏链,则该马氏链可以看成是对Inter网页 面的点击浏览过程。若当结点有出度时,即结点有指 向其它页面的超连接时,等可能地从指向的网页结点 里选择一个进行下一步浏览。当结点的出度为 0,则从 全部网络里随机地选择一个网页进行下一步浏览。此 时,如果矩阵具有唯一非负左特征向量,则此特征向 量,除一常数差别外,是马氏链的唯一不变概率测度。 记此不变概率测度为,则由马氏过程的遍历原理,正 好是网页的平均点击比率。这一直观解释进一步说明 了用矩阵的非负左特征向量来为网页排序的合理性。

中也可以用状态空 间{1, 2, …, n}上的一个严格正概率分布来代替均匀分布。 行业里称为个性化分布,它的直观解释是网页浏览者")
• 对于,也可以有一个直观的解释。设是由转移概率矩 阵确定的马氏链,视为在Inter网上的点击浏览过程, 若的当前状态为,那么或者以概率从指向的网页结点 中等可能地选择一点,或者以概率从全部结点中等可 能地选取一点。根据马氏过程的遍历原理,由迭代法 求出的的非负左特征向量,正好是此点击浏览过程对 网页的平均点击比率。在公式(6)中也可以用状态空 间{1, 2, …, n}上的一个严格正概率分布来代替均匀分布。 行业里称为个性化分布,它的直观解释是网页浏览者 以概率从全部结点中个性化地依分布随机地选取一点。 个性化对网页的排序会有一定的影响。


WWW 2005 paper Page. Rank as a Function of the Damping Factor Paolo Boldi Massimo Santini Sebastiano Vigna DSI, Università degli Studi di Milano 3 General Behaviour 3. 1 Choosing the damping factor 3. 2 Getting close to 1 v can we somehow characterise the properties of ? v what makes different from the other (infinitely many, if P is reducible) limit distributions of P?

Website provide plenty of information: pages in the same website may share the same IP, run on the same web server and database server, and be authored / maintained by the same person or organization. there might be high correlations between pages in the same website, in terms of content, page layout and hyperlinks. websites contain higher density of hyperlinks inside them (about 75% ) and lower density of edges in between.
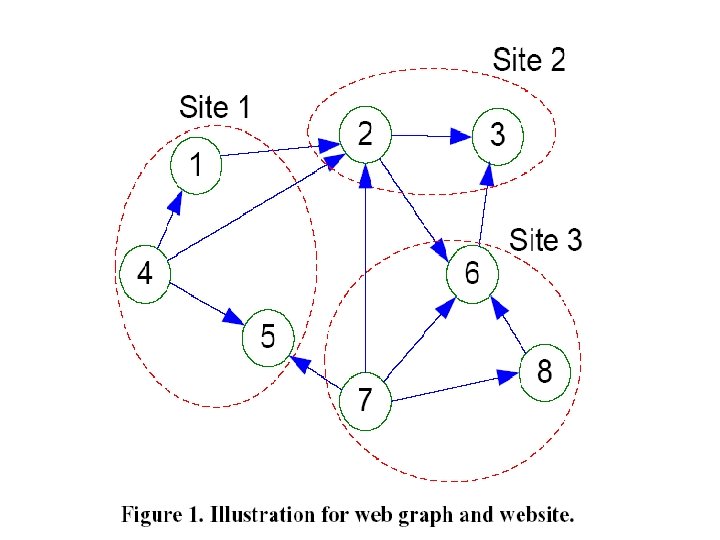
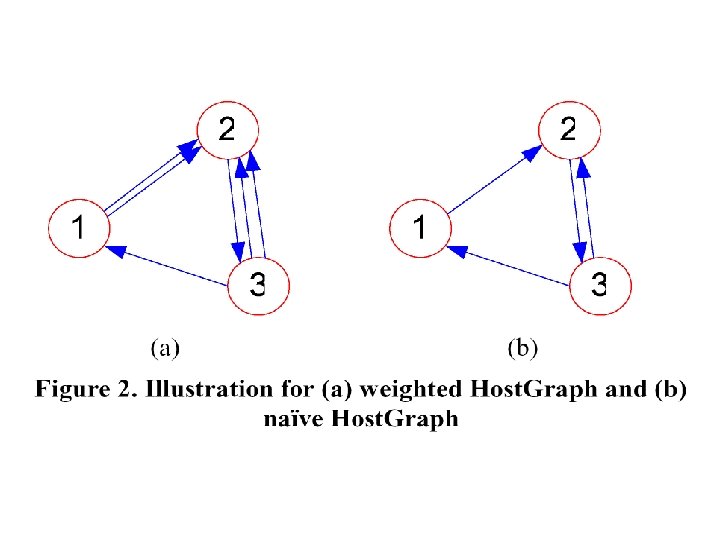

Host. Graph loses much transition information Can a surfer jump from page 5 of site 1 to a page in site 2 ?

From: s 06 -pc-chairs-email@u. washington. edu [mailto: s 06 -pc-chairs. Sent: 2006年 4月4日 8: 36 To: Tie-Yan Liu; wangying@amss. ac. cn; fengg 03@mails. thu. edu. cn; ybao@amss. ac. cn; mazm@amt. ac. cn Subject: [SIGIR 2006] Your Paper #191 Title: Aggregate. Rank: Congratulations!! Bring Order to Web Sites Competition was strong again this year – of 399 papers submitted only 74 were accepted. 29 th Annual International Conference on Research & Development on Information Retrieval (SIGIR’ 06, August 6– 11, 2006, Seattle, Washington, USA).

Describe Importance of Websites in Probabilistic View Ying Bao, Gang Feng, Tie-Yan Liu, Zhi-Ming Ma, and Ying Wang

We suggest evaluating the importance of a website with the mean frequency of visiting the website for the Markov chain on the Internet Graph describing random surfing. We show that this mean frequency is equal to the sum of the Page. Ranks of all the webpages in that website (hence is referred as Page. Rank. Sum ) We propose a novel algorithm (Aggregate. Rank Algorithm) based on theory of stochastic complement to calculate the rank of a website.

The Aggregate. Rank Algorithm can approximate the. Page. Rank. Sum accurately, while the corresponding computational complexity is much lower than Page. Rank. Sum By constructing return-time Markov chains restricted to each website, we describe also the probabilistic relation between Page. Rank and Aggregate. Rank. The complexity and the error bound of Aggregate. Rank Algorithm with experiments of real dada are discussed at the end of the paper.



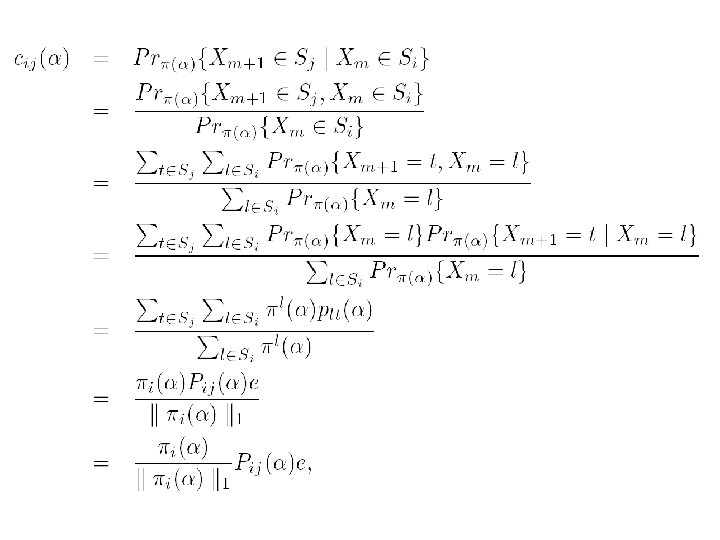
=(cij(α)) is referred to as the coupling matrix, whose elements represent")
The N×N matrix C(α)=(cij(α)) is referred to as the coupling matrix, whose elements represent the transition probabilities between websites. It can be proved that C(α) is an irreducible stochastic matrix, so that it possesses a unique stationary probability vector. We use ξ(α) to denote this stationary probability, which can be gotten from


the transition probability from Si to Sj actually summarizes all the cases that the random surfer jumps from any page in Si to any page in Sj within one-step transition. Therefore, the transition in this new Host. Graph is in accordance with the real behavior of the Web surfers. In this regard, the socalculated rank from the coupling matrix C(α) will be more reasonable than those previous works.



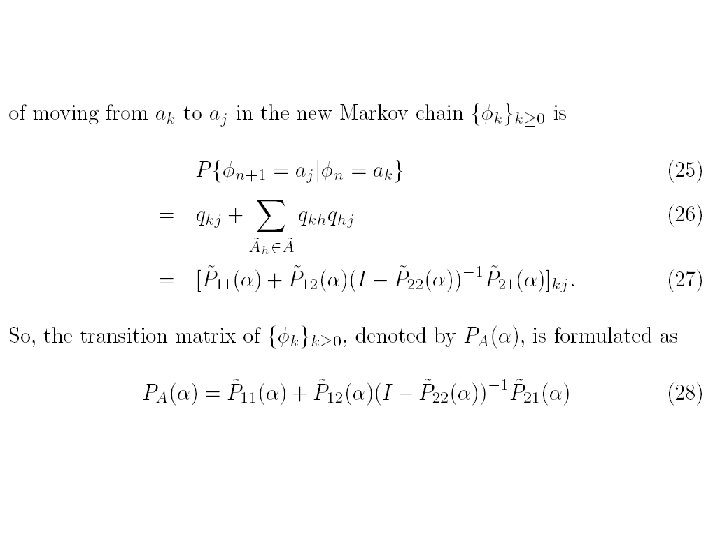





That is, the probability of visiting a website is equal to the sum of Page. Ranks of all the pages in that website. This conclusion is consistent to our intuition.


• Based on the above discussions, the direct approach of computing the Aggregate. Rank ξ(α) is to accumulate Page. Rank values (denoted by Page. Rank. Sum). • However, this approach is unfeasible because the computation of Page. Rank is not a trivial task when the number of web pages is as large as several billions. Therefore, Efficient computation becomes a significant problem.

Aggregate. Rank 1. Divide the n × n matrix into N × N blocks according to the N sites. 2. Construct the stochastic matrix for by changing the diagonal elements of to make each row sum up to 1.

3. Determine from 4. Form an approximation matrix , by evaluating to the coupling 5. Determine the stationary distribution of and denote it , i. e. ,

Experiments • In our experiments, the data corpus is the benchmark data for the Web track of TREC 2003 and 2004, which was crawled from the. gov domain in the year of 2002. • It contains 1, 247, 753 webpages in total.

we get 731 sites in the. gov dataset. The largest website contains 137, 103 web pages while the smallest one contains only 1 page.
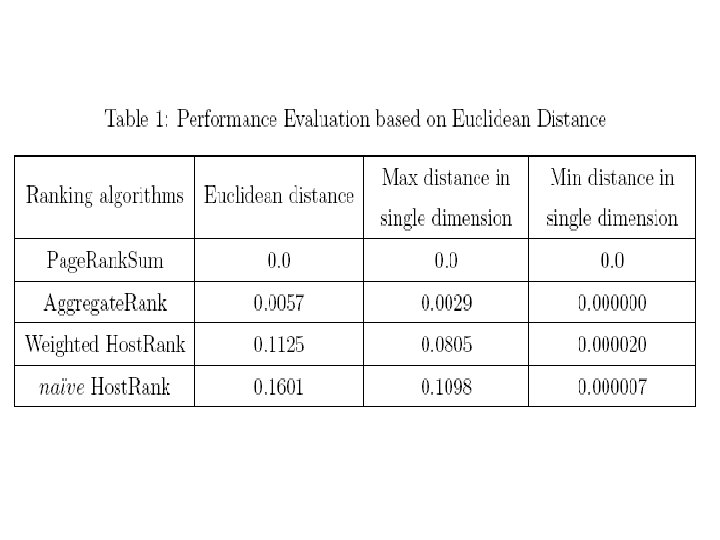

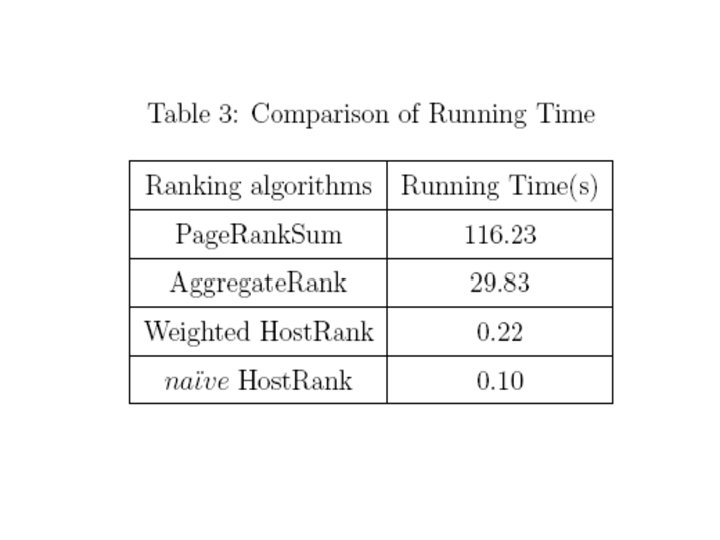
Performance Evaluation of Ranking Algorithms based on Kendall's distance

Similarity between Page. Rank. Sum and other three ranking results.


• Overview of Research in MICA. pdf

不同领域的复杂网络 • 信息网络: WWW, Internet,计算机共享, Email网, 专利使用 • 技术网络: 电力网,电话线路网, • 交通运输网:航线网,铁路网,公路网, 自然河流网 • 社会网: 演员合作网,友谊网,论文引用 姻亲关系网,科研合作网 • 生物网:食物链网,神经网,新陈代谢网, 蛋白质网,基因网络

Examples of networks: • • • Internet, World Wide Web, genetic networks social networks , networks of business relations , neural networks, metabolic networks, food webs, distribution networks blood vessels, postal delivery routes, networks of citations and many others

Communication networks The Earth is developing an electronic nervous system, a network with diverse nodes and links are -computers -phone lines -routers -TV cables -satellites -EM waves Communication networks: Many non-identical components with diverse connections between them.
 Far and Away")
ACTOR CONNECTIVITIES Nodes: actors Links: cast jointly Days of Thunder (1990) Far and Away (1992) Eyes Wide Shut (1999) N = 212, 250 actors k = 28. 78 P(k) ~k- =2. 3

GENOME protein-gene interactions PROTEOME protein-protein interactions METABOLISM Bio-chemical reactions Citrate Cycle
 “One way to understand the p 53 network is to")
Nature 408 307 (2000) “One way to understand the p 53 network is to compare it to the Internet. The cell, like the Internet, appears to be a ‘scale-free network’. ” 一种理解p 53网络的方式是 将它与因特网比较。像因特 网一样,细胞也表现为一个 “无标度网络”。

近年来人们发现相差甚远的领域形 成的随机复杂网络具有惊人的相同 的特征。 Complexity Network Science collaboration WWW Food Web Scale-free network Citation pattern Internet Cell UNCOVERING ORDER HIDDEN WITHIN COMPLEX SYSTEMS

From Mathematical point of view 复杂网络可以从数学上被 描述为有大量结点的动 态的发展的 随机图 SJT 2004_08. pdf

近年来在Science, Nature, Physics Rev. Letter等杂志发 表了大量研究和探讨复杂网络的 文章,人们发现 真实世界的复杂网络不同于Erdös 等数学家研究的 经典随机图.

• 目前已发现的不同领域形成的随 机复杂网络具有的相同统计特征: ± ± ± Small world effect:网络中任意两点间距 离的平均值很小 Clustering:网络中有足够多的三角形 Scale-free:顶点的度的分布满足Scaling -g law P{d = k} µ k

Nevanlinna Prize Jon Kleinberg • Another area in which Kleinberg has made fundamental advances is in that of "small-world" networks. These networks were first noticed in experiments carried out in the 1960 s by the psychologist Stanley Milgram and became the focus of a series of mathematical models based on work of Duncan Watts and Steve Strogatz in the 1990 s.
 : clustering coeff. L(p) : average path length (Watts and Strogatz,")
Watts-Strogatz Model C(p) : clustering coeff. L(p) : average path length (Watts and Strogatz, Nature 393, 440 (1998))
 The number of nodes (N) is NOT fixed. Networks continuously expand")
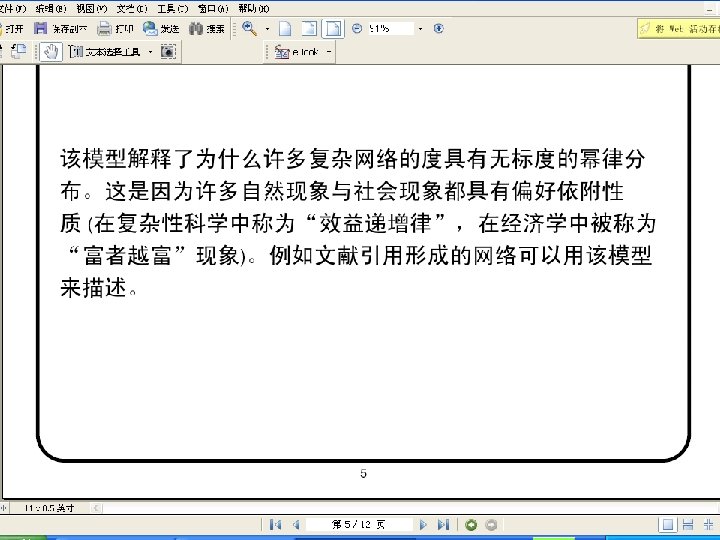
SCALE-FREE NETWORKS (1) The number of nodes (N) is NOT fixed. Networks continuously expand by the addition of new nodes Examples: WWW : addition of new documents Citation : publication of new papers (2) The attachment is NOT uniform. A node is linked with higher probability to a node that already has a large number of links. Examples : WWW : new documents link to well known sites (CNN, YAHOO, New. York Times, etc) Citation : well cited papers are more likely to be cited again
 GROWTH : At every timestep we add a new node with")
Scale-free model (1) GROWTH : At every timestep we add a new node with m edges (connected to the nodes already present in the system). (2) PREFERENTIAL ATTACHMENT : The probability Π that a new node will be connected to node i depends on the connectivity ki of that node P(k) ~k-3 A. -L. Barabási, R. Albert, Science 286, 509 (1999)

Mean Field Theory , with initial condition γ=3 A. -L. Barabási, R. Albert and H. Jeong, Physica A 272, 173 (1999)

• slice. pdf

随机复杂网络是动态的演化的系 统,它具有大量的不断增减的节 点和边,我们所观察到的网络是 其演化过程中相对稳定的一个状 态,它相当于统计物理学家所说 的“稳态”

“Which vertex in this network would prove most crucial to the network’s connectivity if it were removed? ”

“What percentage of vertices need to be removed to substantially affect network connectivity in some given way? ” this type of statistical question has real meaning even in a very large network.

David Aldous:


Random Networks and Markov Processes Zhi-Ming Ma Graph valued Markov. pdf

随机复杂网络的研究需要综合运用图论、 概率论、模拟等学科分支的思想方法 • 一些优秀的数学家,比如: • B. Bollobas, • David Aldous, • Jenifer Chayes, • Richard Durrett • Chung Fan 等都在开展Inter 网与随机网络及其应用的研究。 • 还出现了专门的学术期刊 • Internet Mathematics。

我们需要研究发生在随机网络上的各种过程行 为及其应用。比如: Inter 网的数据处理与信息挖掘 网页搜索与排序 无线自组织网络的覆盖问题与连通问题 • 社会网络或计算机网络上传染过程的研究, • 网络顶点故障对通讯网络性能的影响, • 网络相变与网络动态系统、 • 蛋白质基因的网络结构等。

二、关于无线自组织 网络覆盖问题 的研究

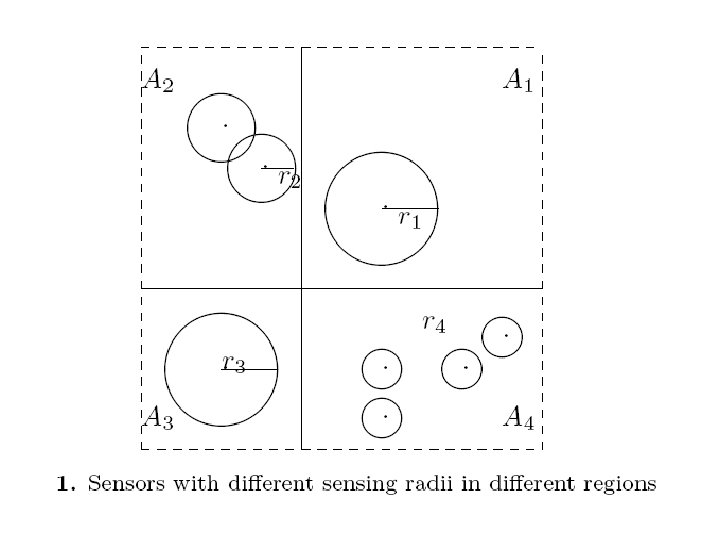
无线传感器广泛用于 军事与非军事领域 • • 力传感器 红外线传感器 位移传感器 光传感器 温度传感器 湿度传感器 磁传感器 流量传感器,....

无线传感器的覆盖问题 • 研究传感器半径与传感器置放密度之间 的关系





“contact tracing” methods used to control transmitted diseases • The probability of reaching a particular vertex by following a randomly chosen edge is proportional to the vertex’s degree It is more likely to find high-degree vertices by following edges than by choosing vertices at random. Thus a population can be immunized by choosing a random person from that and vaccinating a friend of that person.

Find high-degree vertices by following edges

Asymptotic local properties of complex networks and their application to infectious diseases Asymptotic

随机复杂网络已成为数学与 系统科学、统计物理、 生命科学、信息科学、 社会科学、经济金融等 许多领域相互交叉的 共性科学问题。

Network Science Committee on Network Science for Future Army Applications, National Research Council ISBN: 0 -309 -65388 -6, 124 pages, 8 1/2 x 11, (2006) 应美国国防部的要求,美国国家研究委员会 和军队科技委员会做的一个研究报告。 – 启动一个叫做网络科学的研究领域是否合适 – 网络科学的内容和关键研究挑战 – 所需要的研究条件等等 – 军方所应该优先关心的问题

网络科学中的七个主要挑战 1. Dynamics, spatial location, and information propagation in networks 2. Modeling and analysis of very large networks 3. Design and synthesis of networks 4. Increasing the level of rigor and mathematical structure 5. Abstracting common concepts across fields 提高严密性和数学构造的水准 6. Better experiments and measurements of network structure 7. Robustness and security of networks

leading • Ten research. doc questions for network 2003年 9月 在 罗 马 召 开 了 主 题 为 “Growing Networks and Graphs in Statistical Physics, Finonet, Biology and Social Systems”的国际会 议,与会专家提出了今后网络研究的十个主要 问题,现把着十个问题摘录于后以供参考。关 于这十个问题的具体描述可见Eur, Phys. 38, pp 143 -145(2004)的文章“Virtnal Ronnd Table on ten leading questions for netusrk research”。

• · 对于不同增长模型的结构是否存在规范 的分类方法? • · 是否有更多的统计分布帮助我们深入理 解复杂网络的结构和分类? • · 为什么许多网络是组合式的? • · 网络动力学是否有普通性质?
? • ·")
• · 在网络中发生的动力学过程怎样影响网 络的拓扑结构? • · 影响生物网络的演化机制是什么? • · 如何量化不同性质网络间的相互作用( 网络的网络)? • · 有无可能发展出系统的 具来研究大规 模技术与基础设施网络的鲁棒性和易毁 性?

• · 如何来刻画小网络? • · 为什么社会网络都是assortative,而所 有的生物和技术网络都是disassortatve ?

Remark: 关于随机复杂网络的研究仍处于初级阶 段,未来研究在如下几个方面大有潜力: 我们至今没有成熟的理论框架和系统的 程序和方法来研究复杂网络,甚至关于 随机复杂网络的哪些属性属于最重要的 研究目标这样一个基本问题都没有清楚 的答案。

• 目前一些研究者提出了网络的一些演化 模型,解释网络如何演化到我们所观察 到的结构。在这方面的研究还大有可为。 一方面对于已建立的模型缺乏严密的数 学论证,因而不能实质性地理解演化机 制,另一方面还需要开发和建立各种更 为准确的网络模型。

随机复杂网络研究的一些问题 • 网络的拓扑结构——静态几何量及其统 计性质 • 网络机制模型 – Small World Network – Scale Free Network • 网络的演化性质 – 时间演化性质 – 偏好性的检验 • 网络的动力学性质——结构与功能 – 网络上的动力学模型 – 网络的容错与抗攻击能力

• 网络上的物理模型 • 复杂网络上的传统统计物理学模型,并与规则 网络和分形网络进行对比 • Small World网络上的H-H模型:驰豫时间短, 共振性好 • 网络上的传染病模型:利用SIS或SIR模型, 对于顶点的有效扩散系数 ,规则网存在临界 值 c,Small world网 c要小得多,而无标度网 有 c= 0

• 网络的容错与抗攻击能力 failure Internet attack Protein network R. Albert, H. Jeong, A. L. Barabasi, Nature 406 378 (2000)

• 网络的效率 河流与血管的分支网络 食物链网络上能量和物质流的传输 科学家网络及WWW网络上思想和信息的传播 • 基于网络结构的分析手段 交流集团的类聚分析

科学家合作网络 • 加权、有向网络的静态统计性质 In-Out度和权的分布,度权的相关性,单位权 • 网络的演化性质 偏好性的实证检验 • 网络上思想的传播及效率分析 科学家的类聚分析
对网 络结构的作用。 • 研究网络结构对网络上的动力系统的集 体行为(如同步等)的改变")
脑神经元网络 • 神经元为顶点,突触连接为边,突触连 接强度为权重 • 神经元的动力学已知:HH方程 • 突触连接强度的变化:赫布法则 • 研究网络上的动力系统(HH方程)对网 络结构的作用。 • 研究网络结构对网络上的动力系统的集 体行为(如同步等)的改变 • 展现大脑皮层功能分区形成的自组织机 制

产品生产关系网络 • 类比食物链网络,讨论经济领域中的物流关 系,了解网络的结构和抗干扰能力 • 资源、物品顶点,投入产出为边,顶点度和介数的分布特征 可以描写资源和物品及技术和生产在相应生产关系中的地位, 对于发现和保护关键资源和技术具有重要意义; • 技术的发展可以在网络上体现为新的顶点和新的边的形成, 可以用网络演化的 具研究经济的发展; • 网络聚类手段可以用于生产部门的划分。 § 为网络研究提供新的内容

研究内容 • 复杂网络的研究综合运用图论、概率论、 模拟等学科分支的思想方法,集中研究 各种复杂网络的共性,并于现实世界网 络的研究结合起来 • 中心研究内容: ° ° ° 复杂网络的形成机制和描述现实世界网 络的模型 复杂网络的结构稳定性 与复杂网络有关的扩散和输运行为

复杂网络的建模 °Agent-Based modeling °建筑在复杂网络之上的其他结构

复杂网络上的 Percolation ° Internet 的故障 - 线路故障和服务器故障 ° 恶意攻击 - 怎样的结构会降低网络瘫痪的机会

基于复杂网络的传染病动力学 ° ° 标准传染病动力学模型基于所谓的“ 完全混合”假定,而实际的接触传染 的传染病应该基于人们接触的网络模 型 三角债和产业网络中信用危机传播的 动力学

数学基础的研究 ° 什么时候平均场理论是正确的 - ° 中心极限定理强遍历性 弱遍历过程的平均场理论和连续化方法
2f9b6a1875798ae562904572cf395195.ppt