

5bd410f17d444376894875e9ae7edcab.ppt
- Количество слайдов: 79
 Machine Translation Speaker Prof. . Rajeev sangal International Institute of Information Technology, Hyderabad sangal@iiit. net Indo-German Workshop on Language technologies AU-KBC Research Centre, Chennai
Machine Translation Speaker Prof. . Rajeev sangal International Institute of Information Technology, Hyderabad sangal@iiit. net Indo-German Workshop on Language technologies AU-KBC Research Centre, Chennai
 CALTS, UNIV. OF HYDERABAD. SAP, LANGUAGE TECHNOLOGY Dr. Uma Maheswara Rao University of Hyderabad guraosh@uohyd. ernet. in CALTS has been in NLP for over a decade. It has participated in the following major projects: 1. NLP-TTP, DOE Govt. of India. 2. IPDA, DOE Govt. of India. 3. TRCT, TDIL, MCIT 4. English-Telugu, T 2 TMT UPE, UGC, UOH.
CALTS, UNIV. OF HYDERABAD. SAP, LANGUAGE TECHNOLOGY Dr. Uma Maheswara Rao University of Hyderabad guraosh@uohyd. ernet. in CALTS has been in NLP for over a decade. It has participated in the following major projects: 1. NLP-TTP, DOE Govt. of India. 2. IPDA, DOE Govt. of India. 3. TRCT, TDIL, MCIT 4. English-Telugu, T 2 TMT UPE, UGC, UOH.
 1. Morphological Analyzer cum Spell Checker for Telugu • A robust Morphological analyzer cum Spell Checker for Telugu. • With 97% recognition rate. • Tested on 5 million word corpora. • For the users of Windows O. S & Linux.
1. Morphological Analyzer cum Spell Checker for Telugu • A robust Morphological analyzer cum Spell Checker for Telugu. • With 97% recognition rate. • Tested on 5 million word corpora. • For the users of Windows O. S & Linux.
 2. A Multilingual Encyclopedic Electronic thesaurus for translators, MEET, a Web based linguistic application. • • • MEET enables quick access to various synonyms. Provides equivalents in other Indian languages and English. Also provides grammatical and Semantic information. A useful application for translators. Provides access to information in Indian languages on the web. • Currently includes only Marathi, Hindi, Bangla, Konkani and English. • The 2 nd phase proposes to include Telugu, Kannada and Oriya. • Word net for individual languages may be linked to the system.
2. A Multilingual Encyclopedic Electronic thesaurus for translators, MEET, a Web based linguistic application. • • • MEET enables quick access to various synonyms. Provides equivalents in other Indian languages and English. Also provides grammatical and Semantic information. A useful application for translators. Provides access to information in Indian languages on the web. • Currently includes only Marathi, Hindi, Bangla, Konkani and English. • The 2 nd phase proposes to include Telugu, Kannada and Oriya. • Word net for individual languages may be linked to the system.
 3. Telugu Hyper Grammar. • The Telugu Hyper Grammar, designed as a dynamically accessed and non-linearly organized grammar of Telugu grammar. • A user can access information at a particular module from any other module. • Provides access to a Morphological Analyzer, Generator and a Chunker. • Can access various bilingual and bi-directional digital lexica of Telugu and other Indian Languages like Hindi, Kannada, Tamil, Marathi, Oriya, Malayalam and English.
3. Telugu Hyper Grammar. • The Telugu Hyper Grammar, designed as a dynamically accessed and non-linearly organized grammar of Telugu grammar. • A user can access information at a particular module from any other module. • Provides access to a Morphological Analyzer, Generator and a Chunker. • Can access various bilingual and bi-directional digital lexica of Telugu and other Indian Languages like Hindi, Kannada, Tamil, Marathi, Oriya, Malayalam and English.
 4. English-Telugu Parallel Corpora. • Parallel Corpora are a set of thematically corresponding digital texts of some selected works. • Recent trends in Machine Translation are revolutionized by the use of Parallel Corpora. • Parallel Corpora give way to discover similarities and differences between a pair of languages. • A program for aligning parallel texts in English and Telugu is developed and in the process of testing. • Selected parallel texts in Telugu, Kannada, Tamil, Marathi and Malayalam are digitized.
4. English-Telugu Parallel Corpora. • Parallel Corpora are a set of thematically corresponding digital texts of some selected works. • Recent trends in Machine Translation are revolutionized by the use of Parallel Corpora. • Parallel Corpora give way to discover similarities and differences between a pair of languages. • A program for aligning parallel texts in English and Telugu is developed and in the process of testing. • Selected parallel texts in Telugu, Kannada, Tamil, Marathi and Malayalam are digitized.
 5. English-Telugu T 2 T Machine Translation System • English-Telugu Machine Translation System is being built at CALTS in collaboration with, IIIT, Hyderabad; Telugu University, Hyderabad; Osmania University, Hyderabad. • Uses an English-Telugu MAT lexicon of 42 K. • A wordform synthesizer for Telugu is developed and incorporated. • It incorporates an evolutionary semantic lexicon • It handles English sentences of a variety of complexity
5. English-Telugu T 2 T Machine Translation System • English-Telugu Machine Translation System is being built at CALTS in collaboration with, IIIT, Hyderabad; Telugu University, Hyderabad; Osmania University, Hyderabad. • Uses an English-Telugu MAT lexicon of 42 K. • A wordform synthesizer for Telugu is developed and incorporated. • It incorporates an evolutionary semantic lexicon • It handles English sentences of a variety of complexity
 6. MAT Lexica. • Bilingual and Multidirectional. • Machine Readable Dictionaries for Telugu-Hindi, Telugu-Kannada, Telugu-Tamil, Telugu-Marathi, Telugu-Oriya, Telugu-Bangla, Telugu-Malayalam, of 10 K are being developed in collaboration with the Telugu Academy. • The entries were based on the frequency of their occurrence in the corpus of Telugu. • The Dictionaries of Telugu-Hindi, Telugu-Kannada, Telugu-Tamil are already completed. • Major part of these dictionaries are developed through realigning the lexical resources existing at CALTS.
6. MAT Lexica. • Bilingual and Multidirectional. • Machine Readable Dictionaries for Telugu-Hindi, Telugu-Kannada, Telugu-Tamil, Telugu-Marathi, Telugu-Oriya, Telugu-Bangla, Telugu-Malayalam, of 10 K are being developed in collaboration with the Telugu Academy. • The entries were based on the frequency of their occurrence in the corpus of Telugu. • The Dictionaries of Telugu-Hindi, Telugu-Kannada, Telugu-Tamil are already completed. • Major part of these dictionaries are developed through realigning the lexical resources existing at CALTS.
 7. Collocations in Indian Languages. • Collocations or specialized word sequences play a crucial role in a language. It is extremely difficult to identify and translate effectively. They present one of the most challenging tasks in Natural Language Processing. • In the first phase, Telugu data was collected analyzed. • A long list of collocations are collected and checked whether the existing criteria are valid. • These collocations are compared against other specialized word sequences in the language to understand their functional and distributional properties.
7. Collocations in Indian Languages. • Collocations or specialized word sequences play a crucial role in a language. It is extremely difficult to identify and translate effectively. They present one of the most challenging tasks in Natural Language Processing. • In the first phase, Telugu data was collected analyzed. • A long list of collocations are collected and checked whether the existing criteria are valid. • These collocations are compared against other specialized word sequences in the language to understand their functional and distributional properties.
. • Idioms are extremely important but") 8. Machine Readable Dictionary of Idioms (Telugu. English). • Idioms are extremely important but the most ubiquitous, and less understood categories of language. • Machine-readable Idioms in English and their equivalents in Telugu and the mechanics of their recognition and transfer rules are being developed. • The Machine Readable text will be implemented in XML so that access and retrieval becomes easier and faster.
8. Machine Readable Dictionary of Idioms (Telugu. English). • Idioms are extremely important but the most ubiquitous, and less understood categories of language. • Machine-readable Idioms in English and their equivalents in Telugu and the mechanics of their recognition and transfer rules are being developed. • The Machine Readable text will be implemented in XML so that access and retrieval becomes easier and faster.
 9. Electronic Adult Literacy Primer for Telugu • This is developed as part of CALTS participation in Arohan (a literacy campaign adopted by the university). • Aimed at teaching the script or the written form of the language rather than the language itself. • Based on frequency of characters in the written texts. • Learning the most frequent but few characters would ensure greater coverage in learning recognition of characters. • Special features include characters with animation and speech. • A special attention on the presentation of allographs.
9. Electronic Adult Literacy Primer for Telugu • This is developed as part of CALTS participation in Arohan (a literacy campaign adopted by the university). • Aimed at teaching the script or the written form of the language rather than the language itself. • Based on frequency of characters in the written texts. • Learning the most frequent but few characters would ensure greater coverage in learning recognition of characters. • Special features include characters with animation and speech. • A special attention on the presentation of allographs.
 10. A generic system for morphological generation for Indian languages • Morphological generators for various Indian languages particularly for Telugu, Kannada, Tamil, Malayalam, Bangla and Oriya are in different stages of development. • A generic framework for wordform synthesis for Indian languages. • Includes testing module to find the efficiency and coverage of the system.
10. A generic system for morphological generation for Indian languages • Morphological generators for various Indian languages particularly for Telugu, Kannada, Tamil, Malayalam, Bangla and Oriya are in different stages of development. • A generic framework for wordform synthesis for Indian languages. • Includes testing module to find the efficiency and coverage of the system.
 11. Telugu-Tamil Machine translation system • Using the available resources at CALTS a Telugu. Tamil MT is being developed. • Uses the Telugu Morphological analyzer. • Uses the Tamil generator developed at CALTS. • Uses Telugu-Tamil dictionary developed as part of MAT Lexica. • Uses verb sense disambiguator based on verbs argument structure.
11. Telugu-Tamil Machine translation system • Using the available resources at CALTS a Telugu. Tamil MT is being developed. • Uses the Telugu Morphological analyzer. • Uses the Tamil generator developed at CALTS. • Uses Telugu-Tamil dictionary developed as part of MAT Lexica. • Uses verb sense disambiguator based on verbs argument structure.
 12. Word Sense Disambiguation using Argument Structure: • A system, based on the argument structure of Telugu verbs. • Uses feature based semantic lexicon. • Efficiently disambiguates polysemy of verbs in the context. • Is incorporated in Telugu-Tamil MT system.
12. Word Sense Disambiguation using Argument Structure: • A system, based on the argument structure of Telugu verbs. • Uses feature based semantic lexicon. • Efficiently disambiguates polysemy of verbs in the context. • Is incorporated in Telugu-Tamil MT system.
 13. A case sensitive roman translation for Indian languages as overall pattern • A roman transliteration Scheme for unwritten languages of India is developed. • A common transliteration scheme for the scripts of Brahmi derivates and non Brahmi derivates is developed. • Supra segmentals mapped on to roman characters • No nonunique character mapping • Allows complete conversion between various languages
13. A case sensitive roman translation for Indian languages as overall pattern • A roman transliteration Scheme for unwritten languages of India is developed. • A common transliteration scheme for the scripts of Brahmi derivates and non Brahmi derivates is developed. • Supra segmentals mapped on to roman characters • No nonunique character mapping • Allows complete conversion between various languages
 Language Engineering Research at Resource Centre for Indian Language Technology Solutions University of Hyderabad Dr. K. Narayana Murthy University of Hyderabad knmuh@yahoo. com
Language Engineering Research at Resource Centre for Indian Language Technology Solutions University of Hyderabad Dr. K. Narayana Murthy University of Hyderabad knmuh@yahoo. com
 So far • UCSG System of Syntax, Parsers • English-Kannada Machine Aided Translation • OCR for Telugu and other Indian Languages • Telugu Corpus (10 Million Words) • Experimental Text-to-Speech System for Telugu • A Variety of tools
So far • UCSG System of Syntax, Parsers • English-Kannada Machine Aided Translation • OCR for Telugu and other Indian Languages • Telugu Corpus (10 Million Words) • Experimental Text-to-Speech System for Telugu • A Variety of tools
 Post Editing Identify/Rate Word") Architecture of a Hybrid Machine Translation System SL Sentence Tagger(HMM) Post Editing Identify/Rate Word Groups (FSM, Markov Models, MI) Syntactic Generator Identify Clause Structure Assign Functional Roles to Word Groups Structural Description (TL Inst. ) (The Phrases & their Roles of each clause) Rate/Rank Role Assignments Best First Search for Best Parse Structural Description (SL Inst. ) (The Phrase & their Roles for each Clause) TL Sentence Planner Clause/Phrase/Word level Transfer (WSD Statistics)
Architecture of a Hybrid Machine Translation System SL Sentence Tagger(HMM) Post Editing Identify/Rate Word Groups (FSM, Markov Models, MI) Syntactic Generator Identify Clause Structure Assign Functional Roles to Word Groups Structural Description (TL Inst. ) (The Phrases & their Roles of each clause) Rate/Rank Role Assignments Best First Search for Best Parse Structural Description (SL Inst. ) (The Phrase & their Roles for each Clause) TL Sentence Planner Clause/Phrase/Word level Transfer (WSD Statistics)
 Research Activities Department of Computer Science & Engineering College of Engineering, Guindy Chennai – 600025 Participant : Dr. T. V. Geetha Other members: Dr. Ranjani Parthasarathi Ms. D. Manjula Mr. S. Swamynathan
Research Activities Department of Computer Science & Engineering College of Engineering, Guindy Chennai – 600025 Participant : Dr. T. V. Geetha Other members: Dr. Ranjani Parthasarathi Ms. D. Manjula Mr. S. Swamynathan
 Natural Language Processing Translation Support Systems Work done in the area • Morphological Analyzer & Generator for Tamil • Tamil Parser – Tackles both simple and complex sentences. Can handle sentences with a noun clause and multiple adjective and adverb clauses. • Universal Networking Language (UNL) for Tamil – At present all the UNL relations have been handled and simple sentences can be processed. Both Tamil to UNL and UNL to Tamil have been handled • Heuristic Rule based Automatic Tagger – Tagger works without a dictionary and it is based morphological heuristic rules and certain amount of lookahead
Natural Language Processing Translation Support Systems Work done in the area • Morphological Analyzer & Generator for Tamil • Tamil Parser – Tackles both simple and complex sentences. Can handle sentences with a noun clause and multiple adjective and adverb clauses. • Universal Networking Language (UNL) for Tamil – At present all the UNL relations have been handled and simple sentences can be processed. Both Tamil to UNL and UNL to Tamil have been handled • Heuristic Rule based Automatic Tagger – Tagger works without a dictionary and it is based morphological heuristic rules and certain amount of lookahead
 Natural Language Processing, Translation Support Systems - Possible Areas of cooperation Ø Tamil Sentence generator ¯Incorporation of grammatical structures to facilitate sentence formation ¯Design of a format to be given as input to sentence generator ¯Generation of complex sentences Tamil Parser and Semantic Analyzer ¯Tackling of complex grammatical structures ¯Case based semantic analysis of simple sentences ¯Tackling of ambiguous and incorrect sentences by the parser
Natural Language Processing, Translation Support Systems - Possible Areas of cooperation Ø Tamil Sentence generator ¯Incorporation of grammatical structures to facilitate sentence formation ¯Design of a format to be given as input to sentence generator ¯Generation of complex sentences Tamil Parser and Semantic Analyzer ¯Tackling of complex grammatical structures ¯Case based semantic analysis of simple sentences ¯Tackling of ambiguous and incorrect sentences by the parser
 Natural Language Processing Group Computer Sc. & Engg. Department JADAVPUR UNIVERSITY KOLKATA – 700 032, INDIA. Professor Sivaji Bandyopadhyay sivaji_ju@vsnl. com
Natural Language Processing Group Computer Sc. & Engg. Department JADAVPUR UNIVERSITY KOLKATA – 700 032, INDIA. Professor Sivaji Bandyopadhyay sivaji_ju@vsnl. com
 Research Areas • Natural Access to Internet & Other Resources – Headline Generation – Headline Translation – Document Translation – Multilingual Multidocument Summarization • Cross-lingual Information Management – Multilingual and Cross-lingual IR – Open Domain Question Answering
Research Areas • Natural Access to Internet & Other Resources – Headline Generation – Headline Translation – Document Translation – Multilingual Multidocument Summarization • Cross-lingual Information Management – Multilingual and Cross-lingual IR – Open Domain Question Answering
 Natural Access to Internet & Other Resources • Headline Generation – A machine translation problem • the input document identified by a set of features and output headline represents some of them – Example Base • Set of features in the input document and the headline template(s) – Implemented for generating headlines from cricket news in English
Natural Access to Internet & Other Resources • Headline Generation – A machine translation problem • the input document identified by a set of features and output headline represents some of them – Example Base • Set of features in the input document and the headline template(s) – Implemented for generating headlines from cricket news in English
 Natural Access to Internet & Other Resources • Headline Translation – A Hybrid MT system for translating English news headlines to Bengali – Syntactic and Semantic classification of news headlines done – Anaphora and Coreference classes identified in news headlines – Translation Strategy The input headline first searched in Translation Memory, else tagged and searched in Tagged Example Base, else analyzed and matched in Phrasal Example Base, else heuristics applied
Natural Access to Internet & Other Resources • Headline Translation – A Hybrid MT system for translating English news headlines to Bengali – Syntactic and Semantic classification of news headlines done – Anaphora and Coreference classes identified in news headlines – Translation Strategy The input headline first searched in Translation Memory, else tagged and searched in Tagged Example Base, else analyzed and matched in Phrasal Example Base, else heuristics applied
 Natural Access to Internet & Other Resources • Document Translation – Prototype developed for A Hybrid MT system from English to Bengali – Translation Strategy • Identify the constituent phrases of a sentence using a Shallow Parser • translate them individually using an Example Base • arrange the translated phrases using heuristics to form the target language output • Verb phrases translated using Morphological Paradigm Suffix Tables
Natural Access to Internet & Other Resources • Document Translation – Prototype developed for A Hybrid MT system from English to Bengali – Translation Strategy • Identify the constituent phrases of a sentence using a Shallow Parser • translate them individually using an Example Base • arrange the translated phrases using heuristics to form the target language output • Verb phrases translated using Morphological Paradigm Suffix Tables
 Natural Access to Internet & Other Resources • Multilingual Multidocument Summarization – Multidocument summarization in each language • Summarize one of the documents using extraction methods • Revise the summary using other documents – Summary in the target language is the reference summary – Translate all summaries to the target language – Revise the reference summary
Natural Access to Internet & Other Resources • Multilingual Multidocument Summarization – Multidocument summarization in each language • Summarize one of the documents using extraction methods • Revise the summary using other documents – Summary in the target language is the reference summary – Translate all summaries to the target language – Revise the reference summary
 Efforts in Language & Speech Technology Natural Language Processing Lab Centre for Development of Advanced Computing (Ministry of Communications & Information Technology) ‘Anusandhan Bhawan’, C 56/1 Sector 62, Noida – 201 307, India karunesharora@cdacnoida. com
Efforts in Language & Speech Technology Natural Language Processing Lab Centre for Development of Advanced Computing (Ministry of Communications & Information Technology) ‘Anusandhan Bhawan’, C 56/1 Sector 62, Noida – 201 307, India karunesharora@cdacnoida. com
 developed by IIT Kanpur. System") Translation Support System Technology : Angla Bharati (Rule base) developed by IIT Kanpur. System developed jointly by IIT, Kanpur and CDAC Noida Operating system support : LINUX/ WINDOWS Performance : 85% correct parsing, 60% correct translation Embedded Text Editor , Pre Processor and Post editor Lexicon : 25, 000 root words
Translation Support System Technology : Angla Bharati (Rule base) developed by IIT Kanpur. System developed jointly by IIT, Kanpur and CDAC Noida Operating system support : LINUX/ WINDOWS Performance : 85% correct parsing, 60% correct translation Embedded Text Editor , Pre Processor and Post editor Lexicon : 25, 000 root words
 Gyan Nidhi: Multi-Lingual Aligned Parallel Corpus What it is? The multilingual parallel text corpus contains the same text translated in more than one language. What Gyan Nidhi contains? Gyan. Nidhi corpus consists of text in English and 11 Indian languages (Hindi, Punjabi, Marathi, Bengali, Oriya, Gujarati, Telugu, Tamil, Kannada, Malayalam, Assamese). It aims to digitize 1 million pages altogether containing at least 50, 000 pages in each Indian language and English. Source for Parallel Corpus • National Book Trust India Sahitya Akademi • Navjivan Publishing House Publications Division • SABDA, Pondicherry
Gyan Nidhi: Multi-Lingual Aligned Parallel Corpus What it is? The multilingual parallel text corpus contains the same text translated in more than one language. What Gyan Nidhi contains? Gyan. Nidhi corpus consists of text in English and 11 Indian languages (Hindi, Punjabi, Marathi, Bengali, Oriya, Gujarati, Telugu, Tamil, Kannada, Malayalam, Assamese). It aims to digitize 1 million pages altogether containing at least 50, 000 pages in each Indian language and English. Source for Parallel Corpus • National Book Trust India Sahitya Akademi • Navjivan Publishing House Publications Division • SABDA, Pondicherry
 Gyan. Nidhi Block Diagram
Gyan. Nidhi Block Diagram
 Gyan Nidhi: Multi-Lingual Aligned Parallel Corpus Platform : Windows Data Encoding : XML, UNICODE Portability of Data : Data in XML format supports various platforms Applications of Gyan. Nidhi Automatic Dictionary extraction Creation of Translation memory Example Based Machine Translation (EBMT) Language research study and analysis Language Modeling
Gyan Nidhi: Multi-Lingual Aligned Parallel Corpus Platform : Windows Data Encoding : XML, UNICODE Portability of Data : Data in XML format supports various platforms Applications of Gyan. Nidhi Automatic Dictionary extraction Creation of Translation memory Example Based Machine Translation (EBMT) Language research study and analysis Language Modeling
 Sample Screen Shot : Prabandhika
Sample Screen Shot : Prabandhika
 Tools: Vishleshika : Statistical Text Analyzer • Vishleshika is a tool for Statistical Text Analysis for Hindi extendible to other Indian Languages text • It examines input text and generates various statistics, e. g. : • Sentence statistics • Word statistics • Character statistics • Text Analyzer presents analysis in Textual as well as Graphical form.
Tools: Vishleshika : Statistical Text Analyzer • Vishleshika is a tool for Statistical Text Analysis for Hindi extendible to other Indian Languages text • It examines input text and generates various statistics, e. g. : • Sentence statistics • Word statistics • Character statistics • Text Analyzer presents analysis in Textual as well as Graphical form.
 Sample output: Character statistics Above Graph shows that the distribution is almost equal in Hindi and Nepali in the sample text. Most frequent consonants in the Hindi Most frequent consonants in the Nepali Results also show that these six consonants constitute more than 50% of the consonants usage.
Sample output: Character statistics Above Graph shows that the distribution is almost equal in Hindi and Nepali in the sample text. Most frequent consonants in the Hindi Most frequent consonants in the Nepali Results also show that these six consonants constitute more than 50% of the consonants usage.
 Vishleshika: Word and sentence Statistics
Vishleshika: Word and sentence Statistics
 Machine Translation Projects AU-KBC Research Centre MIT Campus, Anna University Chennai
Machine Translation Projects AU-KBC Research Centre MIT Campus, Anna University Chennai
 Tamil - Hindi MAT • Tamil-Hindi Anusaaraka based MAT – Machine-Aided Translation system – Lexical level translation – In collaboration with IIITH & TTU – 80 -85% coverage – User Interfaces: Stand-alone, API, and Web-based on-line – Byproducts • Tamil morphological analyser • Tamil-Hindi bilingual dictionary (~ 36 k)
Tamil - Hindi MAT • Tamil-Hindi Anusaaraka based MAT – Machine-Aided Translation system – Lexical level translation – In collaboration with IIITH & TTU – 80 -85% coverage – User Interfaces: Stand-alone, API, and Web-based on-line – Byproducts • Tamil morphological analyser • Tamil-Hindi bilingual dictionary (~ 36 k)
 Tamil-Hindi MAT System
Tamil-Hindi MAT System
 English - Tamil MAT • English - Tamil MAT - A Prototype – Includes exhaustive syntactical analysis – Limited Vocabulary (100 -150) – Small set of Transfer rules • Phase - II – Extending the prototype to the full-fledged system – Design includes Syntactic and Semantic processing – Trilingual system: English Tamil Hindi
English - Tamil MAT • English - Tamil MAT - A Prototype – Includes exhaustive syntactical analysis – Limited Vocabulary (100 -150) – Small set of Transfer rules • Phase - II – Extending the prototype to the full-fledged system – Design includes Syntactic and Semantic processing – Trilingual system: English Tamil Hindi
") English-Tamil MAT (Prototype)
English-Tamil MAT (Prototype)
 English-Tamil MAT System
English-Tamil MAT System
 Machine Translation and Lexical Resources Activity at IIT Bombay Pushpak Bhattacharyya Computer Science and Engineering Department Indian Institute of Technology Bombay pb@cse. iitb. ac. in http: //www. cse. iitb. ac. in/pb
Machine Translation and Lexical Resources Activity at IIT Bombay Pushpak Bhattacharyya Computer Science and Engineering Department Indian Institute of Technology Bombay pb@cse. iitb. ac. in http: //www. cse. iitb. ac. in/pb
 UNL Based MT: the scenario ENGLISH ENCONVERSION RUSSIAN UNL DECONVERSION FRENCH HINDI
UNL Based MT: the scenario ENGLISH ENCONVERSION RUSSIAN UNL DECONVERSION FRENCH HINDI
 UNL Example arrange agt obj plc John meeting residence
UNL Example arrange agt obj plc John meeting residence
 Components of the UNL System • Universal Word • Relation Labels • Attributes
Components of the UNL System • Universal Word • Relation Labels • Attributes
 Agt defines a thing which initiates an action. agt (do, thing)") Relation agt (agent) Agt defines a thing which initiates an action. agt (do, thing) Syntax agt[": "
Relation agt (agent) Agt defines a thing which initiates an action. agt (do, thing) Syntax agt[": "
 Attributes • Used to describe what is said from the speaker's point of view. • In particular captures number, tense, aspect and modality information.
Attributes • Used to describe what is said from the speaker's point of view. • In particular captures number, tense, aspect and modality information.
, flower(icl>thing)) • I saw flowers") Example Attributes • I see a flower UNL: obj(see(icl>do), flower(icl>thing)) • I saw flowers UNL: obj(see(icl>do). @past, flower(icl>thing). @pl) • Did I see flowers? UNL: obj(see(icl>do). @past. @interrogative, flower(icl>thing). @pl) • Please see the flowers? UNL: obj(see(icl>do). @past. @request, flower(icl>thing). @pl. @definite)
Example Attributes • I see a flower UNL: obj(see(icl>do), flower(icl>thing)) • I saw flowers UNL: obj(see(icl>do). @past, flower(icl>thing). @pl) • Did I see flowers? UNL: obj(see(icl>do). @past. @interrogative, flower(icl>thing). @pl) • Please see the flowers? UNL: obj(see(icl>do). @past. @request, flower(icl>thing). @pl. @definite)
 The Analyser Machine Analysis Rules C Node List Dictionary Enconverter ni-1 A ni A C C ni+1 ni+2 ni+3 A D Node-net B C E
The Analyser Machine Analysis Rules C Node List Dictionary Enconverter ni-1 A ni A C C ni+1 ni+2 ni+3 A D Node-net B C E
 Strategy for Analysis • Morphological Analysis • Syntactico-Semantic Analysis
Strategy for Analysis • Morphological Analysis • Syntactico-Semantic Analysis
 Analysis of a simple sentences << A Report of John’s genius reached King’s ears>> article and noun are combined and attribute@indef is added to the noun. <<[Report ][of] John’s genius reached king’s ears>> Right shift to put preposition with the succeeding noun. <> Ram’s being a possessing noun, shift right. <> These two nouns are resolved into relation pos and first noun is deleted:
Analysis of a simple sentences << A Report of John’s genius reached King’s ears>> article and noun are combined and attribute@indef is added to the noun. <<[Report ][of] John’s genius reached king’s ears>> Right shift to put preposition with the succeeding noun. <> Ram’s being a possessing noun, shift right. <> These two nouns are resolved into relation pos and first noun is deleted:
 Use of Lexical Resources • Automatic Generation of the UW to language dictionary (Verma and Bhattacharyya, Global Wordnet Conference, Czeck Republic, 2004) • Universal Word generation • Semantic attribute generation • Heavy use of wordnets and ontologies
Use of Lexical Resources • Automatic Generation of the UW to language dictionary (Verma and Bhattacharyya, Global Wordnet Conference, Czeck Republic, 2004) • Universal Word generation • Semantic attribute generation • Heavy use of wordnets and ontologies
 Wordnet and Lexical Resources • Approximately 12000 Hindi synsets corresponding to about 35000 root words of Hindi. • Approximately 7000 Hindi synsets corresponding to about 16000 root words of Hindi. • Verb Hierarchy of approximately 4000 unique words corresponding to 6000 senses.
Wordnet and Lexical Resources • Approximately 12000 Hindi synsets corresponding to about 35000 root words of Hindi. • Approximately 7000 Hindi synsets corresponding to about 16000 root words of Hindi. • Verb Hierarchy of approximately 4000 unique words corresponding to 6000 senses.
 Word. Net Sub-Graph sa. Mrc anaa Hyponymy Aavaasa , inavaasa Hypernymy Meronymy rsaao [-Gar Hyponymy Aa^M gana baramad a M e r o n y m y Gar , ga. Rh Hyponymy Sayana kxa Gloss manau. Yyaao. M ka Cayaa hu. Aa vah sqaana jaao d. Ivaarao. M sao Gaor kr banaayaa jaata h. O AQyana kxa Aitiqa ga. Rh Aa. Eam a Jaaop. D, I
Word. Net Sub-Graph sa. Mrc anaa Hyponymy Aavaasa , inavaasa Hypernymy Meronymy rsaao [-Gar Hyponymy Aa^M gana baramad a M e r o n y m y Gar , ga. Rh Hyponymy Sayana kxa Gloss manau. Yyaao. M ka Cayaa hu. Aa vah sqaana jaao d. Ivaarao. M sao Gaor kr banaayaa jaata h. O AQyana kxa Aitiqa ga. Rh Aa. Eam a Jaaop. D, I
 Languages under Study Language Analysis Status Generation Status English D- 60000 R- 5000 D- 60000 R- 400 Hindi D- 75000 R- 5700 D- 75000 R- 6500 Marathi D- 4000 R- 2200 D- 4000 R- 6000 Bengali D- 500 R- 1800 D- 500 R- 2100
Languages under Study Language Analysis Status Generation Status English D- 60000 R- 5000 D- 60000 R- 400 Hindi D- 75000 R- 5700 D- 75000 R- 6500 Marathi D- 4000 R- 2200 D- 4000 R- 6000 Bengali D- 500 R- 1800 D- 500 R- 2100
 Conclusions • Work going on in the creation of Indian language wordnets (Hindi, Marathi in IIT Bombay; Dravidian in Anna University). • Interlingua has a the attractive possibility of being used as a knowledge representation and applying to interesting applications like summarization, text clustering, meaning based multilingual search engines.
Conclusions • Work going on in the creation of Indian language wordnets (Hindi, Marathi in IIT Bombay; Dravidian in Anna University). • Interlingua has a the attractive possibility of being used as a knowledge representation and applying to interesting applications like summarization, text clustering, meaning based multilingual search engines.
 Anglabharathi A MULTILINGUAL MACHINE AIDED TRANSLATION METHODLOGY FOR TRANSLATION FROM ENGLISH TO INDIAN LANGUAGES Dr. Ajai Jain Department of Computer science and Engineering Indian Institute of Technology Kanpur. India ajain@iitk. ac. in
Anglabharathi A MULTILINGUAL MACHINE AIDED TRANSLATION METHODLOGY FOR TRANSLATION FROM ENGLISH TO INDIAN LANGUAGES Dr. Ajai Jain Department of Computer science and Engineering Indian Institute of Technology Kanpur. India ajain@iitk. ac. in
 Machine Translation Work at IIT Kanpur ANGLABHARTI represents a machine-aided translation methodology specifically designed for translating English to Indian languages. Anglabharti uses a pseudo-interlingua approach. It analyses English only once and creates an intermediate structure with most of the disambiguation performed The intermediate structure is then converted to each Indian language through a process of text-generation. The effort in analyzing the English sentences is about 70% and the textgeneration for the rest of the 30%. additional 30% effort, a new English to Indian language translator can be built.
Machine Translation Work at IIT Kanpur ANGLABHARTI represents a machine-aided translation methodology specifically designed for translating English to Indian languages. Anglabharti uses a pseudo-interlingua approach. It analyses English only once and creates an intermediate structure with most of the disambiguation performed The intermediate structure is then converted to each Indian language through a process of text-generation. The effort in analyzing the English sentences is about 70% and the textgeneration for the rest of the 30%. additional 30% effort, a new English to Indian language translator can be built.
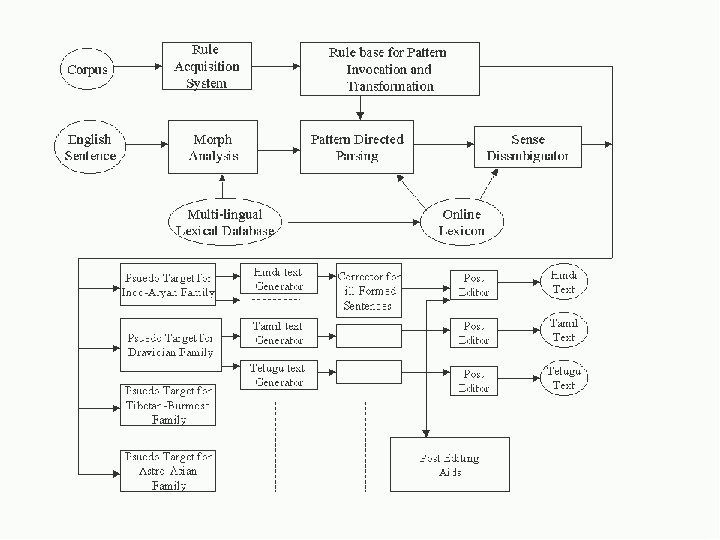
 Language Technologies Research Centre at IIIT Hyderabad Machine Translation Projects Rajeev Sangal sangal@iiit. net
Language Technologies Research Centre at IIIT Hyderabad Machine Translation Projects Rajeev Sangal sangal@iiit. net
 Strategy for Indian Language MT • Use state-of-the-art technology – Take the best in the world – Take open source technology • Multilingual (NOT bilingual) system – Identify features/tasks common to all Indian Languages.
Strategy for Indian Language MT • Use state-of-the-art technology – Take the best in the world – Take open source technology • Multilingual (NOT bilingual) system – Identify features/tasks common to all Indian Languages.
 Strategy for MT … • Use Machine learning techniques extensively – But combine manual with automatic • MAJOR TASK: Build lexical resources
Strategy for MT … • Use Machine learning techniques extensively – But combine manual with automatic • MAJOR TASK: Build lexical resources
 Shakti MT System Technical Features • Hybrid approach • Constituent structure chunks with dependency relations • Transfer system with inter-lingual properties • Named entity recognition
Shakti MT System Technical Features • Hybrid approach • Constituent structure chunks with dependency relations • Transfer system with inter-lingual properties • Named entity recognition
 English Sentence Target Language Independent Target Language Dependent Eng POS Tagger morph & chunker Sentence Parser Indian Language Generator Parsed Output Word Sense Disambiguation (WSD) Tense, Aspect Modality Lookup IL Sentence Word senses marked Transfer Grammar Rule Application Bilingual work E-I Dictionary lookup
English Sentence Target Language Independent Target Language Dependent Eng POS Tagger morph & chunker Sentence Parser Indian Language Generator Parsed Output Word Sense Disambiguation (WSD) Tense, Aspect Modality Lookup IL Sentence Word senses marked Transfer Grammar Rule Application Bilingual work E-I Dictionary lookup
 Shakti MT Status • Producing output in 4 Ils – English to Hindi, Telugu, Marathi (Telugu jointly with Univ of Hyd) – English to Tamil (by AU-KBC)
Shakti MT Status • Producing output in 4 Ils – English to Hindi, Telugu, Marathi (Telugu jointly with Univ of Hyd) – English to Tamil (by AU-KBC)
 Lexical Resources in IL • Dictionaries for MT – English to Ils – (English to 4 ILs collaborative effort) – Parellel senses • Transfer grammars - verb frames
Lexical Resources in IL • Dictionaries for MT – English to Ils – (English to 4 ILs collaborative effort) – Parellel senses • Transfer grammars - verb frames
 Annotated Corpora • Part-of-speech tagged corpora for Ils – Common tagset - Designed to handle features of Indian languages (Differs from Penn tagset slightly) • Shallow-parsed corpora • Ann. Corra treebank – Based on dependency analysis – Uses Paninian karaka relations
Annotated Corpora • Part-of-speech tagged corpora for Ils – Common tagset - Designed to handle features of Indian languages (Differs from Penn tagset slightly) • Shallow-parsed corpora • Ann. Corra treebank – Based on dependency analysis – Uses Paninian karaka relations
 A Pragmatic Approach to Machine Translation for Indian Languages Tanveer A Faruquie IBM India Research Lab New Delhi
A Pragmatic Approach to Machine Translation for Indian Languages Tanveer A Faruquie IBM India Research Lab New Delhi
 Machine Translation @ibm. com v. IBM Web. Sphere Translation Server Ø 16 language pairs ØOn the fly translation of both static and dynamic web-pages ØTranslation using a servlet or JSP ØWindows NT, AIX, Solaris and Linux ØUp to 500 words per second ØMachine translation services for multilingual email and chat
Machine Translation @ibm. com v. IBM Web. Sphere Translation Server Ø 16 language pairs ØOn the fly translation of both static and dynamic web-pages ØTranslation using a servlet or JSP ØWindows NT, AIX, Solaris and Linux ØUp to 500 words per second ØMachine translation services for multilingual email and chat
 Machine Translation @research. ibm. com v. Statistical Machine Translation ØLate 80’s: Source-Channel Paradigm • IBM Translation Models 1 -5 ØAdvantages • Data Driven • Scalable • Easy to build a new MT system • Bidirectional • No deep skills in Linguistics required ØEnglish-French, Arabic-English, Chinese-English, English-Hindi Logic-based Machine Translation ØDeep level of language analysis ØVery Good translation quality
Machine Translation @research. ibm. com v. Statistical Machine Translation ØLate 80’s: Source-Channel Paradigm • IBM Translation Models 1 -5 ØAdvantages • Data Driven • Scalable • Easy to build a new MT system • Bidirectional • No deep skills in Linguistics required ØEnglish-French, Arabic-English, Chinese-English, English-Hindi Logic-based Machine Translation ØDeep level of language analysis ØVery Good translation quality
 Machine Translation: India v. Problem #1 ØToo many language pairs! § Implication: Language Barrier will continue to be a problem. v. Problem #2 ØFragmentation of efforts § No consolidated effort at solving MT problems v. Problem #3 ØLack of NLP tools ØLack of Corpora ØLack of standardized methods of evaluation, encoding, etc. ØHighly Specialized § Poor quality systems, No reusable components, No real learning from each other’s work v. Solutions! ØProblem #1: Statistical Machine Translation ØProblem #2: Collaborative work (2 -3 teams) ØProblem #3: Common Tools Framework plus Standards
Machine Translation: India v. Problem #1 ØToo many language pairs! § Implication: Language Barrier will continue to be a problem. v. Problem #2 ØFragmentation of efforts § No consolidated effort at solving MT problems v. Problem #3 ØLack of NLP tools ØLack of Corpora ØLack of standardized methods of evaluation, encoding, etc. ØHighly Specialized § Poor quality systems, No reusable components, No real learning from each other’s work v. Solutions! ØProblem #1: Statistical Machine Translation ØProblem #2: Collaborative work (2 -3 teams) ØProblem #3: Common Tools Framework plus Standards
 Pragmatic Steps v Build Easy-to-use tools with standardized APIs ØMorphological Analyzers, POS Taggers, Parsers, Corpus Processing Tools • Data driven approach • Reusable Components v. Build Parallel Corpora, Annotated Corpora, Tree Banks v. Standardized Evaluation: Metrics, Test corpora v. Quick Prototypes for new language pairs
Pragmatic Steps v Build Easy-to-use tools with standardized APIs ØMorphological Analyzers, POS Taggers, Parsers, Corpus Processing Tools • Data driven approach • Reusable Components v. Build Parallel Corpora, Annotated Corpora, Tree Banks v. Standardized Evaluation: Metrics, Test corpora v. Quick Prototypes for new language pairs
 Scalable SMT framework for Indian Languages v Work @irl. ibm. com Ø Source-Channel Paradigm Ø Prototype Hindi-English bidirectional SMT system: • 200, 000 sentence pairs of parallel corpus • 80 Million words monolingual Hindi corpus • 800 Million words monolingual English corpus Ø Evaluation : English-Hindi Training corpus size No of test sentences 150, 000 sentences 1032 BLEU Score 0. 1391 NIST Score 4. 6296
Scalable SMT framework for Indian Languages v Work @irl. ibm. com Ø Source-Channel Paradigm Ø Prototype Hindi-English bidirectional SMT system: • 200, 000 sentence pairs of parallel corpus • 80 Million words monolingual Hindi corpus • 800 Million words monolingual English corpus Ø Evaluation : English-Hindi Training corpus size No of test sentences 150, 000 sentences 1032 BLEU Score 0. 1391 NIST Score 4. 6296
 Expert Software Consultants Ltd. Dr. Mukul K Sinha C-7, Almora Bhavan, 2 nd Floor, NDSE-I, New Delhi 110049 Tel: 91 -11 -24642675/24649382 E-mail: expert@vsnl. com
Expert Software Consultants Ltd. Dr. Mukul K Sinha C-7, Almora Bhavan, 2 nd Floor, NDSE-I, New Delhi 110049 Tel: 91 -11 -24642675/24649382 E-mail: expert@vsnl. com
 • Varta: Indic") Language Technology: Messaging • Bharati: Indic Multi-script Message Server (Unicode Complaint) • Varta: Indic Multi-script Internet Chat System • • Valmiki: Indic Multi-script Text Editor Indic IME: INSCRIPT & Phonetic
Language Technology: Messaging • Bharati: Indic Multi-script Message Server (Unicode Complaint) • Varta: Indic Multi-script Internet Chat System • • Valmiki: Indic Multi-script Text Editor Indic IME: INSCRIPT & Phonetic
 • Sandhi-Vichhed System of Sanskrit Shlokas With help") Language Processing Tool: Anavaya System (Sanskrit) • Sandhi-Vichhed System of Sanskrit Shlokas With help of Lexicon & Sandhi Grammar Useful for Easy Understanding by Readers Useful for Machine Translation (With Association of School of Computer & Systems Science. , Jawaharlal Nehru University, New Delhi)
Language Processing Tool: Anavaya System (Sanskrit) • Sandhi-Vichhed System of Sanskrit Shlokas With help of Lexicon & Sandhi Grammar Useful for Easy Understanding by Readers Useful for Machine Translation (With Association of School of Computer & Systems Science. , Jawaharlal Nehru University, New Delhi)
 Multi-modal Messaging System: Samvaad • Samvaad Script-less Speech mail System Audio Visual Interface with Mouse/ Touch screen (No Keyboard) For non-technical savvy people For people of any language
Multi-modal Messaging System: Samvaad • Samvaad Script-less Speech mail System Audio Visual Interface with Mouse/ Touch screen (No Keyboard) For non-technical savvy people For people of any language
 Language Technology: Professional/ Research Associations • Dr. Mukul K Sinha AU-KBC, Chennai JNU, New Delhi BITS Pilani • Pawan Kumar JNU, New Delhi • Tanmoy Prasad UP Technical University, Noida
Language Technology: Professional/ Research Associations • Dr. Mukul K Sinha AU-KBC, Chennai JNU, New Delhi BITS Pilani • Pawan Kumar JNU, New Delhi • Tanmoy Prasad UP Technical University, Noida