

лекция 1.ppt
- Количество слайдов: 83
 LOGO Кластерный анализ Математический аспект
LOGO Кластерный анализ Математический аспект
 Data Mining 1. кластерный анализ 2. метод главных компонент 3. факторный анализ
Data Mining 1. кластерный анализ 2. метод главных компонент 3. факторный анализ
 Классификация и кластеризация v Классификация (от лат. classis — разряд, класс и facio — делаю, раскладываю) система соподчиненных понятий (классов объектов) какой-либо области знания или деятельности человека, часто представляемая в виде различных по форме схем (таблиц) и используемая как средство для установления связей между этими понятиями или классами объектов, а также для точной ориентировки в многообразии понятий или соответствующих объектов.
Классификация и кластеризация v Классификация (от лат. classis — разряд, класс и facio — делаю, раскладываю) система соподчиненных понятий (классов объектов) какой-либо области знания или деятельности человека, часто представляемая в виде различных по форме схем (таблиц) и используемая как средство для установления связей между этими понятиями или классами объектов, а также для точной ориентировки в многообразии понятий или соответствующих объектов.
 Классификация v Классификация - упорядочение по некоторому принципу множество объектов, которые имеют сходные классификационные признаки (одно или несколько свойств), выбранных для определения сходства или различия между этими объектами
Классификация v Классификация - упорядочение по некоторому принципу множество объектов, которые имеют сходные классификационные признаки (одно или несколько свойств), выбранных для определения сходства или различия между этими объектами
 Процесс классификации v Цель процесса классификации состоит в том, чтобы построить модель, которая использует прогнозирующие атрибуты в качестве входных параметров и получает значение зависимого атрибута. Процесс классификации заключается в разбиении множества объектов на классы по определенному критерию.
Процесс классификации v Цель процесса классификации состоит в том, чтобы построить модель, которая использует прогнозирующие атрибуты в качестве входных параметров и получает значение зависимого атрибута. Процесс классификации заключается в разбиении множества объектов на классы по определенному критерию.
 принадлежащих императору; б) набальзамированных; в) дрессированных;") Древняя китайская классификация животных Животные подразделяются на: а) принадлежащих императору; б) набальзамированных; в) дрессированных; г) молочных поросят; д) сирен; е) сказочных; ж) бродячих собак; з) включённых в данную классификацию; и) дрожащих, как сумасшедшие; к) неисчислимых; л) нарисованных самой лучшей верблюжьей кисточкой; м) других; н) тех, которые только что разбили цветочную вазу и о) тех, которые издалека напоминают мух. (Хорхе Луис Борхес, Другие исследования: 1937— 1952).
Древняя китайская классификация животных Животные подразделяются на: а) принадлежащих императору; б) набальзамированных; в) дрессированных; г) молочных поросят; д) сирен; е) сказочных; ж) бродячих собак; з) включённых в данную классификацию; и) дрожащих, как сумасшедшие; к) неисчислимых; л) нарисованных самой лучшей верблюжьей кисточкой; м) других; н) тех, которые только что разбили цветочную вазу и о) тех, которые издалека напоминают мух. (Хорхе Луис Борхес, Другие исследования: 1937— 1952).
 Классификация деление должно быть последовательным правила члены деления должны взаимно исключать друга в каждом акте деления необходимо применять только одно основание деление должно быть соразмерным
Классификация деление должно быть последовательным правила члены деления должны взаимно исключать друга в каждом акте деления необходимо применять только одно основание деление должно быть соразмерным
.") Кластеризация v Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или классы). Если данные выборки представить как точки в признаковом пространстве, то задача кластеризации сводится к определению "сгущений точек".
Кластеризация v Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или классы). Если данные выборки представить как точки в признаковом пространстве, то задача кластеризации сводится к определению "сгущений точек".
 Наиболее широко распространенные формы скоплений
Наиболее широко распространенные формы скоплений
 Цель кластеризации - поиск существующих структур путем: • • • понимания данных путём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа; сжатия данных. Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера; обнаружения новизны. Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
Цель кластеризации - поиск существующих структур путем: • • • понимания данных путём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа; сжатия данных. Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера; обнаружения новизны. Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
 Сравнение классификации и кластеризации Характеристика Классификация Кластеризация Контролируемость обучения Контролируемое обучение Неконтролируемое обучение Стратегия Обучение с учителем Обучение без учителя Наличие метки класса Обучающее множество сопровождается меткой, указывающей класс, к которому относится наблюдение Метки класса обучающего множества неизвестны Новые данные классифицируются на Основание для классификации основании обучающего множества Дано множество данных с целью установления существования классов или кластеров данных
Сравнение классификации и кластеризации Характеристика Классификация Кластеризация Контролируемость обучения Контролируемое обучение Неконтролируемое обучение Стратегия Обучение с учителем Обучение без учителя Наличие метки класса Обучающее множество сопровождается меткой, указывающей класс, к которому относится наблюдение Метки класса обучающего множества неизвестны Новые данные классифицируются на Основание для классификации основании обучающего множества Дано множество данных с целью установления существования классов или кластеров данных

 Кластерный анализ v. Кластерный анализ – это способ группировки многомерных объектов, основанный на представлении результатов отдельных наблюдений точками подходящего геометрического пространства с последующим выделением групп как «сгустков» этих точек (кластеров, таксонов). «Кластер» (cluster) в английском языке означает «сгусток» , «гроздь винограда» , «скопление звезд» и т. д. Термин кластерный анализ, впервые введенный Трионом (Tryon) в 1939 году.
Кластерный анализ v. Кластерный анализ – это способ группировки многомерных объектов, основанный на представлении результатов отдельных наблюдений точками подходящего геометрического пространства с последующим выделением групп как «сгустков» этих точек (кластеров, таксонов). «Кластер» (cluster) в английском языке означает «сгусток» , «гроздь винограда» , «скопление звезд» и т. д. Термин кластерный анализ, впервые введенный Трионом (Tryon) в 1939 году.
 Ø Первые работы, описывающие методы кластерного анализа относятся к концу 30 -х годов. Ø Считается, что термин «кластерный анализ» первым в употребление ввёл американский психолог из университета Беркли Роберт Трайон (Robert C. Tryon) в 1939. Ø Однако активный интерес к данной теме пришёлся на период 60 -80 гг. Ø Импульсом для разработки многих кластерных методов послужила книга «Начала численной таксономии» , опубликованная в 1963 г. двумя биологами — Робертом Сокэлом и Петером Снитом
Ø Первые работы, описывающие методы кластерного анализа относятся к концу 30 -х годов. Ø Считается, что термин «кластерный анализ» первым в употребление ввёл американский психолог из университета Беркли Роберт Трайон (Robert C. Tryon) в 1939. Ø Однако активный интерес к данной теме пришёлся на период 60 -80 гг. Ø Импульсом для разработки многих кластерных методов послужила книга «Начала численной таксономии» , опубликованная в 1963 г. двумя биологами — Робертом Сокэлом и Петером Снитом
 Роберт Сокэл Ян Чекановский. Питер Снит
Роберт Сокэл Ян Чекановский. Питер Снит
 плотность; 2) дисперсия; 3) размеры") Кластеры обладают некоторыми свойствами, главные среди которых следующие: 1) плотность; 2) дисперсия; 3) размеры (радиус); 4) форма; 5) отделимость.
Кластеры обладают некоторыми свойствами, главные среди которых следующие: 1) плотность; 2) дисперсия; 3) размеры (радиус); 4) форма; 5) отделимость.
 внутрикластерные расстояния, как правило, меньше межкластерных ленточные кластеры с центром
внутрикластерные расстояния, как правило, меньше межкластерных ленточные кластеры с центром
 кластеры могут соединяться перемычками кластеры могут накладываться на разреженный фон из редко расположенных объектов кластеры могут перекрываться
кластеры могут соединяться перемычками кластеры могут накладываться на разреженный фон из редко расположенных объектов кластеры могут перекрываться
 кластеры могут образовываться не по сходству, а по иным типам регулярностей кластеры могут вообще отсутствовать • Каждый метод кластеризации имеет свои ограничения и выделяет кластеры лишь некоторых типов. • Понятие «тип кластерной структуры» зависит от метода и также не имеет формального определения
кластеры могут образовываться не по сходству, а по иным типам регулярностей кластеры могут вообще отсутствовать • Каждый метод кластеризации имеет свои ограничения и выделяет кластеры лишь некоторых типов. • Понятие «тип кластерной структуры» зависит от метода и также не имеет формального определения
 Несмотря на различия в целях, типах данных и примененных методах, все исследования, использующие кластерный анализ, характеризуют следующие пять основных шагов: 1) отбор выборки для кластеризации; 2) определение множества признаков, по которым будут оцениваться объекты в выборке; 3) вычисление значений той или иной меры сходства между объектами; 4) применение метода кластерного анализа для создания групп сходных объектов; 5) проверка достоверности результатов кластерного решения.
Несмотря на различия в целях, типах данных и примененных методах, все исследования, использующие кластерный анализ, характеризуют следующие пять основных шагов: 1) отбор выборки для кластеризации; 2) определение множества признаков, по которым будут оцениваться объекты в выборке; 3) вычисление значений той или иной меры сходства между объектами; 4) применение метода кластерного анализа для создания групп сходных объектов; 5) проверка достоверности результатов кластерного решения.
 Многие методы кластерного анализа — довольно простые процедуры, которые,") ПРЕДОСТЕРЕЖЕНИЙ ОТНОСИТЕЛЬНО КЛАСТЕРНОГО АНАЛИЗА 1) Многие методы кластерного анализа — довольно простые процедуры, которые, как правило, не имеют достаточного статистического обоснования 2) Методы кластерного анализа разрабатывались для многих научных дисциплин, а потому несут на себе отпечатки специфики этих дисциплин. 3) Разные кластерные методы могут порождать и порождают различные решения для одних и тех же данных.
ПРЕДОСТЕРЕЖЕНИЙ ОТНОСИТЕЛЬНО КЛАСТЕРНОГО АНАЛИЗА 1) Многие методы кластерного анализа — довольно простые процедуры, которые, как правило, не имеют достаточного статистического обоснования 2) Методы кластерного анализа разрабатывались для многих научных дисциплин, а потому несут на себе отпечатки специфики этих дисциплин. 3) Разные кластерные методы могут порождать и порождают различные решения для одних и тех же данных.
 Задача кластерного анализа заключается в том, чтобы на основании данных, содержащихся во множестве Х, разбить множество объектов G на m (m – целое) кластеров (подмножеств) Q 1, Q 2, …, Qm, так, чтобы каждый объект Gj принадлежал одному и только одному подмножеству разбиения и чтобы объекты, принадлежащие одному и тому же кластеру, были сходными, в то время, как объекты, принадлежащие разным кластерам были разнородными.
Задача кластерного анализа заключается в том, чтобы на основании данных, содержащихся во множестве Х, разбить множество объектов G на m (m – целое) кластеров (подмножеств) Q 1, Q 2, …, Qm, так, чтобы каждый объект Gj принадлежал одному и только одному подмножеству разбиения и чтобы объекты, принадлежащие одному и тому же кластеру, были сходными, в то время, как объекты, принадлежащие разным кластерам были разнородными.
 разработка типологии или") Различные приложения кластерного анализа можно свести к четырем основным задачам: 1) разработка типологии или классификации; 2) исследование полезных концептуальных схем группирования объектов; 3) порождение гипотез на основе исследования данных; 4) проверка гипотез или исследования для определения, действительно ли типы (группы), выделенные тем или иным способом, присутствуют в имеющихся данных.
Различные приложения кластерного анализа можно свести к четырем основным задачам: 1) разработка типологии или классификации; 2) исследование полезных концептуальных схем группирования объектов; 3) порождение гипотез на основе исследования данных; 4) проверка гипотез или исследования для определения, действительно ли типы (группы), выделенные тем или иным способом, присутствуют в имеющихся данных.
 Формулировка задачи кластерного анализа Пусть множество I={I 1, I 2, …, In} обозначает n объектов. Результат измерения i-й характеристики Ij объекта обозначают символом xij, а вектор Xj=[xij] отвечает каждому ряду измерений (для j-го объекта). Таким образом, для множества I объектов исследователь располагает множеством векторов измерений X={X 1, X 2, …, Xn}, которые описывают множество I. Множество X может быть представлено как n точек в p-мерном евклидовом пространстве Ер. Пусть m – целое число, меньшее чем n. Задача кластерного анализа заключается в том, чтобы на основании данных, содержащихся во множестве, разбить множество объектов I на m кластеров (подмножеств) π1, π2, …, πm так, чтобы каждый объект Ij принадлежал одному и только одному подмножеству разбиения и чтобы объекты, принадлежащие разным кластерам, были разнородными (несходными).
Формулировка задачи кластерного анализа Пусть множество I={I 1, I 2, …, In} обозначает n объектов. Результат измерения i-й характеристики Ij объекта обозначают символом xij, а вектор Xj=[xij] отвечает каждому ряду измерений (для j-го объекта). Таким образом, для множества I объектов исследователь располагает множеством векторов измерений X={X 1, X 2, …, Xn}, которые описывают множество I. Множество X может быть представлено как n точек в p-мерном евклидовом пространстве Ер. Пусть m – целое число, меньшее чем n. Задача кластерного анализа заключается в том, чтобы на основании данных, содержащихся во множестве, разбить множество объектов I на m кластеров (подмножеств) π1, π2, …, πm так, чтобы каждый объект Ij принадлежал одному и только одному подмножеству разбиения и чтобы объекты, принадлежащие разным кластерам, были разнородными (несходными).
 Алгоритмы кластеризации Имеется обучающая выборка Xℓ = {x 1, . . . , xℓ} ⊂ X и функция расстояния между объектами ρ(x, x′). Требуется разбить выборку на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике ρ, а объекты разных кластеров существенно отличались. При этом каждому объекту xi ∈ Xℓ приписывается метка (номер) кластера yi. Алгоритм кластеризации - это функция a: X → Y , которая любому объекту x ∈ X ставит в соответствие метку кластера y ∈ Y . Множество меток Y в некоторых случаях известно заранее, однако чаще ставится задача определить оптимальное число кластеров, с точки зрения того или иного критерия качества кластеризации.
Алгоритмы кластеризации Имеется обучающая выборка Xℓ = {x 1, . . . , xℓ} ⊂ X и функция расстояния между объектами ρ(x, x′). Требуется разбить выборку на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике ρ, а объекты разных кластеров существенно отличались. При этом каждому объекту xi ∈ Xℓ приписывается метка (номер) кластера yi. Алгоритм кластеризации - это функция a: X → Y , которая любому объекту x ∈ X ставит в соответствие метку кластера y ∈ Y . Множество меток Y в некоторых случаях известно заранее, однако чаще ставится задача определить оптимальное число кластеров, с точки зрения того или иного критерия качества кластеризации.
 N измерений X 1, X 2, …, X 3 могут быть представлены в виде матрицы
N измерений X 1, X 2, …, X 3 могут быть представлены в виде матрицы
 Основные понятия кластерного анализа Матрица расстояний dii=0 для i=1, 2, …, n.
Основные понятия кластерного анализа Матрица расстояний dii=0 для i=1, 2, …, n.
 Основные понятия кластерного анализа Мерой близости между объектами Xi и Xj является вещественная функция μ(Xi, Xj)=μij со свойствам : Пары значений мер близости можно объединить в матрицу близости:
Основные понятия кластерного анализа Мерой близости между объектами Xi и Xj является вещественная функция μ(Xi, Xj)=μij со свойствам : Пары значений мер близости можно объединить в матрицу близости:
, i, j=1, 2, . . . , n, элемент rij который определяет степень") R=(rij), i, j=1, 2, . . . , n, элемент rij который определяет степень близости i-го объекта к j-му.
R=(rij), i, j=1, 2, . . . , n, элемент rij который определяет степень близости i-го объекта к j-му.
 или нормирование normalization) ( приводит значения всех преобразованных переменных к единому диапазону") Стандартизация (standardization) или нормирование normalization) ( приводит значения всех преобразованных переменных к единому диапазону значений путем выражения через отношение этих значений к некой величине, отражающей определенные свойства конкретного признака.
Стандартизация (standardization) или нормирование normalization) ( приводит значения всех преобразованных переменных к единому диапазону значений путем выражения через отношение этих значений к некой величине, отражающей определенные свойства конкретного признака.
 коэффициенты корреляции; 2) меры расстояния; 3) коэффициенты ассоциативности; 4) вероятностные коэффициенты") Меры сходства 1) коэффициенты корреляции; 2) меры расстояния; 3) коэффициенты ассоциативности; 4) вероятностные коэффициенты сходства Количественное оценивание сходства отталкивается от понятия метрики. При этом подходе к сходству события представляются точками координатного пространства, причем замеченные сходства и различия между точками находятся в соответствии с метрическими расстояниями между ними
Меры сходства 1) коэффициенты корреляции; 2) меры расстояния; 3) коэффициенты ассоциативности; 4) вероятностные коэффициенты сходства Количественное оценивание сходства отталкивается от понятия метрики. При этом подходе к сходству события представляются точками координатного пространства, причем замеченные сходства и различия между точками находятся в соответствии с метрическими расстояниями между ними
 Симметрия. Даны два объекта х и у; расстояние между") Критерии для мер сходства 1) Симметрия. Даны два объекта х и у; расстояние между ними удовлетворяет условию d(x, y)=d(y, x)≥ 0. 2) Неравенство треугольника. Даны три объекта х, у, г; расстояния между ними удовлетворяют условию d(x, y)≤d(x, z)+d(y, z). Очевидно, это просто утверждение, что длина любой стороны треугольника меньше или равна сумме двух других сторон. Полученное выражение также называется метрическим неравенством. 3) Различимость нетождественных объектов. Даны два объекта х и у: если d(x, y)≠ 0, то x≠y. 4) Неразличимость идентичных объектов. Для двух идентичных объектов x и x' d(x, x')=0 т. е. расстояние между этими объектами равно нулю.
Критерии для мер сходства 1) Симметрия. Даны два объекта х и у; расстояние между ними удовлетворяет условию d(x, y)=d(y, x)≥ 0. 2) Неравенство треугольника. Даны три объекта х, у, г; расстояния между ними удовлетворяют условию d(x, y)≤d(x, z)+d(y, z). Очевидно, это просто утверждение, что длина любой стороны треугольника меньше или равна сумме двух других сторон. Полученное выражение также называется метрическим неравенством. 3) Различимость нетождественных объектов. Даны два объекта х и у: если d(x, y)≠ 0, то x≠y. 4) Неразличимость идентичных объектов. Для двух идентичных объектов x и x' d(x, x')=0 т. е. расстояние между этими объектами равно нулю.
 Коэффициенты корреляции
Коэффициенты корреляции
 Пример использования коэффициента корреляции
Пример использования коэффициента корреляции
 Пример использования меры евклидового расстояния
Пример использования меры евклидового расстояния
 Влияние нормировки данных на изменение расчетных мер сходства
Влияние нормировки данных на изменение расчетных мер сходства
 меры расстояния Линейное расстояние Евклидово расстояние
меры расстояния Линейное расстояние Евклидово расстояние
 среднее квадратическое отклонение l-го признака.
среднее квадратическое отклонение l-го признака.
 меры расстояния Квадрат евклидового расстояния Cтепенное расстояние Минковского Степенное расстояние Расстояние Чебышева
меры расстояния Квадрат евклидового расстояния Cтепенное расстояние Минковского Степенное расстояние Расстояние Чебышева
 меры расстояния Манхэттенское расстояние Расстояние Махаланобиса где S ковариационная матрица выборки Х=(Х 1, Х 2, …. . X n) Расстояние Хемминга
меры расстояния Манхэттенское расстояние Расстояние Махаланобиса где S ковариационная матрица выборки Х=(Х 1, Х 2, …. . X n) Расстояние Хемминга
 Номер объекта X 1 X 2 X 3 1 2 3 4 5 220, 0 185, 0 245, 0 178, 0 170, 0 94, 0 75, 0 80, 0 75, 2 73, 1 264, 0 192, 0 220, 0 96, 0 105, 0 199, 6 79, 5 175, 4 28, 4 7, 6 65, 4 Среднее квадратическое отклонение ( σ)
Номер объекта X 1 X 2 X 3 1 2 3 4 5 220, 0 185, 0 245, 0 178, 0 170, 0 94, 0 75, 0 80, 0 75, 2 73, 1 264, 0 192, 0 220, 0 96, 0 105, 0 199, 6 79, 5 175, 4 28, 4 7, 6 65, 4 Среднее квадратическое отклонение ( σ)
 Перед тем как вычислять матрицу расстояний, нормируем исходные данные по формуле.
Перед тем как вычислять матрицу расстояний, нормируем исходные данные по формуле.

 3, 861 2, 324 2, 149 Объект 1 2 3 4 5 Дендрограмма кластеризации пяти объектов
3, 861 2, 324 2, 149 Объект 1 2 3 4 5 Дендрограмма кластеризации пяти объектов
 Коэффициенты ассоциативности • простой коэффициент совстречаемости; • коэффициент Жаккара; • коэффициент Гауэра 1 0 1 a b 0 c d
Коэффициенты ассоциативности • простой коэффициент совстречаемости; • коэффициент Жаккара; • коэффициент Гауэра 1 0 1 a b 0 c d

 Объект 1 1 0 Объект 2 1 1 2 0 1 4 Два объекта имеют только один общий признак, и различаются по 4 признакам. Таким образом, S = 0, 625 (=5/8). Тем не менее J = 0, 250 ( = 1/4).
Объект 1 1 0 Объект 2 1 1 2 0 1 4 Два объекта имеют только один общий признак, и различаются по 4 признакам. Таким образом, S = 0, 625 (=5/8). Тем не менее J = 0, 250 ( = 1/4).
 Коэффициент Гауэра — единственный в своем роде, так как при оценке сходства допускает одновременное использование переменных, измеренных по различным шкалам. Коэффициент был предложен Гауэром (1971) и имеет вид где Wijk — весовая переменная, принимающая значение 1, если сравнение объектов по признаку k следует учитывать, и 0 — в противном случае; Sijk— «вклад» в сходство объектов, зависящий от того, учитывается ли признак k при сравнении объектов i и j. В случае бинарных признаков Wijk = 0, если признак k отсутствует у одного или обоих сопоставляемых объектов
Коэффициент Гауэра — единственный в своем роде, так как при оценке сходства допускает одновременное использование переменных, измеренных по различным шкалам. Коэффициент был предложен Гауэром (1971) и имеет вид где Wijk — весовая переменная, принимающая значение 1, если сравнение объектов по признаку k следует учитывать, и 0 — в противном случае; Sijk— «вклад» в сходство объектов, зависящий от того, учитывается ли признак k при сравнении объектов i и j. В случае бинарных признаков Wijk = 0, если признак k отсутствует у одного или обоих сопоставляемых объектов
 Методы объединения или связи 1. Метод ближнего соседа или одиночная связь 2. Метод наиболее удаленных соседей 3. 4. 5. Метод Варда Метод невзвешенного попарного среднего Метод взвешенного попарного среднего 6. Невзвешенный центроидный метод 7. Взвешенный центроидный метод
Методы объединения или связи 1. Метод ближнего соседа или одиночная связь 2. Метод наиболее удаленных соседей 3. 4. 5. Метод Варда Метод невзвешенного попарного среднего Метод взвешенного попарного среднего 6. Невзвешенный центроидный метод 7. Взвешенный центроидный метод

).") Одиночная связь (метод ближайшего соседа (single linkage или nearest neighbor)).
Одиночная связь (метод ближайшего соседа (single linkage или nearest neighbor)).
 меры расстояния, дендрограмма Диаграмма вложения Дендрограмма на основании евклидового расстояние и метода одиночной связи
меры расстояния, дендрограмма Диаграмма вложения Дендрограмма на основании евклидового расстояние и метода одиночной связи
)") Полная связь (метод наиболее удаленных соседей (complete linkage))
Полная связь (метод наиболее удаленных соседей (complete linkage))
 меры расстояния, дендрограмма Диаграмма вложения Дендрограмма на основании евклидового расстояние и метода полной связи
меры расстояния, дендрограмма Диаграмма вложения Дендрограмма на основании евклидового расстояние и метода полной связи
 Метод невзвешенного попарного среднего (метод невзвешенного попарного арифметического среднего - unweighted pair-group method using arithmetic averages, UPGMA.
Метод невзвешенного попарного среднего (метод невзвешенного попарного арифметического среднего - unweighted pair-group method using arithmetic averages, UPGMA.
 меры расстояния, дендрограмма Диаграмма вложения Дендрограмма на основании евклидового расстояние и метода невзвешенного попарного среднего (UPGMA)
меры расстояния, дендрограмма Диаграмма вложения Дендрограмма на основании евклидового расстояние и метода невзвешенного попарного среднего (UPGMA)
") меры расстояния, дендрограмма Дендрограмма на основании евклидового расстояние и метода взвешенного попарного среднего (WPGMA)
меры расстояния, дендрограмма Дендрограмма на основании евклидового расстояние и метода взвешенного попарного среднего (WPGMA)
 Невзвешенный центроидный метод (метод невзвешенного попарного центроидного усреднения - unweighted pair-group method using the centroid average UPGMC)
Невзвешенный центроидный метод (метод невзвешенного попарного центроидного усреднения - unweighted pair-group method using the centroid average UPGMC)
") меры расстояния, дендрограмма Дендрограмма на основании евклидового расстояние и невзвешенного центроидного метода (UPGMC)
меры расстояния, дендрограмма Дендрограмма на основании евклидового расстояние и невзвешенного центроидного метода (UPGMC)
") меры расстояния, дендрограмма Дендрограмма на основании евклидового расстояние и взвешенного центроидного метода (WPGMC)
меры расстояния, дендрограмма Дендрограмма на основании евклидового расстояние и взвешенного центроидного метода (WPGMC)

 меры расстояния, дендрограмма Диаграмма вложения Дендрограмма на основании евклидового расстояние и метод Варда
меры расстояния, дендрограмма Диаграмма вложения Дендрограмма на основании евклидового расстояние и метод Варда
 Методы кластеризации Иерархические Агломеративные Дивизимные Неиерархические Четкая кластеризация Классификация кластерных методов Нечеткая кластеризация
Методы кластеризации Иерархические Агломеративные Дивизимные Неиерархические Четкая кластеризация Классификация кластерных методов Нечеткая кластеризация
 Методы кластеризации v методы, основывающиеся на иерархической апроцедуре v (итерационные процедуры, которые пытаются найти наилучшее разбиение, ориентируясь на заданный критерий оптимизации, не строя при этом полного дерева: наиболее популярный — алгоритм метод k–средних Мак–Кина
Методы кластеризации v методы, основывающиеся на иерархической апроцедуре v (итерационные процедуры, которые пытаются найти наилучшее разбиение, ориентируясь на заданный критерий оптимизации, не строя при этом полного дерева: наиболее популярный — алгоритм метод k–средних Мак–Кина
 Методы кластеризации Иерархические алгоритмы кластерного анализа могут быть двух типов – агломеративные и дивизионные
Методы кластеризации Иерархические алгоритмы кластерного анализа могут быть двух типов – агломеративные и дивизионные
 Общая схема работы иерархических агломеративных методов
Общая схема работы иерархических агломеративных методов
 Общая схема работы иерархических дивизимных методов
Общая схема работы иерархических дивизимных методов
 Методы кластеризации Иерархические алгоритмы связаны с построением дендрограмм (от греческого dendron - "дерево"), которые являются результатом иерархического кластерного анализа. v. Дендрограмма описывает близость отдельных точек и кластеров друг к другу, представляет в графическом виде последовательность объединения (разделения) кластеров. v. Дендрограмма (dendrogram) - древовидная диаграмма, содержащая n уровней, каждый из которых соответствует одному из шагов процесса последовательного укрупнения кластеров. v. Дендрограммой также называют древовидной схемой, деревом объединения кластеров, деревом иерархической структуры. v. Дендрограмма представляет собой вложенную группировку объектов, которая изменяется на различных уровнях иерархии.
Методы кластеризации Иерархические алгоритмы связаны с построением дендрограмм (от греческого dendron - "дерево"), которые являются результатом иерархического кластерного анализа. v. Дендрограмма описывает близость отдельных точек и кластеров друг к другу, представляет в графическом виде последовательность объединения (разделения) кластеров. v. Дендрограмма (dendrogram) - древовидная диаграмма, содержащая n уровней, каждый из которых соответствует одному из шагов процесса последовательного укрупнения кластеров. v. Дендрограммой также называют древовидной схемой, деревом объединения кластеров, деревом иерархической структуры. v. Дендрограмма представляет собой вложенную группировку объектов, которая изменяется на различных уровнях иерархии.
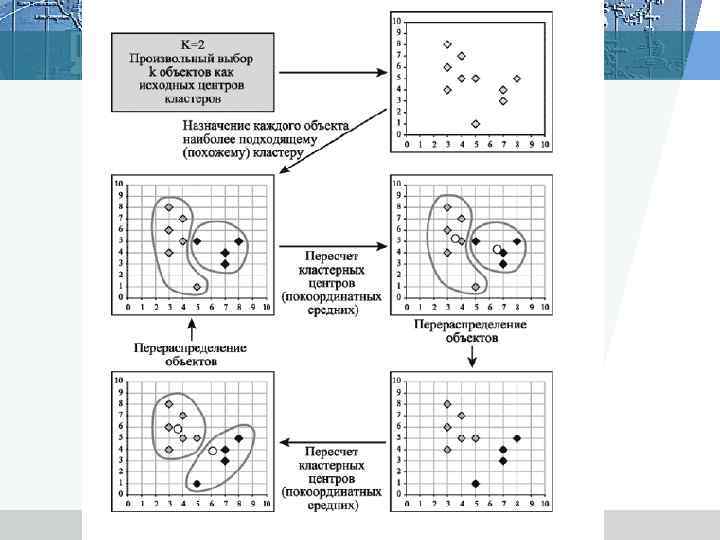
 Итеративные методы Алгоритм: 1. начать с исходного разбиения данных на некоторое заданное число кластеров; вычислить центры тяжести этих кластеров; 2. поместить каждую точку данных в кластер с ближайшим центром тяжести; 3. вычислить новые центры тяжести кластеров; кластеры не заменяются на новые до тех пор, пока не будут просмотрены полностью все данные; 4. шаги 2 и 3 повторяются до тех пор, пока не перестанут меняться кластеры.
Итеративные методы Алгоритм: 1. начать с исходного разбиения данных на некоторое заданное число кластеров; вычислить центры тяжести этих кластеров; 2. поместить каждую точку данных в кластер с ближайшим центром тяжести; 3. вычислить новые центры тяжести кластеров; кластеры не заменяются на новые до тех пор, пока не будут просмотрены полностью все данные; 4. шаги 2 и 3 повторяются до тех пор, пока не перестанут меняться кластеры.
 Алгоритм метод k–средних Мак–Кина 1. Случайно выбрать k точек, являющихся начальными координатами «центрами масс» кластеров (любые k из n объектов, или вообще k случайных точек). 2. Определяем центр каждого кластера µj, j∈{1, . . . , m}как элемент, компоненты которого вычисляются как среднее арифметическое входящих в этот кластер элементов. В центре кластера достигается минимум функции суммы квадратов расстояний от элементов кластера до точки. 3. Отнести каждый объект к кластеру с ближайшим «центром масс» . 4. Пересчитать «центры масс» кластеров согласно текущему членству. 5. Если критерий остановки не удовлетворен, вернуться к шагу 2.
Алгоритм метод k–средних Мак–Кина 1. Случайно выбрать k точек, являющихся начальными координатами «центрами масс» кластеров (любые k из n объектов, или вообще k случайных точек). 2. Определяем центр каждого кластера µj, j∈{1, . . . , m}как элемент, компоненты которого вычисляются как среднее арифметическое входящих в этот кластер элементов. В центре кластера достигается минимум функции суммы квадратов расстояний от элементов кластера до точки. 3. Отнести каждый объект к кластеру с ближайшим «центром масс» . 4. Пересчитать «центры масс» кластеров согласно текущему членству. 5. Если критерий остановки не удовлетворен, вернуться к шагу 2.
 Исходное множество Четыре кластера Два кластера Шесть кластеров
Исходное множество Четыре кластера Два кластера Шесть кластеров
 Общая схема работы итеративных методов
Общая схема работы итеративных методов
 равен: S = (а + d) /") Нумерическая таксономия Фенотипический коэффициент простого соответствия (подобия) равен: S = (а + d) / (а + b +c+d) Дендрограмма, построенная на основе коэффициентов подобия между шестью видами бактерий
Нумерическая таксономия Фенотипический коэффициент простого соответствия (подобия) равен: S = (а + d) / (а + b +c+d) Дендрограмма, построенная на основе коэффициентов подобия между шестью видами бактерий
 Set of subtrees Select a pair of closets subtrees Merge selected subtrees into one No Number of subtrees=1 Yes Tree Dij=max(Dkm)
Set of subtrees Select a pair of closets subtrees Merge selected subtrees into one No Number of subtrees=1 Yes Tree Dij=max(Dkm)
 Information content I=4. 432 ATGTATG ACGTTTG ACGTGTG I=4. 018 I=3, 158 ATGTATG ACGTTTG ACGTGTG I=3, 158 ATGTATG ACGTTTG
Information content I=4. 432 ATGTATG ACGTTTG ACGTGTG I=4. 018 I=3, 158 ATGTATG ACGTTTG ACGTGTG I=3, 158 ATGTATG ACGTTTG
") Нумерическая таксономия Результаты секвенирования четырех изолятов бактерий и соответствующие эволюционное дерево (дендрограмма)
Нумерическая таксономия Результаты секвенирования четырех изолятов бактерий и соответствующие эволюционное дерево (дендрограмма)
 Литературные источники использованные при подготовке: 1. Айвазян С. А. , Бухштабер В. М. , Енюков И. С. , Мешалкин Л. Д. Прикладная статистика: классификация и снижение размерности. — М. : Финансы и статистика, 1989. 2. Дорофеюк А. А. Алгоритмы автоматической классификации // Проблемы расширения возможностей автоматов (Труды Ин-та пробл. управ. АН СССР). Вып 1. – М. : ИПУ АН СССР, 1971. С. 5 -41. 3. Дюран Б. , Оделл П. Кластерный анализ. – М. : Статистика, 1977. – 128 с 4. Жамбю М. Иерархический кластер-анализ и соответствия. – М. : Финансы и статистика, 1988. – 342 с. 5. Ким Дж. О. , Мьюллер Ч. У, Клекка У. Р. и др. Факторный, дискриминантный и кластерный анализ. – М. : Финансы и статистика, 1989. – 215 с. 6. Классификация и кластер / Под ред. Дж. Вэн-Райзина. – М. : Мир, 1980. – 390 с. 7. Кольцов П. П. Математические модели теории распознавания образов // Компьютер и задачи выбора. – М. : Наука, 1989. С. 89 -119. 8. Кузнецов Д. Ю, Трошкина Т. Л. Кластерный анализ и его применение http: //elibrary. ru/item. asp? id=10365372 9. Мандель И. Д. Кластерный анализ. – М. : Финансы и статистика, 1988. – 176 с. 10. Методы кластерного анализа. Иерархические методы http: //www. intuit. ru/department/database/datamining/13/4. html
Литературные источники использованные при подготовке: 1. Айвазян С. А. , Бухштабер В. М. , Енюков И. С. , Мешалкин Л. Д. Прикладная статистика: классификация и снижение размерности. — М. : Финансы и статистика, 1989. 2. Дорофеюк А. А. Алгоритмы автоматической классификации // Проблемы расширения возможностей автоматов (Труды Ин-та пробл. управ. АН СССР). Вып 1. – М. : ИПУ АН СССР, 1971. С. 5 -41. 3. Дюран Б. , Оделл П. Кластерный анализ. – М. : Статистика, 1977. – 128 с 4. Жамбю М. Иерархический кластер-анализ и соответствия. – М. : Финансы и статистика, 1988. – 342 с. 5. Ким Дж. О. , Мьюллер Ч. У, Клекка У. Р. и др. Факторный, дискриминантный и кластерный анализ. – М. : Финансы и статистика, 1989. – 215 с. 6. Классификация и кластер / Под ред. Дж. Вэн-Райзина. – М. : Мир, 1980. – 390 с. 7. Кольцов П. П. Математические модели теории распознавания образов // Компьютер и задачи выбора. – М. : Наука, 1989. С. 89 -119. 8. Кузнецов Д. Ю, Трошкина Т. Л. Кластерный анализ и его применение http: //elibrary. ru/item. asp? id=10365372 9. Мандель И. Д. Кластерный анализ. – М. : Финансы и статистика, 1988. – 176 с. 10. Методы кластерного анализа. Иерархические методы http: //www. intuit. ru/department/database/datamining/13/4. html
 11. Миркин Б. Г. , Черный Л. Б. Об измерении близости между различными разбиениями конечного множества объектов // Автоматика и телемеханика. 1970. № 5. С. 6 -18. 12. Мхитарян В. С. , Архипова М. Ю. , Сиротин В. П. ЭКОНОМЕТРИКА: Учебнометодический комплекс. – М. : Изд. центр ЕАОИ. 2008. – 144 с. 13. Николаенко С. Курс лекций «Алгоритмы кластеризации I I» http : //logic. pdmi. ras. ru/∼sergey/index. php? page=teaching 14. Розенберг Г. С. О сравнении различных методов автоматической классификации // Автоматика и телемеханика. 1975. № 9. С. 145 -148. 15. Чубукова И. А. Лекция «Data Mining» . 16. Факторный, дискриминантный и кластерный анализ: Пер с англ. /Дж. -О. Ким, Ч. У. Мьюллер, У. Р. Клекка и др. ; Под ред. И. С. Енюкова. — М. : Финансы и статистика, 1989. — 215 с. 17. Фрей Т. Э. -А. О математико-фитоценотических методах классификации растительности: Автореф. дис. … докт. биол. наук. – Тарту: Тарт. ГУ, 1967. – 32 с. 18. Воронов К. В. «Машинное обучение (курс лекций, К. В. Воронцов)» http: //www. Machine. Learning. ru/wiki 19. Dallwitz, M. J. 1988. A flexible clustering method based on UPGMA and ISS http: //deltaintkey. com 20. Geoff Bohling. Dimension reduction and cluster analysis. - 2006. – 22 p.
11. Миркин Б. Г. , Черный Л. Б. Об измерении близости между различными разбиениями конечного множества объектов // Автоматика и телемеханика. 1970. № 5. С. 6 -18. 12. Мхитарян В. С. , Архипова М. Ю. , Сиротин В. П. ЭКОНОМЕТРИКА: Учебнометодический комплекс. – М. : Изд. центр ЕАОИ. 2008. – 144 с. 13. Николаенко С. Курс лекций «Алгоритмы кластеризации I I» http : //logic. pdmi. ras. ru/∼sergey/index. php? page=teaching 14. Розенберг Г. С. О сравнении различных методов автоматической классификации // Автоматика и телемеханика. 1975. № 9. С. 145 -148. 15. Чубукова И. А. Лекция «Data Mining» . 16. Факторный, дискриминантный и кластерный анализ: Пер с англ. /Дж. -О. Ким, Ч. У. Мьюллер, У. Р. Клекка и др. ; Под ред. И. С. Енюкова. — М. : Финансы и статистика, 1989. — 215 с. 17. Фрей Т. Э. -А. О математико-фитоценотических методах классификации растительности: Автореф. дис. … докт. биол. наук. – Тарту: Тарт. ГУ, 1967. – 32 с. 18. Воронов К. В. «Машинное обучение (курс лекций, К. В. Воронцов)» http: //www. Machine. Learning. ru/wiki 19. Dallwitz, M. J. 1988. A flexible clustering method based on UPGMA and ISS http: //deltaintkey. com 20. Geoff Bohling. Dimension reduction and cluster analysis. - 2006. – 22 p.
 21. Chamundeswari 1 G. , Pardasaradhi G. , Satyanarayana Ch. An Experimental Analysis of K -means Using Matlab //International Journal of Engineering Research & Technology (IJERT). - Vol. 1 Issue 5, July – 2012. PP. 1 – 5. 22. Jain, Murty, Flynn Data clustering: a review. // ACM Comput. Surv. 31(3) , 1999 23. Joe H. Ward (1963). Hierarchical Grouping to optimize an objective function. Journal of American Statistical Association, 58(301), 236 -244. 24. Sokal R. , Sneath P. Principles of Numerical Taxonomy. - San Francisco: W. H. Freeman, 1963. - 573 р 25. Ward J. H. Hierarchical grouping to optimize an objective function // J. Amer. Statist. Assoc. 1963. V. 58. № 301. Р. 236 -244.
21. Chamundeswari 1 G. , Pardasaradhi G. , Satyanarayana Ch. An Experimental Analysis of K -means Using Matlab //International Journal of Engineering Research & Technology (IJERT). - Vol. 1 Issue 5, July – 2012. PP. 1 – 5. 22. Jain, Murty, Flynn Data clustering: a review. // ACM Comput. Surv. 31(3) , 1999 23. Joe H. Ward (1963). Hierarchical Grouping to optimize an objective function. Journal of American Statistical Association, 58(301), 236 -244. 24. Sokal R. , Sneath P. Principles of Numerical Taxonomy. - San Francisco: W. H. Freeman, 1963. - 573 р 25. Ward J. H. Hierarchical grouping to optimize an objective function // J. Amer. Statist. Assoc. 1963. V. 58. № 301. Р. 236 -244.
 LOGO
LOGO
 Теория нейтральности Кимуры Основное предположение этой теории состоит в следующем: на молекулярном уровне мутации (замены аминокислот или нуклеотидов) преимущественно нейтральны или слабо вредны (существенно вредные мутации также возможны, но они элиминируются из популяции селекцией).
Теория нейтральности Кимуры Основное предположение этой теории состоит в следующем: на молекулярном уровне мутации (замены аминокислот или нуклеотидов) преимущественно нейтральны или слабо вредны (существенно вредные мутации также возможны, но они элиминируются из популяции селекцией).
 Теория нейтральности Кимуры
Теория нейтральности Кимуры