

03a9a5e39b1e3bbc95285dc1c61915f3.ppt
- Количество слайдов: 24
 Linguistic tools Лекция 5
Linguistic tools Лекция 5
 ПОИСКОВЫЕ СИСТЕМЫ: предыстория • Библейские индексы и конкордансы • 1247 – Hugo de St. Caro – было задействовано 500 монахов для составления конкорданса ключевых слов к Библии • Журнальные индексы (Королевское научное общество, 1600 -е)
ПОИСКОВЫЕ СИСТЕМЫ: предыстория • Библейские индексы и конкордансы • 1247 – Hugo de St. Caro – было задействовано 500 монахов для составления конкорданса ключевых слов к Библии • Журнальные индексы (Королевское научное общество, 1600 -е)
") Orville James Nave (1841 -1917)
Orville James Nave (1841 -1917)


 Поиск неструктурированных данных (обычно текстовых документов), в которых находится") Информационный поиск INFORMATION RETRIEVAL (IR) Поиск неструктурированных данных (обычно текстовых документов), в которых находится нужная информация в больших коллекциях/корпусах (обычно хранятся в компьютерах)
Информационный поиск INFORMATION RETRIEVAL (IR) Поиск неструктурированных данных (обычно текстовых документов), в которых находится нужная информация в больших коллекциях/корпусах (обычно хранятся в компьютерах)
 • 1950 – библиотечное дело • 1952 г Кельвин Муерс: information retrieval • 1990 - WWW Google > 8 млрд страниц – Яндекс 6 млн страниц, 2, 5 млн сайтов
• 1950 – библиотечное дело • 1952 г Кельвин Муерс: information retrieval • 1990 - WWW Google > 8 млрд страниц – Яндекс 6 млн страниц, 2, 5 млн сайтов
 • Базы данных • Клиент") Архитектура поисковой системы • Робот ( краулер, спайдер, индексатор) • Базы данных • Клиент (обработка запроса)
Архитектура поисковой системы • Робот ( краулер, спайдер, индексатор) • Базы данных • Клиент (обработка запроса)
 ЗАПРОС • Логический запрос 1=true 0= false Булевская модель поиска
ЗАПРОС • Логический запрос 1=true 0= false Булевская модель поиска
 Manning & Raghavan 2005
Manning & Raghavan 2005
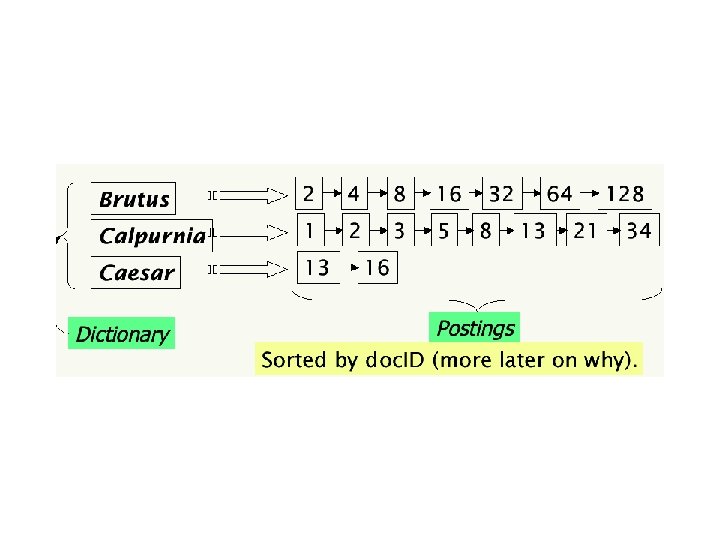
 ЗАПРОС: Brutus AND Caesar NOT Calpurnia Manning & Raghavan 2005
ЗАПРОС: Brutus AND Caesar NOT Calpurnia Manning & Raghavan 2005

 • Для больших коллекций матрица невозможна • Инвертированный индекс ( запоминаем только вхождения, но не их отсутствия) • Записи отсортированы по словам
• Для больших коллекций матрица невозможна • Инвертированный индекс ( запоминаем только вхождения, но не их отсутствия) • Записи отсортированы по словам
 Индексирование • Документы • Токенизация • Лемматизация • Индексатор
Индексирование • Документы • Токенизация • Лемматизация • Индексатор
") ИНДЕКСАТОР: шаг 1 • Пара (слово, ID документа)
ИНДЕКСАТОР: шаг 1 • Пара (слово, ID документа)
 Индексатор: шаг 2 • СОРТИРОВКА !
Индексатор: шаг 2 • СОРТИРОВКА !
 Индексатор: шаг 3 • Вхождения в один и тот же документ объединяются • Добавляются сведения о частоте
Индексатор: шаг 3 • Вхождения в один и тот же документ объединяются • Добавляются сведения о частоте
 ОБРАБОТКА ЗАПРОСА POINTER
ОБРАБОТКА ЗАПРОСА POINTER
 ОБРАБОТКА ЗАПРОСА 1. Двигаемся одновременно по двум рядам пойнтеров. 2. На каждом шаге сравниваем оба пойнтера. 3. Если они равны – то это искомое пересечение. 4. Если они не равны, то двигаем меньший.
ОБРАБОТКА ЗАПРОСА 1. Двигаемся одновременно по двум рядам пойнтеров. 2. На каждом шаге сравниваем оба пойнтера. 3. Если они равны – то это искомое пересечение. 4. Если они не равны, то двигаем меньший.
 • Частота двух терминов") Оптимизация обработки запросов • Начинай с наименее частотного (почему? ) • Частота двух терминов объединенных оператором OR может быть примерно оценена как сумма частот каждого
Оптимизация обработки запросов • Начинай с наименее частотного (почему? ) • Частота двух терминов объединенных оператором OR может быть примерно оценена как сумма частот каждого
 упражнение
упражнение
 R – Точность (precision) P документы") Оценка качества поиска • Релевантность – Полнота (recall) R – Точность (precision) P документы выданные невыданные релевантные a c нерелевантные b d Точность P = a/a+c Полнота R = a/ a+b F мера = (p+r)/ 2 pr
Оценка качества поиска • Релевантность – Полнота (recall) R – Точность (precision) P документы выданные невыданные релевантные a c нерелевантные b d Точность P = a/a+c Полнота R = a/ a+b F мера = (p+r)/ 2 pr