Стандартные способы обработки и анализа данных.ppt
- Количество слайдов: 53



Лекция 8 Стандартные способы обработки и анализа результатов психологического исследования

Содержание Учебные вопросы: 1. Программа обработки эмпирических данных. 2. Способы обработки и анализа эмпирических данных. 3. Виды анализов, используемые в прикладном психологическом исследовании. 4. Последовательность при обработке и анализе эмпирических данных.

Литература Основная: 1. Дружинин В. Н. Экспериментальная психология. ПИТЕР, 2010. 2. Волков Б. С. , Волкова Н. В. , Губанов А. В. Методология и методы психологического исследования. Учебное пособие для вузов. – 4 е изд. , испр. И доп. – М. , Академический проект; Фонд «Мир» , 2007. 3. Сидоренко Е. В. Методы математической обработки в психологии. СПб. , 2006. Дополнительная: 1. Ананьев Б. Г. О проблемах современного человекознания 2 е изд. СПб. , Питер, 2001. 2. Ганзен В. А. , Балин В. Д. Теория и методология психологического исследования. СПб. ГУ, 1991. 3. Кэмпбелл Д. Модели экспериментов в социальной психологии и прикладных исследованиях. – СПб. , 1996. 4. Ломов Б. Ф. Методологические проблемы психологического эксперимента. История и актуальные проблемы развития экспериментальной психологии в России. М. : Наука, 1990. 5. Суходольский Г. В. Основы математической статистики для психологов. С. Пб. , 1998.

Введение Заключительной частью программы психологического исследования является обработка и интерпретация его результатов. Исследователь, получив исходную информацию, стремится перевести ее в наиболее удобный для последующей обработки и анализа вид. Это как правило достигается за счет изменения первоначального качества информации: т. е. осуществляется переход от разрозненных данных (от отдельных испытуемых, элементах измеряемых свойств и т. п. ) к более крупным единицам, позволяющим приступить к логическому анализу и интерпретации данных в свете выдвинутой первоначально гипотезы. Причем в основе выбора общего направления преобразования информации лежит конкретная исследовательская задача, а в основе выбора той или иной формы наглядного отображения данных – возможность наиболее полно, адекватно представить предмет исследования, отразить его природу (структуру, взаимосвязи, динамику и пр. ).

1. Программа обработки эмпирических данных является составной частью программы психологического исследования. Ее ведущие задачи таковы: § § § определение вида и состава необходимой информации определение способов, средств ее регистрации, измерения, обработки и преобразования обеспечение надежности данных определение форм интерпретации обобщение данных установление способов практического применения результатов исследования Общая последовательность этапов обработки и представления данных показана на схеме 1.
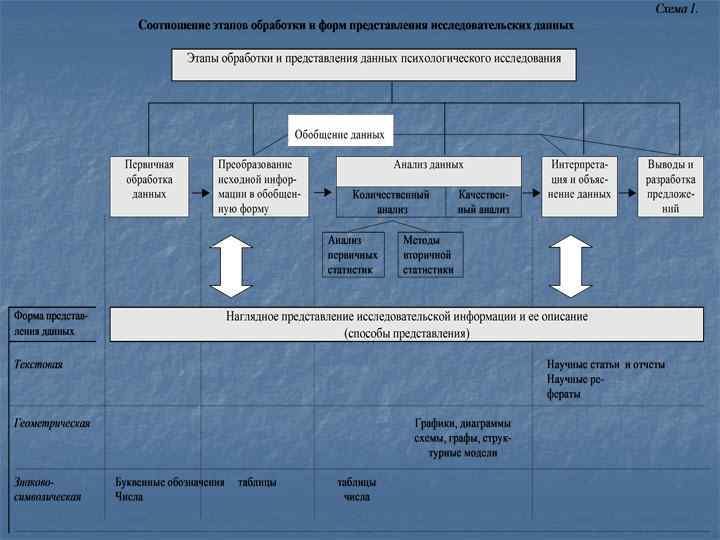

На этой схеме мы видим, что наглядное представление исследовательских данных является неотъемлемым атрибутом и важнейшим условием объективного анализа, объяснения и интерпретации получаемой психологом информации, причем каждый из этапов обобщения и интерпретации исследовательских данных может быть соотнесен с преимущественным использованием определенного способа наглядного их представления. Надо отметить, что реализуемые психологом процедуры (обработка, обобщение, анализ, объяснение и наглядное представление данных) тесно переплетены между собой. Каждая из них является в большинстве случаев либо условием, отправным пунктом, либо переходным звеном к решению следующей (согласно общей программе исследования) задачи.

Общая логика взаимосвязи вышеуказанных процедур следующая. Исследователь, получив исходную информацию, стремится перевести ее в наиболее удобный для последующей обработки и анализа вид. Это как правило достигается за счет изменения первоначального качества информации: т. е. осуществляется переход от разрозненных данных (от отдельных испытуемых, элементах измеряемых свойств и т. п. ) к более крупным единицам, позволяющим приступить к логическому анализу и интерпретации данных в свете выдвинутой первоначально гипотезы. Причем в основе выбора общего направления преобразования информации лежит конкретная исследовательская задача, а в основе выбора той или иной формы наглядного отображения данных – возможность наиболее полно, адекватно представить предмет исследования, отразить его природу (структуру, взаимосвязи, динамику и пр. ).
")
Таким образом, последовательность обработки и обобщения информации сопровождается изменением ее качественных параметров (подлежащих анализу) за счет повышения их информативной емкости, что достигается, в свою очередь, трансформацией форм репрезентации интересующего исследователя явления (свойства). Рассмотрим сущность употребляемых выше понятий. Данные – информация, относящаяся к предмету исследования, направленная на решение его задач. На различных этапах исследования данные проходят обработку, обобщение, анализ, объяснение и интерпретацию. Не следует смешивать «данные» с теми «значениями» , которые эти данные могут принимать. Для того чтобы всегда различать их, Шатийон рекомендует запомнить следующую фразу: «Данные часто принимают одни и те же значения» (так, если мы возьмем, например, шесть данных — 8, 13, 10, 8, 10 и 5, то они принимают лишь четыре разных значения — 5, 8, 10 и 13).

Существуют три типа данных: n n n 1. Количественные данные, получаемые при измерениях (например, данные о весе, размерах, температуре, времени, результатах тестирования и т. п. ). Их можно распределить по шкале с равными интервалами. 2. Порядковые данные, соответствующие местам этих элементов в последовательности, полученной при их расположении в возрастающем порядке (1 й, . . . , 7 й, . . . , 100 й, . . . ; А, Б, В. . ). 3. Качественные данные, представляющие собой какие то свойства элементов выборки или популяции. Их нельзя измерить, и единственной их количественной оценкой служит частота встречаемости (число лиц с голубыми или с зелеными глазами, курильщиков и не курильщиков, утомленных и отдохнувших, сильных и слабых и т. п. ).

Из всех этих типов данных только количественные данные можно анализировать с помощью методов, в основе которых лежат параметры (такие, например, как средняя арифметическая). Но даже к количественным данным такие методы можно применить лишь в том случае, если число этих данных достаточно, чтобы проявилось нормальное распределение. Итак, для использования параметрических методов в принципе необходимы три условия: o o o n данные должны быть количественными их число должно быть достаточным их распределение — нормальным. Во всех остальных случаях всегда рекомендуется использовать непараметрические методы. Обработка данных – преобразование эмпирических данных в вид, необходимый для решения исследовательских задач.

К числу ведущих задач, решаемых психологом в ходе планирования и осуществления обработки данных, относятся следующие: определение вида и состава необходимой для решения задач исследования информации; определение способов обработки и преобразования исследовательской информации; обеспечение и проверка надежности получаемых данных; обобщение и наглядное представление данных. Обработка данных основана на предварительной фиксации информации об изучаемом объекте в виде признаков и включает этапы: первичной обработки данных; преобразования исходной информации в обобщенную форму и наглядное ее представление.

В процессе обработки исследовательские данные претерпевают различные преобразования и обобщения. Это означает: n во первых, преобразование исходной индивидуальной информации, полученной от отдельных испытуемых, в совокупную или обобщенную. n Во вторых, полученная обобщенная информация затем подвергается количественному и качественному анализу. Таким образом, результатом обработки данных является их преобразование (за счет упорядочения и группирования) в форму, пригодную для описания данных с целью перехода в дальнейшем к их анализу и интерпретации.

При этом под описанием понимается: характеристика объекта исследования, его признаков, необходимая для выдвижения, обоснования и проверки гипотез исследования; форма представления информации о полученных в исследовании результатах. В ходе описания эмпирические данные приводятся к виду, доступному для различных теоретических процедур, позволяющих раскрыть сущность установленных взаимосвязей и явлений. Структура описания включает три компонента: эмпирические данные исследования; 2. систему обозначений, придающих описанию экономную, строгую форму и наглядность; 3. научные понятия, отображающие предметную область изучаемых явлений. 1.

n n Обобщение данных рассматривается как одна из задач обработки данных, реализуемая посредством повышения их размерности и информативной емкости с целью перехода от первичного (количественного) анализа к более глубокой теоретической интерпретации. Анализ данных – основной вид обработки эмпирических данных психологического исследования, направленный на выявление устойчивых, существенных свойств, тенденций развития изучаемого объекта. Анализ является неотъемлемым компонентом всех этапов психологического исследования, на его основе поддерживается логическая стройность, последовательность, обоснованность всех процедур исследования. Он строится на основе теоретических и методических принципов, логических и математико статистических методов, других научных положений, относящихся к изучаемым психологическим явлениям и процессам.

n Ход анализа в исследовании достаточно гибкий. Наряду с общей и установленной последовательностью этапов складывается определенная цикличность ряда процедур, возникает необходимость возврата к прежним этапам. Так, в ходе интерпретации полученных показателей и проверки гипотез для уточнения (объяснения) формируются новые подмассивы данных, меняются или строятся новые гипотезы и показатели. Объяснение (интерпретация) – раскрытие на основе анализа эмпирических данных и теоретических положений сущности объекта, возможностей его диагностики посредством поиска ведущих (результативных) факторов и причин, показа их подчиненности определенным объективным законам, тенденциям.

Существуют следующие виды объяснения: v функциональное v структурное v генетическое v причинное v системное. В объяснение входят: выдвижение, обоснование и n n проверка эмпирических и теоретических гипотез. Объяснение представлено положениями, объясняющими отображаемый объект и опирающимися на статистические методы установления взаимосвязи признаков. Эмпирическая проверка гипотез – установление связи одних признаков и факторов с другими, более устойчивыми, интегративными. Теоретическая проверка гипотез – объяснение изучаемых явлений с теоретических позиций (используя систему научных понятий, принципов, законов). В процессе объяснения (теоретической интерпретации) достигается обобщение результатов психологического исследования.

2. Способы обработки и анализа эмпирических данных Полученная в измерении статистическая совокупность несет в себе максимум сведений об исследуемом процессе, которые должны быть далее проанализированы с целью получения характеристики объекта исследования. Но перед этим весь исходный эмпирический материал, имеющийся в виде выборки, должен быть обработан. n Обработка материала исследования, как уже было показано, включает: этап первичной обработки данных (данных индивидуальных анкет, тестов и пр. ) n n этап преобразования исходной информации в обобщенную форму, наглядное ее представление.

n Рассмотрим наиболее общий алгоритм процедуры обработки данных. Вначале исследовательский материал должен быть упорядочен, т. е. сведен к некоторой удобной для обозрения и дальнейшего осмысливания форме. Упорядочение – это некоторый исходный этап первоначальной обработки, состоящий в расположении вариант выборки в какой либо последовательности, удобной для дальнейшего анализа и рассмотрения. Рассмотрим это на примере. В эксперименте по заучиванию ряда десяти двузначных чисел результаты заучивания после первого предъявления составили для 35 и испытуемых следующие величины: 5, 3, 5, 5, 4, 3, 3, 4, 1, 4, 5. 4, 4, 3. 4, 5, 3, 3, 4, 5, 4, 2, 3, 2, 4, 2 , 4, 3, 3, 4, 2, 4, 5.

n n Упорядочив варианты по степени их возрастания, получаем следующий статистический ряд: 1, 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5. Вслед за упорядочением вариант часто производят их группировку. Группировка – это классификация на основе упорядочения имеющихся данных по признаку подобия. Ее смысл состоит в выявлении взаимосвязей между несколькими переменными, в поиске устойчивых сочетаний свойств. Для случаев непрерывной переменной, т. е. такой единицы измерения, которая может иметь дробные значения (в отличие от дискретной переменной, подобной примеру № 1), группировка – это объединение вариант в интервалы, границы которых устанавливаются произвольно и непременно указываются. Такие интервалы могут быть и неравномерными. Срединное значение, или центр интервала, берется обычно числом целым.

n n Важной проблемой группировки психологической информации является вопрос о выборе признаков, на основе которых производится распределение единиц объекта исследования по группам. Поэтому при отборе материала следует учитывать наиболее существенные признаки, позволяющие объединять его в одну группу. Они вытекают из логики исследования, закладываются в методики и инструментарий, хотя в некоторых случаях возможны и корректировки, вызванные полученными результатами. Основания для группировки бывают самыми различными. Материал может быть объединен по роли и значимости; структурным, функциональным признакам; принадлежности к определенным психологическим типам. В выделенной группе концентрируется материал по данной проблеме, полученный различными методами (анкетированием, наблюдением, тестированием, изучением документов и т. д. ). Расчленение исследуемого объекта на составляющие позволяет глубоко и всесторонне проанализировать реальные внутренние характеристики каждого из структурных компонентов изучаемого явления, взаимосвязи между ними, сделать соответствующие научные выводы.

n n Следующим этапом, логически вытекающим из двух предшествующих, является табулирование, т. е. построение таблиц или собственно статистических распределений, в которых каждой варианте хi поставлена в соответствие ее частота fi в выборке или при необходимости – частость wi. В таблицу можно свести не только числовые данные. К данным качественного характера также могут быть применены простейшие способы количественной обработки. Для всей выборки и отдельных подвыборок могут быть подсчитаны частоты встречаемости (количество случаев появления события), а затем и частости (относительные частоты, т. е. частоты, деленные на количество испытаний) интересующих нас индикаторов, проявлений некоторого вида.

n n Так, например, при использовании рисуночного теста “Дерево” можно в качестве параметра рассматривать наличие/отсутствие листьев на ветках в рисунке. Если этот параметр будет определен у всех испытуемых, то это позволит подсчитать частость его появления по всей выборке и для отдельных групп внутри ее. В таблицу могут быть сведены данные и по другим параметрам теста “Дерево”, а затем подсчитаны частости. Далее можно сделать таблицу, в которой будут представлены данные не по отдельным испытуемым, а для всей выборки и отдельных групп, например, полярных групп. Это позволит сделать шаг к более целостному представлению информации. Еще один пример (пример № 2). Допустим, что в эксперименте по выработке двигательного навыка результаты первой пробы для 30 испытуемых (после упорядочения) имеют следующий вид статистического ряда (в сек. ): 5, 3; 5, 9; 6, 2; 6, 6; 6, 8; 7, 0; 7, 3; 7, 7; 7, 8; 7, 9; 8, 1; 8, 3; 8, 4; 8, 6; 8, 8; 8, 9; 9, 3; 9, 5; 9, 7; 10, 3; 10, 6; 11, 0; 11, 4; 11, 6; 11, 9; 12, 6; 13, 1; 13, 9.
: Таблица 1 Статистическое")
Произведя группировку и табулирование, получаем следующее статистическое распределение (см. табл. 1): Таблица 1 Статистическое распределение эмпирических данных. n N – 30

Конечно, такая классификация вариант в искусственные интервалы искажает исходную выборку и требует введения особой поправки на непрерывность интервала при последующих вычислениях. Для примера № 1 статистическое распределение таково (см. табл. 2): n n N – 35 Таблица 2

После создания таблицы на бумаге или электронной таблицы на компьютере необходимо проверить качество полученных данных. Для этого часто достаточно внимательно осмотреть массив данных. Начать проверку следует с выявления ошибок (описок), которые заключаются в том, что неправильно написан порядок числа. Например, 100 написано вместо 10; 9, 4 – вместо 94 и т. п. При внимательном просмотре по столбцам таблицы это легко обнаружить, поскольку сравнительно редко встречаются параметры, которые сильно варьируют. Чаще всего, значения одного параметра имеют один порядок или ближайшие порядки. При наборе данных на компьютере важно соблюдать требования к формату данных в используемой статистической программе. Прежде всего это относится к знаку, который должен отделять в десятичном числе целую часть от дробной (точка или запятая).

n n n Затем массы данных надо проверить на наличие “выскакивающих” вариант – выделяющихся значений, которые могли быть получены в результате неточных измерений, ошибок в записях, отвлечения внимания испытуемого и т. д. Если обнаружены “подозрительные” значения, то необходимо принять обоснованное решение об их выбраковке. Его можно принять, используя достаточно мощный параметрический критерий t. Он рассчитывается по следующей формуле: где: t – критерий выпада; V – выпадающее значение признака; М – средняя величина признака для всей группы, включающей артефакт; tst – стандартные значения критерия выпадов, определяемые для трех уровней доверительной вероятности по специальной таблице.

Смысл критерия в том, чтобы определить, находится ли данная варианта в интервале, характерном для большинства членов выборки, или же вне его. Допустим, нами принят уровень значимости 0. 05 (доверительная вероятность 0. 95), а значение критерия составило 1. 5. Поскольку 95% вариант лежат в пределах М 1. 96 (1. 5 меньше 1. 96), следовательно, данная варианта лежит в указанном интервале. Если же значение критерия больше, например, 2. 4, то это означает, что данное значение не относится к анализируемой совокупности (выборке), включающей 95% вариант, а есть проявление иных закономерностей, ошибок и пр. и поэтому должно быть исключено из рассмотрения.

Например, в эксперименте предлагается решать мыслительные задачи и в числе других параметров регистрируется время решения. При просмотре данных обнаруживается, что у одного из испытуемых время решения заметно больше, чем у остальных. Это бывает связано с тем, что вместо решения очередной задачи, испытуемый начинает “искать закономерность более широкого плана”, “выводить общий принцип” или нечто подобное. Об этом он может сообщить экспериментатору, но может и не сообщать. Понятно, что время решения конкретной задачи при этом может сильно отличаться от средней величины. В этом случае мы оказываемся перед необходимостью принять обоснованное решение – включать данное значение в дальнейшую обработку или нет.

n Предположим, в нашем эксперименте были получены следующие значения некоторого параметра: 10, 20, 30, 40, 50, 210. Следовательно, n = 9. Вычислили: M = 50; = 61. Можно ли считать значение 210 выпадающим? n n n tst (по табл. ) = 2, 4 (для P=0, 95) Следовательно, значение 210 может считаться выпадающим и должно быть исключено из дальнейшей обработки. После исключения выпадающих значений первичные статистические параметры вычисляются заново.

n 3. Виды анализа, используемые в прикладном психологическом исследовании. Дальнейшая логика работы исследователя связана с проведением анализа полученных данных. Виды анализа, используемые в прикладном психологическом исследовании: n 1. Качественный анализ: n n n а) Функциональный – анализ по выявлению устойчивых инвариантных связей объекта исследования. б). Структурный анализ по выявлению элементов (составных частей) объекта исследования и способов их сочетания. в). Генетический анализ по выявлению последовательности фаз развития объекта исследования, установление причинных связей. г). Системный анализ – изучение объекта как целого в его отношениях со средой. 2. Количественный анализ (анализ с использованием методов статистики):
 Анализ средних величин – направлен")
n 2. 1. Методы описательной статистики. n n а) Анализ средних величин – направлен на обобщение изучаемых совокупностей признаков, на сравнение уровней отдельных признаков с уровнем совокупности признаков. б). Графический анализ служит для выявления структуры значений признаков. в). Вариационный (дисперсионный анализ) – изучение колебаний признака относительно его среднего значения. 2. 2. Методы статистического анализа взаимосвязи признаков. n n n а). Регрессионный анализ – изучение изменений значений результативного признака в зависимости от изменений признаков – факторов. б). Корреляционный анализ – установление связи между признаками. в). Логлинейный анализ – поиск и оценка взаимосвязей в таблице, сжатое описание табличных данных. г). Факторный анализ – многомерный статистический анализ вариации признаков, установление внутренней взаимосвязи признаков. д). Кластерный (таксонометрический анализ) – классификация признаков и анализ связей классификационных единиц. е). Теоретико информационный анализ – обработка данных на основе использования математической теории информации.


Существуют различные виды анализа, проводимые на всех этапах психологического исследования. Как мы видим, выделяются прежде всего такие группы (или разновидности), как качественный анализ и количественный анализ (анализ с использованием методов математической статистики). В реальном исследовании все виды анализа тесно связаны между собой. Например, качественный анализ полученных данных возможен на основе их предварительной обработки с использованием методов статистики. Методами статистической обработки результатов исследования называются математические приемы, формулы, способы количествен ных асчетов, с расчетов, р помощью которых количественные показатели, полу чаемые в ходе эксперимента, можно обобщать, приводить в систему, выявляя скрытые в них закономерности. Речь идет о таких законо мерностях статистического характера, которые существуют между изучаемыми в эксперименте переменными величинами.

Некоторые из методов математико статистического анализа позволяют вычислять так называемые элементарные математические статистики, характеризующие выборочное распределение данных, например выборочное среднее, выборочная дисперсия, мода, ме диана и и ряд других. Иные методы математической статистики, например, дисперсионный анализ, регрессионный анализ, позволяют судить о динамике изменения отдельных статистик выборки. С помощью третьей группы методов, скажем, корреляционного анализа, факторного анализа, методов сравнения выборочных данных, можно достоверно судить о статистических связях, существующих между переменными величинами, которые исследуют в данном эксперименте.
 анализа")
4. Последовательность обработки и анализа эмпирических данных. n Все методы количественного (математико статистического) анализа условно делятся на первичные и вторичные. Первичными называют методы, с помощью которых можно получить показатели, непосредственно отражающие результаты производимых в эксперименте измерений. Соответственно под первичными статистическими показателями имеются в виду те, которые применяются в самих психодиагности ческих методиках и являются итогом начальной статистической обработки результатов психодиагностики. К первичным методам статистической обработки относят, например, определение выборочной средней величины, выборочной дисперсии, выборочной моды и выборочной медианы. Данные величины позволяют определить характер распределения результатов по выборке испытуемых.

Рассмотрим более подробно эту группу методов. Речь идет об анализе первичных статистик. Итак, мы знаем, что количественный анализ данных в психологическом исследовании основан на преобразовании исходной индивидуальной информации, получаемой от отдельных испытуемых, в совокупную информацию, обобщающую их ответы в характерных группах. Состав таких групп, порядок отбора в них испытуемых, содержание опроса определяется психологом на основе программы исследования. Рис. 4. Последовательность эмпирических данных обработки и анализа

При любой степени абстрагирования и обобщения на практике психолог имеет дело с отдельными людьми. Индивидуальная информация, полученная от испытуемых, конкретна, она несет в себе только отдельные признаки объектов. Количественный анализ данных в психологическом исследовании представляет собой дальнейший этап преобразования исходной информации на пути восхождения от конкретного к абстрактному, при выявлении общих тенденций и закономерностей. Он всегда применяется вместе с качественным, содержательным анализом данных. Для определения способов математико статистической обработки, прежде всего, необходимо оценить характер распределения по всем используемым параметрам. Для параметров, имеющих нормальное распределение или близкое к нормальному, можно использовать методы параметрической статистики, которые во многих случаях являются более мощными, чем методы непараметрической статистики. Достоинством последних является то, что они позволяют проверить статистические гипотезы независимо от формы распределения.

Нормальное распределение – модель варьирования некоторой случайной величины, значения которой определяются множеством одновременно действующих независимых факторов. Число этих факторов велико, а эффект влияния каждого из них в отдельности очень мал. Такой характер взаимовлияний весьма характерен для психических явлений, поэтому исследователь в области психологии чаще всего выявляет нормальное распределение. При оценке характера распределения результатов в выборке по используемым параметрам используются преимущественно показатели колеблемости наблюдаемых признаков, которые характеризуют разброс значений изучаемого ряда чисел относительно их средней арифметической.

Рис. 5. Виды распределения первичных результатов (а – n нормальное распределение, б – бимодальное распределение, в – асимметричное распределение; М – средняя арифметическая, Мо – мода, Мемедиана)

Простая средняя или среднее арифметическое является достаточно существенным показателем для обработки результатов оперативных исследований. Для ее вычисления нужно разделить сумму усредняемых чисел на их количество. В статистике среднюю арифметическую обозначают буквой М или х. Преимущество средней арифметической – простота вычисления. Однако приемлемая точность при этом достигается только в случае однородности распределения всех усредняемых чисел. Следовательно, психолог может широко использовать в своей исследовательской практике процедуру усреднения исходных данных, но при этом от него требуется методологическая дисциплина и методическая грамотность, творчество и осмотрительность.
 вычисляется по формуле: Х= где n Хi")
n Вычисление среднего арифметического. Среднее арифметическое (Х) вычисляется по формуле: Х= где n Хi величина отдельных элементов совокупности; n N объем совокупности n n Простую арифметическую среднюю используют при нахождении моды и медианы. 1. Мода (Мо) —соответствует либо наиболее частому значению, либо среднему значению класса с наибольшей частотой. 10 11 12 13 14 14 15 15 17 17 19 20 21, Так, в нашем примере для экспериментальной группы мода для фона будет равна 15 (этот результат встречается четыре раза и находится в середине класса 14 15 16), а после воздействия — 9 (середина класса 8 9 10).

Мода используется редко и главным образом для того, чтобы дать общее представление о распределении. В некоторых случаях у распределения могут быть две моды; тогда говорят о бимодальном распределении. Такая картина указывает на то, что в данном совокупности имеются две относительно самостоятельные группы. 2. Медиана (Ме) значение переменной, которое является средним, центральным по положению в общем упорядоченном ряду вариант выборки. Это “золотая середина”, справа и слева от которой остальные варианты располагаются поровну, тогда как их удельный вес не принимается во внимание. Порядковый номер медианы в ряду вычисляется следующим образом. n 7 8 9 11 12 13 14; 11; 7 8 9 11 12 13 14 16; (11 + 12)/2=11, 5

Если в ранжированном ряду четное число членов, то при использовании формулы порядковый номер медианы число, находящееся между двумя средними членами. Это означает, что в середине ряда находятся два члена, среднее арифметическое которых дает одну величину медианы. Коэффициент асимметрии – показатель скошенности распределения в левую или правую сторону по оси абсцисс. Если правая ветвь кривей длиннее левой – говорят о положительной асимметрии, в противоположном случае – об отрицательной; Эксцесс – показатель островершинности кривой распределения. Кривые, более высокие в своей средней части, островершинные, называются эксцессивными, у них большая величина эксцесса. При уменьшении величины эксцесса кривая становится все более плоской, приобретая вид плато, а затем и седловины – с прогибом в средней части.
")
n n Эти параметры позволяют составить первое приближенное представление о характере распределения: n 1) у нормального распределения редко можно обнаружить коэффициент асимметрии близкий к единице и более единицы ( 1, +1); n 2) эксцесс у признаков с нормальным распределением обычно имеет величину в диапазоне 2– 4. Следует отметить, что это только приблизительная оценка. Точную и строгую оценку нормальности распределения можно получить, используя специальные методы проверки. (см. , например, книгу Г. В. Суходольского “Основы математической статистики для психологов”, Л. , 1972. Главы 2 и 5. ).

Начинать с анализа первичных статистик надо еще и по той причине, что они весьма чувствительны к наличию выпадающих вариант. На практике же, очень большие эксцесс и асимметрия часто являются индикатором ошибок при подсчетах вручную или ошибок при введении данных через клавиатуру при компьютерной обработке. Существует правило, согласно которому все расчеты вручную должны выполняться дважды (особенно ответственные – трижды), причем желательно разными способами, с вариацией последовательности обращения к числовому массиву. Для характеристики варьирования элементов совокупности чаще всего применяют дисперсию и стандартное отклонение. Эти числа характеризуют рассеивание (разбросанность) значений элементов совокупности около ее среднего арифметического значения.

n Дисперсию вычисляют по формуле: = n Квадратный корень из дисперсии дает стандартное или среднее квадратическое отклонение ( сигма) – мера разнообразия входящих в группу объектов, она показывает, на сколько в среднем отклоняется каждая варианта (конкретное значение оцениваемого параметра) от средней арифметической. Чем сильнее разбросаны варианты относительно середины, тем большим оказывается среднее квадратичное отклонение. =

Коэффициент вариации – частное от деления сигмы на среднюю, умноженную на 100%. Обозначается CV: Вторичными называются методы статистической обработки, с помощью которых на базе первичных данных выявляют скрытые в них статистические зако номерности. В число вторичных методов обычно включают методы сравнения первичных статистик у двух или нескольких выборок, корреляционный анализ, факторный анализ, регрессионный анализ и др. Данные методы позволяют выявить внутреннюю структуру изучаемого свойства (эмпирических данных), установить статистические взаимосвязи между переменными, сравнить между собой две или более элементарные статистики, установить влияние одной или более переменной на другие переменные.

n Оценка достоверности отличий Одной из наиболее часто встречающихся задач при обработке данных является оценка достоверности отличий между двумя и более рядами значений. В математической статистике существует ряд способов для этого. Достоверность различий средних арифметических можно оценить по достаточно эффективному параметрическому критерию Стьюдента. Он вычисляется по формуле: где: М 1 и М 2 – значения сравниваемых средних арифметических, m 1 и m 2 – соответствующие величины статистических ошибок средних арифметических.
 приводятся в специальных")
n n Значения критерия Стьюдента t для трех уровней значимости (p) приводятся в специальных таблицах “Значения критерия Стьюдента t при различных уровнях значимости (p)”. Число степеней свободы определяется по формуле: d = (n 1 + n 2) – 2, где n 1 и n 2 – объемы сравниваемых выборок. С уменьшением объема выборок (n < 10) критерий Стьюдента становится чувствительным к форме распределения исследуемого признака в генеральной совокупности. Поэтому в сомнительных случаях рекомендуется использовать непараметрические методы или сравнивать полученные значения с критическими (приведенными в таблице) для более высокого уровня значимости.

n Решение о достоверности различий принимается в том случае, если вычисленная величина td превышает табличное значение для данного числа степеней свободы. В тексте отчета указывают наиболее высокий уровень значимости из трех: 0. 05, 0. 01 или 0. 001. Если превышены 0. 05 и 0. 01, то пишут (обычно в скобках) p = 0. 01 или p < 0. 01. Это означает, что оцениваемые различия все же случайны только с вероятностью не более 1 из 100 шансов. Если превышены табличные значения для всех трех уровней: 0. 05, 0. 01 и 0. 001, то указывают p = 0. 001 или p < 0. 001, что означает случайность выявленных различий между средними не более 1 из 1000 шансов.

n Следует помнить, что при любом численном значении критерия достоверности, различия между средними, этот показатель оценивает не степень выявленного различия (она оценивается по самой разности между средними), а лишь статистическую достоверность его, т. е. право распространять полученный на основе сопоставления выборок вывод о наличии разницы на все явление (весь процесс) в целом. Низкий вычисленный коэффициент различия не может служить доказательством отсутствия различия между двумя признаками (явлениями), ибо его значимость (степень вероятности) зависит не только от величины средних, но и от численности сравниваемых выборок. Он говорит не об отсутствии различия, а о том, что при данной величине выборок оно статистически недостоверно: слишком велик шанс, что разница при данных условиях определения случайна, слишком мала вероятность ее достоверности.
")
Заключение. Таким образом, реализуемые психологом процедуры (обработка, обобщение, анализ, объяснение и наглядное представление данных) тесно переплетены между собой. Каждая из них является в большинстве случаев либо условием, отправным пунктом, либо переходным звеном к решению следующей (согласно общей программе исследования) задачи. Последовательность обработки и обобщения информации сопровождается изменением ее качественных параметров (подлежащих анализу) за счет повышения их информативной емкости, что достигается, в свою очередь, трансформацией форм репрезентации интересующего исследователя явления (свойства).
Стандартные способы обработки и анализа данных.ppt