

16_основная_память.ppt
- Количество слайдов: 38
 ЛЕКЦИЯ 16. СИСТЕМА УПРАВЛЕНИЯ ОПЕРАТИВНОЙ ПАМЯТЬЮ
ЛЕКЦИЯ 16. СИСТЕМА УПРАВЛЕНИЯ ОПЕРАТИВНОЙ ПАМЯТЬЮ
 Страничное распределение ВП Для преобразования виртуальных адресов в физические физическая и ВП разбиваются на блоки фиксированной длины, называемые страницами. Объемы виртуальной и физической страниц совпадают. Страницы виртуальной и физической памяти нумеруются. Виртуальный (логический) адрес в этом случае представляет собой номер виртуальной страницы и смещение внутри этой страницы. Физический адрес – это номер физической страницы и смещение в ней.
Страничное распределение ВП Для преобразования виртуальных адресов в физические физическая и ВП разбиваются на блоки фиксированной длины, называемые страницами. Объемы виртуальной и физической страниц совпадают. Страницы виртуальной и физической памяти нумеруются. Виртуальный (логический) адрес в этом случае представляет собой номер виртуальной страницы и смещение внутри этой страницы. Физический адрес – это номер физической страницы и смещение в ней.
 Механизм преобразования ВА в ФА при страничной организации памяти
Механизм преобразования ВА в ФА при страничной организации памяти
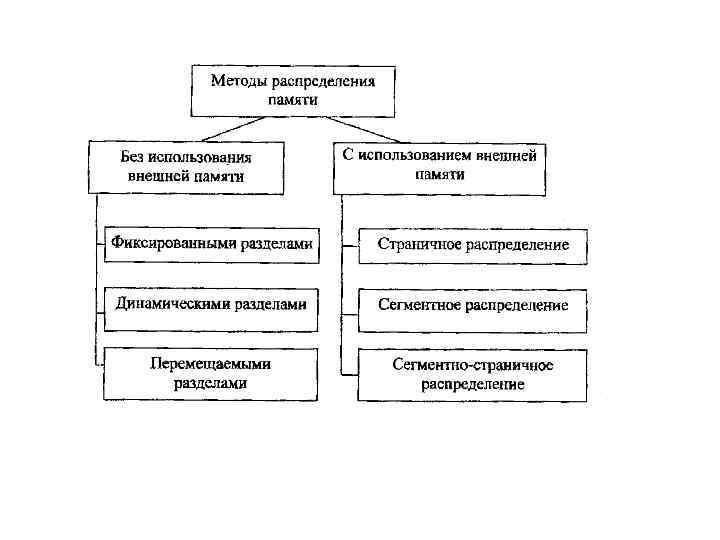
 Рассмотрим пример преобразования адреса ВС в адрес ФС. Пусть VОЗУ = 3 и Vстр=1. Пусть коэффициент мультипрограммирования равен четырем. Переключение между программами происходит через tk = 1. Время выполнения каждой страницы любой программы t = 2 tk. Полагаем, что страницы программ загружаются в ОП по мере их необходимости и, по возможности, в свободные области ОЗУ. Если вся ОП занята, то новая страница замещает ту, к которой дольше всего не было обращений (LRU). Пусть выполняемые программы имеют следующее количество страниц: VA=2, VB=1, VC=3, VD=2.
Рассмотрим пример преобразования адреса ВС в адрес ФС. Пусть VОЗУ = 3 и Vстр=1. Пусть коэффициент мультипрограммирования равен четырем. Переключение между программами происходит через tk = 1. Время выполнения каждой страницы любой программы t = 2 tk. Полагаем, что страницы программ загружаются в ОП по мере их необходимости и, по возможности, в свободные области ОЗУ. Если вся ОП занята, то новая страница замещает ту, к которой дольше всего не было обращений (LRU). Пусть выполняемые программы имеют следующее количество страниц: VA=2, VB=1, VC=3, VD=2.
 Сегментное распределение ВП
Сегментное распределение ВП
 Странично - сегментное распределение
Странично - сегментное распределение
 Самостоятельно 1. Организация виртуальной памяти в ПЭВМ на основе 32 -разрядного микропроцессора. 2. Методы повышения пропускной способности ОП
Самостоятельно 1. Организация виртуальной памяти в ПЭВМ на основе 32 -разрядного микропроцессора. 2. Методы повышения пропускной способности ОП
 Методы организации кэш-памяти Основное назначение кэш-памяти - кратковременное хранение и выдача активной информации процессору, что сокращает число обращений к ОП, скорость работы которой меньше, чем кэш-памяти. Единица обмена между ОП и кэш-памятью – строка (набор слов, выбираемый из ОП при одном обращении к ней). В любой момент времени строки в кэш – это копии строк из некоторого их набора в ОП, однако расположены они необязательно в такой же последовательности, как в ОП.
Методы организации кэш-памяти Основное назначение кэш-памяти - кратковременное хранение и выдача активной информации процессору, что сокращает число обращений к ОП, скорость работы которой меньше, чем кэш-памяти. Единица обмена между ОП и кэш-памятью – строка (набор слов, выбираемый из ОП при одном обращении к ней). В любой момент времени строки в кэш – это копии строк из некоторого их набора в ОП, однако расположены они необязательно в такой же последовательности, как в ОП.
 80386 – 16 байт, 80486 – 8 Кбайт В Pentium кэш разделён на две части: одна – только для команд, другая – только для данных. В Pentium Pro появился кэш L 2 (cache level 2), который имеет больший объём, чем кэш L 1, работающий с ним в паре. Pentium 4 XE (Extreme Edition) 3, 2 ГГц с ядром Gallatin появился кэш L 3. Обычно в процессорах выдерживается следующее соотношение объёмов кэшпамяти: L 1 < L 2 < L 3. Например, в Pentium 4 XE (с ядром Gallatin) кэш L 3 = 2 Мбайт, L 2 = 512 Кбайт, L 1= 8 Кбайт. Бывают исключения из этого правила: в МП AMD Duron и VIA C 3, кэш L 1 = 128 Кбайт (из них 64 Кбайт - под команды, 64 - для данных) и L 2 = 64 Кбайт.
80386 – 16 байт, 80486 – 8 Кбайт В Pentium кэш разделён на две части: одна – только для команд, другая – только для данных. В Pentium Pro появился кэш L 2 (cache level 2), который имеет больший объём, чем кэш L 1, работающий с ним в паре. Pentium 4 XE (Extreme Edition) 3, 2 ГГц с ядром Gallatin появился кэш L 3. Обычно в процессорах выдерживается следующее соотношение объёмов кэшпамяти: L 1 < L 2 < L 3. Например, в Pentium 4 XE (с ядром Gallatin) кэш L 3 = 2 Мбайт, L 2 = 512 Кбайт, L 1= 8 Кбайт. Бывают исключения из этого правила: в МП AMD Duron и VIA C 3, кэш L 1 = 128 Кбайт (из них 64 Кбайт - под команды, 64 - для данных) и L 2 = 64 Кбайт.
 Работа МП по поиску необходимой информации состоит из нескольких циклов обращения на следующие уровни иерархии памяти: • в первую очередь просматривается -------, • если запрашиваемые данные там отсутствуют, поиск продолжается в ------ и так далее. Наименьшая задержка в работе будет, когда запрашиваемые МП данные будут найдены сразу в ------, наихудшим вариантом будет обращение МП к последней инстанции - к -------.
Работа МП по поиску необходимой информации состоит из нескольких циклов обращения на следующие уровни иерархии памяти: • в первую очередь просматривается -------, • если запрашиваемые данные там отсутствуют, поиск продолжается в ------ и так далее. Наименьшая задержка в работе будет, когда запрашиваемые МП данные будут найдены сразу в ------, наихудшим вариантом будет обращение МП к последней инстанции - к -------.
 составляет 4") Длительность обращения МП к кэш-памяти: 1 -го уровня (латентность кэша L 1) составляет 4 такта работы МП, латентность кэш L 2 равна 22 -28 тактов процессора, латентность ОП может достигать 200 -300 тактов процессора. Такая традиционная схема организации кэш-памяти ("инклюзивная" архитектура, при которой всё содержимое кэша L 1 копируется в кэш L 2) оправдана только в том случае, если по объёму кэши L 1 и L 2 уровней сильно различаются. В противном случае пространство кэш-памяти используется дважды, что неэффективно. У процессора AMD Duron кэш L 2 был “эксклюзивный”, полностью независимый от кэша L 1, т. е. информация, хранящаяся в L 1 (128 Кбайт) не дублировалась в L 2 (64 Кбайт). Таким образом, суммарный полезный объём кэш-памяти (эффективный объём) у Duron составлял 192 Кбайт.
Длительность обращения МП к кэш-памяти: 1 -го уровня (латентность кэша L 1) составляет 4 такта работы МП, латентность кэш L 2 равна 22 -28 тактов процессора, латентность ОП может достигать 200 -300 тактов процессора. Такая традиционная схема организации кэш-памяти ("инклюзивная" архитектура, при которой всё содержимое кэша L 1 копируется в кэш L 2) оправдана только в том случае, если по объёму кэши L 1 и L 2 уровней сильно различаются. В противном случае пространство кэш-памяти используется дважды, что неэффективно. У процессора AMD Duron кэш L 2 был “эксклюзивный”, полностью независимый от кэша L 1, т. е. информация, хранящаяся в L 1 (128 Кбайт) не дублировалась в L 2 (64 Кбайт). Таким образом, суммарный полезный объём кэш-памяти (эффективный объём) у Duron составлял 192 Кбайт.
 Итак, существует 2 вида построения кэш-памяти Ехclusive: ничего не лежит в L 1 и L 2 одновременно. Inclusive: всё дублируется в L 1 и L 2 одновременно. МП L 1 L 2 RAM
Итак, существует 2 вида построения кэш-памяти Ехclusive: ничего не лежит в L 1 и L 2 одновременно. Inclusive: всё дублируется в L 1 и L 2 одновременно. МП L 1 L 2 RAM
 В современных МП активно используется ещё один подвид кэша, называемый TLB (Translation Look-aside Buffer, буфер быстрого преобразования адреса). В нём хранятся адреса команд и данных, находящихся в кэше, которые, вероятнее всего, потребуются МП в ближайшее время. Фактически блок TLB предназначен для ускорения поиска необходимой информации в кэш-памяти.
В современных МП активно используется ещё один подвид кэша, называемый TLB (Translation Look-aside Buffer, буфер быстрого преобразования адреса). В нём хранятся адреса команд и данных, находящихся в кэше, которые, вероятнее всего, потребуются МП в ближайшее время. Фактически блок TLB предназначен для ускорения поиска необходимой информации в кэш-памяти.

 принцип локальности программ; 2) оптимальная длина блока. D. Knuth установил,") Принципы построения кэш-памяти 1) принцип локальности программ; 2) оптимальная длина блока. D. Knuth установил, что линейные участки программ обычно не превышают 3. . . 5 команд, а значит, и нет особого смысла в использовании блоков, размер которых превышает эту величину. Таким образом, информация из основной памяти загружается в кэш блоками по 2. . . 4 слова и хранится в нем в течение некоторого времени.
Принципы построения кэш-памяти 1) принцип локальности программ; 2) оптимальная длина блока. D. Knuth установил, что линейные участки программ обычно не превышают 3. . . 5 команд, а значит, и нет особого смысла в использовании блоков, размер которых превышает эту величину. Таким образом, информация из основной памяти загружается в кэш блоками по 2. . . 4 слова и хранится в нем в течение некоторого времени.
 С увеличением длины строки вероятность того, что следующее обращение к КЭШу будет удачным, повышается. Известно, например, что если при объеме кэшпамяти 4 Кбайт и длине строки 4 байт вероятность удачных обращений составляет 80%, то при удвоении длины строки это значение может достигать уже 85%. Однако при увеличении длины строки еще в два раза вероятность удачных обращений достигнет только 87%.
С увеличением длины строки вероятность того, что следующее обращение к КЭШу будет удачным, повышается. Известно, например, что если при объеме кэшпамяти 4 Кбайт и длине строки 4 байт вероятность удачных обращений составляет 80%, то при удвоении длины строки это значение может достигать уже 85%. Однако при увеличении длины строки еще в два раза вероятность удачных обращений достигнет только 87%.
 Типовая структура кэш-памяти
Типовая структура кэш-памяти
 Виды организации кэш-памяти В основу организации кэш-памяти положены принципы отображения адресов блоков ОП на адреса блоков в кэше. Проблема оптимального взаимодействия кэша и ОП решается введением трех типов кэша, различающихся принципами организации: 1) кэш с прямым отображением (direct mapped); 2) полностью ассоциативный кэш (fully associative); 3) множественно-ассоциативный кэш (set associative).
Виды организации кэш-памяти В основу организации кэш-памяти положены принципы отображения адресов блоков ОП на адреса блоков в кэше. Проблема оптимального взаимодействия кэша и ОП решается введением трех типов кэша, различающихся принципами организации: 1) кэш с прямым отображением (direct mapped); 2) полностью ассоциативный кэш (fully associative); 3) множественно-ассоциативный кэш (set associative).
 Для отображения адресов блоков ОП на адреса в кэше используются младшие разряды адреса блока (АБ). (АБ кэш-памяти) = (АБ ОП) mod (число блоков в кэше) Допустим, что в компьютере используется 32 разрядный адрес ОП. Размер блока = 4 байтам, а емкость кэша = 64 Кбайта (16 К блоков по 4 байта). В этом случае для формирования адреса буфера достаточно 16 разрядов, из которых два младших определяют один из четырех байтов в строке (offset), а 14 старших разрядов адресуют один из 16 К блоков кэша (line).
Для отображения адресов блоков ОП на адреса в кэше используются младшие разряды адреса блока (АБ). (АБ кэш-памяти) = (АБ ОП) mod (число блоков в кэше) Допустим, что в компьютере используется 32 разрядный адрес ОП. Размер блока = 4 байтам, а емкость кэша = 64 Кбайта (16 К блоков по 4 байта). В этом случае для формирования адреса буфера достаточно 16 разрядов, из которых два младших определяют один из четырех байтов в строке (offset), а 14 старших разрядов адресуют один из 16 К блоков кэша (line).
 В соответствии с этим адрес ОП можно разбить на два поля: • младшие 16 разрядов - индекс, • старшие 16 разрядов - признак. Индекс определяет адрес кэш-памяти (строку кэша), а признак позволяет отличить один блок ОП от другого при записи в некоторую строку буфера. Хранится он в специальной памяти признаков.
В соответствии с этим адрес ОП можно разбить на два поля: • младшие 16 разрядов - индекс, • старшие 16 разрядов - признак. Индекс определяет адрес кэш-памяти (строку кэша), а признак позволяет отличить один блок ОП от другого при записи в некоторую строку буфера. Хранится он в специальной памяти признаков.
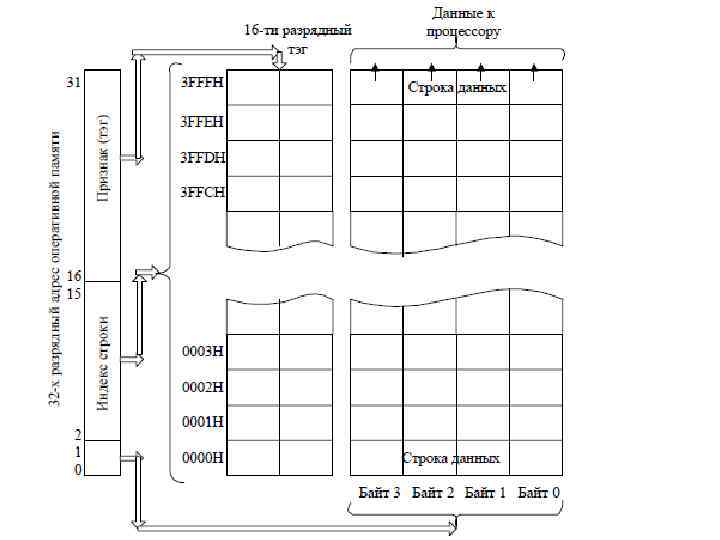
 Существенное преимущество данного типа кэша - необходимо только одно сравнение признака, выбранного из соответствующей строки, и старших разрядов адреса ОП, выданного процессором. Это повышает производительность системы. Недостатки: если адреса двух блоков отличаются только полем признака, то они будут отображаться на одну и ту же строку буфера, поэтому при обращении к таким полям возникает конфликт. Для его разрешения старый блок из кэша переписывается в ОП, а на его место помещается новый.
Существенное преимущество данного типа кэша - необходимо только одно сравнение признака, выбранного из соответствующей строки, и старших разрядов адреса ОП, выданного процессором. Это повышает производительность системы. Недостатки: если адреса двух блоков отличаются только полем признака, то они будут отображаться на одну и ту же строку буфера, поэтому при обращении к таким полям возникает конфликт. Для его разрешения старый блок из кэша переписывается в ОП, а на его место помещается новый.
 Полностью ассоциативный кэш
Полностью ассоциативный кэш
 Полностью ассоциативной кэш разрешает проблему конфликта адресов, но ценой дополнительного оборудования и увеличения времени обработки запроса в память.
Полностью ассоциативной кэш разрешает проблему конфликта адресов, но ценой дополнительного оборудования и увеличения времени обработки запроса в память.
 Множественно-ассоциативный кэш Кэш этого типа разделён на фиксированное количество областей, именуемое степенью ассоциативности, и каждая строка RAM может отображаться в произвольном месте только одной из областей кэша. Обычно это множество мест представляет собой группу из двух или большего числа блоков в кэше. Если множество состоит из n блоков, то такое размещение называется множественноассоциативным с n каналами (n-way set associative).
Множественно-ассоциативный кэш Кэш этого типа разделён на фиксированное количество областей, именуемое степенью ассоциативности, и каждая строка RAM может отображаться в произвольном месте только одной из областей кэша. Обычно это множество мест представляет собой группу из двух или большего числа блоков в кэше. Если множество состоит из n блоков, то такое размещение называется множественноассоциативным с n каналами (n-way set associative).
 Для размещения блока прежде всего необходимо определить множество. Множество определяется младшими разрядами адреса блока памяти (индексом): (адрес множества кэше) = (АБ ОП) mod (число множеств в кэше)
Для размещения блока прежде всего необходимо определить множество. Множество определяется младшими разрядами адреса блока памяти (индексом): (адрес множества кэше) = (АБ ОП) mod (число множеств в кэше)
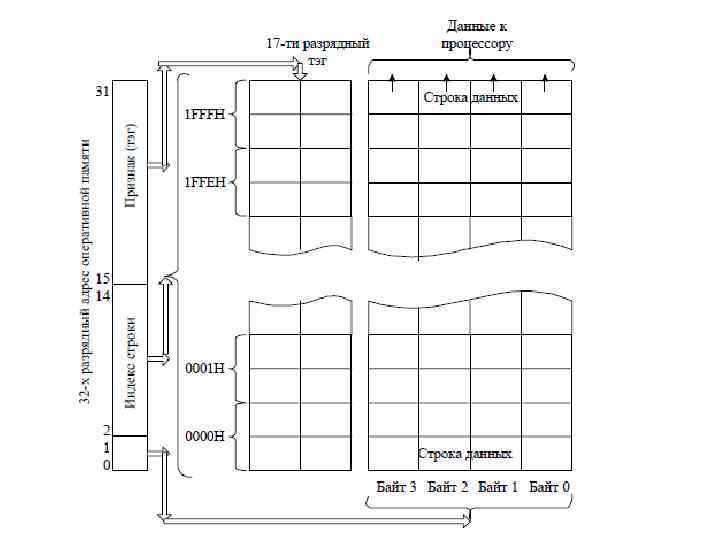
 Важным параметром для множественноассоциативного кэша является правильный выбор степени ассоциативности или, что то же самое, количества каналов у кэша L 2. У процессоров Pentium III и Pentium 4 имелось 8 каналов кэша L 2, у AMD K 7 Athlon - 2 канала, у AMD K 75 Athlon с ядром Thunderbird - 16 каналов.
Важным параметром для множественноассоциативного кэша является правильный выбор степени ассоциативности или, что то же самое, количества каналов у кэша L 2. У процессоров Pentium III и Pentium 4 имелось 8 каналов кэша L 2, у AMD K 7 Athlon - 2 канала, у AMD K 75 Athlon с ядром Thunderbird - 16 каналов.
 время поиска Кэш с прямым отображением Полностью ассоциативный кэш Множественноассоциативный кэш вероятность присутствия необходимой информации минимальное минимальная максимальное максимальная оптимальная производительность
время поиска Кэш с прямым отображением Полностью ассоциативный кэш Множественноассоциативный кэш вероятность присутствия необходимой информации минимальное минимальная максимальное максимальная оптимальная производительность
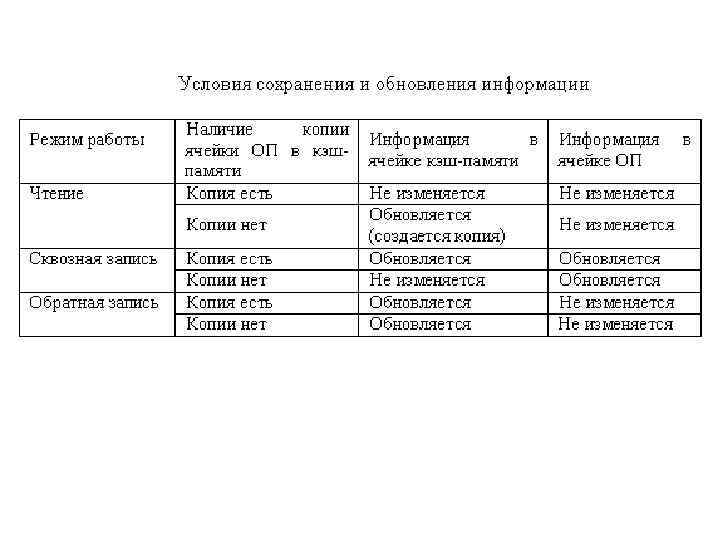
 Методы обновления строк в ОП ЧТЕНИЕ из кэш Если процессору требуется информация из некоторой ячейки ОП, а копия этой ячейки уже есть в кэш, то вместо оригинала считывается копия. В этом случае информация ни в кэш, ни в ОП не изменяется.
Методы обновления строк в ОП ЧТЕНИЕ из кэш Если процессору требуется информация из некоторой ячейки ОП, а копия этой ячейки уже есть в кэш, то вместо оригинала считывается копия. В этом случае информация ни в кэш, ни в ОП не изменяется.
 ЗАПИСЬ в кэш Если результат обновления строк кэше не возвращается в ОП, то содержимое ОП становится неадекватным вычислительному процессу. Поэтому…
ЗАПИСЬ в кэш Если результат обновления строк кэше не возвращается в ОП, то содержимое ОП становится неадекватным вычислительному процессу. Поэтому…
 Метод Write Through, называемый также методом сквозной записи, предполагает наличие двух копий данных - одной в ОП, а другой – в кэш-памяти. Каждый цикл записи МП в ОП идет через кэш. Как только обновили в кэше – сразу пишем в ОП.
Метод Write Through, называемый также методом сквозной записи, предполагает наличие двух копий данных - одной в ОП, а другой – в кэш-памяти. Каждый цикл записи МП в ОП идет через кэш. Как только обновили в кэше – сразу пишем в ОП.
 Метод Buffered Write Through – это разновидность Write Through и называется методом буферизированной сквозной записи. Для того чтобы как-то уменьшить загрузку шины, процесс записи выполняется в один или несколько буферов, которые работают по принципу FIFO (First Input-First Output - первым вошел - первым вышел).
Метод Buffered Write Through – это разновидность Write Through и называется методом буферизированной сквозной записи. Для того чтобы как-то уменьшить загрузку шины, процесс записи выполняется в один или несколько буферов, которые работают по принципу FIFO (First Input-First Output - первым вошел - первым вышел).
 записи – цикл записи МП происходит сначала в кэш-память,") Write Back метод обратной (отложенной) записи – цикл записи МП происходит сначала в кэш-память, если там есть адрес приемника. Если адреса приемника в кэше нет, то информация записывается непосредственно в ОП. Содержимое ОП обновляется только тогда, когда из кэш-памяти в нее записывается полный блок данных, называемый длиной строки-кэша (Cache-line). Прежде чем будет произведена замена содержимого строки кэша на новый блок ОП, старый блок должен быть перезаписан в ОП. Это связано с тем, что данные в этом блоке (если он использовался, разумеется) не совпадают с данными (старыми) этого блока в ОП и являются единственной действительной копией.
Write Back метод обратной (отложенной) записи – цикл записи МП происходит сначала в кэш-память, если там есть адрес приемника. Если адреса приемника в кэше нет, то информация записывается непосредственно в ОП. Содержимое ОП обновляется только тогда, когда из кэш-памяти в нее записывается полный блок данных, называемый длиной строки-кэша (Cache-line). Прежде чем будет произведена замена содержимого строки кэша на новый блок ОП, старый блок должен быть перезаписан в ОП. Это связано с тем, что данные в этом блоке (если он использовался, разумеется) не совпадают с данными (старыми) этого блока в ОП и являются единственной действительной копией.
 Производительность кэш-памяти Формула для среднего времени доступа к памяти в системах с кэш-памятью выглядит следующим образом: ТСР = ТП + КПР*ТПР, где ТП – время обращения при попадании, КПР – доля промахов, ТПР – потери промахе. Эта формула показывает пути оптимизации работы кэш-памяти.
Производительность кэш-памяти Формула для среднего времени доступа к памяти в системах с кэш-памятью выглядит следующим образом: ТСР = ТП + КПР*ТПР, где ТП – время обращения при попадании, КПР – доля промахов, ТПР – потери промахе. Эта формула показывает пути оптимизации работы кэш-памяти.