Презентация Бородкина.pptx
- Количество слайдов: 53



Л. И. Бородкин зав. кафедрой исторической информатики исторического факультета МГУ, член-корр. РАН Big Data для историков: уже реальность или еще перспектива?


• Ответ на поставленный вопрос зависит от определения Больших Данных. • Если следовать авторам вышедшей в 2015 г. в США книги "Exploring Big Historical Data: The Historian’s Macroscope”, то это такие данные источников, которые требуют компьютерной обработки для их понимания. Такое определение позволило авторам провозгласить, что историки давно живут в мире больших данных. • Однако, такое упрощенное понимание больших данных противоречит принятому в информационных науках, в цифровой экономике понятию больших данных.

• Введение термина «большие данные» относят к Клиффорду Линчу, редактору журнала Nature, подготовившему в сентябре 2008 года специальный выпуск с темой «Как могут повлиять на будущее науки технологии, открывающие возможности работы с большими объёмами данных? » , в котором были собраны материалы о феномене взрывного роста объёмов и многообразия обрабатываемых данных и технологических перспективах в парадигме вероятного скачка «от количества к качеству» .

Современное определение • Большие данные — совокупность подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, альтернативных традиционным системам управления базами данных. • В широком смысле о «больших данных» говорят как о социальноэкономическом феномене, связанном с появлением технологических возможностей анализировать огромные массивы данных, в некоторых проблемных областях — весь мировой объём данных, и вытекающих из этого трансформационных последствий

• В качестве определяющих характеристик для больших данных традиционно выделяют «три V» : объём (англ. volume, в смысле величины физического объёма данных), скорость (velocity в смыслах как скорости прироста, так и необходимости высокоскоростной обработки и получения результатов), многообразие (variety, в смысле возможности одновременной обработки различных типов структурированных и неструктурированных данных. • При этом относительно объема больших данных обычно придерживаются таких оценок: Big Data - от нескольких терабайт (тысяч гигабайт) до сотен терабайт; Extremely Big Data - свыше 1000 терабайт (т. е. свыше петабайта).


Образовательные программы • Большие данные в течение последнего десятилетия являются предметом изучения и развития в профессиональной среде специалистов по информатике, прикладной математике. В нашей стране в последние годы появились магистерские программы по технологиям больших данных, например, в МГУ (на ф-те вычислительной математики и кибернетики), СПб. ГУ, МФТИ, НИУ ВШЭ (на ф-тах компьютерных наук, бизнеса и менеджмента). Нередко эти программы развиваются при участии компаний – лидеров IT-индустрии.

Большие данные в исторических исследованиях. Правы ли те, кто говорит:

Из анонса магистерской программы по Большим Данным ВМК МГУ • Создание масштабируемых программ анализа больших разноструктурированных данных в распределенных кластерах, виртуальной и материализованной интеграции данных при создании посредников и хранилищ больших данных, выделения, сопоставления и слияния сущностей в массивных коллекциях неструктурированных и слабоструктурированных данных, а также применения в таких процессах методов статистического анализа и машинного обучения.

• Особое место в программе занимает освоение методов формулирования и решения задач в областях с интенсивным использованием данных, направленных на ускорение исследований и базирующихся на вышеперечисленных методах и инструментах оперирования большими данными. В результате студенты должны овладеть методами решения задач обнаружения аномалий в коллекциях больших данных, моделирования разнообразных явлений при проведении экспериментов, стимулированных гипотезами, извлечения информации из разнообразных коллекций больших данных в социальных средах.

Большие данные в исторических исследованиях • Сегодня можно говорить о том, что проблема анализа больших данных в исторических исследованиях уже возникла и в более широких масштабах заявит о себе в недалекой временной перспективе. Это частично зависит от того, какого определения мы придерживаемся. • Характерной особенностью таких исторических данных является не только огромный объем источников, лежащих в основе нескольких масштабных компаративных исследовательских проектов, реализуемых историками в составе международных коллабораций, но и вариативность этих источниковых комплексов, охватывающих тексты и статистику, визуальные и аудио материалы и т. д.
 IPUMS координируется Университетом Миннесота")
Проект IPUMS (Integrated Public Use Microdata Series) IPUMS координируется Университетом Миннесота

Проект IPUMS может рассматриваться как пример историкодемографического ресурса, обладающего признаками Big Data • К 2012 г. ресурс включал более 672 млн записей (персоналий). Это сведения из первичных листов 301 переписей населения 82 стран XIX – ХХ вв. Объем данных – несколько десятков терабайт. • Важная часть проекта связана с изучением переписей населения США. За последние 25 лет IPUMS получил 70 федеральных грантов и контрактов на общую сумму более $140 млн для изучения, интеграции и распространения собранных данных. Основное финансирование этих проектов было получено от Национальных институтов здравоохранения, Национального научного фонда и Управления по контролю за продуктами и лекарствами. IPUMS включает данные, полученные от широкого круга учреждений, включая Бюро переписей населения, Бюро статистики труда, Национальный научный фонд, Национальный центр статистики здравоохранения, Центры по контролю за заболеваниями и Национальное управление по аэронавтике и исследованию космического пространства.

Инфраструктура проекта • В сотрудничестве со 105 национальными статистическими агентствами, девятью национальными архивами и тремя генеалогическими организациями, IPUMS создал крупнейшую в мире доступную базу данных переписей на первичном уровне. Суммарно IPUMS включает почти миллиард записей из переписей США с 1790 года по настоящее время и более миллиарда записей из международных переписей более чем в 100 странах. • Эта работа опирается на обширную компьютерную инфраструктуру, разработанную в течение двух десятилетий, включая первую структурированную систему метаданных для интеграции разрозненных наборов данных. Используя подход хранения данных в русле Big Data, производится извлечение, преобразование и загрузка данных из разных источников в единую структуру представления, поэтому данные из разных источников становятся совместимыми.

IPUMS: использование технологий Big Data • Крупномасштабная интеграция данных в IPUMS делает тысячи наборов данных переписей населения сопоставимыми. Создано программное обеспечение для проверки согласованности, автоматической «очистки» и редактирования данных, контроля раскрытия информации, гармонизации базы данных, создания метаданных и анализа. • Проект используют технологию машинного обучения для автоматической классификации строк и привязки записей и использует параллельную обработку для управления большими наборами данных в созданной высокопроизводительной вычислительной среде. • Объем данных в проекте IPUMS непрерывно растет, поступают новые наборы материалов национальных переписей.
 • Проект направлен")
Проект CLARIAH (Common Lab Research Infrastructure for the Arts and Humanities) • Проект направлен на создание современной инфраструктуры гуманитарных наук и искусств, с использованием концепции Big Data (на базе института IISH, Амстердам) • Ставится задача привлечения не только больших объемов текстовых источников, аудио- и видеоматериалов, имиджей из газет и других изданий, записей телепрограмм и других медиаматериалов, но и произведений искусства (живописи, скульптуры и др. ). • Важной задачей является интеллектуальный поиск разнотипной релевантной информации и формирование поисковых запросов в целях содержательной интерпретации собранного материала.

Проект CLARIAH • Решение этих задач во многом должно обеспечиваться системой описания ресурсов RDF (Resource Description Framework), позволяющей связывать разнородные данные. RDF основана на идее делать заключения о вебресурсах в форме межкатегориальных связей «субъект — предикат — объект» . Эти связи (суждения) в рамках RDF известны как триплеты (triples). Такая формализация может быть применена к любым оцифрованным объектам, будь то записи в базе данных социально-экономического характера или оцифрованные газеты, или имиджи. • Что касается интеллектуального поиска текстовых материалов (text mining), то эта работа в рамках проекта находится на начальной стадии.

Проект CLARIAH • В проекте производится поиск оцифрованных газет, содержащих в глобальном измерении сведения о рабочих конфликтах в 1870– 1990 гг. При этом ставится задача извлечь из этих материалов следующие сведения (максимальный список данных): даты стачек; населенный пункт; тип конфликта; профессии участников; отрасль; названия вовлеченных предприятий и их число; половозрастной состав участников; длительность конфликта; организации, вовлеченные в конфликт; правовой статус события; источник данных. • Извлечение этих данных из неструктурированных источников потребует использования сложных алгоритмов и программ обработки текстов на естественном языке (предварительно распознанных — это непростая задача при работе с газетными материалами XIX — начала ХХ в. ).

Проект CLARIAH • Интерес представляет и другой запланированный раздел проекта: оцифровка большого массива травелогов — книг, написанных путешественниками (начиная с позднего Средневековья) и использование поисковых алгоритмов для выявления тех фрагментов текста, в которых путешественники затрагивали тему труда и трудовых отношений, а также восприятия людьми этих аспектов профессиональной деятельности. • Анализ таких материалов позволит на программном уровне выявить паттерны труда, их локализацию во времени и пространстве, их кластеризацию и эволюцию в глобальном измерении. Масштаб проекта, охват процессов на протяженных периодах и в глобализирующемся пространстве, привлечение огромных массивов разнородных данных — от структурированных до текстовых и медийных, долговременный мониторинг сетевых ресурсов с целью пополнения коллекции данных проекта позволяют говорить о перспективе использования методологии Big Data

Проект CLARIAH • В рамках проекта можно рассчитывать на то, что в данной проблематике (истории труда) можно будет получить новые ответы на старые вопросы, а может быть, поставить и новые вопросы, которые раньше не рассматривались ввиду отсутствия столь масштабной коллекции данных и новых компьютеризованных методов их обработки и анализа.
")
Проект Chronicling America: оцифровка 12 миллионов выпусков газет Америки (1690 -1963 г. )

Большие данные в задачах виртуальной реконструкции историко-культурного наследия ВИРТУАЛЬНАЯ РЕКОНСТРУКЦИЯ МОСКОВСКОГО СТРАСТНОГО МОНАСТЫРЯ (XVII - XX ВВ. ): КОМПЛЕКСНОЕ ИСПОЛЬЗОВАНИЕ ТЕХНОЛОГИЙ 3 D МОДЕЛИРОВАНИЯ Проект кафедры исторической информатики исторического факультета МГУ (поддержан грантом РНФ, 2014 -2016 гг. ) - Виртуальная реконструкция монастыря и прилежащей Страстной площади на трех временных срезах (1700 г. , 1830 г. , 1910 г. ). - Источниковая база: более 800 визуальных и текстовых исторических источников, включая чертежи и планы зданий, изображения, гравюры и картины XVIII - XIX вв. , фотографии XIX – ХХ вв. , описания монастырских построек, страховые ведомости и т. д. - Программное обеспечение: комплекс программ 3 D моделирования; ГИС-технологии. - Результаты проекта представлены на сайте исторического факультета МГУ: http: //www. hist. msu. ru/Strastnoy/ с обеспечением онлайн доступа к электронной документации проекта и верификацией 3 D моделей - Общий объем ресурса, включающего информацию различных форматов, модели с высоким разрешением – около 1 терабайта.
")
Процесс сборки сцены (срез 1830 г. )

i. Map Builder

Источники. Гравюра первой половины XIX в.

Archi. CAD 19
")
Страстной монастырь в период расцвета (вторая половина XIX века)


Пушкин смотрит на Страстной монастырь. 1892 г.

Разборка колокольни. 1937 г.

Пушкин повернулся спиной… 2014 г.

Реконструкции топографического плана Страстной площади с отметками высот от уровня моря

Аэрофотосъемка. 1937 г.

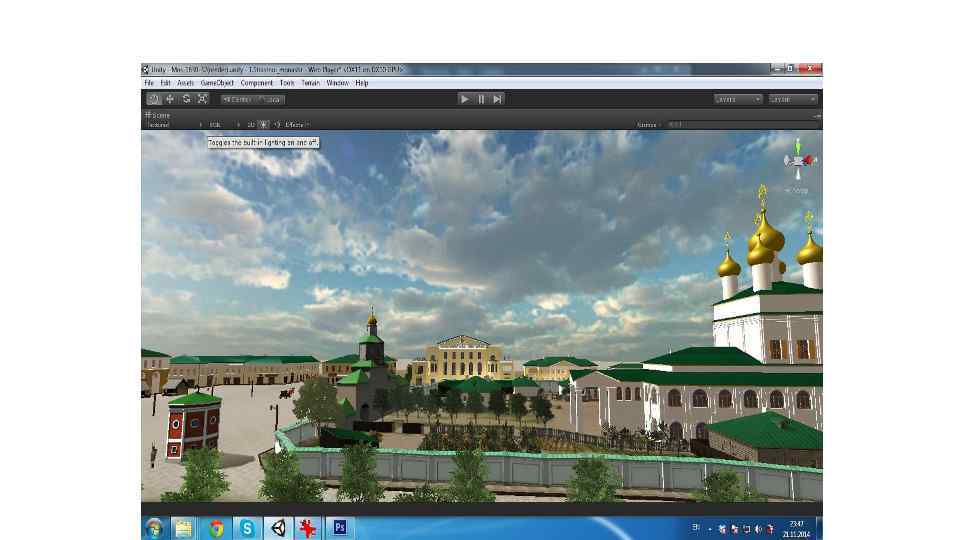
Результаты виртуальной реконструкции Страстного монастыря и Страстной площади
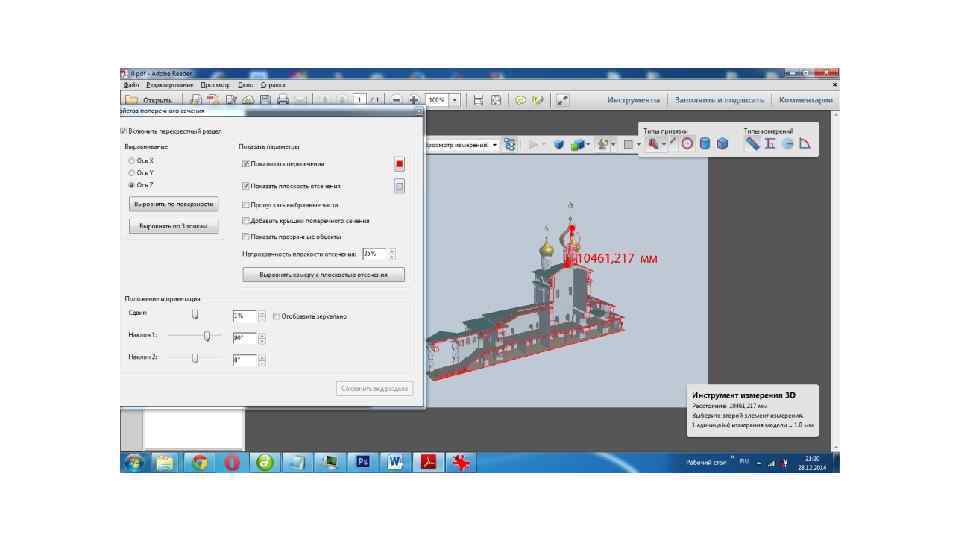





Points of camera position view from photo

Spatial analysis of photographs in Sketch. Up

Archi. CAD 19. Building history




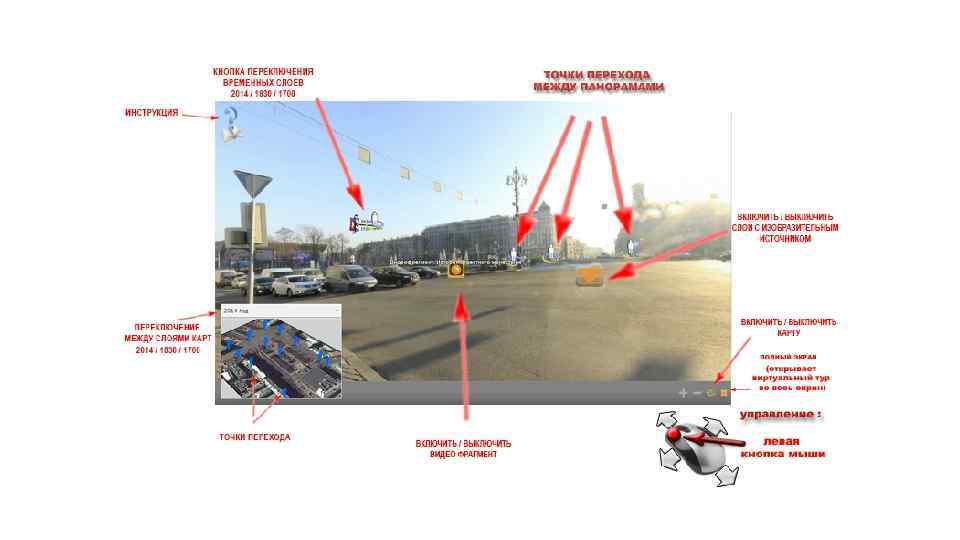
Модуль верификации/валидации 3 D моделей

Дополненная реальность



Thank you for your attention ! Contact details: Leonid Borodkin lborodkin@mail. ru Denis Zherebyatyev dzher@inbox. ru Faculty of History, Lomonosov Moscow State University Department of Historical Information Science
Презентация Бородкина.pptx