
Квесты рабочих групп Практика 5, 22. 11. 2014










- Размер: 1.1 Mегабайта
- Количество слайдов: 13
Описание презентации Квесты рабочих групп Практика 5, 22. 11. 2014 по слайдам
Квесты рабочих групп Практика 5, 22. 11. 2014 Алексей Натёкин
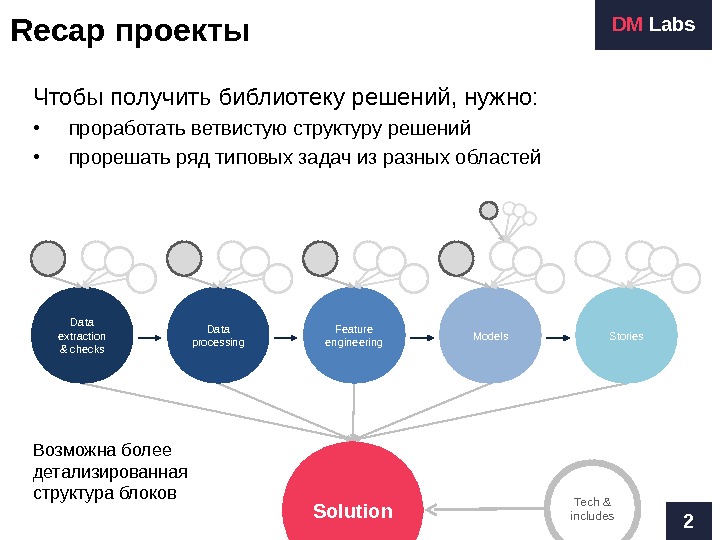
Recap проекты 2 DM Labs Чтобы получить библиотеку решений, нужно: • проработать ветвистую структуру решений • прорешать ряд типовых задач из разных областей Solution. Data extraction & checks Data processing Feature engineering Models Stories Tech & includes. Возможна более детализированная структура блоков
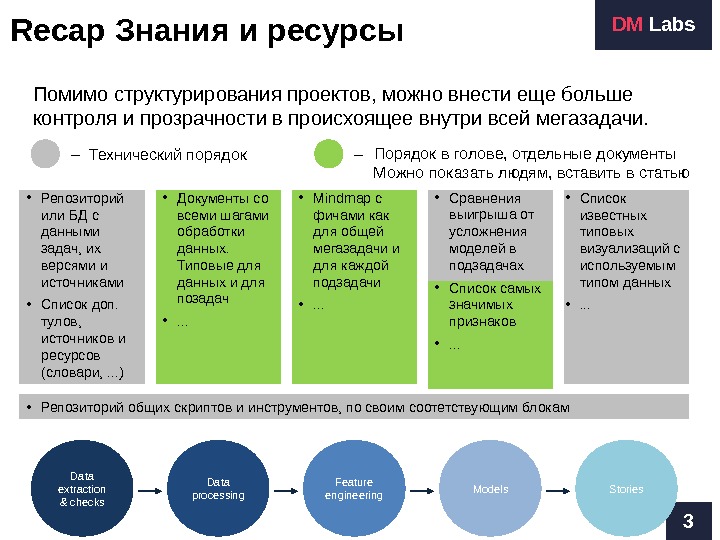
Recap Знания и ресурсы 3 DM Labs Помимо структурирования проектов, можно внести еще больше контроля и прозрачности в происхоящее внутри всей мегазадачи. Data extraction & checks Data processing Feature engineering Models Stories • Mindmap с фичами как для общей мегазадачи и для каждой подзадачи • . . . • Сравнения выигрыша от усложнения моделей в подзадачах • Список самых значимых признаков • . . . • Репозиторий или БД с данными задач, их версями и источниками • Список доп. тулов, источников и ресурсов (словари, . . . ) • Список известных типовых визуализаций с используемым типом данных • . . . • Документы со всеми шагами обработки данных. Типовые для данных и для позадач • . . . – Технический порядок Порядок в голове, отдельные документы Можно показать людям, вставить в статью – • Репозиторий общих скриптов и инструментов, по своим соотетствующим блокам
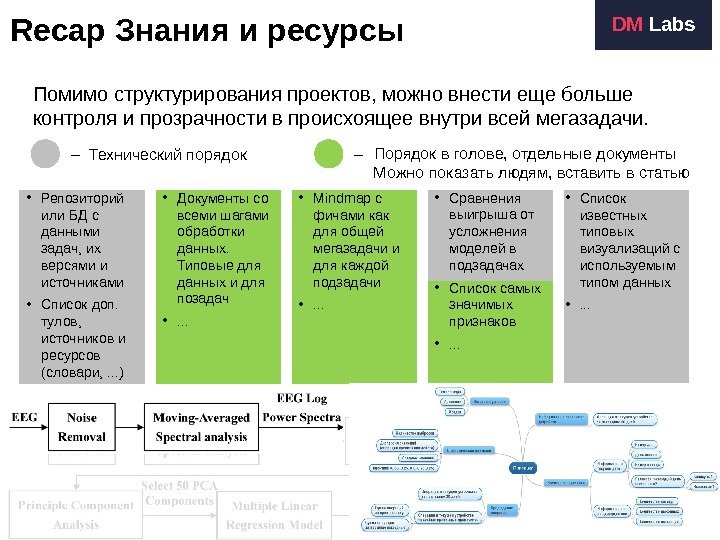
Recap Знания и ресурсы 4 DM Labs Помимо структурирования проектов, можно внести еще больше контроля и прозрачности в происхоящее внутри всей мегазадачи. Data extraction & checks Data processing Feature engineering Models Stories • Mindmap с фичами как для общей мегазадачи и для каждой подзадачи • . . . • Сравнения выигрыша от усложнения моделей в подзадачах • Список самых значимых признаков • . . . • Репозиторий или БД с данными задач, их версями и источниками • Список доп. тулов, источников и ресурсов (словари, . . . ) • Список известных типовых визуализаций с используемым типом данных • . . . • Документы со всеми шагами обработки данных. Типовые для данных и для позадач • . . . – Технический порядок Порядок в голове, отдельные документы Можно показать людям, вставить в статью –
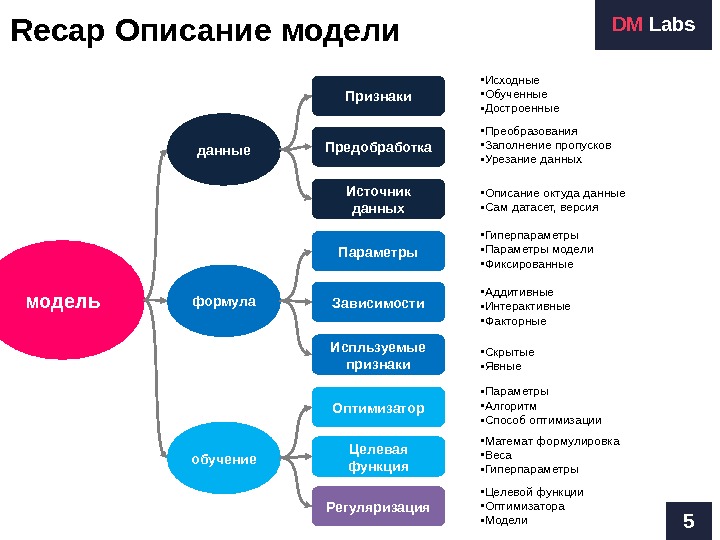
Recap Описание модели 5 DM Labs модель формула обучение данные Источник данных. Признаки Предобработка Регуляризация Оптимизатор Целевая функция. Испльзуемые признаки. Параметры Зависимости • Описание октуда данные • Сам датасет, версия • Преобразования • Заполнение пропусков • Урезание данных • Исходные • Обученные • Достроенные • Скрытые • Явные • Аддитивные • Интерактивные • Факторные • Гиперпараметры • Параметры модели • Фиксированные • Целевой функции • Оптимизатора • Модели • Параметры • Алгоритм • Способ оптимизации • Математ формулировка • Веса • Гиперпараметры
Квесты 6 DM Labs
Image++ 7 DM Labs Функции, инфраструктура, . . . : 1. Оформить генерацию признаков в файлы 2. Генерация признаков к-средними. Можно потестировать на MNIST Визуализация: 1. Сделать из sunburst инструмент валидации – чтобы был список галактик, а sunburst показывал какую он куда относит 2. Плюшки – 2 режима: распределение классов и ошибки 3. Если будет время: доделать цвета, подписи. Можно сделать очень крутую реюзабельную вещь Результаты: 1. Запустить модели на гистограммах. Разобрать xgboost 2. Запустить модели на к-средних 3. Совместить графику и результаты 4. . клевые идеи по к-средним?
Text regression 8 DM Labs Функции, инфраструктура, . . . : 1. Базовая предобработка: стемминг, не-редкие биграммы 2. Извлечение частей речи ( POS-tagging). Смотрите внешние тулы 3. До-собирать данные по акциям 4. Распарсить SEC до нужной секции Визуализация: 1. Самые значимые слова и биграммы 2. Динамику акций против слов – цветные wordcloud’ ы? 3. . эксперименты с вытаскиванием графов слов ( Gephi) Результаты: 1. Запустить kaggle ASAP, запустить SEC- волатильность 2. Сравнить с baseline моделями и там 3. Объяснение того, что у вас получилось (что это все значит? ) 4. . идеи, предложения как это улучшить?
Text clustering/Mindmap 9 DM Labs Функции, инфраструктура, . . . : 1. Скооперироваться с text regression группой 2. Отобрать релевантные вещи для кандидатов в слова mindmap 3. Попробовать алгоритм извлечения устойчивых кластеров: бутстрап lda меток + их matching. «Срезание верхушек холмов» . Можно потренироваться на 2 D гауссианах 4. Разобраться с perplexity и оценкой качества lda 5. Отбор наиболее значимых слов: lasso, выкидывание слов Визуализация: 1. Сначала просто выводить в текстовый файл списки слов\биграмм по кластерам (с отступами=глубине – как списки) 2. Попробовать сделать так: http: // bl. ocks. org/mbostock/4063550 Результаты: 1. Несколько визуализированных майндмепов
SNA 10 DM Labs Функции, инфраструктура, . . . : 1. Простая функция — собирает эго-сеть пользователя: • Граф (пары узлов) • Ключевая информация по узлам (базовая инфа о юзере) 2. Cool-story функция – сбор эго-сети для закрытого списка друзей Данные: 1. Собрать 10 покончивших с собой (больше – лучше) 2. Собрать целиком группу из хотябы 1000 интересующихся этим 3. Собрать участников нашей группы dmtrack 2014 Результаты: 1. Запущенные модели, восстанавливающие возраст 2. Посчитанные ключевые характеристики графов ( igraph/gephi). . . 3. . Графики распределений метрик для всех: самоубийц. Может быть удастся найти кластера
EXG (больше про EEG) 11 DM Labs Функции, инфраструктура, . . . : 1. Генерация csv из matlab/… в отдельные файлы 2. Извлечение и предобработка: фильтры ( MA, …), FFT спектры, ICA 3. Временные вложения (как в SSA) 4. . Визуализация: 1. Linechart’ ы с исходными сигналами ( x vs t), цвет – класс 2. Event-studies: как меняются профили сигналов до и после событий 3. Графики с проекциями от ICA, PCA, … 4. . Результаты: 1. Несколько «поколений» решений задач 2. Как разные «слои» моделей влияют на ваши результаты?
Спорт прогнозы 12 DM Labs Функции, инфраструктура, . . . : 1. Единый репозиторий данных 2. Извлечение признаков: командные, игроков. Сперва простые: количество побед за N матчей назад, количество игр за N дней назад, количество игр с таким составом из последних N игр, сколько новичков\восстановившихся в игре, сколько «ветеранов» 3. Больше признаков для бога признаков 4. Как решать задачу – классификация (чего для чего? ), что-то еще? Визуализация: 1. Базовые сравнения распределений построенных признаков по командам, по статусу (победил\проиграл), игроки-талисманы 2. Проекции построенных признаков Результаты: 1. Запущенные модели 2. Profitability моделей (маленький торговый робот)
Алексей Натёкин natekin@dmlabs. org 13 DM Labs Спасибо!