

Корпуса_доклад.ppt
- Количество слайдов: 46
 Корпусы русского языка: история и перспективы А. А. Степихов, Санкт-Петербургский государственный университет Донецк, 21 ноября 2013 года
Корпусы русского языка: история и перспективы А. А. Степихов, Санкт-Петербургский государственный университет Донецк, 21 ноября 2013 года
 корпусов с помощью компьютерных технологий.") Корпусная лингвистика разработка, создание и использование текстовых (лингвистических) корпусов с помощью компьютерных технологий.
Корпусная лингвистика разработка, создание и использование текстовых (лингвистических) корпусов с помощью компьютерных технологий.
 Языковой корпус – это собрание текстов, представленное в электронной форме и снабженное научным аппаратом – разметкой, или аннотацией. Качество корпуса зависит от: а) полноты самого корпуса (разные типы текстов, письменная и устная речь); б) полноты его аннотации.
Языковой корпус – это собрание текстов, представленное в электронной форме и снабженное научным аппаратом – разметкой, или аннотацией. Качество корпуса зависит от: а) полноты самого корпуса (разные типы текстов, письменная и устная речь); б) полноты его аннотации.
 tagging); n синтаксическая (parsing);") Лингвистическая аннотация Виды разметок: n морфологическая (part of speech (POS) tagging); n синтаксическая (parsing); n семантическая (semantic tagging); n метатекстовая (metadata tagging) – приписывание тексту определенного набора признаков (сфера функционирования, тип текста, тематика текста и пр. ). ; n сохраняющая – отражение стяжек (тыща), растяжек (вооот), игровых форм (хоккей в зн. о’кей), диалектизмов (кажный), иностранного акцента (слюшай); n социологическая (пол, возраст).
Лингвистическая аннотация Виды разметок: n морфологическая (part of speech (POS) tagging); n синтаксическая (parsing); n семантическая (semantic tagging); n метатекстовая (metadata tagging) – приписывание тексту определенного набора признаков (сфера функционирования, тип текста, тематика текста и пр. ). ; n сохраняющая – отражение стяжек (тыща), растяжек (вооот), игровых форм (хоккей в зн. о’кей), диалектизмов (кажный), иностранного акцента (слюшай); n социологическая (пол, возраст).
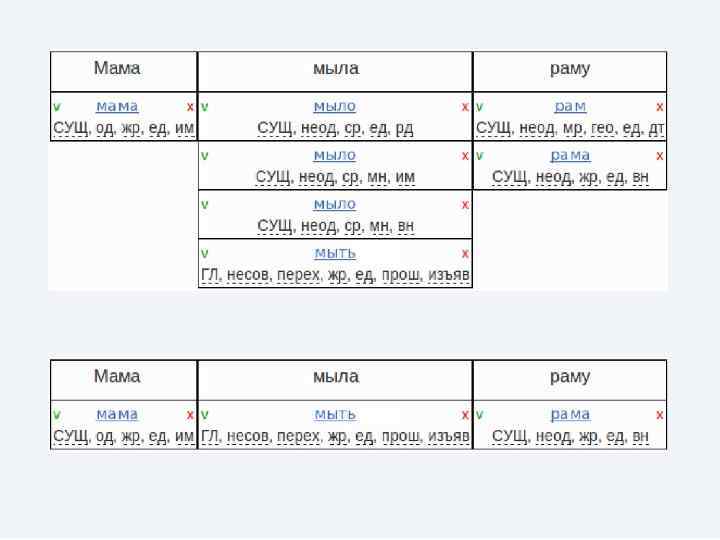
 Пример морфологической разметки <…> учитель постоянно использует <…>: [использовать = V, ipf, tran = sg, act, praes, 3 p, indic]
Пример морфологической разметки <…> учитель постоянно использует <…>: [использовать = V, ipf, tran = sg, act, praes, 3 p, indic]
 Пример синтаксической разметки в виде дерева зависимостей
Пример синтаксической разметки в виде дерева зависимостей
 Применение языкового корпуса n n Решение лингвистических задач; наблюдение за динамикой развития языка; Оптимизация систем автоматического поиска и автоматической обработки текстов; Преподавание языка (прежде всего как иностранного); Журналистская и редакторская деятельность.
Применение языкового корпуса n n Решение лингвистических задач; наблюдение за динамикой развития языка; Оптимизация систем автоматического поиска и автоматической обработки текстов; Преподавание языка (прежде всего как иностранного); Журналистская и редакторская деятельность.
 Лингвистические задачи, решаемые с помощью корпусных данных: n n n Изучение морфологических вариантов и их эволюции; Исследование словообразовательных возможностей языка; Изучение изменений в синтаксических связях; Изучение развития системы словесного ударения; Исследование словоупотребления, лексической вариативности и смысловых отношений внутри синонимических рядов и других лексических групп.
Лингвистические задачи, решаемые с помощью корпусных данных: n n n Изучение морфологических вариантов и их эволюции; Исследование словообразовательных возможностей языка; Изучение изменений в синтаксических связях; Изучение развития системы словесного ударения; Исследование словоупотребления, лексической вариативности и смысловых отношений внутри синонимических рядов и других лексических групп.
 Предыстория 1960 -70 -е гг. : работа над «Частотным словарем русского языка» под ред. Лидии Николаевны Засориной (издан в 1977). Составители – коллектив филологического факультета ЛГУ и Лаборатории семиотики НИИ прикладной математики и кибернетики при Горьковском госуниверситете.
Предыстория 1960 -70 -е гг. : работа над «Частотным словарем русского языка» под ред. Лидии Николаевны Засориной (издан в 1977). Составители – коллектив филологического факультета ЛГУ и Лаборатории семиотики НИИ прикладной математики и кибернетики при Горьковском госуниверситете.
. Впервые –") «Частотный словарь русского языка» База данных – 1 млн. словоупотреблений (tokens). Впервые – работа над решением ключевых проблем корпусной лингвистики: n представительность (объем, структура); n токенизация (разбиение на орфографические слова, или словоформы); n лемматизация (приведение словоформ к словарной форме).
«Частотный словарь русского языка» База данных – 1 млн. словоупотреблений (tokens). Впервые – работа над решением ключевых проблем корпусной лингвистики: n представительность (объем, структура); n токенизация (разбиение на орфографические слова, или словоформы); n лемматизация (приведение словоформ к словарной форме).
 1980 -е гг. : проект «Машинный фонд русского языка» Инициатор – акад. Андрей Петрович Ершов (1931 -1988). Фонд должен был включать: n словарный состав русского языка; n базы данных различных словарей; n терминологическую базу данных; n информационную систему по русской грамматике; n иные подсистемы (фонетическую, диалектную, словарный состав различных периодов развития русского языка); n коллекцию текстов, т. е. корпус. Над созданием работало более 40 организаций.
1980 -е гг. : проект «Машинный фонд русского языка» Инициатор – акад. Андрей Петрович Ершов (1931 -1988). Фонд должен был включать: n словарный состав русского языка; n базы данных различных словарей; n терминологическую базу данных; n информационную систему по русской грамматике; n иные подсистемы (фонетическую, диалектную, словарный состав различных периодов развития русского языка); n коллекцию текстов, т. е. корпус. Над созданием работало более 40 организаций.
 n n 600") 1980 -е гг. : «Уппсальский корпус русских текстов» (Уппсальский университет, Швеция) n n 600 текстов (художественная проза 19601988 гг. и публицистика 1985 -1989 гг. ); 1 млн. словоупотреблений; лемматизация и морфологическая разметка отсутствовала; тексты представлены в латинице.
1980 -е гг. : «Уппсальский корпус русских текстов» (Уппсальский университет, Швеция) n n 600 текстов (художественная проза 19601988 гг. и публицистика 1985 -1989 гг. ); 1 млн. словоупотреблений; лемматизация и морфологическая разметка отсутствовала; тексты представлены в латинице.
 1999 -2000 -е гг. : Тюбингенский корпус русского языка Создавался в рамках междисциплинарной исследовательской программы «Лингвистические структуры данных. Теоретические и эмпирические основы грамматического исследования» . Руководитель проекта – профессор Тюбингенского университета Тильман Бергер. Первый корпус русского языка в Интернете.
1999 -2000 -е гг. : Тюбингенский корпус русского языка Создавался в рамках междисциплинарной исследовательской программы «Лингвистические структуры данных. Теоретические и эмпирические основы грамматического исследования» . Руководитель проекта – профессор Тюбингенского университета Тильман Бергер. Первый корпус русского языка в Интернете.
 1999 -2000 -е гг. : Тюбингенский корпус русского языка Состав корпуса: n Уппсальский корпус; n Подкорпус интервью из газет и журналов, свободно доступных в Интернете, а также с радио «Эхо Москвы» (с 1996 г. ). Объем – 290 тыс. словоупотреблений. n Подкорпус статей из журнала «Огонёк» (19962002). Объем – 9, 2 млн. словоупотреблений; n Подкорпус текстов художественной литературы ХIХ-ХХ веков. Объем – более 14 млн. словоупотреблений.
1999 -2000 -е гг. : Тюбингенский корпус русского языка Состав корпуса: n Уппсальский корпус; n Подкорпус интервью из газет и журналов, свободно доступных в Интернете, а также с радио «Эхо Москвы» (с 1996 г. ). Объем – 290 тыс. словоупотреблений. n Подкорпус статей из журнала «Огонёк» (19962002). Объем – 9, 2 млн. словоупотреблений; n Подкорпус текстов художественной литературы ХIХ-ХХ веков. Объем – более 14 млн. словоупотреблений.
 2000 -2002 гг. : Корпус газетных текстов n n n Создавался в Лаборатории общей и компьютерной лексикологии и лексикографии филологического факультета МГУ. Полные тексты 13 российских газет 19941997 гг. различной тематики, географии издания и политической направленности. Объем – 11 млн. словоупотреблений.
2000 -2002 гг. : Корпус газетных текстов n n n Создавался в Лаборатории общей и компьютерной лексикологии и лексикографии филологического факультета МГУ. Полные тексты 13 российских газет 19941997 гг. различной тематики, географии издания и политической направленности. Объем – 11 млн. словоупотреблений.
 Хельсинский АНнотированный КОрпус – ХАНКО Отделение славянских языков и литератур Хельсинского университета. Создание корпуса мыслится как часть проекта «Контрастивный функциональный синтаксис» .
Хельсинский АНнотированный КОрпус – ХАНКО Отделение славянских языков и литератур Хельсинского университета. Создание корпуса мыслится как часть проекта «Контрастивный функциональный синтаксис» .
 Руководитель – профессор Арто Мустайоки
Руководитель – профессор Арто Мустайоки
 Хельсинский АНнотированный КОрпус ХАНКО Материал – все крупные статьи из журнала «Итоги» за январь 2001 года. Общий объем – 100 тыс. словоупотреблений.
Хельсинский АНнотированный КОрпус ХАНКО Материал – все крупные статьи из журнала «Итоги» за январь 2001 года. Общий объем – 100 тыс. словоупотреблений.
 ХАНКО: Принципы создания n n n Направленность на широкой круг пользователей (студенты, учителя русского языка и др. ); Максимальный охват грамматической информации; Многоуровневость грамматической информации (морфологическая, синтаксическая, функционально-семантическая); Учет многокомпонентных единиц (аналитические формы, составные числительные, неоднословные сочетания, эквивалентные слову); Отражение вариантов грамматической интерпретации.
ХАНКО: Принципы создания n n n Направленность на широкой круг пользователей (студенты, учителя русского языка и др. ); Максимальный охват грамматической информации; Многоуровневость грамматической информации (морфологическая, синтаксическая, функционально-семантическая); Учет многокомпонентных единиц (аналитические формы, составные числительные, неоднословные сочетания, эквивалентные слову); Отражение вариантов грамматической интерпретации.
 С 2003 года: Национальный корпус русского языка
С 2003 года: Национальный корпус русского языка
 Национальный корпус русского языка: Подкорпусы n Основной корпус: письменные тексты с сер. XVIII века до настоящего времени. Художественная литература, мемуары, эссеистика, публицистика, научнопопулярная и научная литература, публичные выступления, частная переписка, дневники, документы и т. п. Объем – 230 млн. словоупотреблений.
Национальный корпус русского языка: Подкорпусы n Основной корпус: письменные тексты с сер. XVIII века до настоящего времени. Художественная литература, мемуары, эссеистика, публицистика, научнопопулярная и научная литература, публичные выступления, частная переписка, дневники, документы и т. п. Объем – 230 млн. словоупотреблений.
 Национальный корпус русского языка: Подкорпусы n Корпус устной речи: расшифровки записей публичной и частной устной речи, а также транскрипты кинофильмов. Период охвата – 1930 -2007 гг. ; n Синтаксический (глубоко аннотированный) корпус: для каждого предложения построена полная морфологическая и синтаксическая структура (дерево зависимостей);
Национальный корпус русского языка: Подкорпусы n Корпус устной речи: расшифровки записей публичной и частной устной речи, а также транскрипты кинофильмов. Период охвата – 1930 -2007 гг. ; n Синтаксический (глубоко аннотированный) корпус: для каждого предложения построена полная морфологическая и синтаксическая структура (дерево зависимостей);
: статьи из средств") Национальный корпус русского языка: Подкорпусы n Газетный корпус (корпус современных СМИ): статьи из средств массовой информации 1990 -2000 -х годов; n Параллельные корпуса (двуязычные (русский и английский, немецкий, французский, испанский, итальянский, польский, украинский, белорусский языки) и многоязычный);
Национальный корпус русского языка: Подкорпусы n Газетный корпус (корпус современных СМИ): статьи из средств массовой информации 1990 -2000 -х годов; n Параллельные корпуса (двуязычные (русский и английский, немецкий, французский, испанский, итальянский, польский, украинский, белорусский языки) и многоязычный);
 Национальный корпус русского языка: Подкорпусы n Корпус диалектных текстов: запись диалектной речи различных регионов России с сохранением их грамматической специфики; предусмотрен поиск с учётом диалектной морфологии; n Поэтический корпус: поэзия 1750 -1890 -е гг. , тексты некоторых поэтов ХХ века; возможен поиск по специфическим для стиха признакам (определённое сочетание, определённый тип рифмовки и т. п. );
Национальный корпус русского языка: Подкорпусы n Корпус диалектных текстов: запись диалектной речи различных регионов России с сохранением их грамматической специфики; предусмотрен поиск с учётом диалектной морфологии; n Поэтический корпус: поэзия 1750 -1890 -е гг. , тексты некоторых поэтов ХХ века; возможен поиск по специфическим для стиха признакам (определённое сочетание, определённый тип рифмовки и т. п. );
 Национальный корпус русского языка: Подкорпусы Обучающий корпус: корпус со снятой омонимией, разметка которого ориентирована на школьную программу русского языка. Объем – 1 млн. словоупотреблений. Доступен для скачивания; n Акцентологический корпус (корпус истории русского ударения): тексты, несущие информацию об истории русского ударения (все тексты поэтического корпуса и акцентуированные записи устной речи, в том числе кинофильмов); n
Национальный корпус русского языка: Подкорпусы Обучающий корпус: корпус со снятой омонимией, разметка которого ориентирована на школьную программу русского языка. Объем – 1 млн. словоупотреблений. Доступен для скачивания; n Акцентологический корпус (корпус истории русского ударения): тексты, несущие информацию об истории русского ударения (все тексты поэтического корпуса и акцентуированные записи устной речи, в том числе кинофильмов); n
: снабжённые видео- и аудиорядом") Национальный корпус русского языка: Подкорпусы n Мультимедийный русский корпус (МУРКО): снабжённые видео- и аудиорядом транскрипты кинофильмов 1930 -2000 -х годов. Возможен поиск по жестам и типу речевого действия (согласие, ирония и т. п. ). Объем – 3 млн. словоупотреблений. Общий объем НКРЯ – 500 млн. словоупотреблений.
Национальный корпус русского языка: Подкорпусы n Мультимедийный русский корпус (МУРКО): снабжённые видео- и аудиорядом транскрипты кинофильмов 1930 -2000 -х годов. Возможен поиск по жестам и типу речевого действия (согласие, ирония и т. п. ). Объем – 3 млн. словоупотреблений. Общий объем НКРЯ – 500 млн. словоупотреблений.
 Форма грамматического поиска в НКРЯ
Форма грамматического поиска в НКРЯ
 Пример формы семантического поиска
Пример формы семантического поиска
 НКРЯ: Studiorum
НКРЯ: Studiorum
 http: //dict. ruslang. ru/
http: //dict. ruslang. ru/
 http: //dict. ruslang. ru/ n n Грамматический словарь новых слов русского языка (Е. А. Гришина, О. Н. Ляшевская). Новый частотный словарь русской лексики (О. Н. Ляшевская, С. А. Шаров), Словарь русской идиоматики. Сочетания слов со значением высокой степени (Г. И. Кустова). Словарь глагольной сочетаемости непредметных имен русского языка (О. Л. Бирюк, В. Ю. Гусев, Е. Ю. Калинина).
http: //dict. ruslang. ru/ n n Грамматический словарь новых слов русского языка (Е. А. Гришина, О. Н. Ляшевская). Новый частотный словарь русской лексики (О. Н. Ляшевская, С. А. Шаров), Словарь русской идиоматики. Сочетания слов со значением высокой степени (Г. И. Кустова). Словарь глагольной сочетаемости непредметных имен русского языка (О. Л. Бирюк, В. Ю. Гусев, Е. Ю. Калинина).
 Авторы: В. А. Плунгян, Е. В. Рахилина, Е. В. Падучева, М. Д. Воейкова, Ю. П. Князев, В. И. Подлесская, Д. В. Сининава, Я. Г. Тестелец. . . rusgram. ru
Авторы: В. А. Плунгян, Е. В. Рахилина, Е. В. Падучева, М. Д. Воейкова, Ю. П. Князев, В. И. Подлесская, Д. В. Сининава, Я. Г. Тестелец. . . rusgram. ru
 2009 г. spokencorpora. ru
2009 г. spokencorpora. ru
 http: //testsynt.") Русский язык: Тестовый корпус с параллельной синтаксической разметкой: Russian Syntax Treebank (RSTB) http: //testsynt. soiza. com/
Русский язык: Тестовый корпус с параллельной синтаксической разметкой: Russian Syntax Treebank (RSTB) http: //testsynt. soiza. com/
 http: //testsynt.") Русский язык: Тестовый корпус с параллельной синтаксической разметкой: Russian Syntax Treebank (RSTB) http: //testsynt. soiza. com/ Результаты разбора 64800 предложений (1 млн словоупотреблений) автоматическими системами синтаксического анализа: • Synt. Atom, Синтаксическое представление в • Sem. Sin, виде деревьев зависимостей. • Russian Malt Узлами дерева являются слова предложения. • ЭТАП-3. Материал: тексты разных жанров, включая научную и художественную литературу, а также тексты новостных сообщений.
Русский язык: Тестовый корпус с параллельной синтаксической разметкой: Russian Syntax Treebank (RSTB) http: //testsynt. soiza. com/ Результаты разбора 64800 предложений (1 млн словоупотреблений) автоматическими системами синтаксического анализа: • Synt. Atom, Синтаксическое представление в • Sem. Sin, виде деревьев зависимостей. • Russian Malt Узлами дерева являются слова предложения. • ЭТАП-3. Материал: тексты разных жанров, включая научную и художественную литературу, а также тексты новостных сообщений.
 Образец вариантов синтаксической разметки в виде дерева зависимостей
Образец вариантов синтаксической разметки в виде дерева зависимостей
 Образец вариантов синтаксической разметки в виде таблиц
Образец вариантов синтаксической разметки в виде таблиц
: opencorpora. org Цель проекта – создание морфологически,") 2009: Открытый корпус русского языка (Open Corpora): opencorpora. org Цель проекта – создание морфологически, синтаксически и семантически размеченного корпуса текстов на русском языке, доступного для исследователей и редактируемого пользователями. Планируемый объем – 1 млн слов. Принцип: Нашел ошибку – исправь!
2009: Открытый корпус русского языка (Open Corpora): opencorpora. org Цель проекта – создание морфологически, синтаксически и семантически размеченного корпуса текстов на русском языке, доступного для исследователей и редактируемого пользователями. Планируемый объем – 1 млн слов. Принцип: Нашел ошибку – исправь!
 opencorpora. org") 2009: Открытый корпус русского языка (Open Corpora) opencorpora. org
2009: Открытый корпус русского языка (Open Corpora) opencorpora. org
 Диахронические корпуса русского языка n n Регенсбургский диахронический корпус русского языка: http: //www-korpus. uni-r. de/diakorp/ Санкт-Петербургский корпус агиографических текстов (СКАТ): http: //project. phil. spbu. ru/scat/ Берестяные грамоты: gramoty. ru Манускрипт (коллекции древнейших и средневековых славянских и русских текстов): mns. udsu. ru
Диахронические корпуса русского языка n n Регенсбургский диахронический корпус русского языка: http: //www-korpus. uni-r. de/diakorp/ Санкт-Петербургский корпус агиографических текстов (СКАТ): http: //project. phil. spbu. ru/scat/ Берестяные грамоты: gramoty. ru Манускрипт (коллекции древнейших и средневековых славянских и русских текстов): mns. udsu. ru
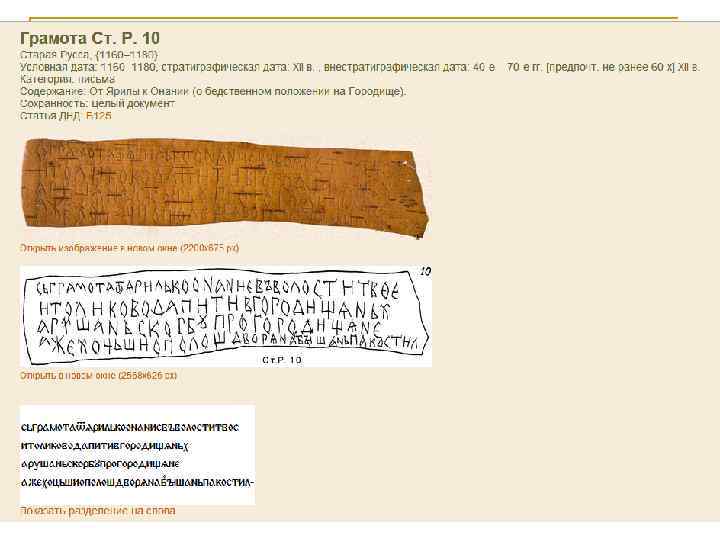
 Корпус «Древнерусские берестяные грамоты»
Корпус «Древнерусские берестяные грамоты»
; Кембриджский") Корпус «Древнерусские берестяные грамоты» . Коллективы: n n n n Лейденский университет (Нидерланды); Кембриджский университет (Великобритания); Университет Хельсинки (Финляндия); Московский государственный университет; Институт славяноведения РАН; Институт русского языка РАН; Новгородский государственный объединенный музей-заповедник.
Корпус «Древнерусские берестяные грамоты» . Коллективы: n n n n Лейденский университет (Нидерланды); Кембриджский университет (Великобритания); Университет Хельсинки (Финляндия); Московский государственный университет; Институт славяноведения РАН; Институт русского языка РАН; Новгородский государственный объединенный музей-заповедник.
 n n Удмуртский государственный университет; Ижевский государственный технический университет. http: //mns. udsu. ru/
n n Удмуртский государственный университет; Ижевский государственный технический университет. http: //mns. udsu. ru/
 Перспективы корпусной лингвистики в России n n Исследование словаря, грамматического строя и тенденций развития русского языка; Совершенствование систем автоматической грамматической и семантической разметки текстов; Расширение объема данных; Создание частных корпусов (звуковые корпуса, корпуса артикуляций и пр. ).
Перспективы корпусной лингвистики в России n n Исследование словаря, грамматического строя и тенденций развития русского языка; Совершенствование систем автоматической грамматической и семантической разметки текстов; Расширение объема данных; Создание частных корпусов (звуковые корпуса, корпуса артикуляций и пр. ).