

03 ЭК_Презентация_Лекция 3.ppt
- Количество слайдов: 122
 Источники и средства поиска информации в Интернете
Источники и средства поиска информации в Интернете
; n продавцы информации (vendors,") Основными участниками рынка информационных услуг являются: n производители информации (producers); n продавцы информации (vendors, Вендоры); n пользователи информации (users) или подписчики (subscribers).
Основными участниками рынка информационных услуг являются: n производители информации (producers); n продавцы информации (vendors, Вендоры); n пользователи информации (users) или подписчики (subscribers).
 и") n Основу обслуживания пользователей информации составляют услуги, связанные с передачей информации (информационный транзит) и с предоставлением в пользование информационных ресурсов.
n Основу обслуживания пользователей информации составляют услуги, связанные с передачей информации (информационный транзит) и с предоставлением в пользование информационных ресурсов.
 n Пользователи - граждане, органы государственной власти, органы местного самоуправления, организации и общественные объединения. n К пользователям относят как конечных потребителей информации, так и промежуточных, оказывающих своим клиентам услуги при решении информационных задач (специальные информационные центры, имеющие доступ к нескольким онлайн системам, или специалисты-профессионалы, занимающиеся платным информационным обслуживанием клиентов, потребителей информации).
n Пользователи - граждане, органы государственной власти, органы местного самоуправления, организации и общественные объединения. n К пользователям относят как конечных потребителей информации, так и промежуточных, оказывающих своим клиентам услуги при решении информационных задач (специальные информационные центры, имеющие доступ к нескольким онлайн системам, или специалисты-профессионалы, занимающиеся платным информационным обслуживанием клиентов, потребителей информации).
 n Владельцы информационных ресурсов обеспечивают пользователей информацией из информационных ресурсов на основе законодательства, уставов указанных органов и организаций, положений, а также договоров.
n Владельцы информационных ресурсов обеспечивают пользователей информацией из информационных ресурсов на основе законодательства, уставов указанных органов и организаций, положений, а также договоров.
 n Наиболее распространенным средством доступа к информационным ресурсам являются компьютерные сети, а способом получения информации выступает режим онлайн.
n Наиболее распространенным средством доступа к информационным ресурсам являются компьютерные сети, а способом получения информации выступает режим онлайн.
 n Создание эффективной системы, которая позволяла бы работать с достаточной скоростью, оперируя огромным кол-вом документов помимо больших затрат и персонала для ее обслуживания, требует также и значительных расходов на маркетинг, по привлечению подписчиков к своей системе. Поэтому далеко не все производители информации могут создавать и поддерживать онлайновые системы. Эти функции берут на себя Вендоры (продавцы информации).
n Создание эффективной системы, которая позволяла бы работать с достаточной скоростью, оперируя огромным кол-вом документов помимо больших затрат и персонала для ее обслуживания, требует также и значительных расходов на маркетинг, по привлечению подписчиков к своей системе. Поэтому далеко не все производители информации могут создавать и поддерживать онлайновые системы. Эти функции берут на себя Вендоры (продавцы информации).
 – n LEXIS-NEXIS n QUESTEL-ORBIT n") крупные Вендоры : DUN & BRADSTREET (D&B) – n LEXIS-NEXIS n QUESTEL-ORBIT n
крупные Вендоры : DUN & BRADSTREET (D&B) – n LEXIS-NEXIS n QUESTEL-ORBIT n
 Информационный поиск
Информационный поиск
 n Термин «информационный поиск» был впервые введён Кельвином Муром в 1948") Information retrieval (IR) n Термин «информационный поиск» был впервые введён Кельвином Муром в 1948 в его докторской диссертации, опубликован и употребляется в литературе с 1950.
Information retrieval (IR) n Термин «информационный поиск» был впервые введён Кельвином Муром в 1948 в его докторской диссертации, опубликован и употребляется в литературе с 1950.
") Информационный поиск n Поиск информации представляет собой процесс выявления в некотором множестве документов (текстов) всех тех, которые посвящены указанной теме (предмету), удовлетворяют заранее определенному условию поиска (запросу) или содержат необходимые (соответствующие информационной потребности) факты, сведения, данные.
Информационный поиск n Поиск информации представляет собой процесс выявления в некотором множестве документов (текстов) всех тех, которые посвящены указанной теме (предмету), удовлетворяют заранее определенному условию поиска (запросу) или содержат необходимые (соответствующие информационной потребности) факты, сведения, данные.

, так и") РОМИП n По проблеме оценки качества проводятся конференции как на международном (TREC), так и на российском (РОМИП) уровне, существуют общепринятые тестовые наборы и открытые результаты качества различных информационных систем на этих наборах
РОМИП n По проблеме оценки качества проводятся конференции как на международном (TREC), так и на российском (РОМИП) уровне, существуют общепринятые тестовые наборы и открытые результаты качества различных информационных систем на этих наборах
 РОМИП Российский семинар по Оценке Методов Информационного Поиска n http: //romip. ru/ n
РОМИП Российский семинар по Оценке Методов Информационного Поиска n http: //romip. ru/ n
 РОМИП n Целью семинара является создание плацдарма для проведения независимой оценки методов информационного поиска, ориентированных на работу с русскоязычной информацией, а также консолидация сообщества российских исследователей и разработчиков, занимающихся информационным поиском.
РОМИП n Целью семинара является создание плацдарма для проведения независимой оценки методов информационного поиска, ориентированных на работу с русскоязычной информацией, а также консолидация сообщества российских исследователей и разработчиков, занимающихся информационным поиском.
 Виды ИП: библиографический, n документальный n фактографический, n аналитический. n
Виды ИП: библиографический, n документальный n фактографический, n аналитический. n
 библиографический n Поиск необходимых сведений об источнике и установление его наличия в системе других источников. Ведется путем разыскания библиографической информации и библиографических пособий (информационных изданий), специально создаваемых для более эффективного поиска и использования информации, книг, стаей и т. п. (например, Ежегодник книги).
библиографический n Поиск необходимых сведений об источнике и установление его наличия в системе других источников. Ведется путем разыскания библиографической информации и библиографических пособий (информационных изданий), специально создаваемых для более эффективного поиска и использования информации, книг, стаей и т. п. (например, Ежегодник книги).
, в которых есть или может") документальный n Поиск самих информационных источников (документов и изданий), в которых есть или может содержаться нужная информация.
документальный n Поиск самих информационных источников (документов и изданий), в которых есть или может содержаться нужная информация.
 фактографический n Поиск фактических сведений, содержащихся в публикациях, например, об исторических фактах и событиях, об архитектурных особенностях конкретных объектов, о технических характеристиках машин и процессов, о свойствах веществ и материалов, о биографических данных ученого, инженера и т. п.
фактографический n Поиск фактических сведений, содержащихся в публикациях, например, об исторических фактах и событиях, об архитектурных особенностях конкретных объектов, о технических характеристиках машин и процессов, о свойствах веществ и материалов, о биографических данных ученого, инженера и т. п.
 аналитический n Поиск аналитической информации, обобщенного характера, основанной на исследованиях различного масштаба, глубины и т. д.
аналитический n Поиск аналитической информации, обобщенного характера, основанной на исследованиях различного масштаба, глубины и т. д.
 формулирование задачи поиска; n 2) разработка рабочей программы поиска; n") Этапы информационного поиска: 1) формулирование задачи поиска; n 2) разработка рабочей программы поиска; n 3) реализация поиска и n 4) оформление результатов поиска. n
Этапы информационного поиска: 1) формулирование задачи поиска; n 2) разработка рабочей программы поиска; n 3) реализация поиска и n 4) оформление результатов поиска. n
 1. Формулирование задачи поиска n обусловлено соответствующим информационным дефицитом. По существу – это краткое определение темы (содержания) поиска. Формулирование задачи чаще всего выполняется в виде элементарной тематической рубрики, однако, можно и в виде плана (тезисов, рубрикатора – перечня предметных рубрик, структурно оформленные ключевых слов), в виде аннотации.
1. Формулирование задачи поиска n обусловлено соответствующим информационным дефицитом. По существу – это краткое определение темы (содержания) поиска. Формулирование задачи чаще всего выполняется в виде элементарной тематической рубрики, однако, можно и в виде плана (тезисов, рубрикатора – перечня предметных рубрик, структурно оформленные ключевых слов), в виде аннотации.
 n Формулирование задачи поиска позволяет определить область и особенности используемой литературы, помочь в составлении программы поиска
n Формулирование задачи поиска позволяет определить область и особенности используемой литературы, помочь в составлении программы поиска
 2. Программа поиска n должна максимально развернуть и конкретизировать поставленную задачу, определяя: объект, виды и методы, возможные направления (маршруты), необходимые ограничения поиска – тематические, хронологические, языковые, жанровые и т. п. , возможные объективные и субъективные затруднения, степень полноты, форму представления результатов поиска.
2. Программа поиска n должна максимально развернуть и конкретизировать поставленную задачу, определяя: объект, виды и методы, возможные направления (маршруты), необходимые ограничения поиска – тематические, хронологические, языковые, жанровые и т. п. , возможные объективные и субъективные затруднения, степень полноты, форму представления результатов поиска.
 Программа поиска должна максимально развернуть и конкретизировать поставленную задачу, определяя: 1. объект, 2. виды и 3. методы, 4. возможные направления (маршруты),
Программа поиска должна максимально развернуть и конкретизировать поставленную задачу, определяя: 1. объект, 2. виды и 3. методы, 4. возможные направления (маршруты),
 5. необходимые ограничения поиска – тематические, хронологические, языковые, жанровые и т. п. , возможные объективные и субъективные затруднения, 6. степень полноты, 7. форму представления результатов поиска
5. необходимые ограничения поиска – тематические, хронологические, языковые, жанровые и т. п. , возможные объективные и субъективные затруднения, 6. степень полноты, 7. форму представления результатов поиска
 3. Реализация информационного поиска n В процессе реализации необходимо чтобы сначала поиск был привязан к теме и к цели, когда особенно необходим широкий охват информационных источников, литературы, т. е. использовать библиографический и документальный виды поиска. И лишь затем информационный поиск конкретизируется, ограничивается непосредственным содержанием решаемой задачи – научное или другое творчество.
3. Реализация информационного поиска n В процессе реализации необходимо чтобы сначала поиск был привязан к теме и к цели, когда особенно необходим широкий охват информационных источников, литературы, т. е. использовать библиографический и документальный виды поиска. И лишь затем информационный поиск конкретизируется, ограничивается непосредственным содержанием решаемой задачи – научное или другое творчество.
 Методы информационнобиблиографического поиска сплошной, n выборочный, n интуитивный, n типологический ("рецептурный «) n индуктивный, n дедуктивный, n метод библиографических ссылок, n метод восхождения от абстрактного к n
Методы информационнобиблиографического поиска сплошной, n выборочный, n интуитивный, n типологический ("рецептурный «) n индуктивный, n дедуктивный, n метод библиографических ссылок, n метод восхождения от абстрактного к n
 4, Оформление результатов поиска n может быть различным в зависимости от целей, если конечная цель информационного поиска написание учебной, творческой. научной работы, то результат должен быть оформлен как библиографический список в рукописи согласно всем правилам, принятым в России.
4, Оформление результатов поиска n может быть различным в зависимости от целей, если конечная цель информационного поиска написание учебной, творческой. научной работы, то результат должен быть оформлен как библиографический список в рукописи согласно всем правилам, принятым в России.
 Принципы построения информационнопоисковых систем
Принципы построения информационнопоисковых систем
 Поисковые системы: состав, функции, принцип работы n Поисковая система — это программноаппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу).
Поисковые системы: состав, функции, принцип работы n Поисковая система — это программноаппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу).
 Пример n Международные поисковые системы ¨ «Google» , ¨ «Yahoo» , ¨ «MSN» . n В рунете это – ¨ «Яндекс» , ¨ «Рамблер» , ¨ «Апорт» .
Пример n Международные поисковые системы ¨ «Google» , ¨ «Yahoo» , ¨ «MSN» . n В рунете это – ¨ «Яндекс» , ¨ «Рамблер» , ¨ «Апорт» .
 Основные характеристики поисковых систем n n Полнота —отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу (отношение числа выданных релевантных документов (а) к общему числу релевантных документов массива).
Основные характеристики поисковых систем n n Полнота —отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу (отношение числа выданных релевантных документов (а) к общему числу релевантных документов массива).
 Основные характеристики поисковых систем Точность n Точность —определяется степенью соответствия найденных документов запросу пользователя (отношение числа выданных релевантных документов (а) к общему числу выданных документов). n
Основные характеристики поисковых систем Точность n Точность —определяется степенью соответствия найденных документов запросу пользователя (отношение числа выданных релевантных документов (а) к общему числу выданных документов). n
 Основные характеристики поисковых систем Актуальность n Актуальность характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. n
Основные характеристики поисковых систем Актуальность n Актуальность характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. n
 Основные характеристики поисковых систем Скорость поиска n Скорость поиска тесно связана с его устойчивостью к нагрузкам. n
Основные характеристики поисковых систем Скорость поиска n Скорость поиска тесно связана с его устойчивостью к нагрузкам. n
 Основные характеристики поисковых систем Наглядность n Наглядность представления результатов является важным компонентом удобного поиска. n
Основные характеристики поисковых систем Наглядность n Наглядность представления результатов является важным компонентом удобного поиска. n
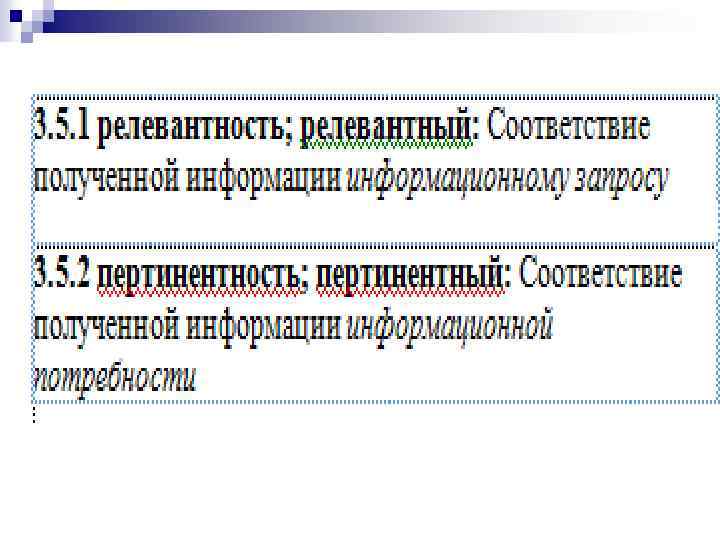
 По Яндекса велению по МОЕМУ хотению… Пертинентность - n Пертинентность поиска – новый тренд в конкуренции поисковых систем соответствие полученной информации информационной потребности пользователя вне зависимости от точности текста запроса n КПД(соотношение полезного объёма выдачи информации к общему и удовлетворенность пользователя этими результатами. ) n
По Яндекса велению по МОЕМУ хотению… Пертинентность - n Пертинентность поиска – новый тренд в конкуренции поисковых систем соответствие полученной информации информационной потребности пользователя вне зависимости от точности текста запроса n КПД(соотношение полезного объёма выдачи информации к общему и удовлетворенность пользователя этими результатами. ) n
 Релевантность поиска означает соответствие найденной информации введенному запросу. n применительно к результатам работы поисковой системы— степень соответствия запроса и найденного, то есть уместность результата n
Релевантность поиска означает соответствие найденной информации введенному запросу. n применительно к результатам работы поисковой системы— степень соответствия запроса и найденного, то есть уместность результата n
 n нерелевантная выдача ? ? ? ? n яндекс сошел с ума ? ? ? n на самом деле он сделал выдачу ПЕРТИНЕНТНОЙ!
n нерелевантная выдача ? ? ? ? n яндекс сошел с ума ? ? ? n на самом деле он сделал выдачу ПЕРТИНЕНТНОЙ!
 Информационная потребность пользователя: «послушать Билана, чтонибудь, что недавно крутили по радио» n Поисковый запрос: «дима билан скачать» (пользователь , исходя из своего пользовательского опыта – User Experience ведь привык ранее скачивать музыку, ведь ему было сложно послушать ее в онлайн, только немногочисленные ролики на You. Tube). n Что же выдает ему Яндекс? n
Информационная потребность пользователя: «послушать Билана, чтонибудь, что недавно крутили по радио» n Поисковый запрос: «дима билан скачать» (пользователь , исходя из своего пользовательского опыта – User Experience ведь привык ранее скачивать музыку, ведь ему было сложно послушать ее в онлайн, только немногочисленные ролики на You. Tube). n Что же выдает ему Яндекс? n
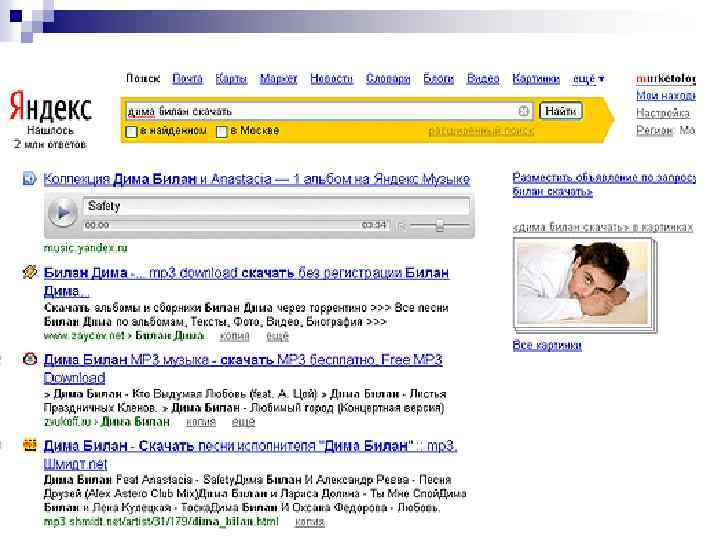
 Поисковая система ищет страницы, содержащие введенные в запросе слова. «Смысл» запроса не анализируется. Для определения релевантности страницы обычная поисковая система использует следующие характеристики: Ø Наличие слов на странице. Чем больше слов запроса присутствует на странице, тем больше релевантность.
Поисковая система ищет страницы, содержащие введенные в запросе слова. «Смысл» запроса не анализируется. Для определения релевантности страницы обычная поисковая система использует следующие характеристики: Ø Наличие слов на странице. Чем больше слов запроса присутствует на странице, тем больше релевантность.
 Ø Частота слов. Релевантность тем больше, чем чаще слова запроса встречаются на странице. Частоту можно комбинировать с обратной частотой - насколько редко слово встречается во всем Интернете. Наиболее ценны те слова, которые много встречаются в тексте страницы, но в общем случае используются редко.
Ø Частота слов. Релевантность тем больше, чем чаще слова запроса встречаются на странице. Частоту можно комбинировать с обратной частотой - насколько редко слово встречается во всем Интернете. Наиболее ценны те слова, которые много встречаются в тексте страницы, но в общем случае используются редко.
 Ø Форматирование слов запроса на странице. Предпочтительнее, если искомые слова оказываются в заголовке или просто выделены по отношению к остальному тексту (жирным, курсивом).
Ø Форматирование слов запроса на странице. Предпочтительнее, если искомые слова оказываются в заголовке или просто выделены по отношению к остальному тексту (жирным, курсивом).
 Ø Соответствие тематик сайта и запроса. Тематику текста можно определять, например, ключевыми словами. Особенно просто определить рубрику сайта, если он находится в каталоге, связанном с поисковой системой.
Ø Соответствие тематик сайта и запроса. Тематику текста можно определять, например, ключевыми словами. Особенно просто определить рубрику сайта, если он находится в каталоге, связанном с поисковой системой.
 Ø Качество ссылок, ведущих на страницу. Это один из ключевых критериев релевантности. Страница должна быть «авторитетным» источником информации. Авторитет страницы тем больше, чем больше других авторитетных страниц на нее ссылается. Впервые этот критерий качества страниц появился в поисковой системе Google, авторы назвали его Page. Rank.
Ø Качество ссылок, ведущих на страницу. Это один из ключевых критериев релевантности. Страница должна быть «авторитетным» источником информации. Авторитет страницы тем больше, чем больше других авторитетных страниц на нее ссылается. Впервые этот критерий качества страниц появился в поисковой системе Google, авторы назвали его Page. Rank.

 Состав и принципы работы поисковой системы 1. n Модуль индексирования может включать три вспомогательных программы (роботов): Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание html-кода каждой страницы и извлекает все внутренние ссылки с этой страницы.
Состав и принципы работы поисковой системы 1. n Модуль индексирования может включать три вспомогательных программы (роботов): Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание html-кода каждой страницы и извлекает все внутренние ссылки с этой страницы.
 – программа, которая") Состав и принципы работы поисковой системы n Crawler ( «путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Состав и принципы работы поисковой системы n Crawler ( «путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
 — программа, которая анализирует") Состав и принципы работы поисковой системы n Indexer (робот- индексатор) — программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т. д.
Состав и принципы работы поисковой системы n Indexer (робот- индексатор) — программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т. д.
 Состав и принципы работы поисковой системы 2. n База данных, или индекс поисковой системы — это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
Состав и принципы работы поисковой системы 2. n База данных, или индекс поисковой системы — это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
 Состав и принципы работы поисковой системы Поисковый сервер n Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска. n
Состав и принципы работы поисковой системы Поисковый сервер n Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска. n
 Поисковый сервер работает следующим образом: n Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска).
Поисковый сервер работает следующим образом: n Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска).
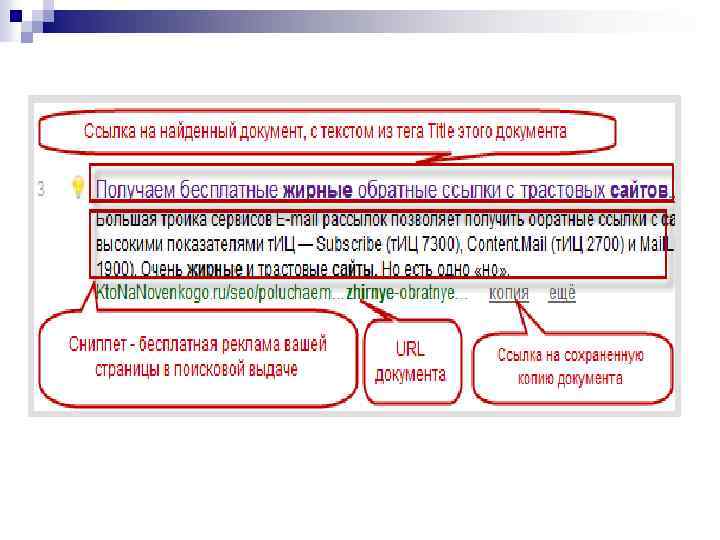
 Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
 n В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск» ).
n В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск» ).
 Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются. n Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов. n
Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются. n Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов. n
, хранящихся в базе данных поисковиков, не является") n Метод простого перебора всех страниц (документов), хранящихся в базе данных поисковиков, не является оптимальным. Этот метод называется алгоритмом прямого поиска. Он плохо подходит для работы с большими объемами данных, так как такой поиск будет занимать много времени.
n Метод простого перебора всех страниц (документов), хранящихся в базе данных поисковиков, не является оптимальным. Этот метод называется алгоритмом прямого поиска. Он плохо подходит для работы с большими объемами данных, так как такой поиск будет занимать много времени.
 индексов. n") Для эффективного поиска в больших объемах данных был разработан алгоритм обратных (инвертированных) индексов. n Именно этот алгоритм используется всеми крупными поисковыми системами в мире n
Для эффективного поиска в больших объемах данных был разработан алгоритм обратных (инвертированных) индексов. n Именно этот алгоритм используется всеми крупными поисковыми системами в мире n
 индексов, поисковые системы преобразовывают документы в текстовые файлы,") n При использовании алгоритма обратных (инвертированных) индексов, поисковые системы преобразовывают документы в текстовые файлы, содержащие список всех имеющихся в документе слов. Слова в таких списках (индекс-файлах) располагаются в алфавитном порядке и рядом с каждым словом указаны в виде координат те места в документе, где это слово встречается. Кроме позиции в документе, для каждого слова приводятся еще и другие параметры, определяющие его значение в документе
n При использовании алгоритма обратных (инвертированных) индексов, поисковые системы преобразовывают документы в текстовые файлы, содержащие список всех имеющихся в документе слов. Слова в таких списках (индекс-файлах) располагаются в алфавитном порядке и рядом с каждым словом указаны в виде координат те места в документе, где это слово встречается. Кроме позиции в документе, для каждого слова приводятся еще и другие параметры, определяющие его значение в документе
 n Для того, чтобы осуществлять поиск по обратным индексам документов, содержащимся в базе данных поисковых систем, используется математическая модель, позволяющая упростить процесс обнаружения нужных документов (по введенному пользователем поисковому запросу) и процесс определения релевантности всех найденных документов этому запросу.
n Для того, чтобы осуществлять поиск по обратным индексам документов, содержащимся в базе данных поисковых систем, используется математическая модель, позволяющая упростить процесс обнаружения нужных документов (по введенному пользователем поисковому запросу) и процесс определения релевантности всех найденных документов этому запросу.
 n Математическая модель, используемая всеми поисковыми системами, относится к классу векторных математических моделей. В этой математической модели используется такое понятие, как вес документа по отношению к заданному пользователем запросу.
n Математическая модель, используемая всеми поисковыми системами, относится к классу векторных математических моделей. В этой математической модели используется такое понятие, как вес документа по отношению к заданному пользователем запросу.
 n В базовой векторной математической модели вес документа по заданному поисковому запросу высчитывается исходя из двух основных параметров: частоты, с которой встречается данное слово в рассматриваемом документе (TF — term frequency) и тем, насколько редко это слово встречается во всех других документах коллекции поисковой системы (IDF — inverse document frequency). Под коллекцией поисковой системы имеется в виду вся совокупность документов, известных поисковой системе. Умножив эти два параметра друг на друга, мы получим вес документа по заданному поисковому запросу.
n В базовой векторной математической модели вес документа по заданному поисковому запросу высчитывается исходя из двух основных параметров: частоты, с которой встречается данное слово в рассматриваемом документе (TF — term frequency) и тем, насколько редко это слово встречается во всех других документах коллекции поисковой системы (IDF — inverse document frequency). Под коллекцией поисковой системы имеется в виду вся совокупность документов, известных поисковой системе. Умножив эти два параметра друг на друга, мы получим вес документа по заданному поисковому запросу.
 n различные поисковые системы, кроме параметров TF и IDF, используют множество различных коэффициентов для расчета веса документа (страницы) по заданному поисковому запросу, но суть остается прежней: вес страницы (документа) будет тем больше, чем чаще слово из поискового запроса встречается в документе (до определенных пределов, после которых документ может быть признан спамом) и чем реже встречается это слово во всех остальных документах, проиндексированных поисковой системой
n различные поисковые системы, кроме параметров TF и IDF, используют множество различных коэффициентов для расчета веса документа (страницы) по заданному поисковому запросу, но суть остается прежней: вес страницы (документа) будет тем больше, чем чаще слово из поискового запроса встречается в документе (до определенных пределов, после которых документ может быть признан спамом) и чем реже встречается это слово во всех остальных документах, проиндексированных поисковой системой
 n формирование выдач поисковых систем по тем или иным запросам осуществляется полностью по формуле (математической модели) без участия человека. Но никакая формула не будет работать идеально, особенно на первых порах, поэтому нужно осуществлять контроль за работой математической модели. Для этих целей используются специально обученные люди — ассесоры, которые просматривают выдачу поисковых систем (конкретно той поисковой системы, которая их наняла) по различным запросам и оценивают качество работы математической модели поисковой системы.
n формирование выдач поисковых систем по тем или иным запросам осуществляется полностью по формуле (математической модели) без участия человека. Но никакая формула не будет работать идеально, особенно на первых порах, поэтому нужно осуществлять контроль за работой математической модели. Для этих целей используются специально обученные люди — ассесоры, которые просматривают выдачу поисковых систем (конкретно той поисковой системы, которая их наняла) по различным запросам и оценивают качество работы математической модели поисковой системы.
 Алгоритмы поисковых систем Google Page. Rank n Тиц Яндекса n
Алгоритмы поисковых систем Google Page. Rank n Тиц Яндекса n
 Page. Rank – постановка задачи
Page. Rank – постановка задачи
 Page. Rank — n это числовая величина, характеризующая «важность» вебстраницы. Чем больше ссылок на страницу, тем она становится «важнее» . Кроме того, «вес» страницы А определяется весом ссылки, передаваемой страницей B. Таким образом, Page. Rank — это метод вычисления веса страницы путём подсчёта важности ссылок на неё.
Page. Rank — n это числовая величина, характеризующая «важность» вебстраницы. Чем больше ссылок на страницу, тем она становится «важнее» . Кроме того, «вес» страницы А определяется весом ссылки, передаваемой страницей B. Таким образом, Page. Rank — это метод вычисления веса страницы путём подсчёта важности ссылок на неё.
 n Page. Rank можно перевести с английского языка как «ранг страницы» , однако Google Inc. связывает слово Page в названии алгоритма не с английским словом «страница» , а с именем Лэрри Пейджа
n Page. Rank можно перевести с английского языка как «ранг страницы» , однако Google Inc. связывает слово Page в названии алгоритма не с английским словом «страница» , а с именем Лэрри Пейджа
 n В 1998 году Google был одной из первых поисковых систем, внедривших ссылочное ранжирование, благодаря чему добился значительного улучшения качества поиска по сравнению с конкурентами. В дальнейшем многие крупные поисковые системы разработали и внедрили свои аналоги Page. Rank и другие методы статического (то есть запросо-независимого) ранжирования документов
n В 1998 году Google был одной из первых поисковых систем, внедривших ссылочное ранжирование, благодаря чему добился значительного улучшения качества поиска по сравнению с конкурентами. В дальнейшем многие крупные поисковые системы разработали и внедрили свои аналоги Page. Rank и другие методы статического (то есть запросо-независимого) ранжирования документов
 n Надстройка для браузера Google Toolbar показывает для каждой вебстраницы целое число от 0 до 10, которое она называет Page. Rank, или важностью этой страницы с точки зрения Google.
n Надстройка для браузера Google Toolbar показывает для каждой вебстраницы целое число от 0 до 10, которое она называет Page. Rank, или важностью этой страницы с точки зрения Google.
 n n Шкала Page. Rank может изменяться от 0 до 10. Можно придерживаться примерно такой градации: Page. Rank от 4 до 5 — наиболее типичный для большинства сайтов средней «раскрученности» . 6 — очень хорошо «раскрученный» сайт. 7 — величина, практически недостижимая для множества сайтов, но иногда встречается. Значения 8, 9, 10 имеют исключительно популярные и значимые проекты. Например, в данный момент у сайта русской Википедии PR равен 8, у английской Википедии, gnu. org и у сайта Microsoft — 9. Значение 10 имеют всего несколько десятков сайтов, например http: //www. whitehouse. gov, http: //www. adobe. com, http: //w 3 c. org и т. д.
n n Шкала Page. Rank может изменяться от 0 до 10. Можно придерживаться примерно такой градации: Page. Rank от 4 до 5 — наиболее типичный для большинства сайтов средней «раскрученности» . 6 — очень хорошо «раскрученный» сайт. 7 — величина, практически недостижимая для множества сайтов, но иногда встречается. Значения 8, 9, 10 имеют исключительно популярные и значимые проекты. Например, в данный момент у сайта русской Википедии PR равен 8, у английской Википедии, gnu. org и у сайта Microsoft — 9. Значение 10 имеют всего несколько десятков сайтов, например http: //www. whitehouse. gov, http: //www. adobe. com, http: //w 3 c. org и т. д.


 ТИЦ Яндекса
ТИЦ Яндекса
 — технология поисковой машины «Яндекс» , заключающаяся в") n Тематический индекс цитирования (т. ИЦ) — технология поисковой машины «Яндекс» , заключающаяся в определении «авторитетности» интернет-ресурсов с учетом качественной характеристики — ссылок на них с других сайтов. т. ИЦ рассчитывается по специально разработанному алгоритму, в котором особое значение придается тематической близости ресурса и ссылающихся на него сайтов.
n Тематический индекс цитирования (т. ИЦ) — технология поисковой машины «Яндекс» , заключающаяся в определении «авторитетности» интернет-ресурсов с учетом качественной характеристики — ссылок на них с других сайтов. т. ИЦ рассчитывается по специально разработанному алгоритму, в котором особое значение придается тематической близости ресурса и ссылающихся на него сайтов.
 n Данный показатель в первую очередь используется для определения порядка расположения ресурсов в рубриках каталога «Яндекса» . При этом на соответствующих страницах каталога указываются лишь округлённые значения, которые помогают приблизительно ориентироваться в «авторитетности» ресурсов раздела.
n Данный показатель в первую очередь используется для определения порядка расположения ресурсов в рубриках каталога «Яндекса» . При этом на соответствующих страницах каталога указываются лишь округлённые значения, которые помогают приблизительно ориентироваться в «авторитетности» ресурсов раздела.
 — процесс корректировки") n n Поиско вая оптимиза ция (англ. search engine optimization, SEO) — процесс корректировки HTMLкода, текстового наполнения (контента), структуры сайта, контроль внешних факторов для соответствия требованиям алгоритма поисковых систем, с целью поднятия позиции сайта в результатах поиска в поисковых системах по определенным запросам пользователей. Чем выше позиция сайта в результатах поиска, тем больше заинтересованных посетителей перейдет на него с поисковых систем.
n n Поиско вая оптимиза ция (англ. search engine optimization, SEO) — процесс корректировки HTMLкода, текстового наполнения (контента), структуры сайта, контроль внешних факторов для соответствия требованиям алгоритма поисковых систем, с целью поднятия позиции сайта в результатах поиска в поисковых системах по определенным запросам пользователей. Чем выше позиция сайта в результатах поиска, тем больше заинтересованных посетителей перейдет на него с поисковых систем.
 n n Факторы, влияющие на положение сайта в выдаче поисковой системы: Внешние — обмен ссылками, регистрация в каталогах и прочие мероприятия для повышения и стимулирования ссылаемости на ресурс. Внутренние (находятся под контролем владельца веб-сайта) — приведение текста и разметки страниц в соответствие с выбранными запросами, улучшение качества и количества текста на сайте, стилистическое оформление текста (заголовки, жирный шрифт), улучшение структуры и навигации, использование внутренних ссылок
n n Факторы, влияющие на положение сайта в выдаче поисковой системы: Внешние — обмен ссылками, регистрация в каталогах и прочие мероприятия для повышения и стимулирования ссылаемости на ресурс. Внутренние (находятся под контролем владельца веб-сайта) — приведение текста и разметки страниц в соответствие с выбранными запросами, улучшение качества и количества текста на сайте, стилистическое оформление текста (заголовки, жирный шрифт), улучшение структуры и навигации, использование внутренних ссылок
 История n n Вместе с появлением и развитием поисковиков в середине 1990 -х появилась и оптимизация. В то время поисковики придавали большое значение тексту на странице и прочим внутренним факторам, которыми владельцы сайтов могли легко манипулировать. Это привело к тому, что в выдаче многих поисковиков первые несколько страниц заняли мусорные сайты, что резко снизило качество работы поисковиков и привело многие из них к упадку. С появлением технологии Page. Rank больше веса стало придаваться внешним факторам, что помогло Google выйти в лидеры поиска в мировом масштабе, затруднив оптимизацию при помощи одного лишь текста на сайте.
История n n Вместе с появлением и развитием поисковиков в середине 1990 -х появилась и оптимизация. В то время поисковики придавали большое значение тексту на странице и прочим внутренним факторам, которыми владельцы сайтов могли легко манипулировать. Это привело к тому, что в выдаче многих поисковиков первые несколько страниц заняли мусорные сайты, что резко снизило качество работы поисковиков и привело многие из них к упадку. С появлением технологии Page. Rank больше веса стало придаваться внешним факторам, что помогло Google выйти в лидеры поиска в мировом масштабе, затруднив оптимизацию при помощи одного лишь текста на сайте.
 «Белая» оптимизация Белым называется оптимизаторская работа над ресурсом без применения официально запрещённых поисковиками методов раскрутки ресурса. n Это комплекс мер по повышению посещаемости веб-сайта, основанный на анализе поведения целевых посетителей. n
«Белая» оптимизация Белым называется оптимизаторская работа над ресурсом без применения официально запрещённых поисковиками методов раскрутки ресурса. n Это комплекс мер по повышению посещаемости веб-сайта, основанный на анализе поведения целевых посетителей. n
 «Белая» оптимизация n Естественная оптимизация позволяет естественным путём, анализируя поведение потребителей, добиться максимальной отдачи от сайта, а именно возрастания целевой посещаемости, популярности ресурса среди пользователей Интернета и рейтинга в поисковых системах.
«Белая» оптимизация n Естественная оптимизация позволяет естественным путём, анализируя поведение потребителей, добиться максимальной отдачи от сайта, а именно возрастания целевой посещаемости, популярности ресурса среди пользователей Интернета и рейтинга в поисковых системах.
 Комплекс мероприятий n n n Постоянное улучшение видимости сайта роботами поисковых систем Постоянное совершенствование удобства сайта для посетителей — юзабилити Постоянный анализ качества обработки заявок с сайта — так называемая услуга «тайный покупатель» Постоянное совершенствование текстов на сайте — контента для формирования семантического ядра Постоянный поиск сайтов родственной тематики для создания партнёрских программ
Комплекс мероприятий n n n Постоянное улучшение видимости сайта роботами поисковых систем Постоянное совершенствование удобства сайта для посетителей — юзабилити Постоянный анализ качества обработки заявок с сайта — так называемая услуга «тайный покупатель» Постоянное совершенствование текстов на сайте — контента для формирования семантического ядра Постоянный поиск сайтов родственной тематики для создания партнёрских программ
 Способы внутренней белой оптимизации
Способы внутренней белой оптимизации
 Способы внутренней белой оптимизации n Подбор и размещение в коде сайта META-тегов: n ключевых слов, краткого описания. Делается это с учётом слов и словосочетаний, по которым сайт должен находиться в поисковых системах. Оптимизация текстов сайта, то есть обеспечение соответствия текстов META-тегам. Так, в тексте должны встречаться слова, обозначенные в META-тегах, как ключевые. Возможно также увеличение «веса» слова в тексте за счёт выделения его жирным шрифтом. Однако не стоит забывать, что переизбыток ключевых слов в тексте может навредить. Вопервых, текст может стать просто плохо читаемым. Во-вторых, поисковые системы могут расценить это как спам.
Способы внутренней белой оптимизации n Подбор и размещение в коде сайта META-тегов: n ключевых слов, краткого описания. Делается это с учётом слов и словосочетаний, по которым сайт должен находиться в поисковых системах. Оптимизация текстов сайта, то есть обеспечение соответствия текстов META-тегам. Так, в тексте должны встречаться слова, обозначенные в META-тегах, как ключевые. Возможно также увеличение «веса» слова в тексте за счёт выделения его жирным шрифтом. Однако не стоит забывать, что переизбыток ключевых слов в тексте может навредить. Вопервых, текст может стать просто плохо читаемым. Во-вторых, поисковые системы могут расценить это как спам.
 n Немаловажной частью внутренней оптимизации является оптимизация файлов robots. txt
n Немаловажной частью внутренней оптимизации является оптимизация файлов robots. txt
 Способы внешней белой оптимизации n n Добавление сайта в базы поисковых систем. Это своего рода «подсказка» поисковым роботам проверить и добавить соответствующий сайт с последующей выдачей его в результатах поиска. Регистрация сайта в авторитетных каталогах сайтов (DMOZ, Yandex Каталог). Размещение пресс-релизов в интернете со ссылкой на продвигаемый сайт.
Способы внешней белой оптимизации n n Добавление сайта в базы поисковых систем. Это своего рода «подсказка» поисковым роботам проверить и добавить соответствующий сайт с последующей выдачей его в результатах поиска. Регистрация сайта в авторитетных каталогах сайтов (DMOZ, Yandex Каталог). Размещение пресс-релизов в интернете со ссылкой на продвигаемый сайт.
 понимается, что вебмастер, который занимается продвижением") «Серая» оптимизация n Под серой оптимизацией (SEO) понимается, что вебмастер, который занимается продвижением ресурса так или иначе затрагивает методы, запрещенные поисковыми системами — Серая оптимизация не ведет к полному бану сайта, но попадает под наложение различных фильтров поисковых систем.
«Серая» оптимизация n Под серой оптимизацией (SEO) понимается, что вебмастер, который занимается продвижением ресурса так или иначе затрагивает методы, запрещенные поисковыми системами — Серая оптимизация не ведет к полному бану сайта, но попадает под наложение различных фильтров поисковых систем.
 «Серая» оптимизация n Серая оптимизация может привести к нежелательному результату: негативному отношению к сайту со стороны поисковиков, падению трафика и порой существенному, частому выпадению из индекса, понижению ТИЦ и Page Rank.
«Серая» оптимизация n Серая оптимизация может привести к нежелательному результату: негативному отношению к сайту со стороны поисковиков, падению трафика и порой существенному, частому выпадению из индекса, понижению ТИЦ и Page Rank.
 «Серая» оптимизация n К серой поисковой оптимизации можно отнести добавление большого количества ключевых слов в текст страницы, зачастую в ущерб читабельности для человека. n «Масло масляное, потому что в нём есть маслопроизводные масляные жиры» .
«Серая» оптимизация n К серой поисковой оптимизации можно отнести добавление большого количества ключевых слов в текст страницы, зачастую в ущерб читабельности для человека. n «Масло масляное, потому что в нём есть маслопроизводные масляные жиры» .
 «Серая» оптимизация n При этом оптимизация заключается сначала в подборе ключевых запросов для конкретной веб-страницы, определении размера целевого «SEO-текста» и необходимой частоты ключевых слов в нём, а затем в формулировании предложений и фраз, содержащих в себе ключевые запросы определённое количество раз в разных падежах, единственном и множественном числе, при разных формах глаголов.
«Серая» оптимизация n При этом оптимизация заключается сначала в подборе ключевых запросов для конкретной веб-страницы, определении размера целевого «SEO-текста» и необходимой частоты ключевых слов в нём, а затем в формулировании предложений и фраз, содержащих в себе ключевые запросы определённое количество раз в разных падежах, единственном и множественном числе, при разных формах глаголов.
 «Серая» оптимизация n При этом задача SEO-копирайтера — написать оригинальный текст таким образом, чтобы подобная оптимизация была как можно менее заметна «живому» читателю (и в частности модератору поисковой системы). Широко применяется также включение ключевого запроса в HTML-теги title, h 1, атрибут meta keywords.
«Серая» оптимизация n При этом задача SEO-копирайтера — написать оригинальный текст таким образом, чтобы подобная оптимизация была как можно менее заметна «живому» читателю (и в частности модератору поисковой системы). Широко применяется также включение ключевого запроса в HTML-теги title, h 1, атрибут meta keywords.
 не имеет отношения к") Оптимизация в сером цвете по мнению Google: Заголовок страницы (поста) не имеет отношения к внутреннему содержимому на странице n Присвоение одинаковых заголовков для всех страниц проекта n Включать в заголовок ключевые слова, которые там не должны быть n
Оптимизация в сером цвете по мнению Google: Заголовок страницы (поста) не имеет отношения к внутреннему содержимому на странице n Присвоение одинаковых заголовков для всех страниц проекта n Включать в заголовок ключевые слова, которые там не должны быть n
 Оптимизация в сером цвете по мнению Google: n n n Задействовать адреса URL с www и без одновременно Делать адреса страниц состоящих из больших (заглавных) букв Удалять страницы от главной на большое число кликов для пользователя Применять выпадающее меню, скрипты выпадающих меню и флеш анимированные меню Оставлять в карте сайта адреса страниц проекта, которые были удалены или не работают
Оптимизация в сером цвете по мнению Google: n n n Задействовать адреса URL с www и без одновременно Делать адреса страниц состоящих из больших (заглавных) букв Удалять страницы от главной на большое число кликов для пользователя Применять выпадающее меню, скрипты выпадающих меню и флеш анимированные меню Оставлять в карте сайта адреса страниц проекта, которые были удалены или не работают
 Оптимизация в сером цвете по мнению Google: n n n Применять не оптимизированные для пользователей страницы с 404 кодом Большое количество ошибок текста и битых (не рабочих) ссылок в пределах одной страницы Злоупотребление большим количеством графики без текстового наполнения Много текста сплошным написанием без дробления на ключевые разделы по семантике Не уникальный текст, применять рерайт других текстов и статей
Оптимизация в сером цвете по мнению Google: n n n Применять не оптимизированные для пользователей страницы с 404 кодом Большое количество ошибок текста и битых (не рабочих) ссылок в пределах одной страницы Злоупотребление большим количеством графики без текстового наполнения Много текста сплошным написанием без дробления на ключевые разделы по семантике Не уникальный текст, применять рерайт других текстов и статей
 Оптимизация в сером цвете по мнению Google: n n Ставить ссылки на другие сайты находящиеся под фильтрами Google Продавать ссылки со страниц проекта через биржи продажи ссылок Создавать текстовое содержимое меньшее в %, по отношению к общему одинаковому окружению страниц (сайдбары, баннеры, шапка, подвал) Использовать скрытые ссылки или мелким шрифтом, не видимым пользователем
Оптимизация в сером цвете по мнению Google: n n Ставить ссылки на другие сайты находящиеся под фильтрами Google Продавать ссылки со страниц проекта через биржи продажи ссылок Создавать текстовое содержимое меньшее в %, по отношению к общему одинаковому окружению страниц (сайдбары, баннеры, шапка, подвал) Использовать скрытые ссылки или мелким шрифтом, не видимым пользователем
 «Чёрная» оптимизация Дорвеи n Клоакинг n Скрытый текст n
«Чёрная» оптимизация Дорвеи n Клоакинг n Скрытый текст n
 или входная страница — вид") Дорвей n (от англ. doorway — входная дверь, портал) или входная страница — вид поискового спама, веб-страница, специально оптимизированная под один или несколько поисковых запросов с единственной целью её попадания на высокие места в результатах поиска по этим запросам. Иногда дорвеем называют и целый веб-сайт, состоящий из таких страниц.
Дорвей n (от англ. doorway — входная дверь, портал) или входная страница — вид поискового спама, веб-страница, специально оптимизированная под один или несколько поисковых запросов с единственной целью её попадания на высокие места в результатах поиска по этим запросам. Иногда дорвеем называют и целый веб-сайт, состоящий из таких страниц.
 Дорвей n Как правило, содержимое дорвея не представляет никакой информационной ценности для посетителя страницы, и содержит в себе ссылку или автоматическую переадресацию (редирект) на некоторую другую целевую страницу или сайт, раскручивающийся при помощи таких дорвеев.
Дорвей n Как правило, содержимое дорвея не представляет никакой информационной ценности для посетителя страницы, и содержит в себе ссылку или автоматическую переадресацию (редирект) на некоторую другую целевую страницу или сайт, раскручивающийся при помощи таких дорвеев.
 Дорвей n Редирект технически может быть реализован при помощи сценариев Java. Script, Macromedia Flash и других технологий. В последнее время многие поисковые боты научились отслеживать быстрый редирект. Поэтому создателям дорвеев приходится использовать более изощренные методы перенаправления пользователей на целевой ресурс. Например, «принуждая» их нажимать на кнопку «Вход» или изображение-ссылку
Дорвей n Редирект технически может быть реализован при помощи сценариев Java. Script, Macromedia Flash и других технологий. В последнее время многие поисковые боты научились отслеживать быстрый редирект. Поэтому создателям дорвеев приходится использовать более изощренные методы перенаправления пользователей на целевой ресурс. Например, «принуждая» их нажимать на кнопку «Вход» или изображение-ссылку
 Дорвей n Оптимизация страницы осуществляется путем искусственного увеличения факторов ранжирования страницы поисковой системой, например за счет создания страницы с текстом с большой частотой вхождения фразы нужного запроса
Дорвей n Оптимизация страницы осуществляется путем искусственного увеличения факторов ранжирования страницы поисковой системой, например за счет создания страницы с текстом с большой частотой вхождения фразы нужного запроса
 Дорвей n n n Программы для автоматического создания дорвеев на жаргоне поисковых оптимизаторов известны как «доргены» . Часто они используют такие статистические методы, как марковские цепи, для создания множества страниц с бессмысленным текстом на основе списка ключевых слов и коллекции тематических текстов. Такой подход позволяет без участия человека создавать страницы с уникальным содержимым, не определяющиеся поисковыми системами как дубликаты других страниц.
Дорвей n n n Программы для автоматического создания дорвеев на жаргоне поисковых оптимизаторов известны как «доргены» . Часто они используют такие статистические методы, как марковские цепи, для создания множества страниц с бессмысленным текстом на основе списка ключевых слов и коллекции тематических текстов. Такой подход позволяет без участия человека создавать страницы с уникальным содержимым, не определяющиеся поисковыми системами как дубликаты других страниц.
 прием «чёрной» поисковой оптимизации, заключающийся") Клоакинг n (от англ. cloak - мантия, маска, прикрытие) прием «чёрной» поисковой оптимизации, заключающийся в том, что информация, выдаваемая пользователю и поисковым роботам на одной и той же странице, различается
Клоакинг n (от англ. cloak - мантия, маска, прикрытие) прием «чёрной» поисковой оптимизации, заключающийся в том, что информация, выдаваемая пользователю и поисковым роботам на одной и той же странице, различается
 Клоакинг n Пользовательская страница оформляется произвольным образом, без каких-либо ограничений, связанных с поисковой оптимизацией. Страница, предназначенная для пауков, наполняется и оформляется в соответствии с требованиями оптимизации, для чего нужно иметь знания о поисковых системах. Для различения роботов и посетителей могут проверяться их IP-адреса.
Клоакинг n Пользовательская страница оформляется произвольным образом, без каких-либо ограничений, связанных с поисковой оптимизацией. Страница, предназначенная для пауков, наполняется и оформляется в соответствии с требованиями оптимизации, для чего нужно иметь знания о поисковых системах. Для различения роботов и посетителей могут проверяться их IP-адреса.
 Во-первых, не нужно организовывать автоматическое перенаправление или заставлять пользователя") Клоакинг n n Преимущества (дорвеи) Во-первых, не нужно организовывать автоматическое перенаправление или заставлять пользователя вручную переходить к нужной странице (этот приём неудобен для пользователей и слишком легко вычисляется поисковыми системами). Во-вторых, конкуренты не смогут увидеть оптимизированную страницу и использовать применённый на ней код в своих разработках, потому что для этого им понадобился бы IP-адрес, совпадающий с адресом какого-либо паука.
Клоакинг n n Преимущества (дорвеи) Во-первых, не нужно организовывать автоматическое перенаправление или заставлять пользователя вручную переходить к нужной странице (этот приём неудобен для пользователей и слишком легко вычисляется поисковыми системами). Во-вторых, конкуренты не смогут увидеть оптимизированную страницу и использовать применённый на ней код в своих разработках, потому что для этого им понадобился бы IP-адрес, совпадающий с адресом какого-либо паука.
 Скрытый текст n Также к чёрным методам SEO можно отнести использование так называемого скрытого текста на страницах сайта. Для пользователей данный текст не виден, однако поисковые роботы легко его индексируют. Обычно в скрытом тексте содержатся ключевые слова для придания «веса» оптимизируемой странице.
Скрытый текст n Также к чёрным методам SEO можно отнести использование так называемого скрытого текста на страницах сайта. Для пользователей данный текст не виден, однако поисковые роботы легко его индексируют. Обычно в скрытом тексте содержатся ключевые слова для придания «веса» оптимизируемой странице.
 Синтаксис запросов, настройки поиска в Яндекс и Google
Синтаксис запросов, настройки поиска в Яндекс и Google
 n n n У каждой поисковой системы есть специальные запросы, по которым система сделает упор в каком-то направлении. Фактически это некий механизм воздействия на черный ящик для того чтобы получить результат больше удовлетворяющий нашим требованиям. В гугле и яндексе, если вводимую фразу выделить двойными кавычками: «запрос» поисковая система будет искать документы в которых имеется только точное совпадение с вводимым запросом. В Яндексе есть возможность просмотра всех страниц сайта, находящихся в индексе. http: //webmaster. yandex. ru
n n n У каждой поисковой системы есть специальные запросы, по которым система сделает упор в каком-то направлении. Фактически это некий механизм воздействия на черный ящик для того чтобы получить результат больше удовлетворяющий нашим требованиям. В гугле и яндексе, если вводимую фразу выделить двойными кавычками: «запрос» поисковая система будет искать документы в которых имеется только точное совпадение с вводимым запросом. В Яндексе есть возможность просмотра всех страниц сайта, находящихся в индексе. http: //webmaster. yandex. ru
 n n Настройки поиска в Гугле И Яндексе Что тут скажешь при поиске есть такая фраза: «Расширенный поиск» . В данных настройках можно указать количество результатов на странице, типы документов, временные рамки, регионы, язык другие пожелания к выдаче. Но обычный пользователь не часто этим пользуется – вы когда в последний раз настраивали поиск для себя? вот видите.
n n Настройки поиска в Гугле И Яндексе Что тут скажешь при поиске есть такая фраза: «Расширенный поиск» . В данных настройках можно указать количество результатов на странице, типы документов, временные рамки, регионы, язык другие пожелания к выдаче. Но обычный пользователь не часто этим пользуется – вы когда в последний раз настраивали поиск для себя? вот видите.
 Сервисы для поиска изображений
Сервисы для поиска изображений
 Самые известные способы быстро найти изображение являются стандартные сервисы n Google Images n Яндекс. Картинки n n можно настроить фильтрацию, поиск по цвету, по размеру изображения
Самые известные способы быстро найти изображение являются стандартные сервисы n Google Images n Яндекс. Картинки n n можно настроить фильтрацию, поиск по цвету, по размеру изображения
 Tin. Eye n сервис поиска больших изображений из маленьких
Tin. Eye n сервис поиска больших изображений из маленьких
 n Прямо на главной страничке сервиса можно загрузить изображение с компьютера или же вставить ссылку на изображение, выбрать критерий поиска – Biggest – и получить изображение необходимого размера, если таковое есть в Сети.
n Прямо на главной страничке сервиса можно загрузить изображение с компьютера или же вставить ссылку на изображение, выбрать критерий поиска – Biggest – и получить изображение необходимого размера, если таковое есть в Сети.
 Пример
Пример
 Flikr n сервис поиска изображений, который поможет найти требуемое по заданным цветовым параметрам n http: //labs. ideeinc. com/multicolr
Flikr n сервис поиска изображений, который поможет найти требуемое по заданным цветовым параметрам n http: //labs. ideeinc. com/multicolr
 n Можно искать по фильтру, состоящему одновременно из десяти цветов и менее. Например, подходящие для нашей комнаты:
n Можно искать по фильтру, состоящему одновременно из десяти цветов и менее. Например, подходящие для нашей комнаты:
 n Найти красивые фото по простым критериям поможет сервис Compfight
n Найти красивые фото по простым критериям поможет сервис Compfight
 n Если в поисковике от Google ввести «вывеска а» , придется разгребать массу ненужной информации. Поиск выдаст или вывески, но не «А» , или «А» , но не вывески, а в большинстве что-то, вообще не имеющее отношения к теме. А с помощью Compfight мы получим множество различных вывесок с буквой «A» – то, что и требуется
n Если в поисковике от Google ввести «вывеска а» , придется разгребать массу ненужной информации. Поиск выдаст или вывески, но не «А» , или «А» , но не вывески, а в большинстве что-то, вообще не имеющее отношения к теме. А с помощью Compfight мы получим множество различных вывесок с буквой «A» – то, что и требуется
