

03396519d4918c39649395fcabc6a959.ppt
- Количество слайдов: 88
 IST 511 Information Management: Information and Technology Information extraction, data mining, metadata Dr. C. Lee Giles David Reese Professor, College of Information Sciences and Technology The Pennsylvania State University, University Park, PA, USA giles@ist. psu. edu http: //clgiles. ist. psu. edu Special thanks to E. Agichtein, K. Borne, S. Sarawagi, C. Lagoze,
IST 511 Information Management: Information and Technology Information extraction, data mining, metadata Dr. C. Lee Giles David Reese Professor, College of Information Sciences and Technology The Pennsylvania State University, University Park, PA, USA giles@ist. psu. edu http: //clgiles. ist. psu. edu Special thanks to E. Agichtein, K. Borne, S. Sarawagi, C. Lagoze,
 Last time What are probabilities What is information theory What is probabilistic reasoning – – Definitions Why important How used – decision making Decision trees Impact on information science
Last time What are probabilities What is information theory What is probabilistic reasoning – – Definitions Why important How used – decision making Decision trees Impact on information science
 Today What is information extraction What is data mining – Text mining as subfield What is metadata Impact on information science
Today What is information extraction What is data mining – Text mining as subfield What is metadata Impact on information science
 Tomorrow Topics used in IST • Digital libraries, • Scientometrics, bibliometrics • Digital humanities
Tomorrow Topics used in IST • Digital libraries, • Scientometrics, bibliometrics • Digital humanities
 Theories in Information Sciences Enumerate some of these theories in this course. Issues: – Unified theory? – Domain of applicability – Conflicts Theories here are – Very algorithmic – Some quantitative – Some qualitative Quality of theories – – Occam’s razor Subsumption of other theories (all can use machine learning) Text mining special case of data mining Natural language processing uses data mining methods Theories – Natural language processing
Theories in Information Sciences Enumerate some of these theories in this course. Issues: – Unified theory? – Domain of applicability – Conflicts Theories here are – Very algorithmic – Some quantitative – Some qualitative Quality of theories – – Occam’s razor Subsumption of other theories (all can use machine learning) Text mining special case of data mining Natural language processing uses data mining methods Theories – Natural language processing
 Science Paradigms Thousand years ago: science was empirical describing natural phenomena Last few hundred years: theoretical branch using models, generalizations Last few decades: a computational branch simulating complex phenomena Today: data science (e. Science) unify theory, experiment, and simulation – Data captured by instruments or generated by simulator – Processed by software – Information/Knowledge stored in computer – Scientist analyzes database / files using data management and statistics
Science Paradigms Thousand years ago: science was empirical describing natural phenomena Last few hundred years: theoretical branch using models, generalizations Last few decades: a computational branch simulating complex phenomena Today: data science (e. Science) unify theory, experiment, and simulation – Data captured by instruments or generated by simulator – Processed by software – Information/Knowledge stored in computer – Scientist analyzes database / files using data management and statistics
 Information extraction, data mining and natural language processing • Natural language processing is the processing and understanding of human language by machines • Information Extraction can be considered a subclass • Also known as knowledge extraction • Data mining is the process of discovering new patterns from large data sets • Text mining is the data mining of text • Text analytics generally refers to the tools used • Information extraction is the process of extracting and labeling relevant data from large data sets, usually text • Large means manually unreasonable
Information extraction, data mining and natural language processing • Natural language processing is the processing and understanding of human language by machines • Information Extraction can be considered a subclass • Also known as knowledge extraction • Data mining is the process of discovering new patterns from large data sets • Text mining is the data mining of text • Text analytics generally refers to the tools used • Information extraction is the process of extracting and labeling relevant data from large data sets, usually text • Large means manually unreasonable
 The Value of Unstructured Text Data “Unstructured” text data is the primary form of human-generated information – Business and government reports, blogs, web pages, news, scientific literature, online reviews, … Need to extract information and give it structure to effectively manage, search, mine, store and utilize this data Information Extraction: maturing, and active research area – Software and companies exist – Intersection of Computational Linguistics, Machine Learning, Data mining, Databases, and Information Retrieval Active crawling for text data
The Value of Unstructured Text Data “Unstructured” text data is the primary form of human-generated information – Business and government reports, blogs, web pages, news, scientific literature, online reviews, … Need to extract information and give it structure to effectively manage, search, mine, store and utilize this data Information Extraction: maturing, and active research area – Software and companies exist – Intersection of Computational Linguistics, Machine Learning, Data mining, Databases, and Information Retrieval Active crawling for text data
 Example: Answering Queries Over Text For years, Microsoft Corporation CEO Bill Gates was against open source. But today he appears to have changed his mind. "We can be open source. We love the concept of shared source, " said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access. “ Richard Stallman, founder of the Free Software Foundation, countered saying… Select Name From PEOPLE Where Organization = ‘Microsoft’ PEOPLE Name Bill Gates Bill Veghte Richard Stallman Title Organization CEO Microsoft VP Microsoft Founder Free Soft. . Bill Gates Bill Veghte (from William Cohen’s IE tutorial, 2003)
Example: Answering Queries Over Text For years, Microsoft Corporation CEO Bill Gates was against open source. But today he appears to have changed his mind. "We can be open source. We love the concept of shared source, " said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access. “ Richard Stallman, founder of the Free Software Foundation, countered saying… Select Name From PEOPLE Where Organization = ‘Microsoft’ PEOPLE Name Bill Gates Bill Veghte Richard Stallman Title Organization CEO Microsoft VP Microsoft Founder Free Soft. . Bill Gates Bill Veghte (from William Cohen’s IE tutorial, 2003)
 Information extraction from text or pdfs For years, Microsoft Corporation CEO Bill Gates was against open source. But today he appears to have changed his mind. "We can be open source. We love the concept of shared source, " said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access. “ Richard Stallman, founder of the Free Software Foundation, countered saying… (William Cohen’s IE tutorial, 2003) Select Name From PEOPLE Where Organization = ‘Microsoft’ PEOPLE Name Bill Gates Bill Veghte Richard Stallman Title Organization CEO Microsoft VP Microsoft Founder Free Soft. . XML or database For extraction of OAI metadata from academic documents, see Cite. Seer. X citeseerx. ist. psu. edu
Information extraction from text or pdfs For years, Microsoft Corporation CEO Bill Gates was against open source. But today he appears to have changed his mind. "We can be open source. We love the concept of shared source, " said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access. “ Richard Stallman, founder of the Free Software Foundation, countered saying… (William Cohen’s IE tutorial, 2003) Select Name From PEOPLE Where Organization = ‘Microsoft’ PEOPLE Name Bill Gates Bill Veghte Richard Stallman Title Organization CEO Microsoft VP Microsoft Founder Free Soft. . XML or database For extraction of OAI metadata from academic documents, see Cite. Seer. X citeseerx. ist. psu. edu
 Information Extraction Tasks Extracting entities and relations: this talk – Entities: named (e. g. , Person) and generic (e. g. , disease name) – Relations: entities related in a predefined way (e. g. , Location of a Disease outbreak, or a CEO of a Company) – Events: can be composed from multiple relation tuples Common extraction subtasks: – Preprocess: sentence chunking, syntactic parsing, morphological analysis – Create rules or extraction patterns: hand-coded, machine learning, and hybrid – Apply extraction patterns or rules to extract new information – Postprocess and integrate information • Co-reference resolution, deduplication, disambiguation
Information Extraction Tasks Extracting entities and relations: this talk – Entities: named (e. g. , Person) and generic (e. g. , disease name) – Relations: entities related in a predefined way (e. g. , Location of a Disease outbreak, or a CEO of a Company) – Events: can be composed from multiple relation tuples Common extraction subtasks: – Preprocess: sentence chunking, syntactic parsing, morphological analysis – Create rules or extraction patterns: hand-coded, machine learning, and hybrid – Apply extraction patterns or rules to extract new information – Postprocess and integrate information • Co-reference resolution, deduplication, disambiguation
 Entities Wikipedia: An entity is something that has a distinct, separate existence, although it need not be a material existence. Features: – – – – Permanent vs transient Unique vs common Animate vs inanimate Small vs large Mobile vs sessile Place vs thing Abstract vs real Bio labels Digital mention or reference
Entities Wikipedia: An entity is something that has a distinct, separate existence, although it need not be a material existence. Features: – – – – Permanent vs transient Unique vs common Animate vs inanimate Small vs large Mobile vs sessile Place vs thing Abstract vs real Bio labels Digital mention or reference
 Example: Extracting Entities from Text – Useful for data warehousing, data cleaning, web data integration Address Citation House number Building Road City State Zip 4089 Whispering Pines Nobel Drive San Diego CA 92122 1 Ronald Fagin, Combining Fuzzy Information from Multiple Systems, Proc. of ACM SIGMOD, 2002 Segment(si) Sequence Label(si) S 1 Ronald Fagin Author S 2 Combining Fuzzy Information from Multiple Systems Title S 3 Proc. of ACM SIGMOD Conference S 4 2002 Year
Example: Extracting Entities from Text – Useful for data warehousing, data cleaning, web data integration Address Citation House number Building Road City State Zip 4089 Whispering Pines Nobel Drive San Diego CA 92122 1 Ronald Fagin, Combining Fuzzy Information from Multiple Systems, Proc. of ACM SIGMOD, 2002 Segment(si) Sequence Label(si) S 1 Ronald Fagin Author S 2 Combining Fuzzy Information from Multiple Systems Title S 3 Proc. of ACM SIGMOD Conference S 4 2002 Year
 Entity Disambiguation Task of clustering and linking similar entities in a document or between documents. – Labels sometime complex are given to these entities Sometimes includes task of extracting or finding those entities (information extraction, focused crawling, etc)
Entity Disambiguation Task of clustering and linking similar entities in a document or between documents. – Labels sometime complex are given to these entities Sometimes includes task of extracting or finding those entities (information extraction, focused crawling, etc)
 Hand-Coded Methods Easy to construct in some cases – e. g. , to recognize prices, phone numbers, zip codes, conference names, etc. Intuitive to debug and maintain – Especially if written in a “high-level” language: Contact. Pattern Regular. Expression(Email. body, ”can be reached at”) [IBM Avatar] – Can incorporate domain knowledge Scalability issues: – – Labor-intensive to create Highly domain-specific Often corpus-specific Rule-matches can be expensive
Hand-Coded Methods Easy to construct in some cases – e. g. , to recognize prices, phone numbers, zip codes, conference names, etc. Intuitive to debug and maintain – Especially if written in a “high-level” language: Contact. Pattern Regular. Expression(Email. body, ”can be reached at”) [IBM Avatar] – Can incorporate domain knowledge Scalability issues: – – Labor-intensive to create Highly domain-specific Often corpus-specific Rule-matches can be expensive
 Entity Disambiguation by some other name? record linkage merge/purge processing or list washing data matching object identity problem named entity resolution duplicate detection record matching instance identification deduplication coreference resolution reference reconciliation database hardening Closely related to Natural Language Processing
Entity Disambiguation by some other name? record linkage merge/purge processing or list washing data matching object identity problem named entity resolution duplicate detection record matching instance identification deduplication coreference resolution reference reconciliation database hardening Closely related to Natural Language Processing
 Entity Disambiguation Applications Speech understanding Question/answering Health records Criminal activities Finance records Semantic web applications Scientific discovery and search Semantic search Others?
Entity Disambiguation Applications Speech understanding Question/answering Health records Criminal activities Finance records Semantic web applications Scientific discovery and search Semantic search Others?
 in") Entity Tagging Identifying mentions of entities (e. g. , person names, locations, companies) in text – MUC (1997): Person, Location, Organization, Date/Time/Currency – ACE (2005): more than 100 more specific types Hand-coded vs. Machine Learning approaches Best approach depends on entity type and domain: – Closed class (e. g. , geographical locations, disease names, gene & protein names): hand coded + dictionaries – Syntactic (e. g. , phone numbers, zip codes): regular expressions – Semantic (e. g. , person and company names): mixture of context, syntactic features, dictionaries, heuristics, etc. – “Almost solved” for common/typical entity types
Entity Tagging Identifying mentions of entities (e. g. , person names, locations, companies) in text – MUC (1997): Person, Location, Organization, Date/Time/Currency – ACE (2005): more than 100 more specific types Hand-coded vs. Machine Learning approaches Best approach depends on entity type and domain: – Closed class (e. g. , geographical locations, disease names, gene & protein names): hand coded + dictionaries – Syntactic (e. g. , phone numbers, zip codes): regular expressions – Semantic (e. g. , person and company names): mixture of context, syntactic features, dictionaries, heuristics, etc. – “Almost solved” for common/typical entity types
 Machine Learning Methods Can work well when lots of training data and easy to construct Can capture complex patterns that are hard to encode with handcrafted rules – e. g. , determine whether a review is positive or negative – extract long complex gene names – Non-local dependencies The human T cell leukemia lymphotropic virus type 1 Tax protein represses Myo. D-dependent transcription by inhibiting Myo. Dbinding to the KIX domain of p 300. “ [From Ali. Baba]
Machine Learning Methods Can work well when lots of training data and easy to construct Can capture complex patterns that are hard to encode with handcrafted rules – e. g. , determine whether a review is positive or negative – extract long complex gene names – Non-local dependencies The human T cell leukemia lymphotropic virus type 1 Tax protein represses Myo. D-dependent transcription by inhibiting Myo. Dbinding to the KIX domain of p 300. “ [From Ali. Baba]
![Representation Models [Cohen and Mc. Callum, 2003] Classify Pre-segmented Candidates Lexicons Abraham Lincoln was](https://present5.com/presentation/03396519d4918c39649395fcabc6a959/image-20.jpg "Representation Models [Cohen and Mc. Callum, 2003] Classify Pre-segmented Candidates Lexicons Abraham Lincoln was") Representation Models [Cohen and Mc. Callum, 2003] Classify Pre-segmented Candidates Lexicons Abraham Lincoln was born in Kentucky member? Alabama Alaska … Wisconsin Wyoming Boundary Models Abraham Lincoln was born in Kentucky. Sliding Window Abraham Lincoln was born in Kentucky. Classifier which class? Try alternate window sizes: Finite State Machines Abraham Lincoln was born in Kentucky. Context Free Grammars Abraham Lincoln was born in Kentucky. V P Classifier st PP which class? VP NP BEGIN END BEGIN NP END pa rs V ly NNP lik e NNP Mo Most likely state sequence? BEGIN VP S Any of these models can be used to capture words, formatting or both. …and beyond
Representation Models [Cohen and Mc. Callum, 2003] Classify Pre-segmented Candidates Lexicons Abraham Lincoln was born in Kentucky member? Alabama Alaska … Wisconsin Wyoming Boundary Models Abraham Lincoln was born in Kentucky. Sliding Window Abraham Lincoln was born in Kentucky. Classifier which class? Try alternate window sizes: Finite State Machines Abraham Lincoln was born in Kentucky. Context Free Grammars Abraham Lincoln was born in Kentucky. V P Classifier st PP which class? VP NP BEGIN END BEGIN NP END pa rs V ly NNP lik e NNP Mo Most likely state sequence? BEGIN VP S Any of these models can be used to capture words, formatting or both. …and beyond
 Name Disambiguation Person Name disambiguation – A person can be referred to in") (Person) Name Disambiguation Person Name disambiguation – A person can be referred to in different ways with different attributes in multiple records, the goal of name disambiguation is to resolve such ambiguities, linking and merging all the records of the same entity together – Large # of mentions and entities Consider three types of person name ambiguities: – Aliases - one person with multiple aliases, name variations, or name changed e. g. CL Giles & Lee Giles, Superman & Clark Kent – Common Names - more than one person shares a common name, e. g. Jian Huang – 118 papers in DBLP – Typography Errors - resulting from human input or automatic extraction Goal: disambiguate, cluster and link names in a large digital library or bibliographic resource such as Medline
(Person) Name Disambiguation Person Name disambiguation – A person can be referred to in different ways with different attributes in multiple records, the goal of name disambiguation is to resolve such ambiguities, linking and merging all the records of the same entity together – Large # of mentions and entities Consider three types of person name ambiguities: – Aliases - one person with multiple aliases, name variations, or name changed e. g. CL Giles & Lee Giles, Superman & Clark Kent – Common Names - more than one person shares a common name, e. g. Jian Huang – 118 papers in DBLP – Typography Errors - resulting from human input or automatic extraction Goal: disambiguate, cluster and link names in a large digital library or bibliographic resource such as Medline
![Popular Machine Learning Methods For details: [Feldman, 2006 and Cohen, 2004] Naive Bayes SRV](https://present5.com/presentation/03396519d4918c39649395fcabc6a959/image-22.jpg "Popular Machine Learning Methods For details: [Feldman, 2006 and Cohen, 2004] Naive Bayes SRV") Popular Machine Learning Methods For details: [Feldman, 2006 and Cohen, 2004] Naive Bayes SRV [Freitag 1998], Inductive Logic Programming Rapier [Califf and Mooney 1997] Hidden Markov Models [Leek 1997] Maximum Entropy Markov Models [Mc. Callum et al. 2000] Conditional Random Fields [Lafferty et al. 2001] Scalability – Can be labor intensive to construct training data – At run time, complex features can be expensive to construct or process (batch algorithms can help: [Chandel et al. 2006] )
Popular Machine Learning Methods For details: [Feldman, 2006 and Cohen, 2004] Naive Bayes SRV [Freitag 1998], Inductive Logic Programming Rapier [Califf and Mooney 1997] Hidden Markov Models [Leek 1997] Maximum Entropy Markov Models [Mc. Callum et al. 2000] Conditional Random Fields [Lafferty et al. 2001] Scalability – Can be labor intensive to construct training data – At run time, complex features can be expensive to construct or process (batch algorithms can help: [Chandel et al. 2006] )
 Data mining? Process of semi-automatically analyzing large data sets and databases to find patterns that are: – – valid: hold on new data with some certainity novel: non-obvious to the system useful: should be possible to act on the item understandable: humans should be able to interpret the pattern
Data mining? Process of semi-automatically analyzing large data sets and databases to find patterns that are: – – valid: hold on new data with some certainity novel: non-obvious to the system useful: should be possible to act on the item understandable: humans should be able to interpret the pattern
 Evolution of Data Mining
Evolution of Data Mining
 Data Mining is Ready for Prime Time • Data mining is ready for general application because it engages three technologies that are now sufficiently mature: · Massive data collection & delivery · Powerful multiprocessor computers · Sophisticated data mining algorithms
Data Mining is Ready for Prime Time • Data mining is ready for general application because it engages three technologies that are now sufficiently mature: · Massive data collection & delivery · Powerful multiprocessor computers · Sophisticated data mining algorithms
 Organizational Reasons to use Data Mining – Most organizations already collect and refine massive quantities of data. – Their most important information is in their data warehouses. – Data mining moves beyond the analysis of past events … to predicting future trends and behaviors that may be missed because they lie outside the experts’ expectations. – Data mining tools can answer complex business questions that traditionally were too time-consuming to resolve. – Data mining tools can explore the intricate interdependencies within databases in order to discover hidden patterns and relationships. – Data mining allows decision-makers to make proactive, knowledge-driven decisions.
Organizational Reasons to use Data Mining – Most organizations already collect and refine massive quantities of data. – Their most important information is in their data warehouses. – Data mining moves beyond the analysis of past events … to predicting future trends and behaviors that may be missed because they lie outside the experts’ expectations. – Data mining tools can answer complex business questions that traditionally were too time-consuming to resolve. – Data mining tools can explore the intricate interdependencies within databases in order to discover hidden patterns and relationships. – Data mining allows decision-makers to make proactive, knowledge-driven decisions.

 A Key Concept for Data Mining • Data Mining delivers actionable data : – data that support decision-making – data that lead to knowledge and understanding – data with a purpose • i. e. , Data do not exist for their own sake. • The Data Warehouse is a corporate asset (whether in business, marketing, banking, science, telecommunications, entertainment, computer security, or security).
A Key Concept for Data Mining • Data Mining delivers actionable data : – data that support decision-making – data that lead to knowledge and understanding – data with a purpose • i. e. , Data do not exist for their own sake. • The Data Warehouse is a corporate asset (whether in business, marketing, banking, science, telecommunications, entertainment, computer security, or security).
 Data Mining - the up side Data mining is everywhere: – – – – – Huge scientific databases (NASA, Human Genome, …) Corporate databases (OLAP) Credit card usage histories (Capital One) Loan applications (Credit Scoring) Customer purchase records (CRM) Web traffic analysis (Doubleclick) Network security intrusion detection (Silent Runner) The hunt for terrorists The NBA!
Data Mining - the up side Data mining is everywhere: – – – – – Huge scientific databases (NASA, Human Genome, …) Corporate databases (OLAP) Credit card usage histories (Capital One) Loan applications (Credit Scoring) Customer purchase records (CRM) Web traffic analysis (Doubleclick) Network security intrusion detection (Silent Runner) The hunt for terrorists The NBA!
 Data Mining - the down side • Data mining is a pejorative in the business database community (“data dredging”) – They prefer to call it Knowledge Discovery, or Business Intelligence, or CRM (Customer Relationship Management), or Marketing, or OLAP (On-Line Analytical Processing) • Legal issues in many countries • The Data Mining Moratorium Act of 2003 – debated within the U. S. Congress – privacy concerns – directly primarily against the DARPA TIA Program (Total Information Awareness)
Data Mining - the down side • Data mining is a pejorative in the business database community (“data dredging”) – They prefer to call it Knowledge Discovery, or Business Intelligence, or CRM (Customer Relationship Management), or Marketing, or OLAP (On-Line Analytical Processing) • Legal issues in many countries • The Data Mining Moratorium Act of 2003 – debated within the U. S. Congress – privacy concerns – directly primarily against the DARPA TIA Program (Total Information Awareness)
 Characteristics of The Information Age: • Data “Avalanche” – the flood of Terabytes of data is already happening, whether we like it or not – our present techniques of handling these data do not scale well with data volume • Distributed Digital Archives – will be the main access to data – will need to handle hundreds to thousands of queries per day • Systematic Data Exploration and Data Mining – will have a central role • statistical analysis of “typical” events • automated search for “rare” events
Characteristics of The Information Age: • Data “Avalanche” – the flood of Terabytes of data is already happening, whether we like it or not – our present techniques of handling these data do not scale well with data volume • Distributed Digital Archives – will be the main access to data – will need to handle hundreds to thousands of queries per day • Systematic Data Exploration and Data Mining – will have a central role • statistical analysis of “typical” events • automated search for “rare” events
 The Data Flood is Everywhere Huge quantities of data are being generated in all business, government, and research domains: – Banking, retail, marketing, telecommunications, other business transactions. . . – Scientific data: genomics, astronomy, biology, etc. – Web, text, and e-commerce
The Data Flood is Everywhere Huge quantities of data are being generated in all business, government, and research domains: – Banking, retail, marketing, telecommunications, other business transactions. . . – Scientific data: genomics, astronomy, biology, etc. – Web, text, and e-commerce
 Data Growth Rate Exabytes 10 -fold Growth in 5 Years! DVD RFID Digital TV MP 3 players Digital cameras Camera phones, Vo. IP Medical imaging, Laptops, Data center applications, Games Satellite images, GPS, ATMs, Scanners Sensors, Digital radio, DLP theaters, Telematics Peer-to-peer, Email, Instant messaging, Videoconferencing, CAD/CAM, Toys, Industrial machines, Security systems, Appliances Source: IDC, 2008
Data Growth Rate Exabytes 10 -fold Growth in 5 Years! DVD RFID Digital TV MP 3 players Digital cameras Camera phones, Vo. IP Medical imaging, Laptops, Data center applications, Games Satellite images, GPS, ATMs, Scanners Sensors, Digital radio, DLP theaters, Telematics Peer-to-peer, Email, Instant messaging, Videoconferencing, CAD/CAM, Toys, Industrial machines, Security systems, Appliances Source: IDC, 2008
 What is Data Mining? Data mining is defined as “an information extraction activity whose goal is to discover hidden facts contained in (large) databases. " Data mining is used to find patterns and relationships in data. (EDA = Exploratory Data Analysis) Patterns can be analyzed via 2 types of models: – Descriptive : Describe patterns and create meaningful subgroups or clusters. – Predictive : Forecast explicit values, based upon patterns in known results. How does this become useful (not just bits of data)? . . . – … through KNOWLEDGE DISCOVERY Data Information Knowledge Understanding / Wisdom!
What is Data Mining? Data mining is defined as “an information extraction activity whose goal is to discover hidden facts contained in (large) databases. " Data mining is used to find patterns and relationships in data. (EDA = Exploratory Data Analysis) Patterns can be analyzed via 2 types of models: – Descriptive : Describe patterns and create meaningful subgroups or clusters. – Predictive : Forecast explicit values, based upon patterns in known results. How does this become useful (not just bits of data)? . . . – … through KNOWLEDGE DISCOVERY Data Information Knowledge Understanding / Wisdom!
 Historical Note: Many Names of Data Mining Data Fishing, Data Dredging: 1960– used by Statisticians (as a bad name) Data Mining : 1990– used by DB & business communities – in 2003 – bad image because of DARPA TIA Knowledge Discovery in Databases (1989 -) – used by AI & Machine Learning communities also Data Archaeology, Information Harvesting, Information Discovery, Knowledge Extraction, . . . Currently: Data Mining and Knowledge Discovery are seemed to be used interchangeably.
Historical Note: Many Names of Data Mining Data Fishing, Data Dredging: 1960– used by Statisticians (as a bad name) Data Mining : 1990– used by DB & business communities – in 2003 – bad image because of DARPA TIA Knowledge Discovery in Databases (1989 -) – used by AI & Machine Learning communities also Data Archaeology, Information Harvesting, Information Discovery, Knowledge Extraction, . . . Currently: Data Mining and Knowledge Discovery are seemed to be used interchangeably.
 Relationship with other fields Overlaps with machine learning, statistics, artificial intelligence, databases, visualization but more stress on – scalability of number of features and instances – stress on algorithms and architectures whereas foundations of methods and formulations provided by statistics and machine learning. – automation for handling large, heterogeneous data
Relationship with other fields Overlaps with machine learning, statistics, artificial intelligence, databases, visualization but more stress on – scalability of number of features and instances – stress on algorithms and architectures whereas foundations of methods and formulations provided by statistics and machine learning. – automation for handling large, heterogeneous data
 Some basic operations Predictive: – Regression – Classification – Collaborative Filtering Descriptive: – Clustering / similarity matching – Association rules and variants – Deviation detection
Some basic operations Predictive: – Regression – Classification – Collaborative Filtering Descriptive: – Clustering / similarity matching – Association rules and variants – Deviation detection
: Data mining") Data Mining Examples • Classic Textbook Example of Data Mining (Legend? ): Data mining of grocery store logs indicated that men who buy diapers also tend to buy beer at the same time. • Blockbuster Entertainment mines its video rental history database to recommend rentals to individual customers. • A financial institution discovered that credit applicants who used pencil on the form were much more likely to default on their debts than those who filled out the application using ink. • Credit card companies recommend products to cardholders based on analysis of their monthly expenditures. • Airline purchase transaction logs revealed that 9 -11 hijackers bought one-way airline tickets with the same credit card. • Astronomers examined objects with extreme colors in a huge database to discover the most distant Quasars ever seen.
Data Mining Examples • Classic Textbook Example of Data Mining (Legend? ): Data mining of grocery store logs indicated that men who buy diapers also tend to buy beer at the same time. • Blockbuster Entertainment mines its video rental history database to recommend rentals to individual customers. • A financial institution discovered that credit applicants who used pencil on the form were much more likely to default on their debts than those who filled out the application using ink. • Credit card companies recommend products to cardholders based on analysis of their monthly expenditures. • Airline purchase transaction logs revealed that 9 -11 hijackers bought one-way airline tickets with the same credit card. • Astronomers examined objects with extreme colors in a huge database to discover the most distant Quasars ever seen.
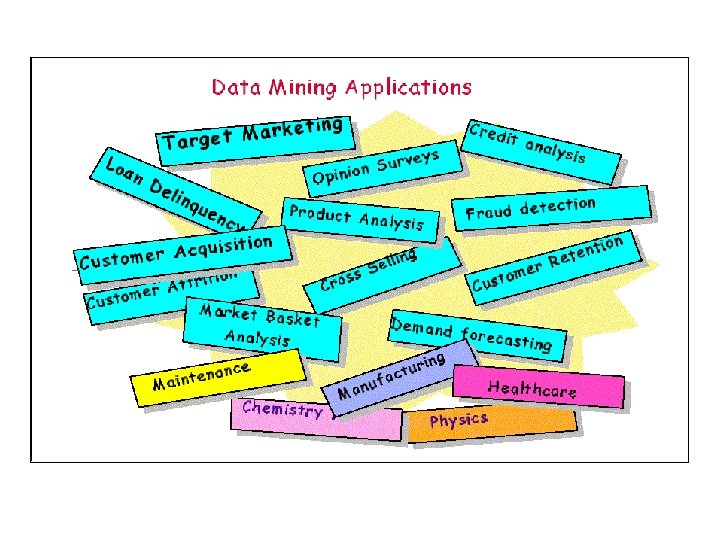
 Data Mining Application: Marketing § Sales Analysis • associations between product sales: • beer and diapers • strawberry pop tarts and beer (and hurricanes) § Customer Profiling • data mining can tell you what types of customers buy what products § Identifying Customer Requirements • identify the best products for different customers • use prediction to find what factors will attract new customers
Data Mining Application: Marketing § Sales Analysis • associations between product sales: • beer and diapers • strawberry pop tarts and beer (and hurricanes) § Customer Profiling • data mining can tell you what types of customers buy what products § Identifying Customer Requirements • identify the best products for different customers • use prediction to find what factors will attract new customers
 Data Mining Application: Fraud Detection § Auto Insurance Fraud • Association Rule Mining can detect a group of people who stage accidents to collect on insurance § Money Laundering • Since 1993, the US Treasury's Financial Crimes Enforcement Network agency has used a data-mining application to detect suspicious money transactions § Banking: Loan Fraud • Security Pacific/Bank of America uses data mining to help with commercial lending decisions and to prevent fraud
Data Mining Application: Fraud Detection § Auto Insurance Fraud • Association Rule Mining can detect a group of people who stage accidents to collect on insurance § Money Laundering • Since 1993, the US Treasury's Financial Crimes Enforcement Network agency has used a data-mining application to detect suspicious money transactions § Banking: Loan Fraud • Security Pacific/Bank of America uses data mining to help with commercial lending decisions and to prevent fraud
 The Necessity of Data Mining • Enormous interest in these data collections. • The environment to exploit these data does not exist! – 1 Terabyte at 100 Mbits/sec takes 1 day to transfer. – Hundreds to thousands of queries per day. – Data will reside at multiple locations, in many different formats. – Existing analysis tools do not scale to Terabyte data collections. • The need is acute! A solution will not just happen.
The Necessity of Data Mining • Enormous interest in these data collections. • The environment to exploit these data does not exist! – 1 Terabyte at 100 Mbits/sec takes 1 day to transfer. – Hundreds to thousands of queries per day. – Data will reside at multiple locations, in many different formats. – Existing analysis tools do not scale to Terabyte data collections. • The need is acute! A solution will not just happen.
 What is Knowledge Discovery? • Knowledge discovery refers to “finding out new knowledge about an application domain using data on the domain usually stored in a database. ” – Application domains: scientific, customer purchase records, computer network logs, web traffic logs, financial transactions, census data, basketball play-by-play histories, . . . • Why are Data Mining & Knowledge Discovery such hot topics? --- because of the enormous interest in these huge databases and their potential for new discoveries. • In large databases, Data Mining and Knowledge Discovery come in two flavors: – Event-based mining – Relationship-based mining
What is Knowledge Discovery? • Knowledge discovery refers to “finding out new knowledge about an application domain using data on the domain usually stored in a database. ” – Application domains: scientific, customer purchase records, computer network logs, web traffic logs, financial transactions, census data, basketball play-by-play histories, . . . • Why are Data Mining & Knowledge Discovery such hot topics? --- because of the enormous interest in these huge databases and their potential for new discoveries. • In large databases, Data Mining and Knowledge Discovery come in two flavors: – Event-based mining – Relationship-based mining
 Four") Event-Based Mining (Event-based mining is based upon events or trends in data. ) Four distinct orthogonal categorizations: • Known events / known models - use existing models (descriptive models) to locate known phenomena of interest either spatially or temporally within a large database. • Known events / unknown models - use clustering properties of data to discover new relationships and patterns among known phenomena. • Unknown events / known models - use known associations and relationships (predictive models) among parameters that describe a phenomenon to predict the presence of previously unseen examples of the same phenomenon within a large complex database. • Unknown events / unknown models - use thresholds or trends to identify transient or otherwise unique ("one-of-a-kind") events and therefore to discover new phenomena. Serendipity!
Event-Based Mining (Event-based mining is based upon events or trends in data. ) Four distinct orthogonal categorizations: • Known events / known models - use existing models (descriptive models) to locate known phenomena of interest either spatially or temporally within a large database. • Known events / unknown models - use clustering properties of data to discover new relationships and patterns among known phenomena. • Unknown events / known models - use known associations and relationships (predictive models) among parameters that describe a phenomenon to predict the presence of previously unseen examples of the same phenomenon within a large complex database. • Unknown events / unknown models - use thresholds or trends to identify transient or otherwise unique ("one-of-a-kind") events and therefore to discover new phenomena. Serendipity!
 • Spatial associations") Relationship-Based Data Mining (Based upon associations & relationships among data items) • Spatial associations -- identify events or objects at the same physical spatial location, or at related locations (e. g. , urban versus rural data). • Temporal associations -- identify events or transactions occurring during the same or related periods of time (e. g. , periodically, or N days after event X). • Coincidence associations -- use clustering techniques to identify events that are co-located (that coincide) within a multi-dimensional parameter space.
Relationship-Based Data Mining (Based upon associations & relationships among data items) • Spatial associations -- identify events or objects at the same physical spatial location, or at related locations (e. g. , urban versus rural data). • Temporal associations -- identify events or transactions occurring during the same or related periods of time (e. g. , periodically, or N days after event X). • Coincidence associations -- use clustering techniques to identify events that are co-located (that coincide) within a multi-dimensional parameter space.
 User Requirements for a Data Mining System (What features must a DM system have for users? ) • Cross-Identification - refers to the classical problem of associating the objects listed in one database to the objects listed in another. • Cross-Correlation - refers to the search for correlations, tendencies, and trends between parameters in multi-dimensional data, usually across databases. • Nearest-Neighbor Identification - refers to the general application of clustering algorithms in multi-dimensional parameter space, usually within a single database. • Systematic Data Exploration - refers to the application of the broad range of event-based and relationship-based queries to one or more databases in the hope of making a serendipitous discovery of new events/objects or a new class of events/objects.
User Requirements for a Data Mining System (What features must a DM system have for users? ) • Cross-Identification - refers to the classical problem of associating the objects listed in one database to the objects listed in another. • Cross-Correlation - refers to the search for correlations, tendencies, and trends between parameters in multi-dimensional data, usually across databases. • Nearest-Neighbor Identification - refers to the general application of clustering algorithms in multi-dimensional parameter space, usually within a single database. • Systematic Data Exploration - refers to the application of the broad range of event-based and relationship-based queries to one or more databases in the hope of making a serendipitous discovery of new events/objects or a new class of events/objects.
 Representative Data Mining Architecture
Representative Data Mining Architecture
 Data leads to Knowledge leads to Understanding Data Information Knowledge Understanding / Wisdom! EXAMPLE : Data = 00100100111010100111100 (stored in database) Information = ages and heights of children (metadata) Knowledge = the older children tend to be taller Understanding = children’s bones grow as they get older
Data leads to Knowledge leads to Understanding Data Information Knowledge Understanding / Wisdom! EXAMPLE : Data = 00100100111010100111100 (stored in database) Information = ages and heights of children (metadata) Knowledge = the older children tend to be taller Understanding = children’s bones grow as they get older
 Imaging data (ones & zeroes) Information (catalogs / databases): (b)") Astronomy Example Data: (a) Imaging data (ones & zeroes) Information (catalogs / databases): (b) Spectral data (ones & zeroes) – Measure brightness of galaxies from image (e. g. , 14. 2 or 21. 7) – Measure redshift of galaxies from spectrum (e. g. , 0. 0167 or 0. 346) Knowledge: Hubble Diagram Redshift-Brightness Correlation Redshift = Distance Understanding: the Universe is expanding!!
Astronomy Example Data: (a) Imaging data (ones & zeroes) Information (catalogs / databases): (b) Spectral data (ones & zeroes) – Measure brightness of galaxies from image (e. g. , 14. 2 or 21. 7) – Measure redshift of galaxies from spectrum (e. g. , 0. 0167 or 0. 346) Knowledge: Hubble Diagram Redshift-Brightness Correlation Redshift = Distance Understanding: the Universe is expanding!!
 Goal of Data Mining The end goal of data mining is not the data themselves, but the new knowledge and understanding that are revealed in the process = Business Intelligence (BI). (Remember what we said about the business community’s opinion of D. M. ) This is why the research field is usually referred to as KDD = Knowledge Discovery in Databases.
Goal of Data Mining The end goal of data mining is not the data themselves, but the new knowledge and understanding that are revealed in the process = Business Intelligence (BI). (Remember what we said about the business community’s opinion of D. M. ) This is why the research field is usually referred to as KDD = Knowledge Discovery in Databases.
 The Data Mining Process The most important and time-consuming step is Cleaning the Data.
The Data Mining Process The most important and time-consuming step is Cleaning the Data.
 Data Mining Methods and Some Examples Clustering Classification Associations Neural Nets Decision Trees Pattern Recognition Correlation/Trend Analysis Principal Component Analysis Regression Analysis Outlier/Glitch Identification Visualization Autonomous Agents Self-Organizing Maps (SOM) Link (Affinity) Analysis Find all groups and classes of objects represented in the data Classify new data items using the known classes & groups Find associations and patterns among different data items Organize information in the databased on relationships among key data descriptors Identify linkages between data items based on features shared in common
Data Mining Methods and Some Examples Clustering Classification Associations Neural Nets Decision Trees Pattern Recognition Correlation/Trend Analysis Principal Component Analysis Regression Analysis Outlier/Glitch Identification Visualization Autonomous Agents Self-Organizing Maps (SOM) Link (Affinity) Analysis Find all groups and classes of objects represented in the data Classify new data items using the known classes & groups Find associations and patterns among different data items Organize information in the databased on relationships among key data descriptors Identify linkages between data items based on features shared in common
 Link Analysis Clustering Decision Tree") Some Data Mining Techniques Graphically Represented Self-Organizing Map (SOM) Link Analysis Clustering Decision Tree Neural Network Outlier (Anomaly) Dectection
Some Data Mining Techniques Graphically Represented Self-Organizing Map (SOM) Link Analysis Clustering Decision Tree Neural Network Outlier (Anomaly) Dectection
 of items were") Data Mining Technique: Clustering In this case, three different groups (classes) of items were found among all of the items in the data set.
Data Mining Technique: Clustering In this case, three different groups (classes) of items were found among all of the items in the data set.
 Data Mining Technique: Decision Tree Classification Question: Should I play tennis today? Similar to game “ 20 questions” Same technique used by bank loan officers to identify good potential customers versus poor customers. (I must really love tennis!)
Data Mining Technique: Decision Tree Classification Question: Should I play tennis today? Similar to game “ 20 questions” Same technique used by bank loan officers to identify good potential customers versus poor customers. (I must really love tennis!)
 ti ac s an id") Data Mining Technique: Association Rule Mining (Market Basket Analysis) ti ac s an id tr on er m sto cu id cts u od ght pr ou b sales records: • Trend (Rule): Products p 5, p 8 often bought together • Trend (Rule): Customer 12 likes product p 9
Data Mining Technique: Association Rule Mining (Market Basket Analysis) ti ac s an id tr on er m sto cu id cts u od ght pr ou b sales records: • Trend (Rule): Products p 5, p 8 often bought together • Trend (Rule): Customer 12 likes product p 9
 is one technique") Data Mining Algorithm: The SOM Figure: The SOM (Self. Organizing Map) is one technique for organizing information in a databased upon links between concepts. It can be used to find hidden relationships and patterns in more complex data collections, usually based on links between keywords or metadata.
Data Mining Algorithm: The SOM Figure: The SOM (Self. Organizing Map) is one technique for organizing information in a databased upon links between concepts. It can be used to find hidden relationships and patterns in more complex data collections, usually based on links between keywords or metadata.
 within a") Data Mining Application: Outlier Detection Figure: The clustering of data clouds (dc#) within a multidimensional parameter space (p#). Such a mapping can be used to search for and identify clusters, voids, outliers, one-of-kinds, relationships, and associations among arbitrary parameters in a database (or among various parameters in geographically distributed databases).
Data Mining Application: Outlier Detection Figure: The clustering of data clouds (dc#) within a multidimensional parameter space (p#). Such a mapping can be used to search for and identify clusters, voids, outliers, one-of-kinds, relationships, and associations among arbitrary parameters in a database (or among various parameters in geographically distributed databases).
 Link Analysis for Terrorist SNA Find all connections and relationships among known terrorists.
Link Analysis for Terrorist SNA Find all connections and relationships among known terrorists.
 Data Mining Technology: Parallel Mining Figure: Parallel Data Mining The application of parallel computing resources and parallel data access (e. g. , RAID) enables concurrent drill-downs into large data collections
Data Mining Technology: Parallel Mining Figure: Parallel Data Mining The application of parallel computing resources and parallel data access (e. g. , RAID) enables concurrent drill-downs into large data collections
 Data Mining Methods Explained • Clustering: Group data items according to tight relationships. • Classification: Assign data items to predetermined groups. • Associations: Associate data with similar relationships. The beer-diaper example is an example of associative mining. • Artificial Neural Networks (ANN): Non-linear predictive models that learn through training and resemble biological neural networks in structure. • Decision Trees: Hierarchical sets of decisions, based upon rules, for rapid classification of a data collection. • Sequential Patterns: Identify or predict behavior patterns or trends. • Genetic Algorithms: Rapid optimization techniques that are based on the concepts of natural evolution. • Nearest Neighbor Method: Classify a data item according to its nearest neighbors (records that are most similar). • Rule induction: The extraction of useful if-then rules from data based on statistical significance. • Data visualization: The illustration and visual interpretation of complex relationships in multidimensional data using graphics tools. • Self-Organizing Map (SOM): Graphically organizes (in a 2 -dimensional map) the information stored within a databased upon similarities and links between concepts. It can be used to find hidden relationships and patterns in more complex data collections.
Data Mining Methods Explained • Clustering: Group data items according to tight relationships. • Classification: Assign data items to predetermined groups. • Associations: Associate data with similar relationships. The beer-diaper example is an example of associative mining. • Artificial Neural Networks (ANN): Non-linear predictive models that learn through training and resemble biological neural networks in structure. • Decision Trees: Hierarchical sets of decisions, based upon rules, for rapid classification of a data collection. • Sequential Patterns: Identify or predict behavior patterns or trends. • Genetic Algorithms: Rapid optimization techniques that are based on the concepts of natural evolution. • Nearest Neighbor Method: Classify a data item according to its nearest neighbors (records that are most similar). • Rule induction: The extraction of useful if-then rules from data based on statistical significance. • Data visualization: The illustration and visual interpretation of complex relationships in multidimensional data using graphics tools. • Self-Organizing Map (SOM): Graphically organizes (in a 2 -dimensional map) the information stored within a databased upon similarities and links between concepts. It can be used to find hidden relationships and patterns in more complex data collections.
 Data Mining Techniques: techniques are based on Algorithms; techniques are used in Applications
Data Mining Techniques: techniques are based on Algorithms; techniques are used in Applications
 KDnuggets
KDnuggets
 Tools used
Tools used
 Industries data mining is used
Industries data mining is used
 http: //www. kdnuggets. com/polls/2004/data_mining_applications_industries. htm Poll of Users: Where do you currently apply data mining? (August 2004) “Industries/fields where you currently apply data mining? ” [216 votes total] Banking (29) ……………. . . 13% Scientific data (20) …………………. . . 9% Direct Marketing/Fundraising (19) …. 9% Fraud Detection (19) ………………… 9% Bioinformatics/Biotech (18) …………. 8% Insurance (15) ……………. . . 7% Medical/Pharma (15) ………………… 7% Telecommunications (12) …………… 6% e. Commerce/Web (12) ………………. 6% Investment/Stocks (9) ………………. . 4% Manufacturing (9) …………. 4% Retail (9) ……………… 4% Security (8) ……………… 4% Travel (2) ………………. . . 1% Entertainment/News (1) ……………… 0. 5% Other (19) ………………. . . 9%
http: //www. kdnuggets. com/polls/2004/data_mining_applications_industries. htm Poll of Users: Where do you currently apply data mining? (August 2004) “Industries/fields where you currently apply data mining? ” [216 votes total] Banking (29) ……………. . . 13% Scientific data (20) …………………. . . 9% Direct Marketing/Fundraising (19) …. 9% Fraud Detection (19) ………………… 9% Bioinformatics/Biotech (18) …………. 8% Insurance (15) ……………. . . 7% Medical/Pharma (15) ………………… 7% Telecommunications (12) …………… 6% e. Commerce/Web (12) ………………. 6% Investment/Stocks (9) ………………. . 4% Manufacturing (9) …………. 4% Retail (9) ……………… 4% Security (8) ……………… 4% Travel (2) ………………. . . 1% Entertainment/News (1) ……………… 0. 5% Other (19) ………………. . . 9%
 The importance of metadata and their rules • So we have all this mined or extracted data: what is it? • Label some of it and call it metadata • You know what it is • Make it available to others (if you can) Tim Berners-Lee – inventor of the world wide web – Founder of the W 3 C Presentation at Ted
The importance of metadata and their rules • So we have all this mined or extracted data: what is it? • Label some of it and call it metadata • You know what it is • Make it available to others (if you can) Tim Berners-Lee – inventor of the world wide web – Founder of the W 3 C Presentation at Ted
 “Metadata is data about data” Metadata often is written in") Metadata (and Markup languages) “Metadata is data about data” Metadata often is written in XML
Metadata (and Markup languages) “Metadata is data about data” Metadata often is written in XML
 Metadata is semi-structured data conforming to commonly agreed upon models, providing operational interoperability in a heterogeneous environment
Metadata is semi-structured data conforming to commonly agreed upon models, providing operational interoperability in a heterogeneous environment
 What is metadata? Some simple definitions ‘Structured data about data’. • Dublin Core Metadata Initiative FAQ, 2005 – http: //dublincore. org/resources/faq/ Machine-understandable information about Web resources or other things. • Tim Berners-Lee, W 3 C, 1997 – http: //www. w 3. org/Design. Issues/Metadata
What is metadata? Some simple definitions ‘Structured data about data’. • Dublin Core Metadata Initiative FAQ, 2005 – http: //dublincore. org/resources/faq/ Machine-understandable information about Web resources or other things. • Tim Berners-Lee, W 3 C, 1997 – http: //www. w 3. org/Design. Issues/Metadata
 "Web resources or other things" • Metadata might be "about"… anything! – – – – HTML documents digital images databases books museum objects archival records metadata records – – – – – Web sites collections services physical places people organizations “works” formats concepts events
"Web resources or other things" • Metadata might be "about"… anything! – – – – HTML documents digital images databases books museum objects archival records metadata records – – – – – Web sites collections services physical places people organizations “works” formats concepts events
 What is metadata? Towards a "functional" view Data associated with objects which relieves their potential users of having to have full advance knowledge of their existence or characteristics. • Lorcan Dempsey & Rachel Heery, "Metadata: a current view of practice and issues", 1998 – http: //www. ukoln. ac. uk/metadata/publications/jdmetadata/ Structured data about resources that can be used to help support a wide range of operations. • Michael Day, "Metadata in a Nutshell", 2001 – http: //www. ukoln. ac. uk/metadata/publications/nutshell/
What is metadata? Towards a "functional" view Data associated with objects which relieves their potential users of having to have full advance knowledge of their existence or characteristics. • Lorcan Dempsey & Rachel Heery, "Metadata: a current view of practice and issues", 1998 – http: //www. ukoln. ac. uk/metadata/publications/jdmetadata/ Structured data about resources that can be used to help support a wide range of operations. • Michael Day, "Metadata in a Nutshell", 2001 – http: //www. ukoln. ac. uk/metadata/publications/nutshell/
 What might metadata "say"? What is this called? What is this about? Who made this? When was this made? Where do I get (a copy of) this? When does this expire? What format does this use? Who is this intended for? What does this cost? Can I copy this? Can I modify this? What are the component parts of this? What else refers to this? What did "users" think of this? (etc!)
What might metadata "say"? What is this called? What is this about? Who made this? When was this made? Where do I get (a copy of) this? When does this expire? What format does this use? Who is this intended for? What does this cost? Can I copy this? Can I modify this? What are the component parts of this? What else refers to this? What did "users" think of this? (etc!)
 What operations/functions? resource disclosure & discovery resource retrieval, use resource management, including preservation verification of authenticity intellectual property rights management commerce content-rating authentication and authorization personalization and localization of services (etc!)
What operations/functions? resource disclosure & discovery resource retrieval, use resource management, including preservation verification of authenticity intellectual property rights management commerce content-rating authentication and authorization personalization and localization of services (etc!)
 sometimes classified according") What operations/functions? Different functions : different metadata Metadata (and metadata standards) sometimes classified according to function – Descriptive: primarily for discovery, retrieval – Administrative: primarily for management – Structural: relationships between component parts of resources – Contextual: relationships between resources No “one size fits all solution”!
What operations/functions? Different functions : different metadata Metadata (and metadata standards) sometimes classified according to function – Descriptive: primarily for discovery, retrieval – Administrative: primarily for management – Structural: relationships between component parts of resources – Contextual: relationships between resources No “one size fits all solution”!
 Metadata importance “data about data” is about as good as the definition gets. . . As a data resource grows, metadata becomes more important Lack of metadata has different consequences – documentation: metadata can be regenerated automatically, or by hand – datasets, pictures: once lost, can be impossible to regenerate
Metadata importance “data about data” is about as good as the definition gets. . . As a data resource grows, metadata becomes more important Lack of metadata has different consequences – documentation: metadata can be regenerated automatically, or by hand – datasets, pictures: once lost, can be impossible to regenerate
 Types of Metadata See http: //www. loc. gov/standards/metadata. html Descriptive – Discovery / description of objects • Title, author, abstract, etc. Structural – Storage & presentation of objects • 1 pdf file, 1 ppt file, 1 La. Te. X file, etc. Administrative – Managing and preservation of objects • Access control lists, terms and conditions, format descriptions, “meta-metadata”
Types of Metadata See http: //www. loc. gov/standards/metadata. html Descriptive – Discovery / description of objects • Title, author, abstract, etc. Structural – Storage & presentation of objects • 1 pdf file, 1 ppt file, 1 La. Te. X file, etc. Administrative – Managing and preservation of objects • Access control lists, terms and conditions, format descriptions, “meta-metadata”
 Which View is Correct? figure 1 from: http: //www. dlib. org/dlib/january 01/lagoze/01 lagoze. html
Which View is Correct? figure 1 from: http: //www. dlib. org/dlib/january 01/lagoze/01 lagoze. html
) http: //www.") Approaches to Metadata from Ng, Park and Burnett, 1997 (also JASIS, 50(13)) http: //www. scils. rutgers. edu/~sypark/asis. html – library science: bibliographic control • “organizing the physical containers of information, by means of bibliographical description, subject analysis, and classification notation construction, so that the container can be efficiently described, identified, located and retrieved” – computer and information science: data management • “not only to store, access and utilize data effectively, but also to provide data security, data sharing, and data integrity”
Approaches to Metadata from Ng, Park and Burnett, 1997 (also JASIS, 50(13)) http: //www. scils. rutgers. edu/~sypark/asis. html – library science: bibliographic control • “organizing the physical containers of information, by means of bibliographical description, subject analysis, and classification notation construction, so that the container can be efficiently described, identified, located and retrieved” – computer and information science: data management • “not only to store, access and utilize data effectively, but also to provide data security, data sharing, and data integrity”
 DL Metadata Issues Who provides metadata? – author? “publisher”? professional cataloger? extracted from content? Is metadata “integrated” with data? – related question: is metadata a first class object? Formats! – which ones? – extensible? – paradox: the more powerful the format, the less likely it will be used. . .
DL Metadata Issues Who provides metadata? – author? “publisher”? professional cataloger? extracted from content? Is metadata “integrated” with data? – related question: is metadata a first class object? Formats! – which ones? – extensible? – paradox: the more powerful the format, the less likely it will be used. . .
 Metadata Formats and Implementation Use markup languages – Interoperable – Extensible – Robust Permits advance search features When online, the beginning of a semantic web!
Metadata Formats and Implementation Use markup languages – Interoperable – Extensible – Robust Permits advance search features When online, the beginning of a semantic web!
 What we covered • Methods and tools for making sense of data • Assists reasoning, decision making • Data manipulation methods • Large data • How metadata helps
What we covered • Methods and tools for making sense of data • Assists reasoning, decision making • Data manipulation methods • Large data • How metadata helps

 Importance of Data “Data is not only important to science but also to the humanities. ” “The sexy job in the next ten years will be. . . to take data -to be able to understand it, to process it, to extract value from it, to visualize it, to communicate it. ” -- Hal Varian (Economist, Berkeley & Google) “Elite American university students do not think big enough. That is exactly the complaint from some of the largest technology companies and the federal government. At the heart of this criticism is data. ” -- New York Times “Statistical agencies face increased demand for data products, and the questions asked by our society are becoming increasingly complex and hard to measure. Meeting these challenges requires innovation [in] cognitive research, and economic and statistical modeling. ” -Roderick Little (Statistician, US Census and U Michigan)
Importance of Data “Data is not only important to science but also to the humanities. ” “The sexy job in the next ten years will be. . . to take data -to be able to understand it, to process it, to extract value from it, to visualize it, to communicate it. ” -- Hal Varian (Economist, Berkeley & Google) “Elite American university students do not think big enough. That is exactly the complaint from some of the largest technology companies and the federal government. At the heart of this criticism is data. ” -- New York Times “Statistical agencies face increased demand for data products, and the questions asked by our society are becoming increasingly complex and hard to measure. Meeting these challenges requires innovation [in] cognitive research, and economic and statistical modeling. ” -Roderick Little (Statistician, US Census and U Michigan)
 Never too much Data “Companies that manage their data well are 5% to 6% more productive. ” NYTimes
Never too much Data “Companies that manage their data well are 5% to 6% more productive. ” NYTimes
 Building DBPedia
Building DBPedia
 Words of wisdom • "We have confused information (of which there is too much) with ideas (of which there are too few). " – Paul Theroux • "The great Information Age is really an explosion of non-information; it is an explosion of data. . . it is imperative to distinguish between the two; information is that which leads to understanding. " – R. S. Wurman in his book: Information Anxiety 2
Words of wisdom • "We have confused information (of which there is too much) with ideas (of which there are too few). " – Paul Theroux • "The great Information Age is really an explosion of non-information; it is an explosion of data. . . it is imperative to distinguish between the two; information is that which leads to understanding. " – R. S. Wurman in his book: Information Anxiety 2
 extraction • Data mining") Questions • Role in information science of • Information (knowledge) extraction • Data mining • Metadata • What next?
Questions • Role in information science of • Information (knowledge) extraction • Data mining • Metadata • What next?